
人工智能音色转换模型可有效服务和促进电影创作生产
2024-01-05 06:47:38王薇娜
现代电影技术 2023年12期
迄今,人工智能(AI)技术已广泛应用于电影声音生成和制作领域,可精准模仿特定演员的声音、语调和语速,以实现高度逼真的语音合成和自动配音,尤其适用于处理语言障碍或需要重新配音的情况;AI 还可根据特定文本生成自然流畅的语音,用于电影旁白、解说或虚拟角色对话。
但在实际应用过程中,AI 生成的人声质量参差不齐,易出现音色模仿不够精准等问题,其主要原因在于音色转换质量。当前其他相关领域中AI音色转换技术的创新应用可借鉴于电影制作中,以有效改善AI生成的人声质量。
近期,国内音乐平台出现歌手“AI 孙燕姿”的众多作品,声音与孙燕姿本人极为相似。“AI 孙燕姿”是一个虚拟歌手,是人工智能模型训练的产物。最早的虚拟歌手是2007 年面世的初音未来,由日本克理普敦未来媒体有限公司(Crypton Future Media,INC.)以雅马哈的VOCALOID 系列语音合成软件为基础开发。随后,哔哩哔哩虚拟偶像洛天依、《英雄联盟》衍生虚拟乐队K/DA 女团等也采用了类似的“二次元形象+语音合成引擎”方式。然而,这些AI 歌手并没有引起太大反响,其中一个重要原因是其通常具有鲜明的虚拟形象和电音音色,使人们很清楚这仅仅是一种娱乐产品,而不会“以假乱真”。而“AI 孙燕姿”的声音和风格与真人极为相近,其将人们带入到人工智能逐步逼近人类智能的前沿科技场景。
“AI 孙燕姿”使用的核心技术来源于Sovits4.0 歌声转换模型,其基于so-vits-svc 开源软件研发。Sovits4.0模型是一种音色转换模型,可将一个人的声音转换成另一个人的声音,具有极高的准确性和逼真度。这意味着“AI 孙燕姿”可通过该模型学习并模仿孙燕姿的音色和唱腔特点,应用于其他歌手甚至其他语言的歌声中,从而创造出逼真的孙燕姿风格歌曲。Sovits4.0 具体实现过程主要包括训练数据集创建、模型训练、模型推理等步骤。其中,训练数据主要用于提取原声特征,生成训练模型;模型推理主要用于提取目标歌曲音调、音高,将翻唱者的音色训练模型与目标声音相匹配;最后,再对生成的歌声进行后期优化,例如加入混响或简单修音,一首AI翻唱歌曲即制作完成。
(1)训练数据集创建
要想获得逼真的歌手声音,首先要模拟声源,这是用来让AI 模型训练的声音素材。对于歌手来说,可以搜集歌手的高品质歌曲并从中提取干净人声,或直接使用语音素材,至少需要准备30 分钟以上的有效人声素材,1~2 小时为佳。声音素材的质量会极大影响训练准确度,为提升人声质量,可对语音素材做预加重、去噪等处理,然后对人声文件进行分割,每段人声不超过15 秒,便于训练器计算。最后将训练数据集放在模型要求的训练目录中。
(2)模型训练
so-vits-svc 是一款开源免费的AI 语音转换软件,可实现“识别数据集→数据预处理→配置训练超参数与设置信息→模型训练”这一流程,其中数据预处理主要是对数据进行响度匹配、重采样、生成配置文件、提取特征,并选择适合的特征编码器,表1列举了该软件提供的几款基础编码器特点。
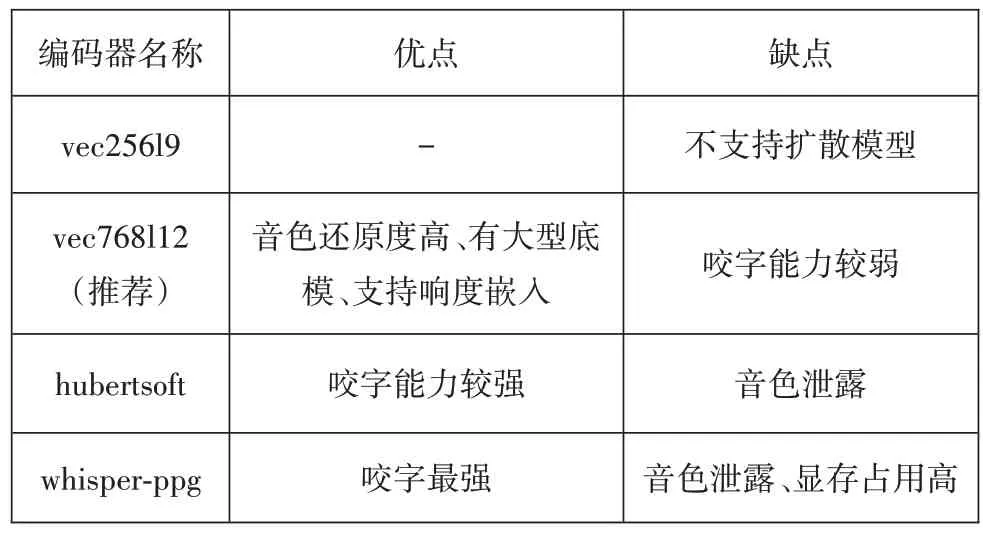
表1 特征编码器对比
配置超参数是指选择适合的批量大小、学习率以及保存训练模型的训练步数要求等。参数配置完成后,即可开始模型训练,训练中可通过观察损失函数(Loss Function)曲线的收敛情况,及时终止训练,进而获得训练模型。
(3)模型推理
模型推理是将目标歌曲的人声替换为训练模型文件的音色。在推理转换过程中,除加载正确的训练模型与配置文件外,还有可选推理参数帮助生成更加逼真的音色效果,包括变调参数、聚类模型混合比例、使用自动f0 预测、使用f0 均值滤波等。变调参数用于设置音色变调,参数范围为-12~12,如男声转女声需要升高,可设置为5~8,女声转男声需要降低,可设置为-5~-8。聚类模型混合比例可控制使用聚类模型的占比,有限提升音色相似度,但会降低咬字准确度。该参数的范围为0~1, 0 为不启用,越靠近1, 则音色越相似,咬字越模糊。自动f0 预测用于将模型音高匹配到推理源音高,主要用于转换语音,使用时会导致变调参数失效。f0 均值滤波开启后能有效改善哑音,但可能会导致跑调。
模型推理完成后即可得到转换后的人声,如果转换效果不理想,还可通过调整训练迭代次数、编码器参数设置、推理参数设置等,进一步优化模型,直到输出满意结果。后续通过合成伴奏,增加合理混响,即可得到AI歌手演唱的新歌。
Sovits4.0 的训练生成过程虽已较为成熟,但“AI孙燕姿”的音色逼真程度高,很大程度还要归功于歌手本人音色的独特性,使AI 模型提取的特征更为显著。值得注意的是,AI 歌手在情绪、咬字、换气等细节处理上还有所欠缺,若应用于影片角色配音,还需进一步调整优化。
除音色转换,AI 声音制作还可服务于电影音乐和音效。音效方面,AI 可分析场景中的视觉元素,并自动生成相应的声音效果,如爆炸声、雨声等。音乐方面,基于人工智能的音乐推荐创作系统可根据电影的情节、氛围和风格,智能推荐或创作适合的背景音乐和配乐。2023 年1 月,谷歌发布有“音乐版Chat-GPT”之称的MusicLM,可自由混搭不同类型的风格和乐器,通过输入“晚宴上的爵士乐”这类指定地点和时间的文字,就能自动创作出符合当下情绪的乐曲。我国中央音乐学院开发的AI 自动作曲系统,可通过人工智能算法进行作曲、编曲、歌唱、混音,能够在23 秒快速创作出一首歌曲,并达到一般作曲家的水平。迄今市场上已有许多AI 作曲的商业软件,如Boomy、MURU、Amper Music、AIVA 等。以Amper Music 为例,该工具可通过几次点击设置音乐风格、乐器、时长、节奏,就可生成一首原创音乐,生成后还能继续编辑音轨,包括调整音量、混响、节奏、旋律、添加或删除乐器等。这些应用不仅提高了声音制作的效率和质量,还为电影创作生产提供了更多创新升级的可能性。
猜你喜欢
《学习方法报》语文新教材高二选择性必修(2023年13期)2023-04-29 00:44:03
河北画报(2020年10期)2020-11-26 07:21:24
意林·全彩Color(2019年11期)2019-12-30 06:08:58
家庭影院技术(2017年9期)2017-09-26 03:41:34
民主(2017年3期)2017-05-12 09:48:52
北方音乐(2017年4期)2017-05-04 03:40:10
学与玩(2017年6期)2017-02-16 07:07:16
中国音乐教育(2014年11期)2014-05-18 09:58:26
小说月刊(2014年12期)2014-04-19 02:40:13
辽河(2004年4期)2004-04-29 00:44:03
