
基于CEEMDAN-SVR的公路隧道运营短期能耗预测模型研究
2024-01-10 04:26付立家陈光勇
公路交通技术 2023年6期
王 钧, 付立家, 尚 康, 陈光勇
(1.甘肃省公路航空旅游投资集团有限公司, 兰州 730030; 2.招商局重庆交通科研设计院有限公司, 重庆 400067;3.重庆交通大学 交通运输学院, 重庆 400074; 4.山东省交通规划设计院集团有限公司, 济南 250101)
近10年来,我国公路隧道每年新增里程1 100 km以上,目前是世界上公路隧道规模最大、数量最多、地质条件和结构形式最复杂、发展速度最快的国家[1-2]。公路隧道是能源消耗大户,打造绿色智慧公路隧道是未来的发展趋势,也是实现双碳目标中重要的环节[1,3-4]。公路隧道节能减排不仅要考虑公路隧道在规划、设计、施工阶段能源消耗量,还要重视运营阶段能源消耗量。工作中主要通过对公路隧道短期能耗量进行预测,明确下阶段能耗水平,在保障隧道运营安全的前提下,针对高能耗单元制定能源管控策略、运营调度计划和养护方案,实现节能减排和安全出行目标,同时不断优化形成能耗预测模型。
能耗预测模型研究大多数集中在建筑能耗领域,如周峰等[5]采用SVM模型对大型公共建筑能耗进行了预测,并诊断了异常能耗数据;曾国治等[6]构建了CNN与RNN组合预测模型,实现了对办公建筑能耗的预测;窦嘉铭等[7]采用等权重和优势矩阵方式组合GA-BP神经网络、RBF神经网络和广义回归神经网络建立了综合预测模型,实现了对建筑能耗的预测。在交通领域能耗预测研究较少,主要集中在车辆、轨道和宏观区域能耗预测方面,如刘强等[8]提出电动公交车能耗灰色关联投影-随机森林(GRP-RF)预测模型,并通过实例分析验证了模型的准确性;吕承举等[9]建立了ARIMA的柴油客车能耗预测模型;杨臻明等[10]建立回归模型对城市轨道交通能耗进行了预测,并预测了上海轨道交通5号年能耗,误差在5%以内;吕欢欢等[11]分别采用SVR与RF预测模型对地铁列车牵引能耗进行了预测。
综上分析,既有研究主要针对道路服务车辆的能耗进行了研究,对交通服务设施能耗预测研究报道较少,为此,本文依托公路隧道基础服务保障设施能耗,参考建筑能耗预测模型建立隧道机电系统短期能耗预测模型,填补路端能耗预测研究空缺,为隧道运营决策、节能减排和低碳环保提供数据支撑和保障。
1 基于CEEMDAN-SVR的短期能耗预测模型
1.1 CEEMDAN-SVR模型预测流程
由于隧道能耗数据样本量小且噪点较多,导致单一模型难以提取潜在的时间趋势特征,预测效果不佳,因此本文采用CEEMDAN模型将公路隧道能耗数据进行分解,得到若干本征模函数IMF分量和残余分量Res,再利用SVR的非线性拟合能力对IMF和Res分量分别进行训练、预测和集成合并,从而有效预测隧道短期能耗数据。CEEMDAN-SVR预测流程如图1所示。该流程包括原始能耗数据预处理、CEEMDAN数据分解和CEEMDAN-SVR预测。数据预处理是对公路隧道原始能耗数据的异常值识别与剔除、缺失数据的修复、能耗数据的标准化、测试集和训练集的划分;CEEMDAN数据分解模型对预处理后数据进行分解,提取能耗数据潜在的时间特征;CEEMDAN-SVR预测处理是根据最优输入步长、输出步长和训练数据集训练最终预测模型,并通过测试集验证模型的准确性和可靠性。
1.2 公路隧道能耗数据预处理
1) 四分位法剔除能耗异常数据
四分位法识别异常数据是根据实际能耗数据进行异常点识别,不考虑数据分布情况,直观反映数据状态。其判断异常值的标准以四分位距为基础,四分位数具有一定的耐抗性,多达25%的数据可变得任意远而不会很大地扰动四分位数[12]。四分位数是将升序排列的样本X=(x1,x2,…,xn)均分为4等份,其3个分割点分别记作Q1、Q2、Q3。四分位数计算步骤如下。
Step1:计算第2个四分位数Q2。
(1)
Step2:计算第1和第3个四分位Q1和Q3。
按照式(1)将数据划分为2部分,再分别计算其
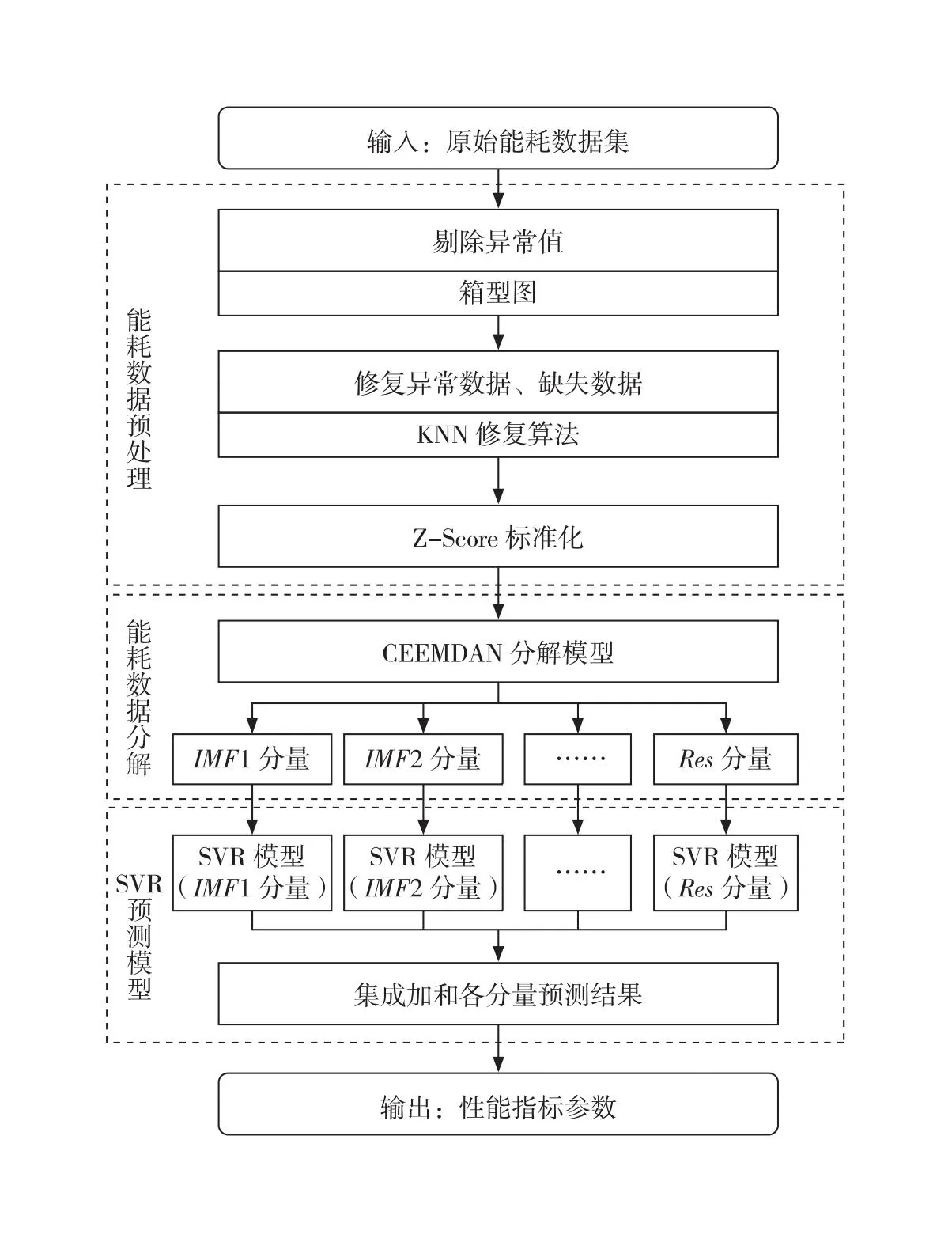
图1 CEEMDAN-SVR模型预测流程
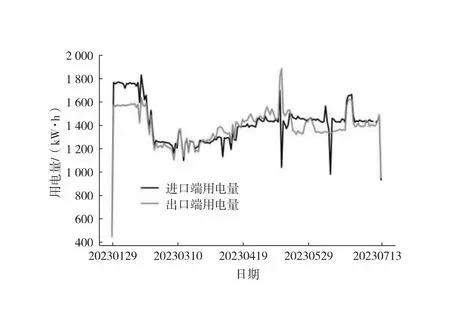
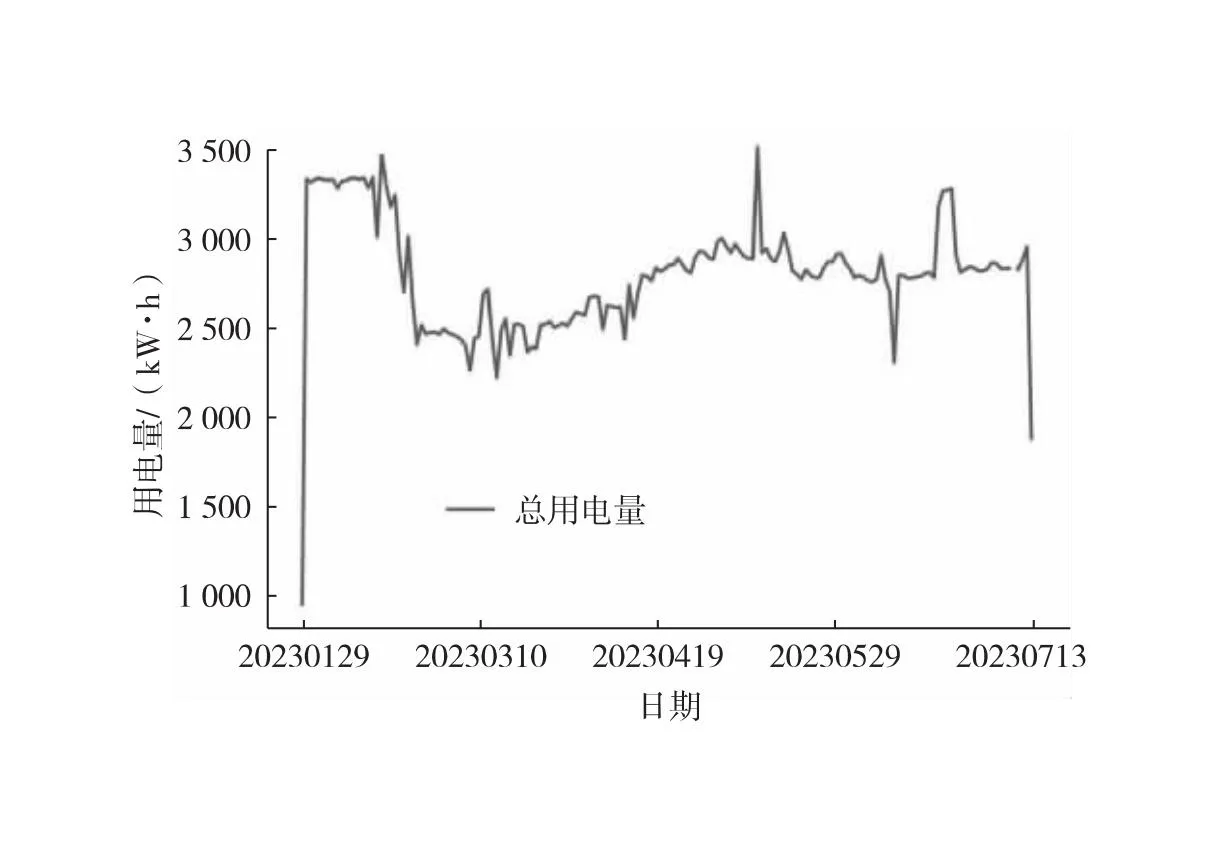
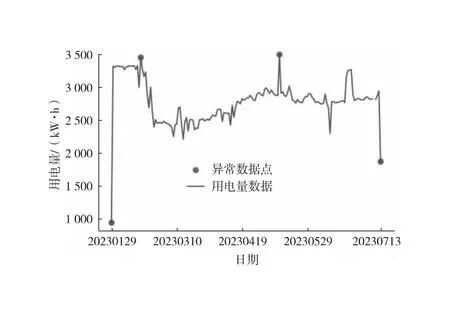
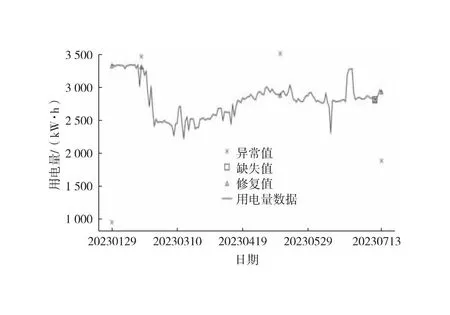
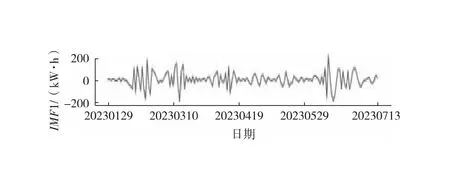
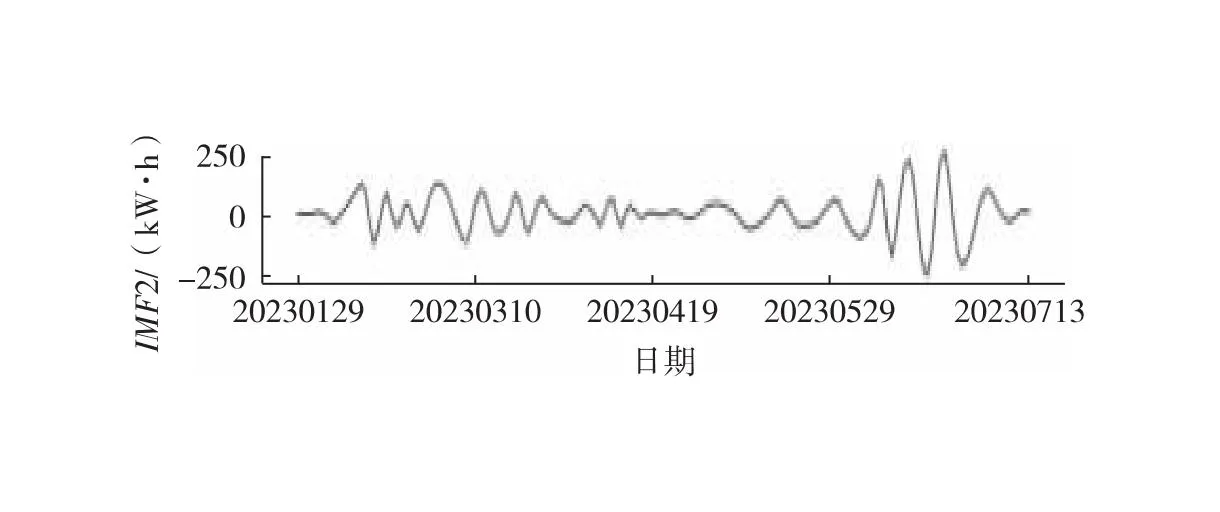
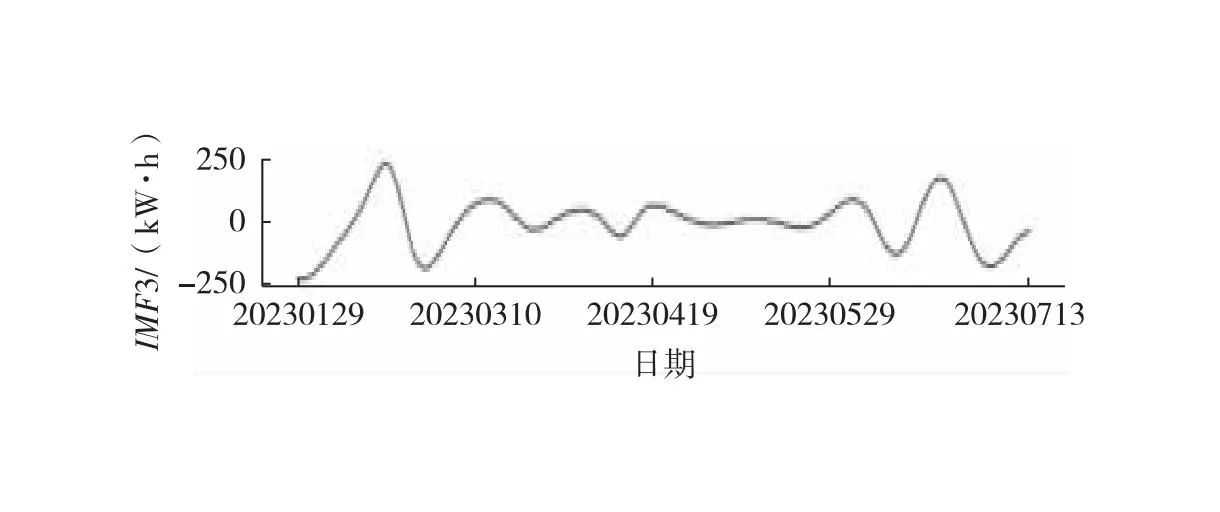
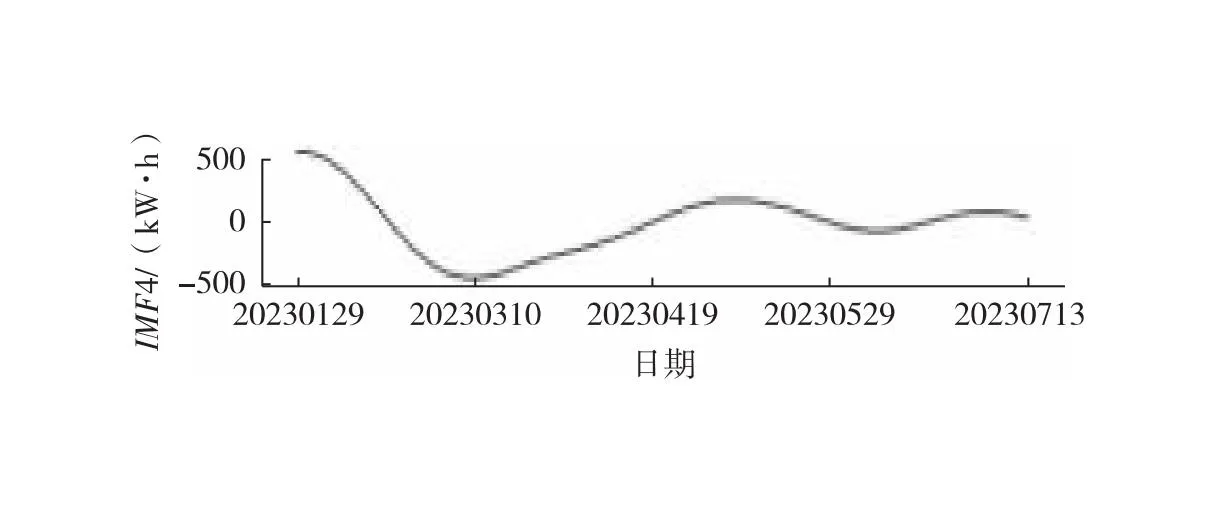
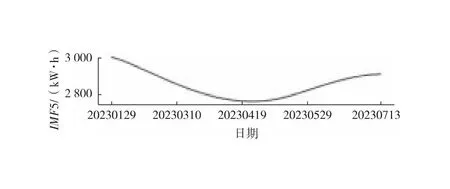
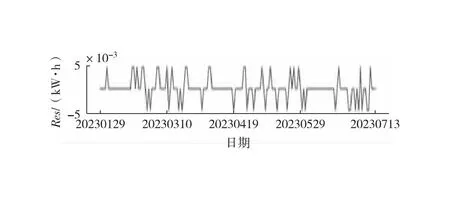
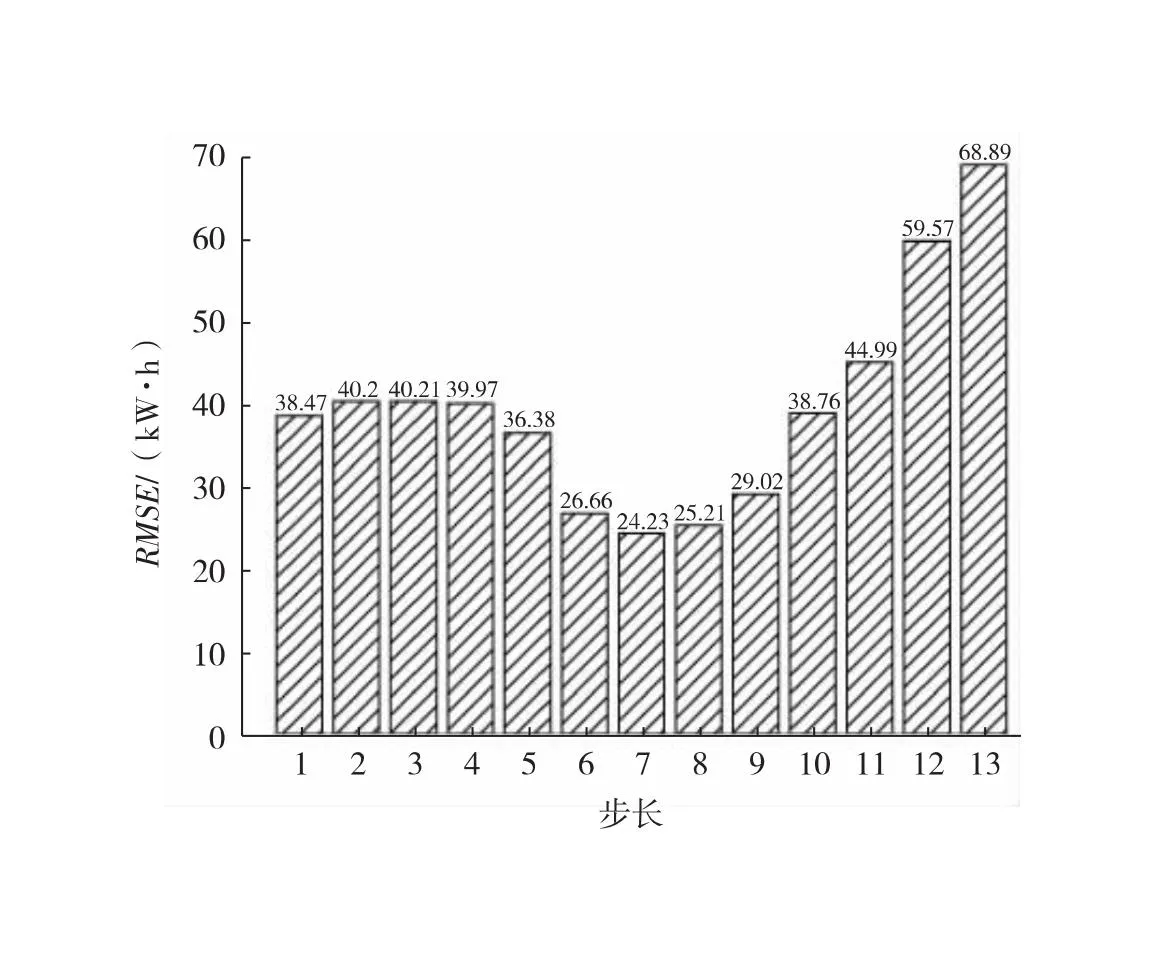
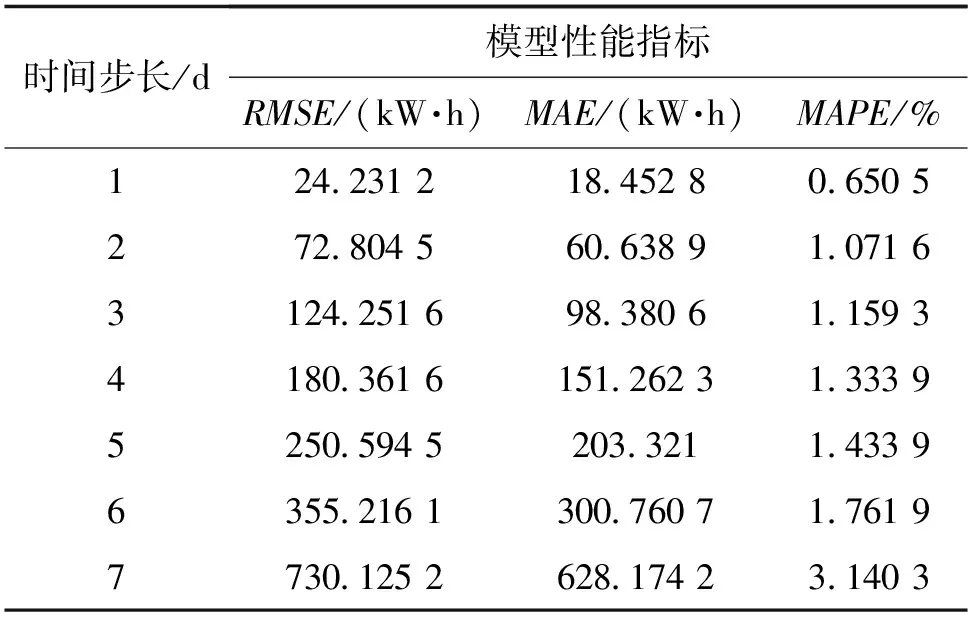
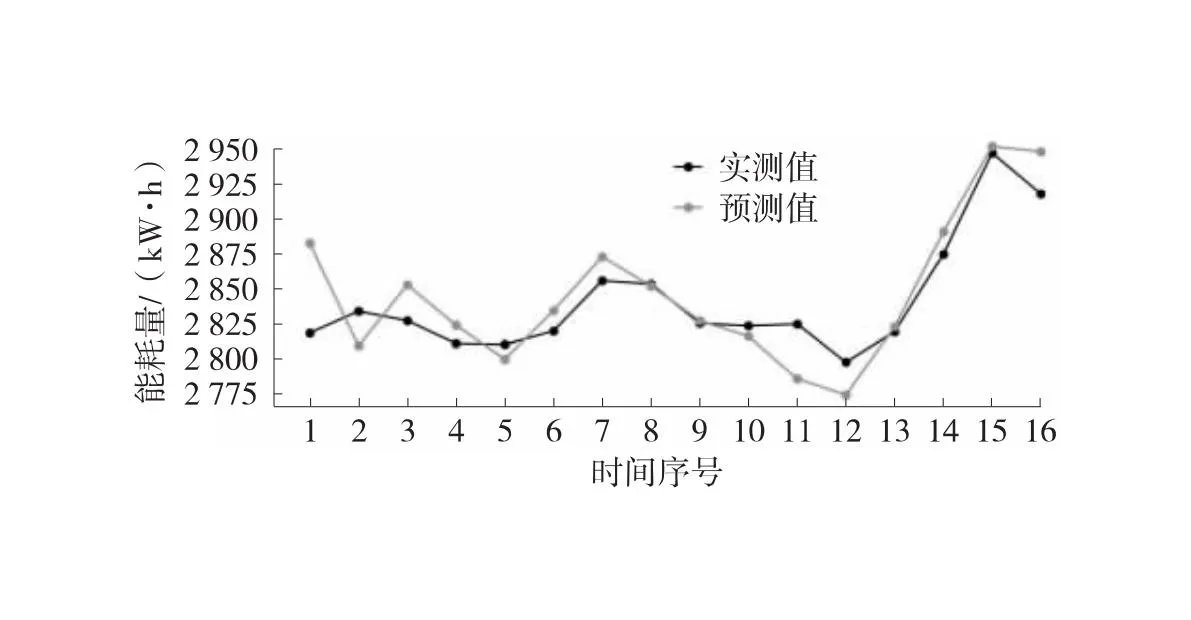
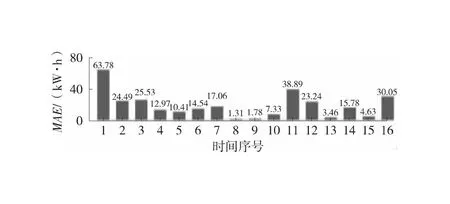
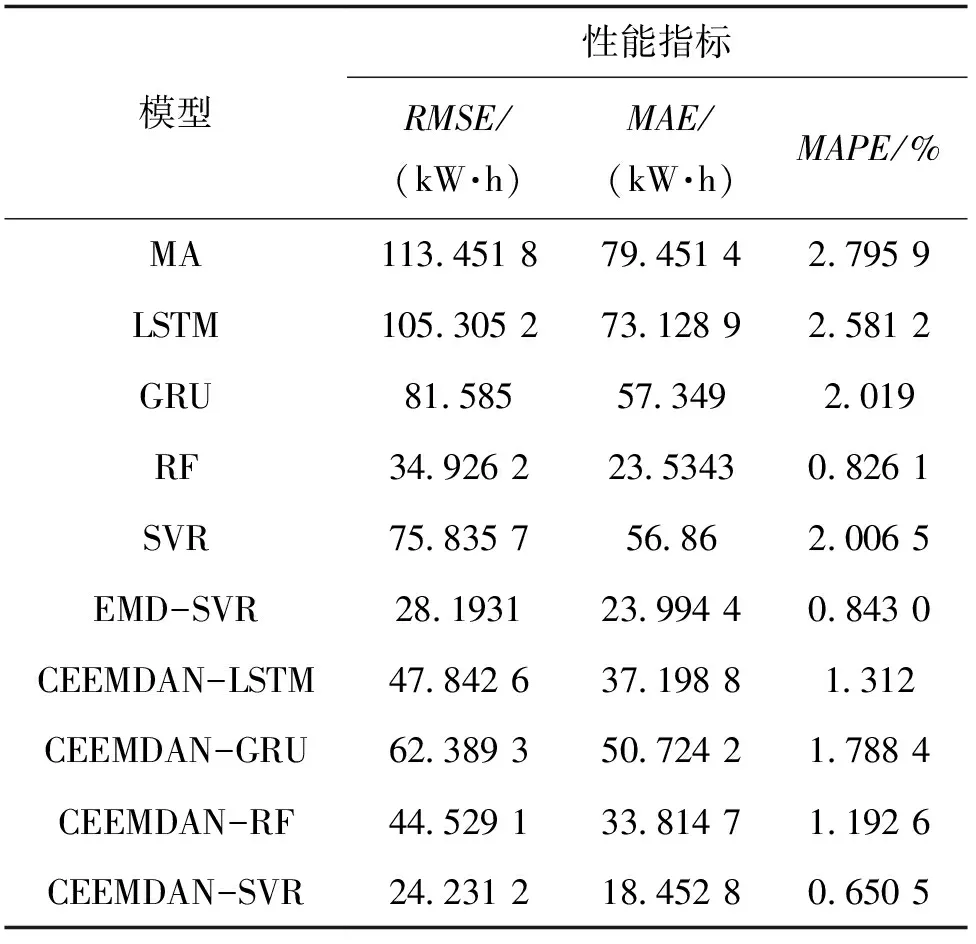
中位数,即为Q1和Q3,且Q1 (2) 当n=4k+3时,计算公式如下: (3) Step3:计算异常值内限。 根据四分位数计算四分位距IQR,从而确定数据样本X中异常值的内限为[F1,F2],处于内限以外的数据会被判定为异常值。 [F1,F2]=[Q1-1.5IQR,Q3+1.5IQR] (4) 式中:IQR=Q3-Q1。 2) KNN修复能耗缺失数据 KNN(K-Nearest Neighbor)算法修复缺失数据具有操作简单、无需假设分布、可处理多变量关系的优势。KNN是以历史数据为依据,通过比较待修复数据与历史数据的最近邻的K个相似值,求其平均值作为缺失数据的修复值,其计算步骤如下。 Step1:剔除缺失数据与异常数据,构建样本数量为n的完整矩阵X=(x1,x2,…,xn)。 Step2:计算缺失数据向量xq与完整数据向量xi的欧式距离。 (5) Step3:计算修复数据的最近邻权重值wi。 (6) Step4:计算缺失的修复值。 (7) 3) Z-Score标准化能耗数据 对修复后能耗数据进行标准化处理,能够消除能耗数据量级影响和分布差异,从而提高模型训练速度和精度。本文运用Z-Score标准化处理能耗数据,由均值和标准差将原始数据转换为标准正态分布,其计算公式如下: (8) 式中:z表示标准化后的能耗数据;x表示剔除异常值和修复缺失值的能耗数据值;μ表示能耗数据的均值;σ表示能耗数据的标准差。 集合经验模态分解模型(CEEMDAN)是针对经验模态分解(EMD)和集成经验模态分解(EEMD)的不足而提出的一种噪声辅助数据分析方法。EMD可将原始信号平稳化,提取信号中不同尺度的波动模式,生成一系列具有不同时间尺度局部特征的数据序列,即为本征模态函数(IMF)[13]。与传统的EMD与EEMD相比,CEEMDAN分解模型在分解阶段加入自适应的高斯白噪声,以进一步消除模态效应,因此具有更为优异的收敛性与自适应性[14]。利用CEEMDAN对能耗数据处理步骤如下。 Step1:利用EMD算法计算第1阶本征模态分量,取其平均值作为第1个模态分量I1(n)。 (9) Step2:计算step1中1阶残量信号。 r1(n)=y(n)-I1(n) (10) Step3:对信号rk(n)+εkEk(ωi(n))通过step1~step2进行模态分解,得到Ik+1(n)分量。 (11) Step4:重复上述步骤,直到残量无法继续分解,至多有一个残量极值时停止分解,原始序列为y(n)可分解为k个模态分量Ii(n)与r(n)。 (12) 式中:操作符Ek(·)表示经EMD算法得到给定信号的第k个模态分量序列;ωi为第i次添加的正态分布的高斯白噪声;εk用于控制第k个信号与噪声之间的信噪比。 支持向量机利用结构最小化原理来提高其泛化能力,能较好地解决高维数、非线性、局部极小等现实问题,适用于在有限样本条件下刻画隐变量与其众多影响因素之间的非线性关系[15]。支持向量机回归SVR(Support Vector Regression)是用于解决回归问题的支持向量机。假设给定训练数据集T={(X1,y1),(X2,y2),…,(Xn,yn)},对于单样本(Xi,yi)计算SVR模型的预测值与真实值间误差,即|f(Xi)-yi|>ε时,计算损失值,以线性SVR模型为例,其目标函数与约束条件如下: (13) 为求解上述模型的最优解,通过拉格朗日函数将其转化为对偶问题,并求解对偶问题,得到如下最优解: (14) 以均方根误差(RMSE)计算SVR预测模型训练过程中的损失值,表征预测值与真实值之间差异程度,计算公式如下: (15) 以均方误差(MAE)和平均绝对百分比误差(MAPE)衡量能耗预测模型的精度。MAE衡量预测值和真实值之差的绝对值的平均值,MAPE衡量平均预测误差与实际观测值的相对大小,计算公式如下: (16) (17) 根据CEEMDAN-SVR模型预测流程,以济莱高速公路蟠龙隧道的历史能耗数据进行实例分析,其模型预测步骤包括能耗数据预处理、CEEMDAN分解能耗数据和CEEMDAN-SVR能耗预测模型,最后对比分析不同预测模型用于验证CEEMDAN-SVR能耗预测模型的准确性和有效性。 蟠龙隧道全长2 447 m,双向6车道,是济南境内最长的高速公路隧道。隧道机电设备的用电能耗数据采集时间段为2023.01.29—2023.07.13,每天采集频率为24 h,该隧道为特长隧道,在隧道供配电方案设计中采用进出口端分开供电,因此采集电能数据分2部分,合并为隧道整体用电能耗,如图2所示。 从图2可知,采集的电能数据存在缺失值与异常值,需对原始数据集进行异常值识别、剔除和修复处理。因此采用箱型图识别并剔除异常数据、KNN插补算法修复缺失数据、Z-Score标准化能耗数据,逐步预处理能耗数据,使其符合能耗预测模型数据要求。 (a) 进出口端用电量 (b) 总用电量 1) 通过式(1)~式(4)计算四分位数及异常值内限,其箱型图参数见表1,异常数据识别效果如图3所示;2) 根据箱型图参数确定图3中隧道能耗异常值的内限为[2 054.57,3 422.99],将处于内限以外的数据判断为异常值;3) 从图3中剔除4个异常数据,形成一组缺失数据;4) 由式(5)~式(7)构建KNN算法,并对异常数据和缺失数据进行修复处理,结果如图4所示。 由式(9)~式(12)逐步分解预处理后的能耗数据,计算得到CEEMDAN模型分解的5个IMF分量和1个Res趋势项,如图5所示。其中IMF5只有一个极小值点,符合CEEMDAN分解的终止条件(至多有一个残量极值时停止分解)。通过分析Res残差分量来判断CEEMDAN分解效果,Res残差分量在±5×10-13kW·h范围内波动,分解剩余残量的能量较小,表明能耗数据可较为完全地分解为IMF1~IMF5,分解效果较好。由于添加了自适应噪声,克服了EEMD的残量过大缺陷,同时避免了EMD模态混叠问题。 表1 箱型图参数 图3 异常能耗数据识别 图4 异常、缺失数据修复 (a) IMF1分量分解结果 (b) IMF2分量分解结果 (c) IMF3分量分解结果 (d) IMF4分量分解结果 (e) IMF5分量分解结果 (f) Res分量分解结果 1) 模型输入步长分析 为探究不同步长对CEEMDAN-SVR预测模型精度的影响,分别构建输入步长为1 d~14 d和输出步长为1 d的训练数据集和测试数据集,在训练集上进行训练,测试集上输出预测结果,并计算整体RMSE,如图6所示。 图6 不同步长预测结果 从图6可知,时间步长为7 d时,CEEMDAN-SVR预测模型的最优输入步长为7 d,即以前7 d能耗数据进行预测。 2) 模型输出步长分析 为验证本文能耗预测模型在不同输出步长下的能耗预测精度,分别构建输入步长为7 d和输出步长为1 d~7 d的训练数据集和测试数据集,在训练集上进行训练,测试集上输出预测结果,并计算整体RMSE,见表2。 表2 多步长预测结果分析 从表2模型性能指标可知,随着预测时间长度增加,CEEMDAN-SVR模型预测精度指标逐级下降,由于能耗数据的不确定性和随机性波形,SVR模型难以捕捉中长期数据波动的依赖,导致模型准确率下降。而在短期能耗预测中,SVR模型利用输入特征(前7 d能耗数据)与目标变量(未来1 d能耗数据)之间的关系,识别出能耗数据潜在的趋势、季节性或周期性模式,并据此获得高精度预测模型。 3) 模型预测结果分析 将各分量的能耗数据集划分为训练集和验证集,分别应用SVR模型在训练集上进行训练,在测试集上输出各分量预测结果,并集成加和整体能耗预测结果,最后输出预测结果的性能指标MAE,如图7所示。从图7(a)可知,在测试集上预测能耗曲线总体上拟合于原始曲线,以均方误差衡量单点拟合效果。从图7(b)可知,最大误差为63.78 kW·h,最小误差为1.31 kW·h,且大部分拟合数据点误差在30 kW·h以下。以MAE评估测试集整体预测水平,其值为18.452 8 kW·h,拟合效果较好。 (a) CEEMDAN-SVR模型拟合效果 (b) CEEMDAN-SVR模型预测误差 4) 不同预测模型结果分析 为验证模型的有效性和准确性,选取单模型移动平均模型(MA)、长短时记忆模型(LSTM)、门控循环单元(GRU)、随机森林(RF)、支持向量机回归(SVR),组合模型CEEMDAN-LSTM、CEEMDAN-GRU、EMD-SVR、CEEMDAN-RF与本文的CEEMDAN-SVR预测模型进行对比分析,以RMSE、MAE和MAPE指标对比各模型在测试集上预测结果,见表3。MAE指标反映预测值与真实值之间平均绝对差异程度,它能更好地反映模型预测的实际误差情况,因此,以MAE指标为主、MAPE指标为辅评估模型预测精度与拟合效果。 表3 不同模型预测性能对比分析 从表3可知,无论是与单模型还是组合模型进行对比,本文所提出的CEEMDAN-SVR模型在RMSE、MAE和MAPE指标上均取得最优预测精度。 LSTM、GRU、RF、SVR四种单一模型预测精度不高,在使用CEEMDAN算法对预处理后数据进行分解,CEEMDAN-LSTM、CEEMDAN-GRU、CEEMDAN-SVR较单一模型的MAE分别提高了49.13%、11.55%、67.55%,验证了分解模型能够有效提升模型精度。 SVR模型对能耗预测准确率不佳,以EMD分解模型与SVR模型组合预测,在MAE指标下,EMD-SVR较SVR单模型预测精度提升57.8%。而以CEEMDAN替换EMD构建CEEMDAN-SVR模型,模型精度进一步提升23.1%。结果表明CEEMDAN能最大程度提升SVR预测模型的准确率。 1) 基于CEEMDAN分解模型和SVR预测模型,能够实现对公路隧道短期能耗数据的准确预测。 2) 基于公路隧道能耗原始数据,构建数据预处理方法(异常数据识别与剔除、缺失数据修复和标准化能耗数据处理),从一定程度上提高预测模型的泛化能力和预测精度。 3) 通过济莱高速公路蟠龙隧道的实例数据,应用CEEMDAN-SVR预测模型,以RMSE衡量预测模型的输入最优时间步长与输出最优时间步长,结果表明,在输入步长为7和输出步长1的条件下,模型预测的精度最佳。 4) 选取时间序列预测模型和数据分解模型进行对比分析,验证不同分解模型与预测模型的拟合效果,结果表明:基于CEEMDAN-SVR模型预测效果最佳,相较LSTM、GRU、RF单模型,预测效果分别提升76.77%、74.77%、67.82%、21.59%,相较SVR、EMD-SVR模型,CEEMDAN-SVR模型预测效果分别提升67.55%、23.1%。1.3 CEEMDAN能耗数据分解模型
1.4 SVR回归预测模型
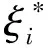
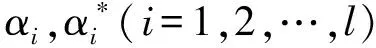
1.5 性能评估指标
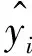
2 实例验证
2.1 实例数据
2.2 数据预处理结果
2.3 CEEMDAN分解结果

2.4 CEEMDAN-SVR预测结果分析
3 结论
猜你喜欢
昆钢科技(2022年2期)2022-07-08
当代水产(2021年10期)2022-01-12
成都信息工程大学学报(2021年5期)2021-12-30
基层中医药(2021年12期)2021-06-05
建材发展导向(2021年23期)2021-03-08
华人时刊(2018年15期)2018-11-10
英美文学研究论丛(2018年1期)2018-08-16
纺织科学研究(2017年6期)2017-07-03
河北科技大学学报(2015年5期)2015-03-11
电测与仪表(2014年23期)2014-04-04
