
Infrared-PV:面向监控应用的红外目标检测数据集
2024-01-03 07:21:58彭冬亮
红外技术 2023年12期
陈 旭,吴 蔚,彭冬亮,谷 雨
〈图像处理与仿真〉
Infrared-PV:面向监控应用的红外目标检测数据集
陈 旭1,吴 蔚2,彭冬亮1,谷 雨1
(1. 杭州电子科技大学 自动化学院,浙江 杭州 310018;2. 中国电子科技集团第28研究所,江苏 南京 210007)
红外摄像机虽然能够全天候24h工作,但是相比于可见光摄像机,其获得的红外图像分辨率和信杂比低,目标纹理信息缺乏,因此足够的标记图像和进行模型优化设计对于提高基于深度学习的红外目标检测性能具有重要意义。为解决面向监控应用场景的红外目标检测数据集缺乏的问题,首先采用红外摄像机采集了不同极性的红外图像,基于自研图像标注软件实现了VOC格式的图像标注任务,构建了一个包含行人和车辆两类目标的红外图像数据集(Infrared-PV),并对数据集中的目标特性进行了统计分析。然后采用主流的基于深度学习的目标检测模型进行了模型训练与测试,定性和定量分析了YOLO系列和Faster R-CNN系列等模型对于该数据集的目标检测性能。构建的红外目标数据集共包含图像2138张,场景中目标包含白热、黑热和热力图3种模式。当采用各模型进行目标检测性能测试时,Cascade R-CNN模型性能最优,mAP0.5值达到了82.3%,YOLO v5系列模型能够兼顾实时性和检测精度的平衡,推理速度达到175.4帧/s的同时mAP0.5值仅降低2.7%。构建的红外目标检测数据集能够为基于深度学习的红外图像目标检测模型优化研究提供一定的数据支撑,同时也可以用于目标的红外特性分析。
红外图像;数据集;监控应用;深度学习;基准测试
0 引言
相比于可见光摄像机,红外摄像机能够全天时全天候工作,因此在城市交通、军事侦查、视频监控等领域有着广泛的应用[1-2]。
虽然红外图像的目标指示性较强,但受传感器探测性能、目标成像距离、目标几何形状等因素影响,红外图像通常分辨率低,缺乏丰富的边缘和纹理信息,在复杂背景下目标信杂比低[3],故早期的红外图像目标检测算法研究主要集中在弱小目标检测方面[4-5]。主要方法包括基于单帧图像的跟踪前检测方法(detecting before tracking, DBT)和基于序列图像的检测前跟踪方法(tracking before detecting, TBD)。DBT方法[6]主要利用单帧图像中目标-背景的差异信息进行去噪、增强等,通过分割得到目标位置,但是在低信杂比和复杂背景下虚警率较高。TBD方法利用运动目标连续性和相似性进行跟踪检测,可通过目标信息的长时间积累实现目标检测,但是在帧间差异较大时目标检测精度会下降,同时该类算法实时性较差[2]。
随着大数据和深度学习理论和技术的快速发展,基于深度卷积神经网络(convolution neural network, CNN)的目标检测模型在可见光图像目标检测与识别方面取得了远超传统方法的性能。典型的目标检测模型可分为两阶段模型和单阶段模型[7]。以Faster R-CNN[8]为代表的两阶段模型,首先通过区域建议网络筛选候选目标区域,然后在候选目标区域进行目标分类和位置精调。以SSD(single shot multibox detector)[9]和YOLO(You Only Look Once)系列[10]为代表的单阶段模型,根据输出的特征图进行回归,输出目标位置、置信度和类别等信息。虽然单阶段算法具有实时性好的优势,但检测精度比双阶段算法略低。
将深度学习算法和模型应用于红外图像目标检测时,王文秀等人[11]针对传统红外检测算法检测率低、实时性差等问题,采用改进的AlexNet[12]深度网络进行红外船只目标识别,可快速准确地识别出红外船只目标,但该方法并不是一种端到端的方法,需通过分水岭方法提取感兴趣船只区域。针对该问题,蒋志新[13]提出了一种基于改进损失函数的Faster R-CNN海上红外小目标检测方法,其是一种端到端的方法,通过样本分类的难易程度来调节权重,在加快模型训练收敛速度的同时提高了检测精度,但该方法实时性较差,不利于工程实际应用。针对红外目标检测准确率和实时性不足的问题,陈铁明等人[14]提出了一种基于改进YOLO v3的红外末制导目标检测方法。通过半实物仿真的方式获得特种车辆、舰船和飞行器3类目标的红外图像,在自适应学习率与动量法联合优化下,对设计的红外目标数据集进行验证,平均准确率达到了77.89%,检测速度达到25帧/s。针对红外弱小目标检测难题,赵琰等人[15]在对红外目标特性进行分析基础上,通过简化YOLO v3网络的处理流程,提升了对红外弱小目标检测精度,实验使用的数据为包含无人机的红外视频序列。吴双忱等人[16]将对小目标的检测问题转化为对小目标位置分布的分类问题,检测网络由全卷积网络和分类网络组成,其中分类网络通过引入注意力模块(squeeze-and-excitation networks, SENet)[17],致力于解决复杂背景下低信噪比和存在运动模糊的小目标检测难题,取得了较好的检测效果。李慕锴等人[18]将SENet模块引入到YOLOv3骨干网络中的残差模块,提高了骨干网络特征提取能力,实现了复杂场景下红外行人小目标的有效检测,相比原算法实时性不变,误检率显著减低。
基于数据驱动的深度学习方法很大程度上依赖于均衡完备的样本数据,目前公开的数据集以可见光图像为主,主要包括VOC(PASCAL visual object classes)数据集[19]、COCO(microsoft common objects in context)数据集[20]、DOTA(dataset for object detection in aerial images)数据集[21]、DIOR(object detection in optical remote sensing images)[22]、UCAS-AOD[23]等,针对不同数据集的特点均提出了很多有效的改进模型[24]。考虑到红外图像的特点,将应用于可见光图像领域的深度目标检测模型应用于红外图像时,需要做出合理的改进,但首先要解决的就是面向具体应用场景的红外数据集构建问题。
韩国科学技术研究院构建的多光谱行人数据集(KAIST)[25]每张图像包含可见光图像和红外图像两个版本,图像分辨率为640×480,分为person、people和cyclist三个类别,该数据集的主要问题是标签质量较低,需对数据进行重新标注。菲力尔(FLIR)红外数据集[26]图片分辨率为640×512,只包含水平视角下的街道和高速路场景,主要面向自动驾驶汽车应用。OTCBVS(object tracking and classification in and beyond the visible spectrum)红外数据集[27]用于测试和评估先进的计算机视觉算法,包含人脸、车辆、行人和舰船等14种不同场景的图像数据,该数据集中目标相对比较少,且场景较理想化。上述3个数据集的示例图像如图1所示。

图1 红外公开数据集样本示例
针对监控领域的实际应用需求,本文构建了一个包含行人和车辆的红外目标检测数据集,将其命名为Infrared-PV。该数据集包含十字路口、横向马路两大主场景,包含地铁口、广场、公交站台等不同背景区域。采集的红外图像类型包含白热目标、黑热目标和热力图3种模式,总计包含2138张图像,采用自研图像标注软件实现了VOC格式的标注任务。同时结合主流的深度目标检测模型给出了在该数据集上的检测性能测试基准。该数据集能够为面向监控应用的红外图像目标检测模型优化研究提供一定的数据支撑。
1 Infrared-PV数据集
1.1 数据集构建方式及目标统计信息
使用FLIR公司的Tau2 336长波非制冷红外机芯配备25mm镜头采集视频数据,对该机芯极性进行控制,包括黑热和白热两种模式,此外还提供热力图模式。采集高度30m左右,聚焦距离大于250m,拍摄扫描视角范围为0°~120°,分别在雨天、晴天、白天、夜晚等环境下采集多个场景的视频图像,然后通过3帧/s的下采样率得到分辨率为720×576或640×480的图像,构建的数据集总计包含图片2138张,主要考虑场景中的行人和车辆2类目标,故将该数据集命名为Infrared-PV。不同极性下的样本数量分布如表1所示,目标示例图像如图2所示。从图2可以看出,在不同极性下目标的显著性不同,在黑热极性下,行人和车辆的轮廓信息更加明显。从热力图模式看,行人、车辆目标的底部和发动机部分红外热辐射更高。

表1 Infrared-PV数据集不同极性图像统计

图2 不同极性目标图像
1.2 标注软件及标注信息
使用自研的图像标注软件对构建的Infrared-PV数据集进行人工标注,标注格式为扩展PASCAL VOC格式,保存本地文件为XML格式。设计的软件与Labelme软件类似,支持图片、视频和VOC格式数据集的标注,同时实现了对数据集的统计和数据增强功能,支持目标类别统计、长宽分布统计等,并可检测标注过程中可能存在的漏标、错标等情况。图3为设计的标注软件界面图,界面上侧为菜单栏,左侧为待标记图像列表,右侧为目标信息显示区域。与Labelme软件不同,研制的标注软件支持以下两方面功能:①通过修改配置文件支持额外语义信息的添加与保存。其中图3右下角区域为语义信息修改和显示区。某一幅图像对应的目标标注内容如表2所示,包括文件名、图像分辨率、目标位置和类别信息,以及拍摄日期(date)、拍摄时间(time)、相机极性(polarity)、天气信息(weather)等语义信息。②增量标注功能。在已获得少量标注样本的情况下,通过训练一个基于深度模型的目标检测器,辅助人工标注,降低标注工作量。为测试各检测模型的检测性能,本数据集对部分遮挡度小于50%的目标进行了标注。

图3 标注软件界面

表2 标注信息
1.3 目标特性统计分析
图4为数据集典型场景的示例图像。从图2和图4可以看出,黑热极性下行人目标的轮廓更加明显,此时目标对比度高于白热极性情况。热力图图像是场景中目标热辐射的伪彩色显示,在该模式下很难得到目标的轮廓信息。车辆目标包括小轿车、公交车、货车等几种车型,目标尺寸大于行人目标,虽然车辆目标的尺度变化较大,但由于与背景差异显著,故比较容易区分,部分遮挡和目标重叠问题是影响车辆目标检测精度的主要问题。由于是室外场景,数据集中的图像背景比较复杂,包括地铁出入口、交通指示杆和建筑物等其他目标,这会给目标检测算法和模型带来一定挑战,主要体现在虚警方面。
数据集中行人和车辆对应的类别分别为person和vehicle,在整个目标中的占比分别为60.3%和39.7%,如表3所示。平均单张图片包含20个左右目标,最多单张图片目标数超过100个,说明本红外数据集目标相对比较密集。从图5(a)和图5(b)目标尺寸和占比分布可以看出,目标主要分布在150×200大小范围内,其中person类别目标长宽分布在10×20像素~20×50像素不等,车辆分布在40×23像素~200×150像素不等,集中在整幅图像尺寸的10%以下,说明本红外数据集多以中小目标为主。从图4可以看出,目标相对比较密集,目标间、背景与目标间存在遮挡情况,因此可以用于评估各检测算法或模型的检测性能和适用性,为红外弱小目标检测、红外行人检测、车辆检测与跟踪等研究方向提供一定的数据支撑。Infrared-PV红外目标检测数据集的获取地址为https://pan.baidu.com/ s/1j0gqBrtTjI89s2Mdp6xpEA(提取码:4ftz)。

表3 Infrared-PV数据集类别统计

图4 Infrared-PV数据集图像
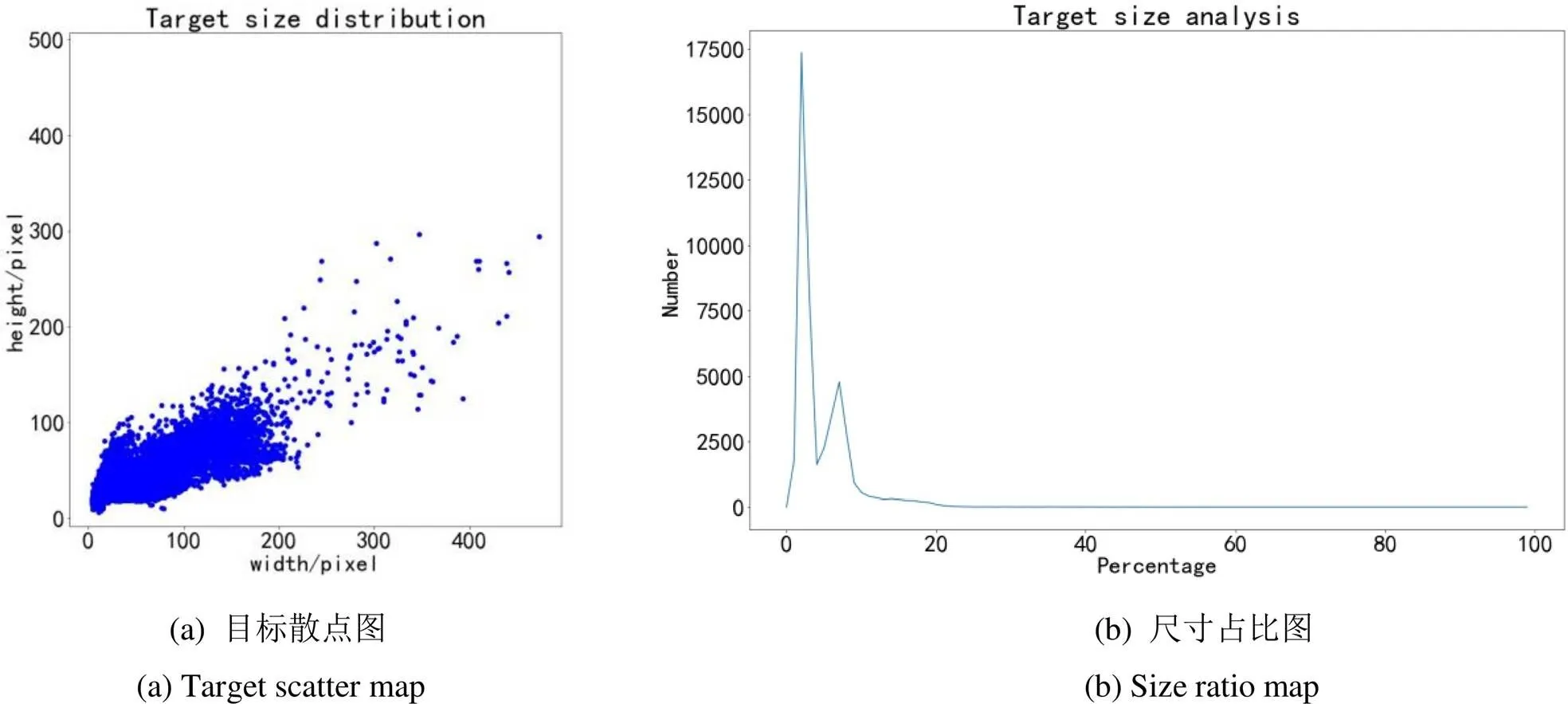
图5 目标统计分析
2 主流目标检测模型
2.1 两阶段目标检测模型
以Faster R-CNN为代表的两阶段模型主要由3部分组成,即特征提取网络、候选区域建议网络(region proposal network, RPN)网络和分类回归网络。特征提取网络避免了传统手工设计特征的局限性,能够学习到更有利于目标检测与分类的特征表示。候选区域建议网络用于判别目标和背景区域,这种端到端模型极大提高了目标检测的速度。分类回归网络对候选目标区域进行类别细分类和位置预测的精调。在Faster R-CNN基础上,研究学者提出了很多改进模型,包括Cascade R-CNN[28]、Libra R-CNN[29]、DoubleHead R-CNN[30]等,这些模型显著地提高了通用目标检测精度。
2.2 单阶段目标检测模型
舍弃RPN模块,直接对目标类型和位置进行回归的单阶段模型,能够实现检测精度和推理速度的平衡,逐渐成为研究的热点,其中最具代表性的模型为SSD、YOLO系列。其中YOLOv3[31]已被成功应用于红外目标检测,并取得不错的效果。YOLO v3是单阶段端到端全卷积网络,模型组成如下:以基于ResNet残差网络[32]的darknet53架构作为特征提取网络,拓展了网络的深度,降低了训练难度;采用类似特征金字塔网络(feature pyramid networks, FPN)[33]的思想,加强了高层语义信息对浅层细节特征的指导;多尺度输出层根据预设先验框对像素点进行回归、分类、后处理,提高了中小目标检测率。
基于注意力机制以及优化的特征融合策略,文献[34]提出了YOLO v4模型。v4版本相比于v3版本改进如下:
①特征提取网络设计方面,使用了加权残差连接、跨阶段局部网络(cross stages partial network, CSPNet),通过加强网络特征融合能力,设计了更优的特征提取网络CSPDarknet53;
②检测分支设计方面,使用了SPP[35]、FPN、PANet[36]等特征融合策略,通过融合不同尺度的语义信息,提高了中小目标的检测和分类性能;
③数据增强方面,综合使用了Cutmix & Mosaic数据增强、DropBlock正则化、类标签平滑、Ciou损失[37]、对抗训练等BoF & BoS(Bags of Freebies & Specials)手段,进一步提高了检测精度。
最新的YOLO v5网络根据网络深度和宽度不同,共包含s、m、l和x四种模型,其中s网络模型结构如图6所示。YOLO v5模型改进了特征提取网络和特征融合模块,用CSPNet模块代替多层混合卷积,显著降低模型复杂度,联合Mosaic数据增强、自适应图片缩放等手段,不仅保证了检测精度,还消除了模型冗余,大大提高了推理的实时性。其中使用GTX 1080Ti显卡的s模型推理时间低至2.5ms,在边缘设备上也有很好的检测效果。
3 实验结果分析
为评估基于深度学习的红外目标检测性能,本文在Infrared-PV数据集上进行了对比实验,构建了用于深度目标检测模型评估的指标,定性和定量分析了各模型在Infrared-PV红外数据集上的性能。
3.1 实验准备
采用的服务器配置如下:CPU为Intel(R) i7-6850K,64G内存,两块NVIDIA GeForce GTX 1080Ti图形处理器,操作系统为Ubuntu 18.04。所有模型使用双卡分布式训练。
Infrared-PV红外数据集以7:3比例随机划分,其中训练集共1496张图像,测试验证集642张图像。
3.2 检测模型及训练参数
本文使用的基准算法为Faster R-CNN,YOLO v3,YOLO v4,YOLO v5目标检测算法,此外还和Cascade R-CNN、FCOS[38]模型的检测性能进行了对比分析。训练采用的目标检测框架和配置文件如表4所示。当输入网络的图像分辨率为608×608时,YOLO系列各模型的锚框大小设置如表5所示。
YOLO v3和YOLO v4系列基于darknet的C语言官方实现,其中YOLO v3模型初始学习率为0.01,批大小为64,子批大小(subdivisions)由显存大小调整,训练总步长为12500,在步长为5000和10000时退火为前一步长的10%;YOLO v4模型初始学习率为0.00001,批大小为8,退火步长为18000和26000;其他为默认设置。

表4 模型配置
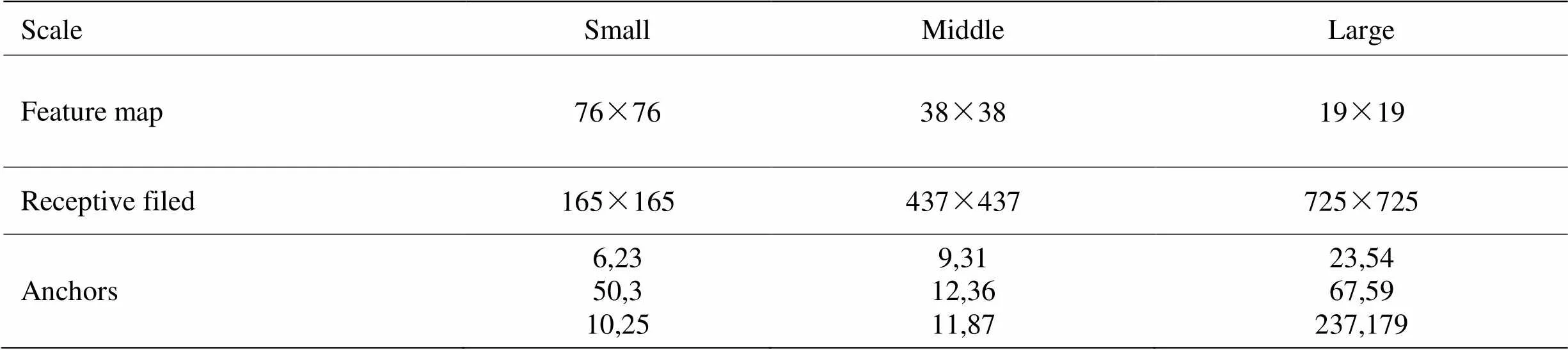
表5 608×608分辨率下Infrared-PV目标锚框
YOLO v5系列基于ultralytics的YOLO v5实现,训练轮次(epoch)为200,批大小为64;采用SGD梯度下降优化器,动量为0.9;初始学习率0.01,预热为3 epoch,采用余弦退火;其他为默认设置。
Faster R-CNN、FCOS、Cascade R-CNN算法基于mmdetection[39]实现。其中超参数设置如下:epoch为50,批大小为8;SGD优化器,动量为0.9;初始学习率为0.02,在epoch为25和38时退火为前一步长的33%;其他为默认设置。
3.3 结果分析
对检测结果进行分析,当目标检测结果与真值的交并比(intersection over union, IOU)大于0.5认为该目标被检测到,以单位时间推理图片张数(frame per second, FPS)评估模型实时性,以各类别的平均精度(average precision, AP)、召回率(recall)以及平均精度均值(mean average precision, mAP)来评估模型的检测性能。
在基准实验中,各模型的检测性能如表6所示,检测结果如图7所示。由于没有对Anchor进行优化,对行人等小目标检测效果不佳,故Faster R-CNN模型的mAP0.5只达到了65.6%,推理速度仅为16.08FPS;当模型输入尺寸为608×608时,YOLO v3模型的检测精度较416×416时提升5.8%。由图7(c)和(d)可见,网络输入尺寸的增加有利于小目标检测和位置框的精准回归,同时降低了虚警率,但实时性有所降低。YOLO v4模型的mAP0.5为78.97%,YOLO v5模型的mAP0.5最高,达到了80.7%。从图7对比看出,YOLO v4模型的召回率高于YOLO v5模型,但是虚警率略高。总体而言,一阶段算法对于遮挡和弱小目标情况检测率相对较高,虽然存在少量虚警,但能够满足检测算法的实时性需求。

图7 各基准模型检测效果对比(置信度:0.25)
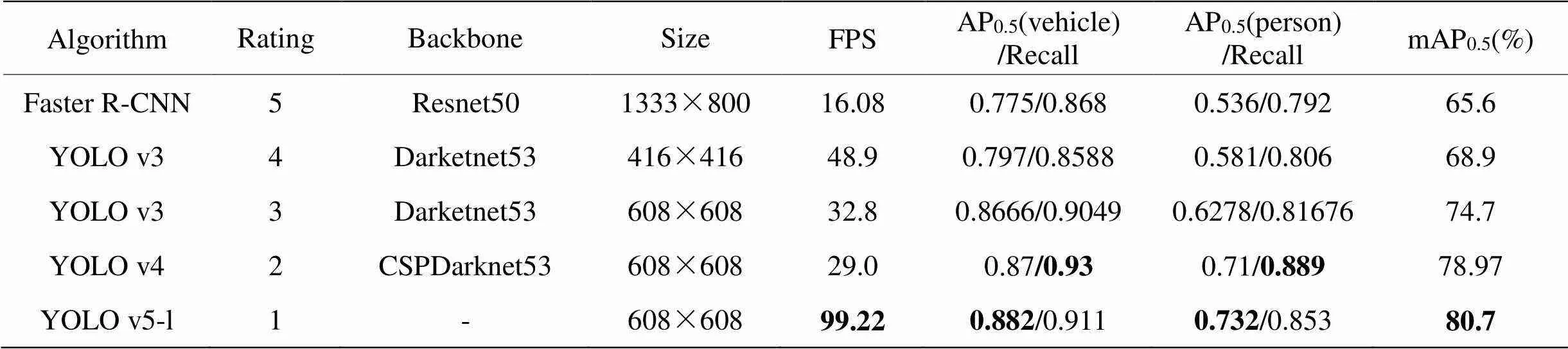
表6 Infrared-PV数据集各检测模型性能基准(置信度:0.05)
注:加粗字体为该列最优值 Note: Bold font is the optimal value
3.4 其他目标检测算法实验
除基准实验外,本文进行了扩充实验以验证其他模型在Infrared-PV数据集上的性能。本文使用先进的骨干网络ResNest[40]替换Faster R-CNN和Cascade R-CNN模型的主干网络,进行了对比实验。
各模型的检测指标结果具体如表7所示。由表7可以看出,采用ResNest的两阶段检测模型相比传统ResNet特征提取网络性能上有显著提升,Cascade R-CNN模型mAP0.5提升了15.3%,达到了最高的检测精度82.3%。由图7(b)可见,对于遮挡、小目标上的实际效果最佳,优于所有单阶段算法,但是该模型实时性较差;在YOLOv4的基础上裁剪模型为原大小的1/16,精度提高的同时实时性提高了一倍,说明针对特定数据集,尤其是目标类别较少的情况下,通过裁剪卷积通道数能够在不降低目标检测率的情况下,提高模型推理速度;FCOS模型对于红外目标检测结果差强人意,主要是因为红外图像纹理信息缺失,边缘信息不明显,像素框定位目标困难,故mAP0.5较低。
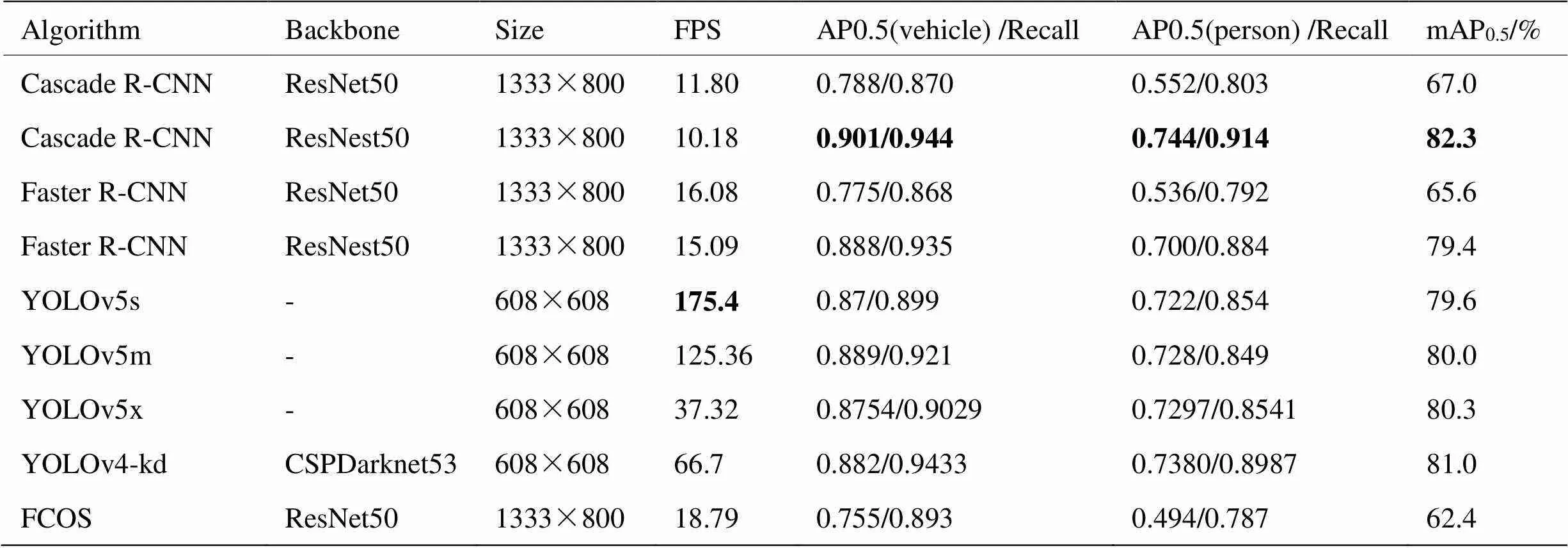
表7 其他模型在红外数据集的测试结果(置信度:0.05)
注:加粗字体为该列最优值 Note: Bold font is the optimal value
4 结论
本文构建了一个包含行人和车辆2类目标的红外图像检测数据集,对于采用的红外视频图像采用自研的标注软件进行了目标标注,然后对数据集的各项统计信息进行了总结分析。结合目前主流基于深度学习的目标检测模型,给出了各模型在该数据集的检测性能。该数据集的构建能够为视频监控场景下的红外目标检测,以及红外图像目标特性分析提供一定的数据支撑。
[1] 陈钱,隋修宝.红外图像处理理论与技术[M].北京:电子工业出版社, 2018.
CHEN Qian, SUI Xiubao.[M]. Beijing: Electronic Industry Press, 2018.
[2] 刘让, 王德江, 贾平, 等. 红外图像弱小目标探测技术综述[J]. 激光与光电子学进展, 2016,53(5): 050004.
LIU Rang, WANG Dejiang, JIA Ping, et al. Overview of detection technology for small and dim targets in infrared images[J]., 2016, 53(5): 050004.
[3] 武斌. 红外弱小目标检测技术研究[D]. 西安: 西安电子科技大学. 2009.
WU Bing. Research on Infrared Dim Target Detection Technology[D]. Xi'an: Xidian University, 2009.
[4] Rawat S S, Verma S K, Kumar Y. Review on recent development in infrared small target detection algorithms[J]., 2020, 167: 2496-2505.
[5] 李俊宏, 张萍, 王晓玮, 等. 红外弱小目标检测算法综述[J]. 中国图象图形学报, 2020, 25(9): 1739-1753.
LI Junhong, ZHANG Ping, WANG Xiaowei, et al. Infrared small-target detection algorithms: a survey[J]., 2020, 25(9): 1739-1753.
[6] 谷雨,刘俊,沈宏海, 等.基于改进多尺度分形特征的红外图像弱小目标检测[J]. 光学精密工程,2020,28(6):1375-1386.
GU Yu, LIU Jun, SHEN Honghai, et al. Infrared image dim target detection based on improved multi-scale fractal features[J].,2020,28(6): 1375-1386.
[7] LIU L, OUYANG W, WANG X G, et al. Deep learning for generic object detection: a survey[J]., 2020, 128(2): 261-318.
[8] REN S Q, HE K M, Girshick R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[J]., 2017, 39(6): 1137-1149.
[9] LIU W, Anguelov D, Erhan D, et al. Ssd: single shot multibox detector[C]//, 2016: 21-37.
[10] Redmon J, Divvala S, Girshick R, et al. You only look once: unified, real-time object detection[C]//, 2016: 779-788.
[11] 王文秀, 傅雨田, 董峰, 等. 基于深度卷积神经网络的红外船只目标检测方法[J]. 光学学报, 2018, 38(7): 0712006.
WANG W X, FU Y T, DONG F, et al. Infrared ship target detection method based on deep convolutional neural network[J]., 2018, 38(7): 0712006.
[12] Krizhevsky A, Sutskever I, Hinton G E. Imagenet classification with deep convolutional neural networks[J]., 2017, 60(6): 84-90.
[13] 蒋志新. 基于深度学习的海上红外小目标检测方法研究[D]. 大连: 大连海事大学, 2019.
JIANG Z X. Research on the Detection Method of Marine Infrared Small Target Based on Deep Learning[D]. Dalian: Dalian Maritime University, 2019.
[14] 陈铁明, 付光远, 李诗怡, 等. 基于YOLO v3的红外末制导典型目标检测[J]. 激光与光电子学进展, 2019, 56(16): 155-162.
CHEN T M, FU G Y, LI S Y, et al. Infrared terminal guidance typical target detection based on YOLOv3[J]., 2019, 56(16): 155-162.
[15] 赵琰, 刘荻, 赵凌君. 基于Yolo v3的复杂环境红外弱小目标检测[J]. 航空兵器, 2020, 26(6): 29-34.
ZHAO Y, LIU D, ZHAO L J. Infrared small target detection in complex environment based on Yolo v3[J]., 2020, 26(6): 29-34.
[16] 吴双忱, 左峥嵘. 基于深度卷积神经网络的红外小目标检测[J]. 红外与毫米波学报, 2019, 38(3): 371-380.
WU S C, ZUO Z G. Infrared small target detection based on deep convolutional neural network[J]., 2019, 38(3): 371-380.
[17] HU J, SHEN L, SUN G. Squeeze-and-excitation networks[C]//, 2018: 7132-7141.
[18] 李慕锴, 张涛, 崔文楠. 基于Yolo v3的红外行人小目标检测技术研究[J]. 红外技术, 2020, 42(2): 176-181.
LI M K, ZHANG T, CUI W N. Research on infrared pedestrian small target detection technology based on Yolo v3[J]., 2020, 42(2): 176-181.
[19] Everingham M, Eslami S A, Van Gool L, et al. The pascal visual object classes challenge: a retrospective[J]., 2015, 111(1): 98-136.
[20] LIN T Y, Maire M, Belongie S, et al. Microsoft coco: common objects in context[C]//, 2014: 740-755.
[21] XIA G S, BAI X, DING J, et al. DOTA: a large-scale dataset for object detection in aerial images[C]//, 2018: 3974-3983.
[22] LI K, WAN G, CHENG G, et al. Object detection in optical remote sensing images: a survey and a new benchmark[J]., 2020, 159: 296-307.
[23] ZHU H, CHEN X, DAI W, et al. Orientation robust object detection in aerial images using deep convolutional neural network[C]//2015(ICIP), 2015: 3735-3739.
[24] TAN M, PANG R, LE Q V. Efficientdet: scalable and efficient object detection[C]//, 2020: 10781-10790.
[25] Hwang S, Park J, Kim N, et al. Multispectral pedestrian detection: Benchmark dataset and baseline[C]//, 2015: 1037-1045.
[26] Teledyne FLIR Systems. FLIR ADAS Dataset[DB/OL] [2023-11-27]. https://www.flir.com/oem/adas/adas-dataset-form/.
[27] Davis J W, Keck M A. A two-stage template approach to person detection in thermal imagery[C]//2005, 2005, 1: 364-369.
[28] CAI Z, Vasconcelos N. Cascade r-cnn: delving into high quality object detection[C]//, 2018: 6154-6162.
[29] PANG J, CHEN K, SHI J, et al. Libra r-cnn: Towards balanced learning for object detection[C]//, 2019: 821-830.
[30] WU Y, CHEN Y, YUAN L, et al. Rethinking classification and localization for object detection[C]//, 2020: 10186-10195.
[31] Redmon J, Farhadi A. Yolov3: an incremental improvement [EB/OL] [2018-04-08]. https://arxiv.org/pdf/1804.02767.pdf.
[32] HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition[C]//, 2016: 770-778.
[33] LINT Y, Dollár P, Girshick R, et al. Feature pyramid networks for object detection[C]//, 2017: 2117-2125.
[34] Bochkovskiy A, WANG C Y, LIAO H Y M. YOLOv4: Optimal speed and accuracy of object detection[EB/OL] [2020-04-22]. https://arxiv.org/ pdf/2004.10934.pdf.
[35] HE K, ZHANG X, REN S, et al. Spatial pyramid pooling in deep convolutional networks for visual recognition[J]., 2015, 37(9): 1904-1916.
[36] WANG K, LIEW J H, ZOU Y, et al. PaNet: Few-shot image semantic segmentation with prototype alignment[C]//, 2019: 9197-9206.
[37] ZHENG Z, WANG P, LIU W, et al. Distance-IoU loss: faster and better learning for bounding box regression[C]//2020, 2020: 12993-13000.
[38] TIAN Z, SHEN C, CHEN H, et al. FCOS: Fully convolutional one-stage object detection[C]//2019, 2019: 9627-9636.
[39] CHEN K, WANG J Q, PANG J M, et al. Mmdetection: open mmlab detection toolbox and benchmark[EB/OL][2019-06-17]. https:// arxiv.org /pdf/ 1906. 07155. pdf.
[40] ZHANG H, WU C R, ZHANG Z Y, et al. Resnest: Split-attention networks[EB/OL] [2020-04-19]. https://arxiv.org/pdf/2004.08955.pdf.
Infrared-PV: an Infrared Target Detection Dataset for Surveillance Application
CHEN Xu1,WU Wei2,PENG Dongliang1,GU Yu1
(1.,,310018,;2.28,210007,)
Although infrared cameras can operate day and night under all-weather conditions compared with visible cameras, the infrared images obtained by them have low resolution and signal-to-clutter ratio, lack of texture information,so enough labeled images and optimization model design have great influence on improving infrared target detection performance based on deep learning. First, to solve the lack of an infrared target detection dataset used for surveillance applications, an infrared camera was used to capture images with multiple polarities, and an image annotation task that outputted the VOC format was performed using our developed annotation software. An infrared image dataset containing two types of targets, person and vehicle, was constructed and named infrared-PV. The characteristics of the targets in this dataset were statistically analyzed. Second, state-of-the-art target detection models based on deep learning were adopted to perform model training and testing. Target detection performances for this dataset were qualitatively and quantitatively analyzed for the YOLO and Faster R-CNN series detection models. The constructed infrared dataset contained 2138 images, and the targets in this dataset included three types of modes: white hot, black hot, and heat map. In the benchmark test using several models, Cascade R-CNN achieves the best performance, where mean average precision when intersection over union exceeding 0.5 (mAP0.5) reaches 82.3%, and YOLOv5 model can achieve the tradeoff between real-time performance and detection performance, where inference time achieves 175.4 frames per second and mAP0.5drops only 2.7%. The constructed infrared target detection dataset can provide data support for research on infrared image target detection model optimization and can also be used to analyze infrared target characteristics.
infrared image, dataset, surveillance application, deep learning, benchmark test
TP391.9
A
1001-8891(2023)12-1304-10
2021-01-15;
2021-02-24.
陈旭(1997-),男,硕士研究生,主要从事图像目标识别、检测与模型优化研究。
谷雨(1982-),男,博士,副教授,主要从事多源信息融合、遥感图像目标检测与识别方面的研究。E-mail:guyu@edu.hdu.cn。
浙江省自然科学基金资助项目(LY21F030010)。
猜你喜欢
黑龙江大学自然科学学报(2022年4期)2022-11-17 08:08:06
环球时报(2022-05-23)2022-05-23 11:28:37
金桥(2021年4期)2021-05-21 08:19:20
作文小学中年级(2020年6期)2020-07-24 08:33:10
电子制作(2019年7期)2019-04-25 13:17:14
光学精密工程(2016年3期)2016-11-07 09:03:43
高中生学习·高二版(2015年12期)2016-01-05 13:08:35
自然资源遥感(2014年3期)2014-02-27 11:56:38
意林(2011年10期)2011-05-14 07:44:00
中学英语之友·上(2008年2期)2008-04-01 01:19:30
