
基于延迟和抖动感知的多播服务功能树嵌入算法
2024-01-27 06:56桂晓菁徐勇军杜娅荣侯泽天
电子与信息学报 2024年1期
刘 亮 陈 翔 桂晓菁 徐勇军 杜娅荣 侯泽天 段 洁
①(重庆邮电大学通信与信息工程学院 重庆 400065)
②(重庆邮电大学自动化学院 重庆 400065)
1 引 言
在支持网络功能虚拟化(Network Function Virtualization, NFV)的软件定义网络(Software Defined Networks, SDNs)中,为实现可靠、安全及可扩展传输等目的,用户请求流通常需要依序遍历由多个虚拟网络功能(Virtual Network Functions, VNFs)组成的服务功能链(Service Function Chain, SFC)[1]。对于单播请求流, SFC可以直接沿着单播路由路径依次选择嵌入节点进行VNF部署,目前已有大量文献对这一工作进行了研究,特别是文献[2]利用拉格朗日对偶理论[3]设计松弛算法求解了具有多资源多QoS约束的单播SFC嵌入问题,具有典型的代表性。多播通过共享的多播树进行多路复用,与单播相比,可以减少骨干网50%以上的带宽消耗[4]。2022年至2028年,全球视频流媒体市场预计将以21.0%的复合年增长率扩张[5],这些视频流大多以多播的形式向用户提供服务。在SDN/NFV架构中具有SFC需求的多播请求流(Multicast Request flows, MRs)是将流量从源点转发到多个目的节点,每个源-目的对之间需要根据SFC的要求依序遍历多个VNFs实例,这将形成一个虚拟网络功能转发图[6]。图1为该文构建的一条多播流从源点s依序经过由防火墙(FW)、入侵检测系统(IDS)、入侵阻止系统(IPS)组成的3条相同SFC后到达各个目的节点的示意。显然这3条SFC共同组成了一颗多播服务功能树(Service Function Tree,SFT)。联合考虑网络中各种资源及QoS约束条件,为多播请求流嵌入SFC是一个巨大的挑战。
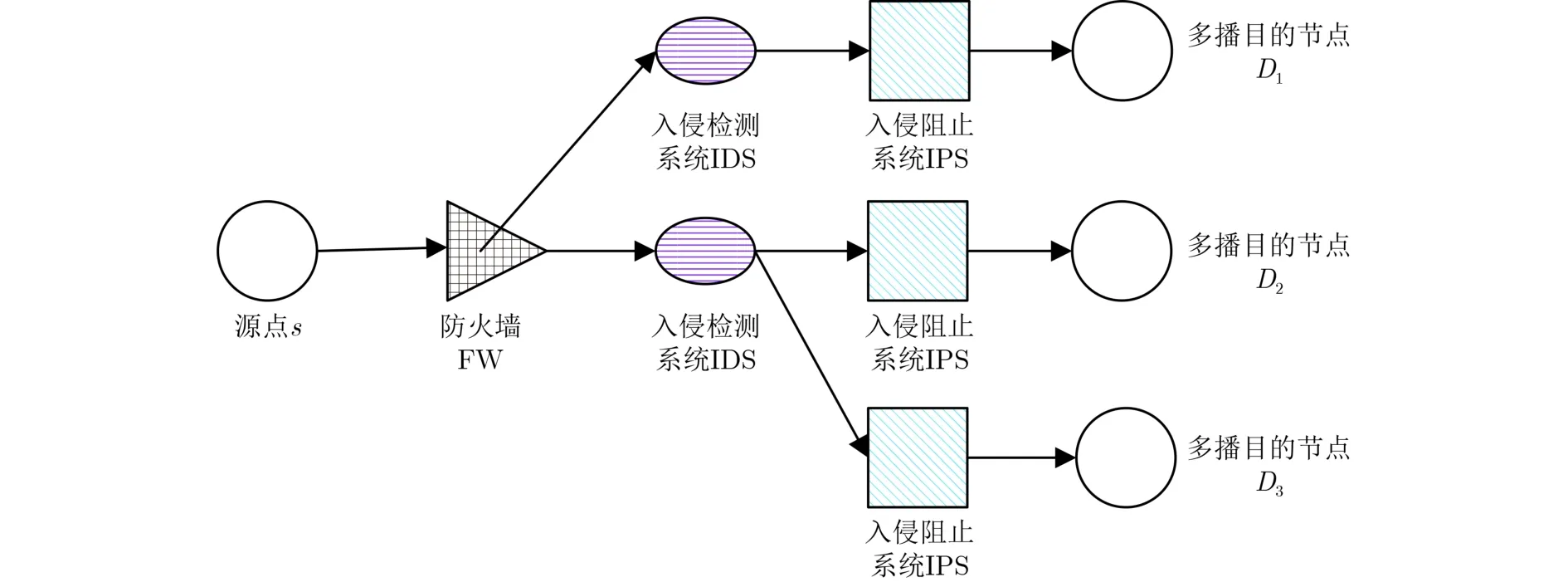
图1 多播服务功能树
目前,在SDN/NFV架构中,研究多播SFT嵌入的文献比较少。文献[7-9]研究了在已经放置了多个VNF实例环境中MRs的路由问题,但文献[7]没有考虑路由过程中VNF的动态部署,文献[8]考虑了VNF的运行和动态部署成本,但没有联合考虑网络中交换节点的转发成本,并且,它们都以多播源-目的对之间的单条SFC进行嵌入。文献[9]重点关注多播业务链的迁移调整,文献[10]则基于预测的方式对多播流的SFC进行动态嵌入,上述工作没有基于多播服务功能树(SFT)对SFC进行灵活整体嵌入,会造成网络资源分配不均衡。文献[11,12]研究了SFT的动态编排和整体嵌入,但文献[11]假设所有VNFs都部署在一个NFV功能节点中,文献[12]则要求多播分发点只能在部署的最后一个VNF节点之后进行,限制了SFT嵌入的灵活性和可扩展性,从而降低了网络资源的使用效率。
此外,对于视频会议、多人游戏等实时性要求较高的多播应用,对时延和抖动有严格要求。文献[13-17]研究了SFT的灵活嵌入和部署问题,但文献[13,14]没有考虑多播延迟和抖动约束,文献[15-17]考虑了端到端的延迟约束,但没有考虑多播目的节点之间的抖动约束,上述工作会影响多播用户的服务体验质量。文献[18]考虑用户的移动性及加入退出机制,研究了NFV网络中多播SFC的嵌入,调整和扩展问题。文献[19]是在无线Mesh网络中,考虑无线信号干扰和资源受限的情况下,以最小化链路成本为目标研究多播服务功能树的嵌入问题。上述工作同样没有考虑多播SFT时延和抖动约束,且和本文的研究场景不同。
综上所述,当前还没有相关工作联合考虑多VNFs实例环境下VNF的动态放置、网络资源约束及网络负载均衡等因素,研究具有严格时延和抖动感知的SFT灵活嵌入和多播路由算法。因此,本文在已有研究基础上,提出一种基于最优链路选择函数进行深度优先搜索构建具有严格时延和抖动约束的多播SFT嵌入算法。具体内容为:
(1)联合考虑VNF动态放置,多资源约束(包括SDN交换机的转发表容量、链路的带宽、功能节点的CPU容量)及网络负载均衡因素正式定义并用ILP模型刻画了延迟和抖动感知的动态SFT嵌入和路由问题(the Delay and Jitter Aware Dynamical SFT embedding and Routing Problem, DJADSRP)。(2)设计辅助边权图,将资源消耗及时延指标转化为边权图中的权值降低问题复杂性,提出最优链路选择函数构建SFT嵌入算法(SFT-EA)求解原问题。(3)将提出的SFT-EA算法与现有算法进行性能对比,结果表明SFT-EA不仅较优地解决了多资源及时延和抖动联合约束下的多播SFT嵌入问题,且在流接受率、网络吞吐量和负载平衡方面具有更好的性能。
2 系统模型
2.1 物理网络
将SDN/NFV网络表示为G=(N,L),其中N,L分别表示节点和链路的集合。用u,v ∈N和<u,v >∈L分别表示物理节点和物理链路,为方便起见,后文用uv ∈L表示物理链路。网络中有两种节点类型,一种是负责转发数据的交换节点Ns ∈N,另一种是由一台或多台服务器组成的功能节点Nf ∈N,N=Ns ∪Nf。G中有一台SDN控制器,为每条多播请求流执行动态的VNF放置和路由路径选择。图2为网络示例,其中节点v1,v3,v4为功能节点,其余为交换节点。
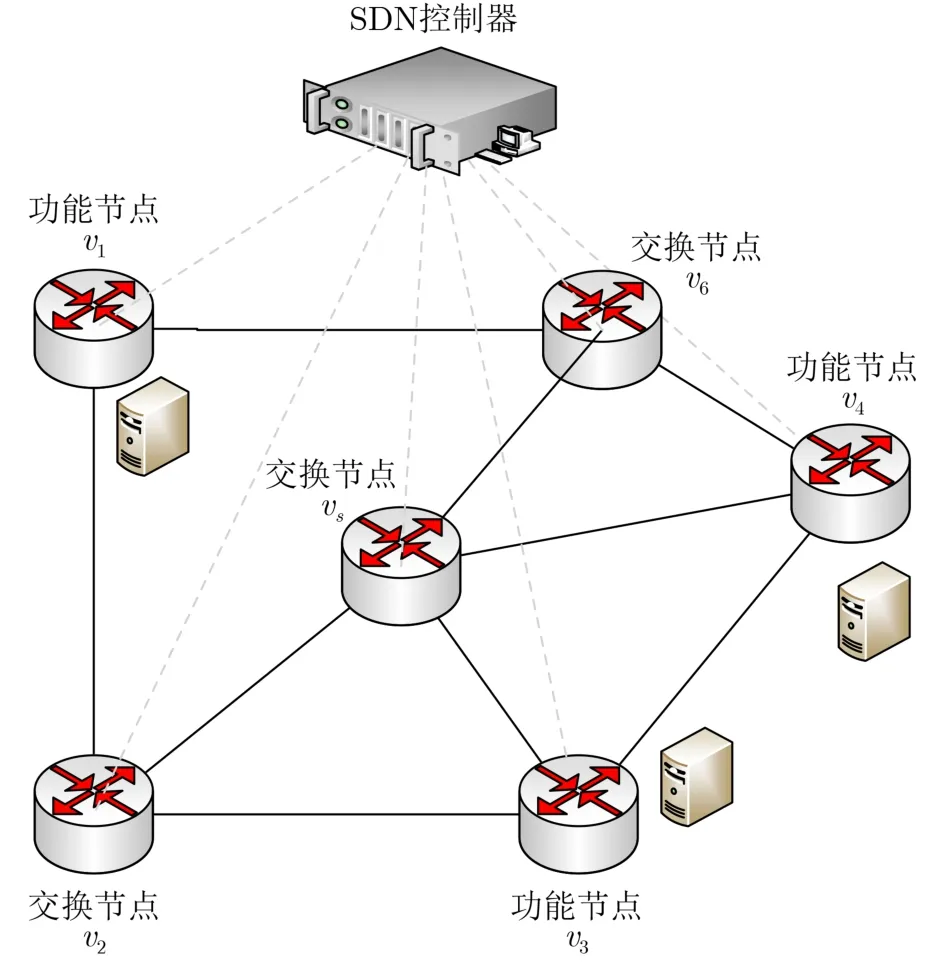
图2 SDN/NFV网络示例

图3 辅助边权图的构造
用MRi表示第i条具有SFC请求的多播流。其中i为整数。当路由MRi时,在节点u上,流表容量和剩余流表项的比率用和表示。用和表示节点u上的CPU容量和剩余比率。物理链路uv∈L的带宽容量、剩余带宽比率、传输时延分别用表示。用η(u)表示节点u的邻居节点集合。
2.2 虚拟网络功能
网络中可能的VNF类型用集合P表示。每种VNF类型p都有特定的部署成本、CPU需求、处理延迟,分别表示为Dp,。具有SFC要求的多播流请求MRi表示为
si和Di分别表示源节点和目的节点集,SCi={SCi(1),SCi(2),...,SCi(l)}表示MRi中每个源目的对必须升序遍历的VNF 集合,即SFC,l=|SCi|为SFC的长度,即MRi中每个源目的对需要经过的VNF实例总数。其中分别表示带宽需求、CPU需求、任意源目的对节点的最大容忍延迟和最大容忍抖动。
2.3 问题定义
在SDN/NFV中,延迟和抖动感知的多播服务功能树动态嵌入和路由问题(DJA-DSRP) 是为MRi寻找或构建一颗多播树SFT,满足各链路带宽,流表容量和CPU资源约束的同时,任何一条源目的节点对的端到端延迟和任意源目的对路径之间的最大时延抖动分别不大于给定的阈值和,且多播树的实现代价最小并可以自动保证网络的负载均衡。
2.4 问题刻画
2.4.1 物理网络转换
在实际网络中,各功能节点允许部署的VNF类型可能不同。为了方便地表达这个约束并降低问题的复杂性,将通过枚举的方式将原来的物理网络转换成一个扩展的伪网络。即根据一种类型的VNFp的CPU需求和功能节点的CPU容量,列举所有可以部署在每个功能节点Nf上的VNF。这些枚举的VNF称为伪VNF,它们的集合记作M。用m ∈M表示第m个VNF,用表示路由MRi时,第m个VNF上剩余CPU的比率。假如VNF m的类型为p时,定义函数τ(m)返回VNFm的类型
2.4.2 相对成本的定义
G中资源使用的一个重要特征是,边际成本会随着资源负载的增加而非线性膨胀。比如,与轻负载链路相比,重负载链路将花费更多的成本来处理传入的网络数据包[2]。为了描述这一特性且自动保证网络资源负载均衡,利用相对成本来刻画资源的使用成本并将链路带宽、交换节点和VNF上CPU资源的相对代价分别定义为
其中,ωbw,ωft和ωcpu均为大于1的常数,和分别为链路上带宽资源、交换节点上流表资源和VNF上CPU资源的剩余率。
2.4.3 ILP模型
确保在部署新的VNF实例m时不会违反CPU容量限制,则需满足
值得注意的是,每个源目的对必须由SFT中的一个SFC服务。由于多播的多路复用特性,流在到达目的节点前可能经过相同的VNF 实例。因此,使用式(12)来保证面向每个目的节点的流只访问SFT中同类型的VNF 1次。
此外,为确保MRi中任意源目的地对不违反最大时延抖动,需满足
综上,构建多播树的成本计算为
优化问题为
3 启发式优化算法
由于在网络中嵌入多播服务功能树是NP难的[13],为降低问题求解复杂度,将功能节点中的CPU资源消耗和转发节点中流表资源消耗转化为边上的权值进行表示。因此,本节将G转化为辅助边权图,然后再将转换为具有相对成本的VNF分裂多阶段边权图,最后基于利用启发式算法对问题进行求解,具体过程如下。
3.1 辅助边权图构建
3.2 多阶段边权图构建
3.3 启发式算法SFT-EA
基于以下思路设计服务功能树嵌入算法(Service Function Tree Embedding Algorithm, SFTEA)来解决式(24)。定义ΔT ∈R+为实际多播树Ti中源目的对路径的最大延迟,即
显然,
此外,如果uˆ∈Di,称uˆ为目的节点;如果uˆ∈/Di,但∈Ti,则称uˆ为中继节点。
显然,
根据式(27)、 式(28)可以得到
SFT-EA的主要思想是在ΔT的范围内从小到大取值,将每一个值作为当前构造的多播树中路径的时延上限。算法首先初始化一棵只包含多播源节点的多播树,然后逐个贪婪地加入中的节点。在节点加入的过程中,使用式(31)中定义的最佳链路选择函数来选择具有最小值的节点vˆ,并将该节点对应的边添加到当前多播树Ti中,然后,将vˆ作为当前节点,重复上述过程。如果找不到符合条件的节点vˆ,则回溯到当前节点的父节点并继续上述过程。最后,若在ΔT时延范围内找不到包含所有目的节点的多播树,则多播树构造失败,结束算法。
SFT-EA算法的伪代码如算法1:
定理1SFT-EA的时间复杂度为O(K|N|3)。
证明 执行SFT-EA时,枚举VNF的时间复杂度为O(|Vf|)。计算G′中链路和节点的相对成本的复杂度为O(|Vs|+|M|+|L|)。最坏情况下,所有类型的VNF实例都可以部署在每个功能节点上,将执行|Vf|+(l-1)|Vf|2+|Vf||Di|次SP算法为Gˆ生成链路,通常是Vf <<Di,因此执行SP算法的次数约为|Vf||Di|。G′上SP的复杂度为O(|L|+|V|log|V|),最多有2l|Vf|+1+Di个节点和(l-1)|Vf|2+l|Vf|+|Vf|+|Vf||Di|条链路,因此,建立Gˆ的时间复杂度是:O(|Vf||Di|(|(l-1)|Vf|2+l|Vf|+|Vf|+|Vf||Di|||+|(2l|Vf|+1+Di)|log2|(2l|Vf|+1+Di)|))=O(|Vf|2|Di|2+|Di|2|Vf|log2|Di|)。KruskalMST计算TLDT的复杂度为O(V2)=O((2l|Vf|+1+Di)2)=O(Di2),在算法中(第10~27行),当没有回溯时,时间复杂度为O(V2),当有回溯时,时间复杂度为O(V3)。用于确定是否访问了所有目的地节点的时间复杂度为O(Di)(第30~34行),在最坏情况下,SFT-EA将迭代K次,路径映射和资源更新的复杂度为O(1)。l的值很小。因此,SFT-EA的算法复杂度是O(K((|Vf|)+(|Vs|+|M|+|L|)+(|Vf|2|Di|2+|Di|2|Vf||log2|Di|)=O(K|Di|3)。在最坏的情况下,网络中除源节点外的所有节点都是多播目的节点,所以,SFT-EA的复杂度为O(K|N|3)。 证毕
图4中的红色粗线给出了具有3个目的节点和3个VNF顺序请求SFT的算法运行示例。

图4 在图 Gˆi 中解决DJA-DSPR
4 性能仿真分析
4.1 仿真设置
在Intel(R) Core(TM) i7-8550U CPU @ 1.80 GHz, 32.0 GB RAM的计算机上,用NetworkX3.1 Library[20]生成 Palmethone网络[21]对提出的算法进行评估。网络中,选择按节点度降序排序的30%的节点作为功能节点。考虑6种类型的VNFS[2]。Dp的取值为Uniform[0,10]×。每条链路的带宽(Gbps)为Uniform[1,10]。交换节点的流量表容量设置为800个单元[2],功能节点上的CPU容量设置为8000MIPS。(ms)设为Uniform[0.002,0.003]×,链路的延迟(ms)为Uniform[2,5][2]。wbw,wft,wcpu设置为2|V|[11]。
对于每条多播流,从目标网络中随机选择源节点和目的节点。为了评估多播规模的影响,将|D|/|V|值设置为0.3,(Mbps)为Uniform[10,120][13]。(MIPS)为Uniform[0,10] ×,为Uniform [50,100],(ms)为Uniform[30,50][2]。此外,将SFC的长度和SFT-EA的迭代最大次数K分别设置为4和10。取30次实验结果的平均值作为结果输出。

算法1 SFT-EA算法
4.2 对比算法
选用SDN/NFV网络架构中与本文研究方向紧密相关且最新的对比算法进行仿真对比。
(1)STB[22]:用传统经典的Steiner树算法构造一个覆盖多播所有目的节点的Steiner树,并找到将源节点连接到该树的最小代价路径。然后沿着该路径嵌入所需的SFC。STB只考虑链路和节点资源的成本;
(2)TSA[13]:通过考虑链路和节点资源成本得到SFC嵌入的初始方案,然后通过添加新的VNF实例逐步构建多播服务功能树(SFT),该算法不考虑流表成本及路径抖动约束;
(3)HAJPR[16]:根据网络中的关键NFV节点构造多径多播树,并且考虑物理资源和延迟约束,不考虑抖动约束,且没有解决VNF的动态嵌入。
4.3 性能比较
图5为平均流接受率的比较。SFT-EA的性能最好。当传入MRs的数量为5 000时,它接受的MR比HAJPR多约6%,比TSA高约13%,比STB高约17%。在SFT-EA中,实现了VNF的动态放置和负载均衡,提供了更好的性能。HAJPR考虑多路径路由,其性能优于TSA和STB。

图5 平均流接受率
图6展示了平均吞吐量的比较。当MR的数量为4 000时,SFT-EA的吞吐量比HAJPR高约5 Gbps,比TSA高约14 Gbps,比STB高约20 Gbps。性能和流接受率相符。
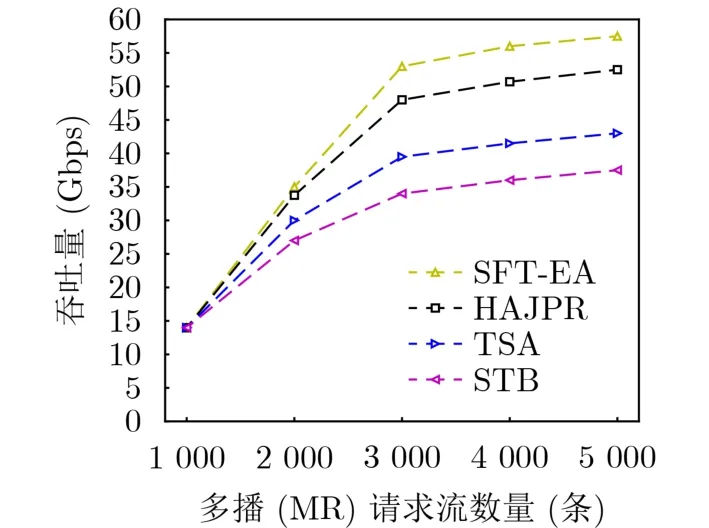
图6 平均吞吐量
图7展示了当4 000条MRs进入网络时链路平均剩余带宽的累积分布。从图中可看出,STB和TSA有大约5%和3%的瓶颈链路。对于SFT-EA,剩余带宽为6G和3G的链路分别约占71%和17%,因此,网络中约有54%的链路剩余带宽在3 Gbps到6 Gbps之间,对于HAJPR, TSA和STB,其剩余带宽在3 Gbps到6 Gbps之间的链路分别约为51%、32%和27%。显然,SFT-EA中使用指数函数来表示链路带宽成本,使其对链路资源的利用比其他算法更加均衡。

图7 剩余带宽累积分布
图8描述了4 000条MRs进入网络时平均剩余流表条目的累积分布。可以看到,TSA和STB有大约3%和5%的交换节点瓶颈。从图中剩余流表条目为400个单位看,STB大约有60%的交换机节点,其剩余流表条目小于400个单位,TSA为49%,HAJPR为35%,SFT-EA为30%, SFT-EA算法的性能优于其他算法。
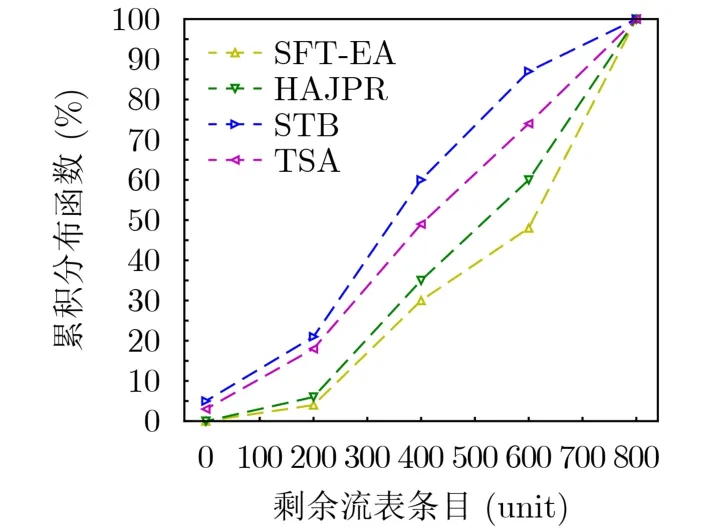
图8 剩余流表累积分布
图9显示了当4 000条MRs进入网络时,功能节点上平均剩余CPU的累积分布。由于STB和TSA不能保证功能节点上CPU的均衡使用,分别有约4%和2%的瓶颈节点。对于SFT-EA,剩余CPU为1 600 MIP的功能节点大约占10%,剩余CPU为4 000 MIPS的功能节点大约占85%,因此,约75%的功能节点的剩余CPU在1 600~4 000 MIPS,而HAJPR,TSA和STB在这区间的剩余CPU分别约为63%、49%和45%。SFT-EA比其他算法更均衡。
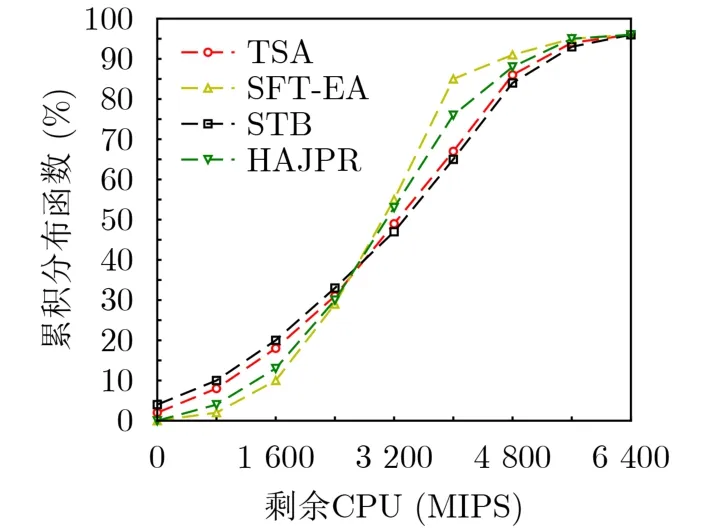
图9 剩余CPU的累积分布
图10展示了不同长度SFC下流接受率的变化。由于MR消耗的网络资源随着SFC长度的增加而增加,因此,流接受率随SFC长度的增加而降低。因STB和TSA无法平衡带宽、流表和CPU资源的利用率,因此它们的性能较差。虽然HAJPR不考虑资源平衡,但由于采用多径路由,且不考虑时延抖动约束,因此性能略高于SFT-EA。
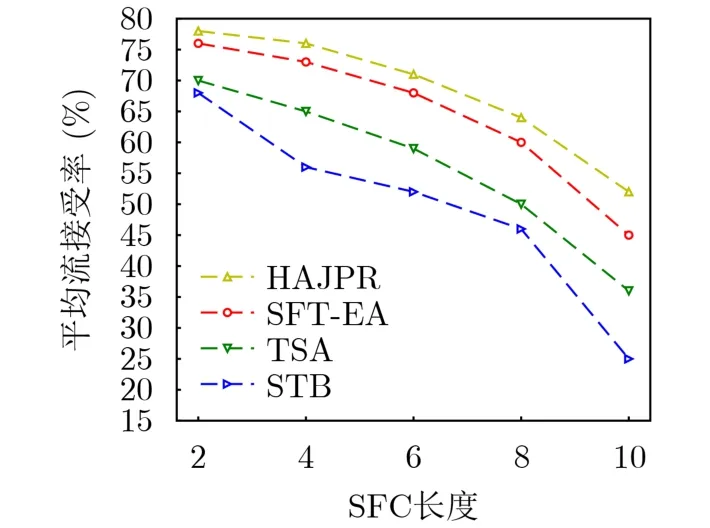
图10 平均流接受率随SFC长度的变化
图11显示了不同比例功能节点下网络的平均流接受率。功能节点的比例越高,可以动态部署VNF实例的节点就越多,MR可以选择冗余的VNF实例来满足其预定顺序,因此,这些算法的平均流接受率就越高。同理,虽然HAJPR不考虑资源平衡,但由于采用多径路由,且不考虑时延抖动约束,因此性能略高于SFT-EA。

图11 不同功能节点数下的平均流接受率
图12给出了多播目的节点数|D|∈[5,25]时,算法的运行时间比较,随着多播目的节点数的增加,4种算法的执行时间都会增加。因SFT-EA需要考虑抖动约束,算法运行时间约高于HAJPR。
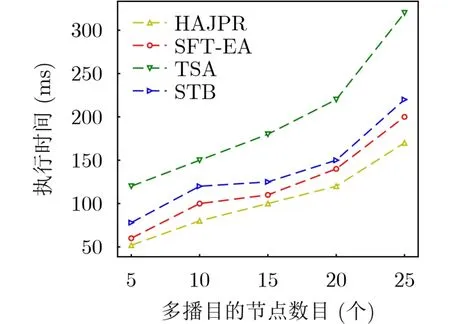
图12 不同目的节点数下算法的执行时间
5 结束语
本文基于SDN/NFV架构,研究了延迟和抖动感知的多播服务功能树嵌入和路由问题。首先将其建模为ILP模型。然后,利用节点分裂,将节点资源成本转换为边的思想,并设计了一个最优链路选择函数和基于辅助边权图的SFT嵌入算法SFT-EA来解决该问题。最后通过实验仿真对算法的性能进行了评价。结果表明,所提算法在吞吐量、流接受率和网络负载均衡方面比现有算法有更好的性能,为虚拟网络环境下具有延迟和抖动约束的多播流调度提供了有价值的参考。
猜你喜欢
计算机研究与发展(2022年12期)2022-12-15
计算机工程与应用(2022年5期)2022-04-09
计算机研究与发展(2022年4期)2022-04-06
中国惯性技术学报(2019年6期)2019-03-04
电子制作(2019年23期)2019-02-23
测控技术(2018年6期)2018-11-25
中央民族大学学报(自然科学版)(2017年2期)2017-06-11
系统工程与电子技术(2016年7期)2016-08-21
电测与仪表(2016年17期)2016-04-11
火控雷达技术(2016年3期)2016-02-06
