
基于特征融合和一致性损失的双目低光照增强
2024-01-13 10:44:56廖嘉文庞彦伟聂晶孙汉卿曹家乐
浙江大学学报(工学版) 2023年12期
廖嘉文,庞彦伟,2,聂晶,3,孙汉卿,曹家乐
(1.天津大学 电气自动化与信息工程学院,天津 300072;2.上海人工智能实验室,上海 200232;3.重庆大学 微电子与通信工程学院,重庆 401331)
在低光照条件下,图像质量显著下降,存在可见度低、噪声高的问题.低质量的图像不仅影响人类的视觉观感,还影响下游目标检测的性能.低光照图像增强旨在提升低光照图像的质量(如图像亮度和对比度),可以应用于视频监控、自动驾驶领域.
低光照图像增强随着深度学习的发展取得了巨大的进步,它包括有监督低光照图像增强和无监督低光照图像增强.有监督低光照图像增强利用神经网络学习低光照图像和正常光照图像之间的映射,如Wang 等[1]提出的流正则化模型增强低光照图像;Lv 等[2]提出基于多分支卷积神经网络的端到端注意力引导方法,并用所提方法实现低光照图像增强;Wang 等[3]将低光照增强任务转化为求残差的任务;Zhou 等[4]将低光照增强任务和去模糊任务共同进行;Zheng 等[5]提出全局的噪声模型估计,对图像进行亮度提高与去噪处理.Retinex 理论已被用于低光照图像增强任务中[6-7],核心思想是先进行亮度增强,再利用增强后的亮度和透射率恢复图像.无监督低光照图像增强是在没有正常光照参考图像的情况下进行低光照图像增强,如Guo 等[8]通过估计亮度增强曲线调整低光照图像,Ma 等[9]通过级联自标定学习机制提升低光照图像质量,Zhang 等[10]将每张彩色图像解耦为灰度图像和颜色直方图.为了促进低光照图像增强任务的发展,研究人员还构建了多个低光照图像数据集,如低光照和正常光照图像对数据集LOL[11]、短曝光和长曝光图像对数据集SID[12].低光照图像增强的方法大部分基于单目图像.相比于单目图像,双目图像能够提供更多有用的信息(如多视角信息和深度信息),基于这一优势,研究人员先后将双目信息用于图像去雾、去模糊、去雨等领域,提出双目图像去雾网络[13](学习双目图像的相关矩阵实现双目图像去雾)、深度感知和视图聚合网络[14](联合视差估计和双目图像去模糊)、成对的降雨去除网络[15](该网络可以补充遮挡区域的信息).此外,Huang 等[16]提出使用Retinex 的双目增强方法,初步表明了双目低光照图像增强的有效性.
双目低光照图像增强技术的发展受限于大规模低光照图像数据集的缺乏.为此,本研究构建大规模真实场景的双目低光照图像数据集(stereo low light 10K, SLL10K),提出基于特征融合和一致性损失的双目低光照图像增强网络(stereo lowlight image enhancement based on feature fusion and consistency loss network, FCNet).为了比较不同方法的低光照图像增强效果,在所建数据集上开展特定模块的消融实验和不同方法的低光照图像增强对比实验,并通过对双目低光照图像的目标检测实验验证FCNet 的目标检测效果.
1 大规模真实场景的双目低光照图像数据集
相比于单目图像,双目图像提供的视觉信息更丰富,可以更好地恢复结构与细节信息.SLL10K(数据集获取链接为https://pan.baidu.com/s/1HJre-CV8OMMpgr7QMasUgQ?pwd=4869)以天津大学为主要采集地点,充分利用校园内丰富的场景变化,历时半年采集完成,包含傍晚和夜间的低光照图像.数据集具有丰富的多样性,如建筑物变化、移动目标变化、季节变化、光照变化等,包含12 658 对室外低光照图像和205 对室内低光照图像.如图1 所示为该数据集中不同场景、不同时间的低光照代表性图像.

图1 SLL10K 的代表性图像Fig.1 Some example images in SLL10K
1.1 室外低光照图像
使用Bumblebee XB3 立体相机拍摄室外双目低光照视频.为了方便网络训练,将从双目相机中输出的视频分辨率缩小一半,设定为640×480像素.数据集共包含257 段双目视频,每10 帧抽取1 帧双目低光图像,得到室外双目低光照图像12 658 对.数据集分为训练集和测试集2 个部分,每个部分的场景不重复,其中训练集包含8 086对双目低光照图像,测试集包含4 572 对双目低光照图像.SLL10K 图像的大部分区域为低光照区域,存在亮度分布不均匀的问题,对实现高质量的图像增强具有较大挑战性.如图2 所示为SLL10K室外场景的训练集和测试集图像对样例.

图2 SLL10K 室外场景的训练集和测试集图像对样例Fig.2 Sample image pairs for training and testing sets in outdoor scene of SLL10K
1.2 室内低光照图像
室外场景很难获取低光照图像的参考图像.为了获取有参考的双目低光照图像,选择在室内采集部分场景数据,共得到205 对有参考图像的双目低光照图像.这些室内图像用于双目低光照图像增强的有参考指标评价.在室内场景中可以采集正常光照下的参考图像,还可以通过改变室内场景的光照来采集参考图像对应的低光照图像.为了采集不同低光照条件的双目低光照图像,设置不同的低光照条件,如仅有顶部暗光源、仅有角落暗光源、几乎没有光源等.此外,改变相机位置、视角,改变室内场景的物品种类、位置,都能够增加低光照数据的多样性.如图3 所示为双目低光照图像和对应的参考图像.

图3 SLL10K 室内场景的测试集低光照图像对和参考图像对样例Fig.3 Sample of low-light image pairs and reference image image pairs in indoor scene of SLL10K
2 基于特征融合和一致性损失的双目低光照图像增强网络
为了充分挖掘双目提供的多视角信息用于双目低光照图像增强,本研究提出FCNet,在单目低光照图像增强方法ZeroDCE++[17]的基础上,添加2 个双目相关模块提取双目多视角信息:双目内外特征融合(stereo inter-intra-feature fusion,SIIFF) 模块和双目一致性(stereo consistency,SC)损失函数,提升双目低光照图像增强的性能.FCNet 的整体架构如图4 所示.

图4 FCNet 的结构图Fig.4 Structure diagram of FCNet
1)为了减少计算量,FCNet 将输入的双目图像Il和Ir进行2 倍下采样(D2),在此基础上利用紧凑特征编码(compact feature encoder, CFE)模块分别从左右目图像中提取深度特征Fl和Fr.
2)FCNet 利用SIIFF 模块进行单目内特征和双目间特征的深度融合,输出融合后的左右特征Flf和Frf.具体地,单目内特征融合主要通过提取上下文信息增强特征表达力,双目间特征融合通过学习双目间的相关信息实现特征增强.
3)利用紧凑特征解码(compact feature decoder,CFD)模块将融合后的特征与紧凑特征编码模块的浅层特征进行融合,利用上采样模块(U2)将特征上采样2 倍.
4)利用亮度增强曲线(light-enhancement curve,LE)模块预测RGB 三通道的亮度增强曲线,分别调整3 个通道的亮度,得到双目增强结果图像Ile和Ire.
2.1 紧凑特征编、解码模块
CFE 模块对经过下采样的双目图像进行深度特征提取,分别生成特征图Fl和Fr.具体地,CFE 模块由4 个级联卷积层构成,每个卷积层的卷积核大小为3×3.每个卷积后紧接1 个非线性激活层ReLU.CFD 模块依次融合CFE 模块不同层的特征.1)将SIIFF 模块的输出和CFE 模块的第3 层特征串接,并经过1 个卷积层进行融合;2)将融合后的特征同CFE 模块的第2 层特征串接和融合,依次类推得到最终的解码特征Fld和Frd.
2.2 双目内外特征融合模块
SIIFF 模块位于CFE 模块和CFD 模块之间,用于提升双目特征的表达力.如图5 所示,SIIFF模块由1)基于大核的单目内融合模块和2)基于注意力的双目间特征融合(attention based inter feature fusion, AIF)模块2 个部分构成.模块1)提取单目内局部上下文信息,增强特征表达能力.为了减少计算成本,模块1)采用2 个并行的非对称大核卷积模块分别从水平方向和竖直方向提取特征,卷积核大小分别为1×9 和9×1.模块2)挖掘跨视角互补信息,提升双目特征表达能力.考虑到空间中某个点在双目图像中位于同一水平线上,只需关注双目图像同一水平方向上不同像素间的相关性,为此设计水平注意力模块(horizontal attention module, HAM).

图5 双目内外特征融合模块的结构图Fig.5 Structure diagram of stereo inter-intra-feature fusion module
获得双目图像增强特征的具体过程如下:
1)利用HAM 生成双目相似性图:HAM 利用线性层Linear 将输入的左特征图Fl∈RB×C×H×W和右特征图Fr∈RB×C×H×W,生成注意力模块的左目查询向量Ql∈RB×C×H×W和右目键向量Kr∈RB×C×H×W,表示为
式中:Linear 为1 ×1 卷 积层,C为输出通道数.
2)将Ql的形状转换为 R(BH)×W×C,将Kr的形状转换为 R(BH)×C×W,并利用矩阵乘法和Softmax 函数计 算二者之间的相似 性图Sr→l∈R(BH)×W×W,表示为
得到的相似性图反映同一水平方向上2 个点的相似度.与此同时,利用Linear 将右特征图Fr∈RB×C×H×W生成右目值向量Vr∈RB×C×H×W.基于相似性矩阵Sr→l和形状 转 换 后的值向 量Vr∈R(BH)×W×C相 乘,得到注意力模块的输出Al∈R(BH)×W×C,表示为
经过形状转换,得到Al∈RB×C×H×W
.类似地,利用HAM 可以分别生成右目查询向量Qr∈RB×C×H×W和左目键向量Kl∈RB×C×H×W,表示为
将Qr的形 状 转 换为 R(BH)×W×C,将Kl的形状 转 换 为R(BH)×C×W,并利用矩阵乘法和Softmax 函数 计算二者之间的相似性图Sl→r∈R(BH)×W×W,表示为
受Wang 等[18]启发,为了减少右目中不相关的点对左目图像的影响,将Sl→r沿最后一维求和,将和小于0.1 的位置置为0,大于0.1 的位置置为1,再经 过 形 状 转 换,得 到 掩 模 矩 阵Ml∈RB×1×H×W.AIF 模块将Fl、Ml和Al融合,得到双目间的输出特征Fla∈RB×C×H×W,表示为
式中: c at 为特征图串接操作;Wo为1×1 的卷积层,用于特征融合.
3)SIIFF 模块将Fla和单目内输出特征Flb相加得到Flf.类似地,可以得到Frf.
2.3 亮度增强曲线
采用单目低光照增强方法ZeroDCE++[17]预测RGB 的3 个通道的亮度增强曲线,利用亮度增强曲线对低光照图像进行增强,表达式为
式中: L En为迭代后的图像,M为曲线参数映射,LEn-1为迭代前的图像.预测得到的亮度增强曲线具有3 个特点:1)增强图像的每个像素值的归一化范围均为[0, 1],以避免溢出截断造成信息丢失;2)曲线是单调的,以保留相邻像素的差异;3)梯度反向传播过程中,曲线的形式简单且可微.
2.4 损失函数
为了充分利用增强前图像的信息,更好指导双目低光照图像增强,使用SC 损失函数来保持双目视觉结构的一致性.为了让FCNet 实现更好的无监督学习,使用空间一致性(spatial consistency)损失函数、曝光控制(exposure control)损失函数、颜色恒常性(color constancy)损失函数和照明平滑性(illumination smoothness)损失函数来优化FCNet.
一般而言,图像增强前后局部区域的像素值亮度趋势应保持不变.双目图像同一位置的2 个像素点属于同一局部区域,亮度相对区域应该保持不变.因此,在网络设计过程中,双目图像间的差异图在增强前和增强后应该尽可能保持一致.在图像增强过程中,可能会出现增强后双目图像间的差异图发生变化(如左、右目图像增强程度不同),导致相邻像素的亮度相对趋势被破坏.SC 损失函数保证了增强前和增强后双目相邻像素的亮度趋势尽可能一致:

为了保持空间相关性,在以区域i为中心的上、下、左、右4 个相邻区域 Σ (i) 上,使用空间一致性损失:
式 中:A为 特 定 区 域 的 像 素 数,Vi、Vj、Ii、Ij均 为增强后的图像和输入图像中特定区域的平均光照强度值.
为了避免曝光不足或过曝光,FCNet 利用曝光控制损失函数对增强图像的局部区域进行调整,避免增强图像出现对比度问题.设置优良曝光等级G=0.6.定义曝光控制损失函数为
式中:B为1 6×16 的区域,表示参与计算的不重叠的局部区域大小为 1 6×16 ;Vk为特定区域的平均光照强度值.
为了修正颜色偏差,在使用增强网络对低光照图像增强过程中,可以利用颜色恒常性损失对图像的RGB 通道进行修正:
式中:Xp为增强后的图像中p通道的平均光照强度值; (p,q) 为通道对,为RGB 的3 个通道两两配对.对RGB 图像进行YUV 或HSB 空间转换,虽然可以分解出亮度分量,但在空间转换过程中会存在信息损失的情况,也无法保证颜色不出现偏差.
为了监督曲线参数图的预测,利用光照平滑度损失对曲线参数图进行修正:
式 中:N为 迭 代 次 数, ∇x、 ∇y分 别 计 算 水 平 方 向 的梯度和垂直方向的梯度,A为曲线参数图.
根据上述损失函数,综合得到FCNet 的损失函数为
式 中:Wsc、Wspa、Wexp、Wcol、Wtv分 别 为 对 应 损 失函数的权重.
3 实验结果与分析
3.1 数据集和实验细节
FCNet 是端到端的可训练网络,无须对子模块进行预先训练.本次实验使用8 086 幅室外图像训练FCNet,使用4 572 幅室内图像对和205 幅室内图像测试FCNet.为了便于对网络进行训练和测试,图像大小设定为640×480 像素.本研究在单个GeForce GTX Titan X 显卡上使用PyTorch 实现提出的方法,用于训练的优化器为Adam,学习率固定为0.000 1.设置本次实验的批大小为1,epoch 的 数 量 为50,Wspa=2、Wexp=5 、Wcol=5 、Wtv=1 900 、Wsc=1.SLL10K 的测试集分为有参考的室内子集和无参考的室外子集.对于无参考图像的室外子集,采用4 个无参考指标来评价不同方法的增强效果,包括无参考图像空间质量评价器(blind/referenceless image spatial quality evaluator,BRISQUE)[19]、自然图像质量评价器(natural image quality evaluator, NIQE)[20]、基于感知的图像质量评价器(perception-based image quality evaluator,PIQE)[21]和亮度顺序误差(lightness order error,LOE)[22].对于有参考图像的室内子集,采用3 个有参考指标和4 个无参考指标来评价不同方法的增强效果,其中有参考指标包括峰值信噪比(peak signal to noise ratio, PSNR)、结构相似度(structural similarity, SSIM)和学习感知图像块相似度(learned perceptual image patch similarity, LPIPS)[6,23],无参考指标包括BRISQUE、NIQE、LOE、PIQE.指标BRISQUE、NIQE、PIQE、LOE 和LPIPS 的数值越小表示图像增强的效果越好,指标PSNR 和SSIM 的数值越大表示图像增强的效果越好.提供室内图像的主要目的是方便其他方法采用本数据集测试时的有参考指标比较.
3.2 消融实验
为了证明FCNet 中每个模块的有效性,对添加的模块进行消融研究.
3.2.1 不同模块的作用 为了验证SIIFF 模块和SC 损失函数的有效性,FCNet 在室内测试集和室外测试集上对2 个模块进行消融研究,结果如表1 所示.表中,“√”表示使用该模块,“×”表示不使用该模块.在室外数据集中,添加SIIFF 模块的FCNet,4 个指标都有明显改善,其中BRISQUE 下降2.138 5,PIQE 下降2.092 7;添加SC 损失函数的FCNet,4 个指标也都有明显改善,其中BRISQUE下降0.451 2,PIQE 下降2.364 8.这说明添加的SIIFF 模块和SC 损失函数都对室外数据有增强效果.在室内数据集中,添加SIIFF 模块的FCNet,大部分指标显著改善,其中SSIM 提高0.015 2,PIQE 降低4.462 1;添加SC 损失函数的FCNet,大部分指标显著改善,其中SSIM 提高0.030 5,PIQE 下降2.812 2.这说明添加的SIIFF 模块和SC 损失函数都对室内数据有增强效果.
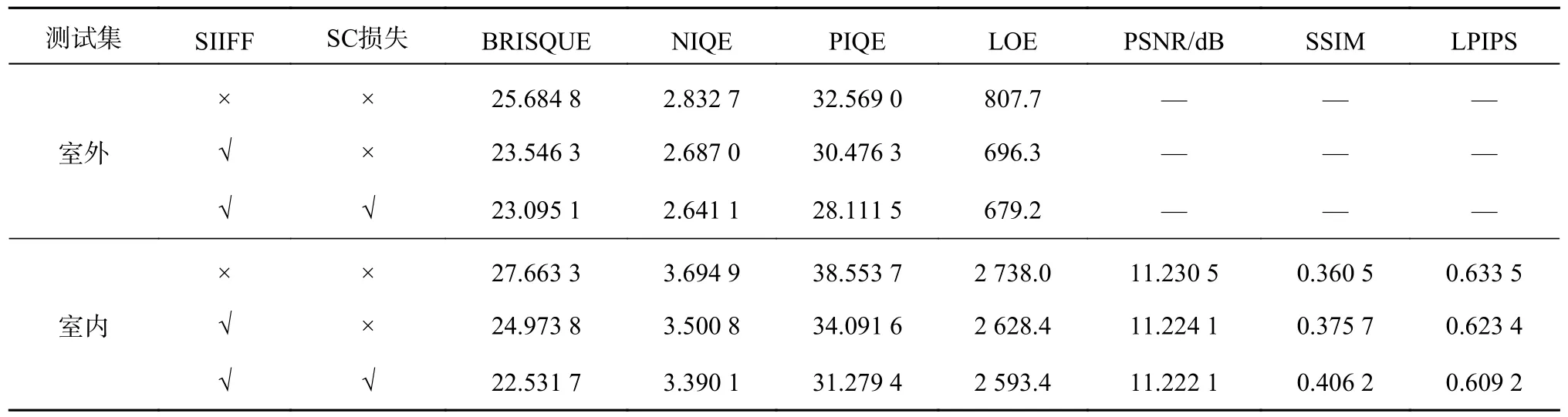
表1 FCNet 的不同模块在2 个测试集上的消融实验Tab.1 Ablation experiment of FCNet’s different modules on two test sets
3.2.2 融合模块数量的影响 为了验证SIIFF 模块数量对网络的影响,进行修改SIIFF 模块数量nm的实验.为了得到更具有说服力的实验结果,该项实验在室外测试集和室内测试集中进行,结果如表2 所示.在室外数据集中,2 个SIIFF模块的所有指标都比1 个SIIFF 模块效果好,其中BRISQUE 下降0.215,PIQE 下降0.442 1,这说明2 个SIIFF 模块比1 个SIIFF 模块对室外数据有更好的增强效果.在室内数据集中,2 个SIIFF 模块的所有指标都比1 个SIIFF 模块效果好,其中SSIM 上升0.042 5,PIQE 下降0.783 1.这说明2 个SIIFF 模块比1 个SIIFF 模块对室内数据有更好的增强效果.

表2 FCNet 的模块数量变化在2 个测试集上的消融实验Tab.2 Ablation experiment of FCNet’s module number variation on two test sets
3.2.3 添加大核卷积的影响 为了验证采用的大核卷积对双目低光照图像增强网络的影响,将SIIFF 模块中的大核卷积改为2 个3×3 的普通卷积,结果如表3 所示.在室外数据集中,使用1×9和9×1 的大核卷积的所有指标都比使用3×3 的普通卷积的效果好,NIQE 下降0.612 4,PIQE 下降3.537 4.这说明使用1×9 和9×1 的大核卷积比使用3×3 的普通卷积对室外数据有更好的增强效果.在室内数据集中,使用1×9 和9×1 的大核卷积的所有指标同样都比使用3×3 的普通卷积的效果好, PSNR 上升0.153 8 dB,PIQE 下降10.597.这说明使用1×9 和9×1 的大核卷积比使用3×3 的普通卷积对室内数据有更好的增强效果.

表3 模块卷积变化在2 个测试集上的消融实验Tab.3 Ablation experiment of convolution variation on two test sets
3.3 数据测试结果
3.3.1 定量比较 将FCNet 与RetinexNet[11]、ISSR[24]、GLAD[25]、DVENet[16]、ZeroDCE++[17]、RUAS[26]的单目、双目低光照图像增强方法进行对比.其中RetinexNet、ISSR、GLAD 和DVENet 是有监督学习方法,ZeroDCE++、RUAS 和FCNet 是无监督学习方法;DVENet 是双目低光照图像增强方法.无监督学习方法均在SLL10K 训练集上进行训练,之后在测试集上得到增强结果;有监督学习方法由于缺乏参考图像,采用其论文提供的预训练模型在SLL10K 上进行测试.
不同方法在SLL10K 室外、室内测试集上的图像增强指标结果分别如表4、5 所示.由表4 可以看出, FCNet 整体上比大部分方法的效果好,各个指标都能居于前列,在无监督方法中表现最好.相比ZeroDCE++网络,FCNet 的左目图像BRISQUE 下降2.589 7,PIQE 下降4.457 5;右目图像BRISQUE 下降2.870 4, PIQE 下降4.743 5.这说明对于室外低光照图像,无论是左目图像还是右目图像,FCNet 都比对应的单目方法ZeroDCE++的处理效果更好.由表5 可以看出, FCNet 的SSIM 指标的数值最大,左目图像比RUAS 高0.025 8,右目图像比RUAS 高0.038 2.双目图像的BRISQUE、PIQE 和LOE 指标较好,在无监督方法中有4 项指标取得最佳.相比对应的单目方法ZeroDCE++,FCNet 方法左目图像在BRISQUE 降低5.131 6,PIQE 降低7.274 3;右目图像在BRISQUE 降低5.988 6,PIQE 降低8.940 3;左右目图像的其余指标也较好.这说明对于室内低光照图像,无论是左目图像还是右目图像, FCNet 都比对应的单目方法ZeroDCE++的处理效果更好.
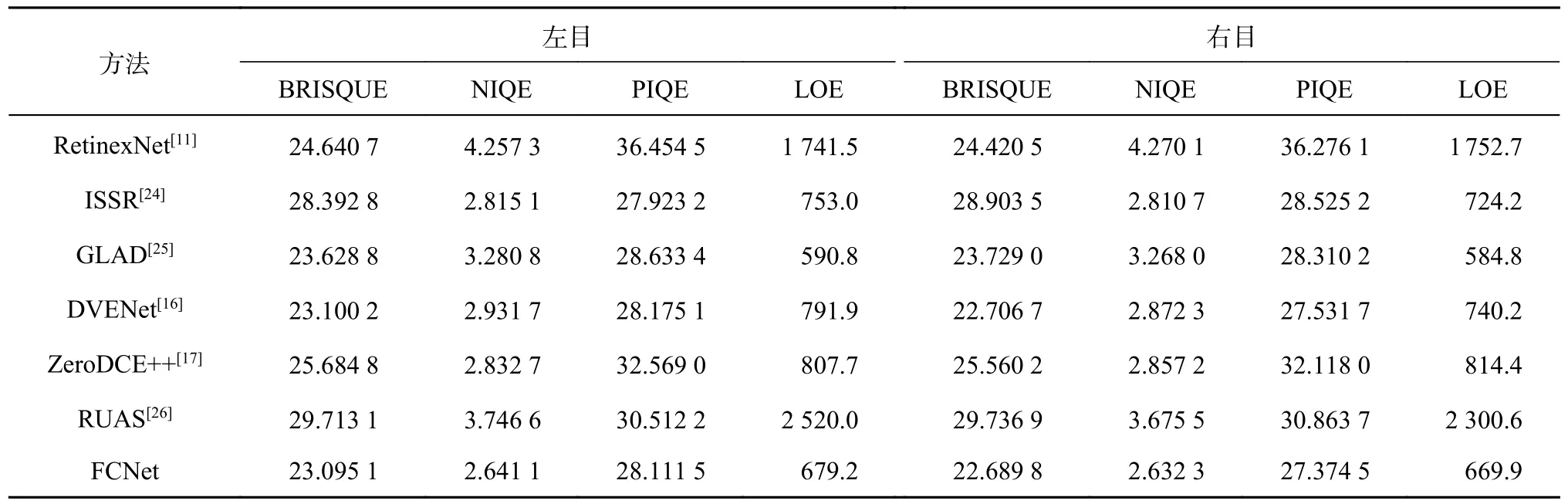
表4 不同图像增强方法在SLL10K 室外数据集上的指标对比Tab.4 Indicators comparison of different image enhancement methods on SLL10K outdoor dataset
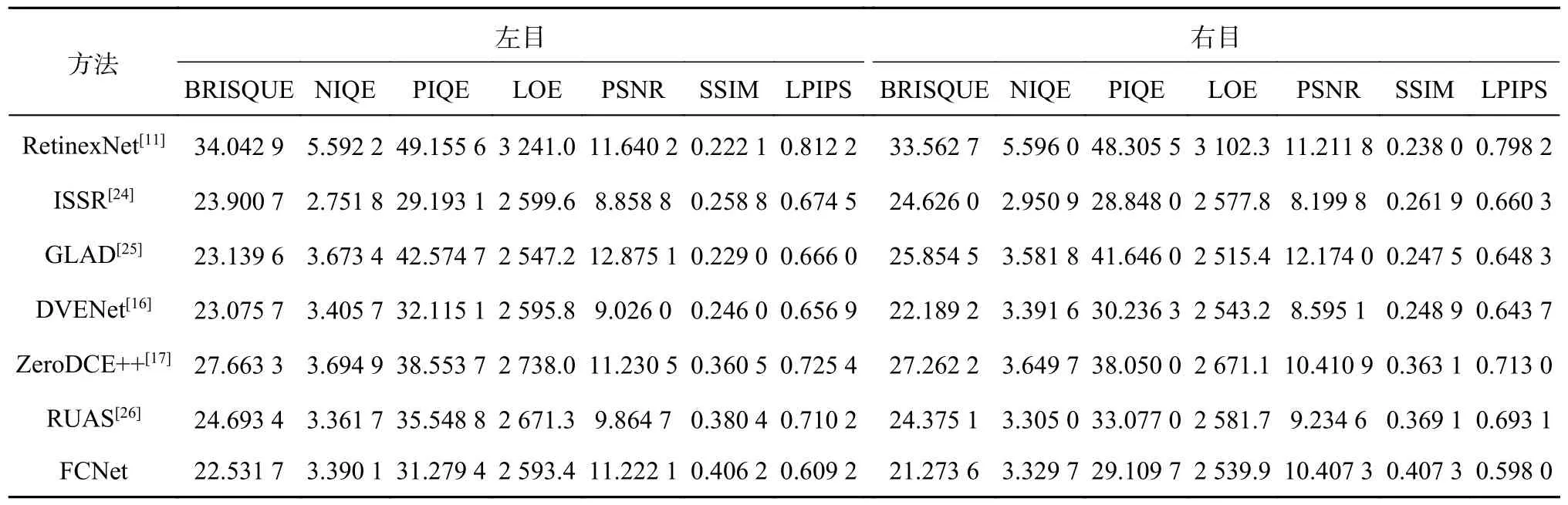
表5 不同图像增强方法在SLL10K 室内数据集上的指标对比Tab.5 Indicators comparison of different image enhancement methods on SLL10K indoor dataset
3.3.2 视觉对比 FCNet 是无监督图像增强方法,因此仅选择2 个无监督方法RUAS 和ZeroDCE++进行可视化对比.如图6 所示为FCNet 与ZeroDCE++、RUAS 无监督方法在不同场景下的视觉比较.对比夜晚灯笼场景图像可以看出,RUAS 增强的图像周围环境的色彩受到灯光区域影响严重,且过曝现象严重;ZeroDCE++增强的图像框出区域路肩受到光照过曝,损失路肩部分细节;FCNet 增强的图像保证了周围环境的色彩,也保证了图像对比度,还避免了过噪和过曝现象,相较于其他方法优势显著.对比夜晚公交场景图像可以看出,RUAS 增强的图像路面和路灯过曝现象严重,损失车辆上和路面上的部分细节;ZeroDCE++增强的图像框出区域车辆玻璃上的噪声显著,车身也略微发白;FCNet 增强的图像路面和路灯没有显著的过曝现象,车辆玻璃上的噪声也不显著,相较于其他方法优势显著.对比夜晚车辆和建筑场景图像可以看出,RUAS 增强的图像路灯过曝现象严重,损失部分细节;ZeroDCE++增强的图像车身区域噪声明显,框出区域的路灯灯光过曝明显;FCNet 增强的图像既能降低噪声,又避免了过曝现象,相较于其他方法优势显著.对比夜晚树木和建筑场景图像可以看出,RUAS 增强的图像增强效果不明显,且路面和窗户部分区域有过曝现象;ZeroDCE++增强的图像框出区域过曝现象严重,损失部分细节;FCNet 增强的图像既降低了噪声,又避免了过曝现象,相较于其他方法优势显著.

图6 不同图像增强方法对4 种场景图像的处理效果对比Fig.6 Processing effects comparison of different image enhancement methods on four scene images
如图7 所示为室内图像单、双目增强效果对比.相较于单目方法,双目方法可以消除部分噪声,如在框出的皮包区域,双目方法的噪声比单目方法的少;在白墙部分,单目方法比双目方法的过曝更显著.单目方法的暗区更清楚的原因是单目方法的暗区部分存在噪声,这些白点噪声导致暗区稍显变亮.

图7 室内图像单、双目增强效果对比Fig.7 Comparison of monocular and stereo enhancement of indoor images
3.4 目标检测实验
进行目标检测实验,对比使用不同方法增强后的图像的目标检测效果.本实验使用经过亮度暗化处理的低光照KITTI[27]数据集,实现过程是将获取的原始KITTI 数据集图像经过Gamma 变换[28],通过调整亮度曲线使图像的亮度变低[2].这种方法可以模拟类似在低光照条件下获取到的双目低光照图像.该实验主要考察光照不充分的车辆图像在使用不同方法进行图像增强后,是否可以标出目标车辆的三维检测框.实验选用KITTI数据集的训练集图像,其中训练图像3 712 张、验证图像3 769 张,图像大小约为1 224×370 像素.目标检测网络选用Disp-RCNN[29].Disp-RCNN 是基于实例级视差估计的双目三维目标检测框架,主要由3 个部分组成:1)检测每个输入对象的二维边框和实例掩码,2)仅估计属于对象的像素视差,3)使用三维检测器从实例点云中预测出三维边界框.具体参数使用Disp-RCNN 的默认参数,检测网络采用官方提供的预训练模型,再将各种方法增强后的双目图像分别输入检测网络,测试各自检测结果.
如表6 所示为不同方法增强后图像的目标检测结果,重叠度(intersection over union, IoU)取0.7,难度选择中等.表中, A P2d为二维检测的平均准确度, A Pori为方向的平均准确度, A Pbev为鸟瞰图的平均准确度, A P3d为三维检测的平均准确度.可以得到,经过低光照处理后的KITTI数据集的目标检测准确率显著下降,如当IoU=0.7时, A P3d中等难度下降16.06 个百分点.多数的图像增强方法都能让目标检测准确率提升.其中FCNet 的检测准确率最高, A P3d中等难度结果为45.45%,相比ZeroDCE++提升了0.47 个百分点,说明使用双目方法可以有效提升对应方法的检测准确率.如图8 所示为单、双目图像增强方法的视差图对比,对比各分图框出的部分可以看出,使用双目方法F C N e t 增强左右目低光照图像通过Disp-RCNN 网络获得的视差图,轮廓符合参考图像视差图的形状,明显优于使用单目方法ZeroDCE++分别增强左、右目低光照图像后一起通过Disp-RCNN 网络获得的视差图.

表6 不同图像增强方法的目标检测结果Tab.6 Object detection results of different image enhancement methods%

图8 单、双目图像增强方法的视差图对比Fig.8 Comparison of parallax map between monocular and stereo image enhancement methods
4 结 语
本研究提出基于特征融合和一致性损失的双目低光照图像增强网络FCNet.特征融合模块基于注意力机制和大核卷积,能够充分融合单目内和双目间的信息,进而增强特征.一致性损失函数保持输入双目图像和输出双目图像间的差异趋势,能够实现更好的图像增强效果.在SLL10K 数据集上的实验表明,相比单目方法,FCNet 能更有效提升低光照图像增强的性能.在经过暗化处理的KITTI 数据集上的实验表明,使用FCNet 增强后的图像能获得更好的目标检测效果.尽管FCNet在该数据集取得了一定的效果,但是在噪声抑制方面仍然存在巨大的进步空间.未来将聚焦如何利用双目多视角的冗余信息抑制夜间噪声.
猜你喜欢
燃气涡轮试验与研究(2021年6期)2021-08-01 03:09:10
海洋信息技术与应用(2020年4期)2021-01-18 06:21:36
电子制作(2019年20期)2019-12-04 03:51:38
中国生物医学工程学报(2019年5期)2019-07-16 07:56:50
中国惯性技术学报(2019年1期)2019-05-21 00:58:30
北京航空航天大学学报(2017年4期)2017-11-23 05:48:16
北京航空航天大学学报(2017年3期)2017-11-23 05:14:58
光学精密工程(2016年4期)2016-11-07 09:05:11
现代计算机(2016年11期)2016-02-28 18:35:20
机械工程师(2015年10期)2015-02-02 01:13:47
