
大数据综合试验区对企业创新的影响研究
——来自中国上市公司的经验证据
2024-02-03 08:13刘明
云南大学学报(社会科学版) 2024年1期
刘 明
[云南大学,昆明 650091]
一、引 言
早在1980年,托夫勒在其著作《第三次浪潮》中首次提出了“大数据”一词,并预言大数据将成为“第三次浪潮的华彩乐章”。2011年,麦肯锡正式定义了“大数据”一词,认为“大数据”就是对超大数据的采集、存储与分析的新技术。当前大数据应用已成为我国实体经济现代化发展的新起点,数据驱动型经济体系和模式正在加速形成,数据资源成为实体经济创新发展的新要素。
从实践成果看,大数据促进了互联网与产业创新的融合,推动了传统产业的升级和新兴产业的出现。首先,农业大数据的出现使农业从传统的农场实践转变为高度自动化和数据密集型的行业。(1)谢康,易法敏,古飞婷:《大数据驱动的农业数字化转型与创新》,《农业经济问题》2022年第5期。尖端技术的应用促进了农产品产量增加,成本降低,环境影响减少,以数据为驱动的生产模式正在以可持续和节约资源的方式释放潜力。其次,大数据加快了传统工业向智能工业转型的步伐。智能工业的核心技术之一就是对各种数据进行分析和处理,高频实时的数据流动为工业生产操作可视化提供新的视野。(2)傅荣校:《工业互联网发展的多维度观察——基于概念簇、战略、政策工具视角》,《人民论坛·学术前沿》2020年第13期。最后,各大电商平台无一例外地都借助大数据实现自身的飞速发展。如抖音通过数据分析会精确计算用户喜好,使其一跃成为与Facebook、YouTube比肩的全球用户活跃度Top5的应用。(3)吴义爽,朱学才,袁海霞:《平台市场后发上位的“根据地”战略研究:抖音案例》,《中国工业经济》2022年第10期。
除对宏观经济社会发展产生深远影响外,大数据技术还对企业运营模式、资源整合能力、创新动力等带来根本性变革。(4)冯檬莹,陈海波,郭晓雪:《大数据能力、供应链协同创新与制造企业运营绩效的关系研究》,《管理工程学报》2023年第3期。企业通过大数据来获得关键的信息正成为企业的必要技能,抢占数据资源并从已有数据中获取独特的商业价值是超越竞争对手的决定性因素。(5)焦豪,杨季枫,王培暖等:《数据驱动的企业动态能力作用机制研究——基于数据全生命周期管理的数字化转型过程分析》,《中国工业经济》2021年第11期。一方面,从企业内部功能来看,大数据使企业能够快速适应新环境,能对公司和供应链层面的业务流程创新产生巨大的运营和战略影响,(6)孙新波,钱雨,张明超等:《大数据驱动企业供应链敏捷性的实现机理研究》,《管理世界》2019年第9期。并且通过构建大数据驱动系统以渗透现有行业从而产生颠覆式创新。另一方面,通过利用会员制和社交媒体中可用的数据,并跟踪信息流实时分析大量数据,企业可以更好地了解客户的偏好和需求,并使用它来利用行为分析,使新产品开发速度更快,成本更低。
正是由于意识到从宏观到微观层面的巨大影响力,世界各国都非常重视大数据政策的制订与施行。(7)陈云伟,曹玲静,陶诚等:《科技强国面向未来的科技战略布局特点分析》,《世界科技研究与发展》2020年第1期。例如,美国国际开发署发布了《数字战略(2020—2024)》,试图在全球范围构建以自身为主导的数字生态系统;2021年日本政府设立“数字厅”,旨在从提升行政机构数字化问题入手推动社会的数字化转型。同样,我国也制定了一系列大数据政策,推动大数据产业发展。2014年,大数据首次被写入中国政府工作报告;2015年8月,中国国务院发布《促进大数据发展的行动纲要》,明确“数据已成为国家基础性战略资源”,并于9月在贵州省设立首个大数据综合实验区(以下简称“大数据综试区”)。陈加友(2017)认为,贵州省运用大数据推进了产业转型升级,推动了工业转型发展,苹果、高通、华为、阿里巴巴等互联网巨头企业相继落户贵州,充分印证贵州省的先行先试取得相当的建设成果。(8)陈加友:《国家大数据(贵州)综合试验区发展研究》,《贵州社会科学》2017年第12期。截至2023年8月,我国已建立8个大数据综试区,相关的研究也陆续展开。
已有文献已从多个方面讨论了建设大数据综试区的影响,但仍然存在研究不足与空白。一些文献使用PSM-DID评估大数据综试区的政策效应,通过主观选择参考组中的协变量来匹配实验组,可能得出片面的实验结果。除此之外,现有文献主要评估了大数据综试区对城市经济增长或者绿色转型的影响,较少有研究关注对企业创新的影响。基于以上不足,本文利用2007年至2021年我国1199个上市公司的面板数据,采用多期双重差分法研究了大数据综试区对企业创新的影响,并探讨其中可能存在的调节作用机制,以期为大数据综试区等相关政策的效果最大化提供参考借鉴,夯实我国以数字化驱动创新的发展道路。
二、理论与假设
(一)大数据综试区对企业创新的直接影响
企业创新水平的提升主要取决于两个方面,一是技术能力,(9)彭灿,杨玲:《技术能力、创新战略与创新绩效的关系研究》,《科研管理》2009年第2期。另一方面是资金投入。(10)王亚男,戴文涛:《内部控制抑制还是促进企业创新?——中国的逻辑》,《审计与经济研究》2019年第6期。大数据综试区的建设则为这两个方面提供了有利条件。从技术能力的角度来看,数据资源现如今被视为企业发展所需的新石油,(11)Sivarajah U,Kamal M M,Irani Z,et al,“Critical Analysis of Big Data Challenges and Analytical Methods”,Journal of Business Research,2017,Vol.70.以大数据、云计算、区块链和人工智能为代表的新技术基础设施与以数据中心和智能计算中心为代表的计算基础设施的不断完善,能够助力企业加强对数据资源的利用,(12)孙新波,苏钟海,钱雨等:《数据赋能研究现状及未来展望》,《研究与发展管理》2020年第2期。以创新生产、销售、运营或管理环节,并重新组装物理组件以利用数字技术开发新价值或开拓新市场。
从资金投入的角度来看,大数据综试区将为试验区内的企业提供财政资金支持,例如无偿资助支持大数据的应用创新项目、设立大数据产业基金、建立大数据中小企业融资风险补偿机制和政府直接购买相关公益性、公共性服务等。政府给企业的资金支持能够缓解企业的财务约束,使企业有相对宽裕的资金开展创新研发活动。(13)罗雪婷:《政府补助对高技术企业技术创新效率的影响研究——基于东中西区域的门槛分析》,《调研世界》2020年第10期。同时,获得财政资金支持的企业更容易得到同行认可以及社会信任,使企业获取更多发展所需资源,可以帮助企业加速或扩大其研发活动。基于此,本文提出第一个假设:
H1:大数据综试区的设立能够直接促进企业的创新水平提升。
(二)大数据综试区对企业创新影响的调节因素
首先,为适应大数据时代的发展要求,企业必须具备相匹配的数字化基础与环境,因此企业自身数字化转型意愿势必会影响大数据综试区政策对企业创新的促进程度。数字化转型意愿高的企业会更加积极地完善数字化设备、提升数字技术应用能力,借助支持政策完善数字化环境,进行适应性改革和创新。同时,进行数字化转型的企业通过技术创新可以构建一个数字开放平台,以平台为支撑参与跨边界多元主体生态共建、价值共创和双赢合作,而平台生态的兼容互补性和开放共生性反过来又可使企业能够抵御技术进步和市场变化带来的风险,从而具有更快的响应速度和更强的创新能力。因此本文提出假设:
H2a:企业数字化转型意愿正向调节大数据综试区与企业创新之间的关系。
其次,人力资本是企业打造竞争优势使最独特与最具价值的资源,尤其是高技能人才已经成为企业创新的首要资源。(14)张杰,刘志彪,郑江淮:《中国制造业企业创新活动的关键影响因素研究——基于江苏省制造业企业问卷的分析》,《管理世界》2007年第6期。Cohen和Levinthal(1990)认为,吸收新知识可使组织变得更具创新性和灵活性,并强调由个体积累的知识和经验决定的员工个人吸收能力是企业吸收能力的基础。(15)Cohen W M,Levinthal D A,“Absorptive Capacity:A New Perspective on Learning and Innovation”,Administrative Science Quarterly,1990,Vol.35,No.1.此外,创新产出水平与人才分布存在高度的正向空间相关性这一观点已被得到证实,(16)郭金花,郭淑芬:《创新人才集聚、空间外溢效应与全要素生产率增长——兼论有效市场与有为政府的门槛效应》,《软科学》2020年第9期。高技能人才在空间上的集聚能够促进知识的传播、交流与共享,通过知识溢出改变原有的经济增长方式并促进企业创新活动的开展。因此本文提出假设:
H2b:企业高技能人才集聚水平正向调节大数据综试区与企业创新之间的关系。
最后,企业所能享受到的直接红利就是各种政策支持。政策支持可以分资金型支持与非资金型支持,资金型支持是直接降低企业研发成本的常用政策工具,主要包含税收优惠、直接财政补贴、放宽银行贷款等,(17)Almus M,Czarnitzki D,“The Effects of Public R&D Subsidies on Firms' Innovation Activities:The Case of Eastern Germany”,Journal of Business &Economic Statistics,2003,Vol.21,No.2.可以为受资助企业提供资源和知识寻求方面的支持;(18)陈玲,杨文辉:《政府研发补贴会促进企业创新吗?——来自中国上市公司的实证研究》,《科学学研究》2016年第3期。非资金型支持主要包括企业人才引进、创新技术支持、帮助企业获取各种许可证、公共服务供给等,可以为企业创建良好的创新环境,(19)于明超,申俊喜:《区域异质性与创新效率——基于随机前沿模型的分析》,《中国软科学》2010年第11期。整合企业创新所需科技资源。因此本文提出假设:
H2c:政策支持力度正向调节大数据综试区与企业创新之间的关系。
三、研究设计
(一)模型构建
1.基准模型。
根据上述分析,可将模型构建为:
EIit=α+βTreati×Policyit+γXit+YearFE+FirmFE+εit
(1)
其中,EIit代表第i个企业在第t年的创新水平,虚拟变量Treati是对样本企业的分组,Treati=1代表位于国家大数据综试区的上市企业,即实验组;Treati=0代表位于国家大数据综试区之外的其他地区上市公司,即控制组,Policyit表示国家大数据综试区政策的影响时间,政策提出当年以及之后年份取值为1,之前年份取值为0。Treati×Policyit是企业分组与时间分组的交互项。Xit代表控制变量,εit为随机误差项。此外,模型同时对个体固定效应和年份固定效应进行了控制,以消除不可预测的异质性干扰。
2.平行趋势检验。
双重差分(DID)模型的一个基本前提是平行趋势,其必须满足实验组和对照组两者之间在政策实施之前没有显著差异,基于此,双重差分模型的估计结果才可以被认为是无偏的。因此本文基于以下模型进行平行趋势检验:
EIit=α1+∑δk[Treati×(t=k)]+γ1Xit+YearFE+FirmFE+εit
(2)
其中t=k代表大数据综试区实施之后(或之前)的第k年,为避免多重共线性问题,本文以政策实施前一年作为基期进行平行趋势检验。
3.机制检验。
为了进一步探究大数据综试区设立对于企业创新的影响机制,在模型(1)的基础上,本文通过企业数字化转型意愿、高技能人才集聚、政策支持力度三个调节变量,构建如下模型。
EIi=α1+β2Treati×Policyit+μTreati×Policyit×Medi+γ2Xit+YearFE+FirmFE+εit
(3)
Medi表示调节变量,μ表示政策变量与调节变量交乘项的回归系数,若μ显著,则表明在大数据综试区设立推动企业创新过程中存在调节效应。
(二)数据来源
本文选取了2007年至2021年为时间窗口,以中国上市公司作为研究对象,数据主要来自于CSMAR数据库、中国国家知识产权局(CSIPO)以及上市公司的年度财务报表。并且按如下方式处理数据:(1)排除了被标记为特殊待遇(ST&*ST)的公司以及被暂停或退市的公司样本;(2)排除所有属于金融、保险行业的公司;(3)排除所有缺少重要变量值的公司;(4)对连续型进行上下1%缩尾处理,去除极端值的影响,最后保留1199家公司作为样本进行分析。
(三)变量选取
1.被解释变量:企业创新(EI)。
现有研究主要根据创新投入与创新产出对企业创新水平衡量。根据陈华东(2016)、张栋(2021)(20)陈华东:《管理者任期、股权激励与企业创新研究》,《中国软科学》2016年第8期;张栋,胡文龙,毛新述:《研发背景高管权力与公司创新》,《中国工业经济》2021年第4期。等学者的研究,选取企业年度研发投入占销售收入的比重来表示企业的创新投入水平(RD),企业申请专利数可以作为企业创新产出水平的直接体现,因此本文选取企业申请专利数作为创新产出(PA)的代理变量。
2.核心解释变量:政策变量(Treati×Policyit)。
政策变量为组合虚拟变量,其系数用以衡量大数据综试区政策对企业创新的影响程度。根据国务院公布的国家级大数据综试区试点名单,本文将位于贵州省的企业的政策冲击时间设为2015年,位于其他试点地区的企业的政策冲击时间为2016年,处于试点地区并且在政策冲击当年或之后年份取值为1,否则赋值为0。
3.控制变量(Controls)。
为了更准确评估大数据综试区对企业创新的影响效应,本文控制了其他可能会对企业创新产生影响的因素。其中存续年龄(Age)用企业成立年份取对数表示;审计意见(Audit)为类别变量,如果出具标准无保留意见则取值为1,其余为0;资本结构(CS)用总负债与总资产之比来表示;无形资产(Intang)用企业无形资产所占份额表示;账面市值比(BM)用股东权益与公司市值的比值来衡量,市场价值(TuobingQ)用企业市场价值与资产重置成本的比值表示(如表1所示)。
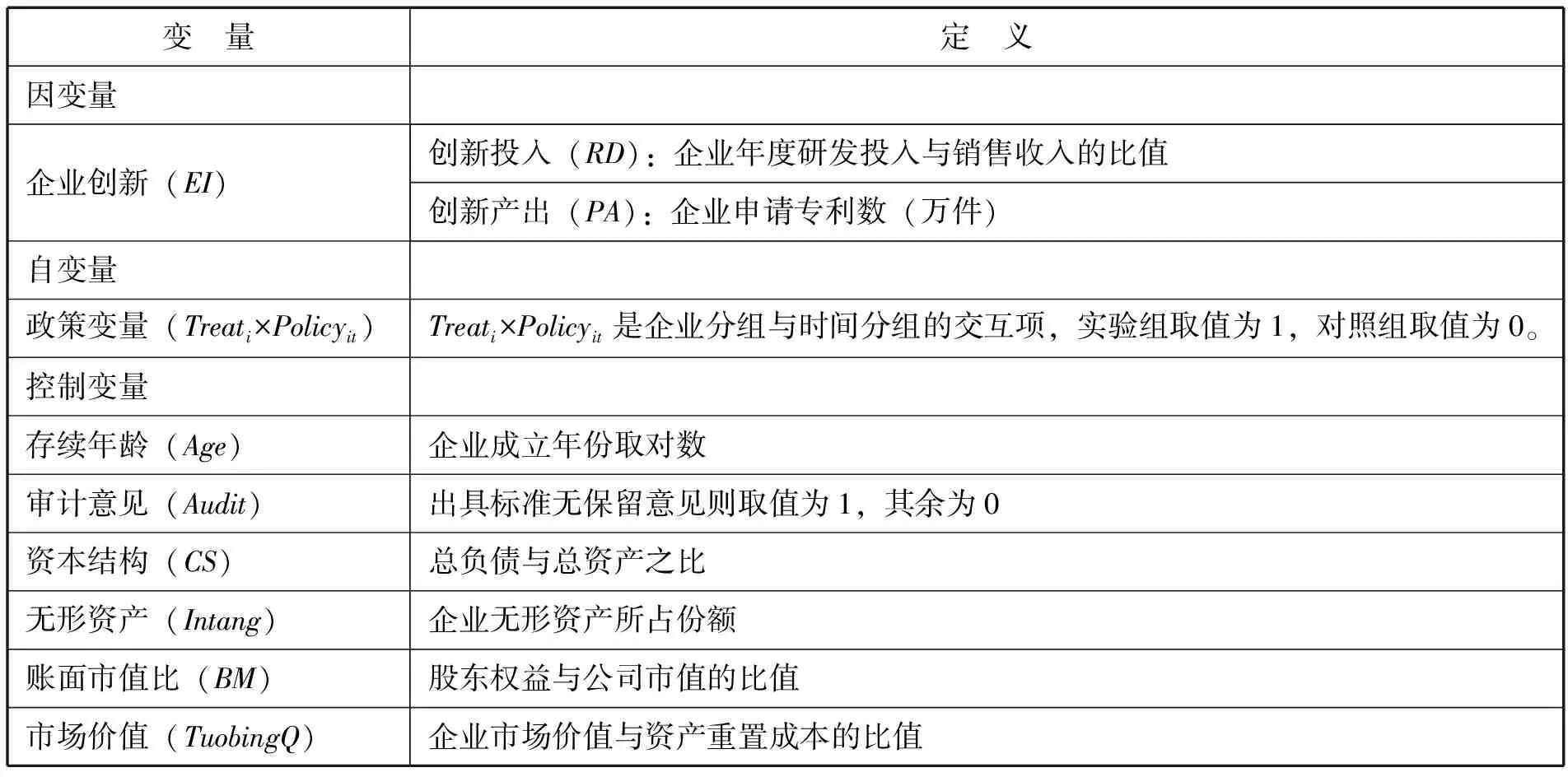
表1 变量列表
四、实证研究
(一)描述性统计
为了更好地描述各变量特征,各变量的描述性统计结果如表2所示,对各主要变量的平均值、方差、最小值和最大值进行了统计。从中可以看出,创新投入的最大值为17.67,最小值为0,创新产出的最大值为7.4,最小值为0,说明在本文所选择的样本中企业创新水平存在较大差异。
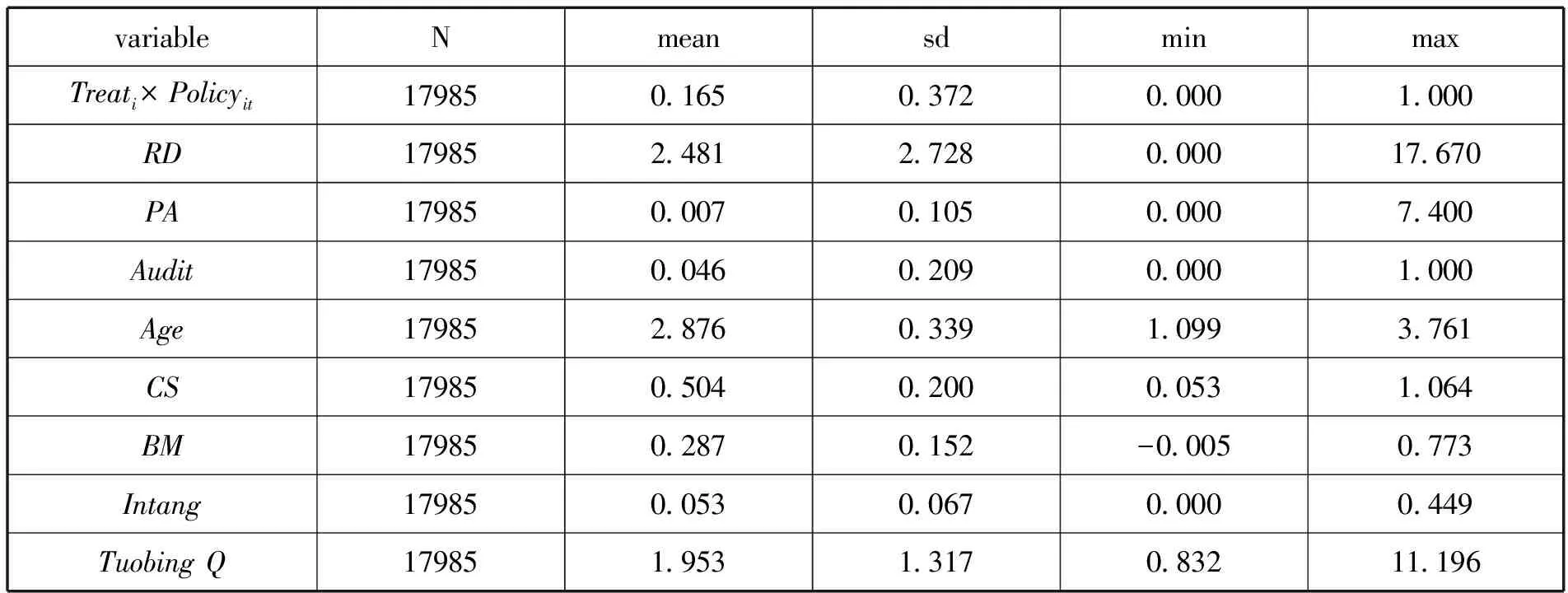
表2 描述性统计
(二)基准回归
为了验证大数据综试区设立是否存在政策效应,按照模型(1)进行回归,回归结果如表3所示。从表3可以看出,无论是否加入控制变量以及是否对年份、企业进行固定,大数据综试区设立对企业创新均产生显著正向影响。进一步地从创新投入和创新产出两个维度来看:对企业创新投入而言,政策冲击虚拟变量的回归系数为0.183,在1%的置信水平上显著,表明大数据综试区的设立能够推动企业加大创新投入,提升企业对研发创新的重视程度;从企业创新产出来看,政策冲击虚拟变量的回归系数为0.02,在5%的置信水平上显著,表明大数据综试区的设立同样能够提升企业的创新产出水平。
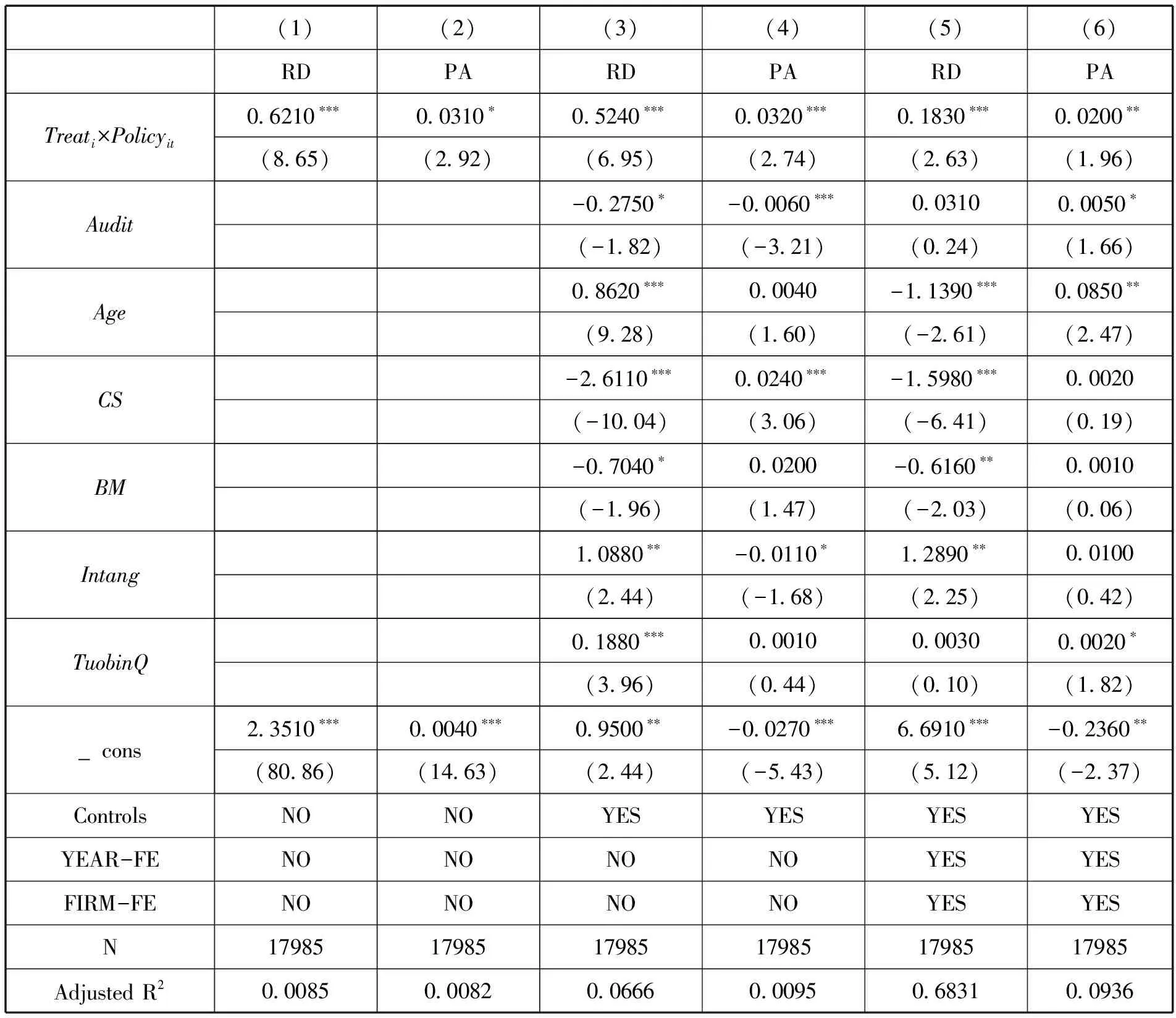
表3 基准回归
(三)平行趋势检验
采用双重差分(DID)模型的一个重要先决条件是满足平行趋势,即在政策实施前实验组和对照组之间不存在显著差异,因此本文采用两种方式进行平行趋势检验。
1.时间趋势法。
第一种方法是通过直接观察实验组与对照组因变量的时间变化趋势,据此判断两组是否符合平行趋势,结果可见图1。由图1可知,不管是创新投入还是创新产出,在政策实施之前两者都没有表现出显著差异,由此初步认为本文所选取的样本是满足平行趋势要求的。
2.事件研究法。
直接观察因变量的变化趋势是一种比较粗略的检验方法,因此本文进一步采用事件研究法进行平行趋势检验。根据模型(2),生成政策实施前后各4年的虚拟变量与处理组虚拟变量的交互项,将这些变量作为解释变量进行回归,交互项系数反映的就是特定年份处理组与控制组之间的差异,结果如图2所示,图2(a)显示了创新投入的平行趋势检验结果,图2(b)显示了创新产出的平行趋势检验结果。由图2可以观察到在政策实施之前,交互项(pre)系数均不显著,而在政策实施之后的交互项(post)系数开始变得显著,说明模型满足平行趋势并且存在一定的时滞效应。
(四)安慰剂检验
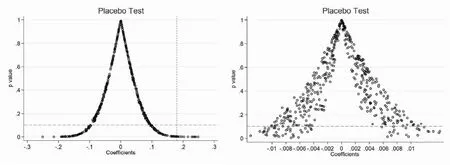
为进一步排除其他不可观测的潜在因素影响大数据综试区建设对企业创新的估计结果,本文进行安慰剂检验,具体思路如下:随机抽取与大数据综试区相同数量的城市构建虚拟试点政策变量,这些被抽取的城市构成“伪处理组”,再为每一个“伪处理组”随机抽取一个年份作为政策时点,最后将两个变量进行交乘,生成“伪政策虚拟变量”交互项进行回归,观察伪政策虚拟变量的估计系数,并将该过程重复500次,得到伪政策虚拟变量的估计系数核密度分布图(见图3),图3(a)显示了创新投入随机抽样的回归结果,图3(b)显示了创新产出随机抽样的回归结果。由图3可以看出,不论是创新投入或是创新产出,随机抽样回归的系数集中分布于零值附近,与真实回归系数相差较大,且P值大部分位于0.1的水平线之上,证明随机抽取的伪政策变量对于企业的创新水平并不能产生显著影响。这表明政策效应并没有受到其他随机因素的影响,本文的研究结论具有稳健性。
(五)预期效应检验
多期双重差分模型的运用需要保证在该项政策实施之前尚未对研究对象形成有效预期,即需要保证大数据综试区政策的外生性。因此在回归方程中加入大数据试验区设立之前一年的虚拟项didf1,回归结果见表4所示,didf1并不显著,可以认为不存在预期效应。
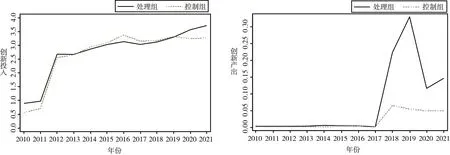
图1 时间趋势法

(a) (b)
(a) (b)
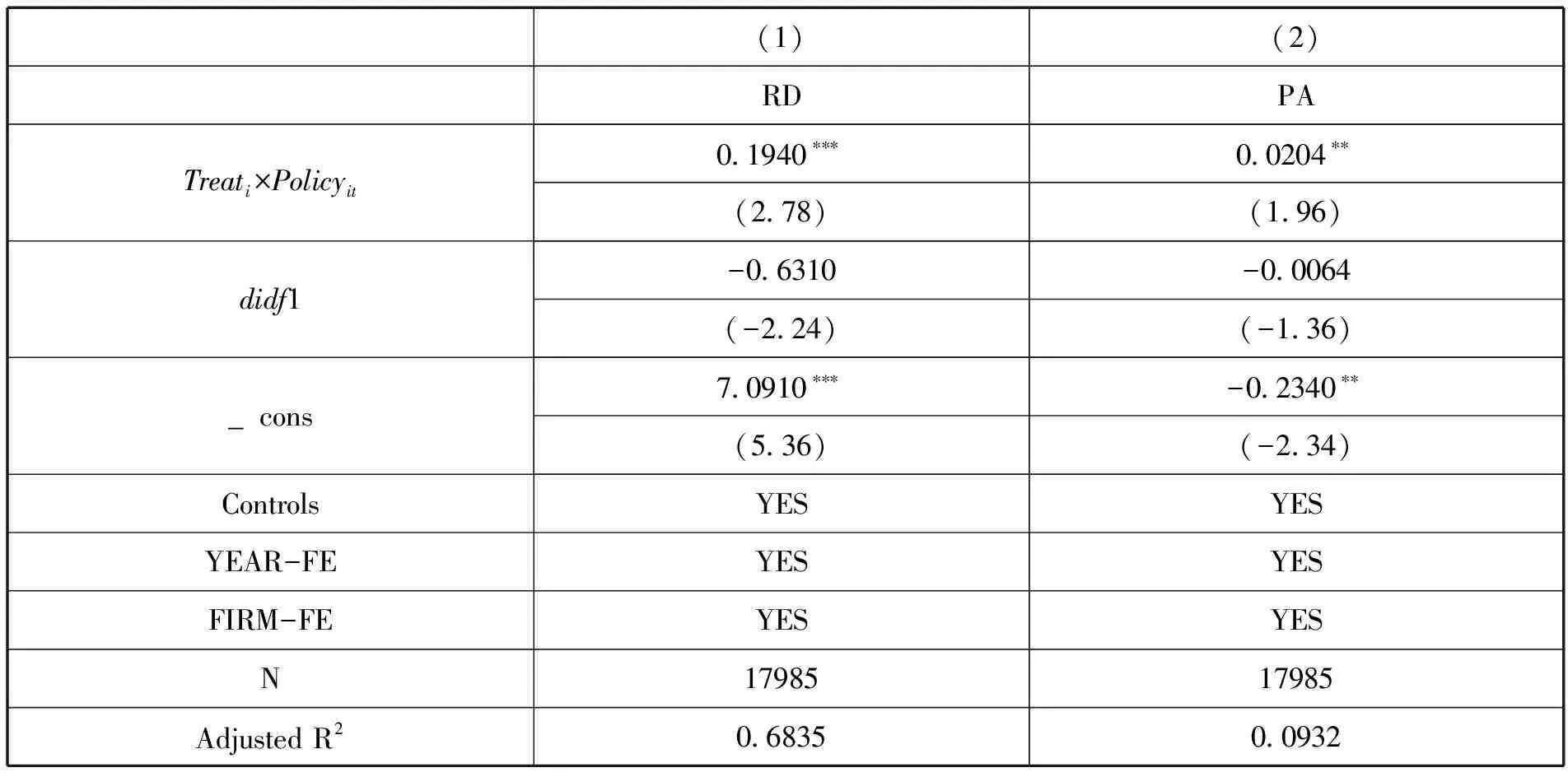
表4 预期效应检验
(六)其他稳健性检验
1.更换被解释变量。
为了避免由变量定性选择导致估计结果存在偏误,本文重新刻画企业创新的衡量方式,现采用企业创新投入总额(rd)与企业发明专利申请数(Ipatent)作为替换变量,回归结果见表5。由表5第(1)(2)列可知,将被解释变量替换之后政策变量的回归系数依旧显著为正,表明前文的结果相对稳健。
2.单期DID。
大数据综试区的设立时间分别为2015年与2016年,但在2015年设立的仅有贵州省,其他试验区均为2016年设立,因此借鉴邱子迅和周亚虹(2021)的做法,(21)邱子迅,周亚虹:《数字经济发展与地区全要素生产率——基于国家级大数据综合试验区的分析》,《财经研究》2021年第7期。将2016年统一设定为政策起始时间,重新估计后结果如下。由表5(3)(4)列可知,将模型设置为单期DID之后回归结果与基准回归相近。
3.排除其他政策的影响。
在研究时间区间内,企业创新可能还会受到其他政策的影响,而导致基准回归结果产生系统性偏差。通过对政府在2015年前后的政策进行梳理,本文选择“宽带中国”政策(didkd)以及智慧城市试点(didzh)来做进一步分析,将这两个政策的虚拟变量带入模型,以评估大数据综试区设立对企业创新的“净效应”,回归结果见表5(5)(6)列。在将“宽带中国”政策和智慧城市试点的虚拟变量纳入模型之后,大数据综试区设立对企业创新的影响仍然显著为正,但系数有所减小,说明大数据综试区的政策效应有可能被高估,但其对企业创新的推动作用仍然显著存在。
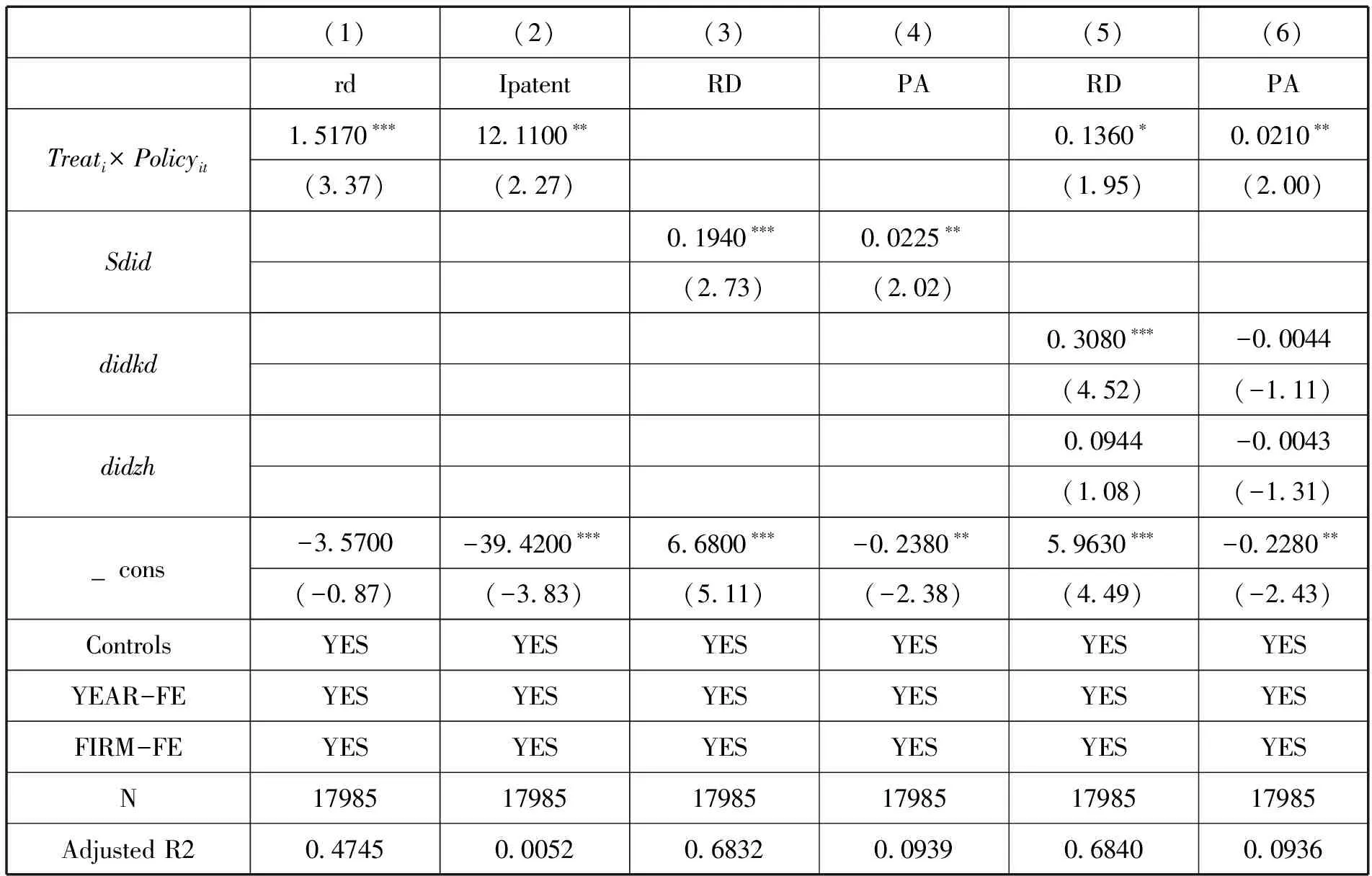
表5 稳健性检验
(七)异质性分析
在基准回归中,本文验证了全样本下大数据综试区对于企业创新的推动作用,但基于总体样本的分析可能会掩盖某些差异。因此,本文对此展开进一步分析。
1.公司治理能力异质性。
本文以高管是否具有金融背景、是否具有海外背景、是否存在“两职合一”作为区分指标,以此检验公司治理能力的差异性是否会导致不同的政策实施效果,回归结果见表6。从表6可以看出,当高管具有金融背景与海外背景时,大数据综试区对于企业创新的推动作用显著。根据烙印理论,金融专业背景有助于高管更好地识别与管控风险,(22)李卓松:《企业风险承担、高管金融背景与债券融资成本》,《金融评论》2018年第10期。使其更加了解银行等金融机构的信息需求,为企业带来更丰富的金融资源以支持研发活动开展。海归高管则会表现出更多个体主义倾向和较高风险或不确定性容忍,(23)淦未宇,刘曼:《海归高管与企业创新:基于文化趋同的视角》,《上海财经大学学报》2022年第1期。因此海归高管更敢于将风险性创新活动纳入企业决策范围,驱动创新决策,企业更可能进行高风险的创新活动。大数据综试区的设立对“两职分离”的企业具有显著的创新推动作用,而“两职合一”不利于企业创新。主要原因可能是“两职合一”作为一种相对集权的领导权结构,会弱化董事会对高管决策的监督功能,在研发投资项目的风险选择、总量决策和结构配置过程中,CEO可能不愿意将资源投向高风险领域,从而导致为了自身利益最大化而导致的非效率研发投资。
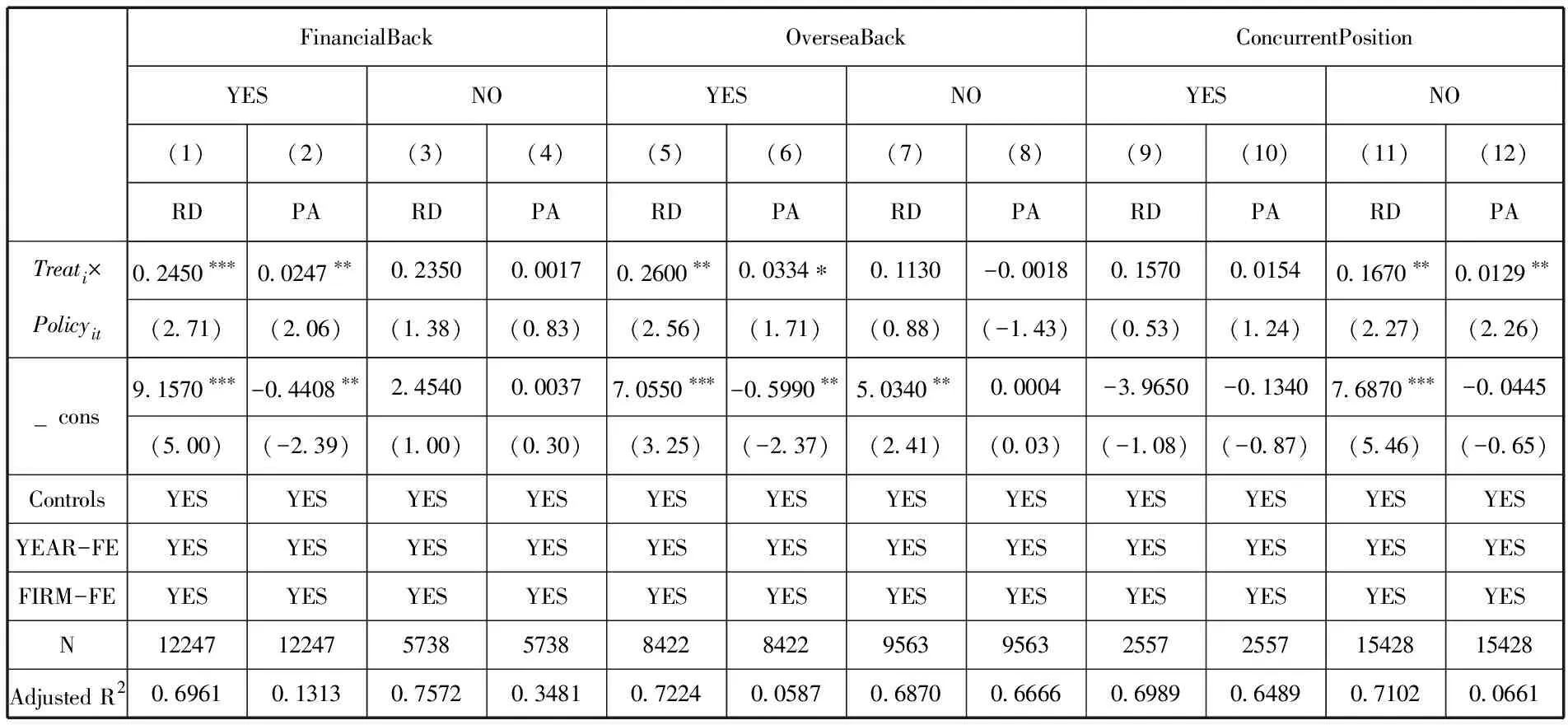
表6 公司治理能力异质性
2.行业异质性。
参照彭薇和熊科(2018)的做法,(24)彭薇,熊科:《全球价值链嵌入下“一带一路”沿线国家产业转移研究——基于世界投入产出模型的测度》,《国际商务(对外经济贸易大学学报)》2018年第3期。根据劳动力、资本和技术三种生产要素在各产业中的相对密集度,将其分为资源密集型、劳动密集型、知识密集型以及资本密集型产业。本文依据上述产业划分将所有企业分为四类进行异质性检验,回归结果见表7。由表7可知,大数据综试区设立对知识密集型产业产生显著的正向影响,对其他类型的产业并没有产生显著影响。知识密集型产业更多依赖智力成果,技术知识所占比重高,一般需要大量持续的资金投入,如果该产业能够充分、便捷的享受税收优惠等政策支持,可有效减轻在研发创新活动中的成本压力与风险,从而激发创新活力,产出更多创新成果。
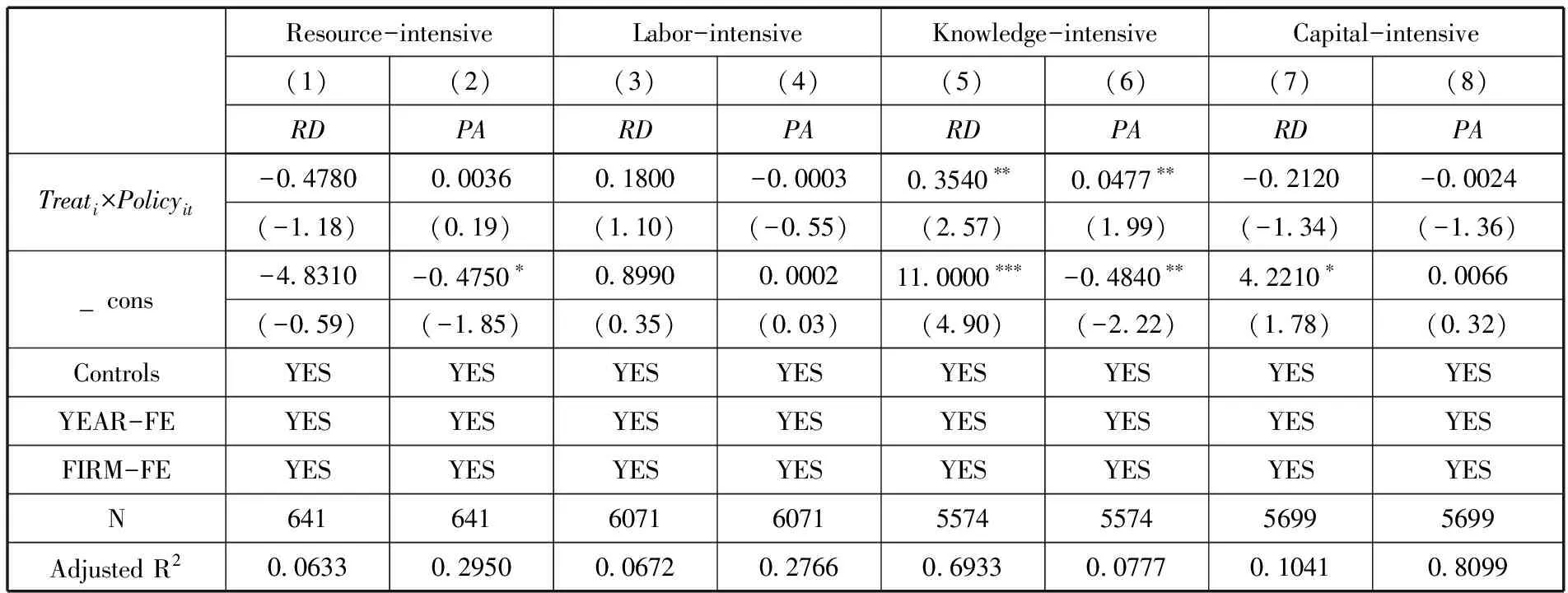
表7 行业异质性
3.地区异质性。
按照《关于明确东中西部地区划分的意见》文件规定,本文将总体样本划分为东、中、西部地区三个子样本分别进行回归,以检验是否存在地区异质性。由表8结果可知,大数据综试区设立对东部地区的企业创新水平产生显著影响,对中西部地区企业创新的推动作用并不显著。从各个子样本的样本数可以看出,东部地区的样本数为11490,占比为63.89%,东部地区是创新资源的主要集中地。上市公司更多地集聚在东部地区归因于东部地区的区位优势与经济基础,为上市企业的发展提供了良好的发展机会与平台。在该区域,产业链上的企业以及平行企业之间可以进行更频繁便捷的交流关联,上下游企业基于长期合作建立的信任,可以推动企业之间进行共同研发,合作创新。
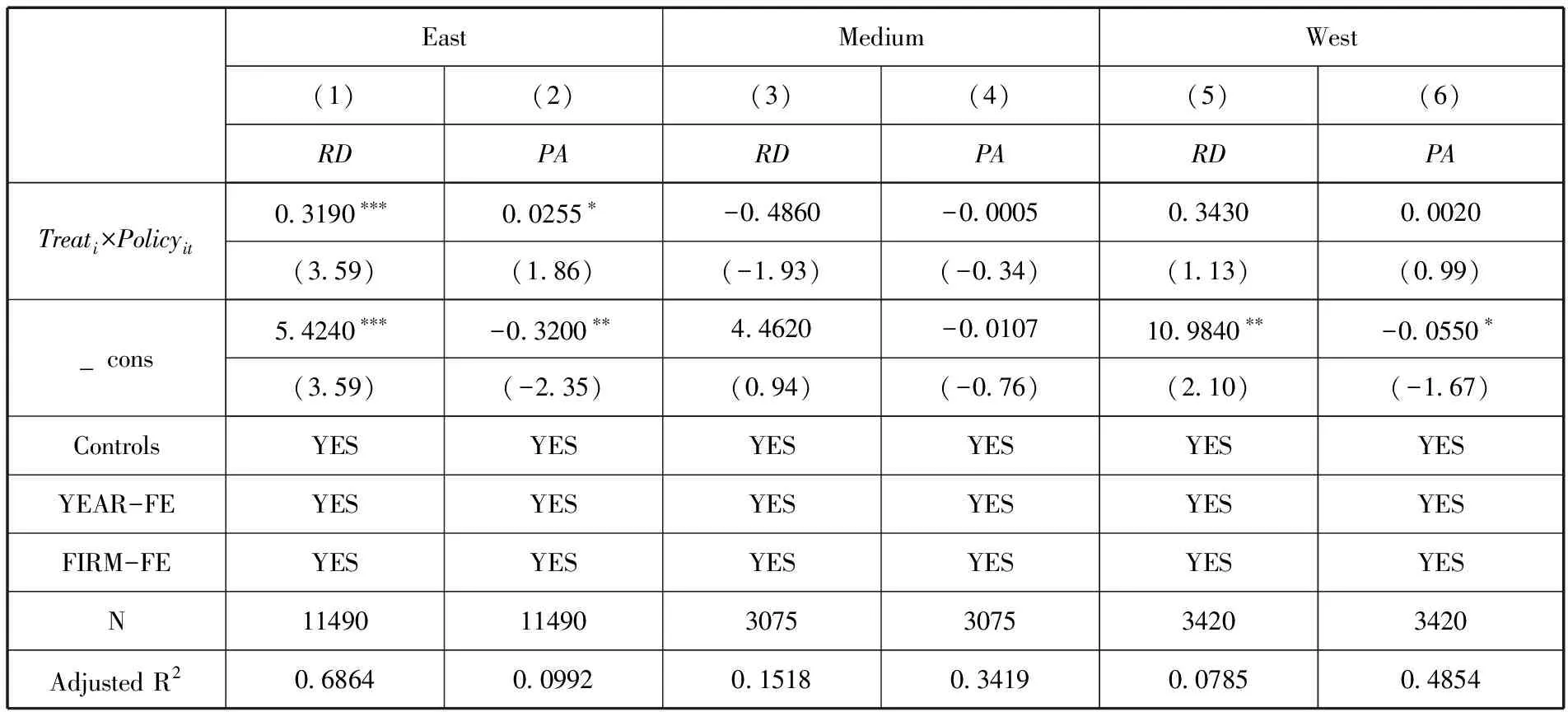
表8 地区异质性
(八)机制检验
为检验前文推测,依照模型(3),分别将企业数字化转型意愿(Digitization)、企业高技能人才集聚水平(R&D personnel)、政策支持力度(Subsidy)与政策虚拟变量进行交乘,以探究是否存在调节机制。企业数字化转型意愿的测度是通过Python爬取企业年报中大数据技术、人工智能技术、区块链技术、云计算技术以及细分指标的关键词词频,此类关键词频数越高也就代表企业数字化转型意愿越高;企业高技能人才集聚水平用企业研发人员占总人数的比值来表示;为了对政策持力度进行量化,选取企业财务报表中所披露的当期政府补助金额取对数来表示。调节效应回归结果见表9。
表9(1)(2)列表示企业数字化转型意愿的调节作用检验结果,可以看出交乘项的系数均在1%的置信水平上显著为正,假设H2a得到验证。这表明企业自身数字化转型意愿越强,大数据综试区的设立对此类企业的创新推动作用更显著。表9(3)(4)列表示企业高技能人才集聚水平的调节作用检验结果,交乘项的系数均显著为正,假设H2b得到验证。这表明当企业所拥有的研发人员越多时,企业的主观能动性越强,为企业更好地抓住政策红利提供了契机,能够促进更多智力创新成果产出。表9(5)(6)列表示政策支持力度的调节作用检验结果,交乘项的系数均显著为正,假设H2c得到验证,表明政策支持能够调节大数据综试区设立对企业创新的推动作用,企业所获得的政策支持力度越大,就有越充足的资金投向研发创新活动,从而促进企业的创新成果产出。
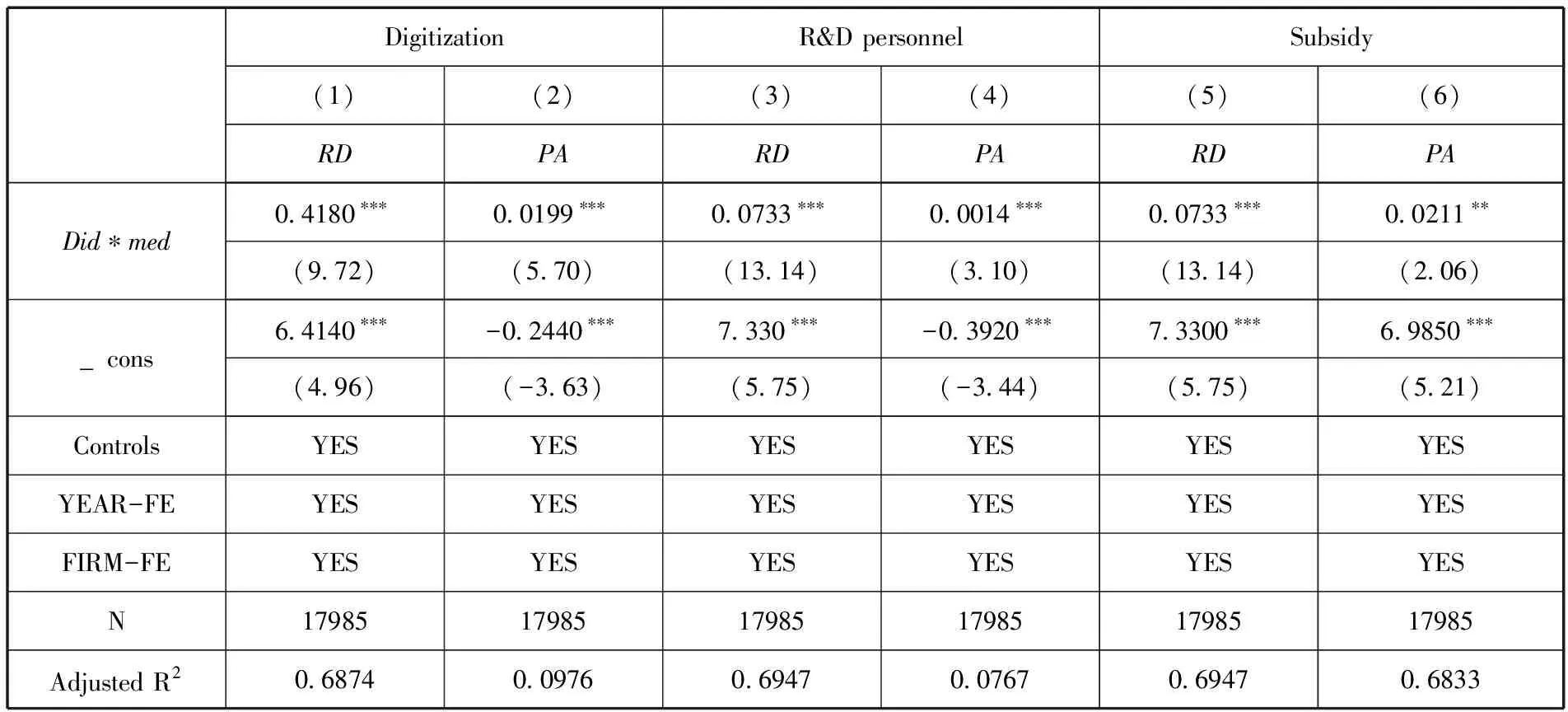
表9 调节效应检验
结 论
本文利用2007年至2021年中国1199个上市公司的面板数据,采用多期双重差分法(DID)研究了大数据综试区建设对企业创新的影响,研究发现:首先,位于试验区的企业比非试验区的企业创新投入水平提高18.3%,创新产出水平提高2%,并且两种促进效应均存在一定的时滞性。在进行一系列稳健性检验后研究结论依然成立。其次,通过机制检验表明,大数据综试区对企业创新的促进效应受到企业数字化转型意愿、企业高技能人才集聚水平以及政策支持力度的正向调节作用。最后,这种特殊的政府引导行为与企业创新之间的关系存在显著异质性。从公司治理能力看,具有海外经验与金融背景的高管对企业的创新促进作用更为明显,与“两职合一”的企业相比,“两职分离”的企业更能被激发创新活力;从企业所在的行业差异看,知识密集型企业在大数据综试区政策冲击之下的反应更为明显;从地理区位看,相较于中西部地区,东部地区的企业能够更充分地享受大数据综试区政策红利,“创新引领率先实现东部地区优化发展”的态势正逐步形成,为建立区域协调发展新机制提供坚实基础。
根据以上研究结论,本文提出了如下政策建议:
(1)我国应进一步加快以大数据驱动数字经济发展步伐,特别是充分发挥大数据综试区建设的引领和示范作用,总结和提炼建设过程中的经验规律,实现大数据综试区实验效果与其他数字化政策的叠加效应。尤其是2019年国家发改委印发《国家数字经济创新发展试验区实施方案》,确立了河北省(雄安新区)、浙江省、福建省、广东省、重庆市、四川省6个国家数字经济创新发展试验区,这些新试点与大数据综试区建设遥相呼应,更应相互借鉴、取长补短,以数字技术驱动区域创新、联动发展。
(2)政策制定应因地制宜,分类施策,量力而行。各试点政策的规范是在发展过程中不断探索与完善的,在国家总体思路指导下,各地方政府应因地制宜探索政策工具、实施方法等具体内容,既要避免因资源的短缺而造成的发展动力不足,也要避免因过度投入所造成的资源积压与浪费。更具体的来说,东部地区应总结与推广创新引领发展的先行经验,发挥创新要素集聚优势,带动中西部地区创新步伐,加快形成区域协调发展新机制。
(3)加强对企业数字化转型的鼓励和引导。现阶段,中小企业在进行数字化转型时普遍具有主观顾虑与客观条件的两大阻碍。为此,各级政府应出台一系列减税降费、转型补贴等惠企扶持政策,充分激发企业数字化转型的意愿与活力。具体的,应鼓励有条件的地方按照规定通过专项资金、补贴政策等方式,为中小企业提供贴息和融资担保。同时,探索建立多元化、多渠道的社会投入机制,鼓励金融机构提供中小企业数字化转型相关的产品和服务,加强对中小企业数字化转型的资金扶持。
(4)实行开放、包容、积极的人才政策,切实扩大企业对高技能劳动力的吸纳能力。鼓励企业根据自身需要采取灵活的办法吸引各类人才,引进具有相关知识和专业背景的人才担任企业高管,尤其是具有海外经验与金融背景的专业人才。同时,要搭建与人才发展相匹配的产业配套政策和工作平台,解决好与个人发展相关的生活 、生产、科研等配套服务,做到“引得进、留得住”。更重要的是,政府要扮演好公共服务提供者角色,构建人力资源信息库,实现数据互联互通、信息共享,促进就业岗位精准匹配。
猜你喜欢
现代经济信息(2023年19期)2023-09-04
国际商务财会(2023年6期)2023-04-10
——基于“反事实”视角
南方经济(2022年3期)2022-03-24
纺织科学研究(2021年6期)2021-07-15
小学生学习指导(高年级)(2021年4期)2021-04-29
河北理科教学研究(2020年2期)2020-09-11
福建基础教育研究(2019年1期)2019-09-10
福建基础教育研究(2019年1期)2019-05-28
中国卫生(2016年2期)2016-11-12
时代青年·视点(2016年5期)2016-05-14
