
基于历史文化知识图谱的问答模型研究
2024-01-22 01:11陈赛飞扬李泽宇王小雪
西南民族大学学报(自然科学版) 2023年6期
陈赛飞扬,殷 锋,李泽宇,王小雪
(西南民族大学计算机科学与工程学院,四川 成都 610041)
随着人工智能技术的不断进步和应用,知识获取方式正在发生革命性的变化.传统的搜索引擎已经不再是唯一的知识来源,新的知识检索方式逐渐崭露头角,其中通过问答方式获取相关知识成为一种备受关注的趋势.历史文献资源中蕴含着巨大的价值,通过将知识问答技术引入历史文化知识问答领域,在一定程度上弥补了该领域的空白,帮助我们深入挖掘潜在的历史意义和学术价值.
在历史文化领域,基于知识图谱的问答系统近年来开始涌现.陈定甲等[1]基于Vue框架构建了轻量化的历史文化知识图谱问答系统,帮助人们更高效地检索信息,但使用的知识匹配推理技术,在处理复杂问题时,难以有效识别问题的语法构造.Li等[2]针对以上问题,研究出了一种以BERT-BiLSTM-CRF网络为基础的命名实体识别方法,用于挖掘历史文化文本的上下文语义信息.邓祥旭等[3]在此基础上引入了自注意力机制,相较于BERT-BiLSTM-CRF模型,获得了更好的分类结果.
虽然在历史文化领域的知识图谱问答系统研究取得了一些进展,但总体而言仍面临挑战.如文献[4]指出,现有方法主要依赖于数据,仍需要大量手动标注来明确问题与答案之间的关系.这在特定领域如历史文化领域中导致了标注数据匮乏的问题,甚至完全没有标注数据,从而使问答模型的训练变得困难.
1 经典ERNIE的优势和局限分析
截至目前,主流的问答系统主要有三种构建方法,基于知识库的问答系统(Knowledge Base Question Answering,KBQA)[5]、开放域问答系统(Open-Domain Question Answering,ODQA)[6]、社区问答系统(community based question answering,CQA)[7].基于知识库的问答系统(KBQA)就其构建方法而言又可分为两类.一是基于信息检索[8]的方法,通过实体链接获得主题实体,学习如何将问题和潜在答案进行向量化表示,最后筛选答案.二是基于语义解析[9]的方法,该方法将问题转化为一种语义表示形式,随后用于检索相关答案.
近年来,随着深度学习技术的快速发展,利用深度学习技术对传统KBQA方法进行优化成为研究热点.其中谷歌在2018年提出基于transformer的预训练语言表示模型BERT[10],该模型因使用动态词向量在预训练过程中对文本的上下文表示作了充分计算,从而在问答理解任务时取得了较好成绩;因此被广泛应用于各领域问答系统中.如曾攀等[11]构建了蜜蜂领域知识图谱,并通过BERT进行问句意图分析.王志明等[12]提出了基于BERT的意图识别模型和基于BERT-BiLSTM-CRF的槽位填充模型来改进传统医疗问答系统,使其对用户的问句文本理解更加深入.近年来,构建在BERT模型基础上的一系列优化模型不断涌现,如Facebook的RoBERTa模型、百度的ERNIE(Enhanced Representation from Knowledge Integration)模型等.文献[13]对比了目前出现的各种BERT优化模型,发现百度的ERNIE相较于其他模型在中文问答任务中效果最佳.
ERNIE[14]模型是基于BERT构建的,相对于BERT,ERNIE改进了预训练语言模型的掩码策略,以便更全面地提取语义知识.与BERT不同,ERNIE将训练数据中的短语和实体作为一个整体单元来进行统一的掩蔽.这种方法的好处在于在学习过程中不会忽略整体的语料信息.此外,基于大量中文文本训练并结合图谱信息的ERNIE模型,能够在中文中有效地捕捉多样的语义模式.
但与文献[4]提到的问题相似,ERNIE在获取和理解历史文化领域文本信息的语义特征,以及捕捉该领域语言表征的能力仍存在一定的局限性.
2 经典ERNIE模型的改进
2.1 改进思路
Liu等[15]提出了一种知识支持的语言表示模型(K-BERT),将知识图谱与词向量相结合,提高了特定领域识别任务的性能.这为构建历史文化领域的知识图谱问答系统提供了有益的思路,有助于克服标注成本高昂和高质量数据匮乏等问题.
总体而言,借鉴先前研究成果和改进方法,针对上述问题,本次研究使用带有知识图谱的K-ERNIE代替ERNIE(Enhanced Representation through Knowledge Integration),增加句子的上下文信息有助于融合句子内容,提升特征提取能力;再融入长短期记忆网络(Long Short Term Memory,LSTM),以更深入地挖掘语义信息.这个整合增强了模型的语义理解能力,使其能够更好地处理丰富的语境信息.
2.2 K-ERNIE-LSTM模型的提出
K-ERNIE-LSTM的模型包含五个关键组成部分:知识模块、嵌入层、视图处理、掩码变换器和LSTM层.模型架构如图1所示,对于输入的句子,知识模块首要步骤是从知识图谱中提取相关的三元组,将原始句子转换为充满知识的句子树.接着,这个句子树会同时送入嵌入层和视图层,进一步转化为标记级嵌入表示和可见矩阵.此模型能够根据任务需求选择不同知识图谱,在进行嵌入层操作之前引入领域专业知识,解决了多元化词向量编码空间不一致和语句偏离核心语义的问题.

图1 K-ERNIE-LSTM的模型结构
1)知识层(Knowledge layer)
知识层是该模型的核心,用于整合外部知识源,其主要任务是从这些知识源中提取与文本相关的领域知识,并将其融合到模型中,以增强文本的语义表示.通过知识注入使模型能够更好地理解和处理特定领域的文本,因为它包含了领域专业术语、关系和实体等信息.
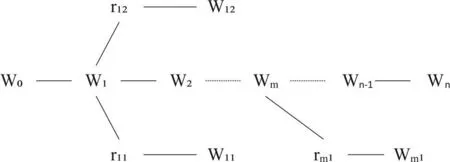
图2 句子树结构
2)嵌入层(Embedding layer)
嵌入层在K-ERNIE中的作用是将句子树转换为嵌入表示,以供Mask-Transformer处理.与ERNIE相似,K-ERNIE的嵌入表示包含了三个重要组件:标签嵌入、位置嵌入和区段嵌入,不同之处在于K-ERNIE的输入是句子树而非标记序列.
标签嵌入与ERNIE相似,但在嵌入之前需要对句子树的标记进行重新排列.位置嵌入用于恢复结构信息,确保重新排列后的句子能被正确理解.区段嵌入用于标识多个句子的边界,以便在合并多个句子时保持语义分离.这些嵌入层共同构成K-ERNIE的基础,为后续处理提供了丰富的文本表示.
3)视图层(Seeing layer)

(1)
4)掩码变换器(Mask-Transformer)
(2)
(3)
(4)
5)LSTM层(Long Short-Term Memory)
LSTM[16]保留了大部分循环神经网络(RNN)的特性,并成功地解决了梯度反向传播中的梯度消失问题.对于经常需要跨越长距离依赖的历史文化类型的文本数据,通过LSTM层可以捕获长期的上下文依赖关系,更好地处理长文本序列.
最后模型将文本标签特征向量映射到实际问答标签,基于上一层的输出,再进行降维和softmax函数归一化,计算标签的近似概率y,如式(5)~式(6)所示.

(5)
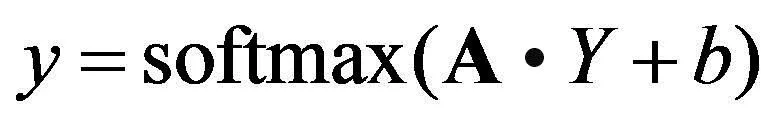
(6)


3 K-ERNIE-LSTM模型效能及分析
3.1 数据收集与知识图谱构建
3.1.1 历史文化领域知识图谱构建
数据集是命名实体识别的关键部分,它决定了在数据集上训练的模型是否适用于实际问题.我们主要选择两个知识图谱进行对比,首先是一个涵盖了中文领域广泛知识的通用化结构化百科知识图谱CN-DBpedia[17],该知识图谱以中文为主要语言.此外由于还没有针对历史文化这一特定领域的公共数据集,我们创建了一个自定义的命名实体识别数据集.数据获取的来源主要有两部分,首先关注了现实中的中国历史文化相关的书籍以及网络上的历史文化相关网页;然后通过百度百科爬取其中的历史文化百科条目.对于纸质书籍等关系型数据,主要通过人工收集整理的方式来构建语料库;对于网站中的半结构数据,通过爬取的方式来获取其中的三元组;对于txt文本数据这种非结构化数据,选取合适的自然语言处理技术进行知识抽取.具体获取的数据条数和数据格式如表1所示.

表1 数据获取详情
整理后的实体关系三元组存储在Neo4j数据库中,可通过查询语句获取相关数据.
3.1.2 问答语句数据采集
选取知乎历史文化版块中相关问答,通过Spacy爬取后作为原始数据,并对用户的自然问句进行文本分类.如表2所示将问句分为8种类别,每一种类别使用不同的标签标注,通过问题模板和属性标注库逆向生成K-ERNIE-LSTM模型的数据集,共18 681条数据.
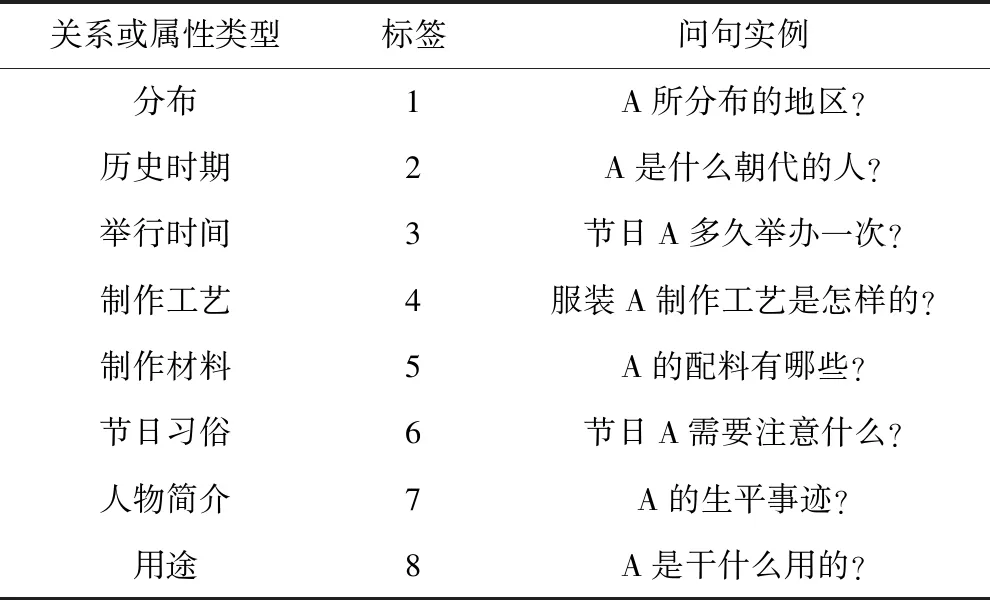
表2 问句标注示例
3.2 评价指标
本文通过精确率(P)、召回率(R)、和F1值来检验和评测模型效果,具体计算公式如式(7)~式(9)所示.
(7)
(8)
(9)
其中:Tp为正样本中被正确预测的数量,Fp为负样本中被错误预测为正样本的数量,Fn为正样本中被错误预测为负样本的数量.
3.3 实验参数
为了保证整个实验的顺利进行,采用了以下实验环境配置,如表3所示.

表3 实验环境
除此之外为了更好地反映基于BERT优化后的模型效果,根据Google BERT的基本版本[18],将K-ERNIE-LSTM与对比模型配置为相同的参数设置.最大输入文本128,学习率为0.000 02,dropout设置为0.5,掩码变换器设置为12层.
3.4 实验设计与结果分析
为了验证模型的效能,本节主要考虑从以下两方面设计对比实验.
1)使用公开知识图谱与自建历史文化领域知识图谱分别对ERNIE模型进行嵌入,对比通用知识图谱嵌入与特定领域知识图谱嵌入对模型效能的影响.
2)与其他预训练模型(BERT)相比,本文所使用的ERNIE模型是否表现出更优的性能.
3.4.1 不同知识图谱嵌入对比实验
本节主要选择常用的大规模通用知识图谱CN-DBpedia与自建知识图谱进行对比实验,图谱嵌入处理及模型实验流程如图3所示.

图3 图谱嵌入处理及模型搭建流程图
三种嵌入方式的实验结果如图4所示,从左到右分别为不使用知识图谱嵌入、使用CN-DBpedia知识图谱嵌入,以及自建历史文化领域知识图谱嵌入后模型对用户问句的识别效果.
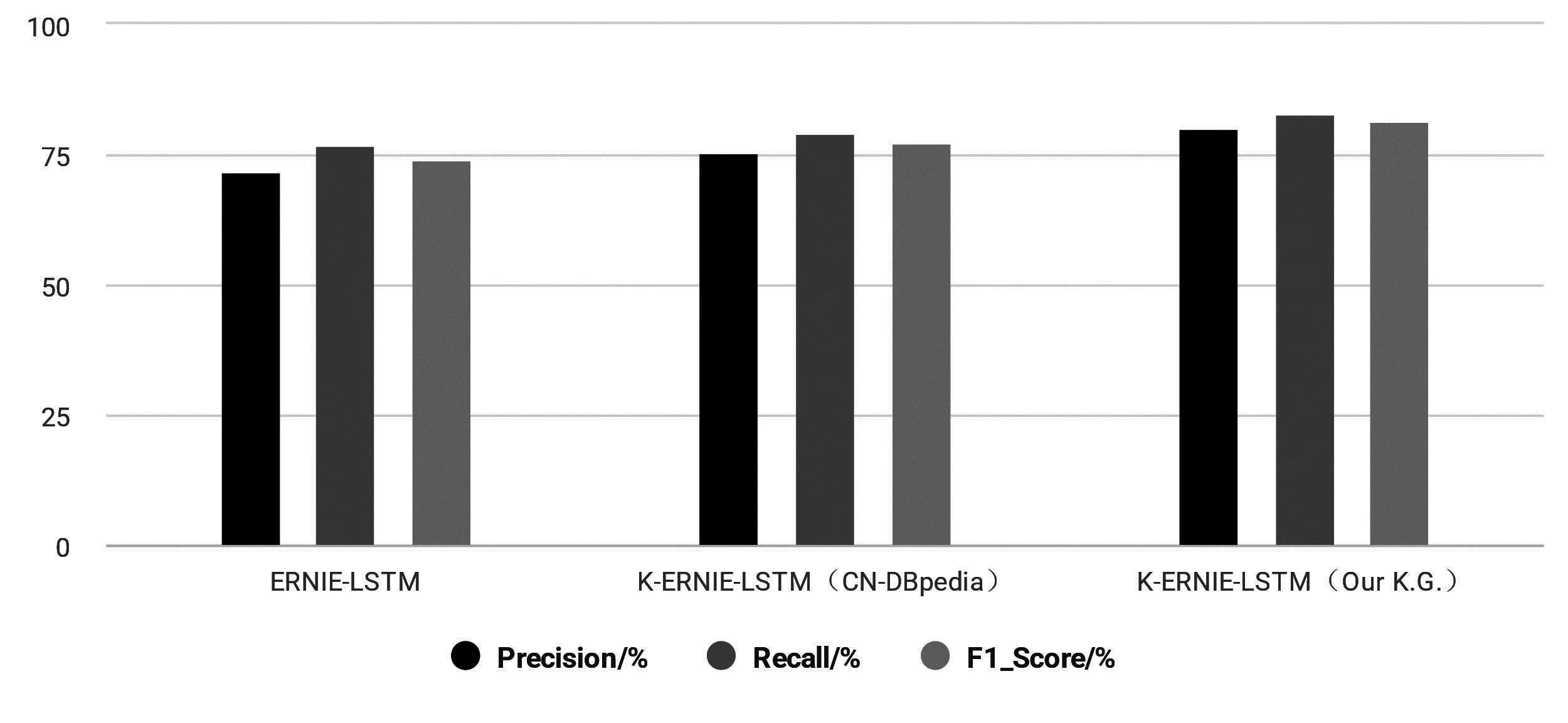
图4 不同嵌入方式的识别任务结果
图4可以看出,不嵌入知识图谱的模型准确率与F1值明显低于知识图谱嵌入后的K-ERNIE模型,说明了知识支持的K-ERNIE-LSTM模型在特定领域的识别任务中效果较好.而且使用特定垂直领域的知识图谱,具有更好的提升效果.因此,根据任务类型选择合适的知识图谱非常重要.
3.4.2 K-ERNIE-LSTM模型对比实验
上组实验分析了不同的知识图谱嵌入策略对模型效能的影响.本节实验主要分析不同的预训练模型,在都基于历史文化领域知识图谱的嵌入下,其性能差异.对比模型有:K-BERT、K-ERNIE、结合LSTM网络的K-BERT-LSTM、K-ERNIE-LSTM四个模型.实验结果如表4所示.
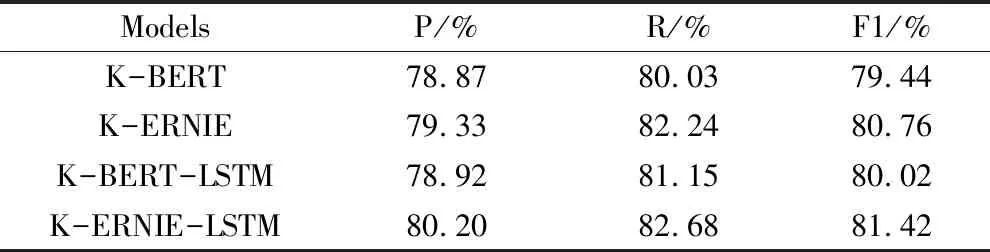
表4 不同模型的实验结果
从表4可以看出,得益于ERNIE模型能够更好理解中文语义表示,对于历史文化领域的问句识别任务,K-ERNIE模型表现要优于K-BERT模型.在结合LSTM模型后,两个模型性能均有所提高,且K-ERNIE-LSTM模型的表现仍优于K-BERT-LSTM模型.本文提出模型相较于K-BERT模型约有2个百分点的性能提升,证明了K-ERNIE-LSTM模型的有效性.
在上述研究中,我们进行了详尽的消融和对比实验,涉及了两种不同的数据集和四种不同的模型,实验结果可以得到以下结论:K-ERNIE-LSTM模型在准确率、召回率和F1得分三个性能指标上均有一定的提升.
4 结论
总的来说,针对历史文化领域的问题回答,存在准确性不足和深层语义匹配的挑战,提出了一种知识图谱嵌入的K-ERNIE-LSTM方法,与传统的算法相比,能有效识别用户的语义信息,其精确率、召回率和F1值有一定的提高.其真正优势在于特定领域中,使用相应的知识图谱,不仅提高了对注入知识的利用效率,还降低了大规模预训练的成本.本文所采用的方法在应用于小型的数据集时进行了测试,这导致了模型的一些限制.在未来的工作计划中,将扩大数据规模,以提高模型的泛用性,并进一步研究模型在长文本分析任务中的表现.
猜你喜欢
少先队活动(2020年12期)2021-01-14
开放教育研究(2020年2期)2020-03-31
青年生活(2019年23期)2019-09-10
中成药(2017年3期)2017-05-17
领导科学论坛(2016年9期)2016-06-05
现代语文(2016年21期)2016-05-25
中共南宁市委党校学报(2015年4期)2015-02-28
大连民族大学学报(2015年2期)2015-02-27
中国音乐教育(2014年7期)2014-02-06
杭州科技(2013年5期)2013-03-11
