
攀枝花旅游评论及情感分析
2024-01-27 12:37:51任湘等
现代信息科技 2023年24期
任湘 等

杨曦 张俊坤 陈尧
摘 要:随着互联网进入“大数据”时代,为了更好地服务社会,大数据将朝向智能化、个性化、商业化进行发展。随着网络用户的爆发性增长,在交流平台提供了大量文字内容数据源,实时性评论反映了用户对于旅游项目各方面的态度,通过分析用户的评价获取用户需求,根据需求提供更加优质的服务、高效的处理流程,成为分析旅游项目的重要方式。鉴于用户情感观点表达形式极具开放性,文章通过机器学习实现对评论的情感分析,从而根据情感分析研究结果对攀枝花旅游业发展提出科学合理意见。
关键词:情感分析;机器学习;爬虫技术
中图分类号:TP181 文献标识码:A 文章编号:2096-4706(2023)24-0131-04
Panzhihua Tourism Comments and Emotional Analysis
REN Xiang, YANG Xi, ZHANG Junkun, CHEN Yao
(School of Mathematics and Computers (Big Data Science), Panzhihua University, Panzhihua 617000, China)
Abstract: As the Internet enters the era of “Big Data”, in order to better serve the society, Big Data will develop towards intellectualization, personalization and commercialization. With the explosive growth of network users, a large number of text content data sources have been provided on the communication platform. Real-time comments reflect users' attitudes towards various aspects of tourism projects. Obtaining user needs through analyzing user evaluation, providing more high-quality services and efficient processing process according to needs, have become an important way to analyze tourism projects. In view of the openness of the expression form of users' emotional views, this paper realizes the emotional analysis of comments through Machine Learning, and puts forward scientific and reasonable opinions on the development of Panzhihua tourism industry according to the research results of emotional analysis.
Keywords: emotional analysis; Machine Learning; crawler technology
0 引 言
自媒體的时代,消息传播异常迅猛,用户热衷于使用自媒体分享自己的感官体验,网络舆论导向对于旅游、餐饮、航空等领域愈发重要。由于网络评论的时效性强,若不实时掌控用户舆论导向,及时对用户诉求进行响应和解决,将对旅游项目的形象形成负面影响,影响客流量造成经济损失。
与此同时,网络评论内容以及网络评分高低也是影响用户舆论导向的重中之重,网络评论是分享用户体验的网络文学载体,在实际情况中,用户表达的多样性以及隐性表达使得获取反馈信息并不理想。而目前平台上的网络评分,是根据各方面服务进行星级选择,从而形成“好”“中”“差”这三类别评价,而实际生活中,用户可能因为某些原因进行好评,但实际文字评论中表现了负面情绪,或者提出了优化建议,若仅仅片面地通过三个类别判断用户满意度,将无法发现问题并进行改善。
根据上述信息可知,如果只从好评和高分从而得出用户满意度结论,不深度挖掘用户评价中反馈的信息,往往达不到预期的效果,用户真正诉求得不到相应处理。因此,本文在获取攀枝花旅游评论数据的基础上,设定情感倾向词,根据语义使用线性代数和统计分析的方法,建立基于事理图谱文本的情感倾向分析,从而对用户评论进行情感倾向挖掘,帮助旅游项目发现旅游路线、景区交通、员工服务、酒店设施等存在的不足之处,及时采取响应的补救措施,改善景区各方面服务,提高用户满意度,完善景区建设,从而引导积极的舆论导向,产生更大的经济效益。
1 处理流程
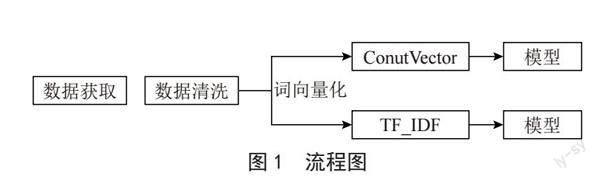
本文通过爬虫进行数据获取,使用pandas库进行初步的数据处理,根据需要选取不同的词向量化方式ConutVector或TF_IDF后传入模型进行情感分析。流程图如图1所示。
2 数据来源
数据来源为使用Python爬取携程旅行网上攀枝花旅游景点的评论数据,由于攀枝花旅游景点数量较多,因此使用seleium自动化工具对数据进行爬取,防止IP地址被封禁。其关键函数实现如下:
def open_browser():
chrome = webdriver.Chrome()
url ="https://you.ctrip.com/sight/pzhu/s0-p1.html"
chrome.maximize_window()
chrome.get(url)
time.sleep(1)
return chrome
def clicks(chrome):
element_A = chrome.find_element_by_xpath()
webdriver.ActionChains(chrome).move_to_element(element_A).perform()
chrome.find_element_by_xpath().click()
time.sleep(1)
# 切换窗口
windows = chrome.window_handles
chrome.switch_to.window(windows[-1])
# 下拉窗口及点击
element_new = chrome.find_element_by_xpath()
webdriver.ActionChains(chrome).move_to_element(element_new).perform()
# 选择排序方式
chrome.find_element_by_xpath().click()
time.sleep(0.5)
3 数据处理
3.1 数据预处理
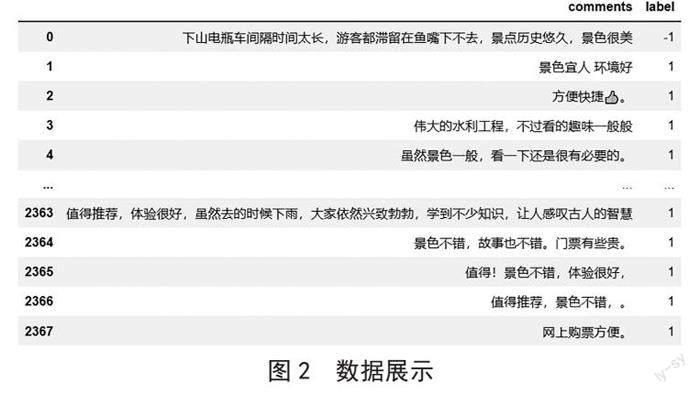
首先我们发现原始数据中顾客评分采用0~5分制,為便利后续处理,根据原始评分生成一个新的对应标签。新标签将评分低于3分标为-1,表示游客对该景点评价较低;3分标为0,表示游客对该景点评价较为一般;而高于3分标为1,表示游客对该景点较为满意。处理后的部分数据如图2所示。
部分实现代码如下:
# 生成标签
label = []
for grade in science["grades"]:
if int(grade[0]) < 3:
label.append(-1)
elif int(grade[0]) == 3:
label.append(0)
else:
label.append(1)
science["label"] = label
science = science[["comments", "label"]]
3.2 分词处理
由于中文字符间边界不明显,因此需要对待评论内容进行分词处理。这里使用Python中jieba中文分词组件。jieba分词运用到了数据结构里的trie(前缀树)对词语进行高效的分类,便于查找,最后将生成所给句子中汉字所有可能成词情况所构成的有向无环图,主要采用了动态规划来找出词频最大切分组合;对于未登录词,采用了基于汉字成词能力的HMM模型,采用Viterbi算法进行计算,将词语分为开始、中间、结束和单独成词四种分类来自动分词。jieba共有三种分词模式:精确模式、全模式、搜索引擎模式。考虑到游客表达方式的多样性以及重复性,为了提高分词的准确性以及解决语句中的歧义,并且不存在冗余单词,本文采用jieba分词中精准模式,将语句用最精确的方式分开,相关函数为jieba.cut(),并返回一个可迭代的数据类型。部分内容如图3所示。
# 分词及文本处理
for line in science["comments"]:
#文本中的中文符号和英文符号
line = re.findall(r"[\u4e00-\u9fa5]", line)
line = "".join(line)
# 精准模式分词
line = jieba.cut(line)
line = " ".join(line)
comment.append(line)
science["comments"] = comment
science.to_csv("comments/science_jieba.csv")
3.3 特征提取
特征提取是机器学习的重要步骤,其目的是在最小维数特征空间中异类模式点相距较远(类间距离较大),而同类模式点相距较近(类内距离较小),从而获得一组“少而精”且分类错误概率小的分类待征。本文尝试了两种算法进行特征提取,分别通过使用TF-IDF和CountVectorizer对分词后的中文语句做向量化处理。TF-IDF与一个词语在文章中的出现次数成正比,与该词在整个文章中的出现次数成反比,并且词语对文章的重要性越高,它的TF-IDF值就越大。TF-IDF的计算分为三步:
1)计算词频:
2)计算文档逆频率:
3)计算TF-IDF:
为了保证模型的预测和良好的泛化能力,对相应参数进行设定。并且使用CountVectorizer时,追加对参数token_pattern进行一定设定,去除了干扰数据,提高了数据的精准性。
3.3.1 使用TF-IDF进行特征提取
部分代码如下:
#开始使用TF-IDF进行特征的提取,对分词后的中文语句做向量化。
TF_Vec=TfidfVectorizer(max_df=0.8,
min_df = 3,
stop_words=frozenset(stopwords)
)
#拟合数据,将数据准转为标准形式,一般使用在训练集中
train_x_tfvec=TF_Vec.fit_transform(train_x)
#通过中心化和缩放实现标准化,一般使用在测试集中
test_x_tfvec=TF_Vec.transform(test_x)
3.3.2 使用CountVectorizer()进行特征提取
部分代码如下:
#开始使用CountVectorizer()进行特征的提取。它依据词语出现频率转化向量。并且加入了去除停用詞
CT_Vec=CountVectorizer(max_df=0.8,#去除超过这一比例的文档中出现的关键词(过于平凡)。
min_df = 3,#去除低于这一数量的文档中出现的关键词(过于独特)。
token_pattern=u'(?u)\\b[^\\d\\W]\\w+\\b', #使用正则表达式,去除想去除的内容
stop_words=frozenset(stopwords))#加入停用词)
#拟合数据,将数据转化为标准形式,一般使用在训练集中
train_x_ctvec=CT_Vec.fit_transform(train_x)
#通过中心化和缩放实现标准化,一般使用在测试集中
test_x_ctvec=CT_Vec.transform(test_x)
3.4 划分数据集
本文将数据集划分为训练数据与测试数据,训练数据与测试数据按照2:8的比例进行分配,训练数据用于训练机器学习算法,测试集用于检测训练数据所训练出模型的效果,并且采用了sklearn中的model_selection中的train_test_split()方法,对训练数据进行分割。划分训练数据与测试数据代码如下:
train_x, test_x, train_y, test_y = model_selection.train_test_split(science["comments"], science["label"], test_size=0.2, random_state=0, shuffle=False)
其中本研究将随机关闭,是为了当训练出现过拟合或其他情况时便于复现。
4 模型构建
本文在构建模型时,因部分参数不确定,进行模型优化时,模型将自行在训练过程中确定参数,最终分别得到经过两种方法得到的实验结果。如表1所示,其中,使用ConutVector转化的向量作为特征传入模型后,使用模型优化的程序时间更长,相应的测试集准确率高于使用TF_IDF的准确率。
5 结果分析
本文通过模型发现游客评论主要情感体现有以下词语:“景色优美、文化底蕴、震撼、游客滞留、消费高、商品贵、避暑胜地”,从“景色优美”“震撼”等词语分析出游客对于攀枝花景色的正面情绪,游客需求可以体现在其文本评论中,如“游客滞留”“消费高”此类词语表现游客对于交通及商品消费的消极和负面情绪,因此有关部门应当根据此类词语采取相应措施,满足游客需求,进一步提高公共文化服务的效能。部分词语如图4所示。
6 结 论
总的来说,本文在特征提取过程中,CountVectorizer只考虑词汇在文本中出现的频率,TfidfVectorizer在考虑词频的基础上,还考虑了词汇在文本中的数量,在数据充足的情况下,效果将会更显著。而本文受困于评论数据单一并且不充足,若有更充足的攀枝花旅游评论数据,该预测值的偏差将会更小。并且本文针对评论情感分析的实现方法,也可应用在其他领域,例如对产品体验评论、餐饮服务评论等进行用户情感分析,收集结果后对产品、服务等进行调整。该方式能更好地满足游客精神文化服务需求,从而进一步带动攀枝花城市建设,促进城市发展。
参考文献:
[1] 何雪琴,杨文忠,吾守尔·斯拉木,等.融合句法规则和CNN的旅游评论情感分析 [J].计算机工程与设计,2019,40(11):3306-3312.
[2] 杨英.小空间尺度区域旅游资源及其评价:以香港为例 [J].产经评论,2012,3(1):104-110.
[3] 薄湘平,张慧.旅游服务补救质量的综合模糊评价方法探讨 [J].南开管理评论,2005(4):12-13+16.
[4] 刘逸,保继刚,朱毅玲.基于大数据的旅游目的地情感评价方法探究 [J].地理研究,2017,36(6):1091-1105.
[5] 赵忠君,孙霞.基于扎根理论的出境游游客满意度影响因素研究——以途牛旅游网游客点评为例 [J].湘潭大学学报:哲学社会科学版,2015,39(5):87-91.
[6] 朱峰,吕镇.国内游客对饭店服务质量评论的文本分析——以e龙网的网友评论为例 [J].旅游学刊,2006(5):86-90.
[7] 高静,章勇刚,庄东泉.国内旅游者对海滨旅游城市的感知形象研究——基于对携程网和同程网网友点评的文本分析 [J].消费经济,2009,25(3):62-65.
[8] 张珍珍,李君轶.旅游形象研究中问卷调查和网络文本数据的对比——以西安旅游形象感知研究为例 [J].旅游科学,2014,28(6):73-81.
作者简介:任湘(2002—),女,汉族,四川绵阳人,本科在读,研究方向:机器学习。
收稿日期:2023-05-06
基金项目:四川省社会科学重点研究基地中国酒史研究中心资助项目(ZGJS2022-07)
猜你喜欢
电脑知识与技术(2017年3期)2017-03-27 14:05:09
智能计算机与应用(2017年1期)2017-03-23 13:24:04
物联网技术(2016年11期)2017-01-12 19:41:22
电子技术与软件工程(2016年22期)2016-12-26 21:36:42
预测(2016年5期)2016-12-26 17:16:57
科技创新与应用(2016年31期)2016-12-03 03:33:48
时代金融(2016年27期)2016-11-25 17:51:36
科教导刊(2016年26期)2016-11-15 20:19:33
科学与财富(2016年28期)2016-10-14 21:19:17
科教导刊·电子版(2016年10期)2016-06-02 18:04:11
