
无人机遥感的多植被指数土壤水分反演模型
2024-01-12 05:55:24冯雅婷朱士江
光谱学与光谱分析 2024年1期
李 虎,钟 韵,2,冯雅婷,林 震,朱士江,2*
1. 三峡大学水利与环境学院,湖北 宜昌 443002 2. 三峡库区生态环境教育部工程研究中心,湖北 宜昌 443002
引 言
土壤水分的含量水平对作物生长有着直接影响,是作物吸收水分的主要来源。 高效地监测土壤水分,有利于及时调整灌溉制度,从而促进作物生长发育与产量形成[1-3]。 土壤水分含量受气候、 环境、 土壤类型、 作物种类等诸多因素的影响,各因素间存在复杂的非线性关系,如何有效、 快速、 精准的监测大田中土壤水分含量已成为当前研究热点。 现有土壤水分测量方法可以分为接触式的直接测量以及非接触式的遥感监测[4-5]两大类; 直接测量法虽然测定精度高,但样本数量少、 时效性低、 代表性差,难以准确反映区域土壤水分变化; 遥感监测获取土壤水分具有时效性强、 范围广、 时空分辨率高、 成本低等优势,其中可见光、 近红外和热红外等波段常用于土壤水分的遥感监测,各种波段对土壤水分反演的方法和原理都有所不同[6-8]。
由于地表有植被覆盖,直接使用光谱指数反演土壤水分精度不高,学者们研究发现通过植被指数反演土壤水分更能满足精度要求。 目前,在利用植被指数反演土壤水分方面已有大量的工作,研究表明各植被指数与土壤水分的关系主要有线性和非线性两种关系[9-11]; 康为民等[12]根据贵州2006年—2007年的遥感数据以及相应的植被干旱指数(temperature vegetation dryness index,TVDI ),对表层土壤干旱情况进行线性反演,结果表明TVDI与表层的土壤水分呈显著相关; 蔡庆空等[13]在TVDI的基础上引入分形覆盖度,得到了改进的植被干旱指数(ITVDI),并构建了一元线性反演方程,在一定程度上避免了干旱指数按土地覆盖类型划分的局限性; 张传波等[1]基于非线性BP神经网络利用波段反射率和植被指数结合建模,决定系数(coefficient of detemination,R2)达到0.928。 多元逐步回归法是一种传统的线性拟合方法,通过逐个引入植被指数进行筛选,将其中不显著的指数剔出,直至方程中所有指数都显著,最大程度的解释了土壤水分的变异性; 神经网络法具有较好的非线性拟合能力,因其优秀的学习能力、 容错性及自适应性,使其在探索植被指数间复杂的线性关系前提下能有效地对土壤水分进行反演。
目前,基于多种植被指数对比线性和非线性模型的土壤水分反演精度的研究鲜有报道。 本研究以不同土壤水分条件的柑橘园区为研究对象,利用多光谱数据构建多种植被指数,并分析植被指数与实测土壤水分间的相关关系,筛选出相关性较好的植被指数基于BP神经网络法和多元逐步回归法建立土壤水分反演模型,通过对比两模型的反演精度指数,形成高效反演土壤水分的多植被指数模型,以期实现柑橘园土壤水分的实时监测。
1 实验部分
1.1 试验地概况
试验于2021年6月—9月在宜昌市仓屋榜试验基地(E111°42′,N30°75′)开展,见图1。 该地为亚热带季风性湿润气候区,气候存在四季分明的特点,高温和降雨同期出现。 近60年平均降水量为1 016 mm,平均气温16.9 ℃,全年无霜期250~300 d,海拔在100~300 m范围内,光热条件较好,适宜柑橘等作物生长。 土壤全磷的含量为(1.90±0.01) g·kg-1,pH值为7.12,土壤的容重为(1.25±0.02) g·cm-3,饱和质量含水量为34.31%±2.5%。

图1 试验位置Fig.1 Location of the test area
1.2 数据采集及预处理
采用ASD Field Spectral FR光谱仪(波长范围为325~1 075 nm,光谱分辨率1.5 nm)及大疆精灵4多光谱版无人机(包含可见光、 红、 蓝、 绿、 红边和近红外6个通道)在柑橘土壤水分变动较大的幼果期和果实膨大期收集柑橘冠层光谱数据,选择在晴朗无云的天气,上午10:00—14:00,并配备4块0.3 m×0.3 m的对照灰板,以灰板反射率校正研究区的反射率影像。
光谱数据在采集时会受土壤和大气的影响,光谱曲线在350~850 nm波段的范围内较平滑,但在850 nm之后曲线浮动区间较大; 因此,叶片光谱曲线应通过移动平均法降噪[14]。 选择光谱曲线上某点前后一定范围的反射率平均值作为该点降噪后的反射率,具体见式(1)
(1)
土壤采样选择在柑橘树滴落线处,以取土钻采集3处土样,土壤质量含水率用烘干法[15]测定后取均值,生育期内每隔7 d测定1次,降雨及灌溉后5 d不进行取样。
1.3 数据分析方法
1.3.1 BP神经网络
BP神经网络(back propagation neural network)是由误差反向传播算法构建的多层前馈网络,通过梯度连续向前反馈训练和学习,调整并优化连接阈值和权值,使算法实际输出值的误差在允许区间的范围内[16]。 BP神经网络模型是通过数据输入层、 隐含层和输出层构成,其中隐含层存在多层,且在构建过程中,每层神经元之间相互独立,相邻层的神经元间单向连接,以单向连接的权值和阈值调控输入、 输出值[17],BP神经网络模型详见图2。

图2 BP神经网络模型Fig.2 BP neural network model
选择适当数量的隐含层可以有效提高估测精度,隐含层节点数量的计算公式如式(2)[18]
(2)
式(2)中:s为隐含层节点数量;x为输入层节点数量;y为输出层节点数量,本文取1;z为0~10之间的一个常数,隐含层的节点数量每次增加1个步长。
为避免输入变量数据中包含极值数据,延长训练时间,致使网络无法进行收敛,对输入、 输出数据进行归一化处理,使数据压缩到(0,1)的范围内,计算公式[19]如式(3)
(3)
式(3)中:y为归一化后数据;x为输入变量数据(不同植被指数); max、 min分别为不同植被指数参数中的最大值、 最小值。
1.3.2 逐步线性回归法
逐步线性回归法是通过逐步引入对因变量(Y)影响最显著的自变量(Xi),对方程中的原有变量进行检验,当原有变量由于引入了新的变量而不再显著时,应将其剔除,变量的引入和剔除需要进行显著性检验,回归方程中仅包含显著性有效变量,以保证最终方程中,既不包含影响不显著的无效变量,也不缺漏对因变量影响显著的有效变量[20]。
1.4 评价指标
共采集了120组样本光谱数据,随机选取70%(84组)的样本数据作为建模数据集,构建土壤水分反演模型,其余30%(36组)样本数据作为检验数据集,进行模型评价。 选择均方根误差(root mean squared error,RMSE)、 决定系数R2和均方误差MSE为模型精度评价指标,RMSE和MSE越小、R2越接近1,模型的反演精度越高。
2 结果与讨论
2.1 植被指数计算与评价
根据参考文献[21-28]并结合实验获得的植被特征,选择了9种土壤水分遥感监测领域常用的植被指数作为备选指标,分别为绿色归一化指数(green normalization difference vegetation index,GNDVI)、 归一化差异植被指数(normalized difference vegetation index,NDVI)、 裸土指数(bare soil index,BSI)、 归一化蓝绿差异植被指数(normalized blue-green difference index,NGBDI)、 绿波段优化土壤调节植被指数(green optimization soil adjust vegetation index,GOSAVI)、 优化土壤调节植被指数(optimization soil adjust vegetation index,OSAVI)、 归一化绿红差异植被指数(normalized difference green-red index,NDRGI)、 红边优化土壤调节植被指数(red edge optimization soil adjust vegetation index,REOSAVI)和红边重归一化植被指数(red edge renormalized difference vegetation index,RERDVI),计算公式详见表1。

表1 植被指数及计算公式Table 1 Vegetation index and calculation formula
选取120组数据,采用SPSS软件对选定的9个植被指数与土壤水分的相关性进行定量分析,分析结果如表2所示。 BSI、 GNDVI、 GOSAVI、 NDVI、 NGBDI、 NDRGI与土壤水分呈显著相关,其相关性由强到弱依次为BSI>NGBDI>GNDVI>NDVI> GOSAVI>NDRGI; 其余OSAVI、 RERDVI和REOSAVI与土壤水分相关性较差,相关性不足0.5。 综合上述分析结果,选择与土壤水分呈极显著关系的4个植被指数(BSI、 NGBDI、 GNDVI、 NDVI)作为逐步线性回归和BP神经网络反演模型的自变量和输入量。

表2 光谱指数相关系数分析Table 2 Analysis of spectral index correlation coefficients
2.2 土壤水分反演模型构建
2.2.1 土壤水分线性反演模型
选取逐步回归法构建土壤水分线性反演模型,并利用检验样本数据对其精度进行验证,模型拟合精度评价结果见表3。 可以看出,土壤水分最优逐步回归模型为Y(土壤水分)=0.057NGBDI-0.052NDVI+0.078GNDVI-0.847BSI+1.029,决定系数(R2)为0.72,均方根误差(RMSE)为3.60%,表明所建方程拟合效果好,能很好的反映土壤水分与所选植被指数之间的关系。

表3 基于逐步线性回归法建立的土壤水分反演模型Table 3 Soil moisture inversion model based on stepwise linear regression method
为了进一步检验模型预测精度和可靠性,对36组样本数据使用模型进行预测,通过对比分析预测值和实测值的差异,对模型的预测精度进行了评价(图3)。 可以看出,土壤水分反演值与实测值的R2达到0.743,RMSE为3.42%,预测精度较高,说明该模型可很好的反映土壤水分与植被指数之间的关系,可用于土壤水分的反演。

图3 逐步线性回归模型反演检验Fig.3 Stepwise linear regression model inversion test
2.2.2 土壤水分非线性反演模型
采集的120个试验样点光谱特征值(BSI、 NGBDI、 GNDVI和NDVI)和实测土壤水分值分布范围差异较大,最大值分别为1.19、 0.47、 0.92、 0.54和0.27,最小值分别为0.78、 0.01、 0.05、 0.04和0.05,这5种数据的数值区间变化较大,在BP神经网络数据训练前,对4种光谱特征值和实测土壤水分值进行归一化处理,使模型变量数值分布在0~1范围内。 在神经网络模型的学习和训练过程中,可能会发生拟合过度的问题,过度拟合表现为模型拟合训练样本数据时效果较好,但拟合验证样本数据时效果较差。
为避免发生上述情况,通过预停止法[1]对神经网络模型进行训练,防止神经网络模型过度拟合。 依据式(2),隐含层以3为第一个节点数,分别设置3~13数量的节点,利用84个试验样点数据对BP神经网络土壤水分反演模型进行训练,对12个试验样点数据进行验证,24个试验样点数据进行测试。 不同隐藏层节点数模型测试的R2和MSE见表4。 当R2最大,MSE最小时,对应的是最优节点数。

表4 不同隐含层节点数的BP神经网络模对土壤水分的反演精度Table 4 Inversion accuracy of soil moisture by BP neural network model with different numbers of hidden layer nodes
由表4可知,隐含层节点数为12时,BP神经网络土壤水分反演模型R2最大,为0.767,MSE最小,为2.027; 隐含层节点数为6时,模型R2最小,为0.488,MSE最大,为3.612。 可见,隐含层节点数的变化对BP神经网络土壤水分反演模型的精度和拟合效果均有较大影响,选取适宜的隐含层节点数可有效提高模型精度。 基于土壤水分反演模型的精度结果建立模型结构为(4,12,1)(4表示BP神经网络土壤水分反演模型输入变量BSI、 NGBDI、 GNDVI和NDVI,12表示模型隐含层节点数,1表示模型输出变量土壤水分反演值)。 BP神经网络土壤水分反演模型训练及测试结果见图4,模型训练决定系数R2为0.767,MSE为2.027,模型测试决定系数为0.864,MSE为1.963,模型测试结果精度较高,说明该模型可较好的反映土壤水分与植被指数之间的关系,可用于土壤水分的反演。

图4 BP神经网络模型反演检验(a): BP模型训练结果; (b): BP模型测试结果Fig.4 Inversion test of BP neural network model(a): BP model training results; (b): BP model test results
2.3 模型精度评价
将宜昌市农科院柑橘试验站25个样点的BSI、 NGBDI、 GNDVI和NDVI数据分别代入逐步回归土壤水分反演模型和BP神经网络土壤水分反演模型中计算土壤水分,将两种模型的反演值与土壤水分的实测值进行回归分析,结果见图5。 可知,25个试验站验证样点的土壤水分实测值为6.2%~23.1%,逐步回归土壤水分模型的反演值为8.1%~21.1%,BP神经网络土壤水分模型的反演值为7.0%~24.6%,两模型的反演值和实测值之间的R2分别为0.816、 0.889,RMSE分别为2.54%、 1.53%,相对误差绝对值(absolute relative error,ARE)分别为21.13%、 8.88%,表明BP神经网络土壤水分反演模型的精度高于逐步回归土壤水分反演模型。 对比分析不同分段土壤水分的光谱反演精度,详见表5。 4种分段下非线性模型的反演精度均高于线性模型,除20%~25%土壤水分外两种模型在绝对误差和相对误差变化规律一致,10%~15%土壤水分的平均绝对误差值最小为0.015 9,相对其他3种差异性不明显,20%~25%土壤水分的平均相对误差最小为0.072 5,相对其他3种差异性不明显。
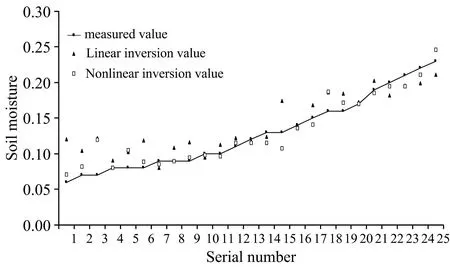
图5 线性与非线性模型土壤水分反演值和实测值对比Fig.5 Comparison of inversion and measured values of soil moisture in linear and nonlinear models

表5 不同含水率线性与非线性模型反演精度Table 5 Inversion accuracy of linear and nonlinear models with different water content
目前,土壤水分反演模型主要包括植被指数模型[11]、 微波遥感模型[29-31]、 经验积分模型[32]和热惯量模型[33-34]等。 其中微波遥感模型、 经验积分模型和热惯量模型在建模过程中难以消除植被覆盖度对土壤水分反演的影响,所建模型的普适性和准确性难以保证,仅适用于植被覆盖度较低的地区; 植被指数模型对土壤背景的变化较为敏感,单一植被指数由于检测灵敏度较高,在植被覆盖度高的地区效果较好,但在植被稀疏、 沙漠或裸土地区效果较差。 杨娜等[11]研究表明单一植被指数NDVI仅在0.2~0.78范围内的反演精度较高,R2达到0.785。 为了消除单一植被指数灵敏度高的局限性,选取了9个植被指数用于建立多种植被覆盖度的土壤水分反演模型,采用线性逐步回归法和非线性BP神经网络法对土壤水分进行反演; 以灰色关联度法筛选出4个与土壤水分呈极显著关系(p<0.01)的植被指数(BSI、 NGBDI、 GNDVI和NDVI),以此建立线性逐步回归法和非线性BP神经网络法的多种植被指数土壤水分反演模型,两种模型的反演精度分别为78.4%和80.5%,BP神经网络模型反演精度较逐步回归模型提高了2.7%,可更有效的反演土壤水分。 同时柑橘园地处丘陵地带,所选择样本柑橘树为不同坡度种植,且取样周期较长,因此土壤含水率变幅较大(0.05~0.26),涵盖绝大多数土壤含水率,可保证模型的普适性。
通过对比线性和非线性建模发现,基于多种植被指数的土壤水分反演模型精度受植被指数数量和建模方法的影响较大。 2种及以下的植被指数模型可以提供的信息过少,容易受到背景因素干扰,导致稳定性缺失,土壤水分反演精度不足0.6,其原因为在不同背景下的地表植被与作物光谱反射率的分辨效果不同; 且植物在水分亏缺时,叶片光谱反射率会发生明显变化,由此影响模型精度。 王佳儿等[35]在不同土壤背景下通过多光谱反射率构建土壤含水率反演模型,结果表明未剔除土壤背景的模型精度在任何深度均高于剔除土壤背景的模型。 非线性模型能有效探索植被指数间复杂的线性关系,其精度高于线性模型; 其中,非线性BP神经网络建模是通过梯度下降搜索更新阈值和权值,逐步减小输出误差,直到满足期望后输出[36]。 线性逐步回归法建模是采用简单的线性拟合方法获得输出值[37]。 因此BP神经网络可有效提高土壤水分的反演精度。 目前,农田土壤水分遥感反演尚无统一模型,多光谱遥感在农田小气候信息中的应用还处于探索阶段,在基于植被指数对不同植被覆盖度的土壤水分反演精度方面仍需深入研究。 现有研究表明,土壤水分与气象因子之间存在较高的相关性,为提高模型精度和适用性,在下一步研究中考虑结合气象因素对土壤水分反演模型进行修正和完善。
3 结 论
选取了9种植被指数用于土壤水分的反演模型构建,通过相关性分析法筛选出与土壤水分关联度较高的4个指数,并利用逐步回归法和BP神经网络法构建土壤水分反演模型,对比分析结果如下:
(1)BSI、 NGBDI、 GNDVI和NDVI与土壤水分在p<0.05水平下极显著相关,相关系数分别为-0.687、 -0.623、 -0.592、 -0.572。
(2)逐步回归法最优土壤水分反演模型为:Y=0.057NGBDI-0.052NDVI+0.078GNDVI-0.847BSI+1.029,决定系数R2为0.720,RMSE为3.60; BP神经网络法最优土壤水分反演模型R2为0.767,MSE为2.03。
(3)通过逐步回归模型和BP神经网络模型对土壤水分进行反演,反演值与实测值之间的R2分别为0.816、 0.889,RMSE分别为2.54%、 1.53%,ARE分别为21.13%、 8.88%,表明BP神经网络模型精度高于逐步回归模型,可有效提高土壤水分反演精度。
致谢:感谢三峡大学徐文老师在论文的修改及润色方面对我深刻细致的指导,以及为实验提供经费支撑,帮助我顺利完成论文的撰写。
猜你喜欢
中等数学(2022年5期)2022-08-29 06:07:38
水土保持研究(2018年5期)2018-10-12 05:29:52
中国农业信息(2018年2期)2018-07-28 08:02:10
石油地球物理勘探(2017年4期)2017-12-18 07:14:55
石油地球物理勘探(2017年2期)2017-11-23 06:02:04
高原山地气象研究(2016年2期)2016-11-10 06:06:27
西藏科技(2015年1期)2015-09-26 12:09:29
科技创新与应用(2015年28期)2015-05-30 20:03:40
长江大学学报(自科版)(2014年2期)2014-03-20 13:20:30
塔里木大学学报(2014年3期)2014-03-11 18:47:27
