
提示词模板在人工智能对话中的实践研究
2024-01-24 14:36:59陈嗣荣冯敬益
电脑知识与技术 2023年34期
陈嗣荣 冯敬益
摘要:通过与人工智能语言模型ChatGPT进行对话,总结出提示词在对话过程中的使用技巧,包括告诉人工智能扮演的角色、提示词模板、在提问过程中追问细节、提问时增加关键词等。利用以上提问技巧,使得ChatGPT的回答更有质量。
关键词:人工智能;提示词模板;对话
中图分类号:TP311 文献标识码:A
文章编号:1009-3044(2023)34-0013-03
开放科学(资源服务)标识码(OSID)
1 研究背景和意义
ChatGPT是一个由OpenAI公司开發的人工智能语言模型[1]。它的作用是回答各种各样的问题,帮助人们解决问题和获取信息。随着ChatGPT的出现,人工智能(Artificial Intelligence,简称AI) 走入了人们的视野。提示在人工智能领域中的含义是指示AI进行某些行为的过程。提示词模板设计并不单单用在跟ChatGPT的聊天中,也用于设计出更好用的,并且能够重复利用的人工智能提示词,用于跟各种各样的机器学习模型进行交互。本研究意义是根据不同的使用场景,设计出相应的提示词。如果没有使用正确的提示词,ChatGPT的回答通常跟人们的需求相差甚远。如果能够编写出结构合理、AI易懂的提示词,就可以让ChatGPT的回答更为准确,可以增加用户的体验,使用户可以更加快速地得到结果,也可以降低初学者的学习成本,使他们不需要太多的学习就可以跟AI进行对话。
2 相关工作综述
2.1 提示词基础知识
在布置一个任务的时候,需要使用到一些词语来对执行任务的人进行引导或指示他怎么做,这些词语就叫提示词,它可以让执行者对任务要求和内容把握更为到位。一个良好的提示词可能包含以下四个元素:指令、背景、输入数据和输出指令。指令,这是人们希望AI完成的一个具体任务是什么。例如,根据如下表格信息,制作一张折线统计图。背景,这指外部的信息或者是额外的上下文,利用这些信息可以引导设计的模型做出更好的回应。例如,最近一年的收入财务报表。输入数据,是指人们想要问的具体问题,通过问题得到想要的回答。例如,最近半年的营收趋势是怎样的。输出指令,指定输出的AI回答的类型或是结构。例如,要求AI的回答是详细的,并且能够举出相关的例子。
如何让一个简单的接话茬能力让ChatGPT看起来能够解决各种各样的任务呢?因为人类大部分的任务都是以语言为载体的。当人们前面说了一些话,它把接下来的话说对了,任务就完成了。ChatGPT作为一个大语言模型,目的就是“把话说对”,而把话说对这件事情可以在不知不觉中帮助人们完成各种任务。
2.2 NLP基础知识
自然语言处理(NLP) 属于计算机科学的其中一个领域[2-4],它可以使机器能够阅读和理解人类的各种语言[2,5],把语句里的细节进行分离并辨识,就像人类相互理解对方说的话一样,自然语言处理包含自然语言理解和自然语音处理两个部分。NLP可以处理一些非结构化的文本,如“把地拖干净”“把鸡肉和白菜添加到我的购物清单中”这样的命令,同时可以转换非结构化文本和结构化文本。把非结构化的文本变成结构化文本,这个过程叫自然语言理解,例如在上面的那个例子中,购物清单可以看成一个列表,鸡肉和白菜可以看成是列表里面的子元素。把结构文本变成非结构化文本,这个过程叫自然语言生成。例如,把课程表的格式去掉,只保留语文、数学等科目名称。
在处理的过程中,NLP把句子分解成单词,然后进行标记。有时候一些英语单词是有共同的词干的,也把它进行一些特定的标记,这样就能短时间掌握比较多的单词。还可以通过词形还原掌握更多的单词。词形还原是将一个给定的标记,通过字典的定义来学习它的含义,并推导出它的根或词元。如better和good,better是从good衍生出来的,所以better的词根就是good,都把它作为同一个标记。
2.3 提示词模板在人工智能对话的应用
从用户的角度看,ChatGPT的形式就是一个对话机器人,准确地说是“续写”机器人。从技术上来讲,ChatGPT它从来都不是一个专门为问答和对话设计的系统。ChatGPT是一个语言模型,语言模型就是刻画语言最基本的规律。那么如何去建立语言模型呢?可以只做一件事情:掌握词汇间的组合规律,而掌握这种规律最直接的表现就是让语言学会“续写”,类似于人类的“接话茬”。当给出前N个词汇的时候,如果一个模型能够告诉人们第“N+1”个词汇大概率会是什么,就认为该模型掌握了语言的基本规律。ChatGPT就是这样一个语言模型。虽然ChatGPT看起来能完成各种任务,但它本质上只做这一件事情:续写,告诉你第“N+1”个词是什么。
2.4 提示词模板在其他领域的应用
除了如ChatGPT这样的大型语言模型外,AI绘画同样也是需要提示词进行创作。利用提示词,可以创作各种各样风格的卡通头像,也可以进行各种插画的绘制,也可以帮模特实现“一键换装”,节约公司的运营成本。
3 向AI提问的方法与技巧
3.1 告诉AI你是谁
在进行一段对话前,首先让AI进行角色定位,通过告诉AI它现在要扮演的角色,可以回答我哪些方面的问题,这样会使得它的回答更为专业。例如,人们跟AI对话的第一句是:“你现在扮演一位教授本科学段的计算机老师,明白角色请回复明白。”这样AI就会以一位计算机老师的身份跟人们进行对话,如图1所示。
3.2 设置个性化的提示词模板
提示词模板包含了格式模板、文案模板、个人信息模板等。
当你希望AI的回答结果是按你预想的格式进行回答的时候,可以采用格式模板。预先给AI一个相关格式的例子,例如输入以下内容:
问题:广东的省会是哪里?
答案:【广州】
问题:湖南的省会是哪里?
AI会回答以下内容:
“湖南的省会是【长沙】。”
在上面的这个例子里,“【】”号就是设定的格式。
3.3 对细节进行追问
在跟AI进行对话的过程中,AI对人们的提问会作出一个基础的回答,但是这些答案并不一定是想要的答案,这个时候就要跟AI进行充分的沟通,例如提示它:“在你回答这个问题之前,可以继续问我一些跟这个回答相关的问题”。如果对AI的回答不满意,可以跟它提出不满意的地方,例如回答不够详细,用的词过于深奥等,让它修正它的答案,通过这样一步一步地引导,AI就会生成人们想要获取的满意答案。如果在对话的过程中,AI回答的答案跑偏了,人们也要及时对提的问题作出修正,例如我需要AI帮我提取一篇文章的大纲,AI回答的时候会有点发散,这时就增加一个条件,让它按照我给出的原文去进行提取,这样它的提取结果就会比较精确。
3.4 提问时增加关键词
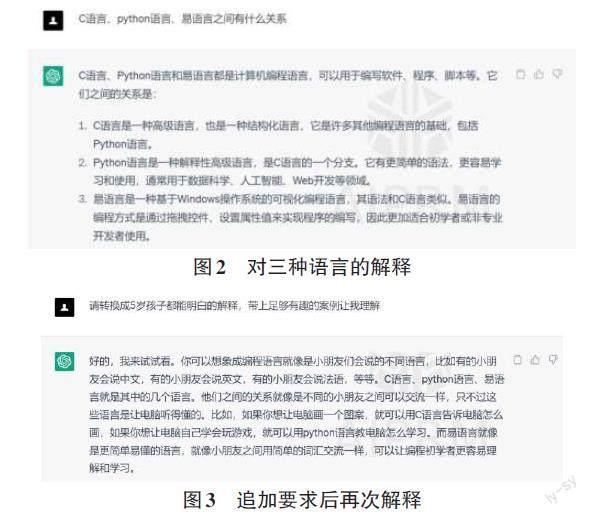
在对AI进行提问的过程中,如果要使提问更有针对性,需要在提问的过程中增加一些关键词。例如想要AI告诉怎么完成这个过程,需要提示它,把实施的步骤罗列出来。对于一些比较专业的问题,AI一般只会对它进行名词解析,作为外行人很难去理解这些专业的名词解析。例如,笔者询问AI:C语言、Python语言、易语言这三种语言之间的关系,AI的回答作为计算机专业的人员会比较容易理解,因为在以前学习的过程中已经学习了相关的知识,如图2所示。但是对于非计算机专业的人员,就会感到生涩难解,这时给出我们的另外的提示:“请转换成5岁孩子都能明白的解释,带上足够有趣的案例让我理解。”这样AI就会尝试用用户要求的条件再次去回答这个问题,如图3所示。
3.5 任务分解,用列表把需求拆分成子任务
任务可以设定AI要实现的具体目标,让AI清楚地理解任务对于设计有效提示词至关重要。任务描述应具体、简洁,避免歧义或模糊,清晰的任务描述有助于AI更好地理解它应该做什么并提高生成内容的质量,是设计提示词时要考虑的关键因素。在生成了总任务之后,用列表的方式把总任务细化成一个一个的子任务。拆分成子任务后,对每一个子任务都清楚描述它的细节,必要的时候,要对任务增加一些限制的条件,这样AI才会对人们布置的任务有更深刻的认识。
3.6 提问中体现特殊性
提问的特殊性是指提示词的详细程度和精确度,对于设计提示词至关重要,因为它可以提高生成内容的质量和相关性。一般来说,提示词越具体,AI就越有可能生成有针对性和准确的回答。模糊或笼统的提示词可能会导致来自AI的题外话、不相关或不一致的回复。例如,如果提问的内容是写一首诗,AI寫的诗歌可能并不是人们想要的,但把提问改为“写一首七言绝句,内容是跟春天有关,诗的开头都要带‘春’字。”这样AI就能按人们所要求的生成诗歌。
3.7 提示词的迭代
迭代是重复执行一系列操作的过程,每次执行都会根据之前的执行结果进行调整,是快速设计过程的关键部分。提示词模板设计是一个迭代的过程,可能需要多次尝试才能创建有效的提示。迭代通过设计、测试和测评的循环来提炼和改进提示词,每次迭代都应该以先前试验的结果为前置条件,目的在于解决遇到的任何限制。例如,当人们修改了提示词以提供更具体的说明或增加额外的上下文后发现AI的回答变得模糊或它产生了偏离主题的回复,采用迭代方法可以持续改进和优化生成的内容。在设计有效、高质和与结果一致的提示词时,迭代是重要的考虑因素。
4 ChatGPT面临的挑战
4.1 ChatGPT的技术挑战
第一,它是不稳定和不可解释的。但这个缺陷不是ChatGPT所独有的,而是整个深度学习模型所具有的,“涌现效应”导致这一问题更加严重。特别在一些敏感的领域,这一问题更加凸显。例如在自动驾驶领域,机器的事故率已经低于人类司机,但为何大家还不愿意完全相信自动驾驶呢?因为自动驾驶虽然事故率低,但是它的事故是不可解释的。
第二,知识更新。让ChatGPT临时接受新的知识比较困难,很多知识在不同的领域是不一样的。人们经常会遇到在特定的场景需要特定的知识的情况,而对于ChatGPT而言,它很难做到。
第三,事实性错误。事实性错误是指信息不符合客观事实,而ChatGPT是无法直接了解客观事实的,他只能了解语言。
第四,输出的同质性。ChatGPT所做出的回答往往是人类的主流观点。因为它是一个概率模型,它会以大概率的答案去回答它的任务。例如,它为什么回答中国的首都是北京,因为它学的语料当中大部分人都是这么说的。它的这种特点实际上有可能加剧信息茧房现象。
此外,还有复杂目标导向、模型效率和模型优化等问题,不再赘述。
4.2 ChatGPT的科学问题
第一,语言不再是人类的专属。ChatGPT可以生成语言。那么这个意味着什么呢?基本上可以预见,在未来的几年当中,互联网上大部分的信息将不再是人类撰写的。事实上,现在Twitter中30%以上的活跃用户都是机器人,在微博中也有大量的水军机器人。
第二,ChatGPT是否能够创造新的知识,还是只将训练语料中的知识换一种更精练和高质量的方式进行表达?如果是后者的话,那么人类对于ChatGPT的使用会造成知识的收敛,降低人类知识的创造效率。如果ChatGPT本身是能够创造新知识的,那它则会大大加速人类获得新知识的效率。
此外,还讨论了语言模型涌现与控制机制、语言的知识表达边界问题、自我意识与自由意志问题、人机共生问题、如何突破语言空间问题,不再赘述。
4.3 ChatGPT的伦理问题
第一,用户隐私的问题。人们输入的问题,技术上是可以被ChatGPT的所有者所获取。
第二,反向影响的问题。ChatGPT会通过它所输出的内容,反过来影响人类的文化,就是人性异化,人性向机器靠拢、机器向人性靠拢。
第三,不当使用。比如说学生用ChatGPT去作弊。
第四,人机共生与加速极化。大模型和人类有一个典型的共生循环,什么意思呢?模型是依赖于人类产生的数据来训练的,ChatGPT用人类说的话做训练之后,他再给出人类答案,并影响人类的认知。人类认知被影响之后,又会说新的话。“你有权保持沉默,但你说的每一句话都会成为训练语料”,新的话又变成ChatGPT新的训练语料。如此反复,就形成一个共生循环。并进一步导致人工智能模型越来越像人,而人越来越像人工智能模型,会向一个人机共生的一种文化去靠近。
第五,生产力垄断与社会和国际关系重建。这一点恰好与区块链形成对比。区块链是分布式,能够去中心化,打破垄断。而ChatGPT这种大模型需要大规模的数据和算力,只有极少数的人或者机构能够提供这样的服务。其实ChatGPT很大程度上是来自于涌现,没有太多的新的技术。很多大的互联网公司都想形成ChatGPT等技术的垄断,从而获得权力,并影响社会、国际关系。回顾互联网发展历史,互联网发明者Tim Berners-Lee做得最伟大的一件事就是放弃了互联网专利。
第六,人工智能的社会角色与伦理地位。随着ChatGPT越来越具有类人的特征,用户不可避免地会将其人格化的冲动。那么他是否会具有类人的地位?这个可能是需要考虑的问题。
5 结论与展望
人工智能,已经从一个概念进入到实际的生产使用中。要利用好人工智能为人类服务,就要掌握如何与人工智能进行有效沟通和对话,提示词模板,就是人和人工智能沟通的桥梁。在未来,成为一名提示词模板工程师是人工智能专业毕业生的一個好方向,现在已经有企业用高薪招聘提示词模板工程师。相信在近几年,这个行业会迎来井喷发展。
参考文献:
[1] WHITE J,FU Q,HAYS S,et al.A Prompt Pattern Catalog to Enhance Prompt Engineering with ChatGPT[EB/OL].[2023-03-20].ArXiv, abs/2302.11382.
[2] CHOPRA A,PRASHAR A,SAIN C.Natural language processing[J].International journal of technology enhancements and emerging engineering research, 2013,1(4):131-134.
[3] HIRSCHBERG J,MANNING C D.Advances in natural language processing[J].Science,2015,349(6245):261-266.
[4] MIHALCEA R,LIU H,LIEBERMAN H.NLP (natural language processing) for NLP (natural language programming)[J].Computational Linguistics and Intelligent Text Processing,2006:19-25.
[5] OTTER D W,MEDINA J R,KALITA J K.A survey of the usages of deep learning for natural language processing[J].IEEE Transactions on Neural Networks and Learning Systems,2021,32(2):604-624.
【通联编辑:闻翔军】
猜你喜欢
建材发展导向(2022年23期)2022-12-22 07:30:02
建材发展导向(2022年12期)2022-08-19 02:33:10
大科技·百科新说(2021年6期)2021-09-12 02:37:27
好孩子画报(2020年5期)2020-06-27 14:08:05
意林·全彩Color(2019年6期)2019-07-24 08:13:50
商界(2019年12期)2019-01-03 06:59:05
IT经理世界(2018年20期)2018-10-24 02:38:24
小康(2017年16期)2017-06-07 09:00:59
南风窗(2016年19期)2016-09-21 16:51:29
中国房地产业(2016年24期)2016-02-16 06:10:20
