
基于关键词提取的大学生就业岗位匹配度分析
2024-01-23 08:36於雯
无线互联科技 2023年21期
於 雯
(汉江师范学院,湖北 十堰 442000)
0 引言
目前,高校的信息化研究与进展不断加深,已有不少高校通过数据分析等信息化手段对学生进行行为画像,如:根据学生学习成绩的学习预警;通过学生的食堂消费数据为贫困学生提供生活补助;对学生进出图书馆以及借阅图书信息推荐阅读榜单及年度读书达人等应用。这些基于数据分析的智能化应用不仅提高了学校的管理水平,也为学生提供了更加人性化的服务[1]。目前,各高校针对学生就业技能方向的研究仍处于起步阶段,虽然大多数高校都开设有就业培训课程,但是不少培训课程和实际就业要求不匹配,缺乏专业的技能分析,部分学生对于该类课程的重视程度不够,使得培训无法达到预期效果。
随着近年应届毕业生数量的节节攀升,高校毕业生的就业问题一直是社会关注的重点问题,大量的待就业群体对社会的稳定与发展带来挑战。与此同时,许多企业也面临着无法招到满意员工的困扰,造成了用人难的局面。为了更好地解决这一问题,提高毕业生与企业之间的匹配度,本文利用招聘信息关键词的提取与分析来了解企业需求,帮助毕业生更具针对性地提升职场技能,从而选择符合自身发展的岗位;企业则能通过准确匹配人才,解决用工难的问题,进一步推动就业情况的改善。基于关键词提取的岗位匹配度分析包括三大部分工作:首先是通过抽取某高校的信息工程专业人才培养方案,基于该专业人才培养方案中开设的课程,将通识课程和专业课程进行划分,分别对应就业技能中的通用技能和专业技能;再根据学生每门课程的成绩代表对该技能的掌握程度,从而得到学生的职业技能表;其次是利用TD-IDF的关键词提取技术,对该专业的对口就业岗位进行关键词提取;最后根据技能表和岗位关键词进行匹配度分析,主要工作流程如图1所示,通过就业技能的分析与匹配可以使学生更清楚地了解自身技能情况和企业的招聘要求,更加有针对性地提高自身专业技能。
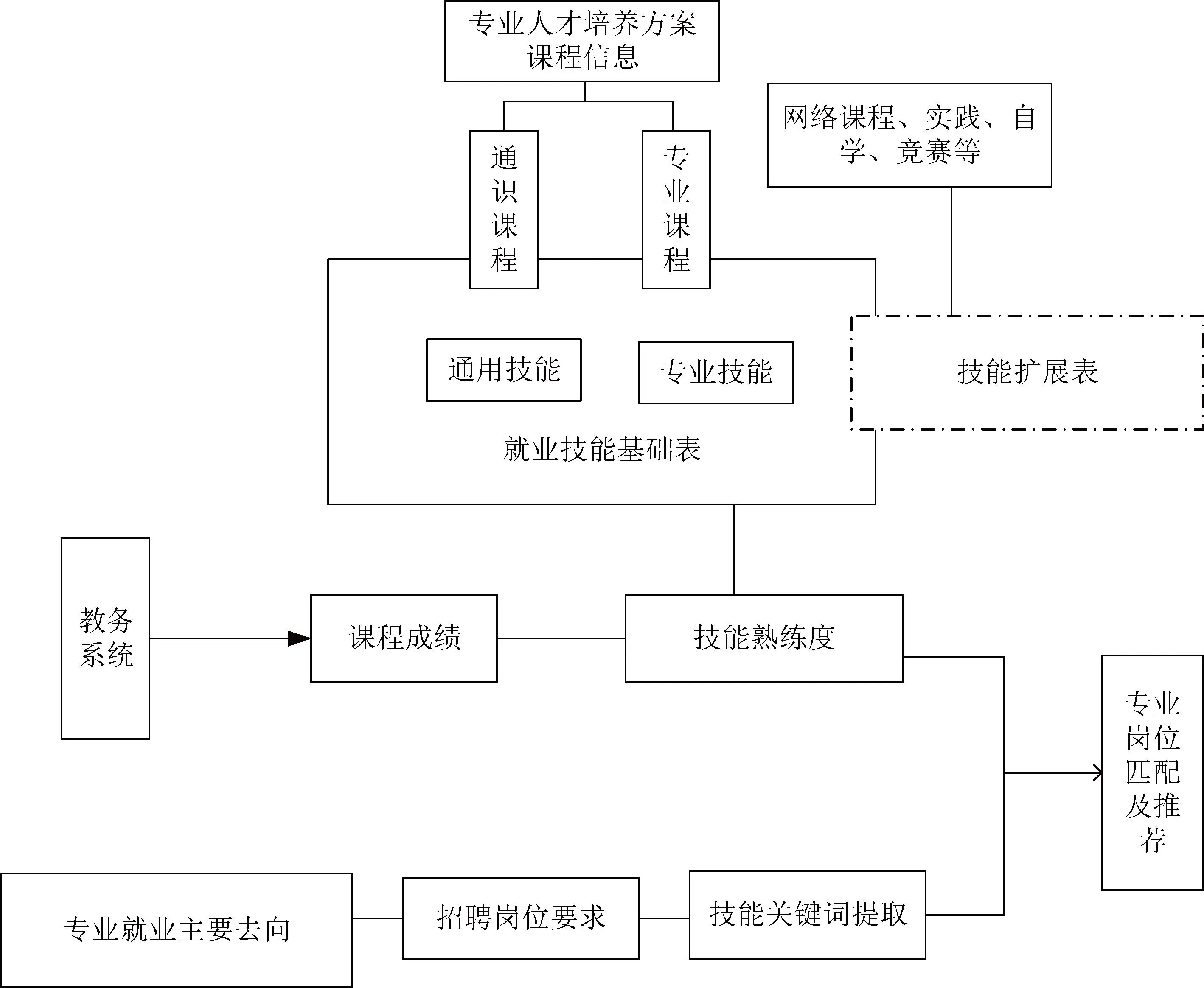
图1 就业岗位匹配度分析流程
1 课程信息与技能匹配
1.1 课程信息提取
以某高校信息工程专业为例,人才培养方案中列出了该专业所开设的全部课程,根据课程的不同属性将其分为通识课程和专业课程,对应不同课程属性分析其培养目标中不同的就业技能。其中,通识课程对应于职场通用技能,专业课程对应于专业技能,如表1所示。

表1 专业课程信息
根据所开设课程的教学大纲,提取不同专业课程所教授的专业技能[2],例如:程序设计语言课程大纲中要求通过该门课程能够使学生系统地学习和掌握C语言的编程知识。因此,可以提取C语言为该门课程对应的技能,通过分析所有课程大纲,形成该专业学生的所学技能,基础表如表2所示。此外,学生还可以课外通过网络课程、实践、竞赛等途径自学掌握多种技能,需要学生根据自身情况进行添加以构成就业技能扩展表,最终构成该名学生完整的技能信息。
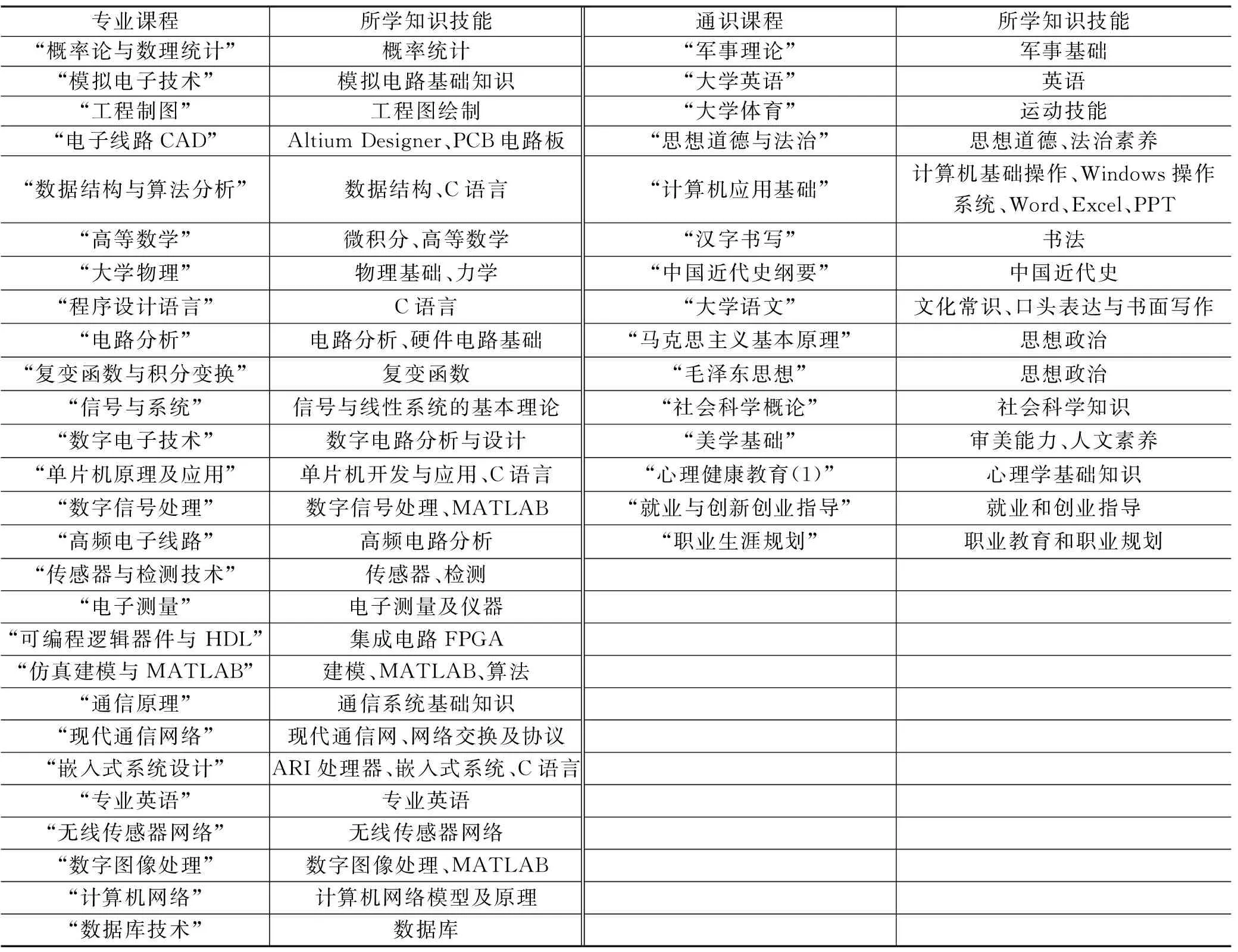
表2 课程与技能对照
1.2 技能掌握情况
通过学校的教务系统获取学生每门课程的学习成绩,根据学生的课程成绩,对学生掌握的知识技能情况进行排序,成绩较好的课程可以记为对该门课程所讲授的知识技能的掌握程度较高,从而为后续专业岗位匹配度分析提供参考依据[3]。将课程成绩低于60分(含60分)记为了解该门课程所对应的知识技能;课程成绩大于60分低于80分(含80分)记为熟悉该门课程知识技能;课程成绩大于80分记为掌握该门课程的知识技能。例如:从系统中获取某位同学的成绩,并按照成绩高低排序后可以得到该同学的通过学习学校课程所获得的知识技能熟练度信息情况,如表3 所示。
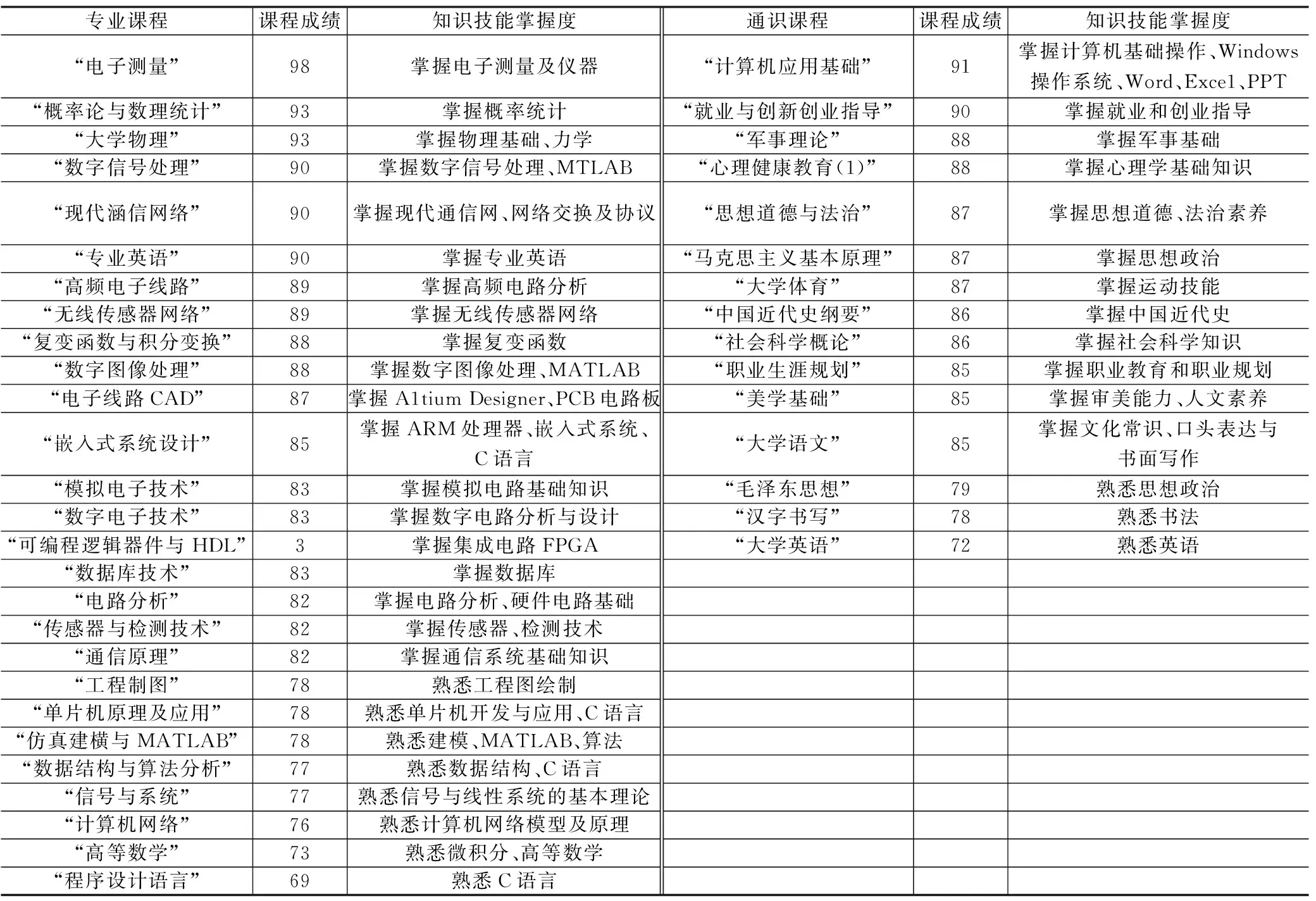
表3 知识技能掌握情况
2 招聘需求关键词分析
2.1 数据采集与预处理
利用网络爬虫技术采集招聘网站上的招聘信息,根据招聘信息中的岗位要求分析招聘企业所需的专业技能,进行关键词提取。通过观察发现爬取到的数据包含大量的脏数据和高耦合的数据[3],本研究需要对这些脏数据进行清洗与预处理后才能正常使用。经过数据清洗,最终得到包含岗位名称、地区、行业、公司、薪资、岗位职责等信息的招聘岗位数据集1 800条。
岗位职责信息通常为一段短文本描述,需要对短文本进行去除停用词、中文分词以及词性标注等操作,以达到更好的分析效果。
中文句子的最小单位是字,而词才是具有语义的最小单位,英文的每个单词都以空格结尾对句子进行切分,而中文文本的句子中没有词的界限,不能直接区分出词和字,因此需要按照中文汉字的排列将连续的字按照规律组合成词语的形式。中文分词就是基于这种思想将字转换成为词的操作,是对于中文文本分析首要的预处理操作,分词的效果将直接影响词性的划分和后续文本处理的效果。针对中文的分词工具有很多种,目前国内比较常用的分词系统包括 jieba分词、中科院的 NLPIR中文分词系统,哈尔滨工业大学语言技术平台(LTP)分词系统等。jieba分词是一种常用的开源分词库,主要是因为它能够根据分割模型以最精确的方式分离句子。同时,jieba 还支持用户自定义的词库,可以有效地提高准确率。本文利用jieba分词工具对岗位描述中的中文短文本进行中文分词,分词代码及结果如图2所示。
经过中文分词处理,中文文本的每个句子将会以词语为基本单位完成划分,而有些词语不具有实际意义,对关键词的提取产生干扰,也会加大数据分析的工作量,造成提取的关键词无效,所以在分词处理以后,引入停用词来优化分词的结果。利用哈工大的停用词表对分词后的文本去除停用词,从文本中删除了无用的重复信息,以便关注更加重要的信息,并且不会对任务训练产生负面影响,还可以减少训练时间。
2.2 基于TF-IDF的关键词抽取
TF-IDF算法包含了TF算法和IDF算法两部分。TF(Term Frequency)算法是统计一个词在一篇文档中出现的频次,基本的算法思想为一个词在文档中出现的次数越多,对文档的表达能力就越强,但是缺少对文档的区分能力,在本文的分析中,表示某个岗位关键词在单个岗位中出现的频率。
(1)
计算TF值时,仅用频次来表示,长文本中的词出现频次高的概率会更大,这一点会影响到不同文档之间关键词权值的比较。因此,在计算过程中,对词频做归一化处理,即分母一般为文档总词数。
IDF(Inverse Document Frequency)算法是统计一个词在文档数据集的多少个文档中出现。算法表明一个词在越少的文档中出现,则其对文档的区分能力也就越强。IDF强调词的区分能力,但一个词既然能够在一篇文档中频繁出现,表明这个词能够很好地表现该篇文档的某些特征,可以降低一些在所有岗位中都通用或者常用的词语而对单个岗位影响不大的词语的作用[4]。
(2)
计算IDF时,采用拉普拉斯平滑在分母+1,避免部分新词没有在语料库中出现而导致分母为0的情况,增强算法的健壮性。TF-IDF算法从词频、逆文档频次两个角度对词的重要性进行度量。结合两种算法的优势即考虑词的出现频次,也考虑词对文档的区分能力。TF-IDF值越大,该词语就越适合提取为文档的关键词。它的优点是能过滤掉一些常用但不具有代表意义的词,同时保留影响整个文本的重要字词。这里应用于提取各岗位招聘需求关键词。根据字词在单个岗位中出现的次数和在整个市场所有岗位中出现的频率来计算一个词重要程度。
(3)
在信息传输、软件和信息技术服务业-软件开发工程师中,“嵌入式”和“开发”出现的频率分别为0.7和0.9,即:
TF(嵌入式)=0.7
(4)
TF(开发)=0.9
(5)
总共有1 800个岗位,其中有50个岗位包含“嵌入式”这个词,500个岗位包含“开发”这个词,可以得到:
(6)
(7)
(8)
(9)
可以看到,虽然“嵌入式”出现频率TF小于“开发”,但是TF-IDF大于“开发”,即TF-IDF得到的是在本行业岗位中出现频率高且在其他岗位中出现频率低的关键词,实现了对不同岗位的招聘信息的关键词提取。
根据该专业毕业生就业去向信息,统计该专业毕业生的主要对口就业方向及岗位,同时根据招聘网站上需求该专业学生相关岗位信息,得到该专业对口的主要就业岗位前五名为:电子工程师、硬件工程师、嵌入式开发、测试工程师、信息工程师。对招聘网站中的这几个岗位要求通过Python程序设计进行文本处理,分词后[5],利用TF-IDF方法提取出岗位要求的技能关键词如表4所示。
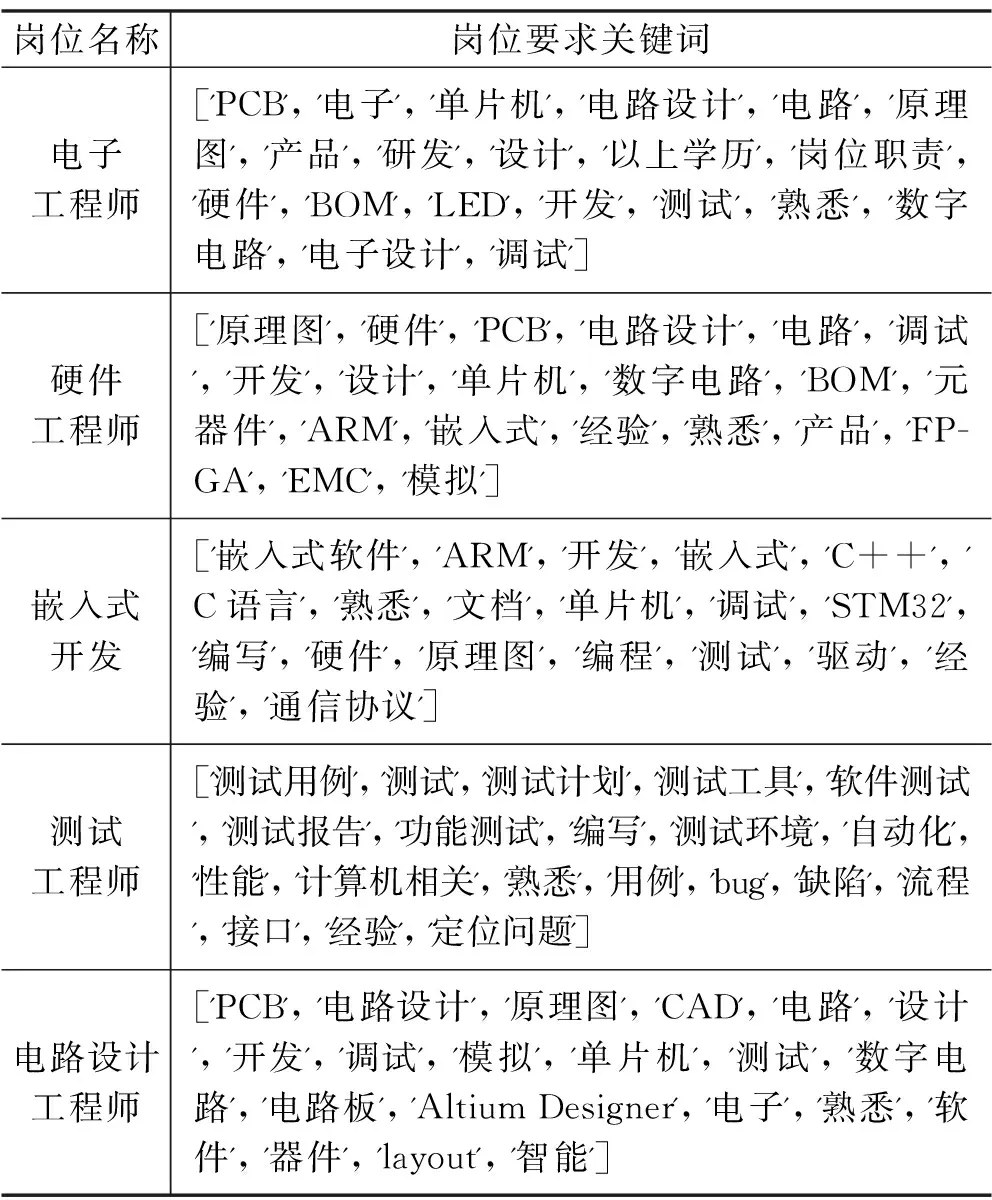
表4 专业对口岗位要求关键词
3 就业岗位匹配
根据学生所学课程技能和掌握程度与招聘岗位技能关键词进行匹配分析。推荐匹配度较高的岗位,供学生进行就业方向参考。如根据上述学生所掌握的知识技能表和招聘岗位的关键词进行匹配分析。熟练度为掌握,则匹配技能数乘以系数1;熟练度为熟悉,则匹配技能数乘以系数0.8;熟练度为了解,则匹配技能数乘以系数0.5。经过对专业技能和岗位匹配度计算,可以得到每位同学对应不同岗位的匹配度数值。数值越高说明该同学和对应岗位的需求越契合,可以在学生选择就业时提供对口的岗位建议,同时也可提醒学生对期望岗位所欠缺的知识技能,可以提早进行规划学习,提高自己的竞争力[6]。如表5所示,得到该名同学与电路设计工程师岗位要求的匹配度最高为5分,则可建议该同学在求职时多关注电路设计工程师相关岗位,有针对性地完善自己的简历及求职方向。

表5 岗位匹配
4 结语
本文基于TF-IDF算法对招聘岗位关键词的提取分析,从众多的招聘信息中提取出不同岗位的需求关键词,对求职与就业以及个人综合能力的提升都可以提供具有说服力的指导建议,实验结果能够较准确地对学生所学知识和就业岗位要求进行匹配,推荐适合学生的就业岗位,也可以提醒学生所欠缺的技能,提高学生对就业的认识,同时对高校的课程设置具有一定的参考价值,可以面向社会需求调整课程设置,提高学生的就业率。同样,本文对于学生自学的个性化技能分析不足,对学生的个性化就业与创业指导有所欠缺。
猜你喜欢
客联(2022年3期)2022-05-31
中国新闻周刊(2021年26期)2021-07-27
校园英语·月末(2021年13期)2021-03-15
乡村地理(2018年2期)2018-09-19
中华儿女(2016年14期)2016-12-20
信息安全研究(2016年4期)2016-12-01
中国卫生(2014年12期)2014-11-12
外语学刊(2011年3期)2011-01-22
