
基于时空序列相似性的大规模内网数据库非法访问信息的挖掘算法
2024-01-09 16:54陈琳
江苏理工学院学报 2023年6期
陈琳
(福建信息职业技术学院物联网与人工智能学院,福建福州 350001)
随着信息化技术的发展,计算机和网络在社会生产、生活中的重要性越来越凸显。为了保障组织机构工作的安全与效率,政府和企业大多建设了自己的内网。内网作为网络应用的重要组成部分,其安全性对信息的保密具有重要意义。内网信息安全问题根据威胁的类型可分为:外部的黑客入侵,即黑客盗取内网的机密信息;外部的袭击行为,主要是内网用户以不同的方式将主机连到外网,从而破坏了内网的封闭性。5G技术为内网的信息化改进提供了更加灵活的接入方式,但也增加了安全威胁。为此,科研人员设计了许多非法访问信息的挖掘方法加以应对。其中,毛伊敏等人[1]运用信息熵和遗传算法设计了挖掘算法,基于对数据相似项目的构建,通过支持度阈值进行挖掘,具有较好的挖掘效果。薛欢庆等人[2]提出了基于关系代数的挖掘算法,通过隶属度函数对数据类型进行设定,在支持向量机的基础上设定关联规则,同样具有较强的挖掘效果。
上述挖掘方法主要用在网络通信数据库中,由于缺乏连续性的数据挖掘规则,忽视非连续性数据的动态特征及数据中存在的时间关联性,导致数据挖掘的最终结果存在偏差,无法有效区分非法访问信息与安全信息。本文通过时空序列相似性设计了一种新的挖掘方法,将数据挖掘作为一个连续的过程,将访问数据看作一个时空序列,对数据的时空属性进行定义,并将其运用于内网数据库的挖掘过程,为保证内网的信息安全提供技术支持。
1 大规模内网非法访问信息挖掘规则知识库的构建
为实现对内网数据库非法访问信息的大规模挖掘,需要预先设定挖掘规则。通过对数据类型的划分,判断其是否为异常行为或攻击行为[3]。由于数据挖掘是一个连续性的过程,因此应建立动态循环的挖掘流程,在数据发出访问时进行对比,并根据访问特征建立数据审计结构,见图1。
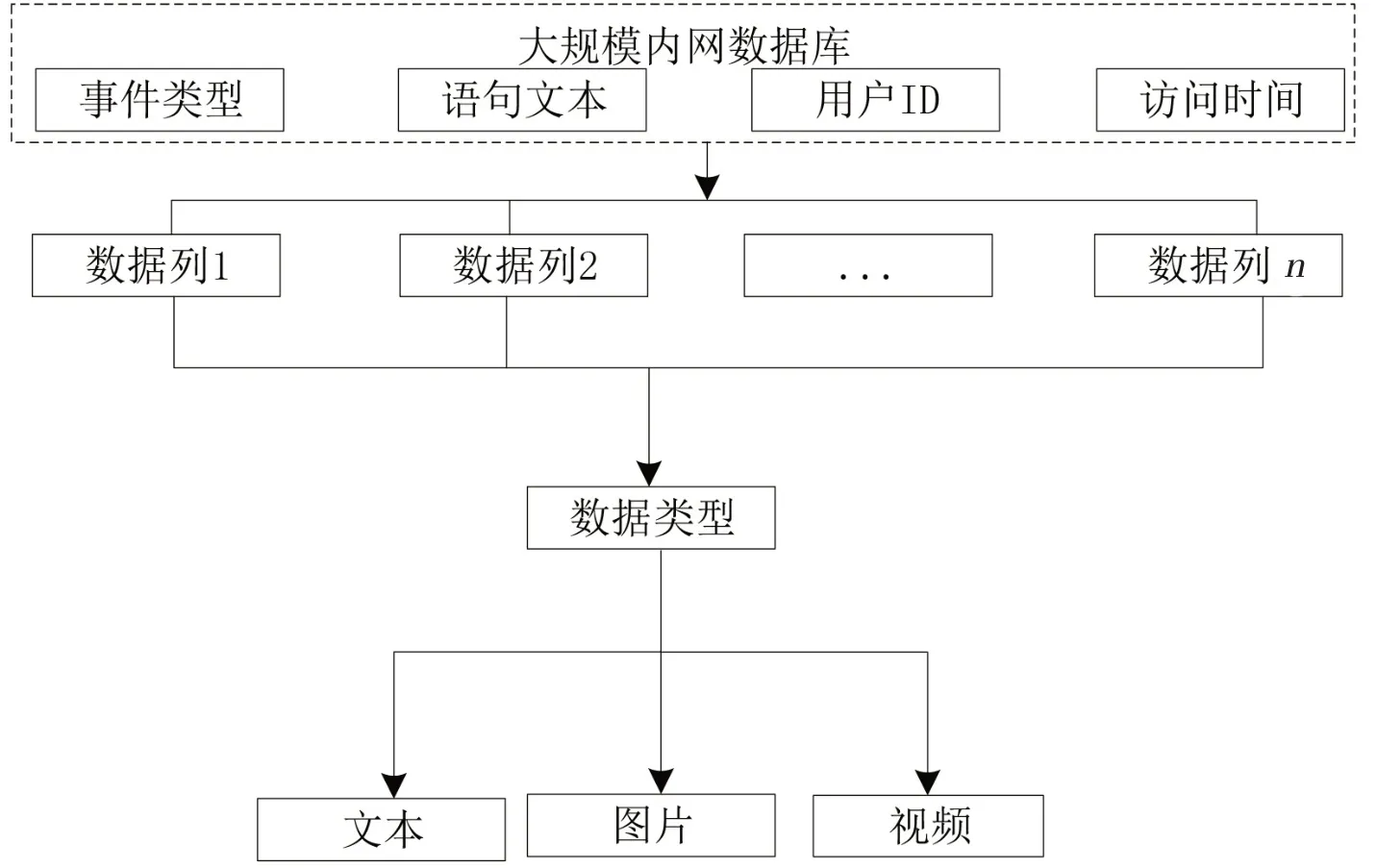
图1 数据审计结构
图1中,n 表示数据列总数。对数据结构的划分主要依赖数据列,包括其访问时间及用户的ID信息等。在采集到访问信息后,将其与具体的特征描述进行对照,完成对数据的先验审计[4]。然后,从语句分析和关联分析两方面判断该访问数据是否为非法访问。具体处理流程如下:
(1)语句分析,主要是对语句的表达形式进行检测,验证其是否存在攻击和非法访问的特征。因此,需要对语句的类型和操作表进行设定,实时跟踪其变化情况。
(2)关联分析,是指对数据库链路中的数据进行关联,根据主外键关系对访问信息进行扩展,验证是否存在相似的历史数据。若具有相似性数据记录,可初步判断为安全数据;反之,判断为非法访问数据。
运行上述分析程序时,常规化的检测用时较少,但如果发生非法访问行为,内网数据库被攻击的概率很高[5]。为此,需要建立以服务数据审计为目标的挖掘规则知识库,如图2所示。图中,m 表示数据量[6]。由于非法访问通常为群体行为,若从单个操作来判断可能为正常的语义,因此需要采用动态的知识库进行规则设定;分别对访问信息的产生时间、路径以及流通至数据库的节点进行检验,判断其是否为数据库中的非法权限用户。通过上述规则,在时间序列中判断非法访问信息的相对位置,并对其位置关系进行标识。

图2 挖掘规则知识库
2 非法访问信息相对序列位置连接关系的标识
序列长度能够记录不同数据产生的位置信息。为实现对大规模内网数据库中非法访问信息的快速挖掘,可利用上文设计的规则知识库获取信息的相对序列,并对其位置的连接关系进行标识。将每一个数据的序列记为单一项集,记作:
式中,b为数据序列串[7],v为数据序列长度[8]。数据序列长度与事件访问时间有关;当为非法访问数据时,其数据序列长度必大于给定的序列长度。据此,可建立序列的位置表征关系,见表1[9]。

表1 数据序列位置表征
根据表中内容,此次将序列划分为4 个类型,分别按照向前和向后两个方向对其进行位置信息判断,每种序列类型分别对应一种位置。以序列定义来看,当数据的序列长度能够继续扩展时,则其中至少含有一个可变位置方向。根据扩展情况定义新序列,并给予新的支持系数,具体为:
其中:v″为数据序列长度的变化结构[10];→为变换过程;f为位置变换表征矩阵;h为支持系数;b″为新序列串。基于此,对数据序列的扩展位置定义如下:
数据序列在传输过程中的具体位置可以用位置方向来表示,表达式见公式(5)。例如:当数据的序列长度v=1 时,其出现在方向z中的位置为z=2,则位置信息表示为(1 ,2 )。
3 时空序列相似性下数据库非法信息挖掘的实现
基于设定的时间序列的位置关系,以时间顺序对数据序列进行排序,根据时空序列相似性对非法访问数据信息进行挖掘。以常规化的数据请求为例,在形式上将数据看作是一个时空序列,并对其时空属性进行定义,则有:
其中:d为数据属性集合;a为属性个数;p为数据的属性域[11];i为时空域;o为数据的表现形式,且oa∈p(da)[12]。测量数据序列之间的相似性,要求序列长度相同,且每个序列的属性一致,计算公式如下:
式中:pv1和pv2表示属性域为p的数据序列[13];ya、ua表示数据序列属性,且ya∈da、ua∈da;t(pv1,pv2)表示序列之间的距离函数[14]。
由于数据在传输过程中为波动状态,直接对相邻数据进行长度计算容易产生误差,因此需要设定一个平衡函数进行检验,该函数表达如下:
式中:e和w为数据在时空序列下的变动字符;r(e,w) 为平衡函数;r1、r2、r3为平衡得分[15];[matches] 为匹配状态;[dismatches] 为不匹配状态;[alighs] 为具有较小差异。在基于连续传输数据对比的挖掘中,只有[matches] 表示访问数据与数据库中的数据相类似,其余均为非法访问状态。至此,本文通过时空序列的相似性,完成非法访问数据挖掘算法的设计。
4 实验测试与分析
运用MATLAB_7.0 测试平台模拟一个内网环境[16],以一个拥有边界防火墙,并与外界隔绝的单位内网作为模拟对象;通过ETHERNET10M/1000M交换机组成局域网,该交换机不会与互联网连接,因此可以实现局域网与外网的隔绝。在此基础上,通过该局域网连接7 组计算机(其中包括两组笔记本电脑),组成一个内网环境;具体配置见表2。
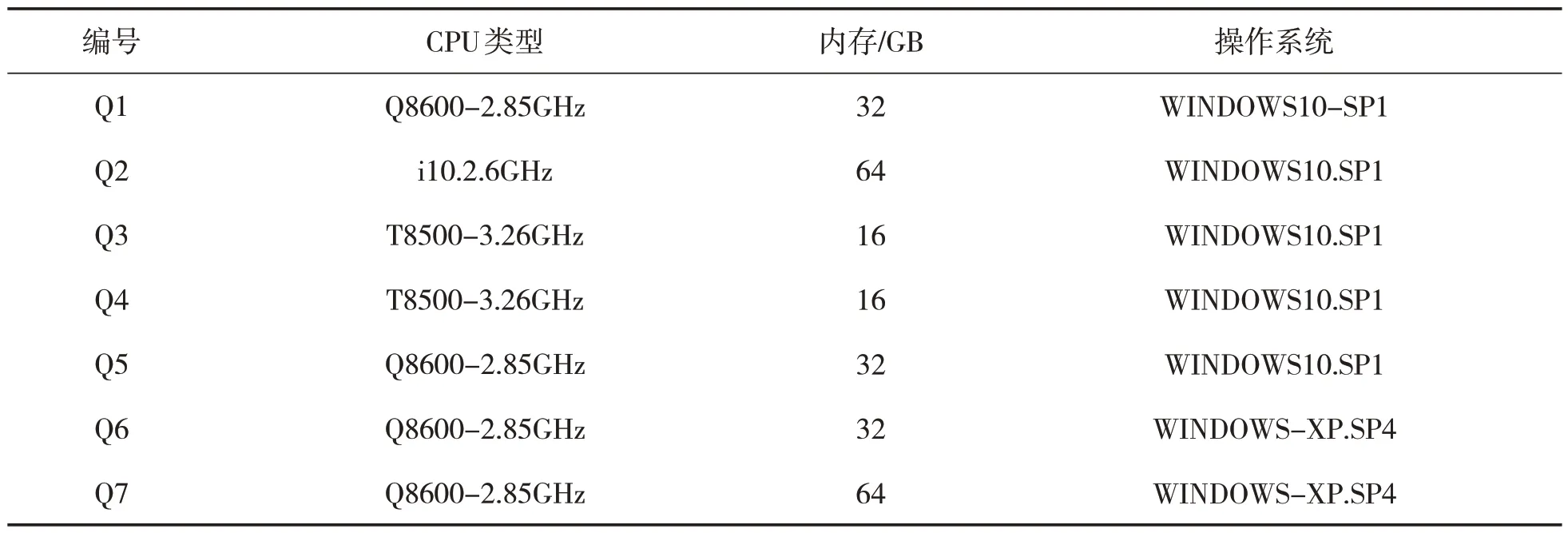
表2 测试环境配置情况
如表2 所示:编号Q1 的主机为整个测试的服务器,是该内网的控制台;其余6台主机为客户端,均安装监控代理装置。利用MATLAB_7.0 测试平台与MySQL 数据库管理系统进行交互,在搭建的内网数据库中随机选择4 150 组用户访问数据作为后期的测试对象,运用SNIFFER 软件对客户端用户的非法访问行为进行监控。完成测试环境的配置后,再对非法访问信息的挖掘测试条件进行设定:在控制主机中编写安全策略,并根据设备信息表中的ID 进行定义,编辑数据库中所有信息的来源IP地址(见表3)。
MySQL 数据库中有140 个数据集,选择其中20个。统计所选数据集在内网中的数据量和安全等级,将5 级以下的设定为安全数据。在MySQL数据库管理系统中创建一个名为“Iris”的表格,插入相应的实验数据;则现阶段数据库中的数据均具有安全性,不会与后期的非法访问产生冲突。除控制主机外,其余的主机均可模拟非法访问行为。为保证测试的统一性,对其余主机的访问IP进行包装,使其尽可能地与安全信息的来源IP相似,也可以作为非法访问信息的来源IP。具体情况如下:
(1)Q2主机:非法IP地址为132.07.2526.18,归类为E2、Q2、R2;
(2)Q3主机:非法IP地址为125.07.2502.65,归类为E3、Q3、R3;
(3)Q4主机:非法IP地址为128.07.3204.33,归类为E4、Q4、R4;
(4)Q5主机:非法IP地址为125.08.2402.33,归类为E5、Q5、R5;
(5)Q6主机:非法IP地址为125.07.2501.64,归类为E6、Q6、R6;
(6)Q7 主机:其他非法IP 地址,归类为E7、Q7、R7。

表3 来源IP地址
通过对4 组主机中产生的非法访问信息的分析,发现其对应的IP 地址与表2 中安全数据的IP 地址较为相似,因此,能够模拟非法数据的访问,符合测试要求。其挖掘算法的Python 伪代码如下:
1.//导入Iris库和访问IP包装模块
2.import pandas as pd
3.from sklearn.preprocessing import StandardScaler
4.from sklearn.cluster spatiotemporal variation attribute
5.//读取Iris数据并进行预处理
6.iris_data = pd.read_csv('iris.csv')//假设数据集保存在'iris.csv'文件中
7.features = iris_data.drop('class',axis=1)//去除目标变量列
8.scaler=StandardScaler()
9.features_scaled = scaler.fit_transform(features)//特征标准化
10.//使用基本聚类算法
11.kmeans=KMeans(n_clusters=3,random_state=42)
12.kmeans.fit(features_scaled)
13.clusters=kmeans.predict(features_scaled)
14.//检测非法访问信息
15.illegal_access=[平衡函数]
16.for i in range(len(clusters)):
17.if clusters[i]!=iris_data['class'][i]://将实际类别与访问数据得分进行比较
18.illegal_access.append(i)//如果不匹配,则认为是非法访问信息
19.//输出非法访问信息的样本索引
20.print("Illegal access samples:",illegal_access)
21.```
运用上述伪代码对非法访问数据进行挖掘,主要是基于对访问数据IP 来源的确定,即只有标定出其具体的来源,才能完成拦截或是阻断。因而,对本次选择的安全IP 地址和非法IP 地址进行特征编码,以二分法进行归类处理,见图3。图中,横纵坐标分别表示特征编码,安全数据全部归类在特征“1”中,非法访问数据归类在特征“2”中。挖掘测试中,设定非法访问数据为同时段发布状态,则4 组主机会同时段对内网数据库进行访问。为了明确本文方法的挖掘效果,特选择基于关系代数的挖掘算法和基于信息熵的挖掘算法进行对比,见图4。
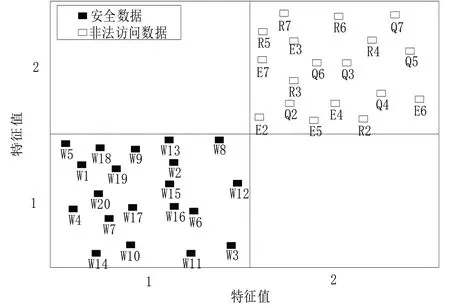
图3 数据特征编码示意

图4 不同算法的挖掘测试
由图4可见,3种算法对非法访问信息的挖掘结果各不相同。其中,基于关系代数的挖掘算法将W8、W13、W19 误判为非法网络数据,而将R2、E3、E6归类到安全数据中。这是因为该算法包括复杂的数据关联和模式挖掘,在处理大规模、非关系型的数据集时效率较低,会产生信息损失和偏差,因此挖掘效果受限。基于信息熵的挖掘算法将W16、W17、W18、W20 误判为非法网络数据,而将R2、R4、E3、Q3、R6归类到安全数据中。这是因为该算法的计算过程涉及多个关系操作及其执行顺序与优化,而信息熵计算又是个复杂的问题,用于处理大规模数据集时难以保证执行效率,必然导致挖掘的准确性和可信度下降。本文算法仅将W6 误判为非法网络数据,将R6 归类到安全数据中,表现出较为理想的挖掘效果。这是由于本文算法利用时空序列相似性,将数据挖掘作为一个连续性的过程,降低了挖掘的误差。
5 结语
本文通过时空序列相似性方式设计了新的数据挖掘算法,主要针对内网数据库中存在的非法访问信息进行挖掘。新算法在用户同时发出访问行为时,能高效、准确地划分安全数据与非法访问数据,挖掘效果理想,具有较好的应用价值。但因在非法访问信息的设定方面没有做专门的统计,所以研究还存在一定的不足,计划在后续研究中加以完善。
猜你喜欢
中学生数理化·中考版(2021年10期)2021-11-22
铁道通信信号(2020年11期)2020-02-07
疯狂英语·新读写(2018年2期)2018-11-29
网络安全和信息化(2018年3期)2018-03-03
黑龙江电力(2017年1期)2017-05-17
中学生数理化·七年级数学人教版(2017年12期)2017-04-18
科技资讯(2017年5期)2017-04-12
科学中国人(2017年14期)2017-01-28
山西建筑(2016年20期)2016-11-22
科技资讯(2016年19期)2016-11-15
