
基于类对比簇分配异构迁移学习的空间滚动轴承寿命阶段识别
2024-02-02 09:29:14刘峰良汤宝平汪永超田大庆
工程科学与技术 2024年1期
刘峰良,李 锋*,汤宝平,汪永超,田大庆
(1.四川大学机械工程学院,四川成都 610065;2.重庆大学机械传动国家重点实验室,重庆 400044)
空间飞行器的机械部件能否正常运转、实现预定功能和达到预期服役寿命,很大程度上取决于飞行器中各机械部件内滚动轴承的寿命和可靠性。由于实时监测空间飞行器在轨运行状态下的轴承寿命状态成本昂贵且很难做到及时更换或维修故障轴承[1],为了保证安装到空间飞行器的滚动轴承能满足任务需求,目前国内外研究机构(如中国国家航天局、美国国家宇航局、俄罗斯联邦航天局等)通常采用地面模拟空间环境开展空间滚动轴承加速寿命试验来识别空间滚动轴承的寿命阶段,进而从大量候选空间滚动轴承中筛选出最优寿命轴承(即被识别为正常阶段的轴承)安装到空间飞行器中。
在(地面模拟)空间在轨环境下,空间滚动轴承的失效一般是由固体润滑膜的磨损造成的精度失效,相比于早期故障或典型破坏性故障状态,空间滚动轴承在精度失效状态及其之前的有效寿命阶段内的振动特征更为微弱。一方面,模拟空间环境的设备(如:真空泵)内部空间狭小,且在该狭小空间内存在多组轴承同时试验,导致空间轴承振动信号受到强烈的环境噪声、电机变频振动、电磁辐射等干扰,这些干扰成分与空间轴承真实振动信号的低频段分量混叠、耦合[1–2]。另一方面,空间滚动轴承一般工作在变工况条件下:模拟空间环境下滚动轴承往往采取径向无加载、轴向加载方式开展加速寿命试验,随着轴承磨损,轴承间隙改变,空间轴承所受轴向载荷将发生持续性的变化;此外,由于真空室容量限制,难以实施电机转速的闭环控制[1–4],故空间轴承的转速并不稳定。地面模拟空间环境下空间滚动轴承加速寿命试验的特殊性使空间滚动轴承的运行、退化和失效过程与地面常规环境下的传统滚动轴承有明显差异,导致地面模拟空间环境下空间滚动轴承寿命阶段识别具有较大的挑战性。
地面模拟空间环境下空间滚动轴承寿命阶段识别的研究起步较晚,相关研究案例还较少。吴昊年等[3]采用无重复均匀随机抽样和多分类器来改进均衡分布适配,再用改进后的均衡分布适配对空间滚动轴承进行寿命阶段识别。董绍江等[4]采用多层降噪技术、经验模态分解方法以及卷积神经网络(ICNN)对空间滚动轴承进行故障诊断。Dong等[5]利用沙利斯熵(TEK)得到积函数信号熵特征,将提取的信号熵特征经主成分分析后输入到优化模糊c均值模型(OFCM)中进行空间滚动轴承寿命阶段识别。陈仁祥等[6]结合线性局部切空间排列(LLTSA)维数约简和最近邻分类器对地面模拟空间环境下的空间滚动轴承进行寿命阶段识别。然而,模拟空间环境下的空间滚动轴承寿命阶段识别是在变工况条件[2]下展开的,以上基于数据概率分布一致性假设的机器学习方法并不能很好地适应变工况环境。此外,以上机器学习方法需要大量带类标签的历史工况(源域)数据进行训练,而且要求各寿命阶段训练数据占比均等。但受试验周期和成本影响,地面模拟空间环境下的加速寿命试验仅能获得部分历史工况下的少量空间滚动轴承全寿命样本用于分类模型的训练,且空间轴承不同寿命状态的时间跨度的不均等以及截尾试验往往造成各个寿命状态的样本数量不均等(截尾试验容易造成精度失效前的正常状态样本居多,而精度失效后的样本数量较少)[7–9]。复杂的地面模拟空间环境试验条件暴露了以上机器学习方法用于空间滚动轴承寿命阶段识别的局限性。
迁移学习(TL)[10–12]在样本概率分布不一致条件下具有良好的域泛化性能,因此为变工况条件下的空间滚动轴承寿命阶段识别提供了全新解决思路。对比学习(CL)[13–16]是一种自监督学习范式,它通过比较数据对之间的“相似”或者“不同”以获取数据的高阶信息来对无标签数据集进行自监督学习,且其在定义正负样本方面的灵活性使得其在少样本情况下可以对两域样本进行灵活再分配,因此用于解决少样本分类问题具有潜力。因此,本文结合迁移学习和对比学习的优势,提出一种无监督迁移学习方法——类对比簇分配异构迁移学习(CAHTL)用于空间滚动轴承寿命阶段识别。CAHTL可以在源域有类标签样本较少以及不同类别样本数量不均等的情况下对目标域(即空间滚动轴承当前工况)的待测样本进行较高精度的寿命阶段识别。
1 CAHTL理论模型
CAHTL的网络结构框架如图1所示,主要由异构迁移学习网络、同域泛对比学习网络以及簇分类网络构成。
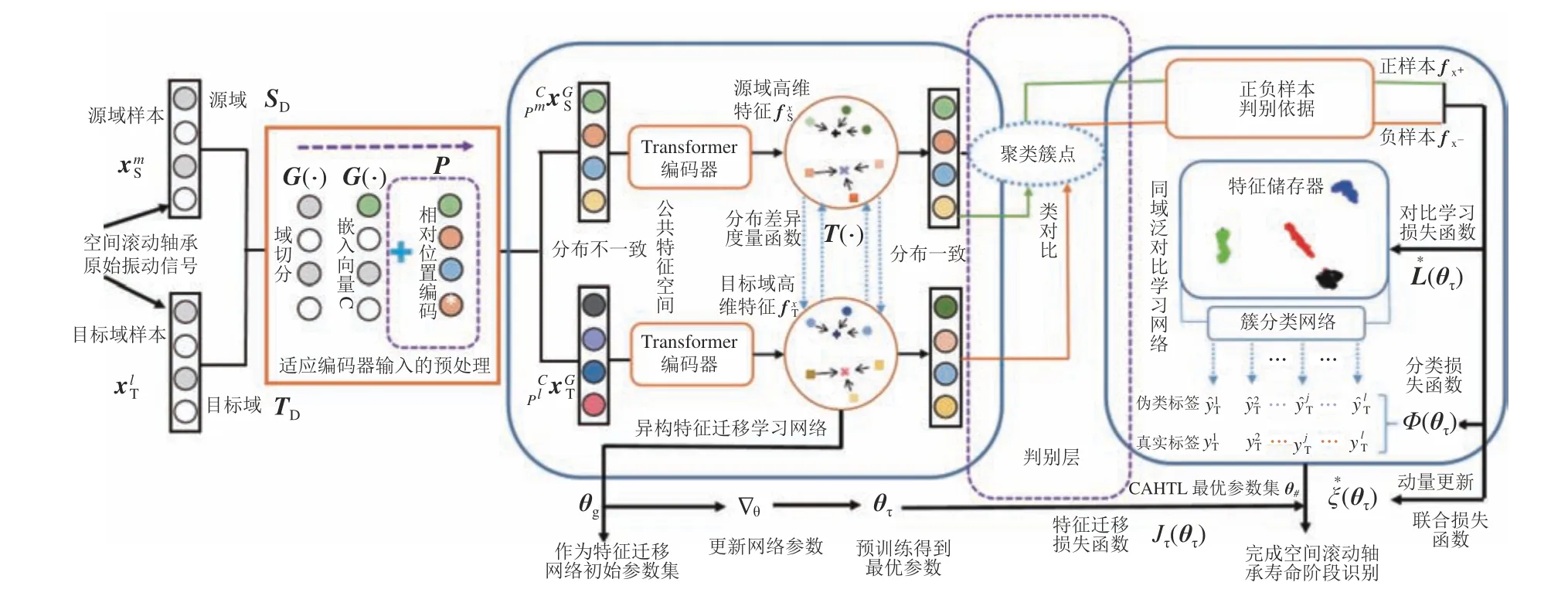
图1 CAHTL的网络结构框架Fig. 1 Structure frame diagram of CAHTL
首先,对空间滚动轴承原始振动加速度信号样本做适应Transformer编码器输入形式的编码预处理,并构建异构迁移学习网络将源域和目标域编码后特征映射到一个公共特征空间,达到将不同分布的样本在公共特征空间内同分布的目的,同时构造特征迁移损失函数对异构迁移学习网络进行预训练来寻找该网络最优参数集,以加速CAHTL的收敛;其次,利用聚类簇点构建正负样本实现公共空间中两域样本特征的数量再分配,再对两域正负样本进行对比学习来解决少样本类判别问题;随后,计算待测样本与聚类簇点的相似度来预测待测样本的伪类标签并构造分类损失函数,以防止样本不均等情况下不同寿命阶段样本识别准确率差距过大和在少有类标签训练样本情况下网络出现过拟合的问题;然后,结合随机梯度下降法和动量更新对待训练的CAHTL模型参数进行不同步训练和更新;最后,将目标域待测样本输入训练好的CAHTL网络完成对待测样本寿命阶段的划分。
1.1 异构特征迁移


式(8)采用最大均值差异度量函数作为分布差异度量函数T(·)。然后,通过优化该特征迁移损失函数来学习异构迁移学习网络的参数,以实现源域样本高维特征向目标域样本高维特征的迁移(也就是将源域和目标域高维特征迁移到同一个公共特征空间内),使得它们之间的概率分布差异最小化。优化特征迁移损失函数的过程就是用随机梯度下降法对异构迁移学习网络的参数 θg进行更新的过程,对 θg进行一次更新的表达式如下:
式中, α为异构迁移学习网络参数的学习率。
重复执行式(7)~(9)所示更新过程,直到将异构迁移学习网络的参数训练至收敛,就完成了对特征迁移损失函数的优化,也即完成了对异构迁移学习网络的预训练。由于后续的同域泛对比学习网络每一次更新前的初始参数都是由训练异构迁移学习网络得到的全局最优解,所以以最后更新好的全局最优解(即预训练好的异构迁移学习网络参数集 θτ)作为同域泛对比学习网络的起始点(即初始值)去学习该对比学习网络的参数时仅需要较少迭代次数就能使同域泛对比学习网络达到收敛,即又好又快地适应新的对比学习任务,因此预训练好的异构迁移学习网络具有良好的泛化性和域适配性。
1.2 同域泛对比学习

由于模拟空间环境下空间滚动轴承两域样本中都存在强烈的复杂信号干扰,使得空间轴承两域不同类别(不同寿命阶段)样本在公共特征空间内间隔很小甚至出现交汇、混叠现象,将导致分类(寿命阶段识别)精度不高;同时由于源域可用样本数量有限导致网络被训练时容易出现过拟合问题,因此采用聚类簇点和构造同域泛对比学习对公共特征空间内的两域样本高维特征进行数量再分配和类判别。
将异构迁移学习网络输出的源域高维特征fS(θτ)聚类成K类,得到K个蕴含类别信息的聚类中心(即聚类簇点),该过程表达如下:
式中,Cn(·)表示k–means聚类算法。
用得到的聚类中心Cn j来对目标域样本特征进行正、负样本判别。对于每一个目标域待判别样本特征来说,正样本f x+为该待判别样本特征与聚类中心一一比较之后相似度最大的聚类中心,即:
式中:δ(·)表示相似度度量函数,其中δ(·)∈[-1,1],采用余弦相似度函数作为相似度度量函数δ(·);而负样本f x-则是除去正样本外的所有其它源域和目标域样本特征。通过以上正负样本判别层使得目标域不同类别的样本特征都有了与自己对应的唯一正样本f x+和 λ (λ ≤M+L-2)个负样本,从而使目标域不同类别样本特征的数量趋向于均衡化,这样较好地解决了两域样本数量再分配问题。
得到正、负样本之后,构造如下同域泛对比学习损失函数L*(θτ):
式中,t为温度超参数,用来控制样本分布的形状。通过优化该同域泛对比学习损失函数,可以让相似的正样本对的距离越来越近,而让不相似的负样本相距越来越远,这样有利于对目标域各类别样本特征进行分类。
1.3 簇分类
计算目标域待测样本的高维特征与不同聚类簇点Cn j(j∈1,2,···,K)的相似度,并选择相似度最大的聚类簇点所对应的类标签作为空间滚动轴承目标域待测样本的预测伪类标签kl(kl代表目标域第l个样本对应的伪类标签),该过程表达如下:
计算该目标域待测样本属于伪类标签kl的概率如下:
将所有目标域待测样本属于其对应的伪类标签概率的负对数之和作为分类损失函数,该分类损失函数推导如下:
然后,结合异构迁移学习网络的特征迁移损失函数J(θτ)、同域泛对比学习损失函数L*(θτ)以及分类损失函数Φ(θτ) 作为CAHTL的联合损失函数ζ*(θτ),该联合损失函数表达如下:
式中, ρ 、 ψ为联合损失函数的平衡约束参数,分别用于约束异构迁移学习网络和同域泛对比学习网络的局部寻优行为。
1.4 CAHTL参数的动量更新
需要对联合损失函数ζ*(θτ)进行优化并且在不同批次训练过程对CAHTL更新网络参数。由于基于传统随机梯度下降的参数更新方式更新速度慢而且聚类中心Cn j会随着训练批次的不同发生不同程度的改变,而一个快速改变的聚类中心又会降低正负样本储存器里所有正、负样本的一致性(这里的一致性是指每个样本特征的正、负样本在判别后保持不变),使得CAHTL难以收敛。因此,本文以动量更新的方式来解决在不同批次训练过程中聚类中心变化过大导致CAHTL难以收敛的问题。待一次随机梯度计算完成之后,将返回结果进行梯度累加并计算本次训练后的参数集均值,此时并不立即更新参数集,而是将该均值作为下一次训练的基础参数集进行动量更新。该参数集动量更新过程如下:
首先,由随机梯度下降法得到第 γ次训练后的CAHTL参数集 θγ,再进行梯度累加并计算该次训练后的CAHTL参数集均值 θγ,即:
式中, α′为CAHTL参数的学习率。
接着,将上一次训练更新得到的参数集均值θγ-1和当前次(即第 γ次)更新得到的参数集均值 θγ相结合来动量更新当前次的网络参数集均值如下:
式中,η ∈[0,1)为动量参数, η的值越大,参数更新越缓慢。由式(20)可知,在每一次迭代训练过程中,会在很大程度上沿用上一次训练所产生的参数集进行参数集更新,同时会一定程度上应用当前批次训练产生的参数集进行更新,这使得聚类簇点不会产生大的突变,同时又能保证CAHTL能收敛。
较少次地重复执行式(19)~(20)就能使CAHTL收敛,完成对CAHTL的参数微调,此时得到CAHTL对该分类任务的最优参数集 θ#,也即完成对CAHTL的训练。
最后,再将空间滚动轴承目标域待测样本输入训练好的CAHTL,以计算出目标域待测样本的类标签(即寿命阶段),即:
这样就完成了利用空间滚动轴承原始振动加速度信号进行空间滚动轴承寿命阶段识别的全过程。由于式(15)~(18)所呈现的簇分类(即分类损失函数构造)过程以及式(20)所表达的对空间滚动轴承目标域待测样本的最终分类过程都未引入新的需要训练的参数,因此对待测样本分类的全过程都无需参数学习。
2 基于CAHTL的空间滚动轴承寿命阶段识别
所提出的基于CAHTL的空间滚动轴承寿命阶段识别方法的实现过程如图2所示,方法如下:
1)对空间滚动轴承源域和目标域原始振动信号样本做适应Transformer编码器输入形式的编码预处理;再将源域和目标域编码后的样本输入T ransformer编码器得到相应的两域高维特征,通过特征分布差异度量函数对两域高维特征构造特征迁移损失函数;通过优化该损失函数即预训练异构迁移学习网络以达到将不同分布的样本在公共特征空间内最大化同分布的目的,并得到异构迁移学习网络的最优参数集。
2)将源域少量有类标签的样本以及目标域无类标签的样本输入预训练好的异构迁移学习网络来构造异构迁移学习网络的特征迁移损失函数。
3)对异构迁移学习网络输出的源域样本高维特征聚类得到包含不同类别信息的聚类簇点,以这些聚类簇点为祖点为目标域待判别样本特征(即目标域待测样本的高维特征)进行正负样本判别,使每个目标域样本特征都得到一个与自己对应的唯一正样本和 λ个负样本,并将该判别结果存储在特征存储器中。得到正、负样本之后,构造同域泛对比学习损失函数,使得在公共特征空间内相似的正样本对相距越来越近,负样本与不同类的样本特征相距更远,以利于对目标域样本特征进行分类。
4)计算空间滚动轴承目标域待测样本的高维特征与不同聚类簇点的相似度,并选择相似度最大的聚类簇点所对应的类标签作为待测样本的预测伪类标签,同时依据预测伪类标签来构造分类损失函数。
5)结合异构迁移学习网络的特征迁移损失函数、同域泛对比学习损失函数以及分类损失函数来构造CAHTL的联合损失函数,采用随机梯度下降和动量不同步更新方式将联合损失函数训练至收敛,以完成对CAHTL参数的微调,即得到CAHTL的最优参数集。
6)将训练好的CAHTL用于对目标域待测样本的分类,完成对空间滚动轴承的寿命阶段识别。
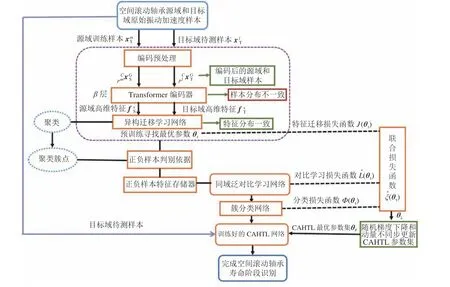
图2 CAHTL用于空间滚动轴承寿命阶段识别方法Fig. 2 Process of using CAHTL to identify the life stage of space rolling bearings
3 实例分析
3.1 实验平台
实验数据主要来自重庆大学机械传动国家重点实验室搭建的地面模拟真空环境下空间滚动轴承振动监测(即加速寿命试验)平台上采集的空间滚动轴承加速寿命试验数据。平台主要由真空泵(可以实现温度范围–50℃~–150℃和压强范围105Pa(大气)~10–5Pa(高真空)的模拟空间环境)、轴承振动监测实验台架、压电式加速度传感器LANCE LC0151T、LANCE双积分信号调理器、NI数据采集卡NI9234和计算机组成,如图3所示。实验工况见表1。空间滚动轴承振动信号监测、采集方案的实现路径如下:将型号均为C36018的空间滚动轴承1和2安装于真空泵中的振动监测实验台架上。真空泵正常运行后,在真空环境下轴承1和2均被加载7 kg的轴向预载(随着轴承磨损加剧,轴向载荷会发生持续性变化),分别在约1 000和约3 000 r/m in的2种非平稳转速(转速不稳定是由电机非闭环控制引起)下运行(表1中的非稳态工况C1和C2),以模拟空间滚动轴承的空间服役状态并激励出空间轴承的振动响应信号。采用压电式加速度传感器、双积分信号调理器、NI数据采集卡和计算机中配套的数据采集软件对这两个空间滚动轴承进行振动监测,每隔2 h以25.6 kHz的采样频率采集一次振动加速度信号,直至这两个轴承都完全止动失效。截取每1 024个连续的振动加速度数据作为一个样本,最终采集到这两个空间滚动轴承全寿命期的总样本数均为744。

图3 空间滚动轴承振动监测平台Fig. 3 Vibration monitoring platform for space rolling bearings
表1中,工况C3的数据来自辛辛那提大学滚动轴承加速寿命退化实验台,该平台如图4所示。将4个型号为ZA–2115双列滚子轴承安装在轴承试验台的旋转轴上,使用转速为2 000 r/m in的电机通过皮带驱动转轴,并通过弹簧机构在转轴和轴承上施加6 000 lbs(约为2 721.5 kg)的径向载荷,采样频率为20 kHz,每10m in采集一次轴承的振动加速度。对每次采集的数据截取前1 024个连续点作为一个样本,共获得1号双列滚子轴承全寿命期的984个样本。
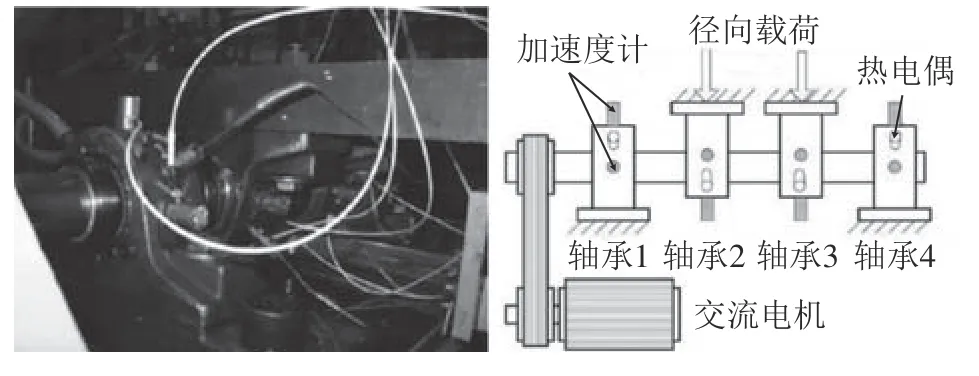
图4 辛辛那提大学滚动轴承加速寿命退化实验台Fig. 4 Accelerated rolling bearing life cycle degradation test platform in University of Cincinnati
在寿命阶段识别实验开始前对3个工况下的3个(空间)滚动轴承全寿命数据进行寿命阶段划分。首先对这3个轴承的每个样本提取来自时域、频域和时频域的27个寿命阶段特征,然后用局部线性嵌入(LLE)方法[20]对所提取的寿命阶段特征进行维数约简,得到对应于每个样本的1维主特征量,再将所得1维主特征量输入3参数威布尔分布可靠度模型[21]以获得这3个轴承的可靠度评估曲线,如图5所示,相邻两时间间隔分别为2 h、2 h、10m in。由可靠度评估曲线将全寿命数据划分成正常状态、早期退化阶段、中期退化阶段、完全失效阶段等4个阶段:从空间滚动轴承运行安全性、稳妥性考虑,将可靠度0.9第1次出现对应的时间点作为划分正常阶段和早期退化阶段的时间点,该点也被视为空间滚动轴承精度失效阈值点[7];将可靠度0.5第1次出现对应的时间点作为划分早期退化阶段和中期退化阶段的分界点[22];将可靠度0.1第1次出现对应的时间点作为划分中期退化阶段和完全失效阶段的分界点[22]。
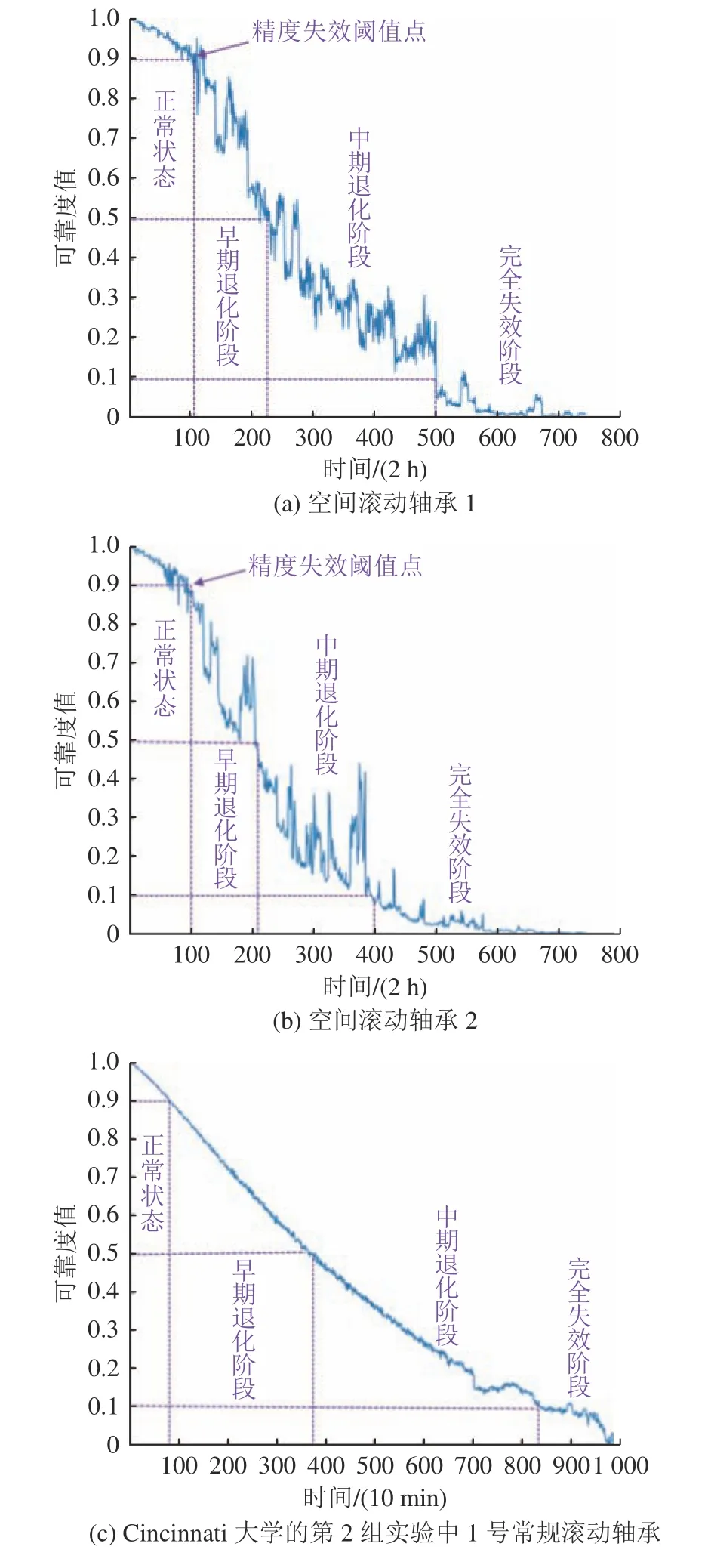
图5 不同滚动轴承可靠度曲线Fig. 5 Reliability curves of different rolling bearings
3.2 CAHTL的参数设置
CAHTL的参数设置如下:小区域长度d=32,小区域切分个数R=32;Transform er编码器的个数α=4×e-2,编码器内多头自注意力头数为4头,每个头的输入向量维度为32维;异构迁移学习网络参数的学习率α=4×e-2;同域泛对比学习网络中的聚类簇点个数K=4,温度超参数t=0.05;联合损失函数的平衡约束参数 ρ 、 ψ一 般在各自的经验区间 ρ ∈(0,1)、ψ ∈(0,1)内取值,这里取 ρ=0.3 、ψ=0.6;CAHTL参数的学习率α′=4×e-2;由于公共特征空间中的源域和目标域高维特征都是由相同的网络结构(Transformer编码器)编码得到,因此两域样本特征一致性较强,故采用一个相对较大的动量参数,即η=0.92,这样聚类簇点不会产生大的突变,同时CAHTL又能收敛。后续实验均沿用以上参数,不再做任何改变。
3.3 实验1(C2 →C1)和分析对比
在实验1(C2 →C1)中,将工况C2下的空间滚动轴承2的正常状态阶段(S1)、早期退化阶段(S2)、中期退化阶段(S3)以及完全失效阶段(S4)的全寿命周期样本作为源域样本来识别工况C1(目标域)下的空间轴承1的全寿命样本的寿命阶段。实验开始前,分别从空间轴承2和空间轴承1的每一寿命阶段中各随机选取100个样本作为源域和目标域的总样本,即用于实验的源域和目标域总样本数均为400。
在源域中按照1∶3∶4∶1的比例选取各阶段样本用作源域有类标签训练样本:S1、S2、S3和S4阶段样本数分别为Q/9 、3Q/9 、4Q/9和Q/9,所有训练样本总数为Q(Q≤225);在目标域中也按相同方法选取样本,待测样本总数也为Q。按照第2节所述的实现流程,将源域和目标域样本输入CAHTL,对目标域空间滚动轴承1进行寿命阶段识别。实验结束后,将CAHTL获得的识别准确率与其他4种典型迁移学习方法进行比较,包括中心力矩匹配(CMD)[23]、域迁移多核学习(DTMKL)[24]、迁移联合匹配(TJM)[25]和分发匹配嵌入(DME)[26]。使用k折交叉验证方法来优化CMD、DTMKL、TJM和DME的参数以确保能够获得最高的识别精度。优化后的参数如下:对于CMD,学习速率为η=e-2,平衡约束参数为0.30;对于DTMKL,正则化参数为0.30,子空间维数D=3;对于TJM,正则化参数为0.25,子空间维数D=4;对于DME,惩罚因子为0.25。
为降低随机性带来的误差,取前30次实验结果的平均值作为每种方法最后的实验结果。不同方法的寿命阶段平均识别准确率对比如图6所示。当源域有类标签训练样本总数Q=27时,CAHTL和其它4种方法的识别准确率对比如图7所示,不同方法对目标域待测样本详细寿命阶段识别结果见表2。此外,利用t分布随机邻域嵌入(t–SNE)算法[27]将Q=27时异构迁移学习前后CAHTL输出的高维特征降维到2维平面,以展示异构迁移学习前后CAHTL的两域最大化同分布效果和分类效果,结果如图8所示。

图6 空间滚动轴承1的4个寿命阶段的平均识别准确率Fig. 6 Comparison of the average identification accuracy of four life stages of space rolling bearing 1
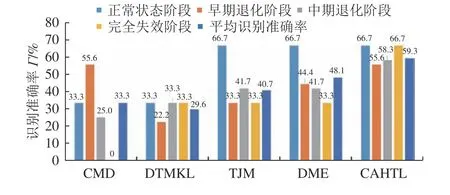
图7 Q=27时寿命阶段识别准确率Fig. 7 Life stage identification accuracy of space rolling bearing 1 when Q=27
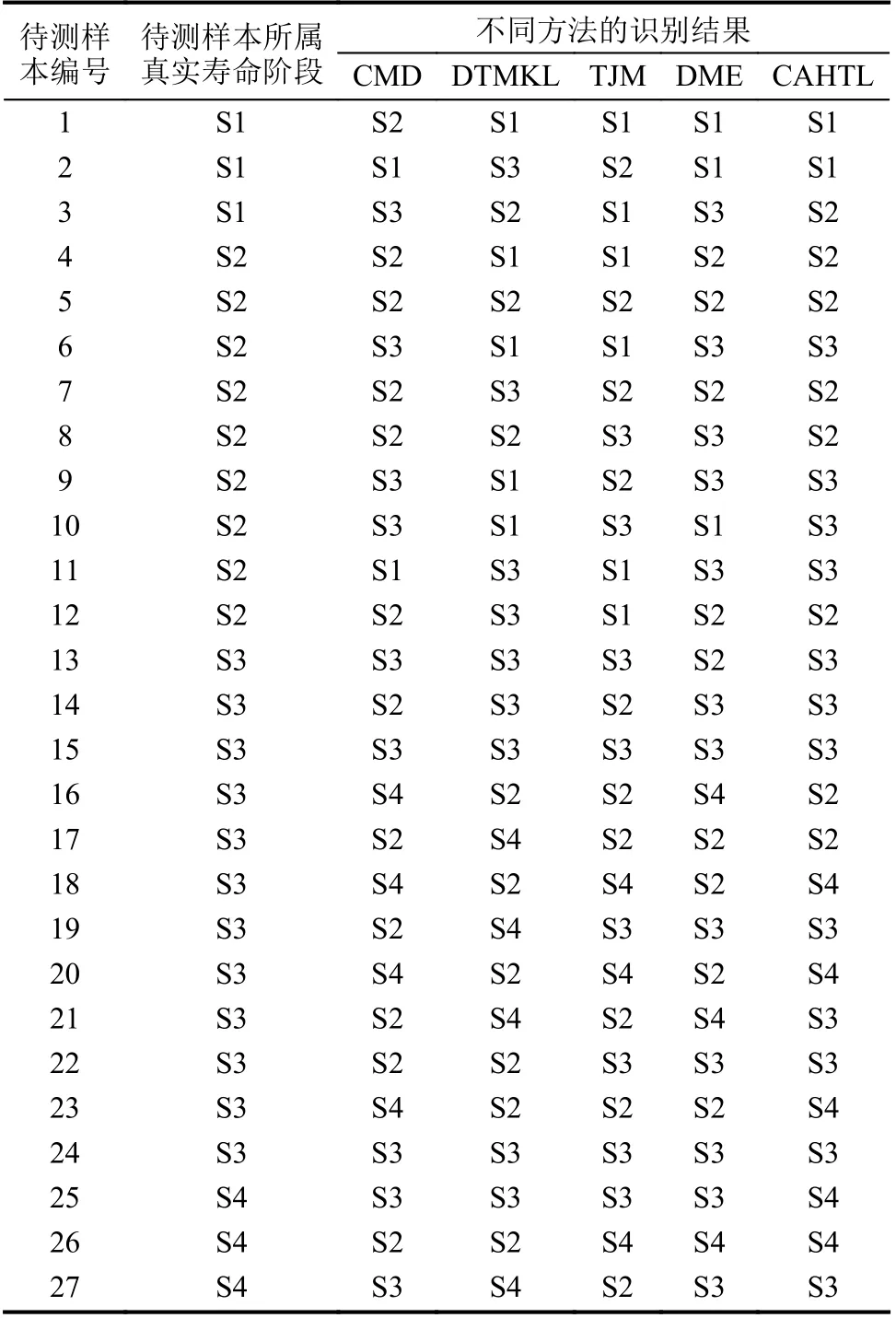
表2 不同方法对目标域待测样本的寿命阶段识别结果Tab.2 Lifetime stages identified by different methods for target domain test samples
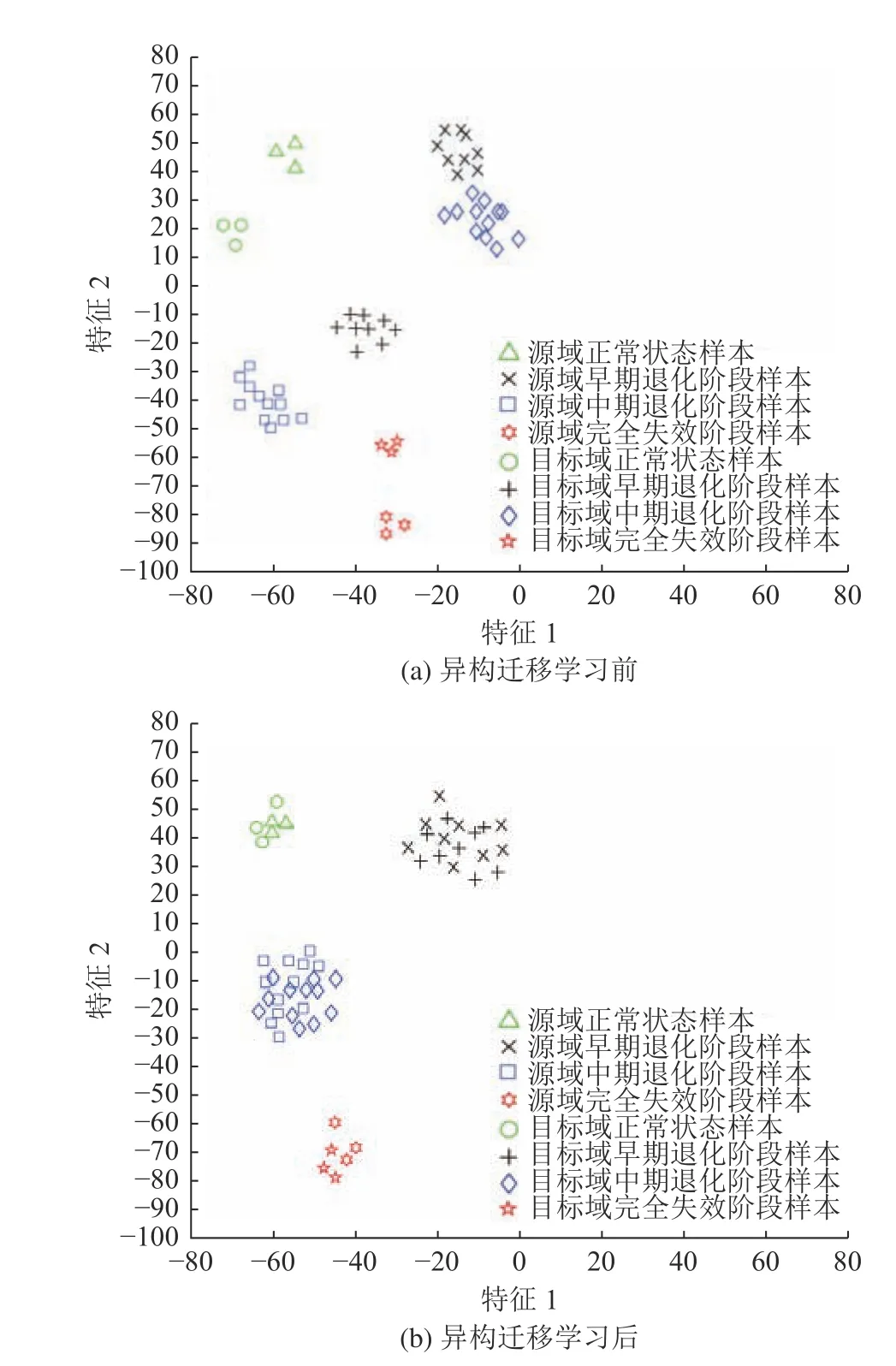
图8 异构迁移学习前后t–SNE的2维散点图Fig.8 2D scatter plots of t–SNE before and after heterogeneous transfer learning
由图6~7及表2的对比结果可知,随着非均等的源域有类标签训练样本数量的减少,CAHTL和其它4种迁移学习方法的识别准确率和平均识别准确率总体上都有不同程度的下降,主要是由于对空间轴承1的4个寿命阶段待测样本训练都不均衡、不充分。但CAHTL的寿命阶段识别准确率和平均识别准确率的下降幅度相比其它4种方法而言是最小的;且CAHTL对4个寿命阶段的识别准确率和平均识别准确率始终比其它4种方法要高,避免了对不同寿命阶段的待测样本识别准确率差距过大(即对少样本寿命阶段的待测样本的识别准确率过低)问题。此外,由图8(a)和8(b)的对比结果可知,CAHTL中的异构迁移学习网络不仅能使源域和目标域中样本在分布上更趋近一致,还能使两域中相同类别的样本更好地聚合在一起,同时又能使两域中不同类别的样本相对更为分散,因此CAHTL的确能够减小源域和目标域样本的分布差异性并提高对目标域待测样本的分类(即寿命阶段识别)精度。
3.4 实验2(C3 →C1)和分析对比
在实验2(C3 →C1)中,将工况C3下的1号滚动轴承的全寿命样本作为源域样本来识别工况C1下的空间轴承1的全寿命样本(目标域样本)的寿命阶段。实验前,分别对工况C3下的1号滚动轴承和工况C1下的空间轴承1的每一寿命阶段各随机取80个样本作为用于实验的源域和目标域各寿命阶段的总样本,即用于实验的源域和目标域总样本数均为320。
在源域中按照4∶1∶2∶3的比例选取各阶段样本用作有类标签训练样本:正常状态、早期退化、中期退化、完全失效阶段样本数分别为 2Q/5、Q/10、Q/5和3Q/10 ,即源域所有训练样本的总数为Q(Q≤200);在目标域中对正常状态、早期退化、中期退化和完全失效这4个寿命阶段按照3∶4∶1∶2的比例进行随机取样作为目标域待测样本,待测样本总数也为Q。将CAHTL对目标域待测样本的寿命阶段识别准确率和平均识别准确率与其他4种迁移学习方法进行比较,对比结果如图9所示;当源域有类标签训练样本总数Q=30时,CAHTL和其它4种被比较方法的寿命阶段识别准确率和平均识别准确率如图10所示。
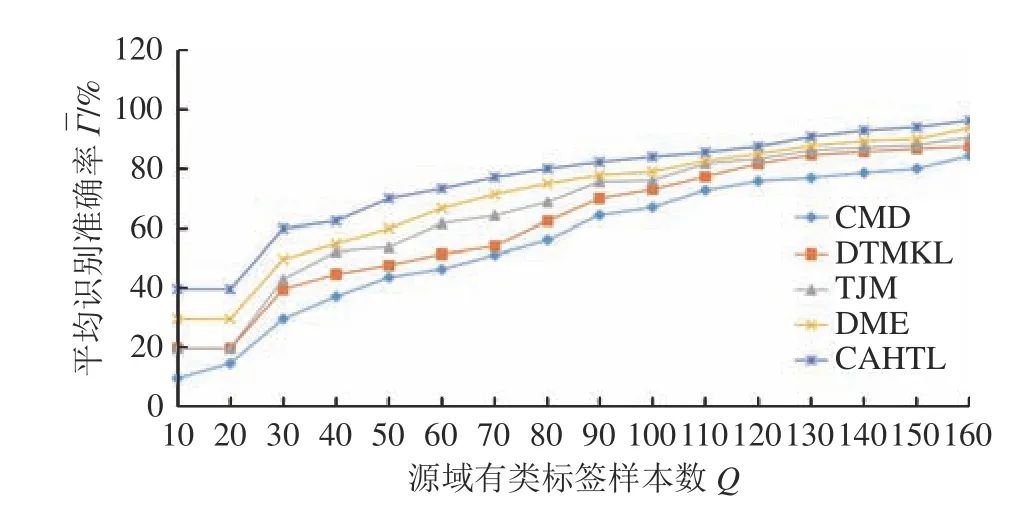
图9 空间滚动轴承1的4个寿命阶段的平均识别准确率Fig.9 Comparison of the average identification accuracy of four life stages of space rolling bearing 1
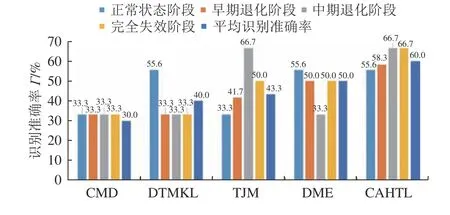
图10 Q=30时寿命阶段识别准确率Fig.10 Life stage identification accuracy of space rolling bearing 1 when Q=30
由图9~10的对比结果可知,随着非均等的源域有类标签训练样本数量的减少,虽然CAHTL和其它4种迁移学习方法对空间轴承1的4个寿命阶段的待测样本的寿命阶段识别准确率和平均识别准确率总体上都有不同程度的下降,但是CAHTL的寿命阶段识别准确率和平均识别准确率的下降幅度相比其它4种方法仍然是最小的;且CAHTL对4个寿命阶段的识别准确率和平均识别准确率始终比其它4种方法要高。
4 结 论
1)本文所提出的CAHTL中的异构迁移学习网络能够将历史工况下的少量有类标签样本和当前工况下的待测样本迁移到公共特征空间内,实现将不同分布的样本在公共特征空间内同分布的目的。
2)由源域聚类簇点构建的目标域样本特征的正负样本可实现两域样本的数量再分配,对两域正负样本进行对比学习可以使待测样本具有更好分类性。
3)CAHTL通过簇分类网络计算待测样本与聚类簇点的相似度完成待测样本分类,且该分类过程无需参数学习,因此可防止源域有类标签训练样本不均等情况下对于不同寿命阶段待测样本识别准确率差距过大和在少有类标签训练样本情况下网络出现过拟合的问题。
4)利用随机梯度下降和动量更新对CAHTL参数进行不同步更新可保持样本特征的一致性并提高CAHTL的收敛速度。
CAHTL的以上优势使得它可利用(空间)滚动轴承历史工况下的少量、非均等的已知寿命阶段的训练样本对空间滚动轴承当前工况下的待测样本进行较高精度的寿命阶段识别。
猜你喜欢
计算机技术与发展(2024年3期)2024-03-25 02:10:02
小学教学研究(2022年5期)2022-04-28 21:29:36
中老年保健(2021年8期)2021-12-02 23:55:49
计算机技术与发展(2020年11期)2020-12-04 07:50:46
作文评点报·低幼版(2020年3期)2020-02-12 09:08:22
华人时刊(2018年17期)2018-12-07 01:02:20
奥秘(2017年12期)2017-07-04 11:37:14
电信科学(2016年11期)2016-11-23 05:07:56
通信电源技术(2016年6期)2016-04-20 06:21:36
电子与信息学报(2015年12期)2015-08-17 11:14:42
