
基于威布尔分布的风功率密度计算方法比较
2024-01-31 03:46李化
南方能源建设 2024年1期
李化
(润阳能源技术有限公司,天津 300300)
0 引言
风资源评估是风电开发的重要环节[1],风功率密度又是风能资源评估的重要参数之一[2],是决定风电场是否具有开发潜能的重要评判标准。在年平均风速和空气密度相同的情况下,不同的风频分布将计算得出不同的风功率密度,因而准确分析风资源的风频分布具有重要意义。
目前,对风频分布的研究多采用威布尔分布,它能比较好地拟合风资源的实际情况。刘鹏等[3]采用了矩估计法模拟风频威布尔分布,此方法简单方便,缺点是不能完全利用风数据样本信息,模拟精度不高。Justus 和Lysen 提出的经验计算方法[4],被2002版《全国风能评价技术规定》采纳,因简单、实用、耗时短,在风电场建设初期做初步评估时被广泛采用。Akdag 和Dinler 提出了用能量因子法来模拟威布尔分布参数[5],此方法目前被广泛应用于风资源流体力学评估模型软件中,如Meteodyn Universe。Stevens MJM 将最大似然法运用于风资源风频分布的模拟计算,并以此估算风电场发电量[6]。最小二乘法由法国勒让德创立,是处理实测值的纯粹代数方法,此方法被广泛应用于各行业,这是一种寻找最佳解,揭示最接近真实情形的状态[7]。
估算风功率密度的方法较多,准确地计算风功率密度有赖于风频威布尔分布拟合的准确性[8]。但是,目前还缺少基于威布尔分布拟合准确性计算风功率密度方面的研究。因此,文章对目前国际常用的5 种风频威布尔拟合方法进行对比研究,采用决定系数对威布尔拟合结果准确度进行评价,并在此基础上利用威布尔分布计算风功率密度,并与实测风数据计算所得风功率密度相比较绝对误差和相对误差,从而确定哪些方法更可靠,更准确。文章选取我国不同经纬度和地形地貌的4 座测风塔实测数据进行威布尔分布拟合和决定系数分析,并计算相应的风功率密度,用案例进行对比验证得出较优方法,可为工程师在实际的风资源评估工作中提供参考和指导。
1 威布尔分布和风功率密度
威布尔分布是由瑞典科学家威布尔从材料强度的统计理论中推导出来的,是日常生活中一种常用的分布,在风电领域的风频分布中也被广泛采纳应用。
威布尔的形状参数 k值反映了风速分布的范围宽窄,一般情况下,k值越小,风速分布越宽。当0 式中: F(v)——威布尔风频累计概率密度(%); v ——风速(m/s); c ——威布尔尺度参数(m/s); k ——为威布尔形状参数。 对威布尔累计概率密度函数(1)求导数,得到威布尔风频分布概率密度函数,如式(2)所示: 式中: f(v)——威布尔风频分布概率密度(%)。 风功率密度是指空气流垂直通过单位截面积的风能,是表征1 个地方风能资源多少的1 个指标,在风资源评估中一般指年均风功率密度,某地的风功率密度越大,说明该地区风能资源越好[9]。风功率密度计算方法有两种,一种是基于时间序列实测风数据[10],风功率密度与风速的3 次方成正比,其计算公式如式(3)所示: 式中: ρ——空气密度(kg/m3); vi——风速时间序列值(m/s); n——时间序列。 另一种是选择合适风速分布的数学模型来模拟风速变化,常见的有双参数威布尔分布、瑞利分布、伽马分布、对数正态分布,大多学者认为双参数威布尔分布可以较好的模拟风速变化[11-13]。基于威布尔分布的风功率密度计算公式如式(4)所示: 该经验方法由Justus 提出[5],我国颁布的《全国风能评价技术规定》中也采用此种方法,此方法计算简单。其 k 值和 c值计算公式如式(5)和(6)[14]所示: 式中: σ ——风速标准差(m/s);Γ(1+1/k)——伽马函数; 此方法由Lysen 提出[15],在Justus 提出的方法上有所改进,其 k 值计算由式(5)给出,c值计算公式如式(7)所示: 基于能量守恒规律,使其威布尔拟合计算得到的风功率密度与实测数据计算所得的风功率密度差值尽可能小的情况下求 k 和 c值。此方法首先求出能量因子 Epf,其计算公式如式(8)所示,再计算 k 值[16],k值计算公式如式(9)所示,c值计算公式同式(7): 式中: Epf——风功率密度能量因子(W/m2)。 1821 年由德国数学家高斯提出最大似然法,此方法首次用于计算发电量可以追溯到Stevens MJM[6],用这种模型来估算风频分布参数 k 和 c值,其中蕴含的规则是:在求得的 k 和 c这个特定的威布尔分布函数中,能得到现在的实测风数据序列样本概率最大。 假设某一风速时间序列样本为: 威布尔概率密度似然函数 f 在某一风速 vi下的公式如式(10)所示: 则风速时间序列样本 V 产生的联合密度函数为: 为了计算方便,等式两边取对数: 上述方程分别对k,c求导,并令其分别为0,见式(13)和式(15),即可求得威布尔分布的参数 k 和c[17],具体见式(14)和式(16): 风速时间序列某一风速的累计概率密度分布函数公式如式(17)所示: 为计算方便,等式两边取对数如式(18)所示: 累计概率密度函数经过上述的变化推导就变成常见的线性 y=mx+b形式。最小二乘法的理论基石是实测值与模拟求得的结果值之间的差的平方总和最小。在用于威布尔拟合中,其公式如式(19)所示: 式中: SSerr——为实测值与模拟结果值差的平方总和。 式(19)对 k 和 c 分别求导,并分别令其为0,得出k值和 c值[18],如式(20)和式(21)所示: 上述最大似然法和最小二乘法所涉及的公式属于理论推导,运算较复杂,在涉及数据繁多的测风数据处理时,常常借助Excel 中的规划求解器Slover 来解决,Slover 规划求解器是一种多次运算组合模拟参数使得目标函数取得最大值或者最小值的解决办法[19],此方法方便快捷,批量处理测风数据能提高计算的效率和准确性。具体运用于此文章时将多次组合模拟 k 和 c值,使得联合密度函数取得最大值,最小二乘法函数即式(19)中的 SSrr取得最小值,此时相应的 k 和 c即为最优解。 在实际运用中,针对风场实测数据的风频分布情况一般采用上述5 种方法进行拟合,文章采用决定系数R2来衡量其拟合结果的精确度[20],其计算公式如式(22)所示: 式中: fw(vi) ——威布尔分布参数计算风速为 vi时的风频(%); fm(vi) ——实测风速序列为 vi时的风频(%);——实测风速序列风频的平均值(%); 0.9 0.8 0.7 R2≤0.7,拟合精度差。 文章选取我国不同经纬度,不同地形地貌及风资源条件各不相同的4 座测风塔,1 个完整年统计值为10 min 的风速样本52 560 个数据进行分析[21]。测风塔1 位于内蒙古茂明的平坦地形,植被稀少地貌非常简单;测风塔2 位于云南昭通东部海拔为2 100 m 左右的多山地带,植被较多,地形复杂;测风塔3位于新疆小草湖的半沙漠干旱地带;测风塔4 位于广东低纬度甲东地区的沿海滩涂附近。其测风塔所在地理区域位置如图1 所示。 图1 4 座测风塔地理位置图Fig.1 The geographic position of 4 masts 测风塔的经纬度,所在地空气密度,年平均风速和实测风功率密度等基本参数如表1 所示。 将测风数据以0.5 m/s 作为一个风速区间范围进行频率统计,采用上文介绍的5 种威布尔拟合方法分别对收集到的4 座测风塔数据进行模拟计算得k 和 c值,用威布尔分布函数可以求出各风速段相对应的频率,在此基础上利用式(4)计算威布尔分布风功率密度和式(22)计算决定系数,各测风塔结果分别如表2~表5 所示。 表2 测风塔1 威布尔分布和模拟风功率密度Tab.2 Simulation results of Weibull distribution and power density of mast 1 表3 测风塔2 威布尔分布和模拟风功率密度Tab.3 Simulation results of Weibull distribution and power density of mast 2 表4 测风塔3 威布尔分布和模拟风功率密度Tab.4 Simulation results of Weibull distribution and power density of mast 3 表5 测风塔4 威布尔分布和模拟风功率密度Tab.5 Simulation results of Weibull distribution and power density of mast 4 从表2~表5 模拟结果可知,4 座测风塔用经验法EMJ 和EML 计算的参数值K 分别相等,C 值均相差0.01,非常接近。 测风塔1 和测风塔4 用5 种威布尔方法模拟风频结果均好,决定系数均高于0.90,能量因子法EPF和最大似然法MLE 的决定系数相对更高,均高于0.96。相应威布尔计算所得的风功率密度与实测数据计算所得风功率密度绝对误差和相对误差也小,其中测风塔1 使用能量因子法EPF 和最大似然法MLE 与实测风数据计算所得风功率467.50 W/m2绝对误差分别为9.70 W/m2和8.00 W/m2,相对误差值分别为2.1%和1.7%。测风塔4 用5 种威布尔方法计算所得风功率密度和实测风功率密度绝对误差分别为46.12 W/m2,44.44 W/m2,5.89 W/m2,3.66 W/m2和66.88 W/m2。 测风塔2 和测风塔3 威布尔模拟的决定系数横向比较也有相似的趋势,能量因子法EPF 和最大似然法MLE 的决定系数高于其他3 种方法,其计算所得的风功率密度与实测数据所得风功率密度更加接近,绝对值误差和相对误差均小于其他3 种方法。尽管测风塔3 模拟决定系数整体偏低,其分布范围为0.69~0.85 之间,但能量因子法EPF 和最大似然法MLE 结果拟合精度较好分别为0.83 和0.85,其相对较高的趋势仍未变化。 测风塔3 用能量因子法EPF 和最大似然法MLE 计算所得的风功率密度与实测数据计算所得风功率密度绝对误差分别为28.81 W/m2和16.53 W/m2,相对误差分别为4.7% 和2.7%;经验法EMJ和EML 绝对误差较大,分别为125.94 W/m2和127.93 W/m2,最小二乘法LLSA 为68.46 W/m2,相对误差分别为20.6%,17.3%和11.2%。 测风塔3 用经验法EMJ 和EML 及最小二乘法LLSA 威布尔模拟结果一般,决定系数分别为0.69,0.69 和0.75,在此基础上利用风频分布计算所得的风功率密度误差更大,这也更好地验证了风频分布拟合准确与否对风功率密度计算准确度影响至关重要,风速与风功率密度是3 次方关系。 4 座测风塔实测风频分布图和威布尔分布模拟分布情况如图2~图5 所示。 图2 测风塔1 实测风速风频和威布尔拟合分布图Fig.2 Wind speed frequency of the measurement data and Weibull distribution simulation of mast 1 图3 测风塔2 实测风速风频和威布尔拟合分布图Fig.3 Wind speed frequency of the measurement data and Weibull distribution simulation of mast 2 图4 测风塔3 实测风速风频和威布尔拟合分布图Fig.4 Wind speed frequency of the measurement data and Weibull distribution simulation of mast 3 图5 测风塔4 实测风速风频和威布尔拟合分布图Fig.5 Wind speed frequency of the measurement data and Weibull distribution simulation of mast 4 文章针对风频分布拟合方法进行比较研究和风功率密度计算结果验证,引用决定系数对风频分布拟合度进行优劣评价,确定威布尔拟合常用的5 种方法准确性高低。为了使结论具有普适性和代表性,文章采用我国不同经纬度,地形地貌各异和风资源禀赋程度各不相同的4 座实测测风塔1 年统计数据进行验证。 最终得出结论:威布尔拟合常用的5 种计算方法中,能量因子法EPF 和最大似然法MLE 能更好地拟合实测风数据的风频,采用威布尔计算所得的风功率密度和实测风数据计算的风功率密度更为接近,误差较小,决定系数值较大,其风频的拟合度优于经验法和最小二乘法;经验法和最小二乘法拟合度相对差一些,相应计算的风功率密度误差也大一些。尽管某些测风塔用5 种方法拟合所得的决定系数相对都较小,拟合度一般,但横向比较能量因子法EPF 和最大似然法MLE 的拟合度仍较经验法和最小二乘法有优势,相应计算所得的风功率密度误差仍小于其他3 种方法。 这一结果与目前我国较流行的流体力学风资源模拟软件Meteodyn Universe 的运算规则相吻合[22],这款软件在做各高层绘图计算时用的是能量因子法EPF,在各风机机位点参数计算 k 值,c值时运用的是最大似然法MLE。 因此,在实际项目风资源评估中,建议采用能量因子法EPF 和最大似然法MLE 来模拟风数据的风频分布,计算得出更加接近实际的风功率密度,可为更好地了解掌握风场的风资源提供可靠依据。2 威布尔分布参数拟合方法及精度验证
2.1 EMJ Justus 经验方法
2.2 EML Lysen 经验方法
2.3 EPF 能量因子方法
2.4 MLE 最大似然法
2.5 LLSA 最小二乘法
2.6 威布尔模拟精度验证
3 案例分析





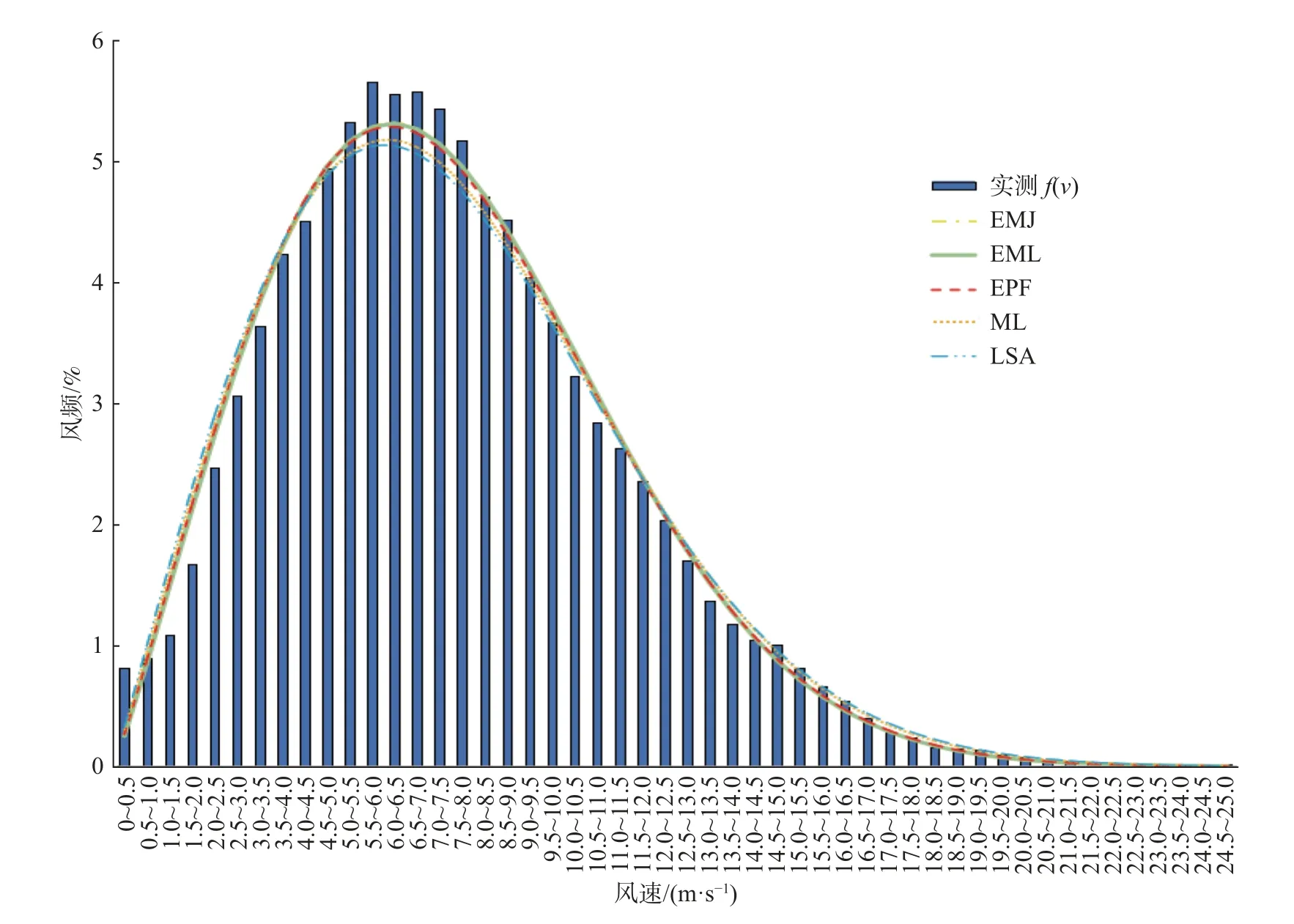



4 结论
猜你喜欢
水力发电(2021年10期)2022-01-13电脑与电信(2021年10期)2021-02-10南方农业学报(2020年4期)2020-06-04南方农业学报(2020年10期)2020-01-21水力发电(2019年1期)2019-04-22科学与财富(2018年12期)2018-06-11山东工业技术(2017年8期)2017-05-08资源节约与环保(2016年6期)2016-11-24广东电力(2016年6期)2016-07-16建筑工程技术与设计(2015年8期)2015-10-21
