
基于空洞卷积和ECANet 的双判别生成对抗网络图像修复模型
2024-01-31 13:23胡文松刘兴德
电子制作 2024年2期
胡文松,刘兴德
(1.吉林化工学院 信息与控制工程学院,吉林吉林,132022;2.吉林化工学院 机电工程学院,吉林吉林,132022)
0 引言
图像修复是合理填补图像中缺失或者损坏的部分,使我们主观视觉上看起来结构一致,内容真实的一种任务,随着图像修复技术的不断发展,在文物资料修补[1]、公安面部修复[2]、医学影像重建[3]等领域有着广泛的应用。
现阶段修复任务主要分为两类,一种是传统的扩散或补丁的方法,另一种是基于深度学习的方法来解决修复问题。通过扩散或补丁的方法[4~7]通常使用变分算法或补丁的方法,使信息由背景区域传递至缺失区域。这种方式虽然对静态数据效果较好,但对于非静态数据(例如自然图像)来说受到限制。为了克服这一挑战,研究者们提出一种基于高效最近邻域PatchMatch[8]算法,该算法在图像编辑领域,包括图像修复等应用,展现出显著的实用价值。
伴随着深度学习的快速发展和生成对抗网络(Generator Adversarial Network,GAN)技术的出现,图像修复技术也迎来巨大的技术革命。Pathak 等[9]提出上下文编码器(Context Encoder,CE),该算法使用编码器-解码器架构,结合L2 重构损失和对抗损失进行预测,但输出图像表现模糊且含有视觉伪影。Iizuka 等[10]提出一种全局和局部双判别器结构(Globally and locally,GL),该算法,但对于细节和纹理处理比较模糊。Yu 等[11]提出一种双步骤方法,以应对图像修复问题。首先,对缺失区域进行粗略修复,随后将修复后的图像输入细化网络中,再引入上下文对于修复图像的局部和全局的结构一致性有所提高注意力机制,以实现对图像纹理和结构的精细修复。
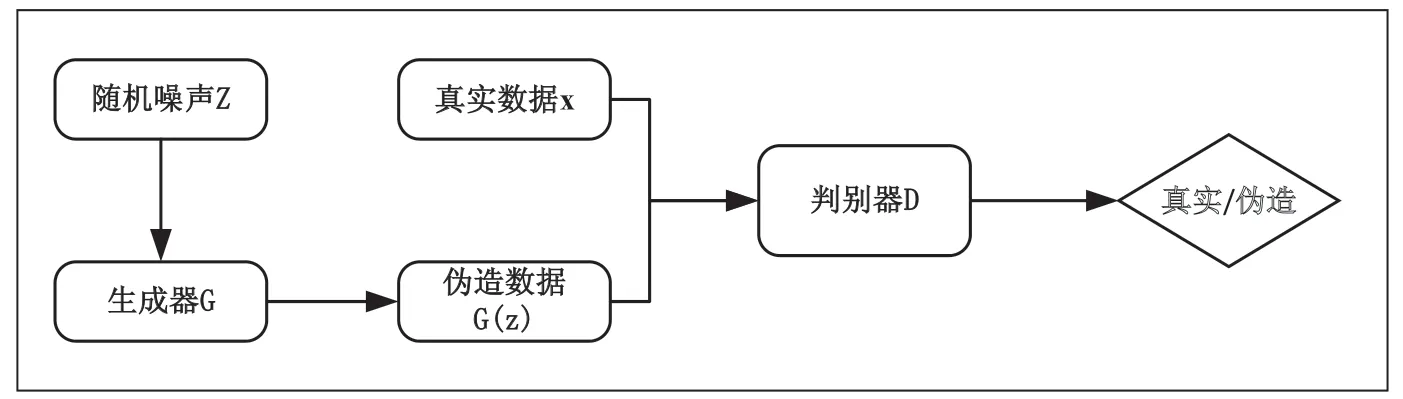
图1 生成对抗网络结构图
1 相关研究
■1.1 生成对抗网络
Lan Goodfellow[12]在2014 年提出生成对抗网络(GAN),它由生成器(Generator,G)和判别器(Discriminator,D)所构成。生成器吸收了随机噪声z 并提供信息,判别器是一个二分类器,它的主要任务就是辨别信息是来源于真实数据x,或者由生成器G(z)所生成的伪造信息。通过使用交叉熵损失,判别器D被训练来正确识别输入数据的真实性。其中,生成器尽可能生成逼真的数据,而判别器最大限度辨别输入数据的真假,这两者通过不断竞争和训练,最终达到博弈的纳什平衡。
■1.2 ECA 通道注意力
为解决图像修复中纹理、结构问题,本文引入通道注意力。借鉴文献[13]提出的一种高效的通道注意力机制(Efficient Channel Attention,ECA),ECA 是基于SE 注意力[14]改进,其网络结构主要分为三个方面:首先,对于一个输入的特征图,Squeeze 操作通过全局平均池化把特征图从大小为(N,C,H,W)转化为(N,C,1,1),这样就达到全局上下文信息的融合;接着,ECA 能够计算自适应卷积核的大小,,其中C为输入的通道数,b=1,γ=2,并采用一维卷积计算通道的权重,最后采用Sigmoid 激活函数将权重映射在(0-1) 之间;最后将reshape 过后的权重值与原有的特征图做乘法运算,得到不同权重下的特征图。
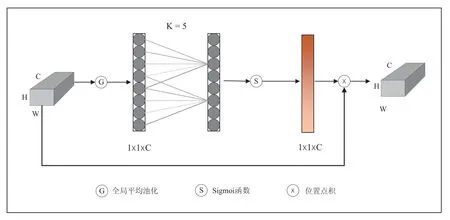
图2 ECANet 结构图
2 改进的网络模型
本文选用文献[10]提出的GL 模型构建基础的图像修复模型,并对模型进行再现和改进,提出一种基于膨胀卷积和ECA 机制的双判别生成对抗网络图像修复模型,本文模型是采用多段式的生成网络修复模型,首先生成器由两个部分构成,一个是粗糙生成网络,另一个是精细生成网络,它们都是由一般卷积和空洞卷积组成。第一步将破损图像加上掩码作为输入,经历两次下采样以此来获得图像的潜在特征,再经过一般卷积和空洞卷积扩大感受视野获得更多特征信息,紧接着两次上采样恢复到原始尺寸。将得到结果作为输入放置到精细网络中并引入注意力进一步修复图像,最后利用全局判别器和局部判别器对真实图像分类,引导生成器的修复,具体框架如图3 所示。
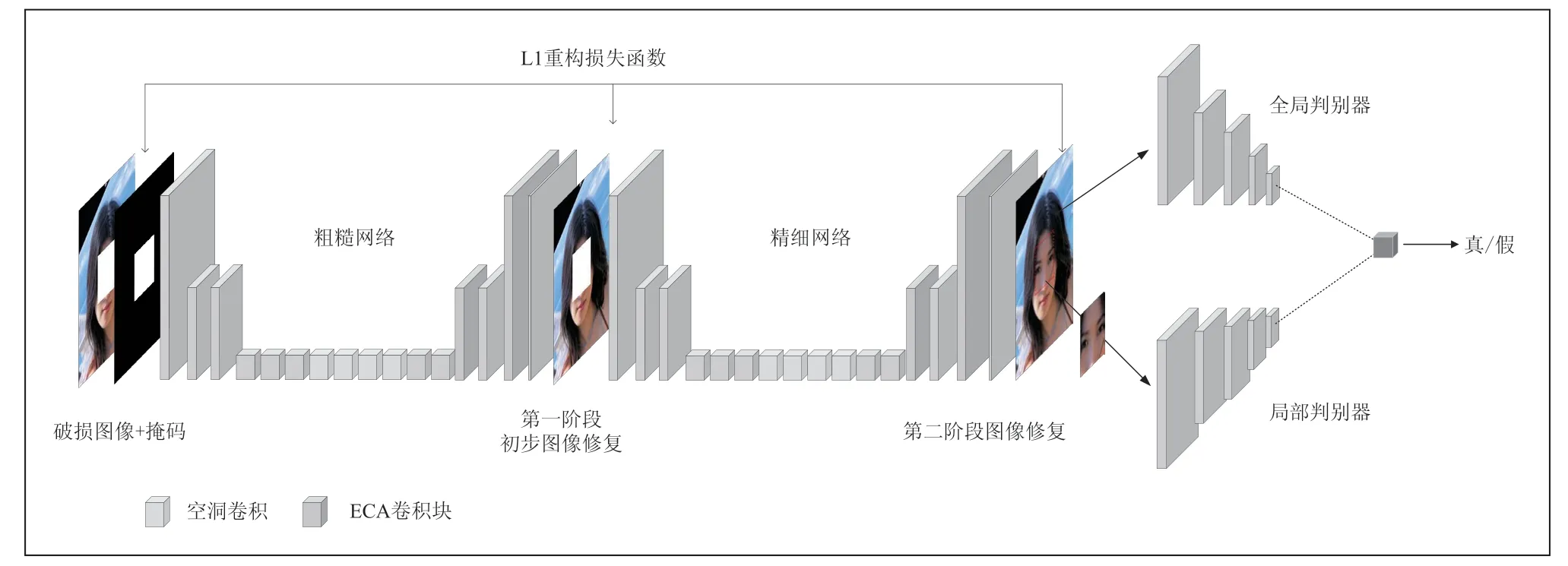
图3 本文图像修复模型架构
■2.1 基于级联的生成网络
本文的生成网络与传统生成网络类似,采用自动编码器的结构。借鉴文献[10],生成网络有粗糙网络和精细网络两部分。粗糙网络共有15 层卷积包含一般卷积和空洞卷积,空洞卷积能够在不增加计算量的情况下,增加模型的感受视野,从而更好地捕获远距离的上下文信息,在网络模型上采样中引入ECA 注意力来增强图像特征,精细网络与粗糙网络的结构一致,在每一次卷积后添加ECA 注意力对特征图细节增强,从而引导生成器的修复能力。
■2.2 基于全局和局部的双判别器网络
为了解决原始生成对抗网络(GAN)中二分类网络这种单一判网络框架下,生成器所生成的图像不足问题。本文借鉴文献[10]中判别器网络模型,引入一个全局判别器G_D 和一个局部判别器L_D。全局判别器由6 个卷积层和一个输出单个1024 维向量的全连接组成,所有卷积都采用2×2 的步幅来降低分辨率,并且所有卷积都使用5×5 内核,局部判别器与全局判别器的网络结构一致。最后,将全局判别器和局部判别器的输出连成一个2048 维的向量,由单个全连接通道进行处理输出一个连续的值,再采用Sigmoid 传递函数,使得该值在0~1 之间内表示,从而判断图像的真实性。
■2.3 目标损失函数
为了训练更稳定和生成图像更加逼真,本文联合使用两个损失函数:WGAN-GP 损失作为训练稳定性,以及L1 重建损失来提高图像的真实性。其中重建损失函数定义如下:
其中,xtarget(i,j)是目标图像在位置(i,j)处的像素点,xgenerator(i,j)是生成的图像在相同位置的像素值。
传统的GAN 损失函数中,生成器和判别器之间的优化目标是最大化一个交叉熵损失,但这种损失函数可能会导致训练不稳定,容易出现梯度爆炸或者模式塌陷等问题。对于这种问题,我们可以采用文献[15]提出的WGAN-GP 损失,WGAN-GP 使用Wasserstein 距离来衡量生成器输出和真实数据之间的不同,其定义如下:
式中,超参数λ是控制惩罚项所占的比重,在实验中设置为10。在训练中,联合L1 重构损失和WGAN-GP 对抗损失作为总损失,其表达式如下:
式中,λL1、λadv分别对应损失权重,参照文献[10][11]中超参数配置多次实验室,本文的λL1和λadv分别设为1,再经过Adma 优化器不断更新迭代参数,优化模型。
3 实验与结果
■3.1 实验方法
实验环境配置:AMD 处理器R7-5700X,Nvidia GeForce RTX 2080ti 显卡,11G 显存。环境为Windows10,编程语言为python3.8,基于Pytorch 框架。
本次实验选用Celeba 数据集,随机从数据集中抽取200 000 图片作为训练集,1000 图片作为测试集,抽取的图片大小为256×256,Batchsize 设为16,模型在数据集上进行50 轮Epoch,生成器和判别器的Learning_rate 设置为0.000 01,使用Adam 优化器,其中一阶、二阶动量分别设置为0.5 和0.999。
■3.2 实验结果
为了验证本文所提修复模型相较于其他修复模型的优越性,将文献提出得到GL[11]、CA[12]两个提出的图像修复方法。采用相同的数据集CelebA_256,相同的遮挡区域进行比较。
GL 中生成网络采用空洞卷积来扩大感受视野,并使用全局和局部特征融合的双判别器网络结构,对于修复图像的局部和全局的结构一致性有所提高。
CA 首次提出从粗到细两段式网络结构,并在生成网络中引入一个Contextual Attention 机制,能够将全局和局部信息有效地结合从而产生更准确的修复结果。
因为选择的数据集是人脸数据集,所以掩码选择的是固定在图像中心,遮挡人脸最重要的特征五官部分,大小约为85。从图4 可以看出,GL 模型的修复结果在遮挡部分出现局部错乱,语义信息不协调,没有学习到掩码的消息,对掩码区域无法进行判定,其中人脸结构又较为复杂,因此在掩码和背景交界处有明显的伪影。CA 模型的修复结果整体效果较好,但在整体语义连贯这个问题上,依然存在较为明显的掩码信息,网络不断地加深,空洞卷积所学习到地特征比较少,并且人脸是人最复杂且重要地生物特征,所以在细节部分,尤其是鼻子和嘴巴修复的不是很好。而本文模型不仅保证图像结构一致性,在掩码与背景交接处无掩码信息残留,在图像细节部分也有明显改善,例如头发、鼻子相比GL、CA 模型图像生成更加精细。

图4 不同模型之间图像修复结果
■3.3 实验分析
为了更全面、客观的评价不同模型的性能,采用峰值信噪比(Peak Signal-to-Noise Ratio,PSNR)和结构相似性(Structural SIMilarity,SSIM)做客观指标,继续选用Celeba_256 数据集,添加不同的掩码,选取100 张待修复图像作为测试,分别投入训练好的模型:GL、CA和本文模型。
从表1 可以看出,本文模型相对于GL、CA,在PSNR 指标上提升了6.6%~7.9%,在SSIM 指标上提升了2.9%~7.5%,说明本文模型在人脸图像数据集CelebA_256对于方形掩码效果更好。

表1 不同模型的客观修复指标结果
4 结论
本文提出了一个全新的图像修复网络模型,它采用空洞卷积和ECANet,并结合双判别器形成对抗网络。生成网络则采取了两阶段的生成模式,从粗向精逐渐还原图像,并在精细层面引入了注意力机制。判别网络使用局部判定和全局判定的双重判别结构。通过对抗损失和重建损失相结合的损失函数,以便进行更精准的纹理和结构修复。并通过多个实验对比,模型在主观视觉效果上表现优异,各项客观指标也有所提升。综合来看,本文提出的修复模型在人脸图像方面表现出良好的修复效果。
猜你喜欢
数学物理学报(2022年4期)2022-08-22
数学物理学报(2022年2期)2022-04-26
通信学报(2019年5期)2019-06-11
金桥(2018年4期)2018-09-26
通信技术(2018年3期)2018-03-21
故事作文·高年级(2017年2期)2017-03-01
新闻传播(2015年20期)2015-07-18
浙江大学学报(工学版)(2015年4期)2015-03-01
电子设计工程(2015年20期)2015-01-29
中国卫生(2014年5期)2014-11-10
