
融合多维情境信息的移动读者画像研究
2024-01-09 16:54习海旭
江苏理工学院学报 2023年6期
习海旭
(1.江苏理工学院计算机工程学院,江苏常州 213001;2.南京理工大学经济管理学院,江苏南京 210094)
随着移动互联网的深入发展,读者借助于手机和平板为代表的移动智能终端可随时随地、高效便捷地获取丰富多样的图书资源,享受更适应信息和互动需求与偏好的图书馆移动服务。为了提升图书馆移动服务的个性化和人性化水平,对移动读者信息需求与偏好进行建模的移动读者画像技术值得深入研究。移动图书馆用户画像简称移动读者画像,目的是抽取移动图书馆用户的各种数据,生成描述用户的标签集合[1]。通过移动读者画像,能够准确地掌握移动读者的信息需求和行为偏好,为其提供易用、满意的图书馆移动服务以及个性化的推荐服务。
大多数的移动读者画像研究主要通过用户自然属性、历史访问、交互行为和社会交往等信息来定义和表示需求与偏好模型[2-3]。随着研究的深入,研究者发现在移动环境下,读者的需求偏好会随着情境因素而动态变化[4],借助移动智能终端丰富的硬件资源和强大的计算资源,实时捕获读者在使用图书馆服务时的状态信息,进行特定情形下的情境信息建模,从而引起学术界广泛的研究兴趣。例如,习海旭等[5]使用本体表示方法构建包含位置、环境光线等信息的情境模型,实现借阅、阅读、发现和监控等移动图书馆的情境感知服务;程秀峰等[6]设计包含自然、偏好、情境和社交4 个维度的标签体系,构建基于用户画像的智慧参考咨询服务;李亚梅[7]分析了科学研究过程中的情境要素,构建了一个通用的科研情境模型,生成带行为权值的情境化主题偏好,并推荐了科技文献。
面对复杂、多维、动态和易变的读者个性化信息需求[8],基于情境信息的移动读者画像存在两大问题:一是针对不同的应用如何选择画像时所需考虑的情境信息;二是如何对所获取的不同情境信息进行权重融合,以构建精确的用户模型。已有研究基于各类图书馆移动服务的不同特点,构建了相应的融入情境信息的用户画像模型。但大多数研究只对不同的感知数据赋予主观权重以确定情境状态,而对不同类别情境信息之间的融合权重考虑不多,未形成一种成熟和完善的、基于多维情境信息融合的移动读者画像方法,无法充分体现图书馆的个性化移动服务。本研究在全面考虑不同应用服务中移动智能设备感知信息的基础上,深入探讨移动读者画像方法,尝试构建一种多维度情境信息融合的移动读者画像模型。
1 基于情境的移动读者画像属性
移动图书馆要提供多样化的移动服务和内容推荐,以满足不同用户的图书馆服务需求;需要描述具备哪些基本属性的用户倾向于使用什么样的方式获取哪些图书馆服务,且在信息阅读时有哪些阅读行为习惯。在此基础上,刻画不同情境信息对服务偏好和资源偏好的影响,形成融入多样化情境的移动图书馆用户动态画像。
1.1 移动读者画像属性的分类
如图1 所示,移动读者画像属性主要分为3类:第1 类是读者基本属性,包括年龄、性别、地域、职业和教育程度等,反映了读者的基本需求。第2 类是读者偏好属性,包括读者在图书馆服务类型、图书馆资源内容上的不同喜好。移动读者一般通过主动和被动2 种方式获得数字资源、在线参考咨询、空间预定、学术、活动、小组支持以及信息素养提升等图书馆服务;以不同的阅读习惯,使用不同学科、主题或关键词分类下的数字资源内容。第3 类是读者情境信息。广义上,与移动读者相关的情境信息包括读者基本属性、身心状态、历史行为,图书馆资源与服务,物理环境与社会文化环境相关的多维度信息;狭义上,情境信息是用户状态以及周围环境对用户需求与偏好产生影响的补充信息,主要包括物理情境和虚拟情境两类[9]。用户状态包括用户姿态运动等身体状态和人格特质等心理状态;周围环境包括物理条件、服务条件和活动、事件以及社交与文化环境等。
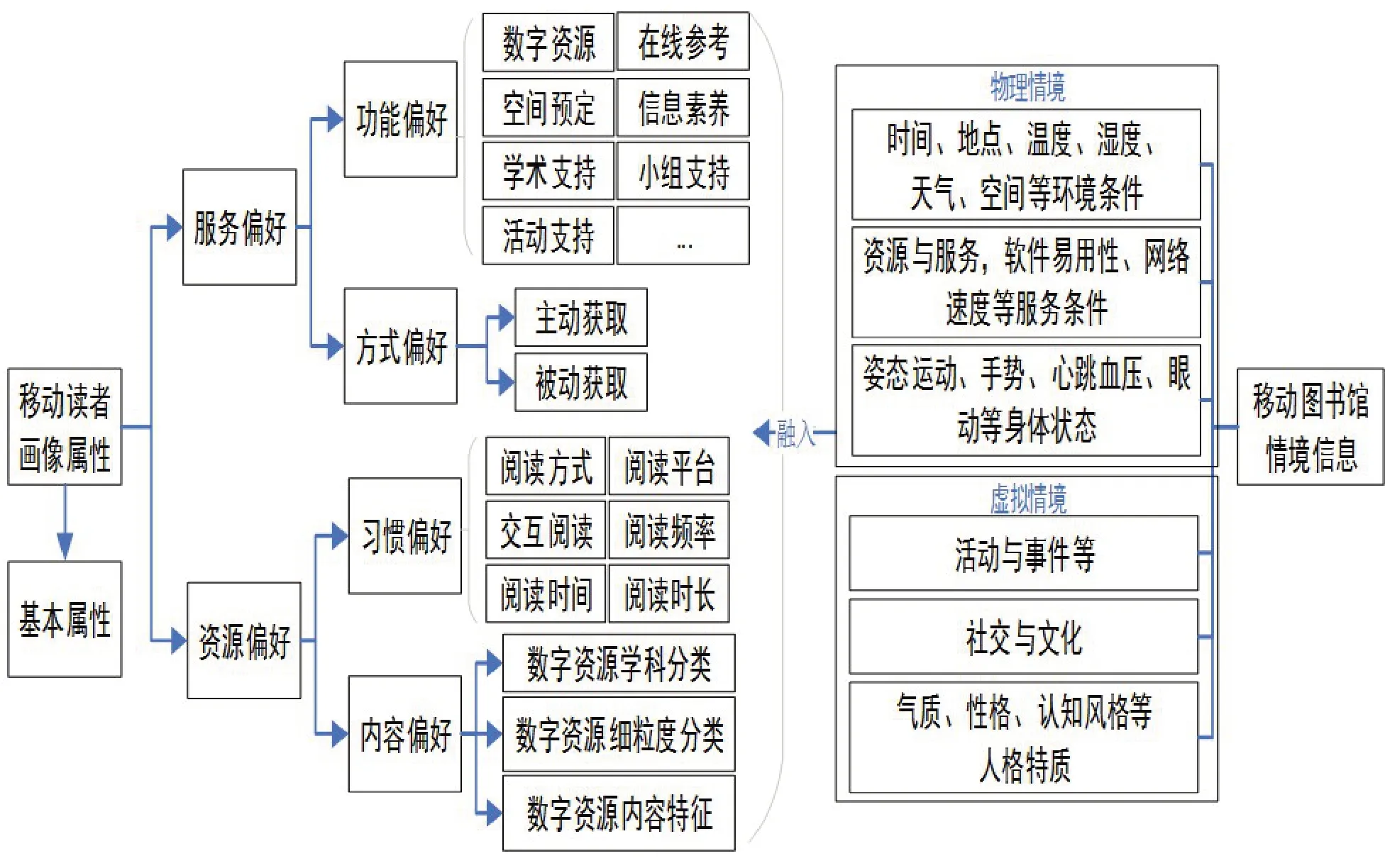
图1 融入情境的移动读者画像属性
这3类读者画像属性之间相互关联,影响着移动读者的图书资源与服务需求。一方面,不同基本属性的读者存在不同的资源和服务需求。例如,不同研究方向的学者关注的是相应主题的学术文献;年轻人倾向看书,而老年人倾向于听书。另一方面,不同的情境信息会对移动读者的资源与服务偏好产生不同程度的影响。例如,因喜欢某个图书馆App 的阅读休息提示功能,而选择使用该App;在新冠疫情期间,有关个人卫生保健的书籍被大量阅读等。再一方面,移动读者在若干典型的服务或阅读场景下,会有不同的信息和服务偏好,而这些应用场景往往又是情境信息的不同组合。例如,在研究工作场景下,人们倾向于主动获取学术领域的图书资源和学术支持服务,且阅读的专注时间较长;旅途闲暇场景下,人们倾向于碎片化阅读小说和被动地获取相关推荐资讯。
1.2 多源画像属性集成的技术架构
移动读者画像属性的类别多样,数据来源及其获取与处理方法存在一定差异。首先,不同类型属性数据的主要提取方法存在一定差异;其次,不同类型属性数据分布在各类图书馆服务应用系统中,需选择合适的多源异构数据集成方法进行融合处理;最后,不同图书馆服务应用采用在线或离线的方式提取和处理画像属性,以满足不同响应速度的需要。
如图2 所示,多源画像属性融合技术架构包括数据提取方法、集成方法和统一分析平台3 个部分。

图2 多源画像属性集成的技术架构
1.2.1 数据提取方法
移动读者基本属性的提取一般在正则表达式匹配定位信息标签后,解析其属性值,并使用数据接口工具,对不同业务管理系统中的服务和资源信息进行抽取、清洗和同步;移动读者偏好属性来源于用户使用图书馆服务的显性历史记录和隐性操作交互,主要采用自定义数据采集应用程序或使用第三方SDK,对读者的行为操作和记录进行数据采点;采集移动读者情境信息时,采用基于ACQUA和Jigsaw框架的数据采集程序在低能耗和低资源的情况下持续采集传感器数据。
1.2.2 数据集成方法
针对不同结构的数据,采用不同的数据集成方法。在结构化数据集成中,周期性地将关系型数据批量进行分析、转换和装载,形成统一完备的Hadoop数据;在非结构数据的集成中,实时收集日志数据,缓冲写入Hadoop数据中。
1.2.3 数据统一分析平台
使用HDFS储存方案,将转换后的各类数据存储在大数据系统Hadoop中,分别使用Hive分布式数据库进行离线数据处理和Hbase 分布式数据库进行在线数据处理,即时数据也可以使用消息队列(Kafka)进行实时流处理和分析。其中,离线数据处理使用MapReduce 任务完成,在线数据使用Spark/Flink框架实时处理。
2 移动读者多维度情境信息融合
2.1 情境信息的融合类型
按照不同的层次,移动读者多维度情境信息融合包括3种类型:数据层次的传感器数据融合,用于确定读者与环境状态;信息层次的情境信息推理融合,用于确定读者高级情境与图书馆服务场景;应用层次的情境信息权重融合,用于确定情境信息影响移动读者偏好的重要程度。
2.1.1 确定读者与环境状态的数据融合
分别融合移动智能终端的传感器数据以及服务应用系统中的相关数据,消除基于单个传感器数据进行决策的不确定性,获得感知对象和环境当前状态的全面且连贯的统一描述[10],如表1所示。

表1 通过情境数据融合获得读者与环境的状态
由表1 可知:通过融合GPS、加速度计、蓝牙、NFC、接近传感器等传感器数据,获得移动读者室内外、短距离和接近位置等的地点信息;通过陀螺仪、磁力计等传感器数据获得读者身体姿态信息;通过融合光传感器、麦克风和摄像头等传感器数据,获得读者环境条件信息等。与读者相关的虚拟环境情境信息大多直接集成相关数据,而不需要融合。
2.1.2 确定读者服务场景的推理融合
通过对一定持续时间范围内读者与环境状态的情境信息分析,能够推理出读者或环境状态的高级情境信息[11],即读者使用图书馆服务时所处的当前应用场景。例如,读者以恒定速度持续发生位置变化,可推理出读者正在行走等。如表2所示,通过不同类型的情境信息的融合推理,可以刻画出读者使用图书馆移动服务时,读者身心状态、所处物理环境和虚拟环境状态3个方面的应用场景。
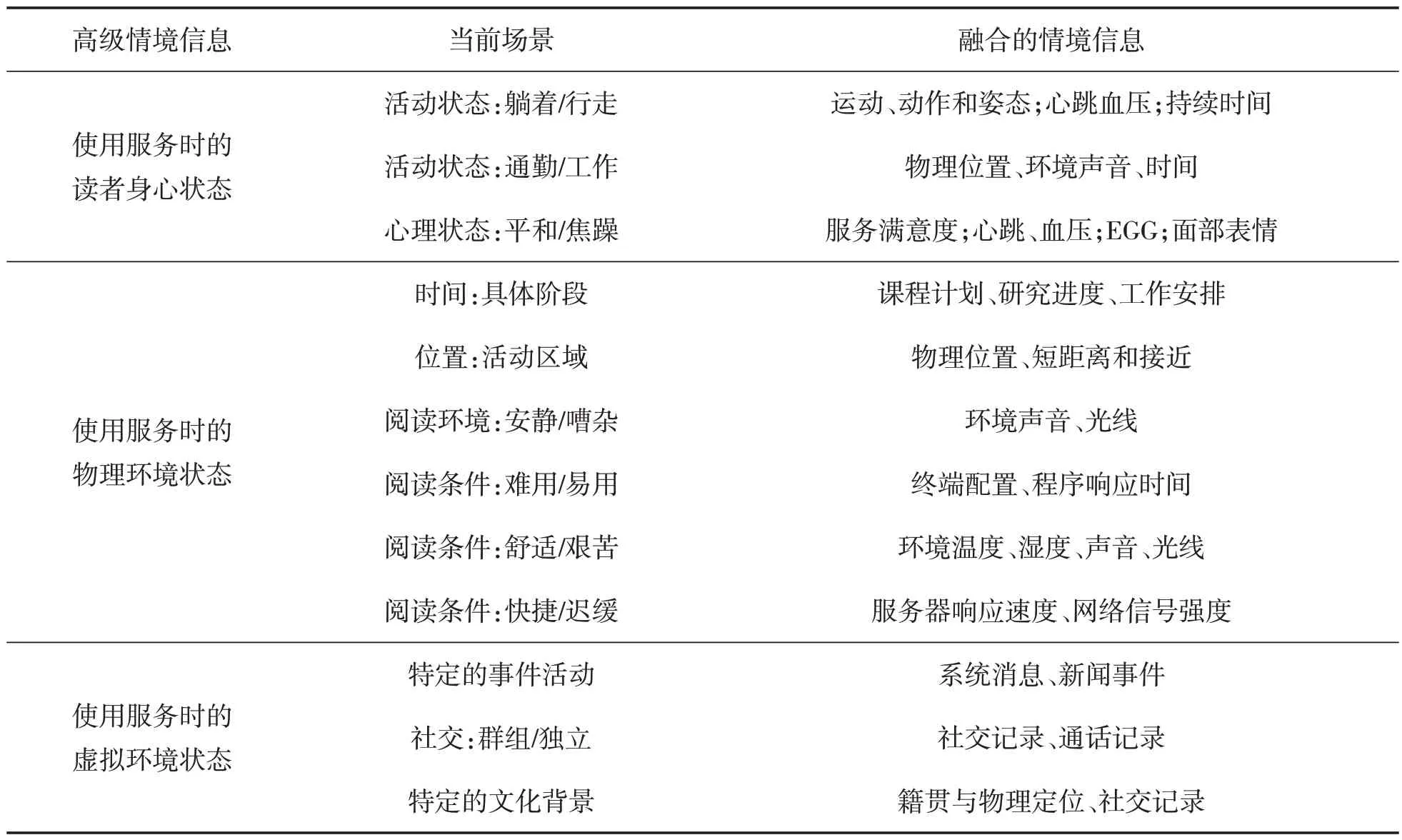
表2 通过情境信息融合获得读者当前应用场景
2.1.3 高级情境信息的权重融合
读者在使用图书馆移动服务时,需求与偏好受到多维度的情境信息或应用场景的影响,但不同情境信息对其产生的影响程度存在一定的差异。例如,相对于研究者,大学生读者对学术论文的偏好程度与时间阶段情境信息关系较大,而受其他情境信息的影响不大,如大学生在毕业设计期间对学术论文的需求激增。因此,围绕不同读者的特定需求与偏好,定义相关情境信息对不同读者特定需求与偏好的影响,按照不同权重融合情境信息,刻画读者对不同情境信息的感知度,从而为读者提供精准的信息与服务推荐。
2.2 情境信息的融合方法
不同类型的情境信息融合,使用不同抽象层次的情境信息,采用不同的融合方法分别实现数据融合、融合分类和融合决策等功能[12]。
2.2.1 传感器数据的融合方法
多传感器数据融合直接对同质的传感器原始数据进行了融合。首先,对数据进行清洗、时间对齐和空间对齐。其中,数据清洗主要使用中位值平均滤波法如公式(1)和(2)所示,消除异常与噪声数据;时间对齐是同步具有不同采样率和时间延迟的各类传感器数据;空间对齐是对齐具有不同空间位置或方向的各类传感器数据。接着,使用卡尔曼滤波算法,将不同传感器测量的同一参数的不同值进行融合。
其中:yi是某时刻的传感器测量值,i=0,1,…,N; max( )yi∉yi;min(yi)∉yi。
2.2.2 高级情境信息推理的融合方法
多传感器的融合分类是对多源异质传感器数据进行特征提取,通过模式识别、推理,获得读者或环境相关的高级情境信息。包括:传统的模板方法、聚类算法、分类模型以及神经网络方法和深度学习方法,其中决策树、SVM以及LSTM、CNN是深度学习方法的典型代表。传统机器学习方法中特征提取方法和分类模型是影响高级情境信息推理有效性和精确度的两个关键因素。深度学习方法主要由模型自动提取特征并进行融合推理分类,是目前的主流方法,例如多层LSTM模型[13]、基于多头注意力机制的卷积神经网络模型[14]和基于GCN的神经网络模型[15]。
2.2.3 情境感知服务的融合方法
面向图书馆移动情境感知服务的融合决策是对多种明确的读者及其环境状态进行信息融合,以合适的方式提供符合当前情境下的资源和功能服务;包括加权决策法、贝叶斯推理法和信任函数理论等。其中,加权决策是对不同情境信息的影响力赋予权重系数后,进行算数平均;贝叶斯推理首先赋予不同的先验信念,通过训练集得到各自的条件概率,然后融合得到总体的后念概率分布,最后得到观测数据的融合结果;信任函数理论通过信度函数描述情境信息与决策之间的关系,通过似然度函数描述情境信息的可靠性和权重,通过似然度函数和信任函数的乘积,得到证据的证据权重,合成多个证据的证据权重可得到决策的证据权重。证据合成如公式2所示:
3 融合情境信息的移动读者画像
融合情境信息的移动读者画像可全面刻画移动读者的特征、需求与偏好及其当前状态和环境,以更好地理解读者并提供满足其个性化需求的图书馆移动情境感知服务。画像过程是在对不同类型的属性数据进行采集、处理、集成和分析融合的基础上,构建细粒度的读者、资源和服务标签,并通过可视化工具展示出移动读者的画像模型。
3.1 移动读者属性标签化
采用不同的方式对读者、服务与资源的属性进行标签化处理,主要包括属性值直接转换、统计分段标签和数据挖掘分类3种方法。如图3所示,读者年龄分段标签为儿童、少年、中青年和老年;读者性别、职业、功能服务和阅读平台等属性值直接作为标签;资源内容分类可分别使用主题分析方法和实体抽取方法抽取关键词后,作为标签或直接使用中图分类进行标识;服务方式偏好按照用户是否检索转化为主动、被动两类;按照样本统计结果,根据阅读频率、时间和时长划分成涉猎型读者、专业型读者,根据阅读方式划分为泛读读者、精读读者,根据交互阅读划分为活跃用户、沉默用户等;前述方法融合而得的各层级情境信息按读者状态、物理环境和虚拟环境3类,标注其取值对服务内容和使用习惯等偏好的影响程度,表示为<情境属性、情境信息值、功能内容/方式习惯、偏好概率>。

图3 融合情境信息的移动读者画像标签体系
3.2 画像模型表示与可视化
使用向量的形式表示移动读者画像模型,以方便基于画像的情境感知服务应用中移动读者相似度的计算,向量表示为<基础信息,功能偏好,方式偏好,内容偏好,习惯偏好,情境信息对偏好的影响向量>。为了可视化画像模型,可使用Tag-Cloud等开源标签可视化工具,以不同权重大小的方式呈现读者标签;为了详细展示阅读时长,可采用柱状图;展示内容偏好,可采用雷达图;展示情境信息对偏好的影响,可使用echarts插件,以堆积图的形式表示等。
4 移动读者的情境信息融合画像实证研究
本文选择高校读者对象进行融合情境信息的移动阅读行为画像实证研究,详细展现了读者画像结果的表现形式,并对画像质量进行问卷调查评价。
4.1 移动读者情境信息的数据来源
由于读者画像涉及用户隐私数据采集,开展面向大规模移动读者,尤其是公众读者的实证研究会遇到各种现实条件限制,操作难度较大。因此,本研究以小范围内的高校读者为对象,验证本文提出的基于情境信息融合的移动读者画像研究方法。征得36位读者(20位数字媒体技术专业本科生,10 位机电产品检测与智能控制专业硕士,6位计算机专业大学教师)的授权,在他们手机和电脑上安装了系统数据采集工具和传感器数据采集工具,实时采集他们在2022年1月15日至2023年2月1日期间,使用微信读书应用时的行为数据以及活动和环境状态数据,这些数据通过因特网实时传输并保存到Hadoop大数据系统中。
4.2 移动读者情境信息统计示例
选择某个高校教师读者的基本信息、移动阅读内容偏好、习惯偏好数据以及对偏好有影响的高级情境信息进行数据统计,展现了移动读者画像中多维情境信息的详细内容。
4.2.1 读者基本信息
该移动读者性别男,地址江苏常州,会员注册时间为2019年3月12日,职业是高校教师,教育程度为博士研究生。
4.2.2 读者阅读内容偏好
在近一年内,该读者阅读过36本书籍,书籍题材从中图法分类来看,涉及历史小说、经济理财和电子技术;从主题分类来看,涉及明清历史、人物传记、股票基金、Web技术、深度学习;从内容实体分类来看,涉及“当年明月”等作者实体、“邓小平”等主人公实体、“三体”等科技实体、“SpringCloud”和“图神经网络”等方法实体。
4.2.3 读者阅读习惯偏好
近一年内,该读者大部分是使用APP 阅读软件,有时使用平板和电脑,总共阅读时长4 031 h 31 min,阅读天数168 d,按照最新国民阅读统计报告,该读者属于阅读爱好者。该读者阅读笔记共有423 条,分布在大多数书籍中,属于精读读者。读者读完29本书,完成率较高,且专业书籍阅读时长最长,属于专业型读者;订阅数只有2本,大部分是查询和检索获得图书,属于主动阅读者;关注读者数3人,赞过的书籍和内容数量都小于平均数,属于沉默用户。
4.2.4 高级情境信息的影响
近一年内,该读者看书时间一般集中在非工作日,一天内看书的时间主要集中在午间和睡前时间,工作时间看书较少且主要看电子技术类书籍;躺着和通勤状态下看的书大多是历史、小说类,工作状态下看经济、电子技术类书籍的概率较大,在行走时几乎不看书;在2022 年7 月~12月,看过新冠病毒预防与保健相关书籍。由此,分别计算出躺着、通勤状态下对历史小说主题的偏好影响概率分别为0.83 和0.81,工作状态下对电子技术类书籍的偏好影响概率为0.78,经济类书籍的为0.12,特定事件情境对内容偏好的影响概率为0.89。此外,用户活动状态对阅读时长的影响概率为0.81,对交互阅读方式的影响概率为0.73。读者所处时间阶段(开学、课题申报等时段)对阅读频率影响概率为0.87。文字大小、屏幕尺寸、网络环境、环境光线等情境信息对自动横屏、自动亮度等阅读辅助功能的偏好影响概率为0.79,而位置和社交对阅读内容和方式的影响不大。
4.3 移动读者情境信息融合画像示例
综合上述画像数据,绘制了该高校教师可视化画像。如图4所示,图4(b)、4(c)的取值都按照统计值进行了归一化处理。由图4(d)可知,假定在Covid-19 公共卫生事件发生期间,为该读者推荐Covid-19 相关图书和其它(Others)相关图书的概率计算过程,见公式(4)和(5)所示:
4.4 移动读者调查问卷的数据分析
本文采用调查问卷的形式对36位高校读者画像质量进行人工评价。
4.4.1 问卷设计
在绘制了所有移动读者的画像之后,要求读者对各自画像中阅读内容、习惯偏好和高级情境对偏好影响等信息进行评分。问卷共有12 道题,每题采用Likert五分量表法计分。每类信息包含4道题,分别衡量该类信息的易理解与一致性两个方面,每个方面含一组正向题目和反向题目。所有正反向题目都将顺序打乱,避免同类正反向题目之间相互影响。
4.4.2 画像质量的调查结果
对不同题项的主观评分进行统计计算,得出如图5 所示的箱形图,转换后得到百分制,平均分为80.96分,且95%的置信区的评分误差为3.43,即在95%的置信度下,画像结果得分在79.246 和82.676之间。

图5 高校读者画像质量问卷得分
进一步分析发现,读者对阅读内容画像评分普遍高于其他两类信息;硕士生和高校教师读者对画像的自我认识一致性较高,而本科生则普遍认为阅读习惯方面的标签吻合度有一定的差异,情境信息对偏好的影响与画像吻合度较高。
5 结语
本文划分了不同类别情境信息之间的融合类型,提出了一种结合信任函数理论和情境感知影响力的多维情境信息融合方法。在此基础上,对移动读者画像的属性构成、属性数据的采集和集成技术框架进行了探讨,最终系统地构建了一种基于多维情境信息融合的移动读者画像方法,为移动图书馆的个性化服务奠定了技术基础。由于数据隐私的限制,本研究没有采集大量读者的阅读行为数据,只以几个用户为例进行了画像实证,但也能够在一定程度上体现本方法的有效性,后续在条件允许的情况下可以进一步增加数据量,进行方法有效性的可靠性研究。本研究实证只涉及使用频率教高的移动阅读服务,没有对其他图书馆移动服务的画像服务研究,虽然不同服务类型受不同的情境感知信息影响,但画像方法和服务类型的变化关系很小。此外,基于情境信息融合的用户画像的图书馆移动服务个性化推荐值得进一步研究。
猜你喜欢
小哥白尼(神奇星球)(2022年3期)2022-06-06
今日农业(2021年19期)2022-01-12
中老年保健(2021年11期)2021-08-22
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
新世纪智能(高一语文)(2020年9期)2021-01-04
非公有制企业党建(2020年10期)2020-10-27
现代出版(2020年3期)2020-06-20
小太阳画报(2018年1期)2018-05-14
小天使·一年级语数英综合(2014年8期)2014-06-26
延河(下半月)(2014年1期)2014-02-28
