
基于注意力机制优化组合神经网络的电力缺陷等级确定方法
2024-01-19 08:16:50程宏伟高莲于虹李鹏
电测与仪表 2024年1期
程宏伟,高莲,于虹,李鹏
(1. 云南大学 信息学院,昆明 650500; 2.云南电网有限责任公司电力科学研究院,昆明 650500)
0 引 言
随着经济社会的进步,电网的现代化建设得到了有效的发展,但现代化电网运行过程中产生了大量的视频、图像和文本等非结构化数据[1],如何对这些非结构化数据进行挖掘,促进电网的自动化和智能化是目前亟待解决的问题。非结构化数据中电力缺陷描述文本蕴含着丰富的电力设备健康状况信息,基于其根据设备缺陷的严重程度进行快速准确地等级划分有助于缺陷的及时消除和检修维护工作的开展,保障电网的安全稳定运行[2]。目前,缺陷等级由运维人员根据电力设备主要部件和对应现象标准将缺陷描述划分为其他、一般、紧急、重大四个类别[3-4],但缺陷情况的复杂多样使运维人员难以准确判定且受到不同运维人员知识经验的影响,缺陷等级判定的一致性难以得到保障,进而影响电力缺陷的及时消除和电网的安全稳定运行。因此,如何实现缺陷描述的准确分类,指导设备检修工作的及时开展,减少因分类不准确造成更大范围的电力系统故障,是当前急需解决的问题[5]。
传统的文本分类算法主要有支持向量机、决策树、朴素贝叶斯和K近邻等[6]。但传统文本分类算法存在文本特征表达弱、文本数据高度稀疏和特征项间相互干扰的不足,且缺少对大规模复杂化问题的泛化能力,因此分类效果较差[7]。随着深度学习算法的发展和应用,文本分类方法得到进一步丰富,Kim在2014年首次将卷积神经网络(convolutional neural network, CNN)应用于文本分类,通过多个不同尺寸的卷积核对词向量进行特征提取,实现了文本分类[8];Lai在2015年构建了CNN和循环神经网络(recurrent neural network, RNN)相结合的文本分类网络结构,得到了较高准确率的文本分类模型[9]。
近年来,由于自然语言处理领域的快速发展,文本处理逐渐应用于电力系统。如文献[10-11]建立了基于K近邻的分类模型,并以断路器作为测试对象,验证了自然语言处理技术在电力系统应用的有效性和可行性;文献[12]提出了基于语义框架的电网文本挖掘模型,实现了缺陷描述句子成分的划分并应用于电网设备的信息统计中,为电力工程建设提供参考和验证;文献[13]采用深度语义学习对变压器运维文本进行挖掘,实现了对变压器运行状态的确定;文献[14]利用双向长短时记忆网络(bidirectional long short-term memory, BILSTM)对典型故障案例进行挖掘并以变压器为例验证了模型的准确性;文献[15]提出了基于CNN的电力缺陷分类模型并以变压器为例验证了模型准确率优于传统的机器学习。
但是,上述文献在解决电力缺陷描述时均存在一定的不足。首先,对于缺陷描述短文本单一的模型具有一定的局限性很难对文本有效信息进行充分提取,例如,常用的CNN使用卷积核对文本的局部信息进行特征构建,但忽略了文本的序列信息;RNN关注文本的序列信息,但缺乏对文本局部信息的关注[16]。其次,电力缺陷描述词汇的专业性使现有的分词方法很难保证分词结果的准确性,常规人工建立分词词典的方法工作量大,人工干预程度高且难以保障分词词典的全面性,进而影响缺陷描述的向量表达,降低分类结果的准确性。
故此,文中提出了一种基于注意力机制优化组合神经网络的电力缺陷等级确定方法。该方法首先将电力缺陷描述以字粒度的形式进行分割量化,然后利用CNN关注文本局部特征,BILSTM关注文本序列特征的特点,完成对电力缺陷描述的充分挖掘,最后引入注意力机制,加强重要文本特征对分类结果的影响,实现对电力缺陷描述的分类,文中的创新点如下:
1)将字粒度分割应用在电力缺陷描述分类中,摆脱了对人工构建分词词典的依赖,避免了电力缺陷描述词汇的专业性对分词结果的影响;
2)建立了基于CNN和BILSTM的组合神经网络模型,更加全面、完整地捕捉文本的局部特征和序列特征,实现对缺陷描述文本的充分挖掘;
3)将注意力机制与组合神经网络模型相结合,得到不同文本特征信息的权重,进一步提高缺陷描述的分类准确率;
4)以云南电网公司2014年-2019年间的11万条电力缺陷描述作为实验对象,验证了文中所提方法的准确性和可行性。
1 基于注意力机制优化的组合神经网络模型
针对已有模型存在的不足,为进一步提高缺陷描述分类的准确率,文中提出了基于注意力机制优化的组合神经网络模型,其结构如图1所示。

图1 模型结构图
该模型包括文本量化层、特征提取层、注意力层和分类层四部分,首先,文本量化层利用字嵌入模型对电力缺陷文本进行向量化转换,得到电力缺陷描述的字向量表达;然后由CNN和BILSTM组成的混合神经网络对文本量化层得到的缺陷描述字向量表达进行特征提取,得到电力缺陷描述的语义特征,其组合顺序有效性验证如文中2.6节所示;接着注意力层对特征提取层得到的语义特征进行权重分配,提高语义特征中重要信息的权重,得到最终的缺陷描述特征向量;最后使用softmax分类器对注意力层得到的缺陷描述特征向量进行分类,获得电力缺陷描述分类结果。
1.1 模型表达
缺陷描述数据集由缺陷描述文本T{t1,t2,…,te}及其对应的缺陷等级L{l1,l2,…,le}组成,每条缺陷描述文本ti字粒度分割后由m个字构成,表达形式为{vi1,vi2,…,vim},因此模型的目标函数表达式为:
(1)
1.2 卷积神经网络
CNN是由输入层、卷积层、池化层、全连接层和输出层5部分构成的前馈神经网络,具有特征提取速度快,网络结构高效简单和网络适应性强的特点[17]。
输入层:接收文本量化层输出的向量化缺陷描述矩阵。缺陷描述文本字粒度分割后得到长度为m的电力缺陷描述表达,根据word2vec生成的字向量表进行向量空间匹配,将对应的字映射到指定维度的n维空间,生成一个大小为m*n的缺陷描述文本向量矩阵。
卷积层:对输入层接收的向量矩阵利用卷积核进行特征提取。卷积核的高度可以视作N-grams窗口值,是一个超参数,其宽度和输入层宽度一致为词向量的维度。卷积核的大小可以根据具体情况进行设定,其作用为设定一种筛选方式对缺陷描述文本向量矩阵中满足要求的特征进行提取,卷积过程如式(2)所示:
ci=f(w×vi:i+s-1+a)
(2)
式中w为卷积核,s为卷积核大小,vi:i+s-1为i~i+s-1个字构成的句向量;a为偏置项,卷积操作后,得到缺陷描述特征矩阵C,C=[c1,c2,…,cm-s+1]。
池化层:池化层将卷积层特征提取后的局部信息进一步筛选,从而实现数据的降维,保留向量矩阵的重要特征,去除不必要信息,达到减小计算量,避免过拟合的目的。这里采用如式(3)所示的MaxPooling池化。
PL=max{C}
(3)
全连接层和输出层:因为BILSTM需要输入序列化的数据结构,因此,全连接层将池化层产生的中断向量pli进行拼接,拼接后的向量用O表示,如式(4)所示,并将序列化数据结构输出作为BILSTM的输入。
O={pl1,pl2,…,plm}
(4)
1.3 BILSTM
LSTM是RNN的一个改进模型[18],其结构图如图2所示,LSTM根据上一时刻的隐藏状态ht-1和此刻输入plt得到遗忘门fdt、记忆门mdt和输入门odt实现记忆单元的遗忘、记忆和输出,对重要的信息进行保留,忽略重要程度较低的信息,避免了传统RNN模型存在的梯度消失和梯度爆炸缺陷[19],计算过程如下:
Step1: 由ht-1与plt得到遗忘门fdt。
fdt=logistic(WMfdplt+Wfdht-1+bfd)
(5)
Step2: 由ht-1与plt得到记忆门mdt。
mdt=logistic(WMmdplt+Wmdht-1+bmd)
(6)
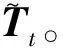
(7)
(8)
Step5:由ht-1与plt得到输出门odt。
odt=logistic(WMoplt+Woht-1+bo)
(9)
Step6: 由odt与Tt得到当前时刻隐藏状态ht。
ht=odt×tanh(Tt)
(10)
式(5)~式(10)中,logistic、tanh为激活函数,WMfd、Wfd、WMmd、Wmd、WMT、WT、WMo、Wo为权值矩阵,bfd、bmd、bT、bo为偏置向量。
BILSTM由正反向LSTM构成,其隐藏状态ht为:
(11)
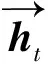
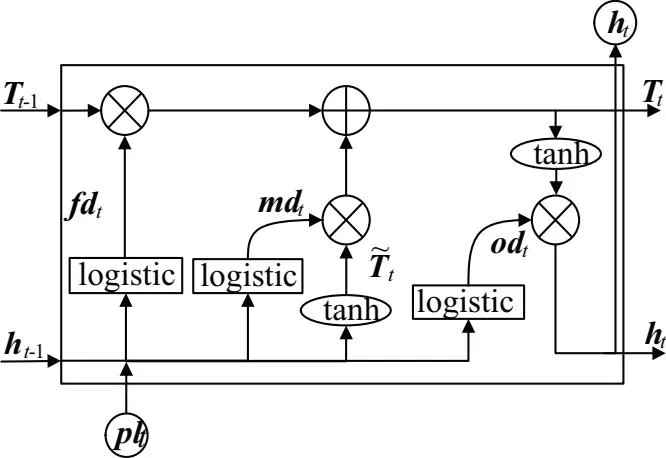
图2 LSTM模型结构图
1.4 注意力机制
注意力机制通过模拟人观察事物时,对主要信息重点关注,对次要信息较少关注的特点,实现对资源的调度分配。当前注意力机制应用在图像分类、机器翻译和情感分析等领域,并通过实验验证了有效性[20]。将前馈注意力机制引入CNN-BiLSTM模型,通过对注意力概率分布的计算,得到具有概率分布的缺陷描述语义特征表达,突出缺陷描述中不同特征的重要程度,达到提高分类准确率的目的[21-22],具体过程如下。
根据CNN-BiLSTM模型输出的隐藏状态ht,获得缺陷描述语义特征表达注意力权重awt如式(12)所示:
awt=tanh(ht)
(12)
式中 tanh为激活函数。
利用softmax函数对式(12)得到的注意力权重awt进行概率化计算,得到概率向量pt,表征该时刻隐藏状态的重要程度,表达式为:
(13)
将BILSTM生成的隐藏状态ht与对应的注意力概率向量相乘,得到其加权值如式(14)所示:
(14)
2 实验对比与分析
2.1 实验环境
文中实验环境如表1所示。

表1 实验环境
2.2 实验数据
为测试文中所提模型在电力缺陷描述分类中的效果,使用云南电网公司2014年—2019年间共计11万条缺陷数据作为实验对象,实验对象电压等级涵盖0.22 kV、0.38 kV、0.4 kV、10 kV、35 kV、110 kV、220 kV和500 kV,所有缺陷描述均由运维人员按照缺陷严重程度分为其他、一般、紧急和重大四个等级。将11万条缺陷描述打乱顺序并平均分为11份,随机抽取8份共计800 00条作为训练集进行梯度计算和模型权重更新;随机选取剩余3份中的2份共计200 00条作为验证集用于设定模型超参数,防止模型出现过拟合和欠拟合;剩余的1份共计100 00条作为测试集用于评价模型性能,数据集基本属性如表2所示。

表2 缺陷描述数据集信息
2.3 数据预处理
2.3.1 缺陷描述预处理
电力缺陷描述无需进行分段和分句操作,但部分电力缺陷描述夹杂着日期、地名和标点符号等影响分类的冗余信息,因此文中在缺陷描述分布式表达前进行去停用词操作,去停用词表参考哈工大停用词表和电力缺陷描述的实际情况建立。将去停用词后的电力缺陷描述建立基于字粒度和词粒度的向量表示。
2.3.2 词粒度向量表示
传统词袋模型根据训练语料库构建特征词表,其维度为1*m,其中m为特征词个数。使用词袋模型时,模型会将待量化文本与特征词表进行对照,当待量化文本中的词与特征词表中的词相对应时,则该词标记为1,反之,标记为0,由此形成一个维度统一但长度很长的文本向量。利用词袋法进行文本向量化主要有两方面的不足:一方面,形成的文本向量特征过于稀疏,维度大小可达几万维度,但仅有少量维度标记为1,其余均为0;另一方面,词袋模型构建的文本向量,并未考虑词与词之间的联系,词语之间相互孤立。
针对词袋模型存在的不足文中借鉴Mikolov提出的文本向量训练模型word2vec[23]。word2vec是一种神经网络概率模型,用于获得文本字或词的字词向量,与传统的词袋模型相比其维度可以按需设定,使计算复杂度大大降低并且避免了高维特征稀疏的问题[24]。此外,word2vec获得的字词向量包含了字词之间的语义信息,加强了字词间的联系。词粒度向量表示流程如下:
1)分词。分词是缺陷描述处理的基础和关键,分词结果的好坏直接关系到缺陷描述分类的准确性,由于电力缺陷描述中夹杂着电力设备的专用名词,因此文中根据文献[3-4]和搜狗输入法提供的电力行业常用词库建立缺陷描述分词词库并使用基于Python的结巴分词工具实现对缺陷描述的分词;
2)词向量训练。使用Word2Vec的Skip-gram模型对分词后的缺陷描述进行训练,得到指定维度的词向量。
2.3.3 字粒度向量表示
尽管词粒度向量表示在文本处理中得到了广泛的应用,但是在专业词汇较多的电力缺陷描述中分词结果的准确性无法完全保障。例如,缺陷描述“变油枕下边缘有渗油痕迹”可以分词为“变油/枕/下边缘/有/渗油/痕迹”、“变油/枕下/边缘/有/渗油/痕迹”、“变油枕/下/边缘/有/渗油/痕迹”和“变油枕/下边缘/有/渗油/痕迹”等多种分词结果。因此文中建立了基于字粒度的向量表示方法,其步骤与2.3.2节所示的词粒度向量表示的步骤类似,但无需建立分词词库进行分词,只需要按字分割即可,因此不存在分词不准确造成语义理解偏差的问题,字、词粒度向量表示时参数设定如表3所示。
2.4 参数设置
2.4.1 基于字向量的模型参数设置
基于字向量采用的实验模型为字粒度卷积神经网络(character granularity CNN, CNN-C)、字粒度双向长短时神经网络(character granularity BILSTM, BILSTM-C)、字粒度卷积循环神经网络(character granularity CBNN, CBNN-C)、字粒度注意力机制优化的卷积循环神经网络(character granularity CBNN optimized by attention mechanism, Att-CBNN-C)。为增强实验的严谨性和可对比性,基于字向量的所有模型实验参数均保持一致,数值如表4所示,其中,模型参数候选值表示实验中测试的模型参数,最优值表示最终确定的模型参数,选取不同参数值时模型验证集准确率如图3所示。

表3 Word2Vec参数设置

表4 基于字向量模型参数设置
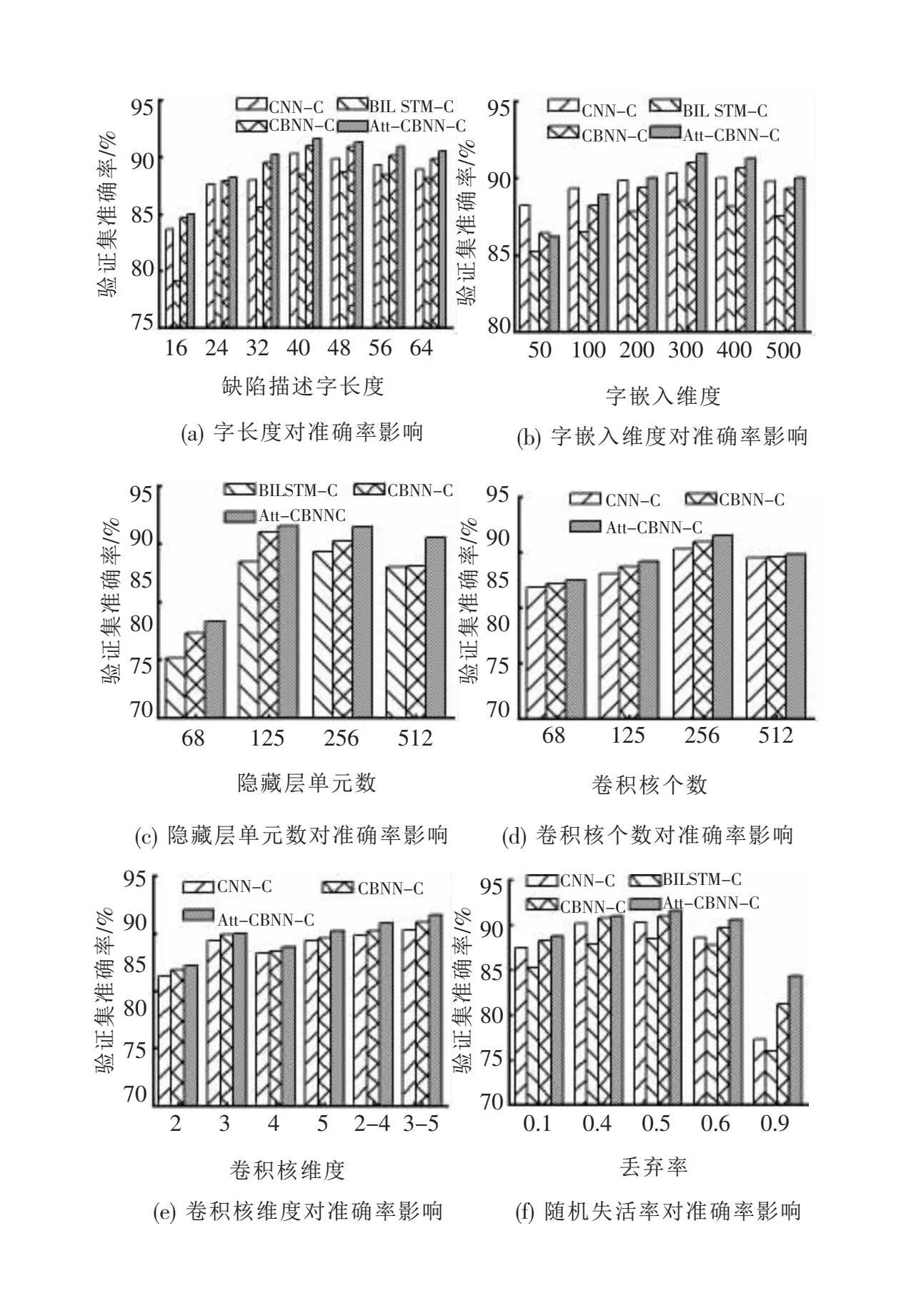
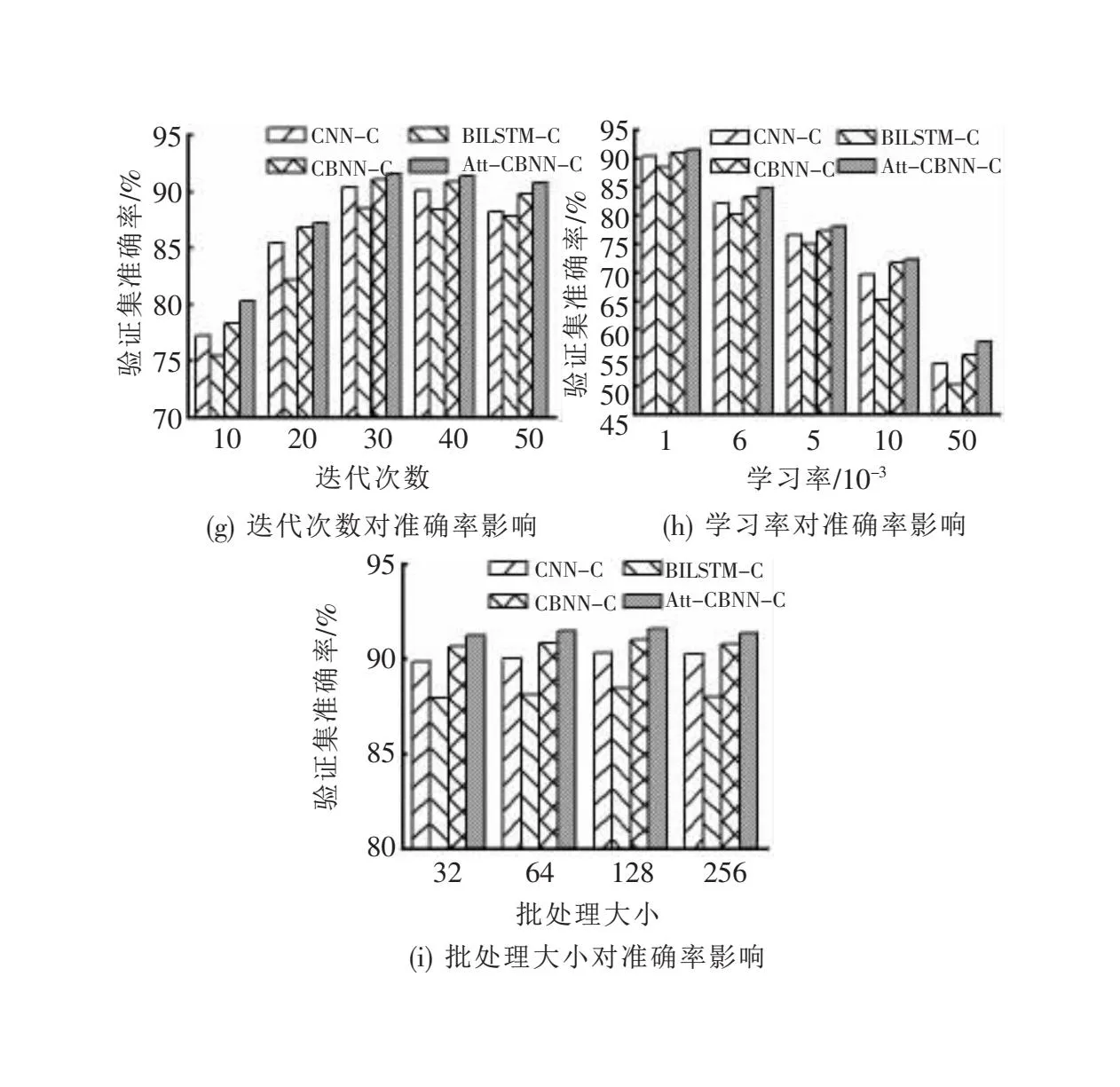
图3 模型超参数对验证集准确率影响
图3(a)~图3(i)表示在字向量中四种模型选取不同模型参数候选值时模型验证集对应的准确率。由图3(a)可知,当缺陷描述字长度设定为40时,四种模型的准确率取得最大值,当设定值过大或过小时模型准确率均有所下降,这是因为设定值过小时部分缺陷描述文本被截断,使部分有用信息丢失,当设定值过大时需要对部分缺陷描述文本进行填充,使干扰信息增加,造成准确率下降。由图3(b)可知,字嵌入维度为300时,模型准确率最优,嵌入维度过大或者过小均造成模型准确率下降,这是由于字嵌入维度过小会使不同字的映射维度较低学习不够全面,维度过大又会使不同字获得的学习特征过于稀疏,使模型准确率下降。由图3(c)和图3(d)可知,LSTM隐藏层单元数和卷积核个数分别为128和256时模型准确率最优,过大或过小的取值会造成模型过拟合和欠拟合,使得模型准确率下降。由图3(e)可知,单一的卷积核维度使模型对缺陷描述特征的提取不够全面,当卷积核维度为3~5组合时,模型可以从不同角度充分提取缺陷描述文本的语义特征,此时模型的准确率达到最优。由图3(f)可知,Dropout随机失活率为0.5时效果最佳,当随机失活率较低时,模型无法在训练集充分学习,出现模型欠拟合,当随机失活率较高时,模型在验证集的泛化能力不足,因此造成模型准确率下降。由图3(g)可知,迭代次数较小时模型训练不足,模型出现欠拟合现象使准确率较低,随着迭代次数的增加,模型准确率逐渐增加,当达到一定迭代次数后,模型准确率趋于稳定,继续迭代,导致模型发生过拟合,使模型泛化能力变差准确率降低,因此,文中选取模型迭代次数为30,在保证模型准确率的同时,减少训练时间。由图3(h)可知,学习率为0.001时,模型取得较高准确率,当学习率较大时,模型参数值在局部最低点时发散,使得模型无法对其参数进行更新,造成准确率降低。由图3(i)可知,批处理大小对模型的准确率影响较小,文中选取批处理大小为128。
2.4.2 基于词向量的模型参数设置
基于词向量采用的实验模型为词粒度卷积神经网络(word granularity CNN, CNN-W)、词粒度双向长短时神经网络(word granularity BILSTM, BILSTM-W)、词粒度卷积循环神经网络(word granularity CBNN, CBNN-W)、词粒度注意力机制优化的卷积循环神经网络(word granularity CBNN optimized by attention mechanism, Att-CBNN-W)。基于词向量的所有模型实验参数与2.4.1节基于字向量的模型参数选取过程一致,参数设置如表5所示。
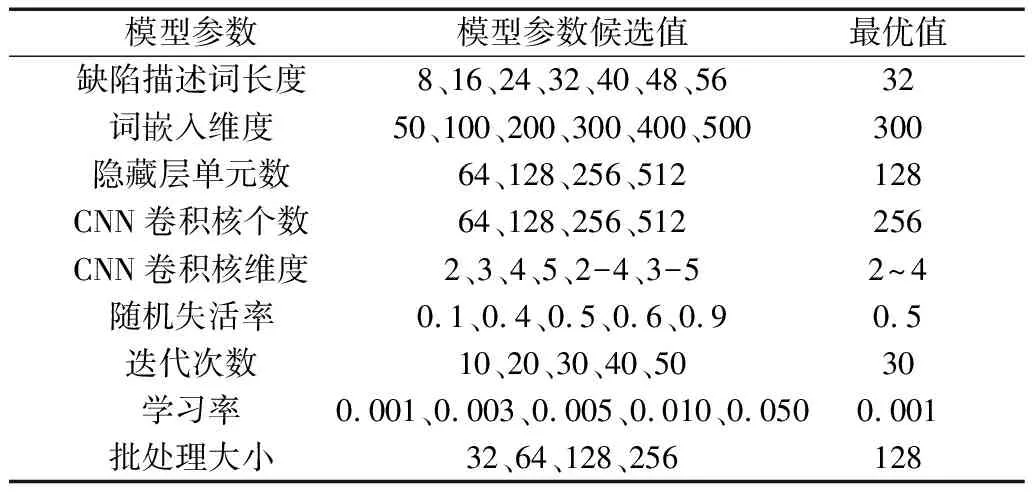
表5 基于词向量的模型参数设置
2.5 评价指标
文中分别采用准确率(Acc)、宏查准率(MP)、宏查全率(MR)、宏F1值(MF1)、加权查准率(WP)、加权查全率(WR)和加权F1值(WF1)对模型评价。评价公式如式(15)~式(23)所示,评价公式中的参数关系如表6所示。
(15)

表6 评价指标关联关系
(16)
式中n表示分类类别数,文中电力缺陷描述分为4类,因此n=4,P1~P4的表达式为:
(17)
(18)
式中R1=TO/NO,R2=TG/NG,R3=TU/NU,R4=TS/NS。
(19)
(20)
式中W1~W4的表达式为:
(21)
(22)
(23)
2.6 混合神经网络组合方式有效性分析
使用注意力机制优化CNN与BILSTM构建的混合神经网络时有Att-CBNN-C和字粒度注意力机制优化的循环卷积神经网络(character granularity BCNN optimized by attention mechanism, Att-BCNN-C)两种组合方式,文中以验证集准确率作为评价指标对两种组合方式的有效性进行分析,实验结果如图4所示。

图4 神经网络组合方式对准确率的影响
由图4可以看出30次迭代后两种模型的验证集准确率均超过0.9,可以对缺陷描述较为准确的分类,但Att-CBNN-C模型的验证集准确率略高于Att-BCNN-C,且不同迭代次数下的变化趋势更加平稳,模型稳定性更好,因此文中选取Att-CBNN-C模型对电力缺陷描述进行分类。
2.7 不同文本分类模型分类性能对比
对基于词粒度和字粒度的电力缺陷描述分类模型分别进行测试,得到的词粒度电力缺陷描述分类模型误分类矩阵和字粒度电力缺陷描述分类模型误分类矩阵如表7和表8所示。

表7 词粒度分类模型误分类矩阵
因为每条缺陷描述被分为其他、一般、紧急和重大四个等级中的一个,因此表7和表8中每个误分类矩阵的大小为4*4,其中第x行第y列表示“应属于等级x但是分类模型将其分类为y”的电力缺陷描述条数。例如,表7中的第1行第2列的数值大小为200,表示有200条电力缺陷描述本应属于其他等级但是CNN-W模型将其误分类为一般等级。
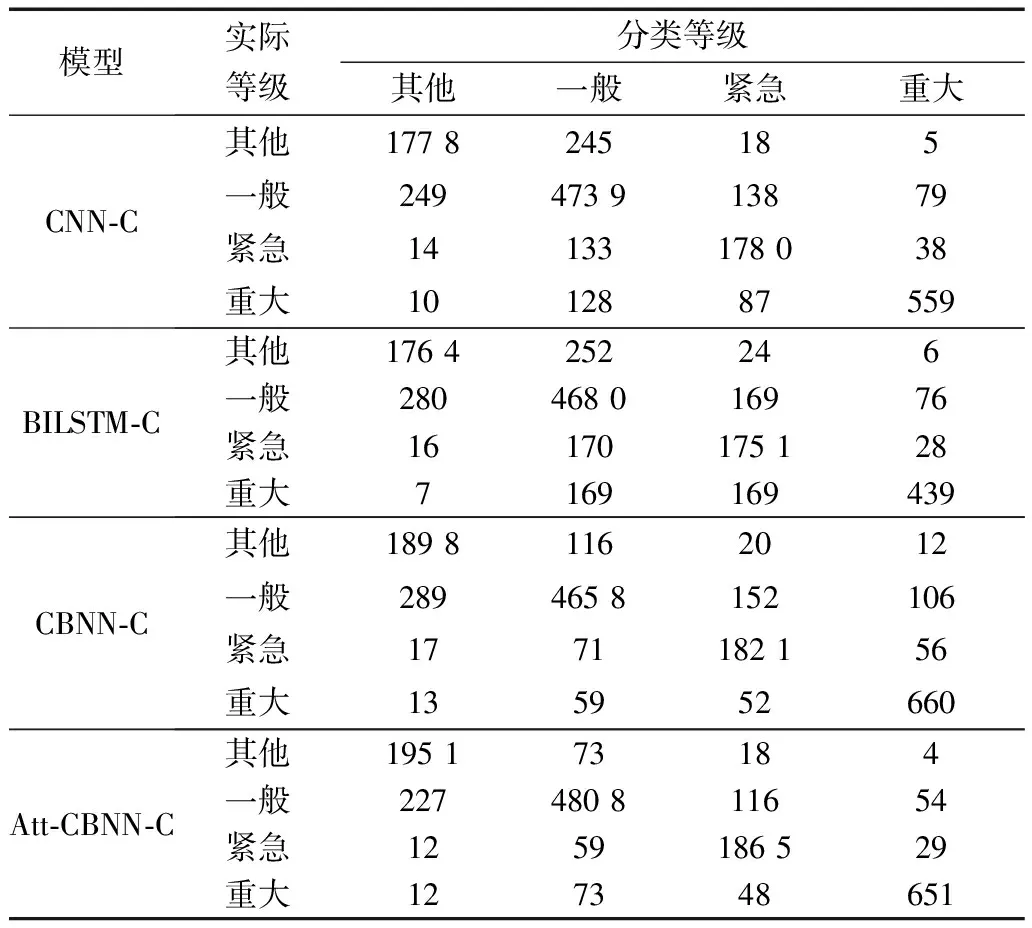
表8 字粒度分类模型误分类矩阵
为了更好地对比分析各种模型的分类性能,将表7和表8所示的模型误分类矩阵按照评价式(15)~式(23)进行统计,评价结果如表9所示。
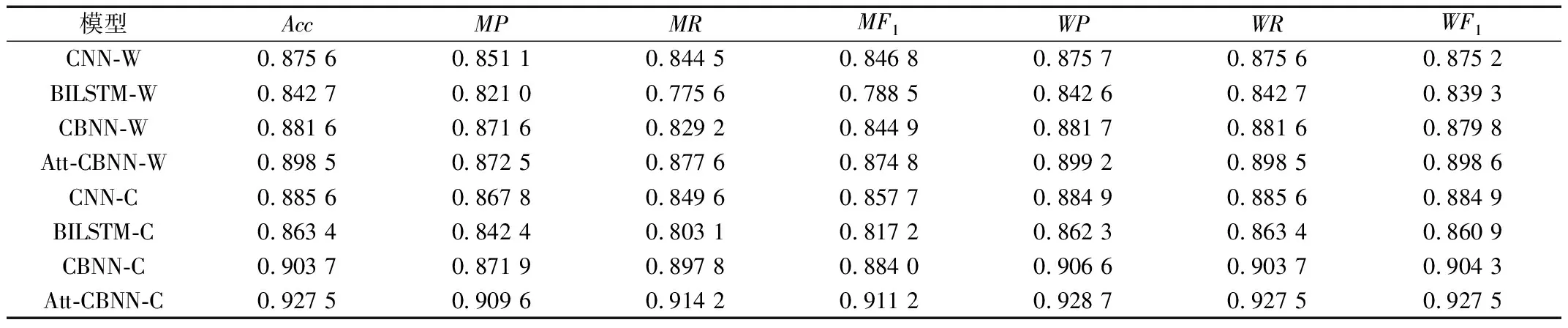
表9 不同模型在电力缺陷描述分类中的性能对比
由表9的实验结果可以看出,基于字向量的电力缺陷描述分类效果明显优于基于词向量的电力缺陷描述分类,Acc性能指标提升1.00%~2.90%,MF1性能指标提升1.09%~3.91%,WF1性能指标提升0.97%~2.89%。这是因为电力缺陷描述中专业词汇较多,尽管使用了人工建立的电力缺陷分词词库,但电力系统设备的多样性和复杂性无法保障词库的全面性,造成现有分词方法无法对缺陷描述准确分词,除此之外,部分词语在全部缺陷描述中出现的次数较少,使得这类词语无法得到充分学习,造成分类准确率降低。
基于字向量的实验模型中,CBNN-C模型比CNN-C模型的Acc性能指标提高1.81%,MF1指标提高2.63%,WF1指标提高1.94%;比BILSTM-C的Acc性能指标提高4.03%,MF1指标提高6.68%,WF1指标提高4.34%。由此可以看出融合CNN和BILSTM的CBNN-C模型不但具备CNN模型提取局部特征重要信息的能力还获得了BILSTM模型捕捉文本长时间间隔的特征,使得文本的语序和语法信息得到更加充分的利用,优于单一的神经网络模型,提高了电力缺陷描述文本的分类准确率。
基于字向量的实验模型中,Att-CBNN-C模型使用注意力机制对BILSTM的输出进行向量编码,得到数值不同的注意力权重,以辨别不同特征的重要性,对缺陷描述分类结果影响较大的语义特征进行权重加强,弱化对缺陷描述分类结果影响较小的语义特征。相比CBNN-C模型的Acc性能指标提高2.38%,MF1指标提高2.72%,WF1指标提高2.32%,验证了注意力机制在电力缺陷描述分类中的可行性和有效性。
3 结束语
针对电力缺陷描述专业词汇较多分词准确率不佳以及单一神经网络模型自身存在不足的问题,提出了基于注意力机制优化组合神经网络的电力缺陷等级确定方法。结论如下:
1)将字粒度应用在电力缺陷描述分类中,摆脱了对人工构建分词词典的依赖,避免了电力缺陷描述词汇的专业性对分词结果的影响,并通过实验验证了相比词粒度电力缺陷描述分类模型,基于字粒度可以更加准确地实现电力缺陷描述分类。
2)区别单一的神经网络模型,文中建立的混合神经网络模型将CNN关注文本局部特征,BILSTM关注文本序列特征的特点相结合,更加全面、完整地捕捉文本的局部特征和序列特征,实现了对缺陷描述文本的充分挖掘。
3)将注意力机制与组合神经网络模型相结合,对缺陷描述分类结果影响较大的语义特征进行权重加强,弱化对缺陷描述分类结果影响较小的语义特征,相比未使用注意力机制的组合神经网络分类准确率提升了2.38%,进一步提高了缺陷描述的分类准确率。
文中提出的基于注意力机制优化组合神经网络的电力缺陷等级确定方法,解决了运维人员人工判定电力缺陷描述时准确性和一致性无法保障的问题,且分类过程中无需人工建立分词词库,避免了分词不准确对分类结果的影响,在保证准确率的同时减少了人工干预,为电网的智能化运行提供帮助。为进一步提高模型的适应性和准确性,自适应更新分布式向量表达和优化算法优化选择神经网络的超参数是下一步工作的目标。
猜你喜欢
粉末冶金技术(2021年3期)2021-07-28 06:26:16
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
南京大学学报(自然科学版)(2021年1期)2021-01-30 14:01:04
智富时代(2019年6期)2019-07-24 10:33:16
中国交通信息化(2018年5期)2018-08-21 03:37:40
系统工程与电子技术(2016年12期)2016-12-24 07:19:14
高中生·天天向上(2016年9期)2016-11-22 09:10:34
青苹果·教育研究版(2013年2期)2013-04-29 00:44:03
