
基于多路混合注意力机制的水下图像增强网络
2024-01-27 06:57孙山林井佩光
电子与信息学报 2024年1期
李 云 孙山林 黄 晴 井佩光
①(广西财经学院大数据与人工智能学院 南宁 530003)
②(桂林电子科技大学信息与通信学院 桂林 541000)
③(桂林航天工业学院电子信息与自动化学院 桂林 541000)
④(天津大学电气自动化与信息工程学院 天津 300072)
1 引言
随着近年来海洋工程的快速发展,海洋技术也在向智能化方向迅速转变。自主水下航行器(Autonomous Underwater Vehicle, AUV)广泛应用于水下目标识别、目标检测、海洋探索等领域。然而,水下的复杂环境和光线在水中的散射和衰减影响,导致AUV获取图像存在色偏、低对比度和模糊等问题。基于水下图像目标检测等视觉任务较难实现。因此,研究如何增强水下图像具有重要意义,这可以提高水下任务的准确性。
波长频率对图像传输具有显著的影响和限制。高频率波长可实现高分辨率,但传输距离会减小;光学器件、环境和传输媒介等因素也会对波长频率产生影响[1]。目前,水下图像增强方法分为基于物理模型方法和基于非物理模型方法。基于非物理模型方法不考虑水下成像物理模型,仅通过调整图像的局部特征和像素值来提高其视觉质量,如:自适应直方图均衡化[2]、限制对比度直方图均衡化[3]、基于融合的方法[4]、灰色世界方法[5]、小波变换[6]等。上述方法在复杂多变的水下环境中没有考虑水下成像的物理模型,可能会引入其他色偏、伪影或过度曝光等问题。基于物理模型的方法是通过水下成像的先验知识估算出水下成像的物理模型参数[7],并利用反演模型来恢复清晰的水下图像,如:雾线先验[8]、衰减曲线先验[9]、一般暗信道先验[10]等。这些基于物理模型的方法虽然实现了一定程度的图像恢复,但过度依赖水下场景先验知识,当先验不适用时,对图像恢复效果较差,泛化性不强,具有一定的局限性。
随着深度神经网络的强大学习能力的发展,深度神经网络在图像增强中得到广泛应用,可用于非线性系统的复杂映射关系,能够自动地从数据中学习特征,避免了传统方法手工特征提取的繁琐和不准确性。Li等人[11]提出了一种名为Ucolor的基于介质传输引导的多色空间嵌入的水下图像增强网络,它利用多颜色空间嵌入以及基于物理模型和学习方法的优点,解决水下图像的颜色偏差和低对比度问题。李钰等人[12]提出一种基于生成对抗网络的水下图像增强方法,通过多尺度生成器实现清晰的水下图像,此方法能够有效地修正色偏、对比度,保护细节信息不丢失。Marques等人[13]提出了一种名为低光水下图像增强器(Low Light Under Water image Enhancer, L2UWE)的框架,用于低光水下图像的高效增强。该框架基于本地对比度和多尺度融合技术,能够有效地提高水下图像的清晰度和亮度。Li等人[14]构建了水下图像增强基准(Underwater Image Enhancement Benchmark, UIEB)并提出了WaterNet水下图像增强网络,该方法能够很好地恢复色偏和图像细节。Sun等人[15]提出基于Pix2Pix生成对抗网络,并引入了深度残差学习和多层感知机等技术以提高模型性能和泛化能力,能够有效去除雾化效应、校正色偏和增加图像细节。方明等人[16]提出基于注意力的多尺度水下图像增强网络,引入注意力机制并设计多尺度特征提取模块,较好地恢复图像颜色和纹理信息。米泽田等人[17]提出一种新颖通用的多尺度级联网络,有效解决特征提取有限的问题。Zhuang等人[18]提出了一种基于超拉普拉斯反射先验的水下图像增强方法,通过建立超拉普拉斯反射先验模型,利用反射成分的统计特征对图像进行约束和优化,以实现图像的增强和去噪。Zhuang等人[19]提出了一种基于贝叶斯Retinex模型的水下图像增强方法,通过建立物理模型并利用局部统计特征对图像进行优化和约束,实现水下图像的增强和去噪。上述方法虽然有效恢复了色偏、低对比度、低照度,但是忽略了水下图像对比度、亮度和颜色之间的关系,没有自适应平衡水下图像的对比度、亮度和颜色。
针对上述水下图像的问题,本文提出一种基于多路混合注意力机制的水下图像增强网络,自适应地平衡水下图像对比度、亮度和颜色之间的关系,在多个数据集上对所提出的方法进行了评估分析。与传统的水下图像增强方法对比,实验结果表明,本文所提方法在图像的对比度、亮度和颜色方面恢复得更好。本文的主要贡献如下:
(1)提出多路特征提取模块。通过对直方图均衡、伽马矫正和白平衡3种图像特征提取,分别获得不同尺度的对比度、亮度和颜色的特征信息,为混合注意力学习模块提供不同深度和尺度的特征。
(2)设计了多支路特征融合模块。针对水下图像对比度、亮度和颜色不佳的问题,融合直方图均衡、伽马矫正和白平衡3种图像特征,增强融合特征的互补性。
(3)构建混合注意力学习模块。分别从通道维度和像素维度两个维度出发,学习直方图均衡、伽马矫正和白平衡特征与融合互补性特征之间的相关性矩阵,计算局部和全局特征的依赖性,实现具有图像增强的导向性输出,恢复增强图像的图像细节、明亮度和色偏。
2 基于多路混合注意力机制的水下图像增强网络
该网络结构如图1所示,由4部分组成:基础部分、多支路特征融合模块、多路特征提取模块、混合注意力学习模块。基础部分,对输入图像进行直方图均衡、伽马校正和白平衡算法的处理,这3种算法用于调整图像的对比度、亮度和颜色。多支路特征融合模块,由8个CR单元(卷积层+ReLU层)和1个跳跃连接组成,通过将原图像和3种预处理图像拼接后送入到多支路特征融合模块进行图像特征的融合,跳跃连接从第4个CR单元连接到最终的输出。多路特征提取模块,由3个Inception[20]模块并行组成,将原图像和3个预处理图像分别拼接后进行图像对比度、亮度和颜色的特征提取。在多支路特征融合模块和多路特征提取模块后加入3个混合注意力学习模块,对提取的特征和融合特征在通道维度和像素维度计算出对比度、亮度和颜色的相关性矩阵,得到的矩阵作用于融合特征,最终与跳跃连接相加得到增强图像。
2.1 基础部分
针对水下图像色偏、对比度低和画面模糊等问题,本文方法在将图像送入网络之前进行了直方图均衡、伽马矫正和白平衡。对原始图像IRAW进行直方图均衡、伽马校正和白平衡,生成3个输出IHE, IGC, IWB。其中,白平衡算法用于图像颜色的矫正,直方图均衡用于提高图像的对比度,而伽马校正算法则用于平滑扩展图像暗调的细节。
白平衡算法采用文献[4]中提出的白平衡算法,论文中对灰度世界算法进行了改进,将灰度世界算法中的照度通过从场景的平均值计算得出的µI值来估计,并通过参数λ进行调整,如式(1)所示
其中,µref为光源颜色的平均值,λ=0.2。
直方图均衡算法采用对比度受限自适应直方图均衡算法,通过分块的方式对图像进行直方图均衡,引入一个限制系数限制直方图的高度来限制对比度的增强大小,防止图像对比度增强过度以及噪声的放大。
(1) 将图像等分为M块,计算该分块区域图像的灰度阈值C
其中,Mavg为像素均值,xpix和ypix分别为该分块区域的x和y上的像素个数,Mg为该分块的灰度级数量。α为限制系数,α=0.01,C为灰度阈值。
(2) 通过灰度阈值C来限制每个分块区域,将超出阈值的像素值平均分配
其中,Spix为超过阈值的像素总数,Mpix为每一级的像素个数。
(3) 对每个分块区域进行直方图均衡化,通过双线性插值运算处理避免分块区域产生块状效应,最后对图像进行中值滤波使图像变得平滑。
人眼感知外界光源的感光值与外界输入的光强并非线性关系,而近似呈指数关系。因此,使用伽马校正可以使图像适应人眼的特性。伽马校正对图像的灰度值进行非线性操作,使输出图像的灰度与输入灰度呈指数关系
其中,gamma为校正系数,gamma=0.7。
2.2 多支路特征融合模块
为增强直方图均衡、伽马矫正和白平衡方法的互补性,本文设计了多支路特征融合模块,将原图和3种图像预处理特征进行融合。该网络由8个CR单元和1个跳跃连接组成,其中使用了不同大小、不同输出通道的卷积进行特征提取。具体而言,8个CR单元的卷积核大小分别为7×7, 5×5,3×3, 1×1, 7×7, 5×5, 3×3和9×9,如图1(a)所示。大尺寸的卷积可以更好地进行全局特征提取。输入图像是3种预处理图像IHE, IGC, IWB与原始图像IRAW的拼接,通过拼接图像送入网络进行学习,以融合图像的对比度、亮度和颜色特征。在第4个CR单元中,连接一个1×1的卷积进行通道降维,并跳跃连接到最终的输出结果上。最后,在通道维度将输出分离为3个输出
其中, ©为通道维度拼接,Convi为多支路特征融合模块第i层的卷积操作,δr为ReLU激活函数,Conv1×1为1×1的卷积操作,Skip为跳跃连接的输出。
2.3 多路特征提取模块
多路特征提取模块由3个GoogLeNet中的Inception模块并行组成,Inception模块如图1(b)所示。本文将原图IRAW和3种处理图像IHE,IGC,IWB分别拼接后,输入到这3个模块中进行特征提取。每个模块内有4个不同卷积大小的分支,利用不同分支对输入图像提取不同尺度的对比度、颜色和亮度特征信息,最后将不同尺度的特征信息融合。多个分支增加了网络的宽度;同时采用小卷积层代替大卷积层,增加了网络的深度,且不会影响卷积表达能力。通过多个具有不同感受野的卷积分支进行特征提取,增加了空间特征的丰富性和特征的多样性。这4个分支的结构分别为:1×1卷积、1×1和5×5的卷积、1×1和两个3×3的卷积、1×1的卷积和平均池化。
将3种预处理图像与原图IRAW沿通道维度进行拼接,Iin为任一IHE, IGC, IWB,得到输入Xin
将Xin送入模块的4个分支进行特征提取,得到4个分支的输出Y1,Y2,Y3,Y4
其中,Convi×i为i×i大小的卷积操作,AvgPool为平均池化操作。
将Y1,Y2,Y3,Y4沿通道维度进行拼接,通过一个1×1的卷积核进行通道降维
2.4 混合注意力学习模块
近几年来,注意力机制在图像处理中得到了广泛的关注。Bahdanau等人[21]首次将注意力机制应用于自然语言处理领域。目前,注意力机制不仅在自然语言处理中被广泛使用,而且在图像处理中也得到了广泛的应用。该机制的核心思想是使网络更关注需要关注的地方。通过利用图像中不同区域之间的关联性,计算出区域之间的全局依赖关系。本文在网络中引入了混合注意力学习模块,该模块对提取的3个特征和3个融合特征的通道维度和像素维度分别计算对比度、亮度和颜色的相关性矩阵,计算得到的矩阵作用于融合特征,如图1(c)所示。
在通道维度对多路特征提取模块提取的特征和多支路特征融合模块的融合特征进行通道维度的相关性矩阵计算,得到的矩阵作用于融合特征。通过计算每个通道在不同空间位置上的重要性来加权每个通道的输出。提取的特征和融合特征经过1×1的卷积生成输入
其中,Cin为多路特征提取模块提取的特征,Fin为多支路特征融合模块的融合特征,Qc,Kc,Vc⊂RC×H×W。
通道维度的自注意力学习可以定义为
其中,δsg,δsm为Sigmoid和Softmax激活函数,LN为LayerNorm操作。
接下来,对通道维度的自注意力输出进行像素维度的自注意力学习。让每个像素点关注自己的重要性,并得到每个像素点的权重,以加权融合特征的每个像素点。像素自注意力能够捕捉不同空间位置之间的相关性。将通道自注意力的输出经过1×1的卷积生成输入
其中,Ac为通道自注意力的输出,Ac⊂RC×H×W。
像素维度的自注意力学习可以定义为
其中,GlobalPool为全局池化操作。
2.5 损失函数
在网络训练中,需要使用损失函数来监督网络的学习过程。损失函数的作用是描述网络预测值和真实值之间的差距大小,并提供一个标准来帮助网络进行训练,使得模型朝着收敛的方向前进。在本文的网络中,使用了两个损失函数来监督网络的学习过程。
平均绝对误差(Mean Absolute Error, MAE),是指预测值与真实值之间差值的绝对值的平均值,表示了预测值的平均偏移程度。MAE损失函数不会放大误差值,其损失值相对平缓,对异常像素具有更好的鲁棒性。MAE损失函数的公式定义如式(14)所示
其中,O(x)和G(x)为本文网络增强图像和参考图像,H, W, C为图像的高度、宽度和通道数。
结构相似性指标(Structural Similarity Index Measure, SSIM)[22]是一种用于衡量两张图片相似程度的指标,可以评估图像在亮度、对比度和结构等方面的相似度。当SSIM接近1时,说明两张图片在结构和纹理上更接近。SSIM损失函数的公式定义如式(15)所示
其中,µO和σO表示O(x)的均值和标准差,µG和σG表示G(x)的均值和标准差,σOG表示O(x)和G(x)的协方差,C1,C2表示正则化参数。
总损失函数可以定义为上述MAE损失函数和SSIM损失函数的线性组合,具体形式如式(16)所示
3 实验
3.1 实验设置
本文选取3类公开的水下数据集进行网络的训练和测试。实验过程中,在Linux18.04系统上使用PyTorch框架完成了训练和测试,该系统的CPU为i9-11900K,内存为64 GB,显卡为NVIDIA Ge-Force RTX3090。在训练过程中,对输入的水下图像进行了统一大小和随机翻转处理。其中,Batchsize为4,40个epoch,优化器采用Adam算法,初始学习率为0.001。
3.2 水下图像数据集
水下图像增强基准[14](Underwater Image Enhancement Benchmark, UIEB)包含了各种水下场景中不同特征的图像退化情况,例如光线不足、模糊等。该数据集共有950个真实世界的水下图像,其中有890张图像具有相应的参考图像,而剩下的60张无法获得满意的参考图像,则被用作数据集的测试集。在这890张具有参考图像的水下图像中,参考图像是通过50名志愿者在12种增强算法中选出质量最好的图片。
增强水下视觉感知[23](Enhancement of Underwater Visual Perception, EUVP)包含了大量的成对和非成对的水下图像。数据集使用了7种不同的摄像头进行水下拍摄,这些图像是在海洋探测和人机合作中收集的,在不同能见度的条件下和不同地点进行拍摄的。此外,数据集中也包含了一些从公开的YouTube视频中提取的图像,这些图像经过筛选包含了不同场景、不同水体类型、不同照明条件等。EUVP数据集分为3个子集:合成的水下暗场景图像、使用ImageNet生成的退化水下图像和水下真实场景图像。
大规模水下图像[24](Large Scale Underwater Image, LSUI)包含了4 279张真实水下图像,每张图像都有相应的高质量参考图像、语义分割图和介质传输图,覆盖了更加多样化的水下场景,包括不同的光照条件、水体类型和目标类别。
本文选用UIEB, EUVP的两个子集和LSUI。其中,ImageNet生成的退化水下图像用EUVP1表示,水下真实场景图像用EUVP2表示,数据集的训练集和测试集按照9:1进行划分,划分情况如表1所示。

表1 4种不同水下数据集的划分
3.3 评价指标
为了评估本文提出网络的性能,本文采用两类评价指标:有参考评价指标和无参考评价指标。其中,有参考指标需要使用参考图像进行评估,而无参考指标则不需要使用参考图像。下面将介绍这两类评价指标。
3.3.1 有参考评价指标
本文使用了均方误差(Mean Squared Error,MSE)、峰值信噪比(Peak Signal to Noise Ratio,PSNR)和结构相似性SSIM这3个指标来衡量增强图像与参考图像之间的差异程度。MSE得分越低,PSNR得分越高,表明增强图像在内容上与参考图像的相似度更高。而SSIM得分越高,则表明增强图像在结构和纹理上与参考图像的相似度更高。
3.3.2 无参考评价指标
水下色彩图像质量评价指标(Underwater Colour Image Quality Evaluation, UCIQE)[25],采用了色度、饱和度和对比度的线性组合进行定量评估,主要应用于量化水下工程和监测图像中的不均匀颜色投射、模糊和低对比度等问题。UCIQE得分越高,表明结果在色度、饱和度和对比度之间的平衡越好。UCIQE的公式定义如式(17)所示
其中,c1=0.468 0,c2=0.274 5,c3=0.257 6,σc,σconl,σs分别为色度标准差、亮度对比和饱和度的平均值。
3.4 消融实验
为了验证网络的有效性和收敛性,本文在UIEB数据集上进行了消融实验,并选择了有参考评价指标作为评价指标。在实验中,把网络各组成部分分为:A:多支路特征融合模块;B:白平衡的多路特征提取模块和混合注意力学习模块;C:直方图均衡的多路特征提取模块和混合注意力学习模块;D:伽马矫正的多路特征提取模块和混合注意力学习模块;E:跳跃连接。评价指标数值结果如表2所示,加粗表示最优值。每个消融网络和本文提出方法在训练过程的损失变化如图2所示。可以看出,完整网络在训练过程中始终具有最低的损失和最佳的收敛性。

表2 网络结构消融实验数值结果

图2 消融实验训练损失曲线图
3.5 对比实验
3.5.1 定性分析
为了进一步验证本文所提方法在增强各种水下场景的水下图像方面的有效性,本文选择了UIEB数据集、EUVP数据集和LSUI数据集,并针对不同的色偏、模糊遮挡和低照度情况,使用多种方法以及本文提出的方法进行了定性评价和分析。
(1)UIEB数据集定性分析,在UIEB数据集上,不同方法和本文提出方法的增强图像的视觉效果对比如图3所示。其中,Fusion[4], Dehaze[26]和UResnet[27]方法在提高图像明亮度方面表现较好,但在减少色偏方面的效果较差,甚至可能引入其他色偏。Shallow-UWnet[28]和WaterNet[14]方法可以有效去除色偏,但对于去除模糊遮挡的效果并不理想。HLRP[18]和BRUE[19]方法可以有效地去除色偏和模糊遮挡,但是对于图像恢复的明亮度和细节效果较差。GDCP[10]方法不仅没有去除色偏,还可能引入其他色偏。相比之下,本文所提方法在去除色偏、模糊遮挡和提高图像明亮度3个方面都获得了不错的效果。

图3 UIEB数据集上不同方法生成的水下图像视觉对比
(2)EUVP数据集定性分析,在EUVP1和EUVP2数据集上,不同方法和本文提出方法的增强图像的视觉效果对比分别如图4和图5所示。其中,GDCP和Dehaze方法并没有很有效地去除色偏和模糊遮挡,并且存在增强过度导致的曝光现象。Fusion方法能够有效地去除模糊遮挡和增强图像细节,但对于去除色偏的效果并不明显。HLRP和BRUE方法能够有效地去除模糊遮挡和色偏,但是对于图像恢复的明亮度和细节效果较差。Shallow-UWnet,WaterNet和UResnet方法都能够很好地去除色偏并适度提高图像明亮度,但Shallow-UWnet并不能很有效地去除模糊遮挡。相比之下,本文所提方法能够有效地去除色偏和模糊遮挡,并提高图像的明亮度,同时增强了图像的细节。

图4 EUVP1数据集上不同方法生成的水下图像视觉对比

图5 EUVP2数据集上不同方法生成的水下图像视觉对比
(3)LSUI数据集定性分析,在LSUI数据集上,不同方法和本文方法的增强图像的视觉效果对比如图6所示。Fusion, GDCP和Dehaze方法在提高图像明亮度方面表现较好,但是没有很好地去除色偏和模糊遮挡。HLRP和BRUE方法在可以有效地去除色偏和模糊遮挡,但是存在增强过度导致的曝光现象。Shallow-UWnet和UResnet方法能够有效地去除色偏,但是对于去除模糊遮挡和提高图像明亮度效果较差。WaterNet方法在去除色偏、模糊遮挡和提高图像明亮度效果较好,但是在增强图像细节方面没有本文提出的方法效果好。相比之下,本文提出的方法在去除色偏、模糊遮挡和提高图像明亮度3个方面都获得了不错的效果。

图6 LSUI数据集上不同方法生成的水下图像视觉对比
3.5.2 定量分析
为了验证本文提出的方法的有效性,本文在UIEB, EUVP和LSUI数据集上使用了有参考评价指标和无参考评价指标来与其他方法进行定量分析。
(1)UIEB数据集定量分析,在UIEB数据集上,本文方法与不同的方法进行了评价指标数值的比较,具体结果如表3所示,加粗表示最优值。结果表明,本文提出的方法在UIEB数据集上,MSE和SSIM评价指标排名第1。从表3可以看出,Fusion方法的PSNR指标和UCIQE指标最好,但是PSNR指标是基于像素误差评价的,人眼对于这种误差的敏感度并不是绝对的。图3的视觉对比显示,使用Fusion方法增强的水下图像引入了不同程度的色偏,虽然Fusion方法的PSNR数值较高,但是其视觉效果不如本文方法好。

表3 UIEB数据集上不同方法的定量评价
从表3可以看出,Fusion, GDCP和Dehaze方法在UCIQE指标上都获得了不错的数值。根据式(17),UCIQE指标是色度、饱和度和对比度的线性组合。但从图3可以看到,这3种方法得到的增强图像在色度、饱和度和对比度方面过度增强,在解决去除色偏、模糊遮挡等问题方面效果并不好。UCIQE指标在某些情况下可能存在局限性,与主观视觉存在一定的差距。综合来看,本文方法取得了较好的结果。
(2)EUVP数据集定量分析,从表4和表5可以看出,本文方法在EUVP数据集的两个子集上SSIM指标都获得了最高的数值,说明本文方法生成的增强图像在结构相似性方面与参考图像更为接近。

表4 EUVP1数据集上不同方法的定量评价
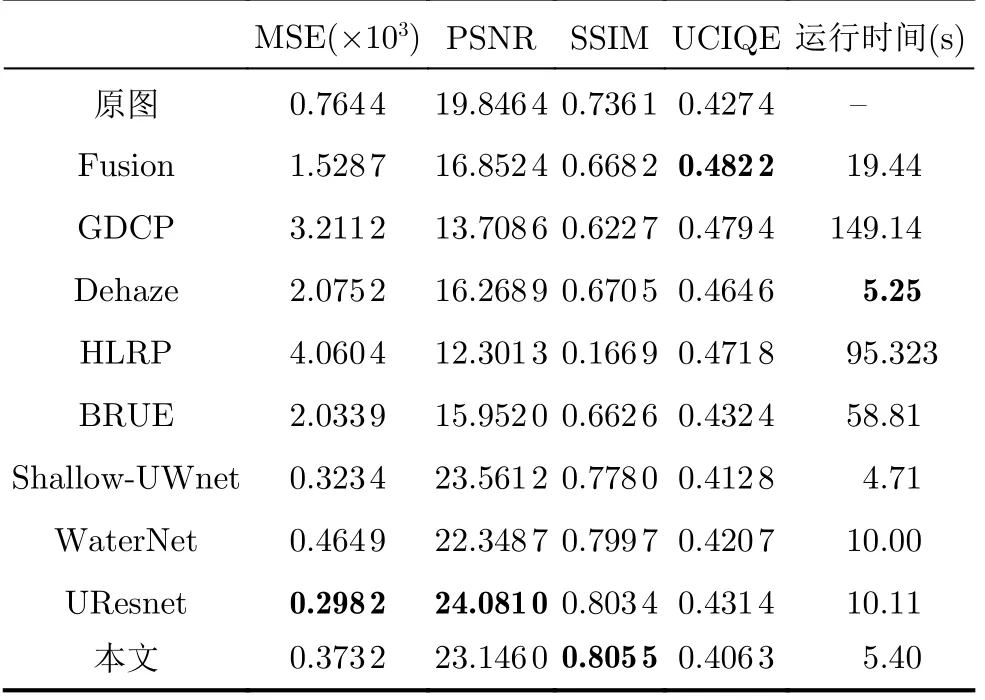
表5 EUVP2数据集上不同方法的定量评价
在EUVP1数据集上UResnet方法在MSE和PSNR指标上略高于本文方法,但从图4可以看出,UResnet去除模糊遮挡的效果并不如本文方法好。在UCIQE指标上,GDCP方法获得了最高的数值,但从图4可以看出,该方法并没有很好地去除色偏,并且对比度过高导致图像失真和细节缺失。
在EUVP2数据集上Shallow-UWnet和UResnet方法虽然在MSE和PSNR指标上略高于本文方法,但从图5可以看出,它们并没有像本文方法那样在图像细节恢复方面表现得好。此外,UResnet方法生成的增强图还存在一定的色偏问题。
(3)LSUI数据集定量分析,从表6可以看出,本文方法在LSUI数据集上SSIM获得了最高的数值,说明本文方法生成的增强图像在结构相似性方面与参考图像更为接近。从表6可以看出,WaterNet在MSE和PSNR指标上略高于本文方法,但从图6中可以看出WaterNet方法在去除色偏方面和图像细节上并不如本文方法好。

表6 LSUI数据集上不同方法的定量评价
3.6 运行时间
本文对不同方法在UIEB数据集上的运行时间和FPS进行了测试。根据表7的数据,本文方法的FPS并不高,但是生成的图像很好地解决了水下图像出现的问题。与其他方法相比,在速度和量化指标方面仍具有一定的竞争力。

表7 不同方法的运行时间和FPS
4 结束语
本文设计了一个基于多路混合注意力机制的水下图像增强网络。本网络通过特征融合模块融合对比度、亮度和颜色特征,增强其互补性;通过混合注意力模块自主学习相关性矩阵。为了达到上述目的,本网络引入了多路特征提取模块进行多路特征提取,增加了网络的宽度、深度以及特征多样性。同时,在网络中构建了混合注意力学习模块,从通道维度和像素维度对提取的特征和融合特征计算出相关性矩阵,得到的矩阵作用于融合特征。实验结果表明,与其他方法相比,本文方法能够很好地恢复色偏、模糊遮挡和提高图像明亮度,并具有较好的泛化性。但是,本文方法的时间复杂度略高,很难满足实时处理的要求,需要进一步改进方法。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
数学年刊A辑(中文版)(2020年2期)2020-07-25
数学物理学报(2019年6期)2020-01-13
电子制作(2018年19期)2018-11-14
数学物理学报(2017年5期)2017-11-23
传媒评论(2017年3期)2017-06-13
自动化学报(2017年11期)2017-04-04
第二课堂(课外活动版)(2016年2期)2016-10-21
噪声与振动控制(2015年4期)2015-01-01
新课程学习·中(2013年3期)2013-06-14
