
基于CNN-Bi-LSTM模型的煤含水率预测研究
2024-01-04 11:58:02刘冠佑
中国煤炭 2023年12期
刘 强,李 娜,张 淼,李 昊,刘冠佑,张 帆
(1.国家能源投资集团神华黄骅港务有限责任公司,河北省沧州市,061000;2.中国矿业大学〈北京〉人工智能学院,北京市海淀区,100083)
0 引言
2023年8月,国家发展改革委等部门发布了关于印发《绿色低碳先进技术示范工程实施方案》的通知,对实施新发展阶段的生态建设提出了新要求,作为我国最重要的化石能源之一,煤炭的清洁利用一直是一个热点问题[1]。在煤炭的开采、运输、储存中,水资源的利用对降低煤炭扬尘起着重要的作用[2]。如何做到煤炭堆场含水率的动态检测,对合理利用水资源、降低煤炭堆场及周边污染有着重要意义[3]。
煤炭水分监测技术主要采用微波技术、核磁共振等非接触式检测技术[4]。王玉曼[5]利用最小二乘支持向量机算法对微波透射煤炭含水率检测方法进行了修正,进一步提高了检测精度,近年来深度学习在诸多领域都得到了广泛应用[6-7],在水分动态预测方面,深度学习方法多应用于土壤、作物、木材等研究对象[8]。另据研究表明,含水率在时间维度上是一个动态的连续过程,相邻时刻的含水率存在着相互影响,而煤炭露天堆场含水率的变化机理与土壤等物质相似,易受到温度和湿度等气象因素的影响,在变化趋势上表现出动态连续性[9]。因此,通过获取大量的煤炭含水率和气象的时间序列数据,可以建立数据驱动的煤炭含水率预测模型。
笔者在露天堆场储运煤含水率监测研究的基础上,提出了一种新的基于CNN-Bi-LSTM混合网络的煤炭含水率预测模型[10]。该模型将基于残差机制的一维CNN(卷积神经网络)与基于注意力机制的双向LSTM(长短期神经网络)网络(Bi-LSTM)相结合,融合了CNN的特征提取能力和Bi-LSTM的时间序列特征记忆能力,通过特定区域气象等多源数据融合分析实现对露天堆场煤炭的含水率趋势预测,并通过对模型训练使其学习到气象数据对煤炭含水率的影响,以实现对未来时刻煤炭含水率的动态预测[11-12]。
1 模型构建
为了使网络模型能够正确理解序列数据并提取其关键特征,需要构建由气象特征、煤炭含水率特征和时间特征这3部分组成的时间序列数据,并基于CNN的数据特征提取能力和LSTM的上下文关联能力[13],提出并建立了CNN-Bi-LSTM混合网络结构模型。该模型由残差机制的一维CNN网络、Bi-LSTM网络以及注意力结构融合构成,由CNN网络提取数据集关键特征并整理成序列交由Bi-LSTM网络进行学习,注意力机制对学习结果进行附加的权重分配,以使预测输出尽可能地接近观测值,CNN-Bi-LSTM混合模型的网络结构如图1所示。

1、2-恒等映射;3-Bi-LSTM层;4-注意力层;5-输出层;6、7-一维残差映射。图1 CNN-Bi-LSTM混合模型的网络结构
基于残差机制的CNN网络结构,通过残差网络在不同卷积层之间加入恒等映射,利用基本残差块实现残差网络的聚合与收敛,使CNN网络中的数据可以跨层流动以克服过度拟合问题,残差块的输出见式(1):
xl+1=xl+F(xl,{Wl})
(1)
式中:xl+1——残差块的输出;
xl——直接映射部分;
F(xl,{Wl})——要学习的残差映射部分。

ht=ot×tanh(ct)
(2)
式中:ht——LSTM输出值;
ot——输出门输出;
ct——新的记忆细胞。
其中,当前单元状态见式(3):
(3)
式中:ft——遗忘门的概率向量;
ct-1——前置记忆细胞;
it——遗忘门的概率向量;

其中,遗忘门的输出见式(4):
ft=sigmoid(Wxfxt+Whfht-1+bf)
(4)
式中:Wxf——遗忘门赋予xt的权重;
Whf——遗忘门赋予ht-1的权重;
xt——当前时间节点的输入;
ht-1——上一个时间节点的输出;
bf——遗忘门的偏置。
最后,注意力机制对LSTM单元的输出[h1,h2,…,ht,…,ht]赋不同的权重,使该模型能够对序列中的不同时间步长给予不同程度的关注,从而对当前任务目标选择更关键的预测信息。
训练过程以最小化重建误差为网络参数优化目标,重建误差的目标损失函数见式(5):
(5)
式中 :Loss——目标损失函数;
y——实际的含水率。

N——数据量。
2 实验验证
2.1 实验环境及模型参数
为了验证所提方法的有效性和可靠性,实验采用戴尔Precision 7920工作站平台,GPU型号是Nvidia Quadro RTX4000,核心处理器型号为Intel Xeon 4210R×2,处理器主频2.4 GHz,本地盘存储大小1 TB,内存64 GB,网络带宽是1 Gbps。网络模型的训练使用Facebook深度学习框架pytorch,编程语言采用python3.7,以及基于多GPU并行训练实现完成。
CNN-Bi-LSTM混合模型的参数设置:卷积层尺寸为3;卷积层和池化层激活函数选择ReLU激活函数;LSTM隐含层2层,激活函数选择tanh;Dropout为0.3;时间步长为5,批大小为2,初始学习率为0.01;优化函数为Adam,损失函数为MSE Loss,训练量为10 000。
根据CNN-Bi-LSTM混合模型的参数设置,实验中对规范模型的构造如下:输入训练集数据为三维数据向量(2,5,5),其中第2维度5为时间步长大小,第3维度5为输入维度的5个特征。首先,数据进入带残差结构的一维卷积层提取特征,得到三维输出向量(2,5,128),其中128为输出通道数;接着,该向量进入最大池化层,池化层不改变向量尺寸,得到三维输出向量(2,5,128);然后,输出向量进入带注意机制的Bi-LSTM层进行训练,得到二维输出向量(2,32),其中32为正向和逆向2层LSTM拼接的大小;最后,进入全连接层得到输出值,并在LSTM层加入Dropout以防止过拟合。训练共进行10 000个Epochs,每2 500个Epochs学习率衰减为原来的0.1倍。
2.2 数据获取及预处理
煤炭堆场洒水作业实验采集了我国河北黄骅港煤炭转运港口煤炭堆存场2020年6~12月和2021年1~4月的煤炭每小时采样的含水率数据和采样时刻的气象数据,每天对煤炭堆垛进行多次人工采样,每隔1 h采样1次,每次采样3组。将采集的煤炭采用烘干法获取含水率后取3组样本的平均值作为该时刻含水率。气象数据取自堆场内部分布的距离采样堆垛最近的气象监测站,每条气象数据包含温度、湿度、气压、风速4项特征。
在获取到足量数据后,将含水率数据和气象数据按时间一致性进行整合,并剔除了受降水、作业等自然或人为因素影响而产生的异常数据,保留了4 350条有效数据。为便于模型读取,利用滑动窗口的方法对有效数据进行序列划分,共产生2 004个长度为5的序列。样本数据包含温度、空气湿度、气压、风速、上一时刻含水率5项特征,以当前时刻含水率作为标签。其中,上一时刻含水率即为烘干法获得的相邻前一采样点的煤炭含水率值。最后,将全部序列按照5∶1的比例交叉划分训练集和测试集,全年数据中的部分训练数据集见表1。
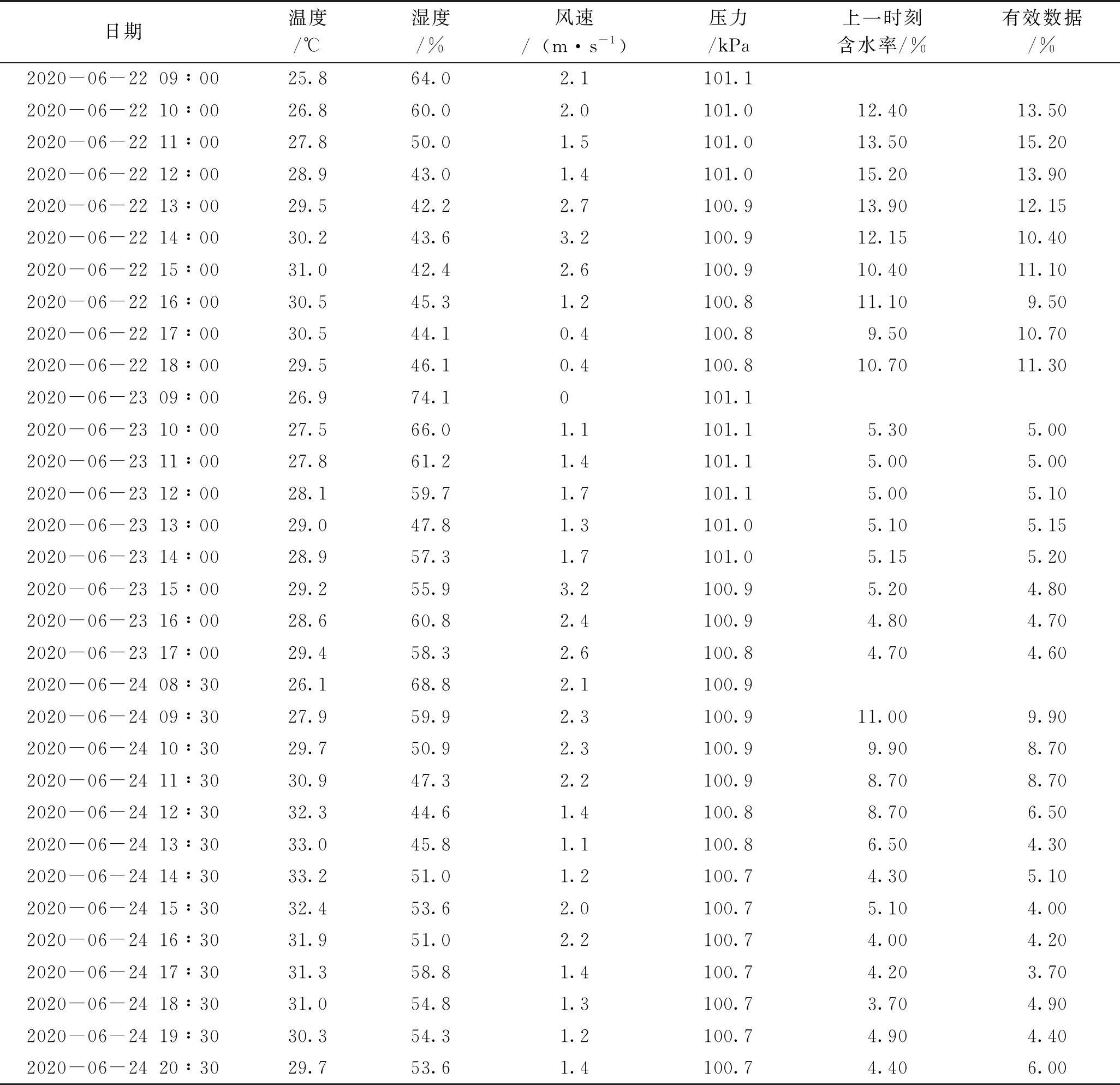
表1 全年数据中的部分训练数据集
全年数据集中各变量的统计分析结果见表2。

表2 全年数据集中各变量的统计分析结果
由于数据采集的季节不同,气象数据的变化,尤其是温度和湿度的变化范围较大,而煤炭含水率观测值在0.9%~27%时出现了小范围的波动,因此增加了精准预测的难度。
2.3 评价指标
为了验证和评估模型的有效性和性能,本文重点考察了以下5个评价指标。
(1)均方误差,见式(6):
(6)
(2)均方根误差,见式(7):
(7)
(3)平均绝对值误差,见式(8):
(8)
(4)拟合优度,见式(9):
(9)
(5)绝对百分比误差,见式(10):
(10)
式中:N——测试集样本数量;
yPred——预测值;
y——真实值;

上述指标中,R2方法数值越接近1,模型的判别度越好。MAE、RMSE、MAE和MAPE的值越接近0,预测精度越高。
3 结果与讨论
为了进一步考察所提出CNN-Bi-LSTM混合模型的可靠性,选择了支持向量机(SVM)、循环神经网络(RNN)、长短时记忆网络(LSTM)、卷积神经网络(CNN)和笔者提出的CNN-Bi-LSTM模型进行对比分析,并采用相同的训练数据集和参数设置对各模型进行了训练。训练结束后,利用同一组测试数据集对模型进行测试,通过对未来1 h的预测值与观测值的比较,以评估各模型对煤炭含水率的预测精度[10]。CNN-Bi-LSTM混合模型与其他模型的预测精度比较见表3。

表3 CNN-Bi-LSTM混合模型与其他模型的预测精度比较
由表3可以看出,R2和MAE是表征模型性能的主要指标,其中R2反映了实验中回归预测模型整体的拟合度,用于检测各预测模型对样本含水率观测值的拟合程度;MAE反映了所有单个样本含水率观测值与算数平均值的偏差,用于直观反映实际含水率预测误差的大小[11]。相较于SVM、RNN、LSTM、CNN模型,笔者所构建的CNN-Bi-LSTM混合模型的R2和MAE分别为0.997 1和0.081 2,明显优于其他模型的性能指标,且其MSE、RMSE和MAPE指标性能仍优于其他模型,分别达到了0.052 8、0.229 9和1.611 7。
CNN-Bi-LSTM混合模型与其他模型的预测值和观测值比较如图2所示。


图2 CNN-Bi-LSTM混合模型与其他模型的预测值和观测值比较
由图2可以看出,随着模型复杂程度的提高,模型的拟合能力也有不同程度的提高。与SVM、RNN、LSTM和 CNN相比,CNN-Bi-LSTM混合模型的拟合效果明显好于上述其他模型,其兼顾CNN的特征提取能力和LSTM的序列预测能力在煤炭含水率预测任务中得到了充分体现。当气象参数骤变时会出现个别异常点现象,但各预测模型的适应性差别较明显,其中SVM泛化性最差,RNN、LSTM和CNN泛化性次之,而CNN-Bi-LSTM泛化性最好。
此外,为了分析比较SVM、RNN、LSTM、CNN和CNN-Bi-LSTM模型预测值的绝对误差情况,研究分析了以上5种模型的绝对误差分布,并对各模型的MAE分值在每个子图中进行标注。CNN-Bi-LSTM混合模型与其他模型绝对误差分析结果如图3所示。尽管大部分模型基本都能将绝对误差控制在[-2,2]范围内,但从表2可以看出,煤炭含水量的存在范围只有[0.9,27],标准差仅为4.57,相对而言,笔者提出的预测模型可以将大部分误差控制在[-0.5,0.5]范围,预测性能更加优越。
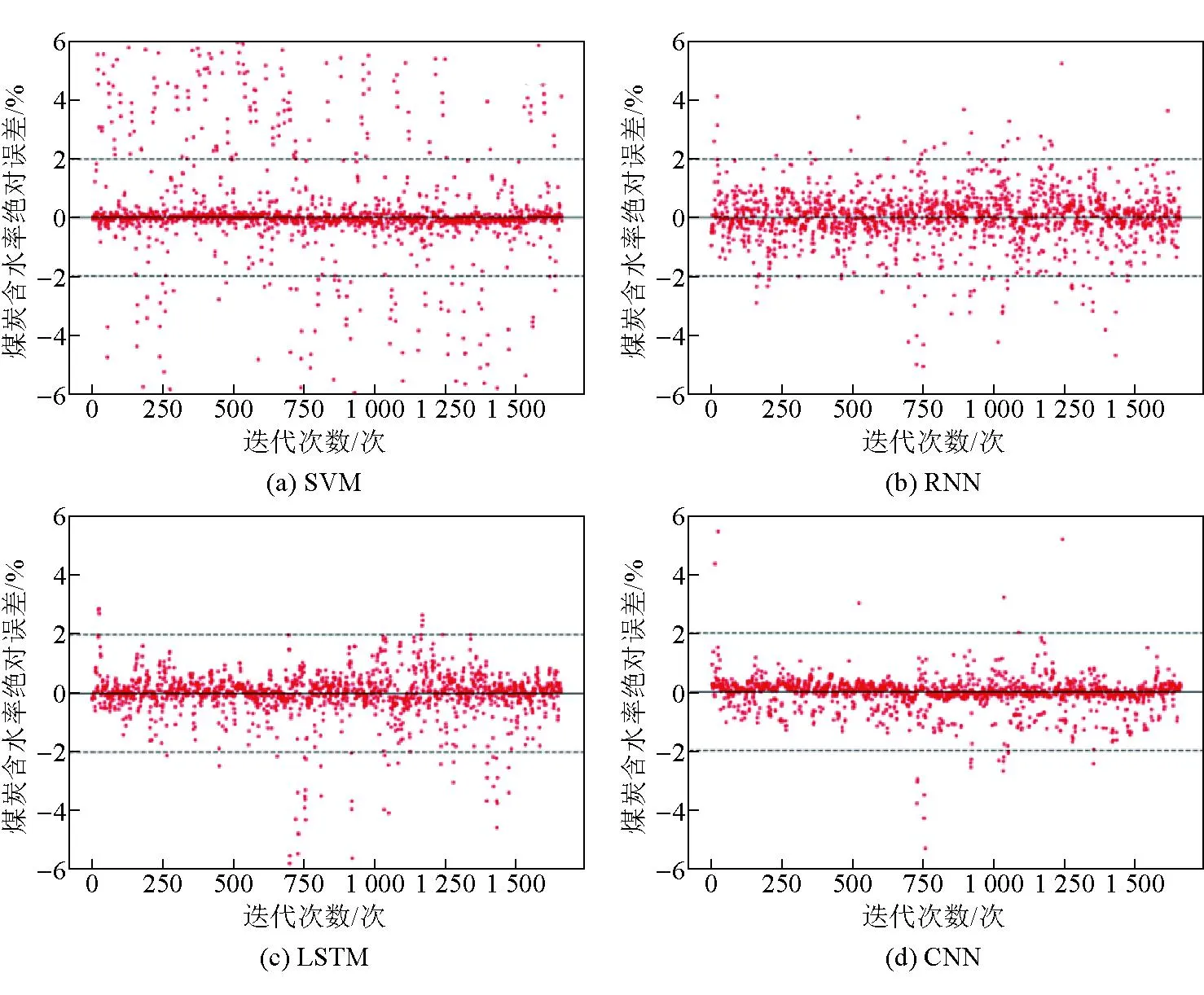
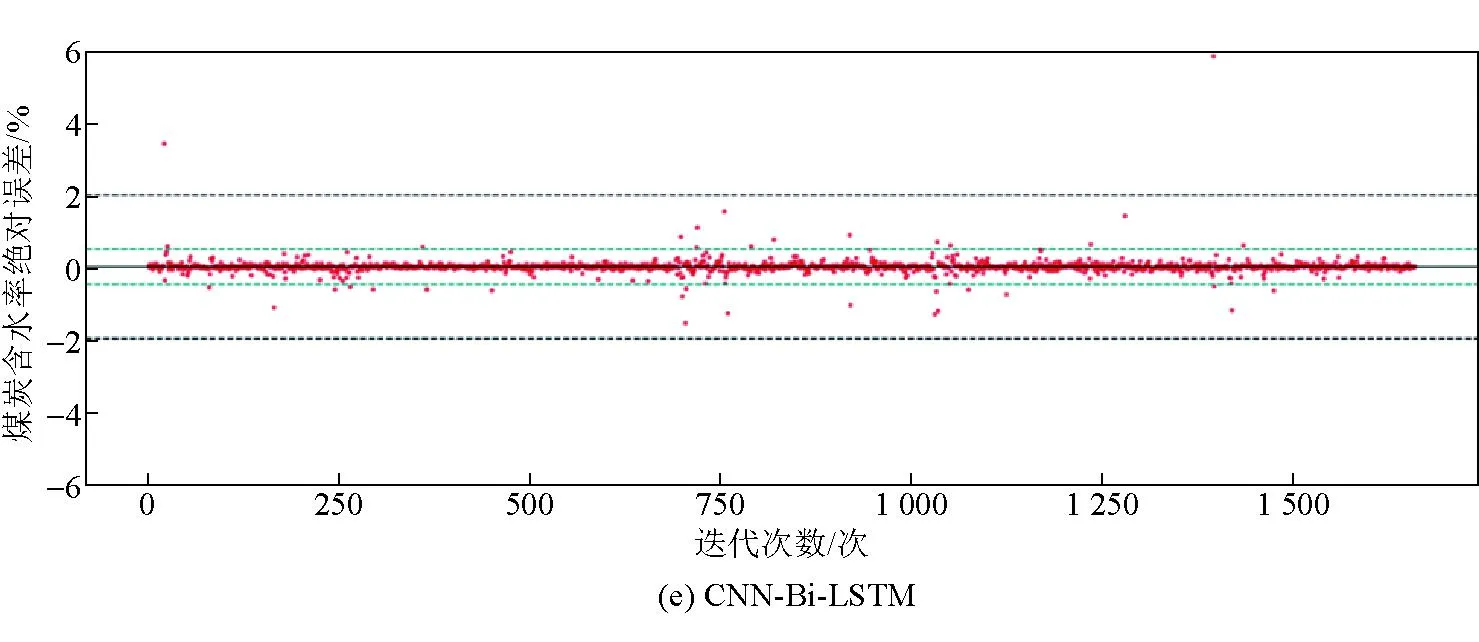
图3 CNN-Bi-LSTM混合模型与其他模型绝对误差分析
CNN-Bi-LSTM模型结构保证了神经网络能够正确理解序列数据并提取关键特征,同时在结构上抑制了过拟合问题,保证了网络对扰动的鲁棒性。
将此模型用于实际生产后,洒水频率由之前的5~6次/d,降低到2~3次/d;每次洒水量从每次固定60 s,变为根据实时预测含水率来控制洒水时长;通过对每个煤种进行单独预测,对各煤种不同环境下的含水率下降因素进行获取,预测后按需洒水,提高洒水量精确度。通过本模型预测的洒水量需求为备水、调水提供依据,能够实现调水、备水一体化管控和联动。
4 结论
(1)提出一种用于预测煤炭含水率的CNN-Bi-LSTM混合模型结构。该模型将残差结构的一维CNN和基于注意力机制的Bi-LSTM相结合,融合CNN特征提取能力和Bi-LSTM的时间序列特征记忆能力,以CNN提取的样本特征作为LSTM的输入序列,训练得到最终的预测结果。
(2)实验结果表明,提出的CNN-Bi-LSTM混合模型在预测精度和收敛率上均优于常见的回归预测模型,所有评估指标得分均优于其他模型,在煤炭堆垛表层煤炭含水率预测方面取得了优异的性能,预测模型具有泛化能力强、收敛速度快、寻优精度高的特点。
(3)所提出的煤炭堆垛含水率预测方法,对优化储运煤管控决策、实现储运煤智能化发展提供重要的理论参考。在保证模型预测精准度的前提下,解决了传统监测模式存在含水率获取时间长、检测精度低和难以动态监测等3个典型问题。
(4)使用基于笔者提出的含水率预测方法建立的洒水管控模型后,煤炭堆场降低了用水量,提升了港口经济效益,减少了煤炭堆场起尘概率,环境状况得到了改善。
猜你喜欢
公路与汽运(2024年1期)2024-03-07 03:02:06
河南科技(2023年1期)2023-02-11 12:17:04
林业机械与木工设备(2022年5期)2022-05-27 09:28:56
网络安全与数据管理(2022年3期)2022-05-23 13:26:48
Chinese Physics B(2022年5期)2022-05-16 07:10:38
中国粉体技术(2021年1期)2021-01-04 02:19:18
北京航空航天大学学报(2020年10期)2020-11-14 09:26:02
黑龙江交通科技(2020年5期)2020-01-13 18:01:35
自动化学报(2019年6期)2019-07-23 01:18:32
长江科学院院报(2018年12期)2018-12-19 09:52:02
