
基于红外和可见光的多模态数据融合方法研究
2024-01-31 13:23王芳罗艺闯刘小虎邢静
电子制作 2024年2期
王芳,罗艺闯,刘小虎,邢静
(西安培华学院 智能科学与信息工程学院,陕西西安,710125)
0 引言
随着硬件设备及相关技术的发展,基于红外和可见光的多源图像融合技术在军事探测、视频监控、医疗成像、图像水印等方面得到了广泛的应用[1]。其利用不同传感器的特点进行优势互补,结合图像处理技术将不同分辨率、不同来源的多模态的图像融合成为一幅包含丰富信息的图像,整体流程如图1 所示。通常,可见光图像具有较高的分辨率、丰富的细节信息及较强的对比度,但易受到光照、运动等因素的影响,而红外图像有较强的抗干扰能力,能够有效捕获目标的轮廓信息,但分辨率较低、细节保持较差,易受热交叉等因素的影响,通过多模态数据融合技术可实现信息的有效互补,扩展系统的时空覆盖率,有效增强系统的鲁棒性。随着以深度学习为代表的人工智能技术的发展,如何实现基于红外和可见光多模态数据的有效融合,是目前研究的热点和难点。
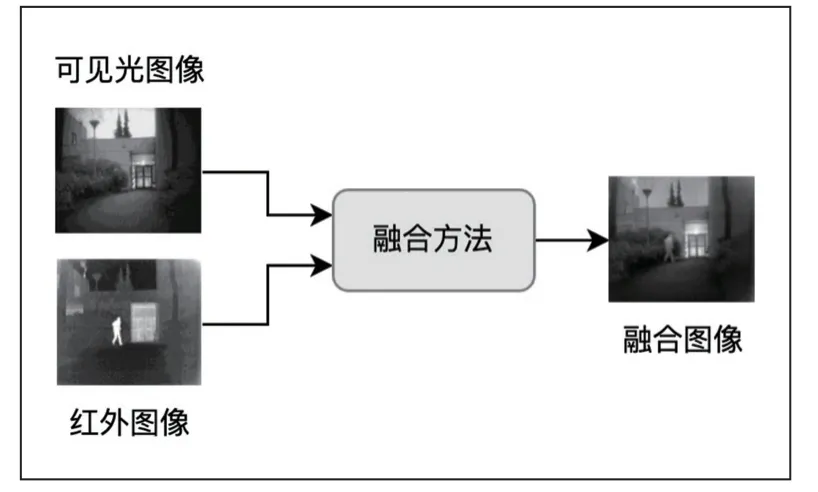
图1 基于红外和可见光的多模态数据融合示意
1 融合分类及评价指标
基于红外和可见光的多模态数据融合,可按照融合级别、融合域及融合方法来进行划分[9],其中每种类别又包含不同的划分。
具体地,根据融合级别可分为像素级融合、特征级融合和决策级融合[2]。像素级融合直接对图像像素点进行融合,如主成分分析方法、小波变换法等,但其需要大量的预处理且由于缺乏严格的对齐,导致融合结果存在严重的畸变;特征级融合通过滤波器或表示学习来抽取图像的表征,进而对特征信息进行融合,如特征金字塔法、卷积神经网络方法等,处理速度快但会丢失特定的信息;决策级融合由各模态分别实现信息的决策后,合并实现全局最优决策,如贝叶斯方法、模糊聚类法等[3],但其缺乏具体的视觉感知,因此不适于计算机视觉相关的下游任务。
根据融合域可分为基于空间和基于变换的方法。基于空间的融合方法直接作用原图像,如加权平均、形态学算子等,但这种方法通常会产生一些如谱畸变的效果。而基于变换的融合方法采用合适的变换方法来避免该问题,如金字塔变换、小波变换等,其首先将原图像投影到变换空间中,进行相应的滤波计算,然后再逆变换到原图像空间。
根据融合方法可分为多尺度变换、稀疏编码、混合融合方法及基于神经网络的方法。基于多尺度变换的方法首先利用特征金字塔、小波变换等算法来抽取不同尺度的表示,然后采用特定的融合规则对不同尺度的表示进行融合,最后将所有尺度融合的结果相加并进行逆变换得到最终的融合图像。基于稀疏编码的方法将原图像用一个完备的字典进行编码来获取稀疏系数,然后采用不同的融合策略结合系数进行加权融合得到融合图像,可以看出,其也可作为一种融合策略。混合融合方法结合了其他融合方法的优点,如将多尺度变换方法和稀疏编码的方法进行结合,其中多尺度变换方法来获取低频特征信息,但会存在视觉冗余信息,进而结合稀疏编码来进行改善融合效果。当前,最具前景的方法是基于深度学习的方法,涉及不同的网络结构,将在下部分进行详细阐述。
对于融合方法的评估,通常有客观评价方法和主观评价法。主观评价从观察者的角度来评估融合图像的清晰度、亮度和对比度等。客观评价通过构建客观的评价指标对融合图像进行评价,主要包括基于信息理论的指标,如FMI,QNICE和QM等,基于图像特征的指标,如QA/BF,QP等,基于图像结构相似性的指标,如SSIM,QY等,以及基于感知启发的指标,如VIF,QCV等[4]。
2 红外可见光融合方法
通过上述融合方法的分类及原理的梳理,可以看出像素级融合和基于空间的方法的思想相同,基于多尺度的方法和基于变换域的分类原理一致,混合融合的方法基于其他的方法,进行结合而得到,因此,本文基于融合的基本原理,按照基于空域的方法、基于变换域的方法、基于稀疏编码和基于神经网络的方法来结合具体的算法进行阐述,并将除基于神经网络的方法以外的其他的方法称为基于传统的融合方法,具体如下:
■2.1 传统的融合方法
传统的图像融合方法包括基于空域的方法、基于变换域的方法及基于稀疏编码和字典学习的方法[4]。基于空域的方法通过计算不同模态的局部或像素级显著性,进行加权平均得到融合图像;基于变换域的方法首先将源图像变换到变换域(如小波域)中,以获得不同频率的分量,然后通过设计相应的融合规则对分量进行融合,最终逆变换回源空间得到融合图像,常用的方法有拉普拉斯金字塔(LP)、低通金字塔(RP)、离散小波(DWT)、离散余弦(DCT)、曲线簇变换(CVT)等。基于稀疏编码和字典学习的方法通常基于稀疏系数来获得图像的局部表征和全局表征,并通过加权融合算法来得到融合图像。
传统的图像融合方法主要受限于以下两个方面:首先,通过复杂的人工设计提取的特征通常无法有效地保留图像中的信息,从而导致融合图像中存在伪影;其次,特征提取方法通常是针对特定的任务来设计的,难以有效地迁移到其他任务中。
■2.2 基于深度学习的融合方法
由于深度学习能够有效地解决传统方法中手工提取特征不全和特征编码设计复杂等问题,目前,基于深度学习的融合方法,大都采用特征级融合。常见的基于深度学习的红外可见光融合框架,主要包含基于自编码器(AE)的方法、基于卷积神经网络(CNN)的方法和基于生成对抗网络(GAN)的方法,分别如图2、图3、图4 所示。
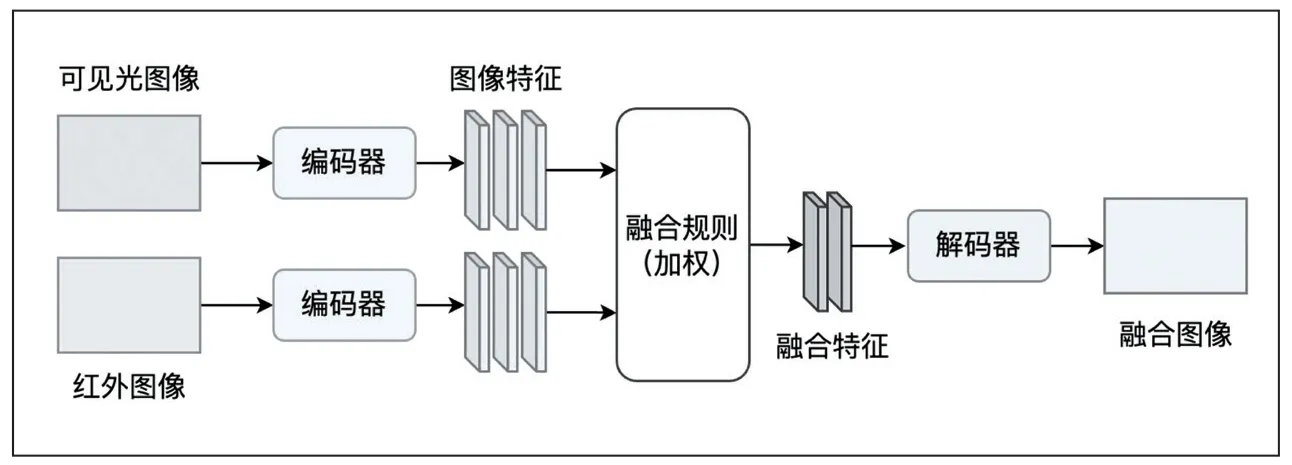
图2 基于自编码器的融合方法
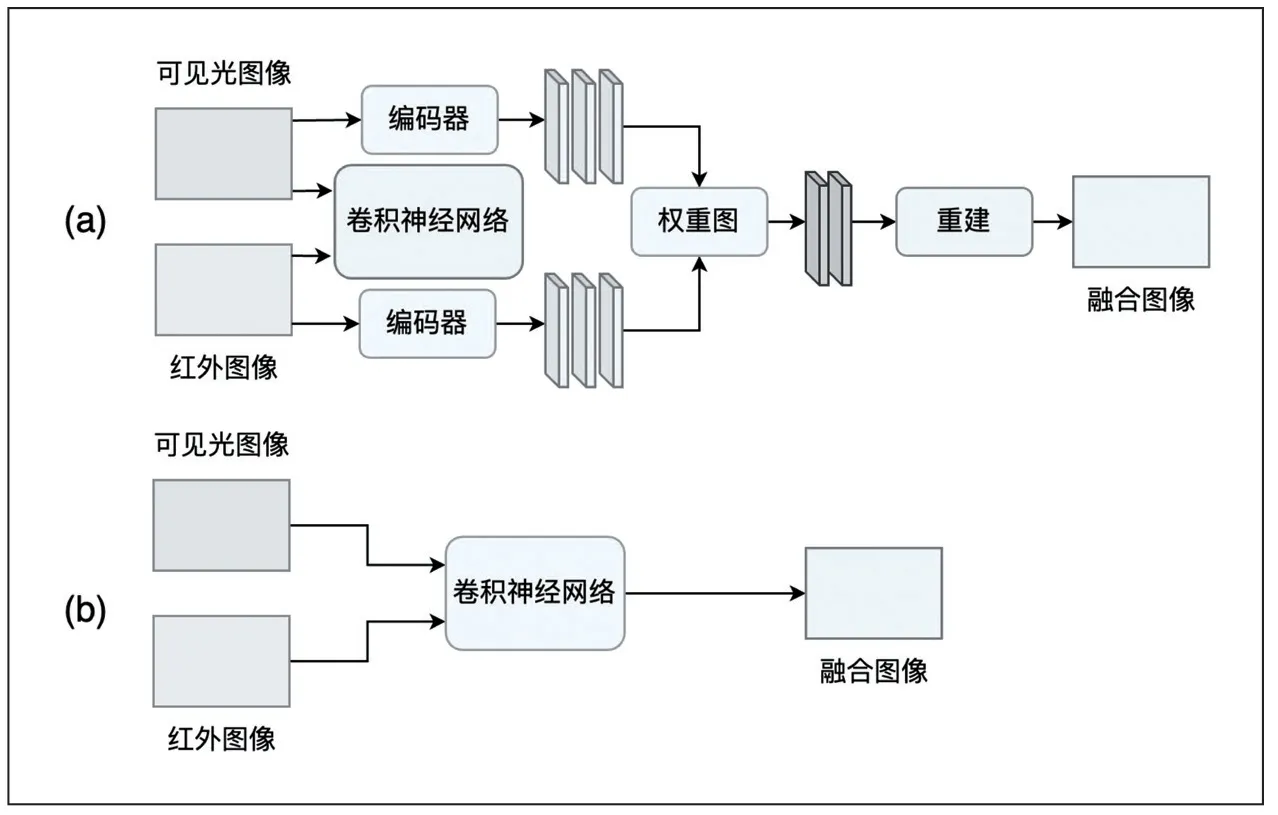
图3 基于卷积神经网络的方法
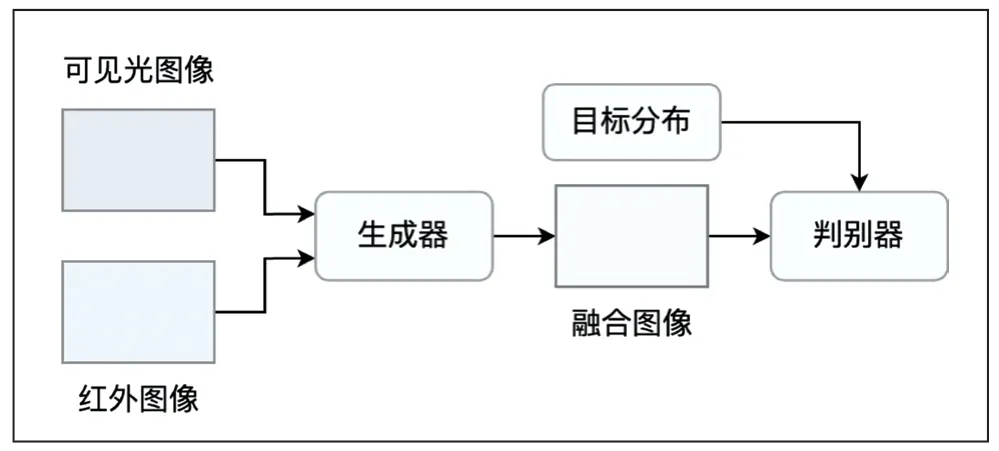
图4 基于生成对抗网络的方法
基于自编码器的方法通常基于预训练的自编码器,然后结合特定的数据集对其进行训练来抽取特定的特征和融合图像重建,其中中间特征的融合可采用常规的融合规则来实现,如图2 所示。DenseFuse[5]方法是其典型代表,其在MS-COCO 数据集上来训练编码器和解码器,并采用逐像素相加和L1-正则的融合方法来实现特征的融合。
基于卷积神经网络的方法在图像融合过程中采用不同的方式来引入卷积神经网络,一种采用端到端的方式来进行特征提取、特征融合和图像重建,如图3(a)所示,PMGI 是其典型代表,其基于梯度损失来引导网络直接生成融合图像。另一种采用预训练的CNN 来进行融合,而图像重建则采用传统方法实现,如图3(b)所示,Liu[6]等采用CNN 来获取融合权重,而图像分解和重建采用Laplacian金字塔实现。
基于生成对抗网络的方法依靠生成器和鉴别器之间的对抗性博弈来估计目标的概率分布,以一种隐含的方式联合完成特征提取、特征融合和图像重建,如图4 所示。FusionGAN[7]是其典型代表,其采用对抗学习来融合红外图像和可见光图像,进而丰富融合图像的纹理特征。
基于自编码器的方法其关键在于特征融合规则的设计,目前多采用基于人工设计的方法来实现,如加权、L1-正则的方法,不可自学习,限制了融合效果。基于卷积神经网络的方法易受到网络结构和损失函数的影响,而基于预训练的网络不能兼顾特征提取和图像重建,融合效果有限。基于生成对抗网络的方法目前最为常用,能够隐含地完成特征抽取、特征融合和图像重建,并产生较理想的融合效果,但如何在训练过程中保持生成器和判别器的平衡,是其面临的难题。
3 融合方法发展趋势
随着Transformer[8]结构的提出,由于其能够构建长距离信息依赖,在自然语言处理领域所展现出极大的优势,受启发于此,图像领域首先在图像分类任务上提出了视觉Transformer 结构ViT[10],后续目标检测和分割也提出了相应的基于Transformer 结构的方法,并展现出了较卷积神经网络好的性能。因此,在红外和可见光多模态融合方法的基础上,提出了基于Transformer 结构的方法,其基本结构如图5 所示。
基于Transformer 的融合方法能够充分利用局部特征信息,并对长距离依赖进行建模,克服了现有融合方法缺乏全局上下文信息的问题,自动学习融合规则,展现出了更具前景的性能。从图5 可以看出,基于Transformer的融合方法整体框架包含编码器模块、特征融合模块和编码器模块三个部分组成,其中编码器用于提取图像特征,特征融合实现可将光和红外特征的融合,解码器用于图像重建,生成最终的融合图像。
(1)编码器模块通常基于预训练模型来提取图像的特征fi(i∈ {1,2}),其中,i=1表示红外特征,i=2表示可将光特征。通常采用卷积神经网络、Transformer 编码器网络或卷积神经网络和Transformer 编码器相融合的网络结构来实现,以提取图像的局部信息和全局信息。通常由于红外和可见光图像所包含信息的差异性,编码器模块采用不同的网络权重来提取相应图像的特征,并且,为了训练的稳定性,在设计时会融入残差网络结构。由于并不是所有的特征都有助于融合图像的重建,因此,需要给不同的特征以不同的权重,即所要阐述的基于自注意力的特征融合。
(2)特征融合模块首先基于图像特征生成细化特征,然后采用融合策略进行特征融合生成最终的特征,作为解码器的输入。基于Transformer 的融合方法通常采用基于注意力的融合策略,以同时保留视觉细节信息和显著的热辐射区域。为了精准获取图像的显著特征,首先需要构建注意力图:
其中,Q,K分别表示自注意力中的Query 和Key,d 为特征维度,Wq和Wk为投射层权重,实现对特征fi的编码,通过该步骤即可得到各特征对应的权重,进而利用注意力加权得到融合特征:
其中,V为自注意力中的Value,Qv为可学习的投射层权重。具体在实现时,可采用类似ViT 的Transformer结构:
其中,MSA为多头注意力网络,MLP为多层感知机网络。由于自注意力机制需要遍历特征图的所有位置,具有平方计算复杂度,因此通常需要结合线性注意力、轴注意力机制及基于先验的注意力机制来降低计算复杂度,提升计算效率。
(3)解码器模块基于融合特征生成融合图像,因此可以采用反卷积或Transformer 的解码器来实现。由于融合后的特征可能会丢失一些特定的细节信息,因此,结合编码器的特征对于重建至关重要,以补充重建图像的细节信息。
此外,为了获取较好的融合效果,损失函数的设计起到了非常重要的作用,除了像素级别的重建,还需要充分地捕获图像的结构信息和梯度信息,具体如下:
其中,Lmse为均方损失函数,用于度量像素级别的重建效果,Lssim为结构相似性损失函数[11],用于学习图像的结构信息,Ltv表示变分损失函数[12],用来保留图像的梯度信息,以消除图像重建过程的噪声。λ1和λ2是用来平衡各损失的系数。
未来,可以从以下几个方面进行研究:①任务相关的融合方法:由于不同的任务所需要的信息不同,可以根据不同的任务设计自监督学习的代理任务,来学习任务相关的融合特征。②更有效的特征抽取方法:卷积神经网络和Transformer 结构各有优势,如何结合两种网络结构以提取更有效的特征,也是值得研究的方向。③高效的网络训练方法:基于Transformer 的融合方法通常需要较大的数据量,及较长的训练的时间,如何结合网络结构和参数有效微调方法,实现融合模型的快速构建,也是研究的重点。
4 总结
基于红外和可见光的多模态数据融合方法,需同时兼容特征提取、特征融合及图像重建,关键在于融合规则的构建,传统的融合方法在特征提取和融合规则方面均需要人工设计,基于深度学习的融合方法,解决了特征自动构建问题,但在融合规则方面多还是基于加权或L1 正则等方法,无法自动学习实现特征融合,且存在受网络结构影响及训练困难等问题,基于Transformer 的方法能够对长距离依赖进行建模,表达及泛化能力强,可实现特征融合的自学习,且网络结构模块化,可方便地和其他网络结构相结合,具有极大的发展前景。
猜你喜欢
环球时报(2022-05-23)2022-05-23
北京航空航天大学学报(2021年9期)2021-11-02
金桥(2021年4期)2021-05-21
电子制作(2019年11期)2019-07-04
电子制作(2019年7期)2019-04-25
成都信息工程大学学报(2018年3期)2018-08-29
北京航空航天大学学报(2018年1期)2018-04-20
电子设计工程(2017年20期)2017-02-10
光学精密工程(2016年3期)2016-11-07
电子器件(2015年5期)2015-12-29
