
基于强化学习的5G无线资源管理方法研究
2024-01-06 12:50:32张伟
移动通信 2023年12期
张伟
(中国联合网络通信集团有限公司广东省分公司,广东 广州 510630)
0 引言
随着移动通信的快速发展,用户对业务高服务质量(QoE,Quality of Experience)需求不断增长,以软件定义网络(SDN)的虚拟化技术与网络切片技术能支持5G网络多元服务及业务模型,并在功能、性能和安全保护方面提供差异化的技术方案。网络切片作为一种引入网络资源灵活管理的方法,负责完成物理网络的虚拟化,按需形成逻辑独立的虚拟网络,并负责虚拟资源到物理网络资源的映射[1]。然而,切片资源分配,也就是基站侧切片资源管理成为了无线资源管理的方向。对于一个网络切片而言,过多的空闲资源会导致资源浪费以及资源利用率下降,过少的资源又不能满足用户业务QoE 需求,因此,如何将有限的切片资源动态分配给各个用户,满足不同时刻用户的差异性需求,提高用户的满意度是无线资源管理亟待解决的问题。Han 等人[2]基于遗传算法提出一种新的在线优化器,从而形成基于SDN 的动态网络切片资源调度和管理方法以满足时变特征的用户业务需求,实验表明,该优化器能有效地逼近最大长期网络效用,实现动态的切片自优化策略。Alfoudi 等人[3]提出了一个基于网络切片的未来5G 系统的逻辑移动性管理架构,该架构中的每一个切片都是通过异构无线接入技术实现用户无线资源管理。为了更有效实现切片资源的自适应管理,许多学者提出强化学习算法来实现切片资源的自主分配,比如:Sun 等人[4]提出一种基于动态资源预留和深度强化学习的下一代无线接入网自治虚拟资源切片框架,首先,该框架根据虚拟网络的最小资源需求比例,定期将未使用的资源保留给虚拟网络;然后,基于用户的平均服务效用质量和资源利用率,利用深度强化学习对虚拟网络的资源量进行自主控制。Li 等人[5]提出一种基于深度强化学习的网络切片资源管理机制,该机制使资源管理与每个切片的用户活动保持一致,从而实现切片资源的自主管理。Azimi 等人[6]提出一种用于5G 网络中RAN 切片的节能深度强化学习辅助资源分配方法,该方法以深度强化学习(DRL)和深度学习(DL)为学习框架,结合功率和频谱资源的约束实现无线切片的资源分配。然而,现有网络切片资源分配方案大多数不够灵活,导致无法动态适应时延较短的业务需求。除此之外,现有的切片分配方案没有考虑用户QoE 需求和用户调度优先级,仅仅从资源匹配性角度实现网络切片资源分配。为了解决上述的问题,本文提出一种以用户QoE 为中心的切片资源分配模型,在用户QoE 与特定网络指标之间进行映射的基础上,结合用户调度优先级,最大化系统的用户QoS 需求和吞吐量最大化,实现网络切片资源分配方案。
1 相关知识
强化学习是一种机器学习的方法,智能体通过在环境中不断学习修正其选择的策略从而实现自我改进与优化。强化学习的原理如图1 所示:
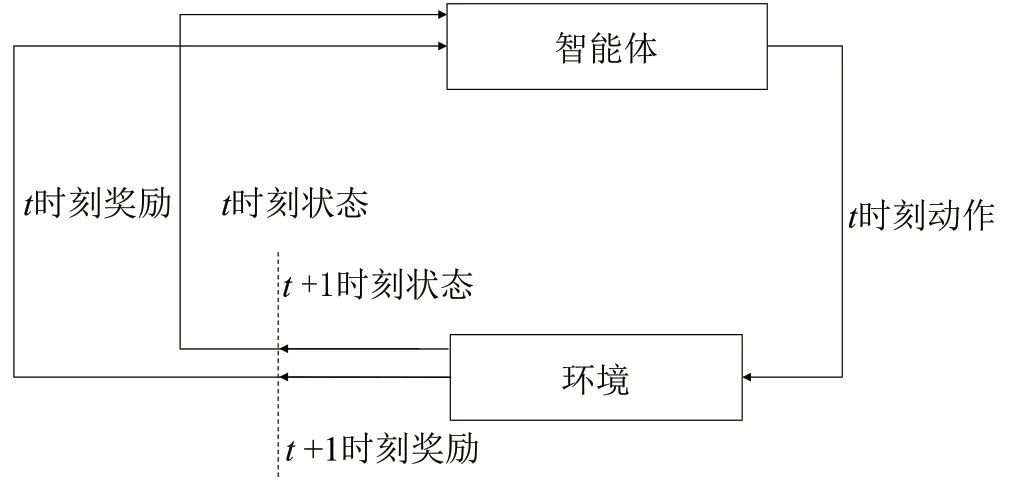
图1 强化学习的原理
图1 展示了强化学习的过程,强化学习包括几个变量:智能体、环境、状态、动作。智能体是一个实体,其能够根据环境执行某种动作从而获得奖励;环境是指智能体所处于的动态可变的场景;状态是指环境在某一时刻所处的场景类型;动作是指智能体所采取的行动策略。
强化学习的目标是为了获得最大化的累积奖励,智能体为了获取累积奖励的最大值,尽量从开始时刻0 到结束时刻T选择“正确”的动作,以此达到累积奖励的最大化。累积奖励可以表示为:
其中γ是衰减因子,是一个常数,用来评估未来奖励对当前奖励的影响。
对于所有状态的动作集,如果一个策略π*的期望收益大于其他策略的期望收益,那么在后续多个时刻中均会采用相同的状态动作函数。最优策略π*表达式为:
2 基于强化学习的5G无线资源管理技术
2.1 系统模型
本文的无线虚拟网络资源分配基于SDN 的架构实现网络切片资源的分配。该架构包括切片控制器、基站、切片以及用户设备。每一个时刻,用户设备会向接收信号强度最大的基站发送接入请求,基站会根据用户请求的业务类型分配指定的切片。然而,在现实生活中,由于用户移动性等原因,网络环境往往是复杂多变的,因此,基于动态用户的需求导致某部分业务的切片资源出现大量的闲置现象;而另一部分的切片资源则出现不够的现象。因此,基于静态的切片资源分配方案显然不满足动态的用户业务需求和吞吐量最大化的要求。为了提高用户满意度和系统吞吐量,本文采用强化学习的方法实现整体切片资源比例的动态调整。
2.2 用户调度优先级
2.3 QoE与网络指标之间映射模型
由于用户业务QoE 有固定的需求,本文考虑到现有5G 业务的需求,将用户业务QoE 映射为网络指标数据速率和业务时延。本文定义t时隙分配变量表示资源分配决策:
那么对应t时隙切片m的吞吐量可以表示为:
2.4 切片资源分配模型
根据用户吞吐量最大化的目标,考虑功率和用户优先级约束下的切片分配模型为:
2.5 基于强化学习的切片资源动态分配
本文描述基于强化学习的资源调度方案,该方案使用基于深度强化学习的动态资源调度策略生成资源分配决策。
(1)状态
假设整个无线系统在时隙t的状态表示为其中,w表示整个无线系统各个切片的带宽wi组成的向量,Thu表示整个无线系统的吞吐量,e表示各个切片剩余带宽组成的向量。
(2)动作空间
(3)回报函数
回报函数定义以整个无线系统的吞吐量。
其中,α取值在0-1 之间。
(4)下一个状态的变动
当前状态下动作空间的选择,得到累积奖励函数为:
(5)资源更新
随着智能体不断决策,整个系统的切片资源比例一致在发生变化,各个切片所分配的带宽不断更新。
3 实验分析
为了验证本文的算法,本文构建了一个仿真场景,无线资源池覆盖一个为半径200 m 的区域,然后该区域设置500 个用户,并根据需求发起eMBB、mMTC 和URLLC 服务,考虑到移动用户的移动性,各区域的用户密度是随机变化的。为了实现无线切片的动态分配过程,本文设置不同业务流量模型来设置对应业务的文件大小和时从而支撑切片的动态分配,具体数据如表1 所示:

表1 业务流量模型参数
为了展示本文算法的性能,本文采用切片根据等比例策略设置和流量比例策略作为对比。等比例策略意味着资源按照预先设好的比例平均分配到不同的切片,每个切片获得1/3 的切片资源。流量比例策略是指将资源按需求按比例分配到不同的切片上。用户根据流量模型随机生成业务报文,获取资源后开始分发业务报文。整个无线资源池在不同分配策略下的系统吞吐量如图2 所示:
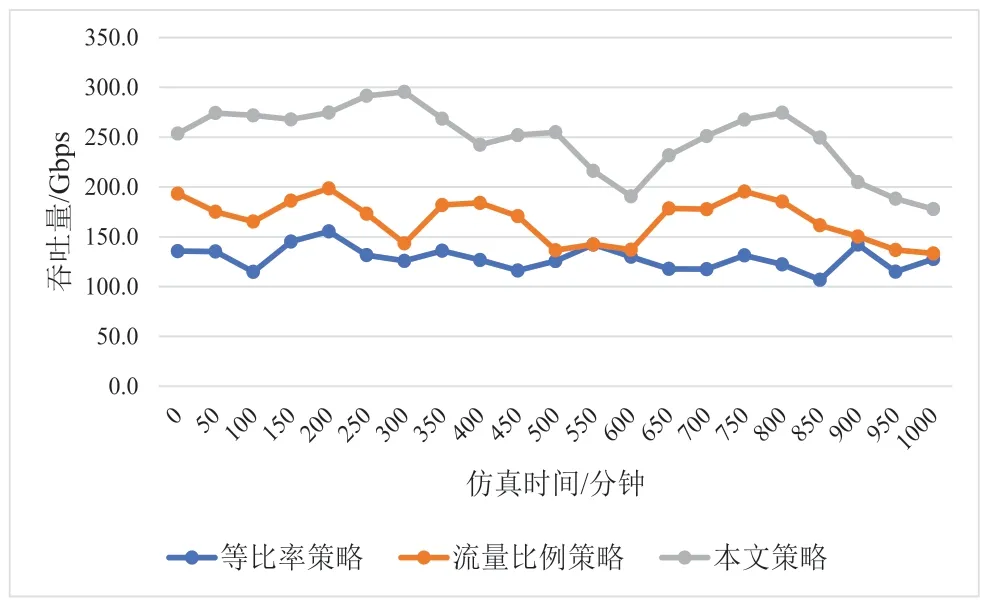
图2 不同算法吞吐量对比
图2 表明强化学习策略有效地提高了系统吞吐量。等比率和流量比例策略使吞吐量在1~2 Gbps 左右浮动,而强化学习策略在大部分仿真时间内将吞吐量提高到2.5 Gbps 以上。基于强化学习的算法关注切片总的吞吐量与用户QoE 上。在切片吞吐量方面,帮助控制器更有针对性管理切片的吞吐量,确保整个无线系统能够按需供给资源。
本文所阐述的公平性,并不是用户接入到无线系统后所拥有的同等资源,而是根据用户业务不同无线资源系统所获得的用户体验(速率和吞吐量)。由此可知,本文策略比等比率策略的用户体验提升15% 左右;比流量比例策略的用户体验提升6% 左右。基于强化学习的算法关注切片总的吞吐量与与用户QoE上,因此,本文的算法能够为用户分配更有针对性的切片,因此本文策略公平性最高。不同算法公平性对比如图3 所示:
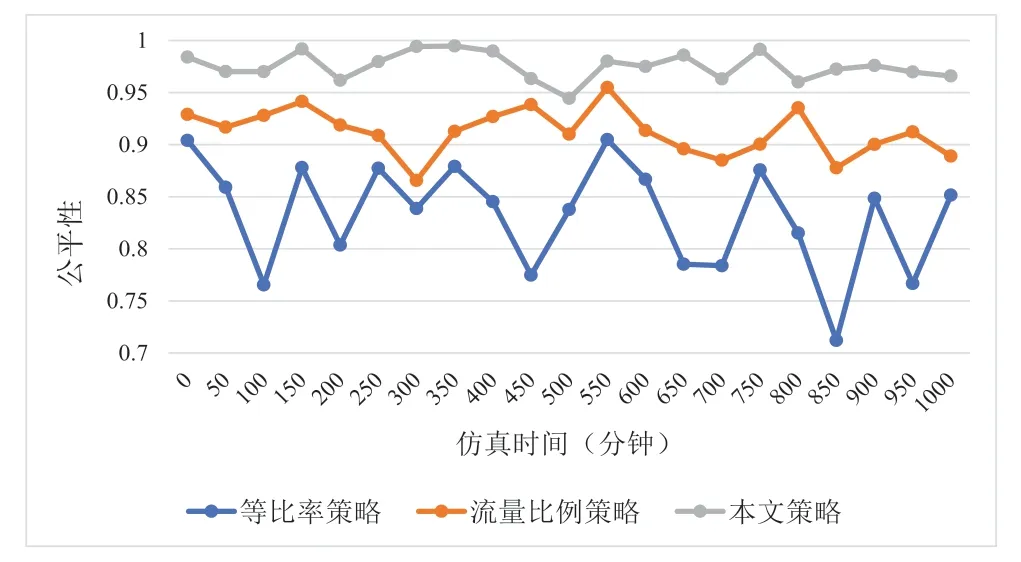
图3 不同算法公平性对比
除此之外,本文还对三种算法的速率以及时延的性能进行对比,分别如图4 和图5 所示。
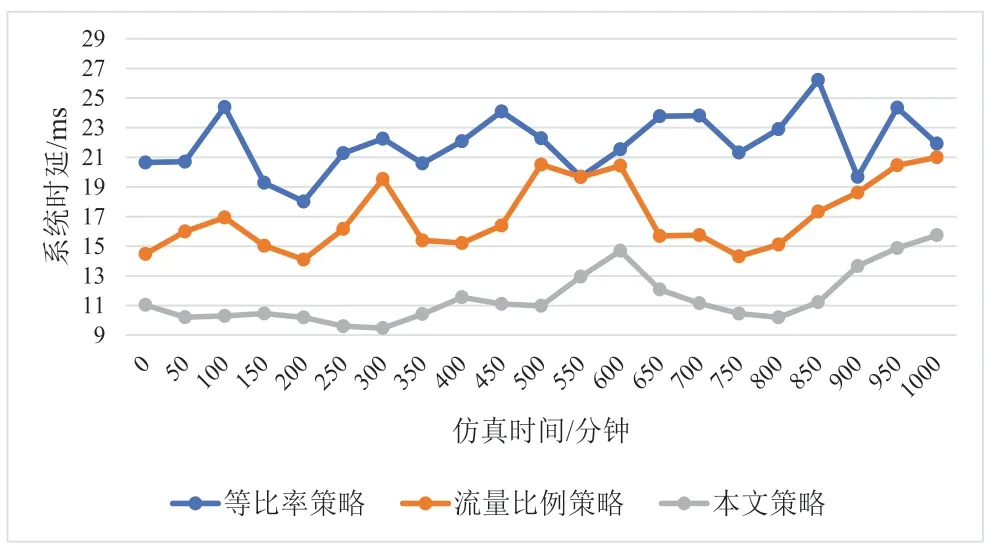
图4 不同算法系统时延对比
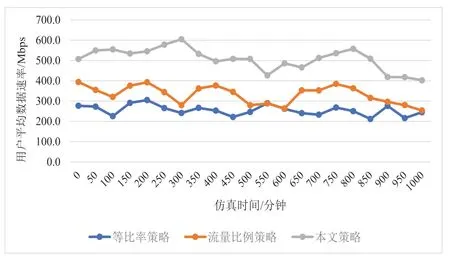
图5 不同算法用户平均速率对比
图4 表明强化学习策略有效地降低了系统业务时延。等比率和流量比例策略使系统业务时延在17~23 ms 左右浮动,而强化学习策略在大部分仿真时间内将系统业务时延降低到15 ms 以下。基于强化学习的算法关注切片平均等待时延与用户业务的时延约束,结合用户业务对时延的需求,帮助控制器更有针对性选择切片,确保无线系统能够按需服务用户。
图5 表明强化学习策略有效地提高用户平均速率。等比率和流量比例策略的速率均在400 Mbps 以下。基于强化学习的算法关注用户业务速率的约束,结合使系统业务时延在17~23 ms 左右浮动,而强化学习策略在大部分仿真时间内将系统业务时延降低到15 ms 以下。基于强化学习的算法关注切片所能提供的平均速率与用户业务速率约束,结合用户业务需求,选择满足用户业务速率约束的切片,提高用户体验。
4 结束语
为保证用户的QoE,提升网络切片资源分配方案灵活性,本文提出了一种基于强化学习的5G 物联网无线资源管理技术。此外,本文针对高度动态的无线切片资源动态变化的问题,引入了强化学习对无线切片资源进行分配,实现了自适应的网络切片动态优化和端到端服务的可靠性。仿真结果表明,基于强化学习的切片资源策略一定程度上具有更好的系统吞吐量和公平性。本文提出的无线切片资源分配方法在5G 切片资源分配方面具有一定的参考意义,可提升无线资源利用率。
猜你喜欢
英语文摘(2020年10期)2020-11-26 08:12:20
测控技术(2018年7期)2018-12-09 08:57:56
集装箱化(2016年11期)2017-03-29 16:15:48
集装箱化(2016年12期)2017-03-20 08:32:27
电信科学(2016年11期)2016-11-23 05:07:58
中国组织化学与细胞化学杂志(2016年3期)2016-02-27 11:15:40
中国当代医药(2015年17期)2015-03-01 02:03:38
集装箱化(2014年2期)2014-03-15 19:00:33
计算机工程(2014年6期)2014-02-28 01:25:32
广东造船(2013年6期)2013-04-29 16:34:55
