
基于协同过滤算法的附近景点推荐
2024-01-27 13:41周喜平杜航勤
电脑知识与技术 2023年36期
关键词:准确率
周喜平 杜航勤


摘要:在推荐算法中,协同过滤算法主要通过分析用户对景点的历史评价数据,找出与当前用户偏好相似的其他用户,从而推荐用户喜欢的物品。针对如何推荐出用户附近的最优景点,文章提出基于Redis的GEO算法与协同过滤算法的附近景点优化推荐算法,加入两种因数并分配权重,从而提高该算法的准确率和召回率。优化后的协同过滤算法不仅可适用于各种类型的景点推荐,而且能够帮助用户快速找到附近感兴趣的景点,提高用户的满意度。
关键词:协同过滤算法;Redis Geo算法;附近景点推荐;准确率;召回率
中图分类号:TP311 文献标识码:A
文章编号:1009-3044(2023)36-0013-03
开放科学(资源服务)标识码(OSID)
0 引言
在旅游规划中,了解并探索附近的景点是一项重要而令人兴奋的任务。基于协同过滤算法的附近景点推荐系统将为用户提供个性化、准确且多样化的推荐,帮助他们发现和体验更多有趣的地方。
除了个性化的推荐,基于协同过滤算法的附近景点推荐系统,首先利用Redis的GEO算法[1]根据用户所在的地理位置计算出与景点的距离并筛选出用户周围的景点数据,再根据基于物品的协同过滤算法对景点数据进行计算,根据不同景点的相似性来推测出用户潜在的风景爱好从而生成推荐列表。本文提出加入两种景点因素并分配这两种因素的权重来优化协同过滤的推荐算法,这种系统具备灵活性和实时性,确保用户在旅行过程中不会错失任何适合他们口味的景点。
基于物品的协同过滤算法[2],首先通过分析用户的历史记录确定用户喜欢景点的类型与评分来收集用户及景点的信息。其次再使用数据预处理技术对收集到的用户与景点数据进行清洗和转换,主要是对原始数据去噪和归一化处理。再进行数据的划分与特征的提取,之后可以使用余弦相似度(Cosine Similarity)或者皮尔逊相关系数(Pearson Correlation Coefficient)来进行相似度的计算,从而选出和目标景点相似度最高的K个近邻景点,封装成推荐景点数据,最后把选出的景点数据推荐给用户。
总体而言,基于协同过滤算法的附近景点优化推荐系统为旅行者带来了便利和乐趣。通过结合个人兴趣和其他用户的喜好,该系统可以为每位用户提供独特且符合期望的推荐[3],使旅行变得更加丰富、有趣且令人难忘。无论是做出决策还是发掘新的亮点,这个推荐系统都将成为旅游规划中不可或缺的利器。
1 基与物品的协同过滤推荐算法与优化
1.1基于物品间的协同过滤算法
1)物品相似度计算
物品之间的相似度计算可以使用余弦相似度(Cosine Similarity)[4]或者皮尔逊相关系数(Pearson Correlation Coefficient)[5]来计算,根据不同的情况来分别使用这两个方法来计算相似度。
余弦相似度算法公式:
[sim(a1,a2) = 1M(P1,n×P2,n)1MP21,n×1MP22,n] ⑴
皮尔逊相似度算法公式:
[sim(a1,a2)=1M(P1,n-P1)×(P2,n-P2)1M(P1,n-P1)2×1M(P2,n-P2)2] ⑵
[sim(a1,a2)]代表物品a1和物品a2的相似度值;[P1,n]是物品1对景点n的潜在评分;景点n∈M,M为物品1与物品2 的共同评分的景点;[P1]是物品1被评分的平均值。
2)推荐生成
根据用户历史数据里面的景点数据筛选出用户的偏好,与用户所在的地理位置附近的景点数据进行对比与排序。例如图1中,根据用户的历史数据与附近景点数据形成历史数据集与附近景点数据集,历史数据1对附近景点1、3有共同点,历史数据2对附近景点2有共同点,历史数据3对附近景点1、3、4有共同点,可以推出历史数据1与附近景点4有共同点所在。
1.2 基于物品协同過滤算法的优化
为了提高协同过滤算法的推荐效果,本文除了引入景点评分因素,还引入景点评论数量因素与景点地理位置因素。在景点间的相似度计算上,除了考虑到每个用户对景点评分的相似度,还需要考虑用户与景点在评论数量上和地理位置上的相似度。如何解决这一问题,需要获取此景点的评论数量,并进行计算用户历史景点的位置信息(经纬度)与用户的地理位置的距离,以此来获取相关因数的数据值,最后进行相似度计算。在推荐景点选取的过程中,基于其他景点的评分数据,预测目标用户在特定时间与位置下对未评价的景点的评分,则需要使用加权平均预测[6]。
加权平均预测中需要赋予评论数量与地理位置的权重[7]。对用户历史记录中每个景点的评论数量数据进行加权就和,权值为各个景点与其他景点的相似度,然后对所有景点相似度的和,从而计算出用户对其他景点的潜在喜欢的可能性。
加权平均预测公式为:
[Wa,i=1M(a)Hi,n×Sa,n1M(a)Hi,n] ⑶
[Wa,i]为用户a对商品i的潜在喜欢评分;[M(a)]为用户历史记录中的景点数据集,景点n∈M(a);[Hi,n]为景点i与景点n的相似度;[Sa,n]为用户a对景点n的评分。
加入评论数量和景点与用户的距离因素的权重,评论数量权重值为景点i与景点n各个评论数量之间的相似度[Ei,n],景点与用户的距离权重值为景点i与景点n在距离上的相似度[Gi,n],并且这三个因数的权重比x、y、z之和必须等于1。重新得出新的加权平均公式:
[Qi,n=xEi,n+yGi,n+zHi,n] ⑷
[1=x+y+z] ⑸
[Wa,i=1M(a)(Qi,n×Sa,n)1M(a)Qi,n] ⑹
上式中,经过优化的物品协同过滤算法的实现,是在经过景点相似度计算之后的加权平均预测公式中加入评论数量和景点与用户的距离因素,形成新的加权平均预测公式。根据新的公式进行计算,得出用户对某一景点的潜在喜欢程度,从而筛选出相似的景点,得到最优结果集并进行推荐,实现最优的附近景点推荐,提高用户的满意程度。
2 实验结果与分析
2.1 数据集
本文的数据来自全国旅游景点数据集,其中全国旅游景点数据集包含了5万个景点数据。将数据集分为训练集与测试集,然后再分为历史数据集与附近景点数据集。数据集中主要包含以下属性:用户,景点,城市,评论数量,景点评分。
2.2 评估指标
本文使用准确率、召回率和F1值[8]来评估算法的性能。准确率代表推荐物品中准确推荐的比例,召回率则代表真实物品中被推荐出来的比例。F1值是准确率和召回率的加权平均。计算出每个景点的F1值,生成全部景点数据集的F1值表。F1的指数越高,代表推荐效果更好。
1)准确率:表示用户喜欢的景点在用户总推荐的景点数据中所占的比例,公式如下:
[Ti,n=iM|m(n)⋃r(n)|iM|c(n)|] ;⑹
2)召回率:表示用户喜欢的推荐景点数与用户总喜欢的推荐景点数的比例,公式如下:
[Gi,n=iM|m(n)⋂r(n)|iM|m(n)|] ⑺
3)F1值的计算公式为:
[F1=Ti,n×Gi,n×2Ti,n+Gi,n] ⑻
上式中:[Ti,n]代表i个景点对用户n的准确率;[Gi,n]代表景点i对用户n的召回率;m(n)为用户喜欢推荐的景点;r(n)为用户总喜欢的推荐景点;c(n)为用户总的推荐景点。
2.3 实验的结论与分析
本文中使用传统的基于物品的协同过滤算法,与本文加入因素的改进的协同过滤算法来进行比较。对比数据与结果如下:
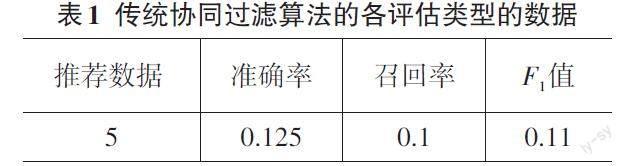
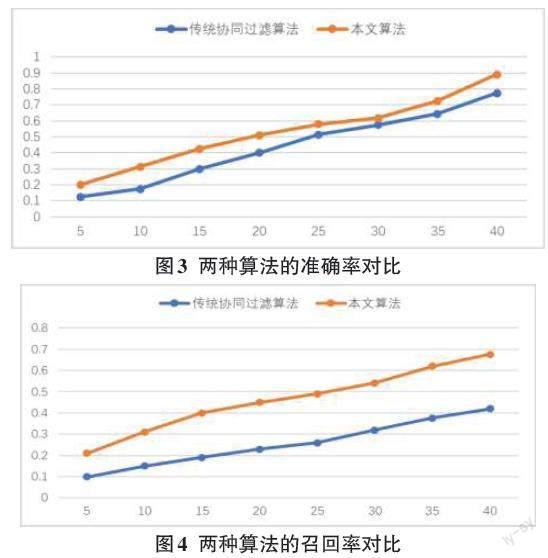
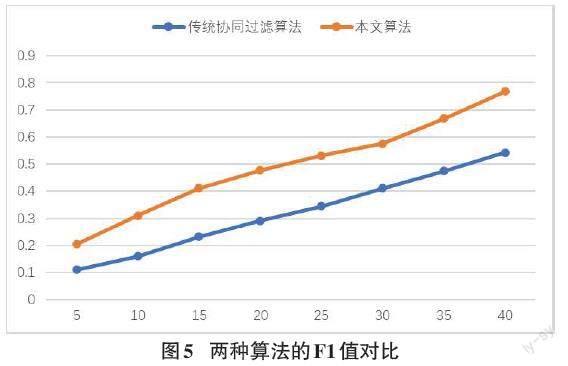
根据表1、表2绘制出两种算法的对比折线图更直观地展示出对比的结果。
通过观察图3~图5中整体的趋势可以看出算法的准确率,召回率,F1值都呈上升趋势,但相比较于传统的协同过滤算法,本文提出的算法更优于传统的协同过滤算法。根据对比结果表明,协同过滤算法不能只对用户、景点、评分这三点来作为推荐的主要重点,引入不同的特征点,把问题具体化,更能计算出最优的推荐结果[9]。
3 结束语
本文首先提出使用Redis的GEO算法来实现对用户地理位置景点的距离计算与数据的筛选。其次除评分因数外,再加入景点评论数量因数和景点与用户的距离因数改进基于物品的协同过滤算法,得出更适合用户喜欢的附近景点的推荐。改进的算法不仅考虑到景点与景点之间的相似度,也对用户喜好与景点特征的相似度進行考虑,从而得出的推荐结果更能符合用户的喜好。通过进行实验传统的协同过滤算法与本文算法来进行对比,结果显示此方法提高了精确率与召回率从而提高F1值,使得推荐效果达到更好。
参考文献:
[1] 周徐虎,李世港,罗仪,等.基于对称映射搜索策略的自适应金鹰算法及应用[J/OL].电子科技:1-10[2023-06-23].https://doi.org/10.16180/j.cnki.issn1007-7820.2024.08.002.
[2] 张盼盼,刘凯凯.基于协同过滤算法的图书推荐系统设计与实现[J].计算机时代,2023(8):144-146.
[3] 陈勇.基于协同过滤算法的旅游推荐系统的设计[J].价值工程,2022,41(30):160-162.
[4] 许馨,郭家赫,乔宇,等.一种基于遗忘机制与余弦相似度的智能推荐算法[J].软件工程,2023,26(10):15-18.
[5] 程娟娟.高校科研与教学关系实证研究——基于皮尔逊相关系数的分析[J].中国高校科技,2022(10):46-52.
[6] 胡红萍,乔世昌,孔慧华,等.基于加权平均樽海鞘群算法和BP神经网络的COVID-19预测[J].新疆大学学报(自然科学版)(中英文),2022,39(1):19-25.
[7] 王睿,姜学军.基于改进协同过滤的图书推荐算法研究[J].信息技术与信息化,2023(4):149-152.
[8] 王照国,张红云,苗夺谦.基于F1值的非极大值抑制阈值自动选取方法[J].智能系统学报,2020,15(5):1006-1012.
[9] 齐晶,刘瀛,刘艳霞,等.基于标签的协同过滤推荐方法研究[J].北京联合大学学报,2021,35(2):47-52.
【通联编辑:谢媛媛】
猜你喜欢
医学食疗与健康(2021年27期)2021-05-13
健康体检与管理(2021年10期)2021-01-03
河北环境工程学院学报(2020年1期)2020-04-03
中国交通信息化(2018年5期)2018-08-21
老年医学与保健(2017年6期)2017-02-06
电子制作(2016年15期)2017-01-15
通信电源技术(2016年5期)2016-03-22
