
基于机器学习的水平定向钻钻孔围岩智能分类探讨
2024-01-11 13:56张晟斌,舒恒,刘夏临,黄胜,周浩
人民长江 2023年12期
张 晟 斌,舒 恒,刘 夏 临,黄 胜,周 浩
(1.中交第二公路勘察设计研究院有限公司,湖北 武汉 430056; 2.中国交建隧道与地下空间工程技术研发中心,湖北 武汉 430056; 3.中山大学 土木工程学院,广东 珠海 519080)
0 引 言
随着一系列重大战略工程的启动与实施,复杂环境下隧道工程的地质智能化、精细化勘察成为工程建设重难点[1]。传统垂直钻探勘察钻孔离散大、无效钻进多、勘察偏差大,无法适用于沿线地形高差大、交通条件差、穿江过海、高山峡谷等环境的条件限制,为此部分学者提出采用水平定向钻技术进行地质勘察的新思路[2]。其具体过程为沿设计轴线钻出勘察孔,后续在孔内开展水压致裂、综合测井和孔内电视等测试作业,对重点区段进行非连续间断取芯等。一系列测试手段可探明隧道沿线地应力大变形、地震断裂带分布、涌水量、地温、水温等隧道地质情况,从而改传统垂直“点”勘察为水平“线”勘察,有效避免传统钻孔勘察的“一孔之见”[3]。目前该项技术已在新疆乌尉公路天山胜利隧道首次成功运用[2],部分学者也在川藏铁路建设上开展了探索[4-6]。
在水平定向钻地质勘察作业中,钻孔围岩质量评价是隧道设计和施工的基石。围岩分类是评价围岩质量的一种主要方法,可较为全面地反映围岩的强度特征、变形特征和隧洞工作面的稳定性特征,可直接用于指导隧洞的设计和施工。目前对隧道围岩进行分类主要采用定性的方法,一般是通过室内试验进行定量的验证,且需要广泛的专业知识和工程经验[7];采用全孔取芯进行定性定量分析虽可更直观地反映围岩岩性,但受限于过长时间周期与过高施工成本,在实际工程中并不适用。
水平定向钻施工涉及多种仪器设备、钻头钻具,施工过程中将产生大量数据,当样本数量充足且相关数据与围岩岩性有内在联系时,运用人工智能与大数据技术建立相关岩性预测模型也为研究思路之一[8-9]。现有研究证实钻孔参数与围岩质量之间存在着一定的关系,将随钻参数应用于围岩智能分类具有信息自动采集、实时分析、无需额外工作的天然优势。作为人工智能研究的重要方法,机器学习已应用于多种类型的隧道分析,如变形预测、岩性预测、岩爆预测、可靠性分析、稳定性分析等[10]。特别是对于高度非线性的问题,机器学习方法往往比传统的统计分析方法具有更好的性能和更高的计算效率。此外机器学习方法具有自动分析和持续学习的智能特征,特别适用于围岩智能分类问题的研究。在岩性识别领域,已有研究表明随钻参数与地层信息有密切关系,并基于机器学习算法开展了大量研究,如Honer[11]、Qin[12]、谭卓英[13-14]、岳中琦[15]等基于地勘钻孔信息与钻进参数评判区分地层岩性;李国和等[16]以地震数据作为输入,以岩性数据作为输出,建立深度信念网络(DBN)模型,实现地层岩性识别;王光宇等[17]提出基于随机森林算法的岩性预测方法,经数据不平衡处理后准确率可达83%;易文豪等[18]构建基于支持向量机的隧道围岩模型,岩性识别的平均准确度达到87.9%;此外,Wang[19]、汤志立[20]等也分别基于不同机器学习算法开展了大量关于岩爆预测方面的研究。上述研究表明,构建基于钻进参数的机器学习算法模型来识别岩性,在一定程度上具备可行性与可靠性,但如何对围岩岩性定量分析,如何更客观智能地进行围岩分类,仍需要进一步研究。
开展基于随钻参数与算法的超长水平定向钻钻孔围岩智能分类方面的研究,对推动水平定向钻智能化、精细化地质勘察有着重要意义。工程岩体质量评价方面,香港大学岳中琦[15]团队开发的钻孔过程监测(DPM)技术可对钻孔时空数据进行实时快速分析,但其基本都基于传统的气动潜孔锤旋转冲击钻或液压回旋勘探钻井。相较而言,采用超长水平定向钻技术进行钻孔围岩分类与评价有2个不同点:① 数据采集与分析方面,水平定向钻随钻参数相较气动潜孔锤旋转冲击钻更为平稳,在钻机振动、钻机输出功率变化、钻进速度等方面波动更小,参数的稳定性与连贯性有利于建立钻进参数与岩体力学间的确定性关系[14-15],机器学习分析方法可更适应随钻参数随机性、不确定性和非线性的特点;② 工程应用方面,水平定向钻地质勘察一般应用于管-隧-洞等超长线性工程,对孔内围岩确定与分类不仅有全孔/间断取芯方法,也可利用钻进过程中的钻孔环空运移岩屑,以及对测试过程中的孔内电视数据结果进行验证[2],数据来源的广泛性与真实性便于工作人员对孔底情况把握更为清晰,有助于实现线性工程的超长距离精细化勘察。
基于此,本文以天山胜利隧道水平定向钻地质勘察项目工程为例,首先介绍钻孔围岩岩样数据采集方法及判别结果;其次对泥浆压力、钻进速度及修正孔底钻进压力等关键钻进参数进行初步分析,建立包含过采样后820组围岩分类数据库;之后引入多种机器学习算法构建相应围岩预测模型,并采用网格搜索交叉验证的方法进行调参优化,以准确率、精确率、召回率、F1值等为性能度量指标对各模型分类性能进行评估验证与探讨;最后通过与现有围岩分类方法比较,分析并探讨基于随钻参数与算法的超长水平定向钻钻孔围岩智能分类方法的优劣势与发展趋势。
1 工程概况
1.1 工程背景
在建的新疆天山胜利隧道,是G0711乌尉高速公路中的关键控制性工程,全长近22 km,建成后将有力推动南北疆交流互通,为“一带一路”发展奠定坚实基础。图1为隧道轴线及勘察轨迹设计图。根据隧道初勘资料,隧址区主要地质构造为华里西期构造区,对线路有影响的构造主要有F6和F7断裂,其中F6断裂(博-阿断裂带)距离隧道入口处大约1.9 km,影响范围约200 m,在新构造运动阶段仍有活动;隧道施工环境极为恶劣,面临高地应力、高海拔、高地震烈度、高寒等特殊环境,隧道设计、施工阶段难度极大,对隧道沿线工程水文地质详细勘察具有必要性与紧迫性。

图1 隧道轴线及勘察轨迹设计Fig.1 Design of tunnel axis and survey track
作为一种新型变革性地质勘察技术,采用水平定向钻进技术对隧道沿线进行精细地质勘察有其显著优势与可行性,其超长距离、超高精度、超快速度、超强适应能力等“四超”特性可有效避免传统垂直钻孔勘察的“一孔之见”[2]。项目使用江苏谷登工程机械装备有限公司生产的GD3500-L型钻机,现场导向钻具组合包括9 7/8英寸(250.8 mm)三牙轮镶齿钻头、1.5°172 mm螺杆泥浆马达、172 mm无磁钻铤与168 mm钻杆等;除对钻进过程中相关钻进参数进行收集外,同时开展非连续间断取芯(1 003 m和1 900 m钻孔深度位置)、综合测井、孔内电视等测试,以对相应钻进深度的地层有较为精准的识别把控。
1.2 围岩勘察分类
1.2.1数据采集方法
围岩岩样数据采集主要有岩屑收集、孔内电视、间断取芯等方法,涉及岩样实物、视频等数据资料,采集方案基本如下:
(1) 岩屑收集。为确保采集到的岩屑为“新鲜”岩屑,以钻杆为单位,在现场每根钻杆正常钻进过程中进行岩屑采集。采集时将准备好的筛网设在返浆口,泥浆透过筛网流进返浆池,岩屑留在筛网中;将筛网中的岩屑倒入岩屑样盆,加入无污染清水小心初次清洗滤掉泥浆;将采集到的岩屑保存至自封袋,并写好标签,每份岩屑不少于500 g;每次取样后,清除残留在筛网上的岩屑并清洗岩屑样盆,以备下次取样使用。
(2) 孔内电视。图2为孔内电视数据采集方法,在勘察孔钻至目标孔深后抽出孔内所有钻具,并以孔内电视仪器替换前方钻头;开启孔内电视设备并缓慢推入孔内,对孔内状况进行全程高清视频录像,待至孔底缓慢拉回,完成视频检测工序。推拉过程中不注入泥浆不旋转钻杆,相应视频可清晰记录孔内围岩岩性、节理裂隙发育、断裂破碎带位置及程度。

图2 孔内电视数据采集方法Fig.2 Data acquisition method of in-hole television
(3) 间断取芯。采用全断面破碎导向钻头钻出导向孔,待到达取芯点位置时(1 003 m和1 900 m钻孔深度位置)抽出孔内所有钻具,并更换相应取芯钻具推至目标取芯位置,待取芯工序完成后再抽出所有钻具并更换回全断面破碎不取芯钻具;重复上述工序直至完成所有取芯任务。
1.2.2围岩分类结果
钻孔累计进尺1 003 m处,随钻具出孔的岩芯较完整,总长约75 cm,灰绿色凝灰质砂岩,为火山碎屑岩,属沉积岩,主要矿物成分为石英、长石和云母。如图3所示,累计进尺1 900 m处,随钻具出孔的岩芯较破碎,总长约220 cm,花岗闪长岩,为显晶质酸性深成岩,属岩浆岩,主要矿物成分为斜长石、石英和角闪石、黑云母等。

图3 进尺1 900 m处岩芯实物Fig.3 Core with drilling length of 1 900 m
图4所示为孔内电视录像及返出岩屑实物图,根据孔内电视可清晰采集全孔沿线围岩岩性变化、断层破碎带的影响范围及孔内涌水状况等重要信息,得出博-阿断裂带的影响范围在1 928.0~2 063.0 m。根据岩屑记录表,得出勘察钻遇地层岩性依次为凝灰质砂岩、花岗闪长岩、碳质板岩、石英片岩和片麻状花岗岩等5种围岩。

图4 孔内电视录像及返出岩屑Fig.4 Image of in-hole television and returned rock debris
表1为综合孔内电视视频与返出岩屑数据对钻孔围岩分布的分析结果,由表1可知,在钻深0~1 605.0 m、1 605.0~1 748.8 m、1 748.8~1 769.8 m、1 769.8~1 969.8 m、1 969.8~2 088.3 m、2 088.3~2 271.0 m等区间内分别识别上述5种围岩,其中钻孔轨迹内凝灰质砂岩分布最广,达1 605 m,碳质板岩分布最小,仅约21 m,并夹杂于花岗闪长岩中;岩屑经清洗干燥后开展室内XRD实验,5种围岩岩性构造与矿物成分等也不尽相同。

表1 隧道围岩分布Tab.1 Tunnel surrounding rock distribution
2 钻孔围岩数据获取及分析
2.1 钻进参数获取
天山胜利隧道水平定向钻勘察现场收集到的实测数据有钻杆根数、钻进深度、泥浆压力、进浆流量、钻进压力等。其中钻杆根数与钻进深度、泥浆压力与进浆流量具有很强的相关性;而钻进压力为地面钻机所测参数,与孔底钻具实际钻压具有一定差距,考虑到钻孔弯曲与摩擦等因素,孔底钻进压力需在已有钻进深度、轨迹曲线等数据基础上进行修正。目前已有学者提出并归纳相关计算公式[21-23]如下:
(1)
a1·an=ax1·axn+ay1·ayn+az1·azn
=|a1|·|an|·cos(Δα)
(2)
式中:F为修正后的孔底钻压,kN;Fg为地面测量的钻机钻压,kN;μ为管孔摩擦系数,一般取0.35;Δα为孔底钻具与孔口钻杆所在向量的夹角,(°);a1和an分别代表孔底第一根钻杆和孔口最后一根钻杆在三维空间中对应的向量,a1=(ax1,ay1,az1)、an=(axn,ayn,azn),与两点的斜深、倾角和方位角相关。
2.2 数据初步分析
结合工程现场随钻参数与孔底修正参数等数据,确立泥浆压力P、钻进速度v及修正计算后的孔底钻进压力F这3类数据为模型自变量,此3类数据可从泥浆循环、钻头破岩等工艺反映水平定向钻实时钻进状态。以孔内电视、返出岩屑等数据反馈得出的围岩岩性为模型因变量,可真实客观反映不同钻进深度L下的钻孔围岩类型。表2所列为勘察孔工程数据。需要指出的是,233组围岩反演案例中各数据指标均完整未缺失,表2所列为样本数据库,其中1代表凝灰质砂岩,2代表花岗闪长岩,3代表碳质板岩,4代表石英片岩,5代表片麻状花岗岩。图5所示为成孔深度下测试数据,可反映不同钻进深度L下的泥浆压力P、孔底钻进压力F、钻进速度v等钻进参数与围岩岩性变化,其中钻孔深度1 928~2 063 m为博-阿断裂带影响范围。由图5可知,钻进速度v随钻进深度L有下降趋势,泥浆压力P则稳步上升,孔底钻进压力F在前600 m波动明显,后期逐渐平稳,这也与实际经验相符;钻孔沿线凝灰质砂岩分布最广,碳质板岩分布最小,博-阿断裂带发育于花岗闪长岩与石英片岩之间。

表2 水平定向钻勘察工程数据Tab.2 Horizontal directional drilling survey engineering data

图5 成孔深度下测试数据Fig.5 Test data at hole depth
233组样本量基本描述见表3,泥浆压力P最大值为6.00 MPa,均值为4.99 MPa,中位数为5.00 MPa,呈现一定的左偏特性;孔底钻进压力F最大值为899.10 kN,均值为577.60 kN,中位数为569.50 kN,呈现明显的右偏分布;钻进速度v最大值为23.90 m/h,均值为9.93 m/h,中位数为9.40 m/h,同样呈现一定的右偏特性。为了更直观地表现出评价指标分布特征,绘制3类变量的分布曲线,如图6所示。

表3 评估变量基本信息Tab.3 Basic information of evaluation variables
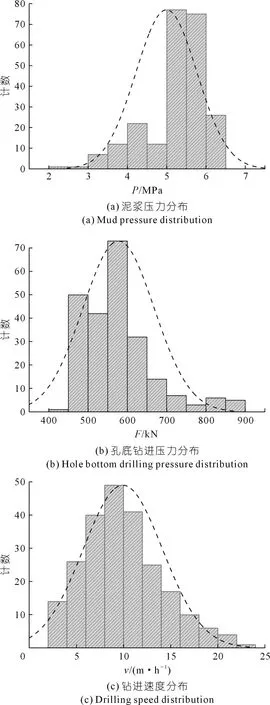
图6 评估变量分布Fig.6 Evaluation variable distribution
2.3 数据不平衡处理
在机器算法分类问题上,数据不平衡导致不同标签数据分布差异极大,训练模型过多关注比例较大的特征数据,致使训练效果不佳,因此有必要进行数据不平衡处理。图7为3种评估指标下的岩性识别参数三维分布,每种颜色表示一种岩性,可知碳质板岩岩样数据相较凝灰质砂岩过少,不同岩样数据存在明显的数据不平衡现象。机器学习中通常采用重采样方法处理不平衡数据,按采样形式可分为过采样、欠采样和混合采样,以改变样本数量或惩罚机制为主要处理思路。常用的过采样方法SMOTE(Synthetic Minority Over-Sampling)算法于2002年[24]被提出,该算法将少数类样本的最近邻样本作为插值,合成复制以达到过采样。考虑到本工程案例样本数据集较小,在机器学习模型训练过程中,为了充分学习各类样本的特征,提高模型的通用性,采用SMOTE算法对花岗闪长岩、碳质板岩、石英片岩、片麻状花岗岩等岩样数据进行过采样处理。

图7 岩性识别的三维分布Fig.7 3D distribution of lithology identification
不同岩性数据经SMOTE过采样处理后样本量均达到164组,样本数据总量由233组扩充至820组。与平衡前相比,各评估指标(泥浆压力P、钻进速度v、孔底钻进压力F)均值与标准差变化较小,表明数据离散程度未发生剧烈变化,基本符合数据过采样平衡要求。
2.4 数据特性分析
机器学习模型输入参数之间的相关性对模型泛化性能可能存在影响,因此有必要对各参数之间的相关性进行分析,表4为各参数之间的Pearson相关系数。可知,泥浆压力P与钻进速度v、孔底钻进压力F存在一定的负相关性,钻进速度v与孔底钻进压力F相关性较弱;钻孔围岩岩性与3类参数具有较强相关性,其中与泥浆压力P呈正相关,与钻进速度v、孔底钻进压力F呈负相关;岩性与各输入参数间相关系数接近,相关系数绝对值在0.53~0.73之间,因此选取这3类指标进行围岩分类是可行的。
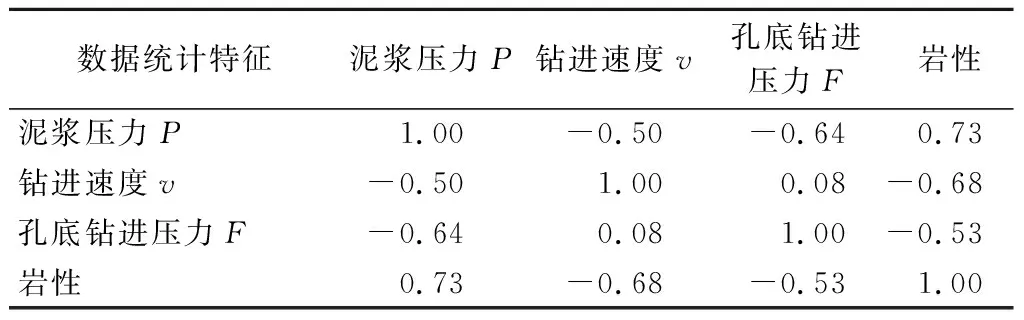
表4 自变量相关性矩阵Tab.4 Independent variable correlation matrix
3 围岩分类模型建立
3.1 算法模型确定
基于Python机器学习工具包(Scikit-learn),使用10种经典监督学习算法来训练钻孔围岩分类模型,其中6种常规算法包括决策树(DT)、K-近邻(KNN)、高斯朴素贝叶斯(GNB)、支持向量机(SVM)、线性判别(LDA)、多层感知机分类器(MLP)等,4种集成算法包括随机森林(RF)、AdaBoost分类器、梯度提升决策树(GBDT)、袋装法(Bagging)等。结合Scikit-learn库中的10种机器学习算法包,对模型进行训练验证,步骤如下:
(1) 对输入数据进行Min-Max标准化处理,并将处理后的数据以7∶3比例分割为训练集与测试集;
(2) 基于Scikit-learn库中算法包和Python工具分别构建10种分类算法模型;
(3) 训练各算法模型,采用5折网格搜索交叉验证以确定各模型最优超参数组合;
(4) 以准确率(Accuracy)、精确率(Precision)、召回率(Recall)、F1值(F1 score)评判各预测模型分类性能。
围岩智能分类模型建立与分析流程如图8所示。

图8 分析流程Fig.8 Analysis flow chart
3.2 算法优化
超参数(Hyperparameter)是模型初建时用于控制算法行为的参数,一般需在训练之初人为赋值;算法调参目的在于使得训练后模型达到最佳状态,需要使损失函数尽可能小,以节省计算机算力与降低泛化误差。机器学习中调参可视为多元函数优化问题,目前成熟的调参方法包括传统手工搜索、网格搜索、随机搜索、贝叶斯搜索等,相关算法在Scikit-learn库中均有对应函数包。
本文在步骤(3)所采取的网格搜索交叉验证(Grid SearchCV)是一种基本的超参数调优技术,其基本思路为对指定参数值或组合穷举搜索,在指定空间内依次遍历并提出参数先验候选值,训练学习器以验证所有参数组合,进而获取模型最优时的参数组合。但由于其对每种超参数组合进行遍历验证,导致计算速度相对缓慢,对计算机性能提出较高要求。
3.3 模型分类性能评估
常用准确率、精确率、召回率、F1值为分类性能度量指标来衡量各模型泛化能力。其中准确率较为常用[20],其可用于评估模型整体分类性能,但需召回率等指标来具体评价模型的优异程度。
评估建立的10种分类算法模型的性能,基于Python机器学习工具包,按照图8流程构建基于10种监督学习算法的围岩分类模型,其性能评估结果如表5与图9所示。结果表明,10种不同算法对凝灰质砂岩、花岗闪长岩、碳质板岩、石英片岩、片麻状花岗岩等岩样分类的精确率分别为0.88~1.00,0.73~0.92,0.58~0.97,0.27~0.99,0.62~0.99,召回率分别为0.60~0.91,0.78~0.95,0.75~1.00,0.43~0.99,0.08~1.00,F1值分别为0.75~0.93,0.78~0.90,0.65~0.98,0.33~0.99,0.15~1.00。5类岩样的平均召回率为0.86,说明利用钻进参数建立的机器学习模型在围岩智能分类中是可行、可靠的。3类评估指标中,F1值作为精确率与召回率的调和平均值,在评估二分类问题时更为适用,对比分析可知碳质板岩与片麻状花岗岩的F1值均大于其他岩层,大部分算法模型中关于石英片岩的F1值小于其他岩层,初步说明本文构建的算法模型对碳质板岩与片麻状花岗岩的分类性能较强。同时不同学习算法对模型分类效果影响显著:随机森林(RF)的分类能力最强,F1值最大可达1.00,说明可非常准确地分类出测试集中的部分岩层;决策树(DT)、K-近邻(KNN)与梯度提升决策树(GBDT)分类能力较强,可达0.98~0.99;而无论是F1值,还是精确率与召回率,AdaBoost分类器分类表现均较差,其对于片麻状花岗岩的F1值与召回率分别只为0.15与0.08,对石英片岩的精确率也仅为0.27,说明该算法对本案例工程围岩分类问题泛化能力较弱,未能对岩性进行准确分类。

表5 钻孔围岩模型性能评估Tab.5 Performance evaluation of borehole surrounding rock model
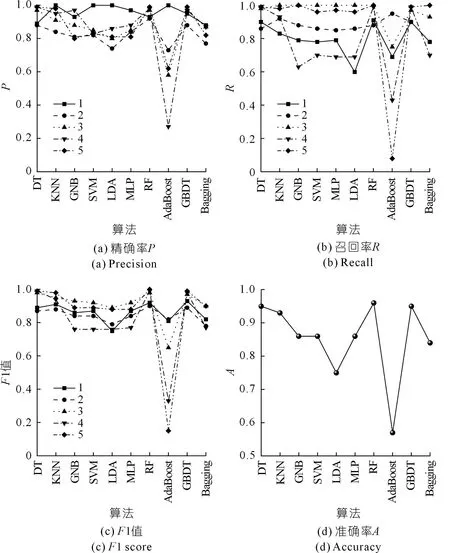
图9 不同算法模型性能评价Fig.9 Performance evaluation of different algorithm models
以准确率作为评判指标分析各算法模型分类性能,除线性判别与AdaBoost分类器外,其他8种监督学习算法准确率均高于0.80,说明依托钻进参数建立的围岩岩性分类模型具有可行性,相关算法对此类问题有较好的可解释性。由图9(d)可知,本文所建立的10种分类模型中,随机森林表现最好,其次是决策树与梯度提升决策树,其准确率均在0.95以上;高斯朴素贝叶斯、支持向量机与多层感知机分类器表现相似,准确率均在0.86左右;线性判别与AdaBoost分类器表现较差,其中AdaBoost分类器准确率仅在0.57左右。
不同算法对应不同岩石类型预测精度不同,其根本还在于岩石自身因素,如岩石可钻性方面,不同岩层钻头破岩的形式不尽相同(贯入破碎、剪切破碎、拉伸破碎等[25]),此外岩屑运移规律、能量耗散形式也会产生一些影响。以上述4项评判指标评估各算法对不同围岩的分类效果,发现各分类器在碳质板岩与片麻状花岗岩上表现较好,表明机器学习方法适用于该类岩石,其中又以随机森林分类器表现最好。
分析各算法的预测精度差异原因,还在于算法本身原理与底层逻辑。常规算法中决策树相对于其他算法的预测准确率较高,初步分析其原因在于该算法能够处理不相关的特征,在小数据集上较其余常规算法更具优势,但也容易出现过拟合问题。集成算法中,Bagging(装袋算法)和Boosting(提升算法)都是将多重或多个弱分类器融合成为强分类器的模型融合算法,从而可以提升模型分类效果;由于Bagging是利用数据全部特征训练分类器,而随机森林在Bagging基础上增加了随机属性选择,即只从数据全部特征提取一部分训练分类器,其性能与效率也有了较大提升,因此本案例中随机森林优于Bagging;相较于均匀取样的Bagging算法,按照错误率来取样的Boosting算法一般而言分类精度更优,基于Boosting的提升决策树的4项评判指标与随机森林相差不大,而对同样基于Boosting的AdaBoost分类器,虽然泛化错误率低但也对离群点更为敏感,由于本案例原始数据集较小并经过数据不平衡处理,导致AdaBoost的弱分类器数目不太好设定,其分类预测的各项指标均弱于其余各项算法。
4 讨论与展望
围岩分级方面,国际上已提出的和正在应用的围岩分类方法约有50多种,如中国工程建设应用较多的GB/T 50218-2014《工程岩体分级标准》中BQ法[26]和GB 50487-2008《水利水电工程地质勘察规范》中HC法[27]等,其多以经验为基础进行定性判别,以围岩质量影响指标进行评判、打分。诸如GB 50487-2008《水利水电工程地质勘察规范》[27]、TB 10003-2016《铁路隧道设计规范》[28]、JTG/T D70-2010《公路隧道设计细则》[29]等标准规范对围岩分类(分级)方法均有具体说明,基本都以围岩稳定性及结构特征等为主要判据,围岩主要分为5~6类,且受到岩石性质、岩石完整度、结构面特征、岩体结构与洞轴线关系、地应力水平、地下水等因素影响,测量误差往往造成对围岩分级判定不准确。
岩性识别方面,目前关于大数据算法在岩性识别的应用多为油气勘探开发和地质钻探领域,综合录井测井工作的数字化、自动化为岩性解释、评价算法模型的建立提供了必要条件[30]。相较而言,隧道围岩岩性多依据传统的定性划分和定量指标,需要工作人员根据经验与岩体参数测试才能准确判定,如TB 10003-2016《铁路隧道设计规范》[28]以岩石单轴饱和抗压强度划分硬质岩或软质岩并确定A~E类围岩,以岩石风化及结构面结合程度确定岩浆岩、变质岩、沉积岩类别,最终确定岩石类型。
无论是岩性识别还是围岩分级,都具有影响因素众多、随机性强、相互耦合且高度非线性的特征,由于围岩与各影响指标之间离散,采用传统方法准确判定较为复杂困难。同时,水平定向钻随钻参数往往与现有分类、分级指标间存在较强联系,基于随钻参数与机器学习算法的超长水平定向钻钻孔围岩智能分类方法具有较强可行性与可靠性。
需注意的是,本案例训练测试数据均来自天山胜利隧道建设过程中某一区间,由于其为中国首次开展相关技术的尝试,数据量有限,故只针对多种机器学习算法在水平定向钻钻孔围岩分类问题展开初步探讨与普适性研究,为今后类似工程提供参考与思路。今后,发展一套适用于超长水平定向钻勘察的围岩分类方法是该项新技术的研究重点之一;围岩描述也需完成从定性到定量再到综合集成的转变;同时,机器学习建模完全依靠数据驱动,忽视了相关物理力学关系,如何处理好数据驱动与物理驱动的关系[31]、如何建立可解释性强的围岩智能分类理论、如何提高学习的泛化能力是亟需解决的问题。
5 结 论
将超长距离水平定向钻技术应用于地质勘察,可克服现有垂直钻孔地质勘察在深山峡谷高海拔地区的应用限制,改变隧道工程地质勘察现状,有力配合川藏铁路、西部大开发等一系列国家战略规划的实施。本文基于钻孔返出岩屑、孔内电视、间断取芯及随钻参数等各类数据,探讨基于多种机器学习算法的围岩智能分类模型性能,结论如下:
(1) 以泥浆压力、钻进速度及修正孔底钻进压力等3类钻进参数为主要的输入参数,采用SMOTE过采样方法对样本量较小的岩样数据进行不平衡处理,平衡后数据离散程度变化小,基本符合要求;
(2) 建立的多种机器学习算法模型中,大部分算法对碳质板岩与片麻状花岗岩的岩本具有较好的分类性能,对石英片岩的预测准确率则较低;
(3) 综合准确率、精确率、召回率和F1值等评估指标,发现随机森林、决策树与梯度提升决策树表现最好,其准确率均在0.95以上,具有较好的泛化效果;线性判别与AdaBoost分类器表现较差,其中AdaBoost分类器准确率仅0.57左右,不适用于本案例围岩智能分类。
综合多类别测试与数据,采用机器学习算法对围岩进行分类具有可行性,可有效避免现有标准规范的围岩分类判定指标随机性强且相互耦合、各参数存在高度非线性的缺陷,可有效揭示各参数之间的内在规律,以快速准确感知地层条件并进行围岩智能分类。由于超长水平定向钻地质勘察正处于初步发展阶段,随钻参数的采集方式、种类、数量需要进一步探讨,相关技术指标仍需进一步确立与完善,结合钻头破岩、岩屑运移等物理力学规律,建立数据-物理双驱动的围岩智能分类理论与模型也是未来发展趋势之一。
猜你喜欢
云南化工(2020年11期)2021-01-14
工程设计学报(2020年5期)2020-11-25
工程技术与管理(2020年8期)2020-08-26
电子测试(2018年1期)2018-04-18
录井工程(2017年1期)2017-07-31
录井工程(2017年1期)2017-07-31
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
电测与仪表(2014年15期)2014-04-04
石油化工应用(2014年12期)2014-03-11
