
基于加权软投票融合模型的脉象信号识别研究*
2024-01-22 08:16刘启超林卓胜朱嘉健刘慧琳
世界科学技术-中医药现代化 2023年8期
刘启超,徐 红,2,林卓胜,朱嘉健,刘慧琳,吴 欣,冯 跃**
(1.五邑大学智能制造学部 江门 529020;2.维多利亚大学可持续工业与宜居城市研究所 墨尔本 8001;3.上海中医药大学基础医学院 上海 201203)
脉诊是中医四诊之一,对提示疾病的状态有重要意义。脉诊需要依靠医生的经验进行判断分析,主观依赖性强[1]。为了推动脉诊客观化发展,许多研究者将机器学习和数据分析等人工智能技术应用于脉诊,展开了脉象信号数据釆集以及数据集构建、提取脉象特征、分析与识别脉象信号等研究。
脉象信号数据是脉诊客观化的基础,然而在数据釆集以及数据集构建中数据类别不平衡问题在医学领域非常普遍。Zheng 等[2]对此使用SMOTE Tomek 算法加以缓解,在基于Stacking 融合模型中准确率提升了4.21%。王若佳等[3]指出数据不平衡将影响模型的分类结果,导致样本数量大的类别预测准确率较高、反之则准确率较低的情况。
目前,从时域、频域、时频域三部分提取脉象特征仍是研究的主要方向。张诗雨等[4]对脉象信号进行多尺度小波分解,根据所得高频细节分量和低频近似分量进行阈值量化处理,利用welch 法对其进行功率谱估计,然后利用小波多尺度分析、经验模态分解以及希尔伯特-黄变换3 种方法提取时-频特征,最后在平脉、实脉、滑脉、弦脉4 种脉象数据中使用支持向量机(Support Vector Machines,SVM)和随机森林(Random Forest,RF)精确率均达到93%。尽管这一方法在一定程度上提高了模型精确率,但是需要极其繁杂的特征提取和数据预处理,并对操作人员的专业背景要求高,在日常医学应用中常有众多病人以及相应的海量数据,时间成本和操作难度都将是巨大挑战。
针对上述不足,本文首先对于医学辅助信息进行探索性分析,并用热图形式呈现,达到初步快速特征筛选得目的。此外,直接使用tsfresh 库对巴特沃兹带通滤波器处理后的脉象信号提取特征向量,简化了提取过程。对于临床数据不平衡问题,通过边界合成少数类样本过采样技术(Borderline Synthetic Minority Oversampling Technique,Borderline SMOTE)解决。提出加权软投票融合模型,其将LightGBM(Light Gradient Boosting Machine,LGBM)、RF、XGBoost、梯度提升决策树(Gradien Boosting Decision Tree,GBDT)4 种机器学习算法进行融合并根据权重得出结果。因为本文数据集是表格数据,具有特征不均匀、样本量小等特点,所以对于这类型数据集深度学习很难找到相应的不变量,进而对于这一领域的数据集常选用传统机器学习方法[5-6],所构建的模型有其优势所在。
1 相关工作
1.1 加权软投票融合模型
投票法是通过多个模型集成进而降低方差,不同算法集成可能会比单个算法获得更好的效果[7]。软投票(Soft Voting)是通过使用输出类概率分类的投票法,为了进一步提升精度加入权重操作,使得原本软投票的普通加和操作,改为加权求和操作,拓扑结构如图1所示。软投票在模型构建中越来越受重视,如任师攀等[8]采用软投票策略对XGBoost 和LGBM 这两个模型进行融合,解决对客户违约风险评估的问题,最后在捷信集团公开的大规模消费信贷数据集上,取得了91.99%的准确率。
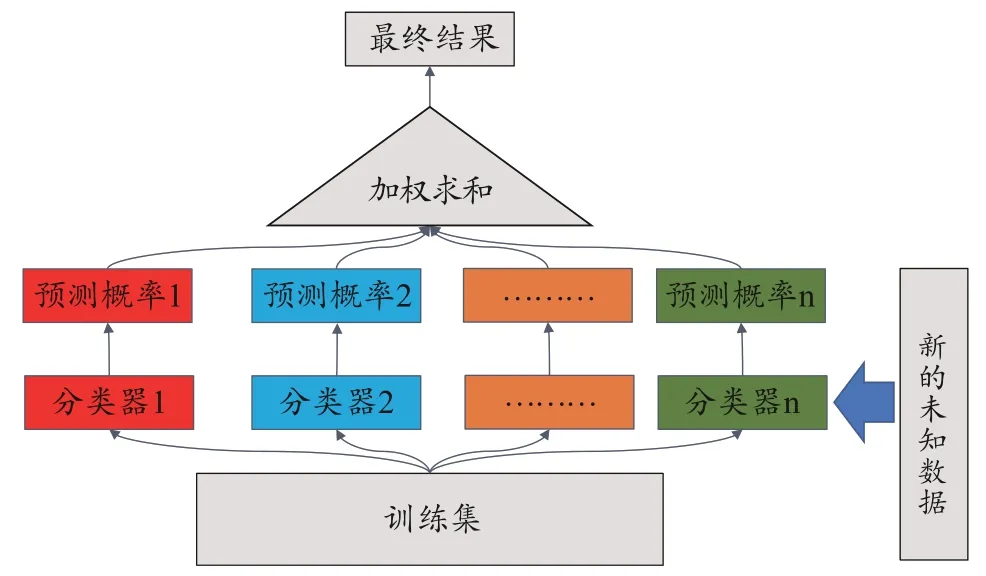
图1 加权软投票算法拓扑结构
1.2 数据不平衡
类别不平衡问题在医学领域是普遍存在的且受到广泛关注,众多研究人员对此进行深入研究。如王江月[9]提出基于局部信息的K 近邻引力平衡算法,意在算法层面对脉象数据不平衡进行解决。此外,在预测急性心肌梗死(AMI)<1 个月,全因死亡率<1 个月中使用了SMOTE和机器学习算法,同样有效的缓解数据不平衡所带来的精度问题[10]。所使用的Borderline SMOTE 是在SMOTE 基础上改进的过采样算法,该算法通过边界上少数类样本合成新样本,从而改善样本分布极其不均衡的情况。
2 研究方法
本文提出的脉象信号分类方法整体流程如图2所示,将脉象信号先经过预处理模块进行去噪处理,然后经过特征提取模块提取特征向量,此外,使用Borderline SMOTE 算法降低由于数据不平衡对于精度的影响,最后将所筛选出来的特征向量作为输入使用加权软投票模块对其进行分类,得出所属脉象。
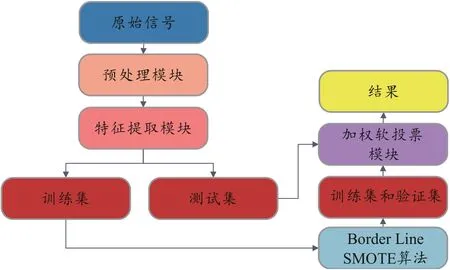
图2 加权软投票融合模型脉象信号分类实现流程
2.1 预处理模块
脉搏波是由心脏持续不断地跳动,进引起血液在血管中流动所造成脉的搏动,由于数据采集过程中易受外界干扰,所以需要对数据进行预处理,本文采用巴特沃兹带通滤波器对脉象信号进行滤波,去除0.2-20 Hz以外的噪声。
2.2 特征提取模块
首先,将预处理模块所得结果调用tsfresh 库进行特征提取操作,其会对滤波后的脉象信号进行单周期分割,获得脉象的单周期波形,进而tsfresh库会自动提取出如峰值、最大值和平均值等较为简单的特征,同时也会提取出如时间反转对称统计量等较为复杂的特征,此外tsfresh 库还可以通过假设检验对特征进行消减,得出最能解释趋势的特征。通过使用tsfresh 进行特征提取和初步的特征筛选操作,得出468 列脉象特征构成特征向量,其中包括脉搏波峰、波谷、最大值、最小值等特征。然后加入辅助医学信息,但是其中蕴含大量空值和无用特征向量,所以需要对其进行特征列的空值处理和探索性分析,提高分类准确率。使用tsfresh 库从一维脉象信号中提取出468 列脉象特征,运用探索性数据分析从辅助医学信息中得出9 列医学辅助特征,结合两者输出构成477 列特征向量进行特征筛选,选出重要性排名前21列特征向量作为输入数据,流程如图3所示。

图3 特征提取模块
2.2.1 辅助医学信息
为了充分利用中医信息采集设备所提供的信息,本文除脉诊信号外,还将周期(Periode)、脉象压力类型(Pulse pressure type)、脉搏率(Pulse rate)等由舌面脉经穴信息采集管理系统所提供的信息作为辅助医学信息,这些信息均是由信息采集管理系统在脉象釆集过程中自动生成并以.xlsx 表格形式存储,通过特征筛选操作得出对分类准确率最有力的9列医学辅助特征。在医学诊断中一些辅助医学信息往往对于最后的分类结果有较大帮助,如Le 等[11]进行多模型融合后加入辅助信息使得最后结果得到提升,Wang 等[12]在模型中加入辅助信息RR间隔,在F1分数中提高。
2.2.2 空值处理以及探索性数据分析
首先需对所有特征向量进行空值处理,直接删除空值占比大于30%的特征向量,小于30%大于0%则用中位数填充,避免影响之后的特征筛选步骤。其次,由于医学辅助信息中蕴含大量冗余和非必要特征向量,本文采用探索性分析达到初步特征筛选的目的,减轻特征筛选步骤中的操作复杂度。采用肯德尔相关系数(Kendall Correlation Coefficient,kendall’s r)绘制热图如图4 中所示。相关性系数取值范围包含-1-1,正值表示正相关,负值表示负相关,0 表示没有相关性,数值越大表示相关性越强。对所有相关性系数取绝对值后,删除与脉象信号类型(Pulse type)相关性数值小于0.05的特征向量,从22个初始医学辅助信息中挑选出Pulse Pressure Type、Pulse Rate 等9列医学辅助特征。
2.2.3 特征筛选
将提取到的468 列脉象信号特征向量和9 列医学辅助特征,绘制成一个.xlsx格式文件,共477列特征向量。利用极度随机树(Extremely Randomized Trees Classifier ,ET)挑选出特征重要性排名前21 列特征向量,排名依据是该特征被使用的次数、使用该特征树的平均信息增益以及使用该特征时的平均覆盖率,结果如图5所示。这种使用树模型进行特征筛选的方法已被越来越多人使用,如刘云翔等[13]采用基于RF的特征筛选算法,在保证精度的前提下将特征集缩小为1/2。

图5 前21列特征向量,横轴为重要性纵轴为最大值、中位数、Periode等特征向量
2.2.4 归一化
为了使数据更具有适应性,降低运算过程中数值复杂度,采用公式(1)中的归一化方法。其中Xmin表示每列中的最小值组成的行向量,Xmax表示每列中的最大值组成的行向量,max表示要映射到的区间,最大值默认是1,min 表示要映射到的区间,最小值默认是0,X表示每一个特征值,Xscale为归一化后的特征值。
2.3 Borderline SMOTE算法
实验数据集存在明显类别不平衡情况,最多类和最少类达到了1∶6.5 的比例,若采用不均衡样本训练模型,将导致分类模型泛化能力差并且容易发生过拟合。本文对数据使用Borderline SMOTE 算法,其针对的目标是和多数类混在一起的少数类样本。需要注意的是算法不能用在整个数据集,不然会导致测试集和训练集的数据有关联,进而干扰分类准确率,因而所用的Borderline SMOTE算法只用在训练集上。
2.4 加权软投票模块
由于数据集为表格数据,所以选用的是在表格数据中表现良好的机器学习算法RF、XGBoost、LGBM、GBDT 四种模型[14-17],每种模型构建两个总共8 个模型,并且内置不同参数,这是为了增加模型多样性提升精度。然后,采用加权软投票算法进行融合,建立六类脉象信号的分类模型,并用测试集进行分类性能检验,过程如图6 所示。由于软投票算法对于模型准确率提升有巨大帮助,所以得到广泛应用,如Yoo[18]等通过使用RAKEL 算法对SE-ResNet-34应用软投票模型,准确率达到88.49%。
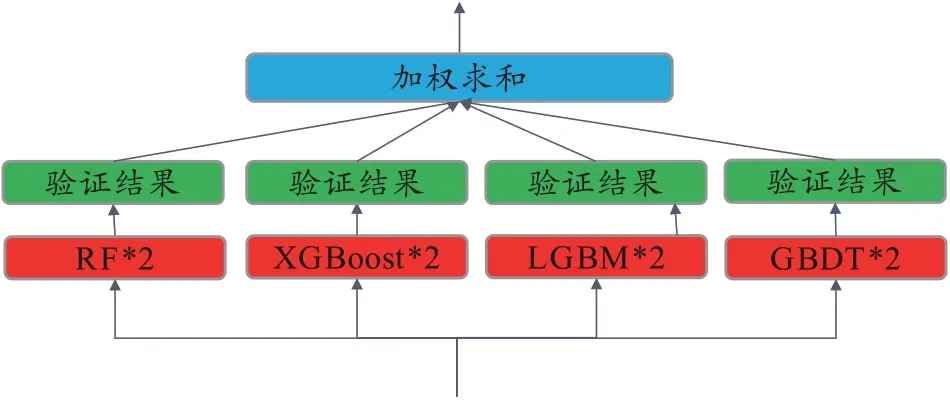
图6 加权软投票模块
3 实验与分析
3.1 实验数据
本文使用的六类脉象实验数据一部分采集自600位参与者,由五邑大学智能医学实验室5位经专业医师培训的科研助理在符合医学伦理委员会的伦理标准下完成。所使用的脉象采集设备是天津慧医谷科技具有二类医疗器械注册证的舌面脉经穴信息采集管理系统(型号MT-SM-01),系统对所采集数据自动标注,标注格式输出为.xlsx 表格格式。另一部分脉象数据则由采集设备厂商提供。本文实验部分共使用1302 例样本,其中数脉216 例、缓脉90 例、滑脉88例、沉脉433例、微脉63例、平脉412例,数据集文件是.xlsx文件格式存储。由于使用Borderline SMOTE 算法合成少数类,均衡后的数据集总共包含2082 例数据。训练集、验证集和测试集,所占比例为6∶2∶2。
3.2 实验评价指标
采用脉象分类模型研究中常用的准确率(Accuracy)、精确率(Precision)、召回率(Recall)和F1分数(F1-score)4种指标来评价模型的整体性能。
其中,TP 表示正样本预测正确的个数;FN 表示被错分为负样本的正样本个数;FP表示被错分为正样本的负样本个数;TN表示被正确预测的负样本数。在这4 个评价指标中,准确率代表着整体预测准确率,精确率代表对正样本结果的预测准确程度,召回率含义是在实际为正样本中被预测为正样本的概率,F1分数则表示precision和recall调和平均值。
3.3 实验结果与分析
3.3.1 特征提取结果与分析
通过数据筛选得出对于分类结果大有裨益的重要性排名前21列特征向量,其中包含最大值、中位数、Periode、Pulse Pressure Type 等,这21 列特征向量便是模型输入,输出为具体脉象类别。此外医学辅助信息的加入对于良好的分类准确率也有巨大贡献,这主要是因为Periode、Pulse Rate 等都与脉象信息有直接关系。在表1 中展示了加入医学辅助特征的RF 与未加医学辅助特征的RF 进行性能对比,加入之后的分类准确率提高了43.21%,充分表明加入医学特征是完全有必要的。此外,采用巴特沃兹带通滤波器对脉象信号进行去噪处理,然后直接使用tsfresh 库提取特征向量,相比于现今复杂的特征提取过程无疑是相当简洁的操作。

表1 单一机器学习模型和加权软投票融合模型性能对比

表2 各融合算法以及benchmark性能结果
为了验证特征筛选的有效性,将未经筛选的477 列特征向量和经过筛选的21 列特征向量在RF 上进行测试,运行时间从原本8 s 降到现在的1.3084 s,减少了6.6916 s 即降低83.65%,可以预见的是在加权软投票融合模型上的训练时间会减少的更多,经过特征筛选后确实有效的减少了运算内存占用和时间消耗。
在特征向量选取个数中进行了实验对比,以耗时少、准确率高作为综合性能判定标准,选择重要性排名前21 列特征向量。其他特征向量在加权软投票模型中的性能表现如图7所示。其中,200列特征向量准确率是87.36%,耗时641.7755 s;65列特征向量的准确率是89.65%,耗时232.4023 s;10列特征向量的准确率为87.11%,耗时66.9019 s。实验结果表明,其他三列特征向量数值相比于本文的90.04%的准确率,以及65.9466 s的耗时,具有一定差距。
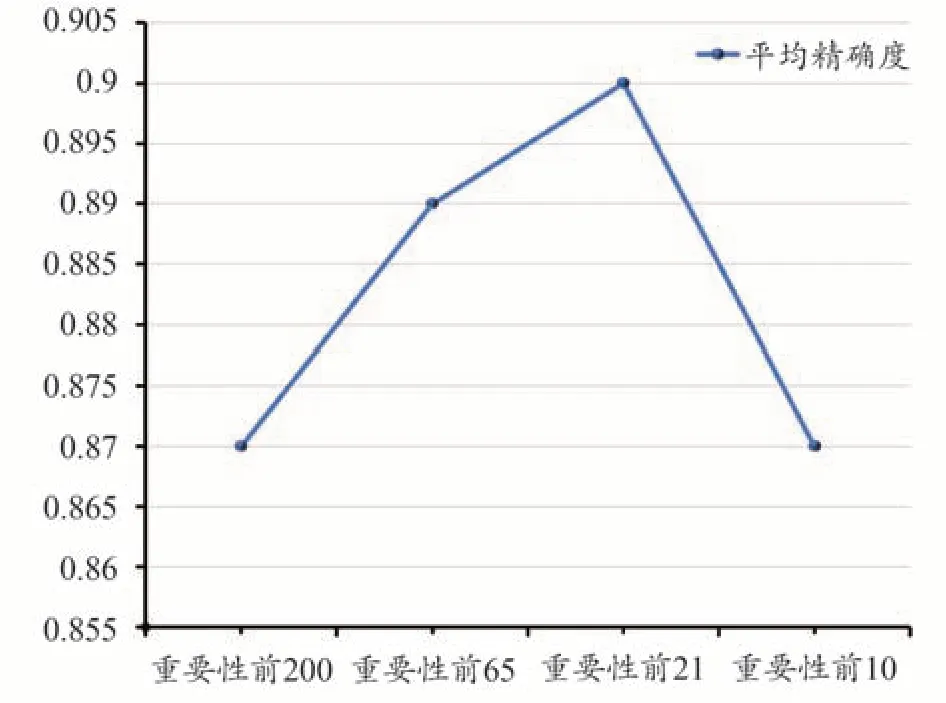
图7 不同数量特征向量性能表现
为了验证Borderline SMOTE 算法有效性,在RF 分类器中进行验证,所用数据集为训练集和验证集,分类准确率由原本的86.20%上升为87.36%,如表1 所示,这一方式被证实是有效的。除了Borderline SMOTE 算法,还考虑使用其他合成少数类算法分别为:普通的过采样SMOTE[19]、欠采样Tomek Links、ENN算法,以及两者的混合SMOTE+ENN 算法,但是由于本数据集的数据分布特点是与多数类混在一起的少数类较多,选择使用Borderline SMOTE 算法,并比较了这几类算法在RF 中的准确率,Borderline SMOTE 算法取得最好的准确率。
针对Borderline SMOTE 算法在平衡数据集中的性能表现,以及加权软投票融合模型在平衡数据集中的表现,进行表3 的实验。实验数据集是从原本的六类脉象数据集中选出沉脉和平脉两类脉象数据进行二分类,将433例沉脉删除21例,使其与412例平脉数量相等,然后选择在单一模型表现突出的5 种模型与本文所构建的加权软投票融合模型进行对比实验。模型输入是两类脉象的21列特征向量,输出为具体脉象类型。表3 中的实验结果表明,在平衡数据中加入Borderline SMOTE 算法并不会对模型性能有影响,这主要是因为该算法侧重于合成少数类,而平衡数据集不存在少数类的说法,自然不能对模型结果产生影响。此外,由于数据集变小了很多,导致所有模型的性能普遍下降,但是加权软投票融合模型仍能比GBDT准确率高1.41%、比RF准确率高2.83%。
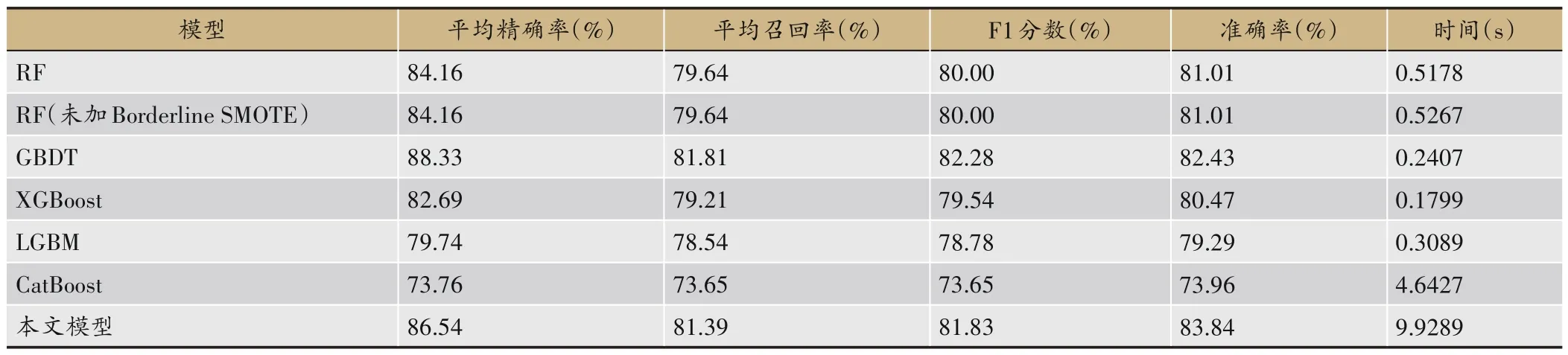
表3 平衡数据模型性能
通过上述对脉象数据进行的预处理与特征提取操作,可以得出对于模型分类结果最有帮助的21列特征向量,较好地反映出不同脉象中蕴含的形态信息,且探索性数据分析和数据可视化使得数据间内在关系得到充分挖掘,以清晰、准确、高效的方式传达数据模式以及洞察信息。此外,Borderline SMOTE 算法使得数据不平衡对于结果的影响得到有效缓解。
3.3.2 加权软投票融合模型实验结果与分析
模型训练环境cpu为i5-12500H,使用的编译器是pycharm,模型架构是pytorch。选用3种机器学习的加权软投票融合模型,其中的单一模型为RF、GBDT、XGBoost 和LGBM,选用这4 个模型是由于Grinsztajn等[20]进行了大量实验,结果证明对于表格数据集深度学习模型并没有传统机器学习模型中的树模型性能好。随后将12 种当今热门的机器学习模型应用在训练集和验证机中,分别为逻辑回归(Logistics regression,LR)、决 策 树(Decision tree,DT)、RF、AdaBoost、XGBoost、LGBM、CatBoost、ET、K 最近邻(KNearest Neighbor,KNN)、SVM、GBDT 以 及MLP(Multilayer Perceptron),实验结果如表1 所示,实验结果显示树模型的各项指标比起其他传统机器学习模型普遍更高。
此外,本文使用的是加权软投票融合模型,表1的实验结果显示该模型精确率达94.61%、平均召回率达93.55%、F1 分数达94.04%、准确率达90.04%,且耗时仅13.4836 s。为了增加加权软投票融合算法的说服力与现今热门的多种模型融合算法做实验对比,实验中使用了5折交叉验证分别评估每个模型在各性能指标下的表现。与此同时,为了对比融合前后性能变化程度,选用了在单一模型中综合性能表现最好的RF作为benchmark,与各融合模型进行对比如表2 所示。实验结果显示所使用的加权软投票模型比未加权重的软投票融合模型准确率高0.77%,比添加权重的硬投票(Hard Voting)融合模型准确率高0.39%,比基于Stacking 算法融合模型准确率高0.77%,在六类脉象数据集上准确率获得90.04%的较好成绩。实验结果表明加权软投票融合模型在脉象分类数据集上具有优越性。
加权软投票融合模型模型的构建主要分为两步:第一步是构建软投票模型;第二步是设置权重。首先在验证集中分别得出XGBoost、RF、GBDT、LGBM 四种模型在评价指标下的性能结果;其次,对模型进行略微调参,过拟合模型融合后可能会加剧模型过拟合风险,因此必须保证每个模型本身过拟合不严重,为此对模型进行抗过拟合处理主要方法就是设置模型中的参数,对RF 选择加入max_depth,对于GBDT 则选择加入max_features,对于XGBoost 选择增加迭代次数,对于LGBM 选择设置max_depth。最后,将4 种模型分别各构建两个,形成内置参数不同的8个模型,增加模型之间的复杂度,相互之间独立性越强,模型整体泛化能力越强。随后,进行模型权重设置,设置方法如下:①先将验证集中的准确率作为权重;②如果准确率没有提高则稍微降低权重精度,由原来的小数点后四位变成现在的小数点后两位;③加大精确率高的模型权重。
3.3.3 深度学习模型对比
不同于传统机器学习,深度学习的特征提取是直接由网络结构完成,这在一定程度上简化了进行特征提取的繁琐性,但是相比于本文使用tsfresh 库进行的特征提取并无太多优势,此外在所对比的Resnet+LSTM+SE、Resnet+LSTM+CBAM、Resnet+LSTM+ ECA、Resnet+LSTM+SE+ECA+CBAM、 Resnet+LSTM+SE+ECA+CBAM+多通道融合、ConvNeXt_tiny5个神经网络中,训练时的模型参数都超过了百万,这导致训练时间非常漫长,epoch 仅设置为500,在参数最少的Resnet+LSTM+SE 上使用五折交叉验证耗费8 h。模型输入与本文一致也是六类经过巴特沃兹带通滤波去噪的一维脉象信号和9 列经过筛选的医学辅助信息,文件以.xlsx 格式存储,输出为模型分类得出的具体脉象类型,所用损失函数为交叉熵,优化器为adam,学习率设置为0.0001,实验结果如表4 所示。可以看出众多当今热门的深度学习模型精度,与本文所用方法相比仍有较大差距。主要有两点原因:首先,传统机器学习中的树模型相比于深度学习模型更能处理特征不均匀、样本量小的数据[20],而通过加权软投票算法将多模型融合的操作再次提升了模型性能;其次,本文设计了较为完善的特征提取、筛选流程,能够得出对最终分类结果最为重要的特征向量。
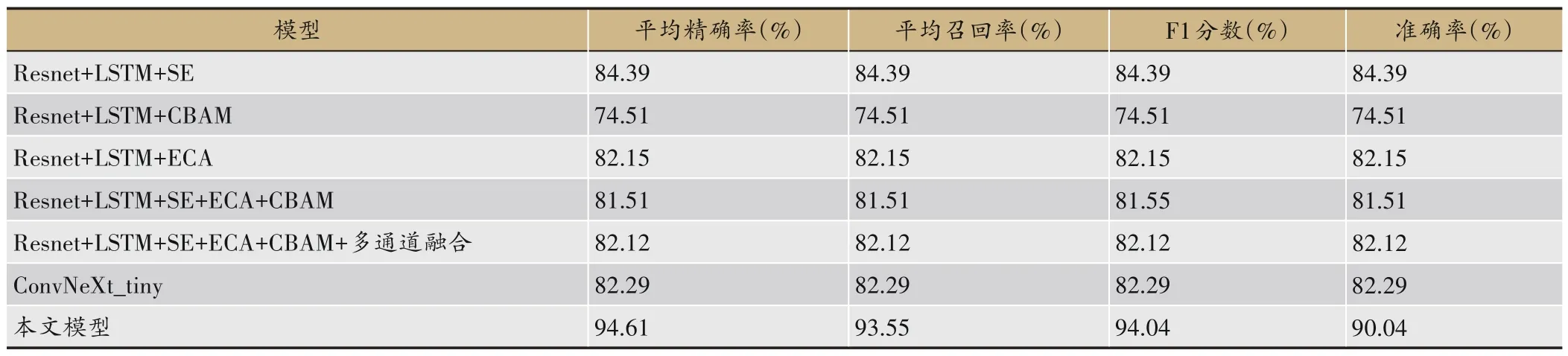
表4 对比深度学习模型精度
综上所述,本文采用六类一维脉象信号和辅助医学信息作为数据集,利用tsfresh库和探索性数据分析,分别得出脉象特征和医学辅助特征,相结合后进行特征筛选,将经过特征筛选的21列特征向量直接作为加权软投票融合模型的输入,这一过程有效保留了脉象信号中的形态信息剔除其中冗余信息,并且简单易操作的特征提取过程是一大优势。对于训练集采用Borderline SMOTE 算法解决数据不平衡问题,再构建加权软投票融合模型对算法处理后的数据进行训练,构建脉象分类模型,输出具体脉象类型。再者,为了解Borderline SMOTE 算法用在平衡数据集中的作用进行了实验验证,结果证明该算法对于平衡数据集并没有实际意义,更多的是用来解决数据类别不平衡问题。该模型由4 种机器学习算法,共8 个模型融合而成,可以达到较好的分类效果。此外,构建实验对比了当今热门的深度学习神经网络结构如注意力+Resnet+LSTM、ConvNeXt 等,实验结果显示本文所设计方法在各项评价指标上仍有较大优势。
4 结论
针对现存众多文章脉象信号特征提取繁杂,往往需要用到小波变换去噪、基于能量比的自适应级联滤波器去漂移、希尔伯特-黄变换提取时-频特征等方法,忽略了操作的复杂性和临床医学所需的实用性。此外,脉象信号数据不平衡问题一直是影响准确度的重要因素。本文在特征提取领域选择对去噪后的数据直接采用tsfresh 库构造特征向量的方法,避免复杂的特征提取流程,随后加入选出的9 列医学辅助特征提升准确度。通过特征筛选得出重要性前21列特征向量,在简化数据集的同时尽量保留更多的细节特征。使用Borderline SMOTE 算法运用在训练集上,改善数据不平衡对分类准确度的影响。最后所提出的加权软投票融合模型,相比现存研究,在一定程度上缓解了单一模型的性能上限低和过拟合风险高的问题,可以获得更高的准确率。实验结果表明,所提出的脉象分类方法是有效的,为脉象信号的分析与识别研究开辟了新的视角和方法。在后续工作中,将进一步研究更具临床实用性的脉象信号分析方法,提高脉象信号的识别率。
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02
保定学院学报(2022年2期)2022-04-07
世界科学技术-中医药现代化(2021年9期)2021-12-31
中国临床医学影像杂志(2019年2期)2019-04-25
电子制作(2018年19期)2018-11-14
许昌学院学报(2018年4期)2018-05-02
中华建设(2017年1期)2017-06-07
自动化学报(2017年11期)2017-04-04
湖南中医药大学学报(2015年1期)2016-01-06
噪声与振动控制(2015年4期)2015-01-01
