
基于Transformer的3D点云场景识别研究与实现
2024-01-24 14:36:59胡丽娜曹政
电脑知识与技术 2023年34期
胡丽娜 曹政

摘要:场景识别是智能机器人实现回环检测、定位任务的关键,该方法通过分析、提取场景中特征从而推测所处位置是否已到访过。由于视觉传感器视场范围小、易受光照影响的缺点,基于3D点云的场景识别方法成为计算机视觉研究领域的热点。文章首先对研究背景和一些主流场景识别方法进行介绍。随后,文章对提出算法的主要步骤进行介绍,包括数据编码模块、Transformer模块以及NetVLAD描述符生成模块。最后,文章在公开数据集KITTI上定量地对比了该文方法和其他开源算法。结果表明,文章提出的方法达到了SOTA(state-of-the-art) 水准。
关键词:机器人;自动驾驶;场景识别;回环检测;3D点云
中图分类号:TP391 文献标识码:A
文章编号:1009-3044(2023)34-0001-03
开放科学(资源服务)标识码(OSID) :
0 引言
场景识别技术[1]涉及计算机视觉与机器人环境感知技术。它旨在通过机器人对当前环境的扫描数据进行特征提取,完成对环境的分析与识别,对是否曾经访问过该场景做出判断。它可以用于同时定位与地图构建(Simultaneous Localization and Mapping,SLAM) 的回环检测环节[1-2]。若当前数据和历史数据之间被检测出存在回环,将这两数据之间的变换矩阵加入里程计的优化当中,可有效地消除里程计因相邻数据匹配带来的累积误差。此外,它还可以应用于基于地图的定位任务。通过当前数据与地图数据之间的回环检测,可以快速地定位机器人在地图中的位置,实现机器人全局位置的初始化,为下游规划、导航任务提供起点信息。对该技术进行研究不仅能提升SLAM方法建图的准确性,还能在GPS拒止条件下为机器人的自主定位提供一种备选的方案。因此,具备理论价值和实际应用价值。
基于3D点云的场景识别技术大体上可分为两个方向[1]:基于手工特征的场景识别与基于深度学习的场景识别。手工特征方法首先通过直方图、体素化、投影等方式生成描述符,随后通过描述符之间的相似度来判断场景之间的相似度。例如,Scan Context[3]是典型的投影方式手工特征方法,它沿直径方向和中心角方向将点云分割为20[×]60大小的子区域,通过记录每个区域内点云的最大高度生成20[×]60的矩阵(即沿z轴方向将点云投影成一个平面描述符),随后通过暴力匹配的方式计算描述符之间的相似性;LiDAR IRIS构建描述符的方式和Scan Context相类似,区别在于LiDAR IRIS[4]将虹膜间的相似度计算方法引入描述符中,提高了计算效率与准确性。深度学习方法则是通过事先标注好的训练数据对深度模型进行训练,当模型拟合后通过输入测试数据便能知晓是否发现回环。OverlapNet[5]是一个典型的基于卷积神经网络(Convolutional Neural Network,CNN) 构建的深度模型,它利用深度、灰度、语义等信息作为输入,能够在复杂环境中估计回环信息。本文将计算机视觉领域现阶段比较火热的Transformer[6]模块引入传统CNN结构当中,随后利用NetVLAD模块对特征进行整合,并生成一维向量描述符用于计算描述符间的相似性。
1 算法设计
1.1 算法流程概述
本文算法的整体流程如图1所示,以KITTI 08序列中点云数据(第1帧和第1511帧)为例,数据编码模块首先将3D点云数据转换为深度图像(见图1中[1×64×90]0大小的蓝色条状部分)。随后,Vgg16网络从输入的深度图像中提取特征。接着,Transformer模块利用注意力机制对特征图进行进一步的学习,对特征进行深度提取。最后,NetVLAD模块将Vgg16网络和Transformer模块的输出转换为具有旋转不变的一维向量(全局描述符,图1中蓝绿黄间隔的条形图所示)。通过计算描述符之间的相似程度完成场景的识别。
1.2 数据编码模块
由于单帧点云内点的数量众多,影响训练效率。因此在送入深度网络训练之前,会将其转换为深度图像、灰度图像或语义图像,对数据进行压缩以减小计算量。本文使用深度图像作为输入数据,深度图像中每一个坐标位置[(u, v)]与点云中每个点[pi(x,y,z)]间的转换关系如式(1) 所示:
[uv=12[1-arctan(y,x)⋅π-1]⋅w[1-(arcsin(z⋅r-1)+fup)⋅f-1]⋅h] (1)
其中,[r]是每个点到原点的距离,[fup]是传感器是视场角的上界,[f=fup+fdown]是传感器的垂直视场角,[w]和[h]分别是生成深度图像的宽度和高度。此外,深度图像中每一个位置的像素值[I(u,v)=r]。
1.3 Transformer模塊
与卷积神经网络不同,Transformer并不需要通过堆叠多层卷积核以扩大感受野,而是通过注意力(Attention) 机制对整张深度图像进行特征提取,以更好地捕捉全局信息,使得深度模型有更好的鲁棒性,也更适合于处理时间较长的场景识别任务。
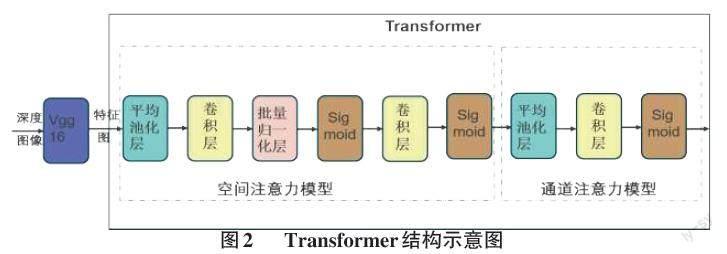
本文提出的Transformer结构如图2所示,整体上分为空间注意力机制部分和通道注意力机制两部分。从Vgg16输出的特征图中并不是所有区域对场景识别任务都同样重要,只有任务相关区域才是重心,空间注意力模型的作用则是针对这部分重心进行处理。通道注意力模型则是对空间注意力模块的输出进行建模,评估其各个特征通道的重要程度,并针对任务类型增强或抑制这些通道。每种注意力模型具体使用的操作见图2虚框中内容。
1.4 NetVLAD模块
NetVLAD是由传统VLAD算法改进而来,以使其能够参与深度网络训练。该算法的实现分为四个步骤:
1) 通过深度网络模型将Transformer模块输出的[N]个[D]维特征描述子[xi]劃分为[k]个聚类中心[ck];
2) 计算分配矩阵[ak(xi)],其公式如式(2):
[akxi=e-αxi-ck2j=1ke-αxi-cj2] (2)
当[xi]和[ck]越接近,[ak(xi)]趋近于1,反之越趋近于0;
3) 通过分配矩阵将特征描述子到聚类中心的残差进行累加,求取加权残差向量和,即获取一个[K×D]维的全局特征,其公式为(3):
[V(k)=i=1Nak(xi)(xi-ck)] (3)
4) 将对全局特征[V(k)]通过多层感知机(Multi-layer Perceptron,MLP) 进行通道维度的降维操作,得到最终所需要的一维向量描述符。
2 实验与评估
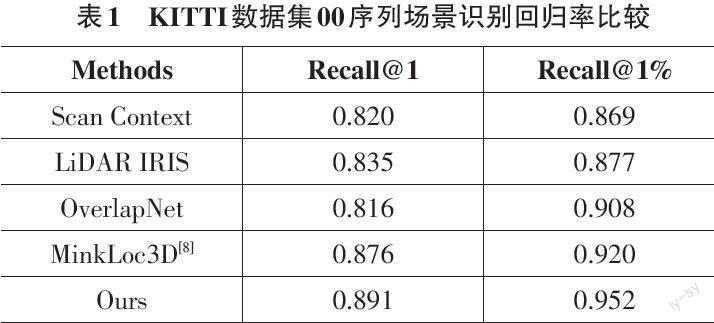
本文使用公开数据集KITTI[7]来评估本文方法的性能,并和两个传统手工方法Scan Context、LiDAR IRIS以及两个深度学习方法OverlapNet、MinkLoc3D进行比较。本文在KITTI数据集的03-10序列上对提出模型进行训练,并将02序列用作验证集,最终在00序列上对各个算法的性能进行评估。实验中具体设定如下,64线雷达点云数据被编码为[1×64×900]的深度图像。此外,NetVLAD模块的聚类中心数量[k]被设定为64。对于评价标准,本文使用了深度学习相关方法常用的Recall@1和Recall@1%作为指标。本文提出方法与对比方法的结果如表1所示:
从表1中可以看出,本文方法在KITTI 00序列上的表现要优于所有对比方法。其中召回率Top1(Recall@1) 为0.891,这说明检索到的正样本数量占数据中所有正样本数量的89.1%,查全率接近9成。比第二名MinkLoc3D高出1.5%。此外,如果将检索范围从Top1变为Top1%,即对于每一帧数据选出总帧数1%数量的候选帧,只要结果之中有一帧与该检索数据的回环真值一致则判定检索成功,则本文提出方法的查全率为95.2%。实验结果表明,将Transformer模块引入深度学习的场景识别方法之中有助于提升算法的性能,也表明本文方法达到了现有方法的水准。
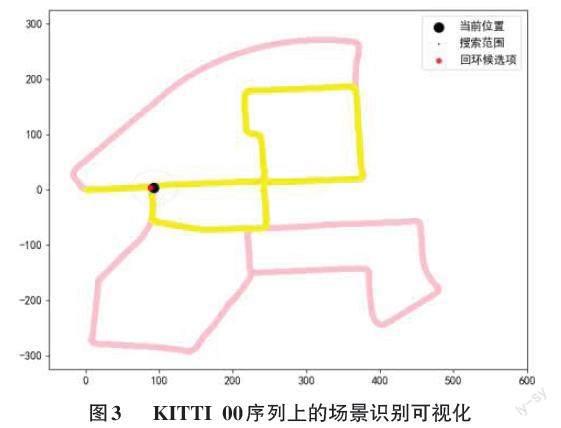
图3展示了所提出算法在KITTI 00序列上的场景识别效果,其中粉色线条代表00序列的整体轨迹,黄色线条代表已走过的路径,黑色代表当前位置。在黑点所在的T形路口上,车辆两次经过该路口,本文算法都能够成功地检索到了这两次回环。这意味着无论从路口的哪个方向进入该位置,该算法都能够准确地识别出该位置已到访过。说明该算法同时具备旋转不变性和准确性。
3 结束语
本文基于深度学习网络和Transformer模块设计了一种新的场景识别方法,并在公开数据集KITTI上将提出方法与几种前沿方法进行了对比。定量的实验结果表明,该算法具备较高的回环检测性能,实现了较高的召回率(Recall@1 0.891和Recall@1% 0.952) 。实验也表明该算法尚存在提升的空间,在一些特殊情况下检索不到回环数据或找不到正确的回环。在未来,可以通过设计新的卷积神经网络对Vgg16进行替换以获得更好的图像特征。此外,还可以设计多层的Transformer结构,通过特征级融合的方式提升网络的性能。
参考文献:
[1] 赵梦成,黎昱宏,张宏宇.ROS的服务类移动机器人SLAM导航的研究[J].电脑知识与技术,2020,16(9):274-276.
[2] 刘焕钊,蒋林,郭宇飞,等.基于三维点云转换视觉图像的回环检测算法[J].组合机床与自动化加工技术,2023(4):91-95,99.
[3] KIM G,KIM A.Scan context:egocentric spatial descriptor for place recognition within 3D point cloud map[C]//2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS).ACM,2018:4802-4809.
[4] WANG Y,SUN Z Z,XU C Z,et al.LiDAR iris for loop-closure detection[C]//2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS).IEEE,2020:5769-5775.
[5] CHEN X,LÄBE T,MILIOTO A,et al.OverlapNet:loop closing for LiDAR-based SLAM[C]//Robotics:Science and Systems XVI.Robotics:Science and Systems Foundation,2020.
[6] 张玮智,于谦,苏金善,等.从U-Net到Transformer:深度模型在医学图像分割中的应用综述[J] 计算机应用.[2023-10-27]. https://kns.cnki.net/kcms2/article/abstract?v=QGW0A_jem_lpuq_w9i3Oshuspl1mJthja0UXxm2oilNlHLcukmxPOS2rH 5DHDd_0vfZPw5c3HSQjZHuGWbwu-tvtfYt5ssfoMd0R_0O_jC eBtiOCF4cw==&uniplatform=NZKPT.
[7] GEIGER A,LENZ P,URTASUN R.Are we ready for autonomous driving?The KITTI vision benchmark suite[C]//2012 IEEE Conference on Computer Vision and Pattern Recognition.IEEE,2012:3354-3361.
[8] KOMOROWSKI J.MinkLoc3D:point cloud based large-scale place recognition[C]//2021 IEEE Winter Conference on Applications of Computer Vision (WACV).IEEE,2021:1789-1798.
【通联编辑:光文玲】
猜你喜欢
测绘学报(2022年12期)2022-02-13 09:13:01
中学生数理化·七年级数学人教版(2020年11期)2020-12-14 06:59:52
中学生数理化·八年级物理人教版(2020年6期)2020-10-30 01:52:57
艺术品鉴证.中国艺术金融(2018年8期)2019-01-14 01:14:28
艺术品鉴证.中国艺术金融(2018年10期)2019-01-08 02:44:26
艺术品鉴证.中国艺术金融(2018年12期)2018-08-26 06:03:48
宝藏(2018年3期)2018-06-29 03:43:10
数字通信世界(2018年1期)2018-04-18 11:05:22
测绘科学与工程(2017年5期)2017-05-07 06:30:44
体育世界(学术版)(2015年3期)2015-07-01 17:15:34
