
机器学习在土壤重金属污染研究中的应用
2024-01-02 06:58:48郭华雨马海丽陈一平李芸邑梁嘉良
三峡生态环境监测 2023年4期
郭华雨,马海丽,陈一平,李芸邑,梁嘉良*
(1.海军后勤部专项工程建设办公室,北京 100841;2.重庆大学 环境与生态学院,重庆 400045)
土壤重金属污染问题在全球范围内受到长期关注[1]。土壤中的重金属因其毒性、持久性、生物可利用性和较长的生物半衰期而被认为是土壤环境中最危险的污染物之一。世界卫生组织认为,整个生态系统正在由于过度暴露于重金属而不断受到威胁[2-4]。土壤重金属可能通过皮肤吸收、口服摄入、口鼻呼吸等途径进入人体,从而损害人体的神经、消化和内分泌系统,甚至可能诱发癌症[5]。一些重金属还能够通过抑制酶的活性,引起中度的细胞质损伤,从而影响神经组织,甚至损害解毒的关键器官[6]。因此,调查和研究土壤重金属的相关信息,开发合理的土壤重金属污染修复技术,从而加强重点地区的污染防治成为了研究热点。目前,传统的方法主要依靠现场采样和复杂的、多步骤的实验室测试来获得土壤重金属的相关信息[7]。重金属的浓度通常由专业的实验室测定,检测结果虽然具有较高的精度,但对于大规模的污染调查,现场采样成本高且耗时长,生态环境信息综合分析能力弱,使得传统的化学方法难以在监测土壤重金属污染时具有高效率和较强的时效性[8-9]。因此,有必要开发新的技术,既能得到准确的土壤重金属相关数据,又减少人力、财力及时间上的消耗。
机器学习是基于样本数据建立模型,在没有明确编程的情况下做出预测或决策的新技术,其模型包括监督、无监督和半监督学习,输入的数据常被分成训练集和测试集,模型在训练集上训练,而测试集用于评估模型的稳健性和准确性[10]。机器学习拥有强大的拟合能力,分析和学习大量复杂、多维的数据集,发现数据中隐藏的关联,并且比其他方式更加有效和准确[11]。因此,在过去十年,机器学习,尤其是深度学习在图像分类、机器翻译[12]、化学[13]、材料科学[14]、生物医学[15]和量子物理[16]等领域得到了长足的发展。近几年,机器学习在环境领域也得到了广泛应用,在评估环境风险[17]、评估水和废水基础设施的健康状况[18]、优化处理技术[19]、识别和确定污染源的特征[20]以及进行生命周期分析[21]等方面显示良好的应用前景。
近年来,基于机器学习模型的土壤重金属研究受到了极大的关注[22],不仅将劳动力、经济、时间和空间要求方面的成本负担最小化,还促进了对自变量和因变量之间的非线性和复杂联系的理解[23]。然而,模型的性能会受到某些因素的影响,如数据集的数量、数据类型、数据优化以及由算法而产生的偏差等等[24]。由于算法类型众多,通常需要基于数据类型和应用方面,首先对数据集进行筛选,然后对模型进行训练和验证,以获得最稳健、准确的计算模型。因此,本文总结了机器学习在土壤重金属领域不同方面的应用,对各方面的常用建模过程和模型筛选过程进行了综述,以期进一步推动机器学习在土壤重金属研究中的应用。
1 机器学习与土壤重金属污染
1.1 重金属含量
在土壤重金属污染领域,机器学习最常被应用于土壤重金属含量的预测。研究者们通常以土壤的光谱信息、遥感信息、理化性质、采样点气候等因素为输入参数,以实验室测定的重金属含量为目标函数进行模型构建,并比较不同计算模型的预测准确度。该技术方案不仅能够实现对指定地点的重金属含量的预测,还可以分析决定不同地点重金属浓度的关键因素,进而绘制土壤重金属分布地图。
1.1.1 土壤重金属含量预测
重金属含量是评价土壤重金属污染程度最重要的特征,而土壤中重金属浓度与土壤性质息息相关。高光谱遥感技术由于其丰富的光谱信息,已逐渐被应用于土壤的物理化学性质检测[25]。然而,高光谱数据的高维数和冗余特性严重影响了估算模型的准确性和稳定性[26],因此需要对高光谱进行筛选。研究者们使用Pearson 相关系数阈值来确定与土壤重金属含量相关性最高的光谱变量[27-28],也有研究者在提取高光谱数据作为参数时就使用了机器学习法[29]。偏最小二乘回归(partial least squares regression,PLSR)能够在输入参数存在严重多重相关性的条件下进行回归建模,更易于辨识高光谱中的系统信息与噪声。Tang等[30]利用PLSR-VIP 值评价和相关分析方法选择特定光谱特征波段,提取的有效特征带与强相关系数基本一致,共计提取了637 个Cr 的特征带,756个Ni的特征带。Han等[31]通过序贯正交化(sequential preprocessing of orthogonalization,SPORT)对PLSR模型进行优化后得到序贯正交偏小二乘(sequential and orthogonalized - partial least square,SO-PLSR),大大提高了建模精度,训练集R2达到0.89,测试集R2达到0.82。
提升树(boosting tree,BT)是弱分类器组合起来形成强分类器的一类模型,梯度提升决策树(gradient boosting decision tree,GBDT)是其中一种,可在缺失输入参数持续可控的情况下保持强抗噪性[32]。Tang 等人[30]以高光谱特征值和Al-Fe 矿物含量作为参数,使用GBDT、随机森林(random forest,RF)、支持向量机(support vector machine,SVM)、极端梯度增强树(extreme gradient boosting,XGBoost)、自适应提升树(adaptive boosting,AdaBoost)5 种模型对Cr、Ni 浓度进行预测,结果表明GBDT 为最佳预测模型,Cr 和Ni 的R2分别达到0.85 和0.71。极端梯度增强树(XGBoost)是在GBDT的基础上改进得到的模型,可以根据重要性排序来识别敏感特征,防止模型过拟合[33]。Sun等[34]以高光谱降维得到的特征值和Ni浓度相关的光谱指标作为参数,使用RF、XGBoost、SVM、反向传播神经网络(back propagation neural network,BPNN)、高斯过程回归(Gaussian process regression,GPR)5 种模型对Ni 浓度进行预测,结果表明XGBoost为最佳预测模型,标准差(standard deviation,SD)与均方根误差(root mean squared error,RMSE) 之比(residual predictive deviation,RPD)可达到2.08。为提高Boosting 的预测精度,可以与其他算法联合使用。传统的AdaBoost 模型通常采用分类回归树(classification and regression tree,CART)作为基本学习器[24-35],Lin 等人[36]提出了一种新的堆叠AdaBoost 模型,选择CART、SVM、GPR、k 近邻(k-nearest neighbor,KNN)、多层感知器(multilayer perceptron,MLP)、核岭回归(kernel ridge regression,KRR)6种机器学习模型作为AdaBoost 的基本学习器。结果表明,将CART、GPR、MLP、SVM 作为基础学习器的堆叠AdaBoost模型相对稳定,精度更高。
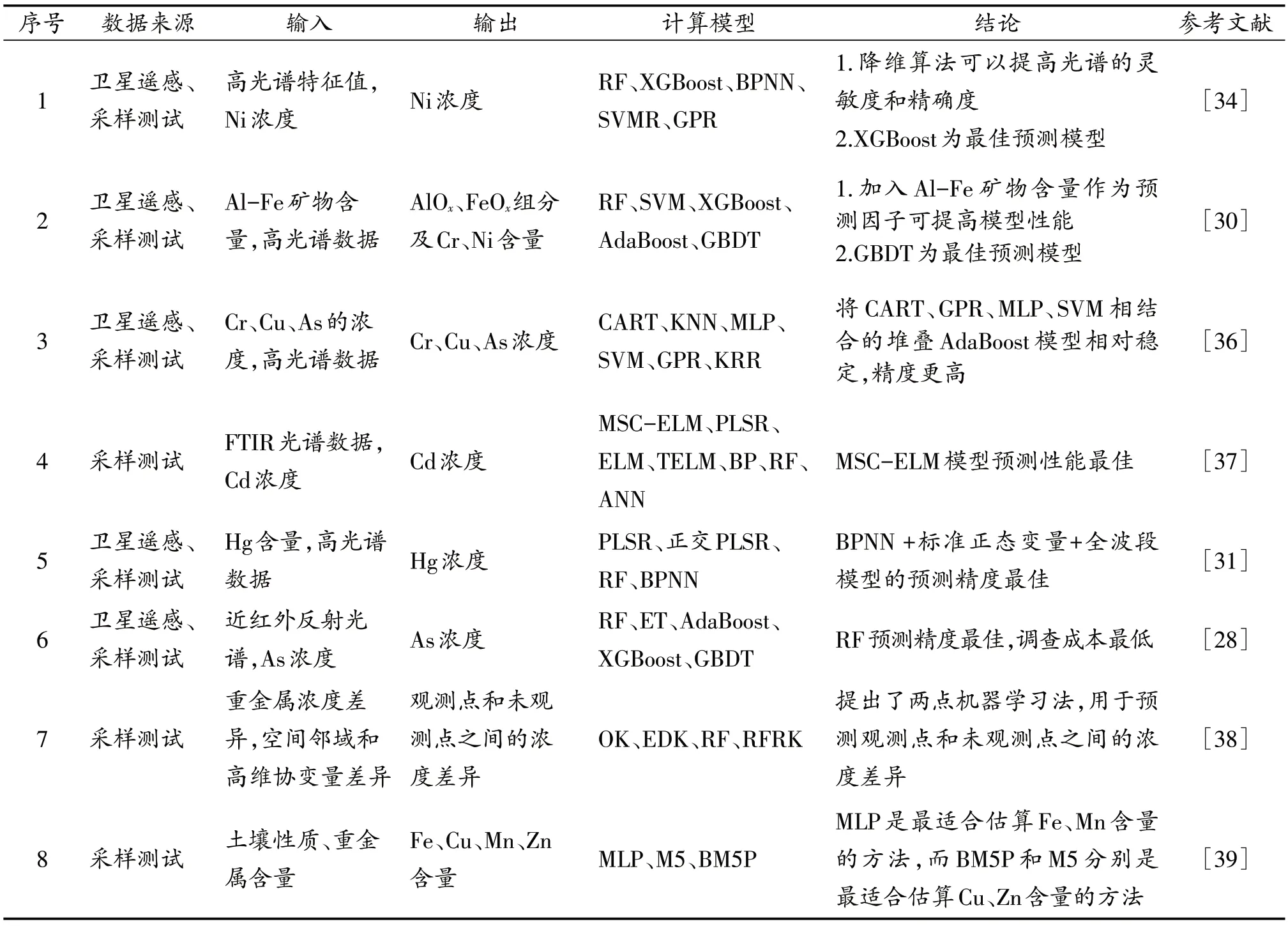
表1 机器学习在土壤重金属浓度预测中的部分应用Table 1 Application of machine learning in soil heavy metal concentration prediction
1.1.2 土壤重金属含量的影响因素
土壤环境是复杂的,没有单一因素可以单独影响土壤重金属含量,各种影响因素之间可能表现出复杂的相互作用。在某些情况下,某一因素可能与土壤重金属含量没有直接关系,但可能与其他因素相互作用,从而影响土壤重金属含量[40-41]。
RF模型使用特征重要性指标来分析影响因素,特征重要性是通过对每个特征的重要度分数进行排序来计算的,这些分数反映了每个特征对模型预测性能的贡献程度[42]。Li 等人[43]使用RF 模型甄别了自然和人为因素导致的Cd 污染,定量评估自然和人为因素对Cd 积累的贡献,并进一步确定了影响因素之间的相互作用。Yang等人[44]使用正交矩阵因子分解(positive matrix factorization,PMF)模型和RF 模型相结合的方法确定了重金属的潜在环境影响。结果表明,不同重金属的关键影响因素不同,例如,影响Cd和Cu浓度的关键因素是与污染源的距离,而As、Ni 和Cr 的关键影响因素则是土壤母质、pH、有机质等。
重金属来源的空间位置也会影响其含量,因此研究者们引入二元局部莫兰指数(bivariate local moran’s I,BLMI)对污染企业网格进行空间分析。Jia 等[45]使用多项朴素贝叶斯(naive bayes,NB)方法对26 万多家企业的地理数据进行了分类,之后使用BLMI 进行了分析,探讨了不同工业类别与土壤Cd和Hg含量之间的关系,例如,过度施肥和采煤是导致地区高Cd 浓度的主要原因。Huang等[46]将NB、RF、BLMI 相结合,分析了某工业地区土壤重金属浓度的影响因素,具体来说,先利用NB 识别出作为贡献因子的250 家污染企业,之后利用RF 测定了影响因素对As、Cd 和Hg 浓度的定量贡献,最后利用BLMI 生成了重金属浓度与关键影响因素之间的空间聚类图,明确揭示了它们之间的相互作用和内在效应。

表2 机器学习在土壤重金属影响因素分析中的应用Table 2 Application of machine learning in soil heavy metal influence factor analysis
1.1.3 土壤重金属分布地图
绘制重金属分布地图是了解土壤重金属空间分布最直观的方式,是针对性地对土壤污染问题进行治理的前提[49]。传统的土壤化学污染调查方法昂贵、费时、费力,而使用机器学习进行数字土壤制图则在便捷性方面拥有显著优势[50]。数字土壤制图基于不同的机器学习模型,这些模型的输入数据来自全球定位系统(global positioning system,GPS)、地理信息系统(geographic information system,GIS)、光谱波、现场扫描仪、遥感数据等[51-53],而机器学习模型的选择对于建模过程和结果都至关重要。
Azizi等人[54]将遥感数据、地形属性、专题地图和土壤属性作为输入参数,评估了RF、立体回归树(cubist regression tree,Cubist)对空间重金属含量分布的预测精度,结果表明,RF 模型对Ni和Cu的预测精度较高,而Cubist模型对Mn的预测性能更佳。Yang 等人[55]从150 篇文献中收集了有关重金属的土壤吸附数据、土壤特性、吸附系统性质,研究了CART、线性回归(linear regression,LR)、随机梯度下降回归(stochastic gradient descent regression,SGDR)、支持向量回归(support vector regression,SVR)、KNN、脊回归(ridge regression,Ridge)6 种传统学习模型和RF、GBDT、XGBoost、极端随机树(extremely randomized tree,ET)4 种集合模型,建立了6 种金属的独立模型,可在已知土壤性质的情况下,预测并绘制土壤重金属的全球分布图。空间插值法是指在给定的有限点数据集上,通过某种计算模型,对未知位置的数值进行估计或预测的方法,被广泛应用于与地理有关的领域中[56-58]。Sergeev等人[59]以空间坐标为输入参数,以元素含量为输出参数建立模型,首先分析了人工神经网络(artificial neural network,ANN)-MLP 和广义回归神经网络(general regression neural network,GRNN)模型的残差(预测值与实际值的差),然后对残差加以普通克里金(ordinary kriging,OK)计算,并将输出与人工神经网络模型相结合,得到MLPRK和GRNNRK模型的预测结果。Song 等[60]使用多元线性回归-普通克里金法(MLR-OK)、支持向量机-普通克里金法(SVM-OK)和随机森林-普通克里金法(RF-OK)的混合统计模型进行土壤重金属空间分布预测和制图,结果表明,OK的引入使模型预测精度(R2)提高了30%。
1.2 重金属固定
固定化是土壤重金属修复的一种有效技术,它具有高效、环境可持续和低成本的优势[61]。生物炭具有比表面积高、孔隙结构发达、易于表面改性等特点,可以通过络合、沉淀和吸附的方式将重金属固定在土壤中[62-63],是常用的土壤重金属修复材料。然而,由于生物炭理化性质的多样性,探究生物炭固定重金属效率的定量构效关系存在着费时、费力、成本高的局限性[64-65]。
机器学习可以基于庞大、复杂和大维度的数据来构建预测模型,为研究生物炭在固定土壤重金属方面的定量构效关系提供了有力工具[66]。Guo等[67]收集了32 篇文献,提取了844 个数据点,使用RF、SVMR、GBDT、LR四种模型预测了生物炭对重金属固定效率,结果表明RF 模型预测效果最佳,其中生物炭投加量、土壤pH和有机碳含量对土壤重金属固定效率的影响最大,且呈正相关关系。Sun 等人[68]从发表的文献整理得到包含74 种生物炭和43 种土壤的数据库,使用ANN 和RF对生物炭固定5种不同重金属和类金属的过程进行建模,通过生物炭特性、土壤理化性质、操作条件和重金属的初始状态对重金属吸附效率进行了预测。由于文献提供的数据类型不一致,作者还评估了各模型对缺失数据的容忍度和插值的可靠性,结果表明ANN 和RF 都具有较好的预测性能,而RF模型具有更高的数据容错性。Palansooriya等[69]从文献中筛选出了20 个变量作为参数输入RF、SVMR、ANN模型,在训练阶段对最佳超参数进行了调整,使用五次交叉验证将预测误差降至最低,优化后的RF 模型预测效果最佳。因果分析表明,影响重金属固定效率的因素依次为生物炭性质>实验条件>土壤性质>重金属性质。
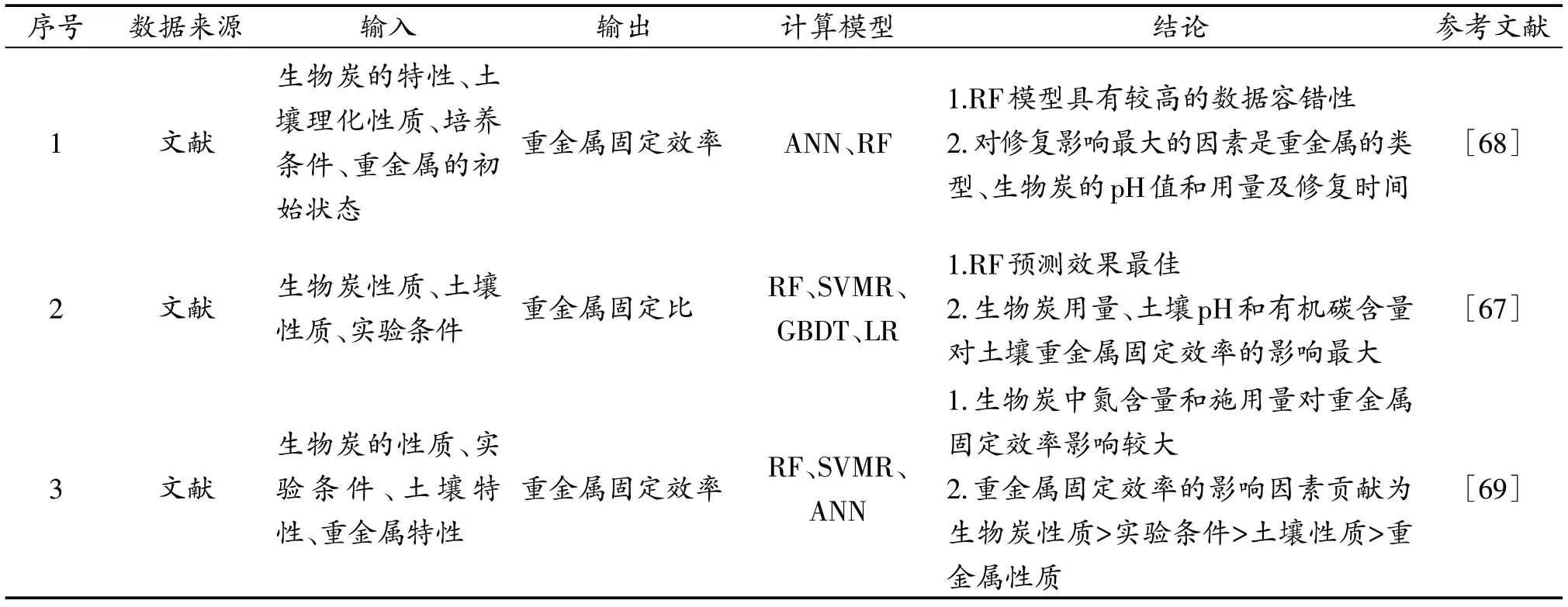
表4 机器学习在重金属固定中的应用Table 4 Application of machine learning in the fixation of heavy metals
1.3 重金属溯源
了解土壤中重金属的来源是治理土壤污染的关键。传统的溯源方法主要包括主成分分析(principal component analysis,PCA)、PMF 和同位素分析[70],其中PMF 模型使用最小二乘法对数据进行迭代计算,并在非负约束条件下评估各因子的贡献,目前已被广泛应用于土壤重金属污染源的量化分析,但是如果数据点之间存在多重共线性,则该方法失效[71-72]。机器学习方法可以建立具有较强预测能力的非线性模型,从而克服上述缺陷。例如RF 可用于确定各种来源对土壤重金属污染的贡献[73],自组织映射(self-organizing map,SOM)作为一种高维可视化方法,已被应用于分析污染源及其分布[74-75]。
Shi等人[76]采用传统的统计分析——PMF和三种机器学习方法——SOM、条件推理决策树(conditional inference tree,CIT)、RF 来识别和评估土壤中不同来源的重金属的贡献,利用PMF 模型得到了各来源的土壤重金属总负荷贡献率占比,利用SOM 模型分析了各种重金属的主要来源,利用CIT模型识别了各种重金属的重要影响因素,利用RF 模型量化并识别了潜在影响因素。Zheng 等人[77]提出了PMF 与GBDT 和SOM 相结合的方法,以量化土壤重金属各种来源的贡献,并从野外采样和地理空间数据中识别相关驱动因素,不仅评估了土壤重金属的浓度和空间分布,还利用GBDT-偏相关图(partial dependence plot,PDP)模型识别了影响污染源的驱动变量。重金属之间的相关性会导致图形结构各元素之间的关系发生变化,但是在使用SOM 模型的研究中,这些关系往往被忽视,导致评估不准确。图卷积神经网络(graph convolutional network,GCN)在自动化的同时能够学习到图的特征信息与结构信息,具有优异的鲁棒性[78-79]。Gao 等[80]首先训练GCN 学习了土壤样本之间的图结构关系,然后使用SOM 和图卷积自组织映射(graph convolutional self-organizing map,GCSOM)将数据可视化,结果显示,GCSOM 得到的数据图具有更大的聚集性和更清晰的分类边界。

表5 机器学习在土壤重金属溯源中的应用Table 5 Application of machine learning in soil heavy metal traceability
1.4 重金属污染风险评估
常用的土壤重金属污染风险评估方法包括单因素污染指数法[82]、污染负荷指数法[82]、Nemerow 综合污染指数法(nemerow integrated pollution index,NIPI)[83]和潜在生态风险评价法(potential ecological risk index,RI)[84]等。随着人工智能和机器学习在各个领域的兴起,人们开始将机器学习与传统评价方法相结合,以更加准确快捷地评估污染风险。RI 可以将重金属的环境生态影响与毒理学相联系,评估任何潜在的生态危害。Huang等[85]根据RI 值使用K-means 将数据集划分为5 种类型,有效覆盖了不同的土壤重金属污染程度,然后利用SVM 构建了风险评价模型,该模型训练集和测试集的准确率均能达到95%以上,具有良好的分类和评价性能。NIPI 可以综合反映重金属对土壤的不同影响,突出重金属高浓度对环境质量的影响,避免因平均而弱化重金属权重的现象。Wang 等[86]首先将土壤样本的可见和近红外光谱(visible and near-infrared spectroscopy,VNIR)进行预处理,测得土壤中重金属含量,计算出每个样品的NIPI和RI值,并将NIPI和RI数值分为不同的风险等级,然后利用PLSR、Cubist、GPR 和SVM 构建重金属含量和2 种污染指数的预测模型,结果表明,SVM 具有较高的预测精度和较强的泛化能力。Zhou等[87]将单因素指数法与NIPI结合使用,单因素定义为pH,NIPI 直接反映土壤重金属超标倍数和污染程度,使用遗传算法(genetic algorithm,GA)-反向传播(back propagation,BP)、MLR、BP、M5 模型树4 种模型预测某地区的重金属污染风险,结果表明,GA-BP 模型具有较快的收敛速度,并且预测精度最佳。
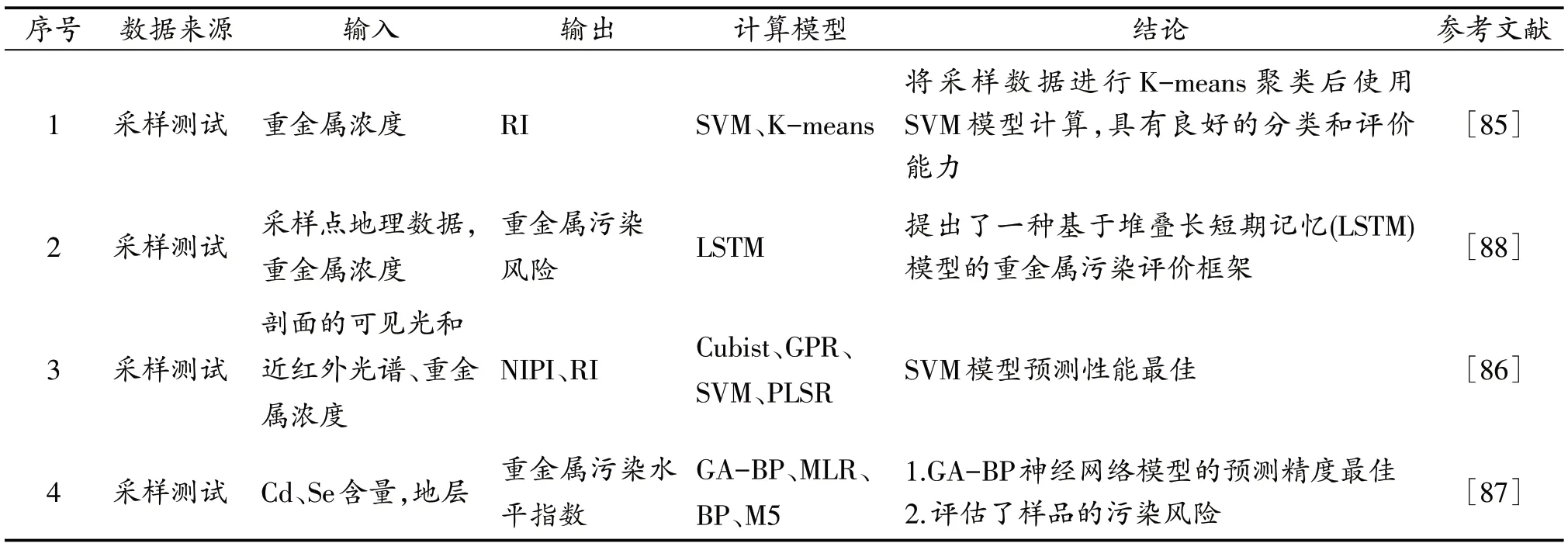
表6 机器学习在土壤重金属风险预测中的应用Table 6 Application of machine learning in soil heavy metal risk prediction
2 总结与展望
机器学习的应用大大提高了土壤重金属研究的效率,已然成为相关研究的热点之一。在土壤重金属浓度预测、重金属浓度决定因素分析、重金属污染溯源、重金属固定剂设计和土壤重金属污染风险评估等方面,机器学习均表现出强大的应用潜力。然而,机器学习在土壤重金属相关研究中的应用还处于初级阶段。具体来说,数据集和算法是机器学习的两大关键要素,而数据集又是模型构建的基础。现阶段数据集的构建主要依赖研究者们自行到各个地点采取上百个样本并进行测定。由于相关数据测定的成本和时效性问题,此类研究往往依旧耗时费力。更严重的是,由于不同研究者数据采集方法之间的差异,不同研究之间的数据往往不能够通用,客观上降低了研究的参考价值。因此,建议依托物联网技术收集整理土壤样本的相关数据集信息,构建平台,以实现低成本、高效率的实时数据共享。
猜你喜欢
环球时报(2022-07-13)2022-07-13 17:18:39
环球时报(2022-03-14)2022-03-14 18:19:44
矿产综合利用(2020年1期)2020-07-24 08:51:42
当代陕西(2019年7期)2019-04-25 00:22:18
领导决策信息(2018年26期)2018-10-12 02:18:26
电影(2018年8期)2018-09-21 08:00:06
中成药(2018年8期)2018-08-29 01:28:16
当代化工研究(2016年6期)2016-03-20 16:21:46
中国资源综合利用(2016年3期)2016-01-22 07:28:21
小猕猴智力画刊(2015年4期)2015-04-28 23:55:53
