
基于可见/近红外光谱与化学计量学的杏品种无损鉴别方法
2024-01-12 05:54:26邢雅阁罗华平张远华
光谱学与光谱分析 2024年1期
高 峰,邢雅阁,罗华平,张远华,郭 玲*
1. 塔里木大学机械电气化工程学院,新疆 阿拉尔 843300 2. 自治区教育厅普通高等学校现代农业工程重点实验室,新疆 阿拉尔 843300 3. 塔里木大学园艺与林学学院,新疆 阿拉尔 843300 4. 新疆生产建设兵团塔里木盆地生物资源保护利用重点实验室,新疆 阿拉尔 843300
引 言
新疆南疆地区得益于其独特的自然地理环境,孕育了极其丰富而又复杂的杏种质资源。 根据2021年FAO数据记载,我国杏树种植面积为2.46万ha,年产量为6.90万t,产量为2.8 t·ha-1,而南疆是我国杏种植面积最大的地区,鲜果远销到全国各地。 杏果肉富含多糖、 多酚、 类胡萝卜素、 类黄酮和有机酸等多种活性物质[1-3],具有很高的营养价值。 不同品种的杏在品质和价格方面差异很大,仅仅通过外观难以区分和鉴定,化学分析法可以实现杏的品种鉴别[4],但检测时间长、 成本高,不利于推广使用。 随着杏鲜果产业的兴起,实现杏果实的在线分拣鉴定显得尤其重要。
光谱分析技术通过利用化学计量学方法在样品光谱数据和待测属性之间建立联系,实现定性和定量分析,具有分析速度快、 成本低、 无破坏性等特点,经过近半个世纪的发展,已经较为成熟[5],广泛应用于食品[6]、 医疗[7]、 环境[8]等各个方面。 在食品与农副产品的掺假鉴别、 品种识别、 产地溯源等定性分析方面,Zhang等[9]使用近红外光谱结合模式识别方法,实现掺假食用明胶的鉴定。 Li等[10]和Cortes等[11]使用近红外光谱实现了苹果品种的鉴别。 Tong等[12]使用近红外光谱与化学计量学方法实现水稻的品种和来源的鉴别。 何勇等[13]使用中红外光谱和反向传播神经网络(BPNN)模型实现核桃产地及品种的鉴别。 Dan[14]利用近红外光谱与机器学习方法,实现对橙子产地的鉴别。 Qian等[15]使用傅里叶近红外光谱和偏最小二乘判别实现绿豆产地和品种的判别。 在杏品种鉴别方面,采用光谱分析技术实现杏品种鉴别的研究有待开展。 以新疆南疆地区的6个品种杏为研究对象,采集样品在350~1 000和1 000~2 500 nm两个范围的光谱数据,结合化学计量学算法检测杏的品种,建立杏品种的准确鉴别模型。
1 实验部分
1.1 材料与试剂
在新疆生产建设兵团第一师阿拉尔市分别采集“黄杏”、 “橄榄杏”、 “小白杏”、 “小米杏”、 “库买提杏”、 “小吊干杏”6个品种杏样品,使用便携式车载冰箱冷藏保存后带回实验室,待样品恢复至室温后采集光谱。 挑选同一品种中大小均匀一致、 表面色泽鲜亮且无损伤的样品,最终每个品种挑选出90个作为实验对象,共计540个样品。
1.2 仪器与设备
使用美国海洋光学公司的USB-650红潮(Red Tide)光谱仪(350~1 000 nm)、 ISP-REF反射式积分球(自带光源)、 标准白板(STAN-SSH)采集样本可见/近红外(visible/near infrared,VIS/NIR)范围光谱; 使用美国赛默飞世尔的Antaris Ⅱ FT(NIR型傅里叶近红外光谱仪(1 000~2 500 nm)采集样本近红外(near infrared,NIR)范围光谱。
1.3 方法
1.3.1 光谱采集
将样品从车载冰箱中取出后,使用纸巾将样品表面擦拭干净,等待恢复至室温后开始采集光谱。 采集样品VIS/NIR范围光谱时,对海洋光学USB-650光谱仪及ISP-REF反射式积分球(自带光源)进行预热30min,使光源趋于稳定。 以标准漫反射白板作为参考,去除背景噪声,将样品放置于反射式积分球上,采集样品赤道部位光谱,光谱仪设置为自动参比,光谱平均次数为4,光谱平滑次数为1,并按照采集顺序保存光谱数据。 使用Antaris Ⅱ FT-NIR傅里叶近红外光谱仪采集样品NIR范围光谱时,提前预测光谱仪自带光源30 min,之后以仪器内部空气为背景进行参比,将样品放置于光谱采集装置上,采集样品赤道部位光谱,确保光谱采集区域与VIS/NIR范围光谱一致。 设置谱区采集范围: 1 000~2 500 nm,光谱分辨率: 4 cm-1,扫描次数: 32次,增益: 4倍,之后保存光谱数据。
1.3.2 数据处理
光谱采集时受仪器噪声及环境光影响会产生一定噪声,对光谱数据进行Savitzky-Golay(SG)卷积平滑处理(设置窗口数为5,拟合3次多项式),以降低光谱信号中背景噪声与基线漂移。 不同品种杏的表皮光滑程度不同,因此对光谱进行多元散射校正(multiple scatter correction,MSC)处理,以消除杏表皮差异带来的散射影响。
全波段光谱数据中可能含有对品种分类没有帮助的冗余信息,且全光谱数据建立的模型复杂程度较高、 工作效率低,不利于实际应用; 利用化学计量学方法对光谱数据降维,从而简化模型,提高工作效率[16-17]。 使用主成分分析(principal component analysis,PCA)、 竞争性自适应加权算法(competitive adaptive re-weighted sampling,CARS)、 随机蛙跳算法(random frog,RF)、 连续投影算法(successive projection algorithm,SPA)4种方法对光谱数据进行降维,降低光谱数据共线性。
为获取可靠分类结果,选用线性判别法(linear discriminant analysis,LDA)、 朴素贝叶斯(Naive Bayesian,NB)、 k近邻法(K-nearest neighbor,KNN)、 支持向量机(support vector machine,SVM)4种方法建立分类模型并进行对比。 KNN模型设置最近邻数量为5,SVM模型使用线性内核。 使用混淆矩阵计算分类精度,准确率(accuracy)为分类模型的评价指标。 准确率越接近1,说明模型预测效果越好。
(1)
式(1)中:TP实际为正,预测为正的数量;TN实际为负,预测为负的数量;FP实际为负,预测为正的数量;FN实际为正,预测为负的数量。
2 结果与讨论
2.1 不同品种杏的光谱曲线特征分析
由于350~400 nm范围光谱包含大量噪声,选择400~1 000和1 000~2 500 nm范围内光谱进行后续分析。 图1(a)和(b)为6个品种的杏经过预处理后的平均光谱。 由图1可以看出,各类光谱有着相同的变化趋势,光谱图中波峰、 波谷位置基本一致,说明杏果实所含的水分、 糖分、 有机酸等成分有相同之处,光谱吸收峰强度差异可能与品种间各组分含量有关。 图1(a)中,400~500 nm可见光谱反射值较低,对应为类胡萝卜素光谱吸收范围,680 nm处出现明显吸收峰对应C—H振动,540~680和720~920 nm两处出现较宽的反射峰对应果肉中多种有机物的含氢基团。 图1(b)可见光谱中,1 200 nm附近吸收峰对应C—H的第三泛频带,1 450 nm附近吸收峰与O—H键的一级倍频伸缩振动有关,1 950 nm附近吸收峰对应C—H和C—O的组合带,与杏果肉中的果胶、 类胡萝卜素、 有机酸等物质在近红外光谱的吸收有关。

图1 杏可见光光谱(a)与近红外光谱(b)Fig.1 Visible spectrum (a) and Near infrared spectrum (b) of Apricot
2.2 基于全波段光谱的杏品种分类模型
将样本按照3∶1的比例划分为训练集和预测集,基于全波段光谱数据建立LDA、 NB、 KNN和SVM分类模型,预测集预测结果如表1所示。 在VIS/NIR范围内,4种模型的总分类正确率均大于80%,其中SVM模型的总分类正确率高达95.7%。 同时,“库买提杏”和“小吊干杏”在4种模型中分类正确率均较高,可能与其光谱在540~680 nm范围与其他品种杏有较大差异有关。 NIR范围内,NB与KNN模型的分类效果较差,正确率仅为64.5%、 65.2%,而LDA与SVM模型的分类效果较好,正确率分别为97.8%、 90.6%。 在4种模型中,不同品种杏的分类正确率无较大差异,原因可能是NIR范围内不同品种杏的光谱无明显差异。 由以上结果可知,基于全光谱数据结合合适的建模方法可以较好地实现对不同品种杏的鉴别分析,且VIS/NIR范围内模型的平均分类正确率更高,更适用于杏品种的区分; 4种分类模型中,NB与KNN模型在NIR范围的分类正确率较低,说明NB和 KNN可能不适用于NIR范围内杏品种的判别分析。 由于全光谱模型运算效率低,不利于实际应用,部分模型预测效果较差可能与全光谱数据中存在的与分类无关的冗余信息有关,因此有必要对光谱数据降维。
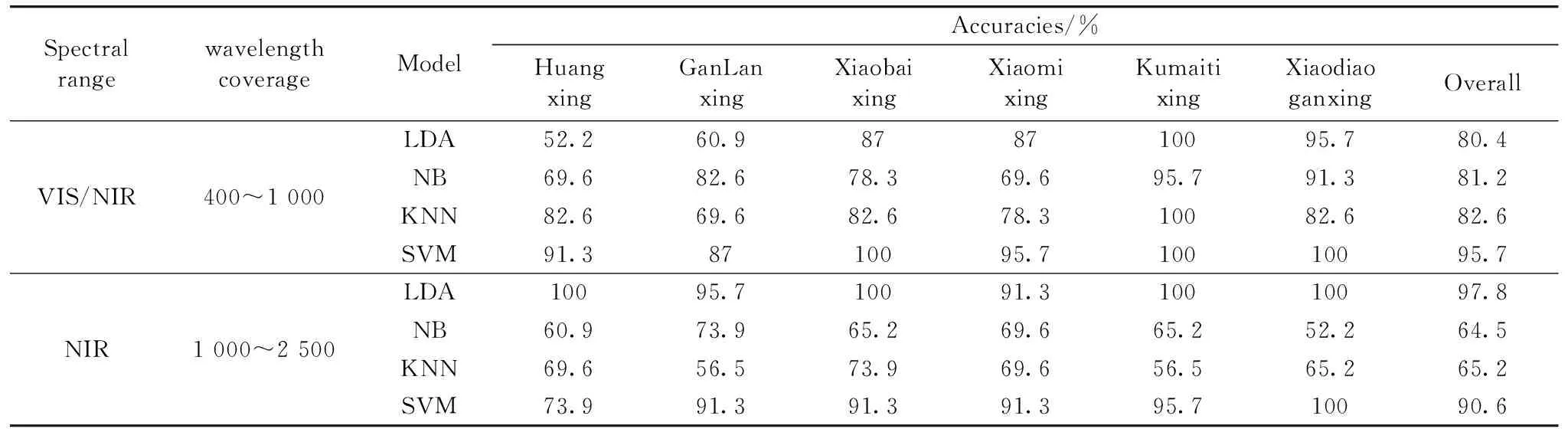
表1 基于全波段光谱的分类模型对比Table 1 Comparison of classification models based on full-band spectrum
2.3 全波段光谱的主成分分析
PCA基于数学变换原理,降维后的数据能保留原始变量的信息,且变量彼此间互不相关。 前20个主成分的累积贡献率如图2(a,b)所示。 在两个光谱范围内,取前3个主成分时,累积贡献率都在95%以上,说明前3个主成分已经能很好地表达原始光谱数据中的信息。 前3个主成分的空间分布图如图3(a,b)所示。 在VIS/NIR范围内,6类杏样本的空间分布有一定差异,但无法实现准确区分,在NIR范围内,6类杏样本的空间分布有很大程度重叠交织,无法实现品种区分。 取前三个主成分时,能很好表达原始光谱信息,但无法实现很好的分类效果,使用PCA降维后的数据进行杏品种分类识别时,应当对比分析选择不同主成分数目时的建模结果。

图2 杏光谱主成分分析的累积贡献率(a): 可见光谱; (b): 近红外光谱Fig.2 Cumulative contribution rate of PCA for apricot spectra(a): Visible spectrum; (b): Near-infrared spectrum

图3 杏光谱主成分分析的前三个主成分分布图(a): VIS; (b): NIRFig.3 Principal components analysis score plot of apricots(a): VIS; (b): NIR
2.4 基于PCA降维的杏品种分类模型
为了探究PCA降维对各模型分类结果的影响,基于PCA选取不同主成分数目对原始光谱数据进行降维,结合4种建模方法建立不同分类模型,结果如图4(a,b)所示。 由图4(a,b)可知,主成分数目对各模型分类结果有较大影响,且各模型的分类正确率变化趋势一致; 4种分类模型中,LDA、 NB、 SVM三种模型的分类效果优于KNN模型; 两个范围光谱的模型中,VIS/NIR范围内的模型分类效果优于NIR范围内的模型。 对比PCA降维模型与全光谱模型的预测结果可知,在VIS/NIR范围内,LDA与NB模型的总分类正确率得到显著提升,分别由80.4%、 81.2%提升至最高97.8%、 94.2%; 在NIR范围内,NB模型的总分类正确率相比于全光谱模型得到显著提升,由64.5%提升至89.1%; 两个范围光谱中,KNN和SVM模型对全光谱与PCA降维数据的判别结果无明显差异; NIR范围内,LDA模型的分类正确率低于全光谱模型,但由图4趋势可知,当主成分数目继续增加时,其分类正确率会与全光谱模型结果一致。 以上结果表明,PCA降维能够简化模型,提高部分模型的预测效果。
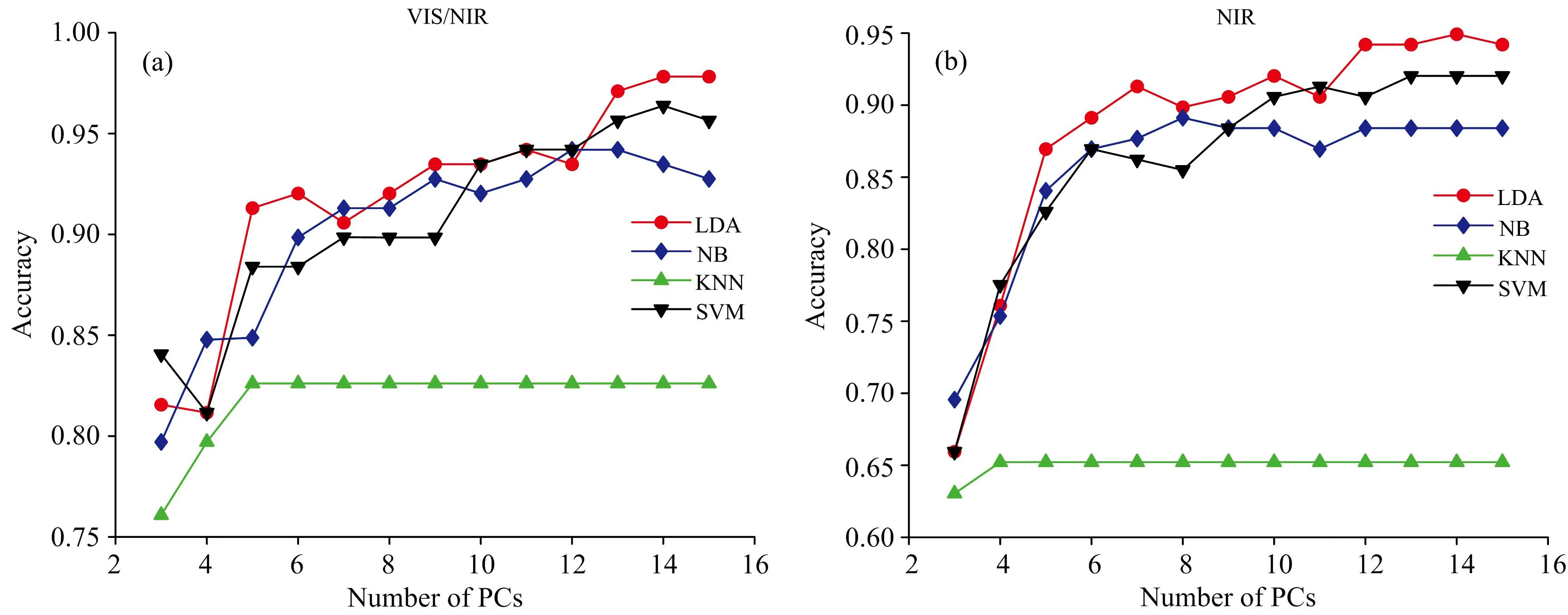
图4 主成分数目对模型分类结果的影响(a): VIS; (b): NIRFig.4 The effect of PCs on the classification results(a): VIS; (b): NIR
2.5 特征波长提取
2.5.1 基于CARS的特征波长提取
CARS采用随机取样方法,选择一部分样本建立偏最小二乘模型,重复迭代N次,最终选择交互验证均方根误差(RMSECV)最小的一组变量。 CARS选择特征波长的过程如图5(a,b)所示,设置迭代次数50次,最大主成分数为20,交互验证次数为10次,随着迭代次数增加,RMSECV呈现先降后升的趋势。 在VIS/NIR范围内,第14次采样时RMSECV最小,选择了132个特征波长,占全波段的21.96%; NIR范围内,第17次采样时RMSECV最小,选择了177个特征波长,占全波段的11.36%。 由于使用CARS方法选择的特征波长数量较多,可能仍包含与分类无关的信息,因此使用SPA方法进一步筛选特征波长。 经SPA进一步筛选后,在VIS/NIR范围内,选择的特征波长数量由132降为25,在NIR范围内,特征波长数量由177降为26,分别占全波段的4.16%、 1.67%。

图5 CARS选择杏光谱特征波长结果(a): 可见光谱; (b): 近红外光谱Fig.5 Result for variable selecting by CARS in the spectra of apricot(a): Visible spectrum; (b): Near-infrared spectrum
2.5.2 基于RF的特征波长提取
RF基于初始变量提取子集进行多次迭代计算,最终给出每个变量的选择概率,选择概率较高的变量则为特征波长。 选择特征波长时,设置初始抽样变量为2,模拟蛙跳次数2 000次,阈值为0.2。 对全波段光谱使用RF选择特征波长,结果如图6(a,b)所示。 在VIS/NIR范围内,选取了173个特征波长,占全波段的27.79%,NIR范围内,选择了142个特征波长,占全波段的9.12%。 由于使用RF选择的特征波长数量仍然较多,使用SPA方法进一步优化筛选特征波长。 经过SPA再次筛选后,在VIS/NIR范围内,选择的特征波长由173降为10,在NIR范围内,特征波长数量由142降为25,分别占全波段数量的1.66%、 1.60%。
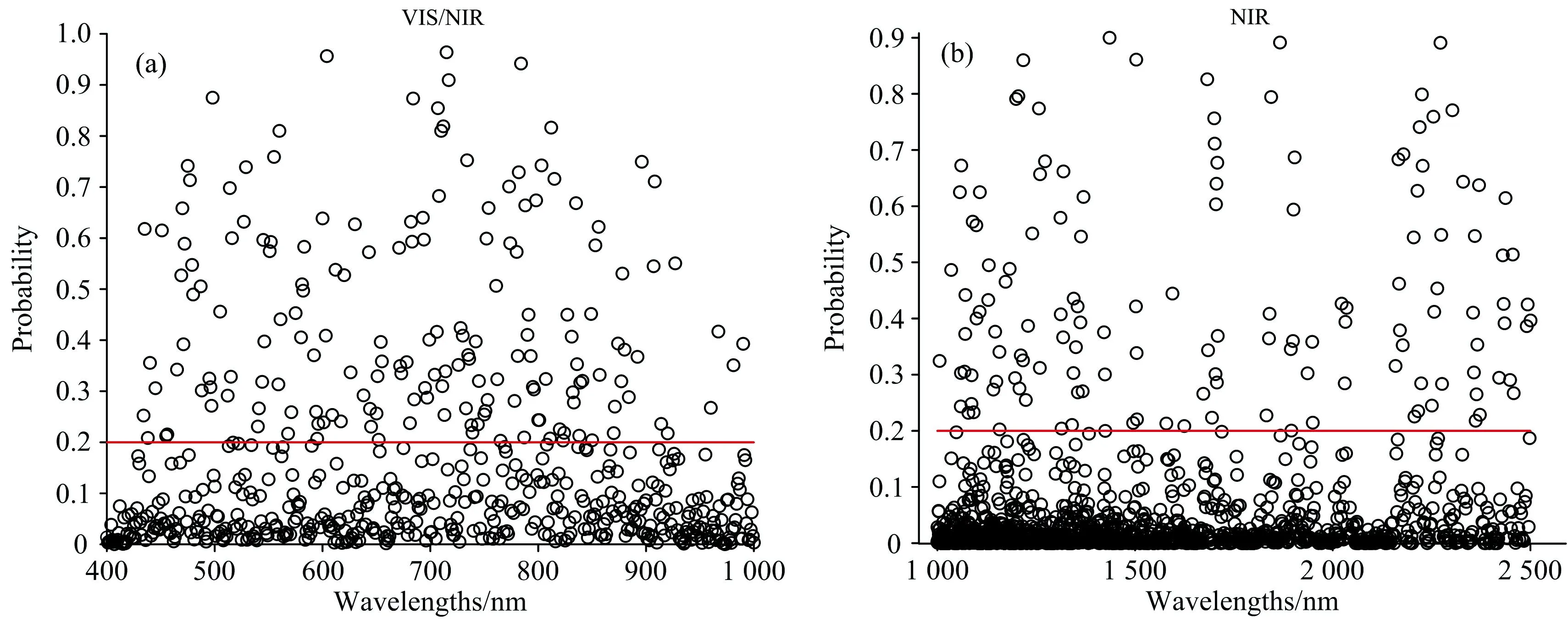
图6 RF选择杏光谱特征波长结果(a): 可见光谱; (b): 近红外光谱Fig.6 Result for variable selecting by RF in the spectra of apricot(a): Visible spectrum; (b): Near-infrared spectrum of apricot
2.5.3 基于SPA的特征波长提取
SPA基于向量的投影分析,将波长投影到其他波长上,选择不同波长向量投影中最大的波长为特征波长,将这些特征波长点组成波长子集,最终选择的波长组合即为特征波长组合,能够有效降低数据共线性。 选择特征波长时,设置特征波长上限为50。 对全波段光谱使用SPA筛选特征波长,结果如图7(a,b)所示。 在VIS/NIR范围内,选取了10个特征波长,占全波段的1.66%; NIR范围内选择了27个特征波长,占全波段的1.73%。
2.6 基于特征波长建立的杏品种分类模型
为了验证CARS、 RF与SPA选择的特征波长对各模型分类结果的影响,基于特征波长建立不同分类模型,结果如表2、 表3所示。 由表2可知,在VIS/NIR波段,CARS-SPA-LDA与SPA-SVM模型的分类正确率最高,均为95.7%,但SPA-SVM仅使用了10个特征波长,因此模型更为简洁。 由表3可知,在NIR波段,RF-SPA-LDA分类正确率最高,达到95.7%,对应的特征波长数量为25。 对比表2与表3,VIS/NIR范围光谱建立的模型分类效果更优; 4种分类模型中,LDA与SVM模型的分类效果优于NB与KNN模型; VIS/NIR范围内,SPA方法选择的特征波长建模效果最优,NIR范围内,RF-SPA方法选择的特征波长建模效果最优。 通过比较表1与表2、 表3可知,经过三种方法选择特征波长后,仅有VIS/NIR范围内的LDA模型的分类精度得到明显提升,由80.4%提升至最高95.7%。 整体上VIS/NIR范围内其他三种模型与NIR范围内4种模型的分类效果均略低于全光谱模型,原因可能是选择特征波长时,部分对分类有用的信息被剔除,影响了分类结果。

表2 基于VIS/NIR降维数据的模型分类结果Table 2 Classification model results based on VIS/NIR dimensionality reduction data

表3 基于NIR降维数据的模型分类结果Table 3 Classification model results based on NIR dimensionality reduction data
通过比较表1、 图4、 表2、 表3结果可知,整体上VIS/NIR范围内模型的分类效果优于NIR范围内模型。 最优预测模型为VIS/NIR范围内的PCA-LDA模型,分类正确率高达97.8%,且仅使用了前14个主成分; 经过降维后LDA模型分类正确率得到有效提升; NB与KNN模型在降维前后分类精度变化不大,模型较为稳定,但总体分类效果较差; SVM模型在降维前后分类效果变化幅度较小,且能保持较高分类正确率。 LDA与SVM模型更适用于杏品种的鉴别。
3 结 论
基于“黄杏”、 “橄榄杏”、 “小白杏”、 “小米杏”、 “库买提杏”、 “小吊干杏”在VIS/NIR与NIR两个范围的光谱结合化学计量学方法建立了一种杏品种快速无损鉴别的方法。 结果表明: 全光谱数据建立的模型可以实现不同品种杏的鉴别,最高鉴别正确率达到97.8%; 经过降维后,模型依然能保持较高的正确率,VIS/NIR范围内,部分模型的鉴别正确率提高,NIR范围内,模型鉴别正确率无明显提升,表明选择合适的降维及建模方法能够简化模型、 提高模型预测能力。 对比不同模型结果可知,基于VIS/NIR范围光谱建立的模型鉴别能力较好; 几种降维方法中PCA降维效果最优,不仅能简化模型还提升了部分模型的鉴别正确率; 4种分类器中,LDA与SVM更适用于杏品种的鉴别,降维后仍能保持较高正确率。 研究结果表明,基于VIS/NIR范围光谱结合PCA与LDA可以实现不同品种杏的鉴别分析,对杏果实的在线分拣鉴定有一定的指导意义。 在今后的研究中,将对其他品种杏进行分析,建立更为完善的杏品种鉴别模型。 同时,考虑经济效益,应当将杏的品质指标与光谱建立联系,探究一种能同时实现品种定性判别与品质定量检测的方法。
猜你喜欢
ELLE世界时装之苑(2024年5期)2024-05-14 09:45:39
车主之友(2022年4期)2022-08-27 00:57:12
中华养生保健(2020年7期)2020-11-16 01:14:26
海峡姐妹(2019年12期)2020-01-14 03:24:40
家教世界·创新阅读(2016年11期)2016-12-27 18:49:15
天津护理(2016年3期)2016-12-01 05:40:01
故事会(2016年15期)2016-08-23 13:48:41
高师理科学刊(2016年8期)2016-06-15 20:27:45
西藏科技(2015年4期)2015-09-26 12:12:58
计算物理(2014年1期)2014-03-11 17:00:18
