
基于EfficientNet网络模型的猪肉新鲜度智能识别方法
2024-01-03 15:32:00张家瑜黄继超陈坤杰
食品科学 2023年24期
刘 超,张家瑜,戚 超,黄继超,陈坤杰,
(1.南京农业大学工学院,江苏 南京 210031;2.南京理工大学泰州科技学院智能制造学院,江苏 泰州 225300)
近年来,随着生活水平的逐年提高,我国居民的人均肉类产品消费量不断增加,消费者对肉类产品的质量、尤其是新鲜度的关注也越来越高[1]。
目前,我国对猪肉新鲜度的评价主要采用理化方法,包括微生物浓度检测、总挥发性氨基氮(total volatile basic nitrogen,TVB-N)含量检测[2]、电导率检测[3]、pH值检测等[4]。尽管理化检测方法准确、可靠,但检测时,需要对样品进行破坏处理,检测过程复杂、繁琐、耗时较长,无法满足对猪肉新鲜度进行快速和在线检测的要求[5]。在猪肉销售以及猪肉制品的加工过程中,如果能快速确定猪肉的新鲜度,对增加猪肉的商品价值,提高猪肉制品的品质,乃至保障猪肉产品的安全非常重要,因此,研究开发无损、快速、在线的猪肉新鲜度检测方法和技术,具有十分重要的实际意义。
计算机视觉检测具有无损、快速、无害等特点[6],可对生产线上肉类产品质量进行安全、无损的快速检测[7]。因此,近些年来,通过获取猪肉图像,再根据猪肉颜色、形状以及表面纹理特征,进行猪肉品质的评估和测定获得了广泛的研究及应用[8-10]。
由于卷积神经网络(convolution neural network,CNN)可以将图像直接输入网络避免特征提取及分类过程中数据重建的复杂度,因此,用CNN进行图像分类与识别,具有传统机器视觉所不具有的巨大优势。基于图像的猪肉新鲜度评估和测定,可视为一个图像分类问题。通过CNN对猪肉图像进行分类,就可能实现对猪肉新鲜的快速无损测定。Hu Jun等[11]用AlexNet、VggNet、GoogleNet、ResNet以及改进的区域CNN网络框架对鱿鱼的种类和新鲜度进行分类预测,发现与人工识别比较,自动识别的精度大于80%。邱洪涛等[12]采用ResNet50模型对猪肉新鲜度进行分级,对采集的约2 000 张图片进行1 000 次网络训练迭代后,验证结果的准确率达到了96.90%。焦俊等[13]同样也提出了一种基于改进残差网络的黑毛猪肉新鲜度识别方法,获得了94.5%的准确率。但二者的研究都由于猪肉样本数量不足以及未通过预训练确定模型基本结构等原因,存在模型训练耗时过长、模型的稳定性不足等问题。尽管存在某些不足,但上述研究表明,基于图像与CNN,可以对猪肉新鲜度进行快速检测。
近十年来,CNN发展迅速,模型迭代层出不穷,其中的EfficientNet模型在2019年一经提出,便在Imagenet top-1达到当年最高的图像识别准确率84.3%。不仅如此,与之前准确率最高的GPipe相比,EfficientNet模型在参数数量仅为其1/8.4的情况下,速率提升了6.1 倍[14],是目前图像分类与识别表现最优秀的模型之一。为此,本实验提出一种基于图像和EfficientNet框架的猪肉新鲜度测定方法,结合猪肉图像的特点,对网络进行改进。通过改进优化器算法,提高网络的泛化性。通过与目前最经典的AlexNet、ResNet50、VGG16等先进CNN架构的比较,对改进的EfficientNet预测模型性能进行评估,以期为将来开发快速无损的猪肉新鲜度检测系统提供理论和技术支持。
1 材料与方法
1.1 材料与试剂
新鲜猪后腿肉购自江苏泰州大润发超市,购买之后利用蓄冷装置迅速运至实验室。切片大小约为50 mm×80 mm,厚度为10 mm,取30 片。每个样本单独包装灭菌自封袋中,在4 ℃的环境下分别放置0、24、48、72、96 h。待测定微生物菌体浓度、大肠菌菌体浓度和pH值。
平板计数琼脂培养基(纯度99%)广东环凯微生物科技有限公司;Aliz-gal琼脂(纯度100%)上海弘顺生物科技有限公司。
1.2 仪器与设备
SW-CJ-2D型双人单面净化工作台 苏州净化设备有限公司;M2 CCD摄像头 深圳市微星电科技有限公司;拯救者刃9000-25ICZ计算机 联想集团股份有限公司。
1.3 方法
1.3.1 猪肉新鲜度分级依据
猪肉新鲜度分级的主要依据TVB-N含量、微生物菌体浓度、大肠菌菌体浓度和pH值等参数,基于机器视觉的猪肉新鲜度检测主要以猪肉的颜色、纹理、色泽等特征作为判断依据。通过数字图像处理将上述特征转换成特征向量。猪肉pH值能够较好地反映肉品新鲜度的变化,色差分析符合一定的规律[15],微生物会加快猪肉在冷藏过程中蛋白质的氧化,微生物的生长繁殖会促进猪肉的腐败变质,菌落数与猪肉色泽都存在正相关[16]。大肠杆菌来源于人和动物的肠道,广泛存在水、土壤、空气等生活环境中,是冷鲜猪肉中的一类主要腐败菌,也是食品必须检测的细菌指标[17]。根据GB/T 9959.2—2008《分割鲜、冻猪瘦肉》,本研究采用pH值、微生物菌体浓度、大肠杆菌菌体浓度作为猪肉新鲜度的判断依据。
将1.1节处理样品分别放置0、24、48、72、96 h后取出。进行微生物菌体浓度、大肠菌菌体浓度和pH值的检测。微生物菌落总数计数:根据GB 47892—2010《食品微生物学检验 菌落总数测定》进行测定;大肠菌群的计数:根据GB/T 4789.32—2002《食品卫生微生物学检验 大肠菌群的快速检测》测定;pH值:根据GB 5009.237—2016《食品pH值的测定》测定,并记录所有样本3 项测试数据的范围。
为了更细致研究猪肉新鲜度分级,以GB/T 9959.2—2008规定为基础,配合感官评价,本研究将新鲜猪肉在4 ℃环境下放置时间与相应理化参数进行对应数据处理,将猪肉新鲜度分为新鲜肉、次新鲜肉一级、次新鲜肉二级、腐败肉一级、腐败肉二级共5 级。不同猪肉新鲜度等级主要理化参数和放置时间关系如表1所示,该分级参数与张婷[18]、胡云峰等[19]研究结果基本一致。
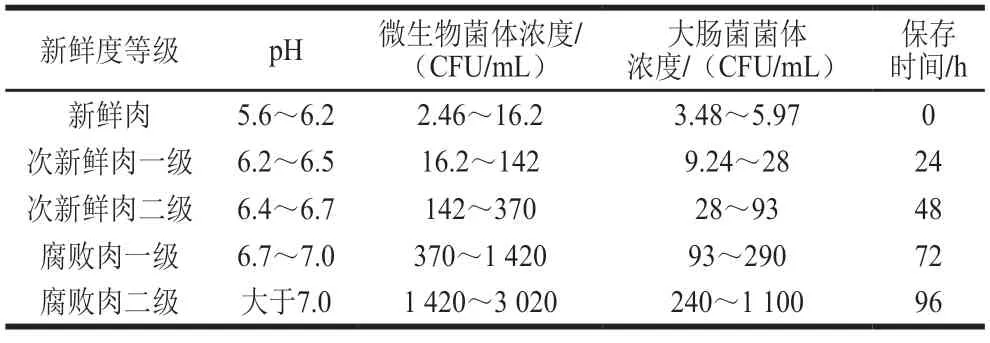
表1 猪肉新鲜度分级主要参数Table 1 Major parameters used for pork freshness grading
1.3.2 数据集制作与数据增强
1.3.2.1 原始数据集制作
取550 片作为猪肉图像样本,在4 ℃的环境下分别放置0、24、48、72、96 h后,在自然光下,采用CCD摄像头进行图像采集,通过USB上传到计算机保存。采用1.3.1节方法进行微生物菌体浓度、大肠菌菌体浓度和pH值的检测,对比设定的猪肉新鲜度参数范围,将不在范围内的猪肉图片删除,每一个放置时间取500 张符合表1分级参数的图像作为原始数据集样本。每一个等级的图片如图1所示。

图1 各等级肉图片Fig.1 Pictures of pork of different grades
1.3.2.2 数据集增强
采用数据增强函数[20],通过45 度旋转、宽度偏移、高度偏移、水平翻转和随机缩放等方法将2 500 张不同新鲜度的原始图片数据集扩展为60 000 张,每个等级图片12 000 张。对60 000 张图像对应新鲜度等级标注,然后采用随机抽取的方式,将图像数据集分成训练集83%、测试集12%、验证集5%,如表2所示。

表2 数据集总览Table 2 Dataset overview
1.3.3 EfficientNet预测模型的构建及改进
1.3.3.1 EfficientNet预测模型构建
EfficientNet通过对网络深度、宽度和输入分辨率的综合调整,获得对特定需求的最优网络参数,使网络同时具备了网络大小与识别准确率的双重优势。图片输入后,经过3×3卷积核进行卷积操作,后经过多个MB卷积模块,最后通过1×1卷积池化全连接层输出。
EfficientNet网络的基本框架如图2所示,其中,图2b~d分别是对网络的宽度、深度以及输入图像分辨率的扩展。图2e是对网络的宽度、深度以及输入分辨率的复合扩展。

图2 EfficientNet网络结构示意图Fig.2 Schematic diagram of EfficientNet architecture
EfficientNet使用MobileNet V2中的MBConv作为模型的主干网络。MBConv主要由一个1×1的普通卷积(升维作用,包含BN和Swish),一个k×k的Depthwise Conv卷积(包含BN和Swish),一个SE模块,一个1×1的普通卷积(降维作用,包含BN),一个Droupout层构成。SE模块由一个全局平均池化,两个全连接层组成。第1个全连接层的节点个数是输入该MBConv特征矩阵channels的个数,使用Swish为激活函数。第2个全连接层的节点个数等于Depthwise Conv层输出的特征矩阵channels,使用Sigmoid为激活函数。EfficientNet 网络结构如图3所示。所建立的EfficientNet baseline结构如表3所示。
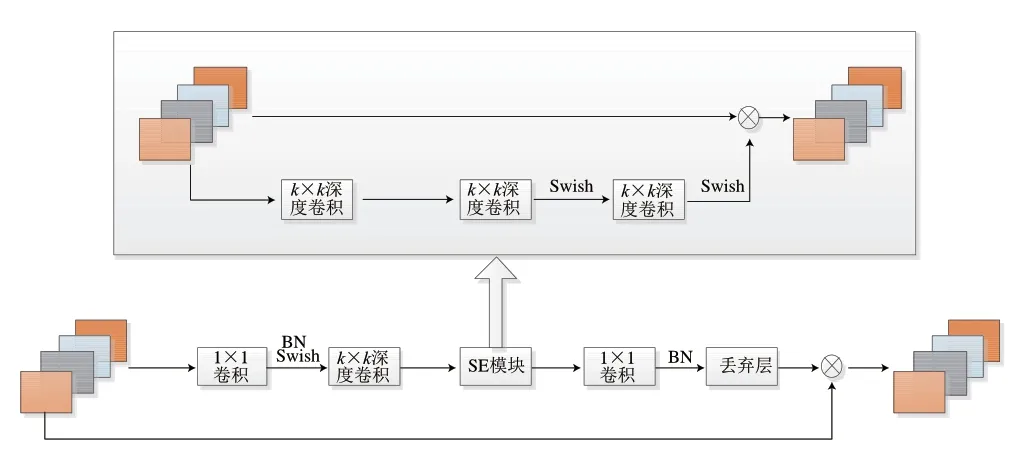
图3 EfficientNet网络结构示意图Fig.3 Structural diagram of EfficientNet network

表3 EfficientNet baseline结构Table 3 EfficientNet baseline structure
输入图像的分辨率、网络深度及宽度的交互作用,显著影响EfficientNet模型的预测精度和效率,对这3 个参数平衡且合理配比的探索,才能获得最优EfficientNet模型结构。因此,EfficientNet通常由B0和B7之间的8 个模型组成,B0和B7之间的参数如表4所示。

表4 EfficientNet B0与B7之间的参数Table 4 EfficientNet parameters in the range of B0 to B7
1.3.3.2 EfficientNet优化算法改进
EfficientNet网络中采用了传统的随机梯度下降(stochastic gradient descent,SGD)算法。由于随机SGD算法中每个参数的学习速率一致,较难选择合适的学习率,会导致反向求导过程中产生局部最优解,使猪肉新鲜度识别准确率降低。
为加快模型训练的收敛速率,本研究首先采用自适应矩估计(adptive moment estimation,Adam)[21]优化算法以代替原网络中的SGD算法,通过自适应随机优化算法,可避免训练初始阶段梯度消失的情况,并达到稳定训练、加速收敛的目的。Adam算法结合了自适应梯度算法和均方根传递算法的有点,经过偏置的矫正,每一次迭代的学习率都有一个确定的范围,减少了超参数更新的波动。在反向传播过程中,参数更新过程如表5所示。
表5中,ωt和ωt-1分别代表第t和t-1次更新参数值,参数α是更新学习率,α越高,模型收敛速率越快,但得到的解有可能是局部最优解,学习率低,会导致模型收敛速率慢,计算量大。
mt表示梯度的指数加权移动平均,是求过往梯度与当前梯度的均值,β1初值取0.9,当t=1,修正系数放大10 倍。当t>30时,此时修正系数可以忽略。这相当于对原始梯度进行了平滑处理,使更新过程更加平稳,同时,更多地考虑近期数据,使更新过程更加灵敏。
vt表示梯度平方的指数加权平均,是求过往梯度的平滑与当前梯度平方的均值。β2初值取0.999,当t=1,修正系数放大1 000 倍,t>3 000时,此时修正系数可以忽略。可以反映累计梯度的大小和波动信息。β2越大,梯度平方效果越明显。
更新公式与学习率α和超参数β1、β2关系如下式:
随着迭代次数的增加,当gt较小时,更新计算就会放大学习率,提高运算速率,当gt较大时,更新计算就会缩小学习率,使计算精细,准确寻找到梯度最小值,进而提高模型的泛化性和鲁棒性。初始值α=0.001、β1=0.09、β2=0.999、ε=10-8在CIFAR-10数据集上实验[21],预测效果较SGD优化算法有显著提高。本研究在应用迁移学习预训练也采用了CIFAR-10数据集,因此,本研究学习率和超参数初值与文献[21]一致。
Adam优化器算法是用是用指数滑动平均去估计梯度每个分量的一阶矩和二阶矩,得到每步的更新量,继而提供自适应学习率。但是,自适应学习率在训练早期因样本数量有限会有很大方差的问题,从而可能收敛到局部最优,为了解决该问题,有学者提出了Adam的一个新变体校正自适应矩估计(rectified adaptive moment estimation,RAdam)[22],通过修正自适应学习率的方差项缓解收敛问题。由于该算法能够动态的打开和关闭自适应学习率,会带来更快的收敛速率。在反向传播中过程中,参数更新如表6所示。

表6 RAdam算法参数更新步骤Table 6 Updated steps of RAdam algorithm parameters
由表6可以看出,根据SMA最大值[23-24]可以控制自适应学习率的开断,这有利于提升模型的收敛速率。RAdam使用一个动态整流器调整Adam算法中基于方差自适应动量,并有效地提供了一个基于当前的数据集的自动热身可定制机制,保证了训练前期数据更新效率。初始值设置为α=0.001、β1=0.9、β2=0.999,设置原理与Adam优化器一致。
本研究首先采用Adam优化器对EfficientNet模型进行改进优化,并在EfficientNetB0到B7模型中选取应用于猪肉新鲜度识别效果最好的模型。再采用RAdam优化器对模型进一步优化,并对比识别效果。
1.3.4 迁移学习
为了提高网络模型对猪肉新鲜度图像识别精度和泛化能力,减少后期建模的训练时间,采用迁移学习方法[25],先利用CIFAR-10数据集对网络进行预训练,将训练好的网络参数作为待建模型的初始参数完成权值初始化。然后,对CNN模型进行改进,将最后一个全连接层更改为5输出,使模型适用五分类问题。另外,选择Softmaxt作为最后一层的激活函数,选择损失函数为分类交叉熵。
对预训练后的模型采用与训练CIFAR-10数据集时相同的方法进行优化。除了VGG16模型采用SGD优化方法外,而其他模型均采用Adam优化方法。Adam方法的学习率设为0.001,SGD方法的学习率设为0.01。
1.3.5 模型评价指标
模型评价参数包括真阳性(true positives,TP)、真阴性(ture negatives,TN)、假阳性(false positeves,FP)和假阴性(false negatives,FN)[26]。其中本实验采用准确性、灵敏度、特异性和精度作为模型评价指标。准确性表示在所有样本中正确分类样本的比率,敏感度是正确预测的阳性与所有真阳性的比率,特异性是指正确预测的阴性与所有真阴性的比率,精度是所有阳性识别中正确预测阳性的比例,具体计算公式如下:
式中:TP表示每个类别中正确分类的图像数量;TN表示除相关类别外的所有其他类别中正确分类的图像的数量;FP表示除相关类别外所有其他类别中错误分类图像的数量;FN表示从相关类别中被错误分类的图像的数量。l为样本的总类别数,i为每个类别的评价指标。
1.4 数据分析
模型在Windows环境下编译,CPU为I7-8700,内存8 G,显卡为NVIDIA GTX1060 6 G。所有代码基于TensorFlow 2.0版本,用Keras框架实现。数据处理采用Excel 2019版本。
2 结果与分析
2.1 实验过程
为充分评估EfficientNet网络对猪肉新鲜度识别的优越性,本研究选取同类先进的深度CNN进行性能比较,其中包括AlexNet[27]、VGG6[28]、ResNet[29]。实验均采用TensorFlow开源框架。
猪肉新鲜度检测是一个五分类问题,为减少训练时间,提高识别精度,先将本研究采用的模型在CIFAR-10进行预训练,完成权值初始化。为使模型适用五分类问题,对模型进行改进,将最后一个全连接层更改为5输出,选择Softmaxt作为最后一层的激活函数,选择损失函数作为分类交叉熵。另外,对预训练后的模型采用与训练CIFAR-10数据集时相同的方法进行优化。除VGG16模型采用SGD优化方法外,其他模型均采用Adam优化方法。Adam方法的学习率设为0.001,SGD方法的学习率设为0.01。为使样本图片满足每个模型对输入图片分辨率的要求,通过TensorFlow函数对图片进行处理。各个模型的输入图像大小、优化器参数、学习率设置如表7、8所示。

表7 深度学习模型的默认输入图像大小Table 7 Sizes of default input images used for deep learning models

表8 深度学习模型优化器和学习率参数Table 8 Deep learning model optimizers and learning rate parameters
用增强后的猪肉新鲜度图像数据集对所有模型进行总训练轮数为14 个epoch的训练并验证,结果如表9所示。相较于其他3 类模型,EfficientNet网络模型普遍具有较高的预测准确率,模型的训练时间呈现出随着输入图片的增大而明显增加的趋势。其中,B4网络模型准确率最高,达到99.40%,B2网络模型准确率虽然较B4略微逊色,但训练时间明显低于B4。B5、B6和B7模型的训练时间都高于300 min,但准确率并不是最高,说明输入图片的增大会造成训练时间的明显增加,但不会改善模型准确率。这也许可以说明,分辨率、网络深度及宽度这3 个参数平衡且合理配比,才是决定网络模型的性能关键因素。
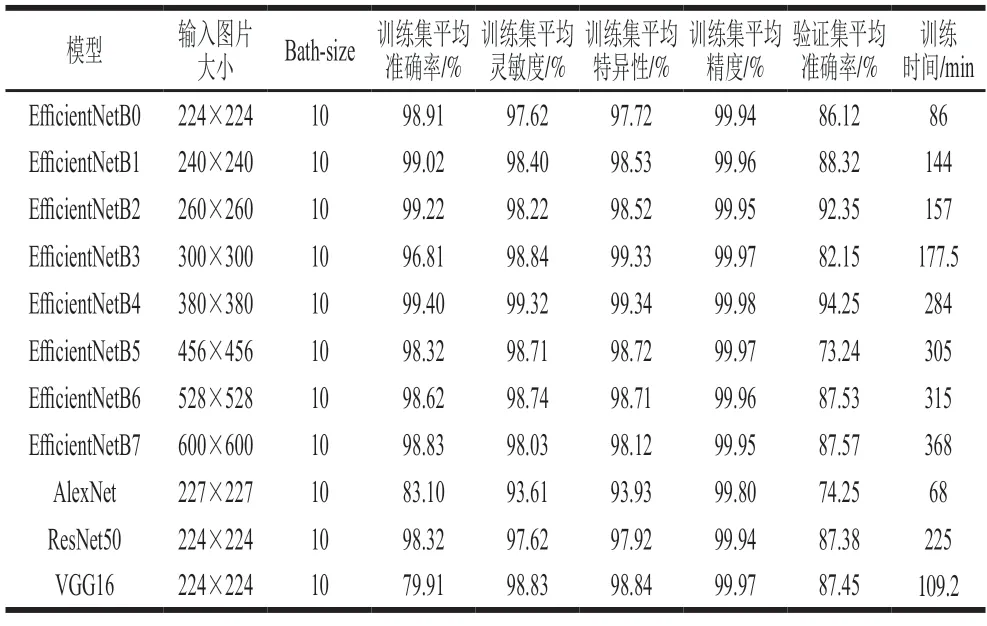
表9 不同模型运行的数据结果Table 9 Operation results of different models
表9显示,AlexNet模型的训练集和验证集准确率均较低,但训练时间最短。这可能是因为AlexNet采用Relu作为激活函数,解决了Sigmoid激活函数在网络较深时的梯度弥散问题;另外,其全连接层采用了50%的舍弃忽略了一部分神经元,减少了网络的过拟合情况。虽然采用了较高的分辨率,但是并没有显著提高预测的准确率。VGG16模型是由若干卷积层和池化层堆叠的方式构成,比较容易形成较深的网络结构,具有很高的拟合能力。实验显示VGG16网络的训练时间相对较短,但是对训练集的准确率最低,仅有79.9%,说明卷积层和池化层的堆叠对于猪肉新鲜度特征的提取效果较差。相比于AlexNet和VGG16,ResNet50网络的训练时间虽然有了明显增长,但准确率显著提高。表明50 层的网络能够提取更加准确的特征值,有利于提高训练集的准确率。这可能是因为ResNet50网络模型采用residual模块成功解决了梯度消失和梯度爆炸问题,使50 层的神经网络能够保证持续优化。EfficientNet模型的平均正确识别率高达98.62%,明显优于Alexnet、VGG16和ResNet50模型,其中,EfficientNetB2模型的正确识别率达到99.22%,训练时间仅需157 min,综合性能最佳,是一种最适合猪肉新鲜度识别的方法。
为考察预训练和迁移学习在建立预测模型过程中所起作用,在通过迁移学习确定各类模型结构和初始权值后,在利用猪肉新鲜度训练集对各个模型进行训练过程中,模型的准确率和损失函数值如图4所示。

图4 模型的准确率曲线(A)和损失曲线(B)Fig.4 Accuracy curves (A) and loss curves (B) of all models
由图4可知,在训练的初始阶段,AlexNet和VGG模型准确率较低,损失函数下降的较慢;而EfficientNet和ResNet模型的准确率在训练刚开始就较高,损失函数也是在训练刚开始就迅速下降。尤其是B2模型,在2 epoch以后,训练准确度就基本稳定,完成了4 epoch以后,就基本达到了最大准确率。尽管AlexNet和VGG模型模型在训练开始阶段准确率较低,但在完成14 epoch以后,也都基本达到各自的最大值。说明通过预训练,可以使建模实际所用时间大大减少,迁移学习对模型性能提升效果非常显著。上述分析显示,在所有模型中,EfficientNetB2展现出较高的识别准确度和较短的训练时间,综合性能最优。用测试集中的1 500 张图片对该模型进行测试,考察模型对5 种不同新鲜度猪肉预测能力,结果如表10所示。除特异性指标外,模型的其他性能指标都非常优异,证明EfficientNetB2是预测猪肉新鲜度等级的最佳模型。
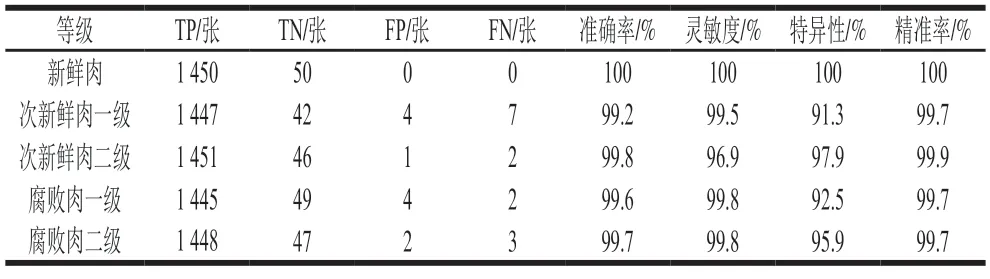
表10 EfficientNetB2对每个类的测试集的分类性能Table 10 Classification performance of EfficientNetB2 for test sets of five freshness levels
为探索对EfficientNet优化器算法改进效果,对于EfficientNetB2模型,分别采用SGD、均方根传播(root mean square propagation,RMSProp)[30]、Adam[21]、RAdam[22]4 种优化器,用测试集和验证集对模型的模型性能进行测试和验证,结果如表11所示。
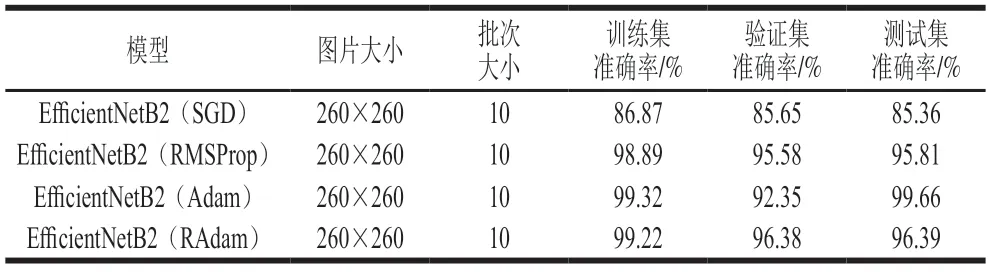
表11 应用不同优化器的EfficientNetB2模型性能Table 11 Model performances of EfficientNetB2 using different optimizers
由表11可知,总体而言,模型EfficientNetB2采用Adam优化器是较为适合的算法。改用RMSProp和SGD优化器后,模型的性能显著下降,采用SGD优化器的EfficientNetB2在公共数据集上完成图像识别任务的准确率较高(ImageNet数据集中准确率达到94%),但对于猪肉新鲜度识别任务,表现的准确率明显低于Adam优化器性能,说明这两类优化器并不适用于EfficientNet模型识别猪肉新鲜度任务。采用RAdam优化器后,训练集准确率虽然没有提高,甚至还比Adam低了0.1%,但是其验证集准确率出现了明显的提升,可见RAdam优化器较好的提升了模型的泛化性,对工程应用有实际意义。
2.2 误差分析
为了分析模型识别错误的情况,本研究提取EfficientNetB2(Adam)模型和EfficientNetB2(RAdam)模型中识别错误的图片。并对识别错误图片的特点做了分析。其中,EfficientNetB2(Adam)模型识别错误图像中2.3%为原始图像,97.7%为数据增强后图像,而EfficientNetB2(RAdam)模型识别错误图像中,100%为数据增强后图像。
由表12可知,两种模型对原始图像识别的准确率较高,EfficientNetB2(RAdam)模型对原始图像识别准确率为100%,证明该模型的泛化性较强。两种模型对随机缩放后的图像识别错误率较高,其原因主要是随机缩放后图像特征产生了变化,尤其是颜色分布的改变,影响了模型判断的结果。角度旋转并没有改变猪肉的颜色分布,模型对该类型图像识别正确率为100%。

表12 模型错误识别图像分布Table 12 Distribution of errors in image recognition by models
3 结论
采用EfficientNet网络模型对猪肉的新鲜度进行识别,可以获得很高的准确率。尤其是EfficientNetB2模型,正确识别率高(9 9.2 2%),训练时间适中(157 min),综合性能最佳,是一种最适合猪肉新鲜度识别的方法。
采用迁移学习后,在进行建模训练时,只经过14 个epoch,各类模型的正确识别率即达到稳定的最大值,模型的训练时间显著缩短。因此,迁移学习和深度学习结合,是一种高效的CNN建模方法。
采用RAdam优化器代替原有的SGD优化器,虽然不能提高模型识别的准确率,但提升了模型的泛化性,对工程应用有实际意义。
猜你喜欢
数学物理学报(2021年6期)2021-12-21 06:24:38
今日农业(2021年5期)2021-11-27 17:22:19
今日农业(2020年17期)2020-12-15 12:34:28
应用数学(2020年2期)2020-06-24 06:02:50
中国化肥信息(2019年12期)2020-01-16 08:40:04
数学年刊A辑(中文版)(2018年2期)2019-01-08 01:59:52
数学小灵通·3-4年级(2017年5期)2017-06-05 09:12:37
食品工业科技(2014年13期)2014-03-11 18:16:43
食品工业科技(2014年13期)2014-03-11 18:16:40
食品工业科技(2014年9期)2014-03-11 18:15:56
