
基于SMO算法的驾驶员疲劳检测*
2024-01-10 06:54丁琳
企业科技与发展 2023年12期
丁琳
(江苏财经职业技术学院,江苏淮安 223003)
0 引言
根据国家统计局的统计,我国2022年全年道路交通事故每万车死亡人数为1.46 人,疲劳驾驶是引起交通事故的主要原因。如何有效地判断驾驶员的疲劳状况从而降低交通安全事故发生的概率成为汽车行业重点研究的方向。1994年,日本先锋公司研发了一种通过检测心跳速度测试驾驶员是否处于疲劳状态并发出警告的系统。2001年,美国纽约伦斯勒理工学院的WU 等人[1]设计出一种摄像机定位人眼的硬件系统,通过检测瞳孔的信息饱和度判定人眼是否处于疲劳状态。2003年,澳大利亚Seeing Machines公司通过在汽车的仪表盘上安装微型传感器获取驾驶员头部和面部的疲劳信息,以此判定驾驶员是否处于疲劳状态。2015年,“沃尔沃”在XC60 系列汽车上安装了驾驶员安全警告系统,通过摄像头实时监测汽车与车道标志的距离及当前车辆的形式轨迹,以此判断车辆是否处于正常行驶状况。国内开展此项研究的成果也较多,韩政[2]设计一种基于改进的随机森林级联回归方法检测人脸的关键特征点,通过检测驾驶员眨眼次数和打哈欠时嘴巴张开的程度与频率等信息综合判断其疲劳状态。高嫄[3]提出一种融合多个疲劳特征的疲劳状态检测算法,同样需要获取驾驶员眼睛和嘴巴的信息并结合驾驶员大脑运动的过程综合判断疲劳信息。李德武[4]考虑到在做人脸图像分割时,光线问题会导致图像分割出现差错,因此利用肤色在色度空间上的聚类特性,提出基于肤色分割的人脸定位方法。李庆臣[5]设计一种多疲劳指标综合的疲劳状态检测系统,解决了因特殊情况导致实际测试环境受影响后结果出现偏差的问题,结合面部、头部、光线等多方面信息进行疲劳检测。
本文在前人研究的基础上,将人脸的关键点检测作为优化的途径,首先随机给出关键点的初始分布,其次利用整体人脸外观信息和全局人脸形状不断迭代优化,最后通过全局人脸约束修正最终的检测结果,以此判断驾驶员的疲劳驾驶行为。
1 基于机器视觉的疲劳状态识别
关于疲劳状态的定义有很多,对于人体来说,疲劳状态意味着人的劳动能力下降,反应能力减弱,而这些状态的表现形式多数都可以体现在人的脸上。本文采取的疲劳状态检测是以人眼闭合状态的持续时间判断驾驶员是否处于疲劳状态,检测流程图如图1所示。
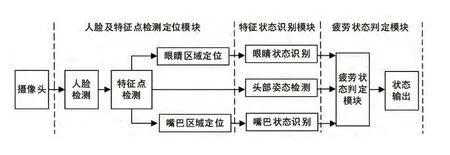
图1 疲劳状态检测流程
由于本文检测方法进行特征提取时需要定位在人眼部位,提取人眼信息,因此如何准确地检测人脸并准确地定位到人眼的位置,是研究人员需要解决的主要问题。本文采取的方式是借助机器视觉中强大的图像处理库,通过SMO(序列最小优化)算法[6]进行大量的人眼开闭训练,以达到准确定位人眼并提取信息的目的。
1.1 人脸特征定位
进行人脸定位时,首先需要检测诸如鼻子左侧、鼻孔下侧、瞳孔位置、上嘴唇下侧等特征点的位置,获取特征点的位置后进行位置驱动的变形,人脸即可被校正[7]。人脸定位方式采用OpenCV 库中的DetectFace 函数,该函数可以依靠自身的训练结果提取图片中的人脸信息与所需的脸部关键特征点。借助DetectFace 函数,将摄像头采集到的图像数据灰度化,再经函数处理,便可得到人脸的精确定位。除了人脸信息,函数中还包含了人脸中各个特征关键点的信息,如眼、鼻、嘴等的特征信息,可根据需要对不同部位进行信息提取,从而对人脸进行更精确的检测。
1.2 基于SMO挑选策略的眼部特征参数提取
在基于SMO 挑选策略的人脸检测中,特征点训练采用眉心、下巴的中心点、左脸颊和右脸颊4 个位置的特征。训练时,采用SMO 算法进行特征分类。SMO 是SVM 分类算法的一个发展分支,是针对二次规划式的高效算法,它处理问题时每次只选择其中的2 个算子处理,对SMO 进行优化,根据优化的结果更新SVM,观察因更新导致的变化[7]。在实际的图像处理过程中,更新属于一个伴随的操作,它根据算法的时间复杂度和准确度进行迭代。SMO 采取的方法是先计算检测图片大小的约束问题,再解决原来带有约束的最小化问题。图像大小的边界约束举例如下:使用α1表示第一个乘子,α2表示第二个乘子;因为乘子变少,乘子间约束关系的表示就更简单,边界约束情况如图2所示。
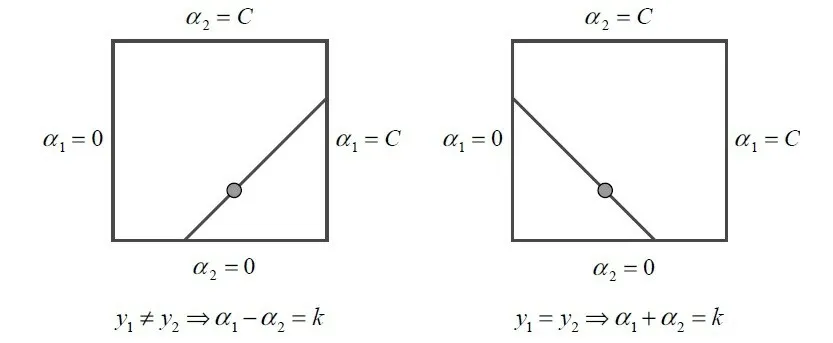
图2 边界约束
由图2 可以看出,因为边界约束的存在,所需要的乘子均在方框内部,加上线性等式约束的存在,这些乘子就处于对角线的位置,而使用SMO 算法的目的就是在这些线段上寻找一个最优解的存在。
如果计算结果显示2个乘子是不等关系,线段的边界约束关系如下所示:
如果计算结果显示2个乘子是相等关系,相对应的线段边界约束关系如下:
因为边界约束关系的改变,导致原来应用于对角线的关系函数不再适用,相对应的关系函数变更为下述公式:
一般情况下,任何一个边界函数都由一个明确的目标函数表示,这个目标函数表示线性等式所约束的方向存在一个最小值和一个仅大于0的最大值。在上述情境下,函数的最小值由以下函数计算得到:
如果当Ei=ui-yi,则用来表示第i个训练样本的误差,通过公式(5)表示有约束条件的最小值:
假设s=y1y2,那么之前SVM 算法中没有计算的第一个拉格朗日算子就可以通过第二个拉格朗日算子的计算结果表示:
公式(6)的计算并不是绝对的,假设存在1 个非正数的目标函数,例如如果SMO 算法中的Kernel K不符合Mercer's条件,计算出的目标函数就会存在不确定性,无法正确判断目标函数的存在状态。即使Kernel K 符合计算条件,也无法排除计算得到一个函数值为0的目标函数,即没有得到算子。例如,在一个训练样本里的向量有很多都是相同的输入,那么就会出现上述函数值为0 的情况。为了让SMO 处理这类问题,需要增加更多的公式满足所需要的条件,例如下列公式:
SMO 算法的挑选策略通过外层循环达到对整个训练集全局搜索的目的,采用这个方法可以清楚地计算出不满足KKT(Karush-Kuhn-Tucker conditions)条件的样本数量,根据这些样本数量判断是否需要优化算法,如果没有不满足条件的样本数量,则不需要优化,说明样本本身就是最优的;反之,则需要进行优化。不断重复此步骤,直到所有样本都符合KKT条件的标准。完成第一个乘子的选择后,开始选择第二个乘子,SMO 会选择最小的函数值作为第二乘子,因为从最小值开始优化可以提高优化的效率。如果优化后仍不满足条件,那么采用SMO 在所有的非边界样本上进行搜索,使乘子的目标函数值最小;如果仍然失败,则使用SMO 搜索覆盖整个训练集,以便更好地寻找满足条件的乘子,即找到最佳分类。
1.3 基于人眼开合度的训练测试
训练时需要构建正负样本数据集,本文需要建立眼睛状态分类器。眼睛有两种状态,一种是睁开状态,一种是闭合状态,本文检测的是闭合状态的眼睛。此次采取的训练方式是建立人的左眼和右眼的灰度图信息库,将其中的70%作为训练数据,剩余的30%作为训练的测试数据。运行模型训练模式,此时程序会依次打开闭眼状态训练库(如图3所示)和睁眼状态训练库(如图4所示),分别训练人眼开和闭的2种状态,训练完成后对训练器进行测试。

图3 闭眼状态训练库

图4 睁眼状态训练库
2 仿真实验
经过SVM 训练器的训练后,可以从人眼信息状态灰度图判断人眼的状态,接着是采集实时画面,将画面中的人眼信息传输到SVM 测试器,与之前样本训练的结果进行对比,反馈实时的人眼信息状态。疲劳检测流程图如图5所示。
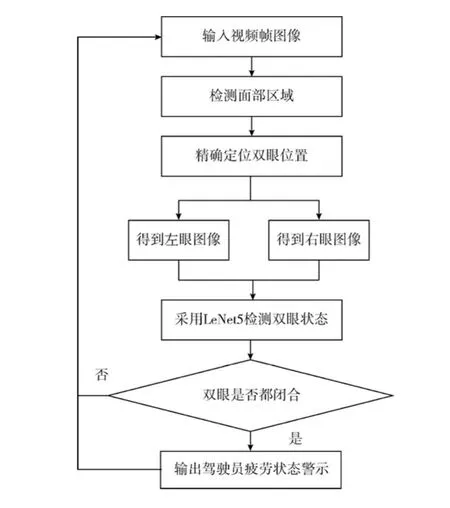
图5 疲劳检测流程图
仿真实验中计算机性能参数为Intel I7 CPU,DDR3 8G RAM,win10 64 bits。采集视频片段的时长为2~4 s,视频帧率为25 fps,视频分辨率为720×480。首先通过SVM 训练器的训练,准确定位人眼的位置并与人眼状态库进行比较,判断人眼闭合的状态,然后进行疲劳状态检测,在预定时间内正确地反馈人眼信息,对处于疲劳状态的人进行提示。
图6 至图9 为文献[1]中的方法和本文方法的疲劳状态检测性能对比结果。经对比可知,本文方法比文献[1]中的方法的训练准确率高10%以上,这是由于本文在模型测试过程中减小了模型规模,即减少了模型中可学习的参数的数量,并且在迭代过程中对比训练数据的表现,达到阈值即停止,避免对数据过度优化,因此状态分类的正确率得到了明显提高。
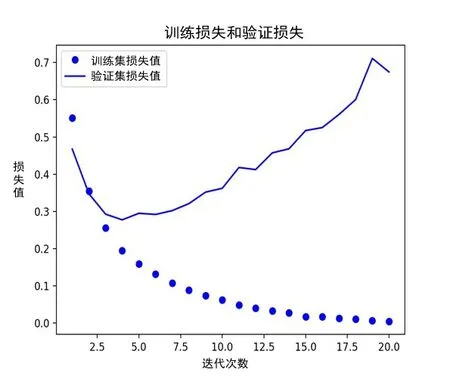
图6 文献[1]中的方法训练损失和验证损失
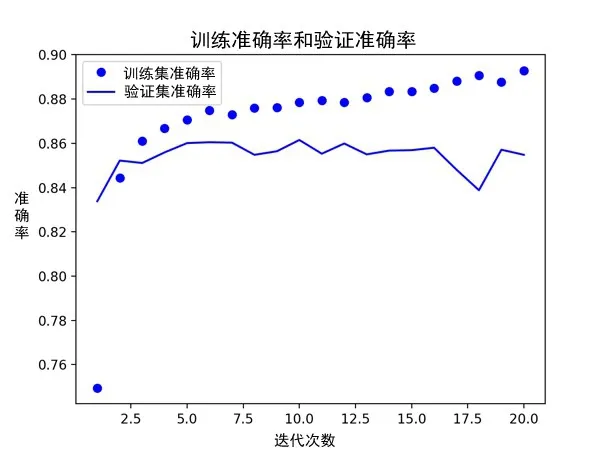
图7 文献[1]中的方法训练准确率和验证准确率
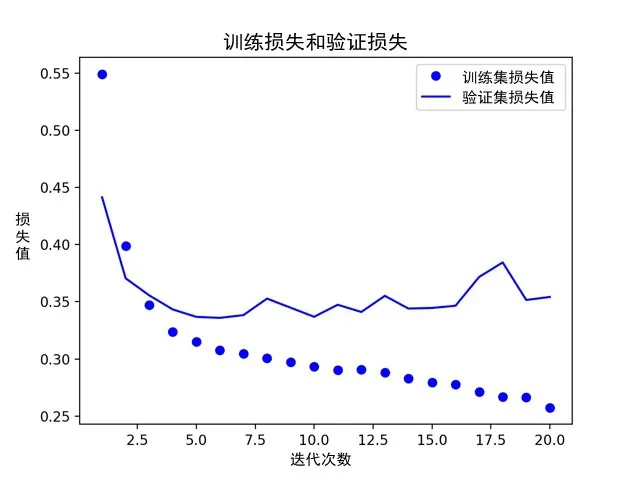
图8 本文方法的训练损失和验证损失
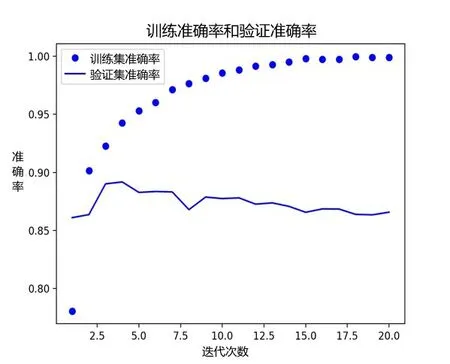
图9 本文的训练准确率和验证准确率
3 结语
在交通领域实行实时监测很重要,然而在大量数据下SVM 的样本训练存在实时性不高的问题。SMO 算法在一定程度上提高了训练速度,在保证SVM 分类准确度的前提下,通过剔除大量的非支持向量减小训练样本规模的方式,缩短样本的训练时间,提高SVM 分类算法的实时性。本文提出的结合驾驶员人眼信息的疲劳检测算法,通过检测驾驶员的人眼状态信息的行为特征,利用SMO 算法训练库的优势,经过一定量的人眼信息训练,获得准确的人眼信息反馈,从而在一定时间内完成对驾驶员疲劳状态的判断。该疲劳检测系统对未来的交通防护起到了重要的作用,也为今后汽车行业的科技发展提供更好的研究方向与技术支撑。
猜你喜欢
数学物理学报(2021年6期)2021-12-21
少儿美术·书法版(2021年9期)2021-10-20
快乐语文(2019年9期)2019-06-22
数学物理学报(2019年2期)2019-05-10
中学生数理化·八年级物理人教版(2018年11期)2019-01-31
数学物理学报(2018年6期)2019-01-28
动漫星空(2018年9期)2018-10-26
优雅(2016年12期)2017-02-28
电影故事(2016年5期)2016-06-15
