
非成对训练样本条件下的红外图像生成
2024-01-04 02:24:48蒋昕昊杨志勇
光学精密工程 2023年24期
蔡 伟,姜 波,蒋昕昊,杨志勇
(火箭军工程大学 兵器发射理论与技术国家重点学科实验室,陕西 西安 710025)
1 引言
红外成像技术利用红外探测器获取目标与环境的热辐射差异,通过光电转换技术形成可观测的红外图像,具有抗干扰能力强、探测距离远、可全天候工作等优势,因此在军事侦察、公共安防、医疗成像等方面发挥了重要作用。但在红外成像技术的发展过程中,经常需要丰富多样的红外图像数据作为验证测试的样本。同时基于深度学习的算法也必须使用大量的红外数据对模型进行训练,从而确保模型的训练效果。然而,在许多场景中,由于测试环境、搭载设备等客观因素的限制,采用实拍红外图像的获取方式是十分困难的,构建大规模的红外数据集成本极高。因此利用红外图像仿真技术生成高质量的红外数据,不仅能够有效地降低获取红外数据的成本,还可以生成很多自然环境以及外场试验难以获得的红外数据,这些数据将为红外相关设备在军事、民用领域的应用提供有力支撑。
Vega/VegaPrime,SE-Workbench,MuSES,DIRSIG 等传统的红外仿真技术[1-3]利用人工构建的三维模型计算每个单位的热辐射,模拟真实场景下的红外数据。但这些方法的计算框架较为复杂,需要大气温度、相对湿度、风速等诸多额外的环境信息。而利用图像风格迁移的方法将种类多样的可见光图像直接转换为红外图像相比于传统的红外仿真方法更加快捷方便。近几年,随着深度学习技术的迅速崛起,生成对抗网络在图像生成和转换、信息安全、视觉计算等领域展现出显著的应用价值[4-6]。基于生成对抗网络的图像风格迁移模型取得了巨大成功。Pix2pix[7]首次使用U-Net 作为生成器,PathGAN(Generative Adversarial Network)作为 判别器,实现了语义图到真实场景图、卫星图到地图、日景图到夜景图的转换,但Pix2pix 对训练样本要求严格,必须使用成对图像作为输入。然而,针对图像跨模态转换问题,很难采集和建立充足的成对训练数据,因此Pix2pix 在实际应用中具有一定局限性。而CycleGAN,DiscoGAN,DualGAN等[8-10]方法利用一种循环一致性损失函数对非成对图像进行训练,实现了四季场景转换、照片与艺术画互转。但基于循环一致性损失函数的方法通常要求图像之间的双向映射,这种限制严格的双向映射对于模态差异较大的图像转换效果并不理想,尤其面对复杂场景的红外图像转换时模型的性能受到极大影响。如图1 所示,Cycle-GAN 在进行可见光图像到红外图像转换时,由于双向映射的严格要求,反而造成了图中红色方框内的生成结果失真(彩图见期刊电子版)。因此,如何在非成对样本训练的条件下高质量的实现红外图像的转换,对于红外数据集的构建具有重要的研究价值。

图1 两种红外仿真算法生成图像效果对比Fig.1 Comparison of image effects generated by two infrared simulation algorithms
基于以上分析,本文提出了一种使用非成对样本进行训练的可见光图像到红外图像转换的生成对抗网络(Visible to Infrared Generative Adversarial Network,VTIGAN),有效实现了红外图像仿真生成。VTIGAN 相比于循环一致性损失的方法而言,并不要求模态间的双向映射,而是引入多层对比损失和风格相似性损失约束网络训练,重点关注可见光图像到红外图像的单向映射,因此不仅降低了网络复杂度,红外图像的生成质量也更高。本文的贡献总结如下:
(1)针对可见光图像到红外图像转换时模态差异较大,现有算法使用非成对数据训练效果不佳的问题,本文提出了一种新颖的红外图像仿真生成算法VTIGAN,实现非成对训练样本下可见光图像到红外图像的转换;
(2)在生成对抗网络的基础上引入多层对比损失、风格相似性损失和同一性损失约束网络模型的训练,在图像转换过程中最大程度保留输入的可见光图像语义内容不变,同时生成逼真的红外风格特征;
(3)在公开的可见光-红外数据集上进行了大量实验,证明了VTIGAN 生成的红外图像在定量评价和视觉效果上的优越性,相比于其他算法更加适合非成对训练样本条件下可见光图像到红外图像的转换。
2 算法原理
假设可 见光域 为χ⊂RH×W×C、红外域 为γ⊂RH×W×C,给定非成对可见光图像数据集和红外图像数据集分别为X={x∈χ},Y={y∈γ}。本文的目的是通过VTIGAN 学习一个映射G:X→Y,从而实现可见光图像到红外图像的转换。VTIGAN 包含一对生成器和判别器{G,DY},生成器G完成X→Y的映射,判别器DY负责确保转换后的图像属于红外域。生成器G由编码器、转换器、解码器组成,分别表示为Genc,Gcon,Gdec,生成红外图像ў的过程如式(1)所示:
在图像转换过程中,VTIGAN 从编码器中提取输入图像的多层特征信息,并使用一个双层MLP 网络[11](HX和HY)将提取到的特征信息投影到共享的嵌入空间,从而计算输入和输出图像间的多层对比损失。此外,VTIGAN 还引入了两个轻量的特征映射网络{Hf,Hr},提取仿真红外图像和真实红外图像间的公共信息,并以此构成风格相似性损失。特征映射网络{Hf,Hr}依次由卷积层、ReLU 激活函数、平均池化层、双层点卷积级联而成。
图2 显示了VTIGAN 的整体网络架构。VTIGAN 主要结合了对抗损失、多层对比损失、风格相似性损失以及同一性损失实现网络模型的训练。下面将从网络结构和损失函数两个方面详细介绍本方法的具体原理。
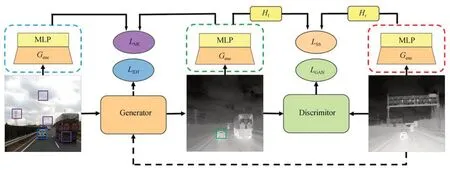
图2 VTIGAN 的基本框架Fig.2 Basic framework of VTIGAN
2.1 生成器
VTIGAN 利用卷积神经网络和transformer[12]的组合,构建了 一种新 颖的生成器,主要由编码器、转换器、解码器三部分组成。具体网络结构如图3 所示。
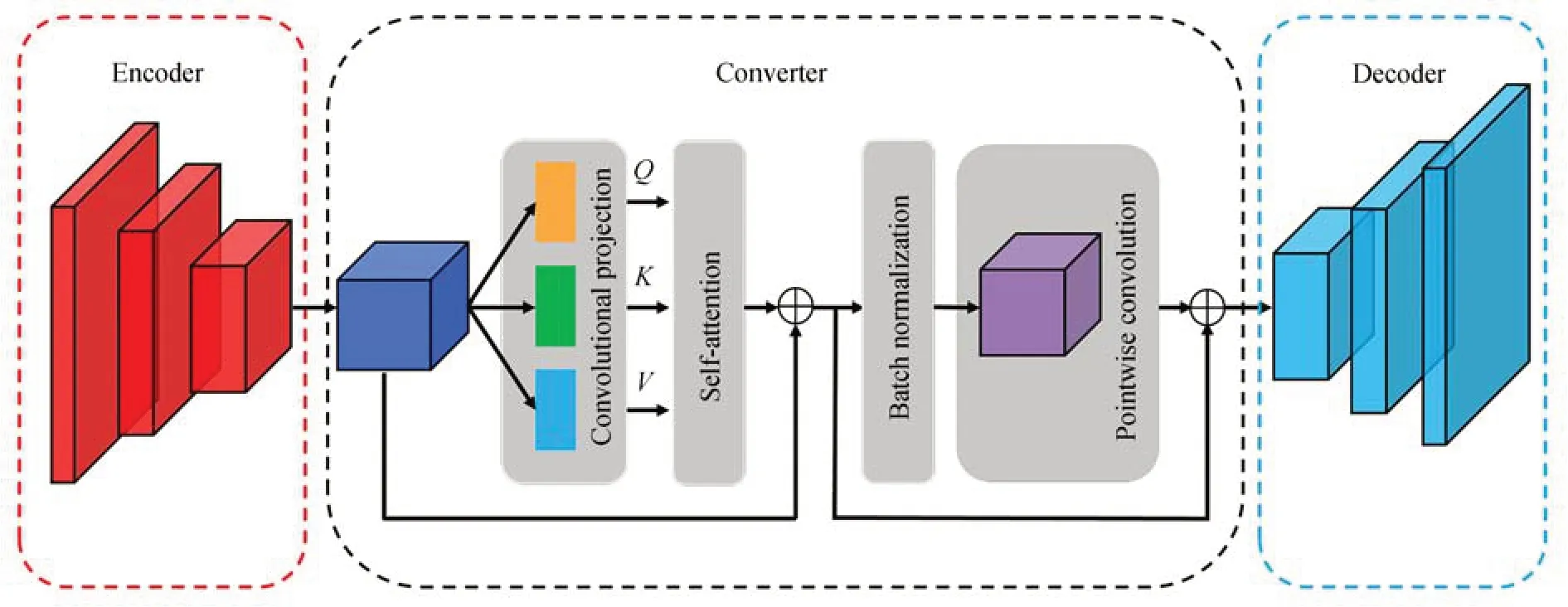
图3 生成器网络结构Fig.3 Network structure of generator
2.1.1编码器
编码器主要利用卷积神经网络对图像进行特征提取,便于之后的转换器进行相应的转换。第1个卷积层采用64 个尺度为7×7 的卷积核提取特征,并加入3 个像素的填充保留特征图的空间维度。接下来的两个卷积层分别由128 和256个卷积核组成,所有卷积核尺度为3×3,步幅设置为2,填充设置为1。每个卷积层后面还包括一个批量归一化层和Relu 激活函数。设T∈RH×W×C表示编码器输出的张量,则输入尺寸为256×256×3 的可见光图像,输出T的尺寸为64×64×256。
2.1.2转换器
转换器利用transformer 架构在潜在空间对深度特征进行解纠缠并重新组合,实现可见光到红外的风格转换。为方便后续的矩阵运算,首先使用卷积投影模块(conv_projection)将T映射为三组向量,这些向量称为查询向量Q、键向量K、值向量V。投影模块主要由深度可分离卷积[13]构成,其中特别的是生成Q的投影模块使用步幅为1 的深度卷积,其他投影模块的深度卷积步幅为2。设WQ,WK,WV分别为投影模块的训练参数,则三组向量的学习过程如式(2)所示:
其中:Depthwise(·) 表示深度可分离卷积,reshape(·) 表示矩 阵重组。向 量Q∈,K∈,V∈,sq=4 096,sk=sv=1 024,tq=tk=tv=256。
卷积投影模块之后设置了一个自注意力模块(Self-Attention)。在此模块中,查询向量Q、键向量K通过矩阵运算对全局特征进行解纠缠,并生成自注意力矩阵更新值向量V中的特征信息。此过程如式(3)所示:
其中:Θ∈R64×64×256,KT为键K的转置,softmax(·)表示归一化函数,reshape(·)表示矩阵重组。
与常规的transformer 架构不同,为进一步降低计算量,本文使用双层点卷积代替MLP 作为transformer 中的最后处理模块。转换器的最终输出如式(4)所示:
其中:Γconv256和Γconv512分别表示卷积核数量为256和512 的卷积层,ΓGELU表示高斯误差线性单元激活函数,ΓBN为批量归一化层。
2.1.3解码器
解码器的构成与编码器恰好相反,采用3层逐级连接的反卷积,将转换器输出的特征图逐级还原为红外图像,完成整个生成过程。编码器、转换器、解码器的结构参数详见表1。
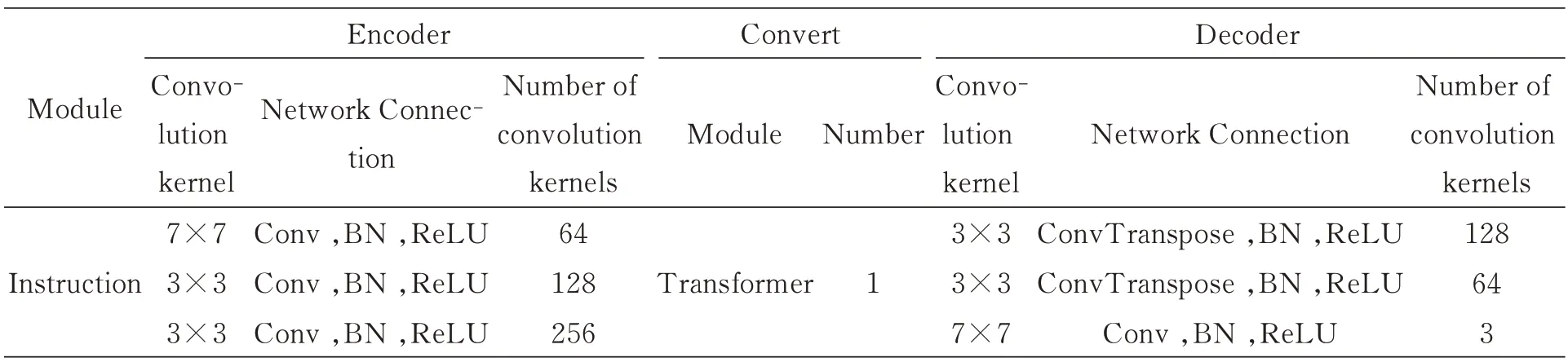
表1 生成器内部参数Tab.1 Generators internal parameters
2.2 判别器
在一般的生成对抗网络中,判别器通常由多个卷积层构成,最终输出一个介于0~1 之间的标量作为判定样本真伪的概率。这种判别方式针对整张图像进行加权得出结果,无法关注到图像的局部特征。由于可见光图像与红外图像模式差异大,此种判别方法精度要求过低无法实现高质量的图像生成。因此,本文使用70×70 的PathGAN[6]作 为VTIGAN 的判别 器,具体结 构如 图4 所 示,其输入 为256 pixel×256 pixel 的 图像,输出结果为30×30 的矩阵,每个矩阵元素代表输入图像中一个70×70 感受野的图像补丁为真的概率,最终以全部矩阵元素的均值判定整张图像的真假。这种补丁级判别器针对每一个图像补丁精准判别,重点关注了图像局部特征的提取和表征,更加适合可见光到红外这两种模式差异较大的图像转换。
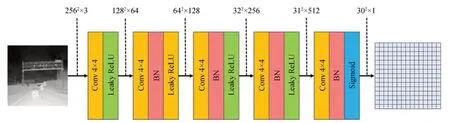
图4 判别器网络结构Fig.4 Network structure of discriminator
2.3 损失函数
2.3.1 对抗损失
在传统生成对抗网络中通常使用交叉熵损失函数,这会导致生成的图像虽然被判定为真实图像,但实际仍远离判别器的决策边界。由于此时交叉熵损失函数已经拟合,生成器不会继续进行优化,最终限制了生成的图像质量。通过理论分析和实际测试发现最小二乘损失函数可以对判定为真实样本的图像进行惩罚,使距离决策边界较远的样本不断靠近决策边界,从而进一步提高图像转换的效果。因此,VTIGAN 选择最小二乘损失函数构建对抗损失,其表达形式如式(5)~式(7)所示:
其中:y为真实红外图像为生成红外图像,)表示计算期望,D Y(·)表示判别器判定图像为真的概率。
2.3.2 多层对比损失
图像转换过程中,要求输入图像和输出图像在对应空间位置上应具有相似的语义信息。因此VTIGAN 引入多层对比损失最大化输入和输出图像对应位置间的互信息。通过将可见光和红外图像对应位置互信息的最大化,可以监督生成网络提取两个对应位置的共性部分(图像转换时应该被保留的内容),同时忽略其他位置上的特征对图像转换的影响,具体实现如下。
多层对比损失的目的是关联查询样本和所对应的正样本,并排除数据中的其他负样本。如图2 所示(彩图见期刊电子版),设定查询样本为生成的红外图像中随机选取的绿色图像框,正样本则为可见光图像中相同位置所对应的蓝色图像框,而可见光图像中除正样本位置外随机位置选取的紫色图像框均为负样本。首先将查询样本、正样本和N 个负样本映射为P维向量,分别表示为q∈RP,ν-∈RN×P,ν+∈RP,接着对P维向量进行L2 正则化,此时可构建一个(N+1)类的分类问题,并计算排除负样本选出正样本的概率。在数学上可使用交叉熵损失[13]表示为:
其中,δ为查询样本和其他样本间的距离缩放因子。
VTIGAN 使用Genc和双层MLP 的组合分别对可见光和红外图像进行特征提取,同时为了更加精确的进行特征表示,可见光和红外图像的特征提取网络之间并不共享权重。以可见光图像为例,选取Genc(x)中的L 层传递到MLP 中,将其投影为特征集合,如式(9)所示:
由上述公式可得到最终输入与输出图像间的多层对比损失,如式(11)所示:
2.3.3 风格相似性损失
在红外图像数据集Y={y∈γ}中,不同红外图像虽然语义内容各不相同,但具有相似的红外风格特征。为了提高生成红外图像的真实性,VTIGAN 使用风格相似性损失充分挖掘生成图像和真实样本之间的联系,最大程度上实现红外风格特征的转换。如图1 所示,在网络中首先使用编码器Genc和双层MLP 将生成的红外图像和真实红外图像转换为两组特征集合,接着利用两个轻量的特征映射网络{Hf,Hr}将特征集合映射为64 维的风格特征向量,此时利用风格相似性损失度量二者之间距离,其形式化表达如式(12)所示:
通过在深层信息上约束生成图像和真实图像间风格特征的相似,可以促使生成红外图像更加真实,而不是简单的色彩叠加。
2.3.4 同一性损失
生成器以可见光图像作为输入,可以实现可见光图像到红外图像的映射,然而若将红外图像作为输入,理想的生成器将不进行任何更改而直接输出原始图像。这种以红外图像直接作为输入,得到的输出图像与输入图像之间的L1 损失被定义为同一性损失。其表达式如式(13)所示:
同一性损失的加入可以在训练过程中纠正生成器的偏差,激励生成器生成更加真实的红外图像的特征。
2.3.5 总损失函数
上述各种损失函数都会对红外仿真图像生成效果产生影响,将各项损失进行加权,最终构成VTIGAN 的整体损失函数,如式(14)所示:
其中,λ是调整各项损失函数在训练中占比的权值。
3 实验结果与分析
3.1 准备工作
本文算法的有效性检验在Pytorch 深度学习开发框架下进行,硬件平台配置如表2 所示。
3.1.1 数据集制备
本文使用的数据集为艾睿光电红外开源平台提供的可见光-红外数据集。该数据集内容丰富,包含了车辆、建筑、植物等多种物体的可见光和红外图像,图像尺寸均为256 pixel×256 pixel。为充分验证算法的有效性,本实验将该数据集划分为交通场景和建筑场景两大类,其中交通场景主要包含车辆和公路的可见光与红外图像,建筑场景主要包含水泥建筑、树木、草坪等物体。两类场景中均含有5 000 组图像作为实验样本,其中训练集包含可见光和红外图像各4 500 张,且训练过程中图像均采用随机输入的方式,确保在非成对训练样本条件下进行训练。测试集则包含500 组配对的可见光和红外图像,其中500 张可见光图像作为测试样本,而与之对应的500 张红外图像作为参考样本对生成红外图像进行定量评价。
3.1.2 评价指标选取
为比较不同算法的图像迁移效果,本文使用全参考评价方法定量分析生成红外图像质量,主要选取以下三个指标:峰值信噪比(Peak Signalto-Noise Ratio,PSNR)、结构相似度(Structure Similarity Index Measure,SSIM)和Frechét inception distance(FID)。
PSNR[15]作为使用最广泛的全参考评价指标之一,在图像压缩、超分辨率重建等领域发挥了重要作用。PSNR 基于对应像素点间的均方误差衡量生成图像与参考图像之间的差异,其值越大代表生成图像失真越小,即生成图像的质量越高。PSNR 的形式化表达如式(15)所示:
其中:MSE表示参考图像和生成图像之间的均方误差,MAXI为图像中的最大像素值。
SSIM[16]用于计算生成图像与参考图像之间的相似性,取值范围在0~1 之间,值越大图像相似性越高。SSIM 用均值作为亮度的估计,标准差作为对比度的估计,协方差作为结构相似程度的度量,更加符合人类视觉提取图像结构信息的方式。假设参考图像和生成图像分别为x和y,其结构相似性定义如下:
其中:l(x,y),c(x,y),s(x,y)分别x和y的亮度比较、对比度比较以及结构比较,μx和μy分别为x和y的均值,σx和σy分别为x和y的标准差,σxy表示x和y的协方差,C1,C2,C3,α,β,γ均为常数。
FID[17]通过Inception 模型度量生成图像与参考图像在深度特征空间中的距离,具有较好的鲁棒性,其分数越低,说明生成图像的质量越高且多样性丰富。FID 的形式化表达如式(18)所示:
其中:μr,μg分别为参考图像和生成图像的特征的均值,Σr,Σg分别为参考图像和生成图像的特征的协方差矩阵,Tr表示求矩阵对角线元素和的运算。
3.1.3 实验参数设置
使用动量为0.5 的自适应矩估计优化器(Adam)[18]对训练过程中神经网络损失进行优化,初始网络参数随机选自均值为0,方差为0.02的高斯分布。经调试后,实验具体参数设置如表3 所示。
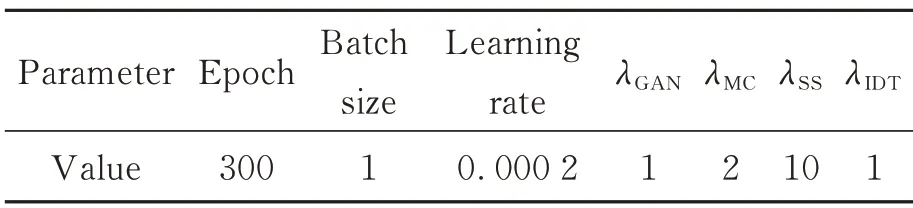
表3 实验参数设置Tab.3 Setting of experimental parameters
3.2 实验结果分析
为了验证VTIGAN 算法在可见光到红外图像迁移任务上的优良性能,本文将其与其他图像迁移算法进行了对比实验分析。主要对比网络包含CycleGAN,DSMAP(Domain-Specific Mappings)[19],UGATIT(Unsupervised Generative Attentional networks)[20],GLANet(Global and Local Alignment Networks)[21],CUT(Contrastive Learning for Unpaired Image-to-Image Translation)[22]。为了充分对比不同算法之间的性能差异,本文从客观定量分析和主观视觉评价两方面对图像风格迁移结果进行了评价。
3.2.1 客观定量分析
使用PSNR,SSIM 和FID 三个指标对各模型的测试结果进行定量分析,对比结果如表4所示。
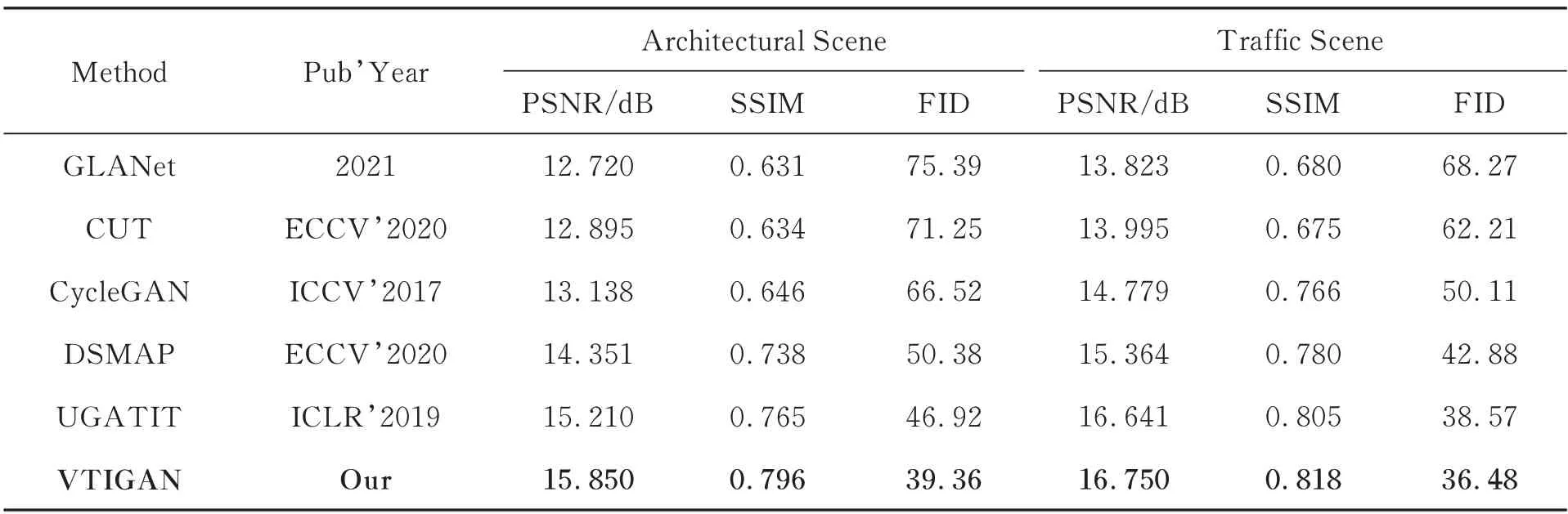
表4 图像评价指标对比Tab.4 Comparison of image evaluation indexes
从不同方法的实验结果来看VTIGAN 在三项指标的评价结果上达到了最优,相比于Cycle-GAN 在PSNR,SSIM 和FID 三个指标上分别提升了16.8%,14.3%和35.0%,相比于排名第二的方法UGATIT 在PSNR、SSIM 和FID 三个指标上分别提升了3.1%,2.8%和11.3%。从两组不同场景实验的评价结果对比来看,由于交通场景相比于建筑场景复杂程度略低,因此在交通场景上的图像生成结果均优于建筑场景。但场景复杂度对不同方法的影响程度并不相同,从表4 中数据分析可以看出,VTIGAN 从交通场景到建筑场景三项图像评价指标下降幅度分别为5.3%,2.7%和7.9%,指标下降幅度最小。而CycleGAN 的表现受场景复杂度的影响最大,在PSNR,SSIM 和FID 三个指标上分别下降了11.1%,15.7% 和32.7%。从定量评价结果来看本文提出的VTIGAN 针对可见光图像到红外图像的迁移取得了最优的表现,且该方法具有较好的鲁棒性,对于复杂场景下的抗干扰能力更强。
3.2.2 主观视觉评价
为了更加直观比较各模型在可见光图像到红外图像迁移任务上的性能差异,本节选取了水泥建筑、树木、草坪、工地、交通车辆五类主要实例的红外图像生成结果直接进行比对,各方法具体实验结果示例如图5 所示。

图5 实验结果示例Fig.5 Example of experimental results
图5 中第一列为测试时输入的可见光图像,第二列为真实的红外参考样本,后面依次排列的是不同方法的测试结果。从五类实例的生成效果来看,GLANet,CUT,CycleGAN 三种方法对于5 类实例的红外特征生成均有明显的错误,例如水泥建筑的结果对比中CycleGAN 未能正确生成楼房的红外特征,GLANet 和CUT 对于车辆的红外信息均生成错误。而DSMAP,UGATIT,VTIGAN 三种方法对于红外特征均能正确的生成,但从图像的逼真程度和清晰度来看VTIGAN 优于DSMAP 和UGATIT。这些方法对于红外图像仿真均有一定的应用价值,但也存在一些共性的不足,从图5 中可以看出交通车辆的红外图像中远处行驶的两辆车,由于目标较小,六种方法均未正确生成其红外特征,甚至直接造成了信息的缺失。总之,从主观评价上来看,本文提出的VTIGAN 相比于其他方法生成图像的红外特征精确且清晰度和逼真度更优。
3.3 消融实验
本文联合对抗损失、多层对比损失、风格相似性损失、同一性损失四种损失函数对网络模型进行训练。为验证各个损失函数的有效性,本节采取消融实验的方法测试多层对比损失、风格相似性损失、同一性损失对算法性能的影响。实验结果如表5 所示,在本实验中依次去除多层对比损失、风格相似性损失、同一性损失,并保留其他损失函数不变,从实验结果可知去除任意一项损失函数均导致算法性能的下降。其中,多层对比损失和风格相似损失作为图像迁移过程中的主要约束,去除后导致算法性能大幅下降,进一步验证了本文算法的有效性。
4 结论
可见光图像迁移生成红外图像具有重要的理论研究意义和实际应用价值。本文针对非成对数据条件下可见光图像迁移生成红外图像的任务要求,提出了一种新颖的红外图像仿真算法VTIGAN。VTIGAN 以特征提取能力强大的transformer 架构为基础构建了一种新的生成器,使用PathGAN 作为判别器对生成图像进行更精细化的鉴别,并联合对抗损失、多层对比损失、风格相似性损失、同一性损失四种损失函数对模型的训练加以约束,确保红外图像高质量的生成。在可见光-红外数据集上进行实验,与目前主流的图像迁移算法相比VTIGAN 在客观定量分析和主观视觉评价两方面均取得明显优势,对于复杂场景下的抗干扰能力优于基于循环一致性损失函数的方法,相比于CycleGAN 在PSNR,SSIM 和FID 三个指标上分别提升了20.6%,23.2%和40.8%,能够生成清晰度更高、红外特征更准确的红外仿真图像。在下一步的研究中将关注以下两方面:(1)现有算法对于图像中的小目标转换效果不佳,下一步研究可加强模型对小目标红外特征转换的能力,以进一步提高红外仿真图像的使用价值;(2)可见光-红外数据集的种类和数量仍然较少,下一步可从大型数据集制备的角度来提高模型性能。
猜你喜欢
环球时报(2022-05-23)2022-05-23 11:28:37
江西教育·职教版(2022年9期)2022-04-29 00:44:03
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
数学小灵通·3-4年级(2021年5期)2021-07-16 07:46:32
金桥(2021年4期)2021-05-21 08:19:20
电子制作(2019年11期)2019-07-04 00:34:38
电子制作(2019年7期)2019-04-25 13:17:14
今日农业(2019年15期)2019-01-03 12:11:33
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
光学精密工程(2016年3期)2016-11-07 09:03:43
