
基于机器学习的民航信息岗工作负荷预测研究
2024-02-02 11:46:16李华锋辜汝桐吴东岳
民航管理 2024年1期
□ 李华锋 辜汝桐 吴东岳/文
一、引言
民航的信息收集和分析工作是保障航空公司航班签派放行和运行控制不可或缺的一部分,对民航信息岗位的有效管理是确保各类信息上传下达的有力措施。航行情报工作的航行通告体现了民航信息工作的信息质量要求——完整、及时、准确、一致与规范。随着民用航空业的高速发展,通告量快速增长、通告类型与来源也不断丰富,然而以航行通告岗为代表的民航信息部门所面临的工作负荷也不断加大。工作负荷的大小无疑直接影响着工作人员的工作状态,因此精确评价和预测民航信息岗工作负荷有助于提升服务品质、保障飞行安全。
对民航从业人员工作负荷的分析过去集中在主观量表、工作时长以及生理指标等三个维度,国际民航组织(1984)1使用DORATASK 方法与MBB 方法,开创性地总结出一种ATC 扇区容量与工作负荷有效评估方法。随着大数据时代的到来,当前已有不少学者使用机器学习等方法对工作负荷进行预测与评估,Chatterji 和Sridhar(1999)2通过神经网络模型对管制员的工作负荷进行评估与模拟,得到工作负荷的预测模型,可模拟各种情形下管制员的工作负荷。Agnetis 和Smriglio(2000)3提出一种隐枚举算法,分析在m 个并行机上寻找n 个作业的可行调度模型,该算法能有效地求解签派员的工作负载。吴丹和潘卫军(2015)4以扇区复杂性因素为评价指标,综合考虑扇区交通态势,借助ATWIT 技术进行测评,用BP 神经网络评估管制员工作负荷。温瑞英和王红勇(2015)5根据地空通信实测数据,利用岭迹图筛选复杂度评价指标,建立岭回归BP 神经网络组合模型,对管制员的工作负荷进行预测。杨琪等(2021)6结合飞行员生理指标数据、NASATLX 量表主观评价数据指标,建立基于粒子群算法优化的支持向量机的飞行员工作负荷预测模型。综上,可看出目前学界对于工作负荷的研究已经逐渐从评估转变为预测,而机器学习与深度学习等算法在其中发挥了极大的用处。
本文以航行通告岗为例,提出基于相似日数据的AdaBoost 民航信息岗工作负荷预测模型,使用灰色关联分析采集训练集中的相似日数据,提高样本的数据相关性,最后根据集成学习理念构建特征机器学习预测模型,并将其运用于工作负荷预测之中。基于本文所提方法,航空公司在后续需要进行工作负荷预测时,可以实时根据系统后台数据进行预测,有效缩短工作负荷评估周期,提高工作负荷预测的准确性。
二、基于 GRA 和“近大远小”时间原则的相似日选择
(一)相似日与相邻日
相似日是指预测日在训练集中信息类型和数量相似的历史日(孟洋洋等,2010)7。相似日能够反映特定类型与数量的信息收发情形下民航信息岗的工作负荷。然而,由于部分训练数据与预测日之间的时间跨度较长,外界的变化(如航季变化、大规模军事演习、特殊地区的变化等)可能导致相似日数据与预测日的实际情况存在很大的不同。利用这些数据样本对模型进行训练,预测结果与实际值可能存在较大误差。
相邻日是指与预测日时间相近的历史日。相邻日与预测日之间,时间跨度短,除了信息类型与数量有所不同之外,其他情况大体上是一致的,这弥补了仅以信息类型与数量作为依据进行预测的不足。相似日和相邻日的合理使用能够起到取长补短、相得益彰的效果,因此在相似日选择上采取“近大远小”的时间原则(谭风雷等,2022)8。选择相似日数据可以提高模型训练时输入特征与目标输出之间的相关性。由于相似日的航行通告数据在工作负荷和情境因素上与目标日更为接近,因此机器学习模型能够更好地学习和预测工作负荷趋势。
航行通告岗的信息处理体现在航行通告的数量与类型,而航行通告的及时处理与通报是航行通告岗的基本工作要求,因此航行通告岗的整体工作负荷主要体现在单位时间内是否及时处理收到的通告。本文以单位时间内通告处理数量与通告接收数量之比作为航行通告岗工作负荷的评价指标。采用“近大远小”时间原则筛选出相似日数据,以工作负荷为特征的训练集更具有类似性和时间延续性。
(二)基于 GRA 的相似日选择(高扬和许星,2013)9
不同类别的信息,影响其处理难度、工作量以及处理过程的灵活程度等,因此在分析航行通告岗的工作负荷时使用航行通告类型与收报情况作为评价航行通告复杂性的评价指标,所选指标具体如表1:

表1:航行通告复杂性评价指标
收报类型与数量的波动性和无规律性是影响工作负荷预测精度的重要原因,因此寻找预测日与历史数据间的关系对于提升预测精度至关重要。本文选取灰色关联分析作为数据样本集的获取方法。灰色关联分析针对航行通告复杂性情况进行分析,以数据序列为基础,通过灰色关联度反映影响因子间的相似程度。在序列中,令X0为被预测序列,Xi为对比序列,数据序列和对比序列之间的关联度系数为:
三、AdaBoost 工作负荷预测模型
(一)CART 算法
CART 决策树又名分类回归树,是在ID3 决策树的基础上进行优化的决策树,主要有以下三个特点:CART 既能是分类树,又能是回归树,这主要取决于输出数据是离散还是连续的。CART 采用二值分割法对数据进行分割,形成二叉树。当CART 是分类树时,基尼指数被用作节点拆分的基础。基尼系数越小,该特征中包含的杂波就越低。当CART 是回归树时,以样本的最小方差作为节点分割的依据,它主要是对各种特征因子进行递归划分,预测结果由最终的叶节点均值得到。
(二)AdaBoost 算法
通过CART 算法构建初步模型,提出自适应提升的工作负荷预测方法,利用 AdaBoost 的权重分配与重组,再次提高模型的预测精度。自适应提升算法最早应用于分类问题,随着研究的深入,AdaBoost 算法现可通过改变样本权值的分布应用于回归预测。
AdaBoost 从初始训练集中训练CART 基学习器,在每次的迭代过程后根据基学习器的表现与误差调整训练样本分布与计算权重;与普通boosting 族算法不同,AdaBoost 会提高前一轮基学习器错误分类的样本权值,同时降低正确分类的样本的权值,不断重复,直到达到预先指定的基学习器数量。最后根据组合策略将所有基学习器组合起来,得到最终的强学习器。这个过程被称为集成学习,其一般结构如图1所示。
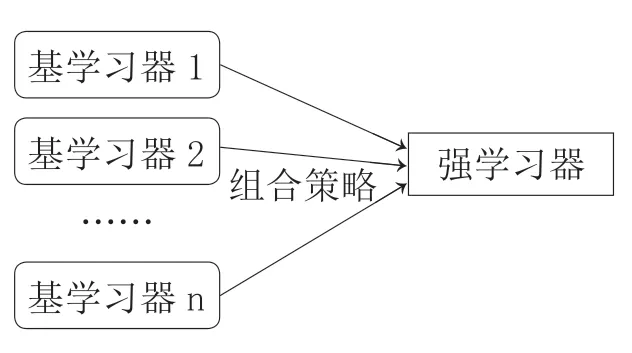
图1:集成学习结构
构造基于相似日的AdaBoost 民航信息岗工作负荷预测模型步骤为:
1.利用 GRA 分析训练集数据与预测日间的关联程度,采取“近大远小”时间原则选择相似日构成训练集,并将数据进行归一化处理。
2.初始化CART 和训练样本的权值分布D(1),在步骤1 的基础上,得到决策树的全局分裂最优解,并将结果赋予CART 决策树。
式中,m为样本容量,w1i表示训练初始基学习器时第i个样本的权值;
3.使用权重为Dk的样本集训练数据,即对T 个决策树进行训练时,得到基学习器Gk(x)并计算误差:
4.根据预测误差计算出第k个基学习器的回归误差率以及其权重系数:
5.根据权重Dk更新下一次样本的权重分布(Zk是规范化因子):
6.根据以上步骤训练到设定的基学习器数量与其对应的权重系数ak,根据相应的组合策略得到最终强学习器:
f(x)=Gk*(x)
其中,Gk*(x)是所有的中位数值乘以对应序号k*对应的弱学习器。
基于相似日的AdaBoost 工作负荷预测模型流程如图2,根据最终强学习器进行民航信息岗工作负荷预测并得到最终预测结果:
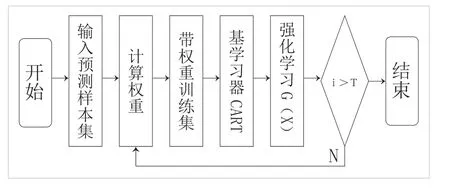
图2:基于相似日的GA-CART-AdaBoost工作负荷预测模型流程
四、算例分析
(一)数据来源
以南方航空运指中心航行情报部航行通告室为研究对象,通过采集其2021 年第四季度的航行通告处理数据进行解析处理,内容包括收发报数量,处理时间,通告类别等信息。
(二)基于GRA 的相似日样本集提取
下面将历史样本中2021 年11 月26 日~2021 年12 月05 日作为待预测日,分析这10 个待预测日的相似日选择结果。以2021 年11 月26 日为例,筛选出关联度≥0.9 的相似日共9 日,分别为评价项10 月2 日、8 日、14 日、22 日、29 日,11 月4 日、5 日、8 日、9 日、10 日、15 日、21 日、22 日、30 日,12 月7 日、10 日、17 日。此时基于时间“近大远小”原则,通过统计手段选择时间跨度上最近的5 个相似日为11 月15 日、21 日、22 日、30 日与12 月7 日。同理可得2021 年11 月26 日~2021 年12 月05 日10 个待预测日的相似日选择结果,结果如表2 所示。根据以上相似日选择搭建训练集样本,本文以1 小时为1 个时间片段,每个时间片段的计算结果作为1 个样本,去除重复日数后有效样本数共计840 个,其中训练集与测试集的占比为8 ∶2。
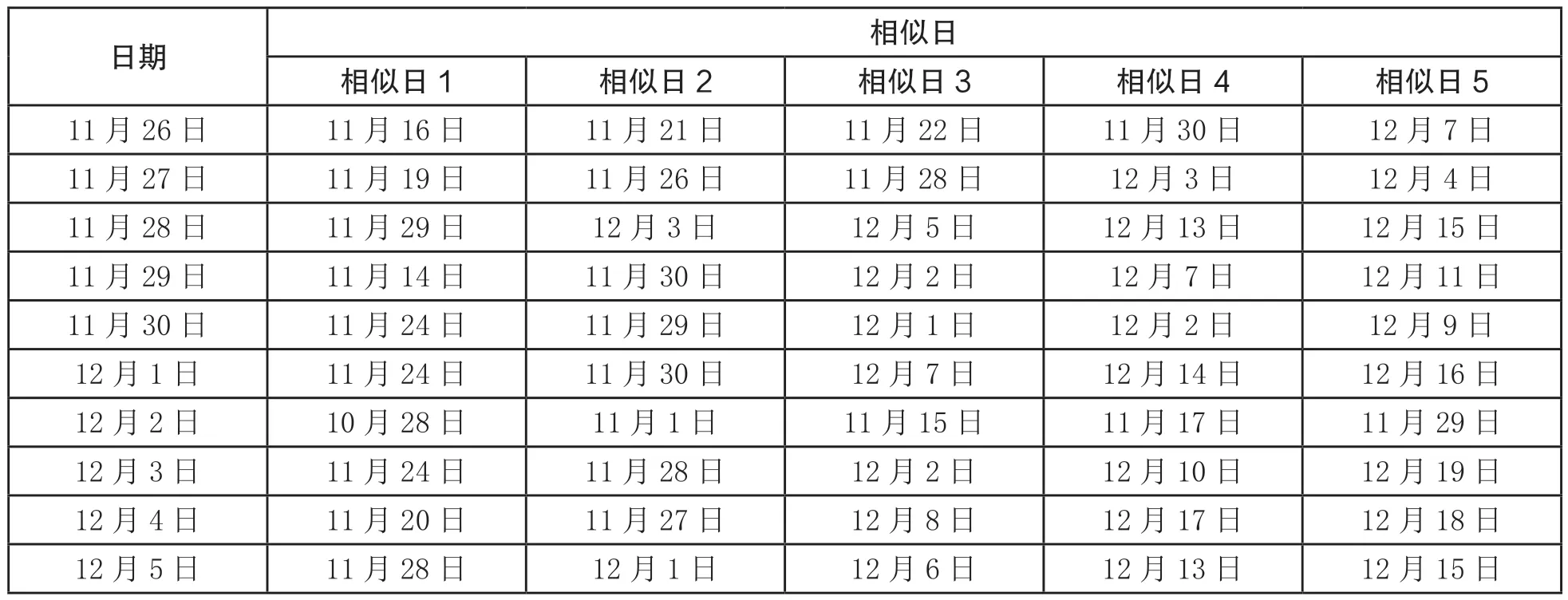
表2:待预测日的相似日选择结果
从表2 可以看出,待预测日筛选出的相似日有的距离待预测日较远,有的距离较近,这表明文中所采用的方法不仅考虑了时间因素,还充分考虑了航行通告当日的复杂性情况,这样选择的相似日具有较高的相似性。
(三)模型精度评价指标
选用均方根误差(RMSE)、平均绝对相对误差(MAPE)、决定系数R2这3 项性能指标对预测模型精度进行评价:
1.均方根误差(RMSE):均方误差(MSE)是预测值与实际值之差平方的期望值,RMSE 为均方误差(MSE)的平方根,取值越小,模型准确度越高。
2.平均绝对相对误差(MAPE):绝对误差的平均值,是平均绝对误差(MAE)的变形,它是一个百分比值。取值越小,模型准确度越高,越能反映预测值误差的实际情况。
3.决定系数R2:将预测值跟只使用均值的情况下相比,结果越靠近1 模型准确度越高。
式中:yi表示第i个预测时间段真实的工作负荷值;表示使用预测模型预测的第i个工作负荷值; 表示真实工作负荷值的平均值。
(四)模型预测结果及对比分析
为验证本文预测模型相比于其他预测模型在预测精度和预测效率上是否具有优越性,本文对比分析3 种预测模型的预测性能。
预测模型1:构建单一CART 工作负荷预测模型。
预测模型2:在模型1 的基础上,经过自适应提升算法的权重自分配与重组,构建 AdaBoost 工作负荷预测模型。
预测模型3:在模型2 的基础上,使用GRA 和“近大远小”时间原则对训练集的相似日进行选择,构建基于相似日的AdaBoost 工作负荷预测模型。
具体模型预测误差评价指标对比如表3 所示。由表3 可知,相比于 CART、AdaBoost 预测模型,本文所使用方法的误差评价指标RMSE 分别降低32.44%和10.19%,MAPE 分别降低78.13% 和66.11%, 相对系数分别提高10.10%和1.21%,基于相似日的AdaBoost 预测模型的各项预测误差指标值均最小。因此,本文所提预测模型预测效率和预测性能优于上述其他模型。
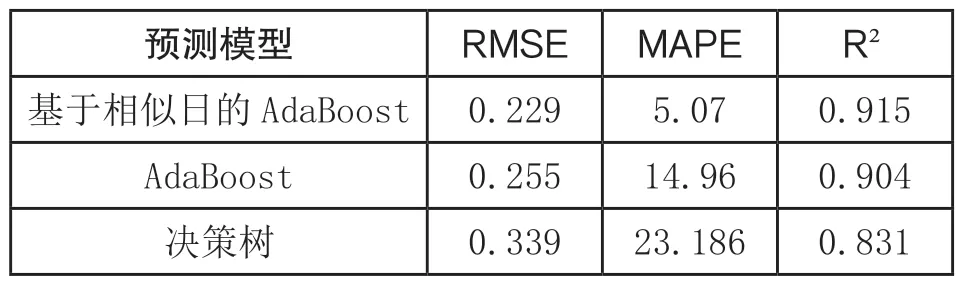
表3:预测误差指标对比
五、应用场景
预测模型在工作负荷预测以及告警上表现优异,能够在席位资源编排、动态调整工作、人力成本分析等方面提供技术与数据支持。通过准确的工作负荷预测,为情报人员设定合理的负荷阈值。当预测的工作负荷超过阈值时,系统可以发出预警,提醒管理层及时采取措施进行干预。可以评估工作任务分配合理性,根据预测的工作负荷数据,动态调整情报人员的工作任务,对席位资源合理化管理,使得工作效率最大化。
未来也可为相关工作任务与环境提供合理优化参考指标,解决如何在日益增长的信息管理需要下确保信息及时上传下达的难题,使用机器学习、运筹学等方法对信息处理策略进行优化(胡海青等,2022)10。根据预测的工作负荷和紧急程度,合理安排信息处理顺序,确保高优先级的信息能够得到及时处理,同时避免在低优先级信息上浪费过多资源。
通过准确的工作负荷预测,可以为控制情报人员的工作负荷处于合理水平提供有效的支持,能够更好地平衡情报人员的工作负荷,提高工作效率和准确性,深入贯彻“数据驱动安全”的新发展理念。
六、结语
基于对民航信息岗工作负荷研究不够深入、工作数据与评估预测模型结合较为局限的问题,本文提出基于相似日的AdaBoost 民航信息岗工作负荷预测模型,根据工作负荷预测精度与信息复杂性关联性强的特点,以预测日的信息类别与数量为研究特征,利用时间“近大远小”原则有针对性地选择相似信息收发情况下的相似日作为训练数据集,提高模型回归精度。同时将CART 决策树进行集成学习,在基于GRA 寻找的相似日训练数据集基础上,对比其他预测模型,具有较高的预测精度与预测稳定性,并成功应用于航空公司航行通告岗工作负荷的预测与评估工作中。本文所使用的研究方法为加快推动传统评估方法和创新算法深度融合,促进传统要素驱动向注重创新驱动转变,提升行业系统化、协同化、智能化提供了全新视角。
在工作过程中存在大量非结构化动态的工作负荷数据,如何在海量数据中获得一种更为高效、准确、适用性强的工作负荷评价与预测的指标体系和方法,是未来继续研究的方向。
此外,在处理特征相关性强的数据时,决策树的回归结果表现一般,对于类别样本数不一致的数据,信息增益的结果将倾向于具有更多数字特征的数据。如何优化模型的泛化能力也是未来研究的重点。(作者单位:中国南方航空股份有限公司)
猜你喜欢
中老年保健(2021年12期)2021-08-24 03:30:28
疯狂英语·新读写(2021年6期)2021-08-05 07:49:10
中学生英语(2017年6期)2017-07-31 21:28:55
青年歌声(2017年6期)2017-03-13 00:57:56
东北电力技术(2016年2期)2016-05-17 04:32:46
中国化肥信息(2016年35期)2016-05-17 04:25:50
核科学与工程(2015年2期)2015-09-26 11:56:59
云南师范大学学报(哲学社会科学版)(2015年5期)2015-02-28 21:25:07
云南师范大学学报(哲学社会科学版)(2015年2期)2015-02-28 21:24:49
电测与仪表(2014年14期)2014-04-04 11:53:40
