
基于气象耦合特征分析及改进XGBoost 算法的用户分布式光伏短期出力预测模型
2024-01-06 16:30邓序之刘淇叶傲霜许佳时杨王旺王玺应文韬邵佳佳李芝娟陈小毅
南方电网技术 2023年12期
邓序之,刘淇,叶傲霜,许佳时,杨王旺,王玺,应文韬,邵佳佳,李芝娟,陈小毅
(1. 国网上海浦东供电公司,上海 200120;2. 华中科技大学电气与电子工程学院,武汉 430074)
0 引言
随着化石能源短缺危机以及气候变暖带来的生态问题日益严峻,能源产业大力推进能源低碳化转型、电能替代等战略手段[1-2],我国电力产业也迎来了加快构建适应新能源占比逐渐提高的新型电力系统的新一轮技术变革[3-5]。分布式太阳能光伏发电作为一种安装灵活、产能丰富的清洁能源发电方式,在“3060”目标推动下具有良好的发展前景[6-9]。然而,光伏发电受到太阳辐照强度、降水量等气象因素及昼夜出力周期性的影响,具有较强的随机性、波动性等不稳定特点,给负荷用电及电网的安全稳定运行带来了较大的挑战[10-12]。因此,对用户分布式光伏的精准预测具有重要意义[13-17]。
目前,已经有很多学者对光伏预测展开了深入研究。文献[18]提出一种交叉全局人工蜂群算法优化Elman 神经网络的模型,解决了算法易收敛于局部极值的问题。文献[19]搭建了基于优化变分模态分解(optimal variational model decomposition,OVMD)-自适应t 分布麻雀搜索(adaptive t-distribution sparrow search algorithm,tSSA)-最小二乘向量机(least squares support vector machine,LSSVM)算法的光伏功率预测模型,对时间序列数据进行了分解处理。文献[20]构建了一种基于自适应噪声完全集成经验模态分解算法,结合黑猩猩优化算法优化极限学习机神经网络的光伏出力短期预测模型,降低了环境因素序列的非平稳性。文献[21]提出一种基于变分模态分解(variational model decomposition,VMD)- 长短期记忆(long short-term memory,LSTM)网络与误差补偿的超短期预测模型,通过误差补偿预测提高了预测精度。文献[22]提出一种基于极端梯度提升(extreme gradient boosting,XGBoost)模型和长短期记忆(long short term memory, LSTM)网络模型的短期光伏发电功率预测组合模型,并与随机森林、梯度提升决策树(gradient boosting decision tree, GBDT)模型等进行比较具有更好的预测精度。文献[23]提出了一种基于多特征融合和XGBoost- LightGBM-ConvLSTM的短期光伏发电量预测模型,解决了传统模型预测误差大、特征数据少、深层神经网络模型出现梯度爆炸或消失的问题。文献[24]提出一种针对分布式系统的时空相关性建模方法,并结合深度自注意力网络实现出力预测,研究了分布式光伏的空间相关性。
尽管上述研究取得了一定的成果,但仍存在以下问题没有解决:1) 样本依赖性,尽管上述研究的预测精度较传统预测方法有较大的提升,但对选用样本的依赖性较大,换一组样本预测精度不能保持稳定;2) 局部最优问题,单一模型或组合模型不可避免会在迭代过程中陷入局部最优,从而使得预测模型缺乏很好的泛化能力。
本文针对以上两个问题提出了一种基于Bagging 思想改进的XGBoost 算法预测模型,在Bagging 的过程中引入了集成模型,降低了单一模型陷入局部最优带来的对预测精度与泛化能力的干扰影响,同时大幅降低了预测模型的样本依赖性,提高了预测精度,具有良好的实际应用能力。
1 模型预测算法简介
1.1 XGBoost算法
XGBoost 是一种基于GBDT 的高精度集成学习模型[25-26],其本质在于将多个弱分类器(决策树1-t)集成到一个强分类器中,以提高预测精度。以回归预测为例,XGBoost 的每棵树(树1 除外)都学习之前所有树结果总和的残差(负梯度),通过将残差值与之前的预测值累加,可以不断接近实际值,其结构如图1所示。
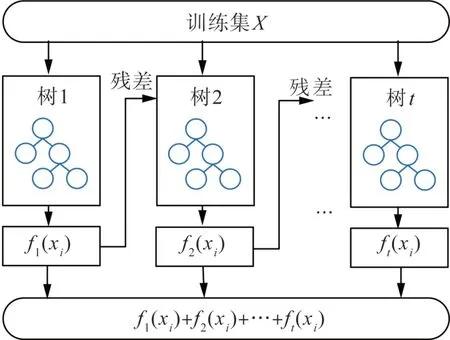
图1 XGBoost算法结构图Fig. 1 Structure diagram of XGBoost algorithm
XGBoost进行串行集成的具体数学原理如下。
对于已知数据集,树的集成模型如式(1)所示。
式中:F={f(x) =ωq(x)}(q:Rm→T,ω∈RT)为树的集合;K为树的数量;xi为第i个数据点的特征向量;q为每一棵树的结构映射到样本所对应的叶子的索引;Rm为m维输入的线性空间;T为树上叶子的数量;每一棵树fk对应一个独立的树结构q和叶子的权重ω。
其损失函数e包含两部分,第一部分是预测值和实际值之间的残差,第二部分为每棵树的复杂度之和,用以限制模型过拟合,如式(2)所示。
式中:ŷi为模型预测值;n为样本点数量;l为预测值和真实值残差;γ为叶子数量控制参数;λ为正则化参数;Wk为第k棵树的最优拟合值。
XGBoost 采用增量训练方法,即训练过程中保持原有模型,每次添加一个新的项(即一棵新的树)到目标函数中,而每一轮加入的新树都需要尽可能地减小目标函数,训练过程如式(3)所示。
式中为第i个样本在第t轮的模型预测值,在保留上一轮的模型预测值后,加入新的函数ft(xi)。
综上,XGBoost 在进行回归预测方面具有以下优点:1) XGBoost通过决策树模型的串行集成提高了输出的准确性,具有较强的学习能力;2)XGBoost 通过正则化控制模型的复杂性,有助于防止过度拟合,提高模型的泛化能力;3) XGBoost通过二阶泰勒展开来扩展损失函数,加快了优化速度。
1.2 Bagging算法
虽然XGBoost已经是一种学习能力强、精度高的算法,具备一定的泛化能力和抗过拟合能力。但XGBoost 的串行迭代过程使得整个树模型过度生长,样本依赖程度较大,仍然存在过度拟合的风险,并且XGBoost算法缺乏随机性,在更换数据源时可能存在高误差的风险。通过在XGBoost算法中引入随机训练样本构造,模型整体的方差还可以进一步降低。
Bagging 正是这样一种引入随机性的样本构造与并行集成方法[27-28],Bagging 可分为随机采样与投票组合两个过程,其原理如图2 所示。Bagging通过随机采样方式(bootstrap)得到随机样本,若数据集中有m个化合物样本,每次随机有放回的抽取1 个样本,重复m次,则可得到一个含有m个样本的样本子集。随机有放回的抽样操作使得每次收取时每个样本都有可能被选中,因此样本子集中可能会有重复的样本。于是,经过n轮随机采样法可得到n个样本子集,每个样本子集都含有m个样本,然后基于这n个样本子集训练得到n个预测模型,最后通过投票结合策略(aggregation)将n个预测模型组合。
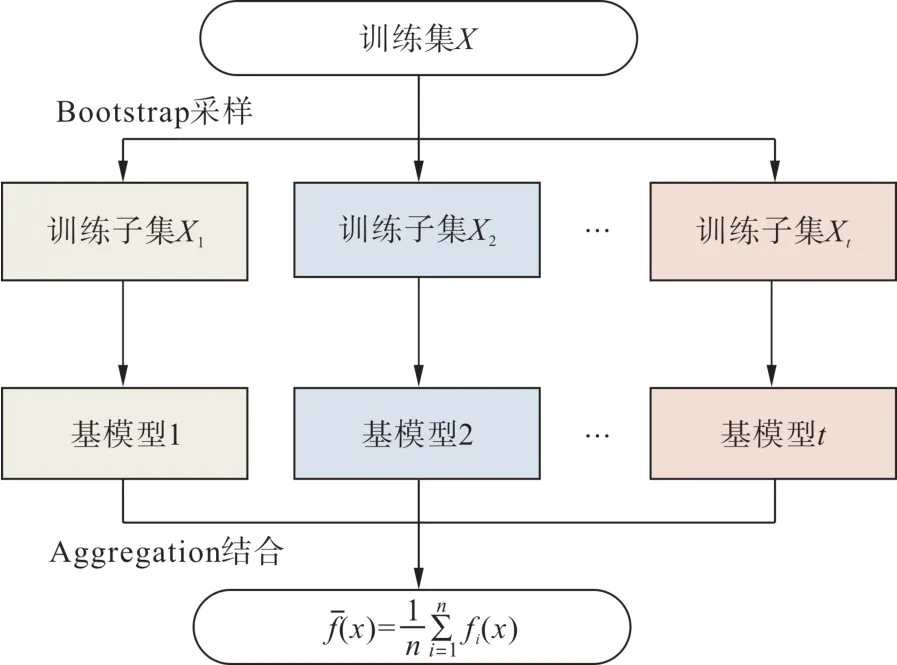
图2 Bagging算法原理图Fig. 2 Schematic diagram of Bagging algorithm
Bagging 算法每次抽取的输入数据之间相互独立,且构造的每个基模型的样本数据分布相同,Bagging 在模型集成的过程中模拟了各种随机情况,降低了出现高误差的风险。在用户分布式光伏出力预测方面Bagging 算法的引入能有效减少集成模型的输出方差和降低模型过拟合程度,提高模型的泛化能力,避免预测模型在利用部分用户进行训练之后在新增用户上的表现不佳。
2 多维气象耦合特征分析与集成预测模型
2.1 气象-光伏互信息与特征筛选
预测模型本身具备一定的特征筛选能力,但随着模型输入的影响因素的增多,高纬度的输入特征与冗杂的输入数据仍将导致模型的学习和训练效果变差,因此需要提取重要的输入特征,协助模型取得最佳的训练效果。对于分布式光伏系统气象是影响程度很大且特征数较多的一类影响因素,其中也包含着一些与光伏出力无关和彼此耦合的数据,因此需对输入的气象特征进行筛选。
由于实际测量得到的光伏出力数据与气象数据均存在较强的波动性,并且从长时间尺度来看,两者之间存在着一定的非线性相关性,这种情况下仅能衡量线性相关性的皮尔森相关系数不太准确,而互信息(mutual information,MI)可以解决非线性相关性的衡量问题[29]。MI 是信息论里一种有用信息的度量,可以看作一个随机变量中包含的关于另一个随机变量的信息量,可用于衡量两个随机变量之间的相互依赖性。除了能够反映两个变量之间的非线性关系之外,MI 还能考虑在给定另一个特征的情况下一个特证能提供的信息量的多少。
分别设分布式光伏出力和某个气象影响因素为随机变量X和Y,由于光伏出力和气象因素都是离散随机变量,其MI定义如式(4)所示。
式中:p(x,y)为X和Y的联合概率密度函数;p(x)和p(y)分别为X和Y的边缘概率密度函数。
MI 的大小受随机变量的概率分布影响很大,一般不直接比较大小,而是要先进行标准化,使得互信息量的大小得到统一,取值范围变为0—1。根据图3 所示韦恩图,可以定义标准化互信息(normalized mutual information, NMI)的表达式如式(5)所示。

图3 互信息与信息熵的韦恩图Fig. 3 Wayne diagram of mutual information and information entropy
式中H(X)为随机变量X的信息熵,其表达式如式(6)所示。
根据NMI的值的大小可筛选出对光伏出力影响大的气象因素。
2.2 气象耦合特征降维与主成分提取
通过MI 筛选气象因素后,所选气象特征内部可能存在耦合。为了进一步降低数据维数,避免数据冗余,提高计算速度,可以使用主成分分析法(principal component analysis,PCA)找出几个独立的综合特征变量来代替原始变量。PCA 的要求是:通过对原始变量进行相关性分析与协方差计算得到原始数据的最佳线性组合方式,用尽可能少的综合变量来包含尽可能多的原始变量信息。
PCA 的流程图如图4 所示。在最终获取的所有主成分综合变量中,第一主成分的方差最大,包含原始变量的相关信息量越丰富,其余主成分的方差依次减小,以至于包含的总信息量达到原始信息量的85%。另外,各个主成分变量之间的协方差为0,满足互不相关原则。
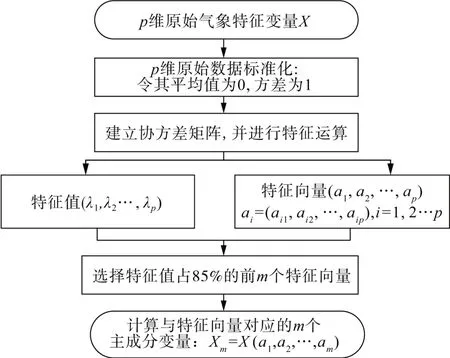
图4 PCA计算流程图Fig. 4 Flowchart of PCA calculation
基于MI 和PCA 可以获得多个气象综合变量,而不是原始的多维气象耦合特征数据。气象综合变量和气象类型数据将作为外部影响因素输入负荷预测模型。
2.3 集成预测模型流程
通过Bagging 算法对XGBoost 预测模型进行改进,得到本文所提出的集成预测模型的框架如图5所示,其流程如下。

图5 改进的XGBoost算法集成预测模型Fig. 5 Improved XGBoost algorithm integrated prediction model
1) 数据预处理:根据有效数据占比对用户分布式光伏出力数据进行筛选,对得到的原始数据中的异常值进行剔除,对剔除值与缺失值进行3 次样条插值。
2) 特征相关性分析与筛选:分析多维气象因素与分布式光伏出力总量之间的相关性,剔除相关性低的气象因素。
3) 数据降维:提取所选气象因素的主成分,以主成分变量代替原数据。
4) 样本集生成:对训练集进行随机有放回抽样,生成10个训练子集。
5) XGBoost预测基模型建立:每个预测模型对应一个训练子集,建立并训练XGBoost 预测模型,输出每个基模型的未来光伏出力。
6) 输出最终预测结果与评价:取10 个基模型的平均值与真实值对比并评估预测精度。
2.4 评价指标选取
在传统的电力系统负荷预测领域平均绝对百分比误差(mean absolute percentage error,MAPE)通常被选作预测精度的评价指标,其优势在于能直观反映预测误差相对大小。但对于分布式光伏出力预测,由于在夜晚期间光伏出力为0,MAPE 的直接除法运算在遇见分母(实际值)为0 或接近0 的值时没有意义,因此无法准确评估模型的预测精度。
为解决MAPE 使用范围受限的问题,可以在MAPE 的基础上引入反正切变换,得到平均反正切绝对百分比误差(mean arctangent absolute percentage error,MAAPE)。MAAPE 不仅保留了MAPE便于在不同模型和数据之间比较的优点,而且其取值范围始终在闭合区间以内,不会出现过大的异常值,具有更好的鲁棒性。MAAPE 的原始取值范围为0到π/2,为了使MAAPE 具有和MAPE 一样的直观数值体现,需要对MAAPE 的值进行调整。当MAPE为50%时,MAAPE的原始值为π/6,以这两个值相等且均为50%为基准进行调整,平均反正切绝对百分比误差值EMAAPE计算公式如式(7)所示。
式中:xt为实际值;et为绝对误差(即实际值与预测值之差的绝对值);θt为相对误差(et/xt)的反正切变换。
平均绝对误差(mean absolute error,MAE)可以直接反映模型的误差值,通过综合MAE和MAAPE两个评价指标,可以更好地反映模型的预测精度,并用于不同模型之间的精度比较。
3 算例分析
3.1 气象耦合特征分析
本文选取美国Pecan Street 能源项目数据库中的一个居民小区的39 个光伏系统总负荷作为研究对象,这些用户分布式光伏系统的具体地点为美国德克萨斯州首府奥斯汀市的MUELLER 绿色能源社区,光伏出力数据的时间范围为2014 年1 月1 日至2015年3月30日。奥斯汀市位于美国德克萨斯州中部,地处北纬30 °左右,气候与我国杭州、宁波等城市类似,本文从美国国家海洋和大气管理局(National Oceanic and Atmospheric Administration,NOAA)下载了该市这段时间内的详细气象数据,包括12维每小时气象数据以及每日的天气类型。
由于每个光伏系统对应的气象数据相同,为避免单个光伏系统出力随机性的影响,首先将39 个光伏系统的出力求和作为一个整体。另外,考虑到光伏系统在夜间出力为0,分两种情况分别剔除夜间数据和不剔除,计算各维气象因素与总光伏出力之间的NMI,结果如表1所示。
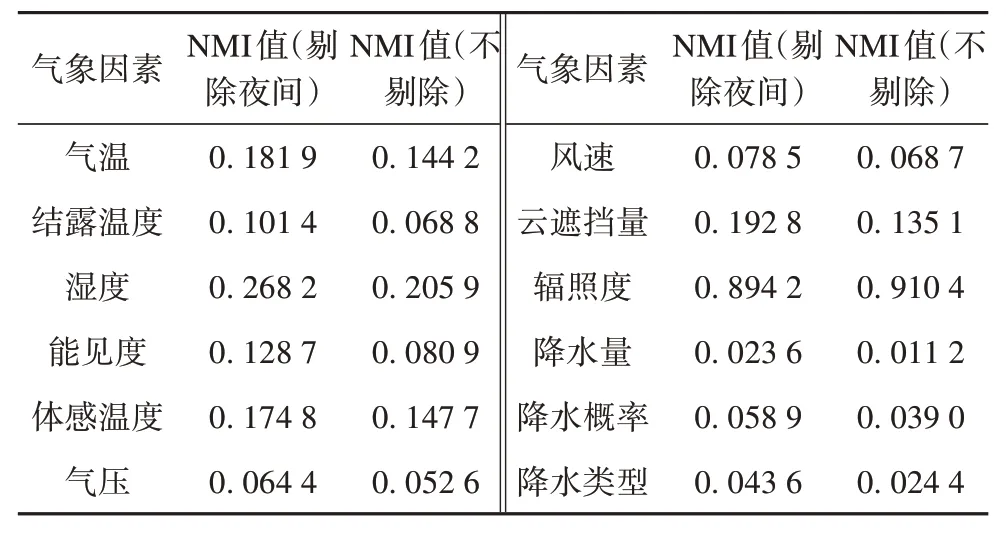
表1 多维气象因素与光伏出力NMI计算结果Tab. 1 Multidimensional meteorological factors and photovoltaic output NMI calculation results
在剔除了夜间数据的情形下,除辐照度外(辐照度夜间也为0)其余气象因素的NMI 值均有一定程度的增大,因此以剔除夜间数据的NMI 值为准,筛选出NMI 值大于0.1 的气象变量作为后续耦合特征降维的对象,分别为:气温、结露温度、湿度、能见度、体感温度、云遮挡量及辐照度。另外,计算上述特征与光伏出力间的皮尔森相关系数,以更好地显示其正负相关关系,如图6所示。
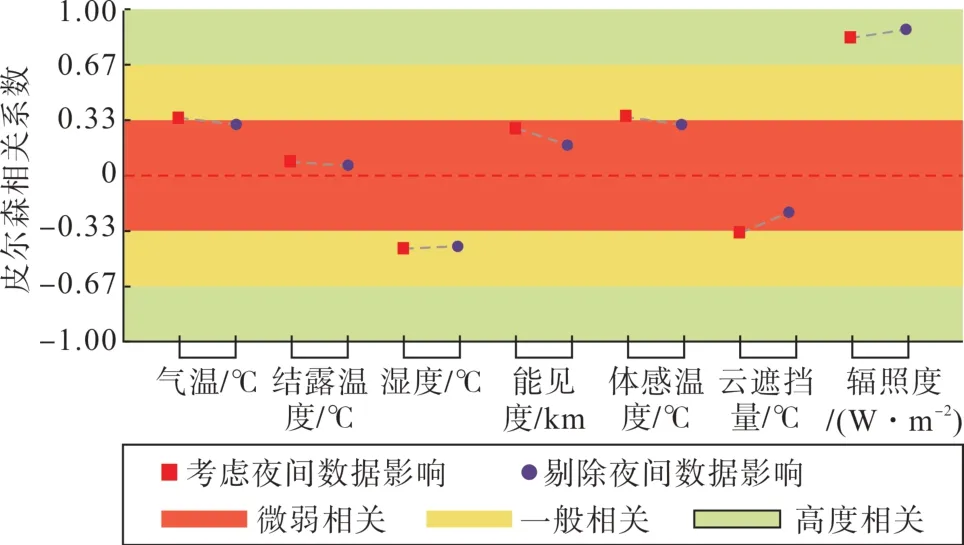
图6 多维气象因素与光伏出力皮尔森相关系数Fig. 6 Pearson correlation coefficient between multidimensional meteorological factors and photovoltaic output
注意到气温、结露温度、体感温度的单位相同,辐照度和云遮挡量之间可能也存在相关关系,采用主成分分析法消除特征间的相关性,进一步降低气象因素的维度,各主成分的贡献率如图7所示。
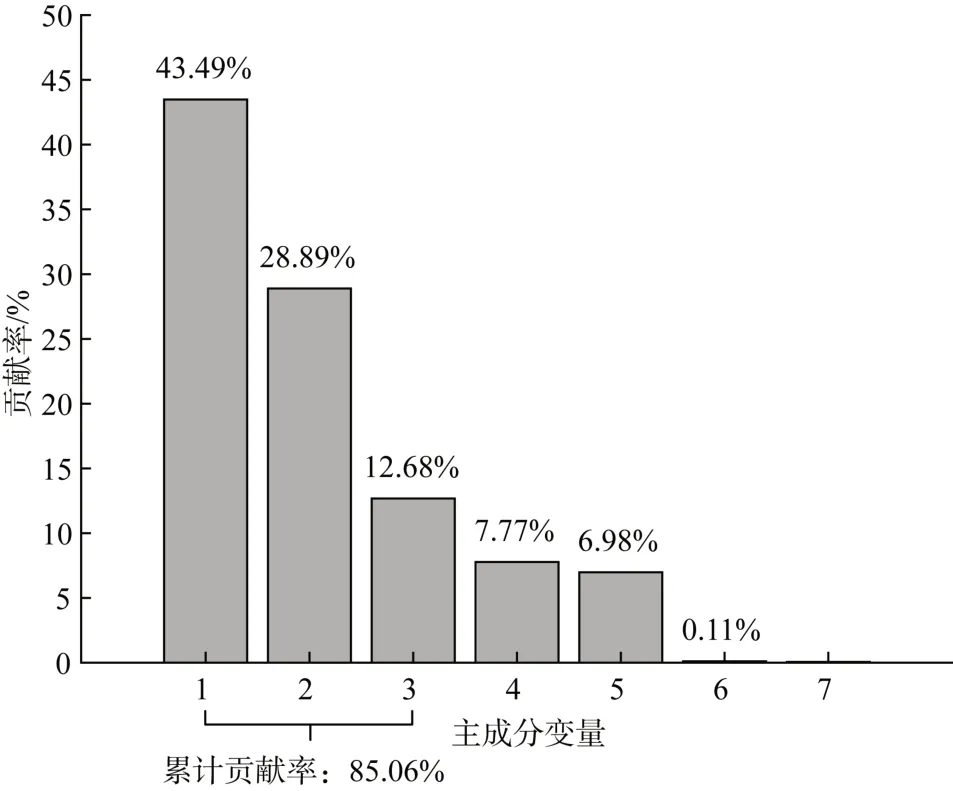
图7 主成分变量贡献率示意图Fig. 7 Schematic diagram of major constituent variable contribution rate
通过NMI 和PCA 的特征选择和降维,得到三维天气综合变量来代替原始的12 维天气数据,其中第一主成分主要包含气温、体感温度及结露温度信息,第二主成分主要包含湿度和云遮挡量信息,第三主成分主要包含辐照度与能见度信息,各主成分相互独立,减少了杂糅数据的干扰,有利于光伏出力预测模型的建立。
3.2 分布式光伏出力预测
基于改进XGBoost 算法对39 个用户的分布式光伏出力进行预测,设置原始XGBoost模型的超参数如表2 所示,并依据本文的集成方法对10 个XGBoost 模型进行Bagging 组合,另外采用传统BP神经网络和随机森林(random forest, RF)模型作为对比,其超参数设置如表3—4所示。
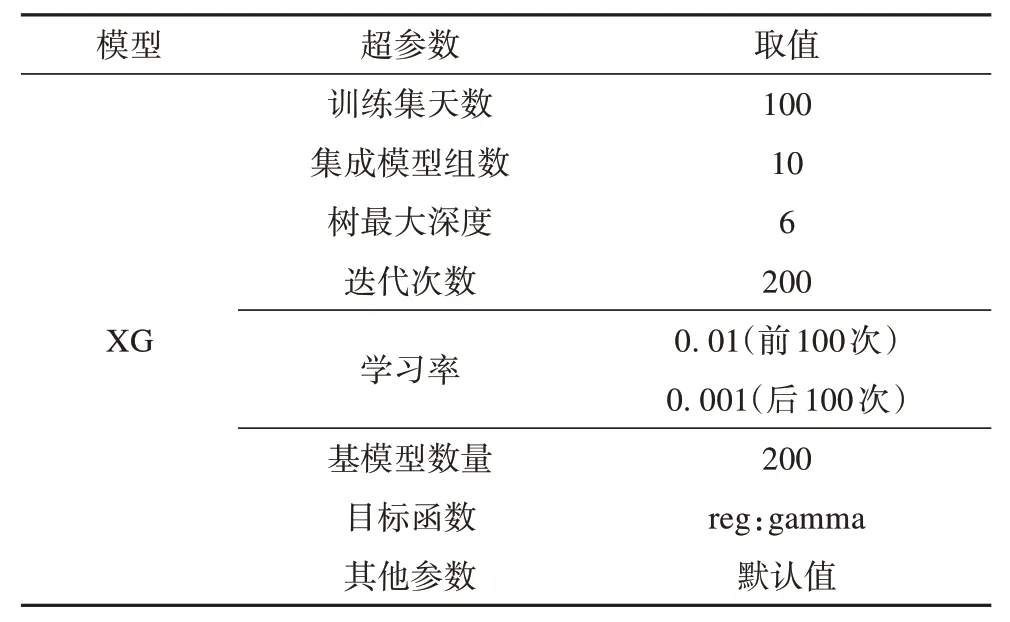
表2 XG预测模型参数表Tab. 2 Parameter table of XG forecast model

表3 BP预测模型参数表Tab. 3 Parameter table of BP forecast model

表4 RF预测模型参数表Tab. 4 Parameter table of RF forecast model
日前预测时,预测日前一日的光伏出力数据已知,模型的输入输出数据结构如图8所示。
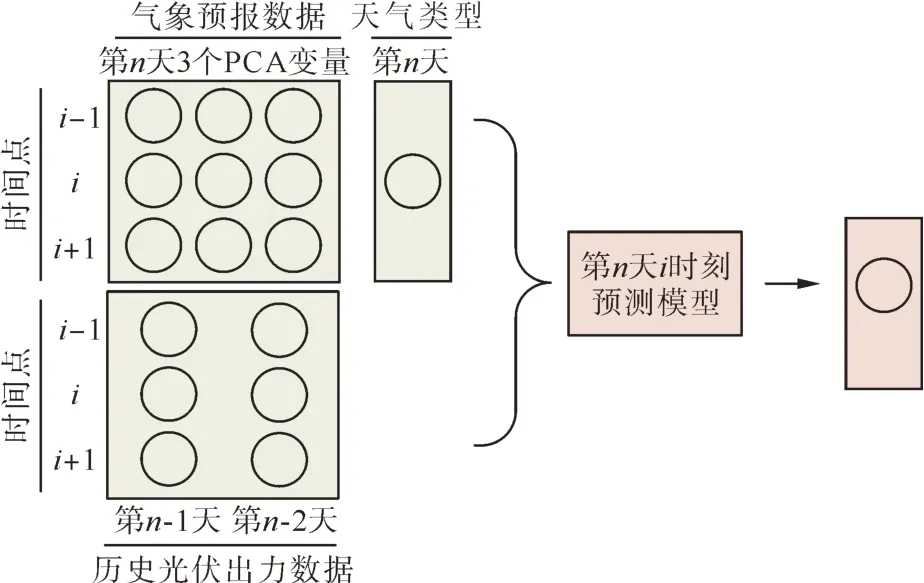
图8 日前预测模型输入输出数据结构Fig. 8 Input and output data structure of day ahead forecast model
不考虑夜间光伏出力为0 的情况,对两个典型日下的光伏出力总功率进行预测,结果如图9—10所示。
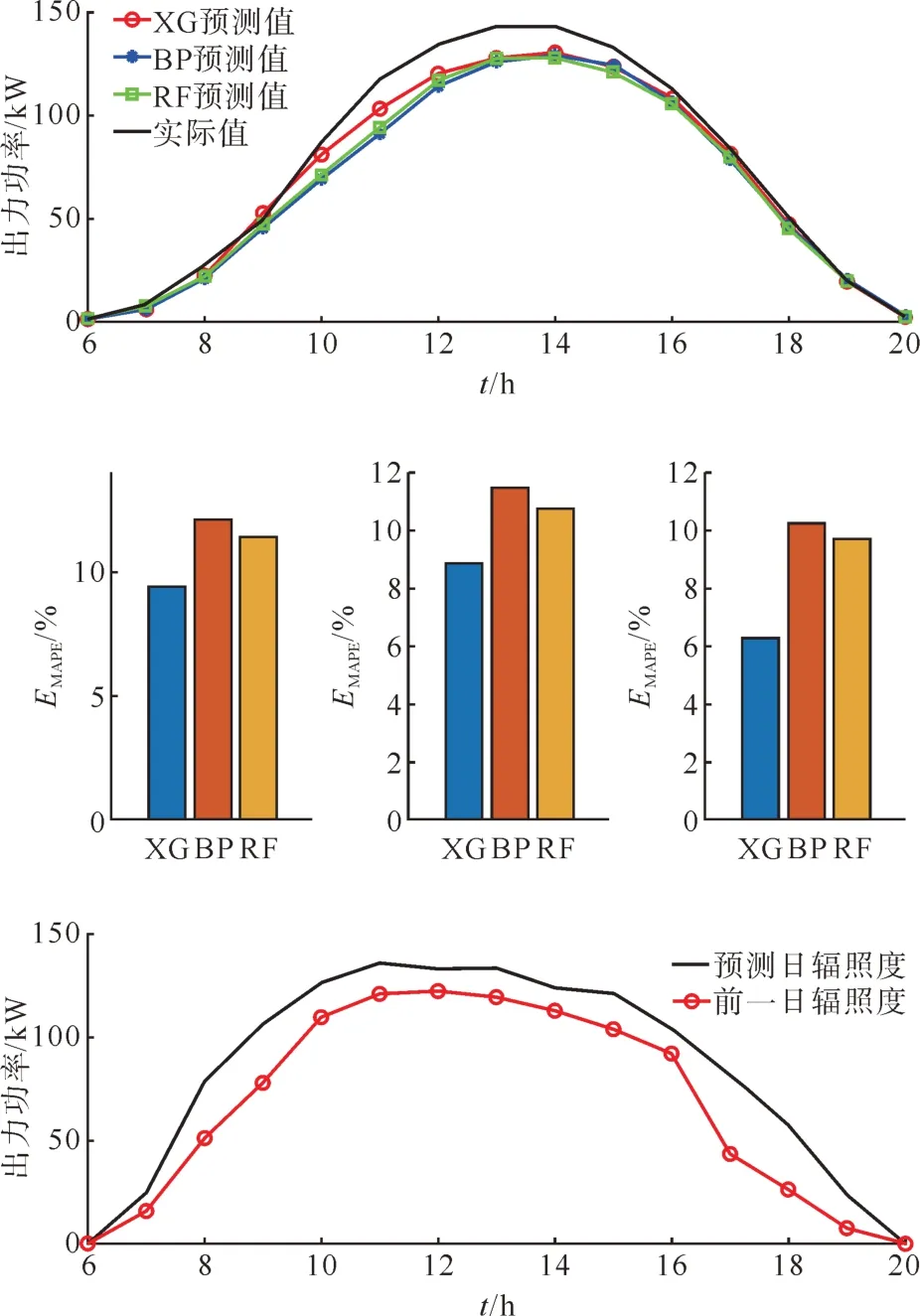
图9 连续晴朗日下光伏出力总功率预测结果及辐照度曲线Fig. 9 Forecast results of total PV output powers and irradiance curves in continuous sunny days
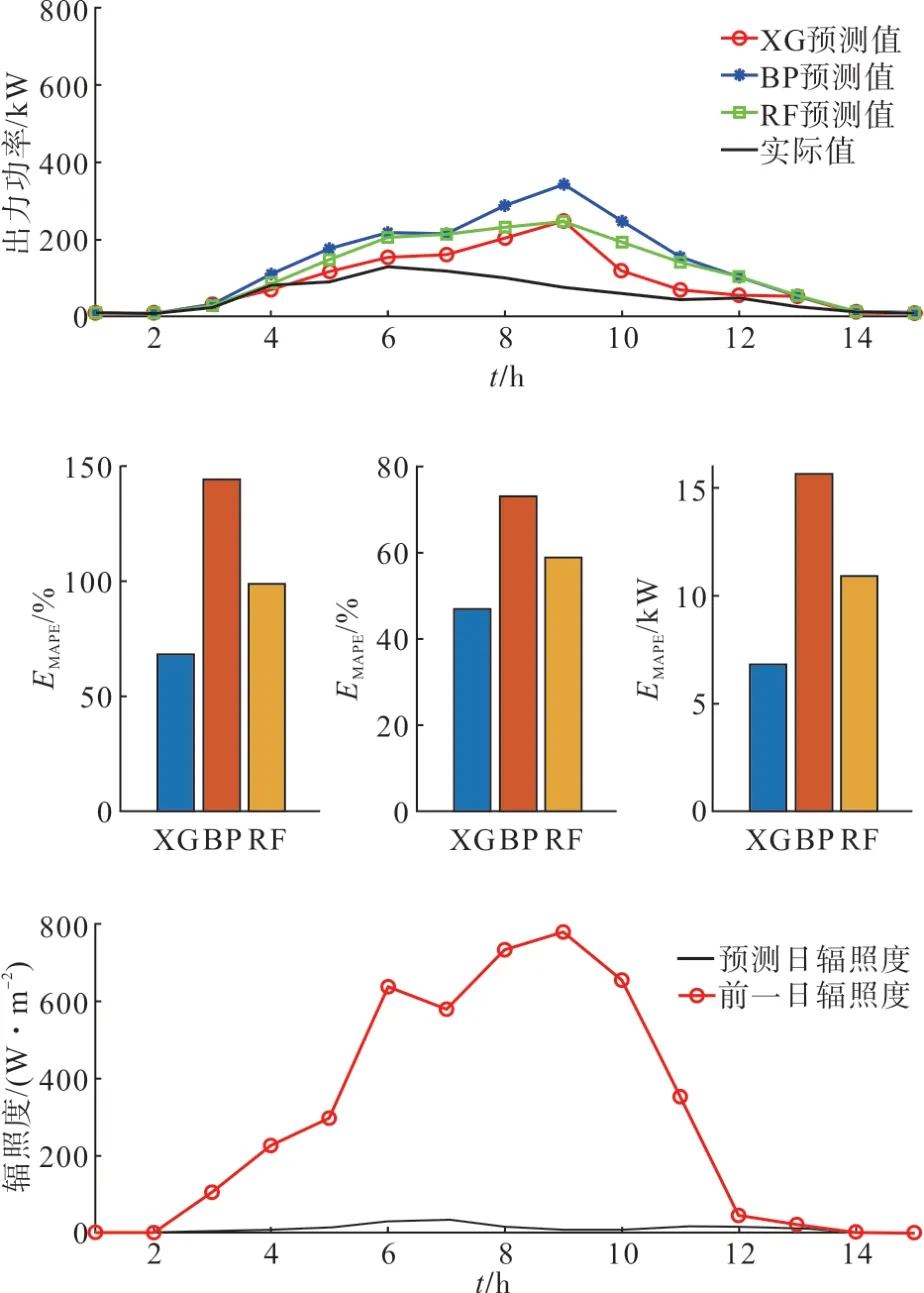
图10 突然阴雨日下光伏出力总功率预测结果及辐照度曲线Fig. 10 Forecast results and irradiance curves of total PV output power under sudden rainy days
在两个典型日下本文提出的XG 模型的预测精度均高于传统BP 模型和随机森林模型。另外通过对比两典型日下的MAPE、MAAPE 及MAE 指标,虽然XG 模型的MAE 差距很小(即预测功率的绝对数值误差较小),但MAPE 的数值差距很大,甚至在BP 模型中达到了144.35%,这对模型评价是非常不利的。而采用MAAPE 替代MAPE 指标后,在低误差情形下的数值差距不大,高误差或低基准值情形下MAAPE 的数值相对较低但仍不能准确反映模型实际精度,因此将MAAPE 和MAE 指标结合进行模型评估的方式更为合理。
进一步选取XG 模型对连续50 d 的光伏出力总负荷进行预测,每天预测结果的MAAPE 及MAE如图11所示。
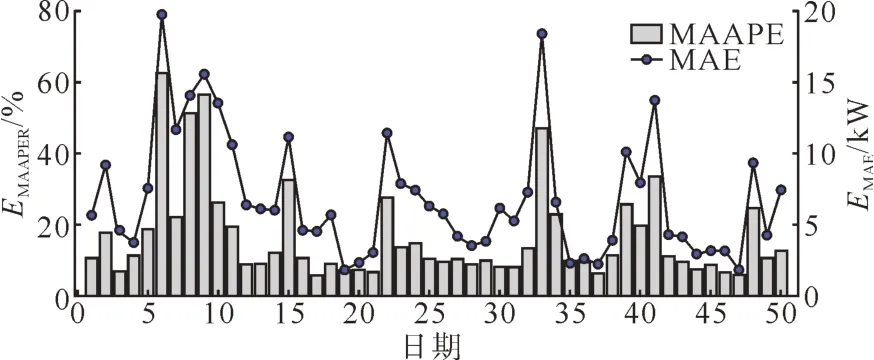
图11 XG模型预测结果评价指标示意图Fig. 11 Sketch diagram of XG model prediction results evaluation indicators
50 d 预测结果的MAE 平均值为6.934 kW,MAAPE 平均值为16.73%,当MAE 大于8 kW 且MAAPE 大于25%时,可认定为该日预测误差偏大,总计9 d。当MAE 小于6 kW 或MAAPE 小于10%时,可认定该日预测误差较小,总计28 d。
4 结语
用户侧分布式光伏数量的逐步增加,为了协助用户消纳分布式光伏发电、提高用户用电质量和提高用户储能的利用率,本文提出了基于气象耦合特征分析及改进XGBoost算法的用户分布式光伏短期出力预测模型。该模型一方面针对单一预测算法容易出现过拟合及存在样本依赖等问题引入了Bagging 思想对XGBoost 预测模型进行了改进,提高了模型的整体预测精度和泛化能力,另一方面针对多维气象因素彼此耦合且存在与光伏出力无关数据干扰的缺陷,提出利用互信息与主成分分析挖掘相关性和去除数据内部耦合的方法,进一步提高了模型对气象数据的跟踪能力。
相比于传统BP 神经网络模型和随机森林模型,本文所提出模型无论在相对指标(MAAPE)还是绝对指标(MAE)上的整体预测精度均较高,在50d 预测结果中MAE 平均值为6.934 kW,MAAPE平均值为16.73%,超过半数情形下的相对误差小于10%,具有良好的实际应用能力。总体来看,本文所提出的模型整体预测精度较高且稳定性较强,其中预测误差偏大的情形均出现在天气变化剧烈的时候,后续还能进一步区分天气变化的剧烈程度进行相似样本选取,从而进一步改善模型的预测性能。
猜你喜欢
作文周刊·小学一年级版(2022年24期)2022-06-18
内蒙古气象(2021年2期)2021-07-01
领导决策信息(2018年46期)2018-04-20
百科探秘·航空航天(2017年11期)2017-12-20
能源(2017年10期)2017-12-20
能源(2017年5期)2017-07-06
电测与仪表(2016年23期)2016-04-12
河南电力(2016年5期)2016-02-06
雷达与对抗(2015年3期)2015-12-09
电测与仪表(2015年5期)2015-04-09
