
改进的神经渲染方法在建筑施工场景中的应用
2024-01-21 15:14:12张在成
计算机与现代化 2023年12期
张在成,李 健
(陕西科技大学电子信息与人工智能学院,陕西 西安 710021)
0 引 言
通过快速且准确地构建模型来记录真实世界中地形和建筑施工场景是目前计算机视觉领域中的热点问题。建筑施工中的3D技术是借助计算机系统构建出建筑施工的物理模型,使用神经渲染技术对场景展示可以实现对建筑施工模型和计算机模型的交互。
传统的3D建模技术中存在细腻度低和计算量大的问题,神经渲染是一种深度图像或视频生成方法[1],能显式或隐式地控制场景属性(如照明、几何体、外观等),更高效地完成对施工场景的数字化展示。早期的方法一般使用“拼图”[2]的方法实现视觉的合成,但是合成的范围十分有限。为了获得更多角度的颜色值,Niemeyer 等人[3]通过一种占位方式来表示三维建模中的几何构造,并采用数值的方式找出模型中表面结构与各条光线之间的交集,从而得到神经网络的输入。Sitzmann 等人[4]在接下来的任务中,通过检测每个坐标在三维空间中所对应的颜色和特征向量,并引入一个可微函数来判断物体表面的情况,虽然这种方法是由循环神经网络所构成的。但是,以上方法仅仅解决了空间上难度相当小的三维空间几何构造,而且所绘制的结果也过于平滑。
针对上述问题,Mildenhall 等人[5]提出的神经辐射场(NeRF)利用输入图像作为信息进行监督,为三维空间中的复杂几何结构拟合出准确的隐式函数[6],从而对场景中不同角度的视觉进行合成。NeRF在神经网络的权值内编码表示场景,将3D 位置和观看方向映射到神经辐射场,改进了之前的离散体素网格方法,能够渲染具有复杂几何结构场景的新颖场景视图。在室内场景中,相较于早期的方法能呈现更多角度的合成效果,并且能够解决更复杂的几何结构的渲染。
在室内光线条件较好的环境中神经辐射场渲染具有很好的效果,然而在室外光线复杂的环境中进行渲染时,会存在光线难以捕捉等问题,因此神经辐射场不能满足室外施工环境的视觉合成应用。针对以上问题,Martin-Brualla 等人[7]提出了NeRF-W 的方法,提出了一种外观编码器,将输入图像和输入图像的深度缓冲区作为输入,该外观编码器能观察输入,并将输入图像中的光照和场景的几何体关联来学习更复杂的几何外观提高视觉合成效果。但此方法把场景视为一个整体。针对室外环境因背景范围太大而导致视觉合成时出现伪影等问题,Zhang 等人[8]通过将场景分为背景和前景来进行渲染,解决了范围对视觉合成的影响,但此方法没有很好考虑室外光照对视觉合成的影响。
针对在室外施工场景进行视觉合成时,会因为室外场景的光照难以捕捉、施工场景的背景和前景差异太大,导致视觉合成效果不足等问题,本文使用一种预训练的外观编码器加入渲染网络中,并在渲染时将场景分离为前景和背景。该方法能够实现复杂、多对象的场景表示,同时能够解决室外光照和范围的影响,实现室外施工场景的视觉合成。本文的主要工作如下:
1)通过输入的室外施工场景图像对整个场景进行表示,实现从各个视角的神经渲染。
2)在渲染网络中加入预训练的外观编码器,降低室外光照影响,提高室外施工场景的视觉合成效果。
3)通过把施工场景的前景和背景分开渲染来减少施工场景范围对神经渲染的影响。
1 相关工作
1.1 场景表示
视图合成任务是使用对象或场景的观察图像从新的角度渲染出逼真的图像,图形学和计算机视觉领域先前的工作通过使用计算机图形的传统3D 的表示,这些表示适合高效渲染。对于密集采样的场景,利用光线渲染技术[9]采样光线之间插值来高效地渲染新视图。稀疏图像采样进行渲染时通常会重建场景的显式3D 表示。基于体素[10]的表示方式可以通过标准的深度学习体系结构进行处理,但即使在稀疏数据结构上操作,体素的分辨率也相对较小。基于点云[11]的表示方式内存效率更高,但由于缺少连接信息,它们需要密集的后处理。基于网格[12]的表示方式不执行后处理,但通常需要可变形模板网格,将几何体表示为三维面片的集合,从而产生自相交集。基于神经网络编码的隐式表示[13]方式具有连续性和高空间分辨率,可以隐式地描述几何体纹理,并且不会离散化空间,因此具有更好的渲染效果。针对目前缺少对室外施工场景的表示,本文主要通过隐式表示方式对室外施工场景进行建模,从而实现新颖视角的视觉合成。
1.2 场景重建
恢复图像捕捉过程中丢失的三维信息是计算机视觉的长期目标之一[14],传统的场景重建方法首先使用运动中的大规模结构生成稀疏重建,然后执行多视图立体(MVS)[15]或变分优化来重建稠密场景模型。然而,该方法仅假设单一的外观,或者简单地恢复场景的平均外观。
最近,Hedman 等人[16]引入了一种神经网络,用于计算与视图相关的纹理映射的混合权重,从而减少重建区域中的伪影。然而,神经场景渲染能够利用深度神经网络学习潜在场景表示,允许生成新视图,但仅限于简单的合成几何体。本文在这些方法的基础上,首先使用SFM[17]算法来得到相机参数,再利用MVS 来转换数据格式得到需要的数据。在基于图像的渲染中,通过使用代理几何体将输入像素扭曲到输出中,生成新视角下的图像。
1.3 基于图像的绘制
给定视图的密集采样,可以通过光场采样插值技术[9]重建不同视角下渲染出的新颖视图。对于具有稀疏视图采样的神经渲染,利用计算机视觉和图形学的技术在观察视图中进行传统的几何和外观描述,从而合成不同视角下的新颖视图。利用网格对环境进行表达是一种新方法,其外观可以是漫反射[18]或依赖于视图的。该表示方式可以通过可微光栅化器[19]或路径跟踪器[20]直接进行优化,以使用梯度下降法重现一组图像的输入。由于局部极小值或场景条件较差,在优化之前需要具有固定拓扑的网格进行初始化,基于图像重投影的网格优化变得比较困难。所以该方法通常不适用于无约束的真实场景。
另一种合成新视图的方式是利用体积表示一组输入的RGB 图像数据集。体积的描述方式能够在空间中表示复杂的结构,能很好地进行梯度的优化,并且相比于网格的方式,能降低干扰视觉的伪影影响。本文引入用于新颖视图合成的体积渲染,回归密度和颜色的三维体积,将潜在代码解码为三维体,然后通过体绘制获得新图像。早期Kutulakos等人[21]使用体积表示的方法为观察到的图像网格预测颜色。Mildenhall 等人[22]为了对网络进行更好的训练,使用了更多的大型场景,网络对输入的一组场景图像进行体积表示,然后使用alpha-compositing 或光线合成在测试时对新颖视图进行神经渲染。虽然这种体积的表示方式对合成的效果有显著的提高,但由于其离散采样时间和空间复杂性低的本质,在渲染高分辨率图像时还需要在空间中进行更精细的采样。
2 本文方法
如图1 所示,本文问题定义为利用所提出方法在室外施工环境的图像集中对场景进行隐式表示,然后通过神经渲染得到各个视角的图片,达到对施工工地的场景展示。

图1 整体模型结构
针对基础的NeRF 工作加入外观编码器减少室外光照对于视觉合成的影响,在最后渲染合成视图时,通过把施工场景中的静态物体和远处的景物分开渲染来减少范围的影响。通过加入上述2 部分工作,提高室外施工场景的视觉合成效果。
2.1 算法设计
给定静态场景的多视图图像,本文依据NeRF 的方法重建代表形状的不透明度场σ和代表视图相关表面纹理的辐射场c,其中σ和c都隐式地表示为多层感知机(MLP)。不透明度场是根据3D 位置计算的,辐射场由三维位置和观察方向参数化。因此:σ(x)表示不透明度为位置函数,其中,x∈R3;c(x,d)指的是作为位置和观察方向的辐射度,其中,d∈R3。
理想情况下,对于不透明材料,σ会在地面真实表面位置达到顶峰值,同时c降低到表面光场[23]。对于给定的一组训练图像,如公式(1)所示,对给定的n个训练图像,通过最小化地面真值观测图像Ii和在相同视点利用σ和c渲染图像(σ,c)之间插值的随机梯度下降方法来优化σ和c。
通过光线捕捉隐式体积σ和c来计算神经渲染图像(σ,c)的每个像素值,如公式(2)所示,在给定光线r=o+td,o∈R3,d∈R3,t∈R+,颜色通过计算积分得到:
当在优化复杂的神经辐射场时,其分辨的收敛偏低,为了补偿网络的光谱偏差并合成更清晰的图像,如公式(3)所示,使用位置编码γ,将x和d映射到傅里叶特征中:
其中,k是一个超参数,用于指定傅里叶特征向量的维度。
2.2 外观编码器
如图2 所示,为了减少光照影响,捕捉不同外观下输入视点Bi和输出图像I1之间的关系,需要进行多模态图像翻译[24]。在这样的表述中是学习潜在的外观向量,该向量捕捉输出域I1无法从输入域Bi推断的变化。通过Z=Ea(I1,Bi)计算潜在外观向量,其中Ea是一个外观编码器,将输出图像I1和缓冲图像Bi作为输入,让外观编码器Ea观察输入可以关联I1中光场,在缓冲图像中使用场景几何体,减少室外光线对视觉合成的影响。

图2 外观编码器效果图
为了训练外观编码器Ea和渲染网络R,首先需要找到场景中的最有效组合,但是这种组合仍然有缺点,它无法很好地模拟罕见的外观。为了提高模型的表达能力,本文采用在代理任务上独立地对外观编码器Ea进行预训练来稳定渲染网络和外观编码器的联合训练。该任务是使用输入图像之间合适的距离度量来优化输入图像嵌入到外观潜在向量的过程。如果2 个图像的距离度量下降,那么它们的外观嵌入也应该在外观潜在空间中接近,将输入图形嵌入外观潜在空间这种分阶段的训练方式可以使用更简单的模型来捕捉更复杂的外观。
阶段性培训方法的关键是外观预训练阶段,在该阶段需要在代理任务上独立地对外观进行预训练。然后,训练渲染网络R,同时固定Ea的权重,使渲染网络能够找到输出图像与代理任务生成嵌入之间的相关性。这种分阶段的方法简化并稳定了神经渲染的训练,去除了周期和跨周期一致性的损失与潜在向量重建的损失,使训练更简单,正则化项更少。
2.3 前景和背景渲染
由于公式(2)中的体积渲染公式是在欧几里得深度上的积分,当真实景物动态范围很小的时候,积分可以通过使用有限个样本进行数值逼近。然而对于室外施工环境而言,动态深度范围可能会很大,因为背景可以任意远离。在如此高的动态深度范围会导致神经辐射场的体积场景表示中存在严重的分辨率问题,因为要合成照片的真实感图像,公式(2)中的积分需要在前景和背景区域都具有足够的分辨率,这很难通过三维空间的欧几里得参数化简单采样来实现。
如图3 所示,本文采用一个倒球面参数化来解决这个限制,更好地完成自由视图的合成。将场景空间划分为2 个体积,一个内部单位球体和一个外部体积,外部体积由一个覆盖内部体积补体的倒球体表示。其中内部体积包含前景和所有相机,而外部体积包含环境的其余部分。这2个部分由2个独立的神经辐射场建模,要渲染光线的颜色,将分别对其进行光线投射,然后进行最终合成。由于场景的这一部分有很好的边界,所以不需要对内部的神经辐射场进行重新参数化,对于外部神经渲染,采用反向球体的参数化。外部体积中的3D 点(x,y,z)1,可以通过(x′,y′,z′,1/r)来重新表示,其中t∈(t′,∞)是沿着与(x,y,z)相同方向的单位向量,代表球体上的一个方向,而0<1/r<1是向着该方向的反向半径,指向球外的点r⋅(x′,y′,z′)。

图3 场景内容不同参数化
与欧几里得空间不同,在欧几里得空间中,物体可以与原点保持无限距离,重新表示的四元组中的所有数字则是有限的。这不仅提高了数值的稳定性,还遵循了更远的物体应该获得更少分辨率的事实。可以通过直接投影光线到有界体积来渲染相机光线的颜色,即经过拆分把公式(2)中的积分划分为2 个部分。其中光线r=o+td被拆分为2 个部分,当t∈(o,t′)时认为在球体之内,t∈(t′,∞)则在球体之外。这样可将公式(2)改写为:
在欧几里得空间中计算公式(5)和公式(6)中的第1 部分所以使用σin(o+td)、cin(o+td,d),而公式(6)中的第2 部分值需要在倒球面空间中计算背景σout(x′,y′,z′,1/r)、cout(x′,y′,z′,1/r,d),为了计算第2 部分中的r=o+td,需要先计算σout,让射线在点a处相交,与中心垂直交点为b,点a通过解|o+tad| = 1 得到,点b通过解dT|o+tbd| = 0 得到,通过将向量a沿着向量b×d旋转得到(x′,y′,z′)。计算得到σout后,只需从区间[0,1]抽取有限的数量的点来计算第2部分。
从物理层面看外部球体,通过一个虚拟的摄像机来观看,该摄像机的图像平面是场景原点处的单位球体,因此3D 点(x,y,z)投影到图像平面上的(x′,y′,z′)用点的深度或视差。从这个角度看,仅适用于向前捕捉的NDC[25]参数化与本文的表示相关,因为它使用虚拟针孔相机,而不是球形投影面。从这个意义上说本文采用的反向球体与最近在视图合成工作中提出的多球体图像的概念相关[26]。
3 实 验
3.1 实验方案
本文为了展示捕捉室外施工环境下复杂场景的视觉合成结果,将在某工地采集的室外施工场景数据集进行训练和测试。本文实验采用Pytorch 深度学习框架,在一台显存为16 GB 的Tesla V100 的GPU 主机上进行分布式训练。
实验首先采集RGB 图像,通过COLMAP 和MVS进行处理得到需要的相机参数等数据,并且通过外观编码器的预训练得到向量Z,把得到转换的数据和向量Z输入渲染网络中进行渲染得到2 个部分σ和c,最后通过改进的体绘制方法得到最终渲染图像。
3.2 定量分析
在神经渲染中对图像质量的高低进行评价时可以使用实验得到的图像峰值信噪比(Peak Signal to Noise Ratio,PSNR)和结构相似性(Structural Similarity,SSIM)进行判定。PSNR 和SSIM 的数值与合成的图像质量成正比。给定一个大小为m×n的干净图像I和噪声图像K,公式(7)为均方误差定义。
通过比较图像的结构信息改变来判断图像的失真程度,结构相似性如公式(9)所示。
其中,μ、xμy分别表示样本x,y的均值、分别表示样本x,y的协方差;σxy表示样本x和y的协方差。
当计算SSIM时,从图片取一个N×N的窗口,通过滑动窗口进行计算再通过取平均值作为全局的SSIM。
在室外施工工地采集的7 个施工场景上进行训练和测试,定量实验结果如表1所示。
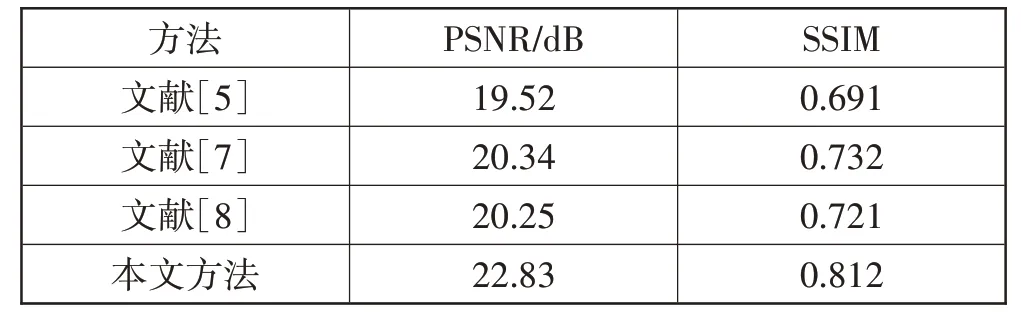
表1 施工场景的平均PSNR和SSIM
通过实验结果得知本文改进后方法的PSNR 和SSIM 在几种方法中表现最好。由表1 可以得知改进后的视觉合成算法在室外施工场景中PSNR 和SSIM相较于文献[5]、文献[7]和文献[8]的方法至少提高了12.2%和10.9%。
3.3 定性分析
图4 展示了本文方法的定性结果,总体上呈现了在对室外施工场景进行视觉合成时本文所提出的方法能够更好实现室外施工场地下的神经渲染,并且针对于室外施工场景中由于背景范围和施工场景中的物体较远的问题,本文通过使用前景和背景的分离渲染一定程度上减少了伪影的影响。而对室外光照难以捕捉的问题本文则通过引入一个预训练的外观编码器,把生成的向量加入渲染网络,减少光照对于室外施工场景视觉合成的影响。
施工场景下的人员进行新颖视角合成后,对其中一个视角进行分析,通过对比文献[5]、文献[7]和文献[8],可以看出本文方法能够提升新视角下的图片渲染质量。图5 输出图像中的上框可以说明通过分离前景背景进行渲染提高了远距离下的渲染质量,而图5 中的下框则说明加入外观编码器后一定程度上减少了光线的影响。

图5 单个视角下的视图对比
3.4 消融实验
为了进一步说明本文提出的在网络中加入和不加入预训练的外观编码器、是否把前景和背景分开渲染对新视角下渲染的图片的质量提升,对所采集的施工工地场景进行消融实验。为了便于比较,把2 个模块分开进行消融实验,评价指标依然采用峰值信噪比和结构相似性进行定性说明。表2 从一个场景中定性地显示了加入外观编码器对渲染效果的提升。加入外观编码器和把前景背景分开渲染后PSNR 和SSIM 都上升了,提高了渲染的质量。可以看出外观编码器对图片渲染质量的影响更大,进一步说明室外施工场景下提高光线捕捉的重要性。
4 结束语
针对室外施工环境,本文提出了一种从RGB 图像集渲染新视角的视觉合成方法。基于神经辐射场对施工场景进行隐式表示,首先通过SFM 算法进行稀疏重建得到相机参数,使用预训练的外观编码器输出向量加入渲染网络中降低室外光照对视觉的影响,在渲染网路中利用前景和背景分开训练的方法,解决室外施工环境中范围太远的合成效果问题。实验表明本文提出的模型能在室外施工工地实现不同的视角的视觉合成且效果更佳。但本文针对的是静态下的施工环境,今后的工作将针对施工工地中的施工人员进行动态的视觉合成研究。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31 08:59:12
阅读(快乐英语高年级)(2022年6期)2022-06-17 04:48:48
家庭影院技术(2021年10期)2021-11-20 06:08:52
成都信息工程大学学报(2018年3期)2018-08-29 01:08:40
中学生数理化·中考版(2017年6期)2017-11-09 02:46:46
非公有制企业党建(2017年10期)2017-11-03 02:26:27
紫禁城(2017年6期)2017-08-07 09:22:52
现代兵器(2017年4期)2017-06-02 15:59:24
现代兵器(2017年4期)2017-06-02 15:58:14
电子设计工程(2017年20期)2017-02-10 03:39:29
