
基于十字注意力机制改进U-Transformer的新冠肺炎影像分割
2024-01-02 08:35:50史爱武高睿杨马淑然
软件导刊 2023年12期
史爱武,高睿杨,黄 晋,盛 鐾,马淑然
(武汉纺织大学 计算机与人工智能学院,湖北 武汉 430200)
0 引言
新冠肺炎近年来已成为全球热点话题,对新冠肺炎患者肺部病灶的准确识别与诊断,有助于患者得到及时治疗[1]。新冠肺炎(COVID-19)发生至今已有4 年,2022 年11 月11 日,国务院联防联控机制综合组发布了优化疫情防控二十条最新措施;2022 年12 月8 日,全国包括武汉、广州在内的多个城市进行疫情防控措施调整;2023 年9 月,美国宣布重启免费新冠检测计划。在疫情防控常态化的背景下,借助人工智能技术辅佐医生利用COVID-19 患者CT 影像诊断病情,使用图像分割技术先行将病灶进行清晰分割,可方便医生临床诊断用药,对于减轻医疗系统负担具有重要的现实意义。在新冠肺炎诊断中,使用CT 图像进行影像学检查是安全、有效的[2]。目前对于肺部CT片进行病灶分割有支持向量机和深度学习的方法。邵欣蔚[3]利用支持向量机算法对儿童社区获得性肺炎进行分类,分类准确率可达到90%。但采用支持向量机处理医疗影像,在数据量较大时存在效率低、准确率得不到保障的问题。近年来,以卷积神经网络为代表的一大批深度学习方法在影像学分类中得到了应用。2017 年,刘长征等[4]使用7 层卷积神经网络对400 例肺炎患者的CT 影像资料进行分类,准确率相较于支持向量机算法提高了5.7%,但该方法无法有效去除背景对病灶区域分割的干扰;2018 年,Rajpurkar 等[5]采用自己提出的121 层卷积神经网络,针对ChestX-ray14 上11 种肺部疾病检测的准确率与放射科医生的诊断结果相似甚至更优,但其对全局特征的关注存在不足;2021 年,Li 等[6]提出一种基于不确定性引导的深度学习神经网络,该网络对肺部CT 影像资料检测的准确率达到了77%。如 今U-Net[7]、V-Net[8]、3D U-Net[9]、DenseUNet[10]、Y-Net[11]也被应用于各种医疗影像分割中,这些方法在许多困难的数据集中都取得了令人印象深刻的效果,但在纯粹的卷积模式中,每个卷积核只能关注局部而不是全局上下文。目前有一些数据集引入Atrus 卷积[12]和注意力机制[13-20]来解决卷积网络导致的全局依赖不足的问题,但均存在对小病灶的关注不足、对病灶边缘描绘不够精确的问题。
本文针对目前已有算法对病灶边缘检测精确度不高、容易忽略小病灶的问题,提出一种基于U-Transformer 和注意力机制改进的分割网络,在网络的跳转链接添加自定义注意力模块,用于增强对于病灶区域的感知识别,并采用全局—局部分割策略,以期改善传统分割模型对医疗影像分割全局上下文关注不足的问题,从而使对小病灶特征点的识别更加准确。
1 相关工作
计算机断层扫描(CT)图像是最常见的胸部医疗影像,对其进行病灶影像统计和纹理特征分析被广泛应用于定量描述病灶图像特征[21]。
1.1 新冠肺炎CT影像表现
在新冠肺炎影像诊断过程中,不同严重程度的新冠肺炎患者具有不同的胸部图像特征[22],如图1所示。
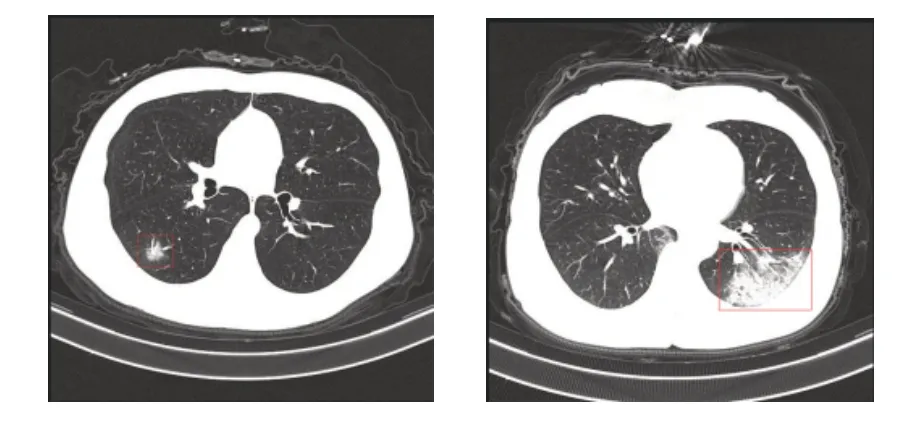
Fig.1 CT images of COVID-19 patient图1 新冠肺炎患者肺部CT图像
新冠肺炎患者肺部CT 上最常见的特征是毛玻璃混浊(Ground-Glass Opacity,GGO)和实变(Consolidation,CL),随着病情的加重,GGO 和CL 的数量增加,其主要分布在肺部边缘。当病情改善时,病灶会被吸收形成纤维化条纹[23-26]。
1.2 U-Transformer网络框架
医疗图像分割对于分割边界要求较高,虽然FCN 在图像语义分割任务中性能优于CNN,但并不适合作为医疗图像分割的基本网络框架。2021 年,Petit 等[27]结合UNET 与Transformer 优势研发了U-Transformer 网络,使其在医疗图像分割中具有更好的性能。其借助自注意模块(MHSA),利用编码器特征之间的全局交互,跳过连接中的交叉注意力(MHCA)模块,允许过滤掉非语义特征,之后在 U-Net解码器中进行精细的空间恢复,以克服U-Net 在分割时对于长期上下文相互作用和空间依赖性运用不足的问题。
2 改进的自注意模块
2.1 十字注意力模块
MHSA 模块意在从UNET 网络中提取全局结构信息,因此其位于UNET 网络的最底部。MHSA 模块的主要目的是将最深层特征图中的每个元素相互链接,让上层结构均可以访问包括所有输入图像在内的感受野,从而使一个特定像素的决定受到全部输入像素的影响。注意力公式如下:
其中,Q 表示查询矩阵,K 表示键矩阵,V 表示值矩阵。softmax 为每个输出分类的结果都赋予一个概率值,表示属于每个类别的可能性,如式(2)所示:
其中,Zi为第i 个节点的输出值,C 为输出节点数量,即分类的类别数量。
本文对注意力模块进行优化,提出十字注意力方式(Criss-cross,CC)进行注意力感知,如图2 所示。本文在水平和垂直条纹中并行执行自注意计算,通过将输入特征拆分为等宽的块来获得每个条纹。这种条纹宽度(Shaped window,Sw)是十字形窗口的一个重要参数,因其可以在限制计算成本的同时实现强大的建模能力。根据网络深度调整条带宽度:浅层的宽度较小,深层的宽度较大。

Fig.2 Criss-cross attention method图2 十字注意力方式
(1)输入特征X∈R(H×W)×C 首先线性投影到k个头部上,然后每个头部在水平或垂直条纹范围内进行局部自注意力操作。X 被均匀划分为不重叠的水平条纹 [X1,..,XM],每个水平条纹都包含Sw×W 标记。Sw 是条带宽度,可以通过调整来平衡学习能力与计算复杂度。形式上,假设第k 个头部的投影查询(Q)、键(K)和值(V)都具有维度dk,则第k 个头部水平条纹自注意输出的定义如式(3)所示:
其中,Xi∈R(Sw×W)×C,M=H/Sw,i=1,...,M。dk,分别表示第k 个头部查询、键和值的投影矩阵,并且dk 设置为C/K。垂直条纹自注意也可类似地进行推导,仅需修改注意力矩阵划分模式即可,其第k个头部的输出表示为V-Attentionk(X)。
(2)假设输入图像没有方向偏差,本文将k 个头部平均分成两个平行组(每组有k/2 个头部,k 通常是一个偶数值)。第一组头部执行水平条纹自注意操作,第二组头部执行垂直条纹自注意操作。最后,这两个并行组的输出将重新连接在一起,如式(4)所示。
其中,WO∈RC×C是常用的投影矩阵,其将自注意结果投影到目标输出维度(默认设置为C)。
如上所述,在本文的自注意机制设计中,最重要的是将K 分成不同的组,并相应地应用不同的自注意操作。相比之下,现有的自注意机制在不同K 上应用相同的自注意操作。本文方法的计算复杂度如式(5)所示:
对于高分辨率输入,考虑到H、W 在早期阶段大于C,在后期小于C。本文早期选择较小的Sw,后期选择较大的Sw,并将Sw 设置为可变参数,提高了算法的灵活性,可以在后期以有效的方式扩大不同层级的注意力区域,在注意力的感受和性能方面优于原先的自注意力模块。
2.2 位置投影模块
自注意的排列方式是不变的,并且忽略了标签的位置信息,时常向注意力网络中引入位置编码,尤其在COVID-19 的病灶检测中。医学图像中病灶分割的空间依赖性强,本文为在分割中更好地使用位置编码,提出将位置编码与自注意计算分开计算的方式,以使位置编码更好地辅佐分割网络对病灶部分进行精准分割。其位置投影模块如图3所示。下文将解释PE 模块的计算以及最后的融合公式。

Fig.3 Position projection module图3 位置投影模块
本文的PE 模块位置信息计算公式如式(6)所示。本文将输入序列表示为x=(x1,...,xn)的n 个元素,并且输出相同长度的注意力z=(z1,...,zn),其中xi,zi∈RC。自注意计算可表述为:
其中,qi、ki、vi是队列(Q)、键(K)和值(V)通过输入xi与d的线性变换得到位置信息。zi第k个元素的计算公式如式(7)所示:
2.3 改进后的CCUNET模块
(1)CCUNET 主体结构如图4(a)所示。每一层使用3*3*3 的卷积核进行卷积、批标准化(Batch Normalization,BN),再进行RELU 激活。下采样采用2*2 的卷积核进行最大池化,上采样中下层向上层传递数据采用1*1 的卷积核进行通道缩减采样,之后进行BN,再进行RELU 激活。上采样采用2*2 的核采样后,用3*3 的卷积核还原尺寸,在最深层次添加一个十字多头自注意(Criss-Cross Multi-Head Self-Attention,CCMHSA)模块。CCMHSA 模块结构如图4(b)所示。

Fig.4 CCUNET network structure图4 CCUNET网络结构
(2)CCMHSA 接受一个(w,h,d)大小的图像特征数组,然后以wd 为面进行positional encoding,再分别送入CC 和PE 模块计算注意力矩阵以及位置信息,之后进行叠加运算,计算公式如式(7)所示。
(3)CCMHCA 仅修改了原U-Transformer MHCA 模块中的MHSA 部分,其他部分没有变化。其在用于上采样时更多地关注全局信息,扩大每层感受阈,其具体结构不再赘述。其中,每一层CCMHSA 模块的Sw 参数设置为[1,2,7,7]。
2.4 改进后的U-Transformer网络
本文最终设计出基于全局—局部策略以及CCUNET网络的GP-CCUNET 用于COVID-19 患者CT 影像检测,其网络结构如图5 所示。该网络同样分为全局部分和局部部分两条分支,其中全局部分4 层CCUNET 的Sw 参数选取为[1,2,7,7],局部部分3 层CCUNET 的Sw 参数选取为[1,2,7]。切片图过大的感受野不但无法提升分割精度,而且会降低与全局分支的互补性,导致整体网络的分割精度下降。最后,对切片图进行重定向后,对特征图以1:1 的权重进行叠加,得到分割结果。下文将用实验证明该模块中每个模块间均具有互补性,可以有效提高针对COVID-19患者CT 影像病灶的分割精度。
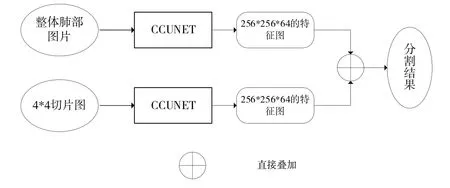
Fig.5 GP-CCUNET network structure图5 GP-CCUNET网络结构
3 实验与分析
3.1 数据来源
本文实验所用到的数据均为从Kaggle 下载的公开标注的COVID-19 数据集。将MosMedData、Coronacases、COVID-19 detection 全部按高度轴切割,将切割出肺部区域的原始 CT 影像和对应的 GT 影像转换成 2D 的切片,并按照患者序号进行保存,获得了39 000 张图片,其中包含肺部图像约26 000 张。每张图像的原始分辨率为512×512,本文将其放缩为256×256,并将灰度值截断为 [-240,160]再归一化到[0,1]。同时调整其窗宽为[-1 000,600],将 CT切片保存为 jpg 图片,将 GT 切片保存为 png 图片。
3.2 评估指标
医疗图像分割问题可被转化为病灶区域(即前景)与背景的分类问题。当样本是正类,分类器将其正确预测为正样本时,称为TP(True Positive);正样本被错误地预测成负样本时,称为FP(False Positive);相应地,当负样本被准确预测成负类时,称为TN(True Negative),负样本被预测为正样本时称为FN(False Negative)。由此得到精度和召回率计算公式如式(8)、式(9)所示。
当新冠肺炎的分割正负样本数量不均衡时,导致精度及召回率并不能很好地衡量分割效果,所以本文引入F1系数。F1系数是一种用于度量集合相似度的函数,表示分割结果与原医生专家标注结果的重叠率,如式(10)所示。F1系数越高,证明分割结果越接近专家的分割标准。
3.3 实验结果比较及分析
本文针对CCUNET,采用不同的Sw 参数进行实验,结果如图6 所示。其中,FLOPS 为运算时间,F1 为评价指标中的F1 分数,F1 越高则分割越精确。从图中可以看出,当Sw=1 或2 时,感受窗口大小不足,感受野不够大,准确率较低。当Sw 为[1,2,7,7]、7 时准确率几乎一致,是因为高层网络进行训练时,并无过多信息需要感受,信息密度也并不大,不需要设置7 大小的窗口进行注意力感知。从[14,14,14,7]、[28,28,14,7]两个模块可以看出,再增加Sw 的大小,会大幅增加十字注意力模块的运行时间,但F1 的效果提升并不明显。所以本文最终选取[1,2,7,7]作为CCUNET 的Sw 参数。
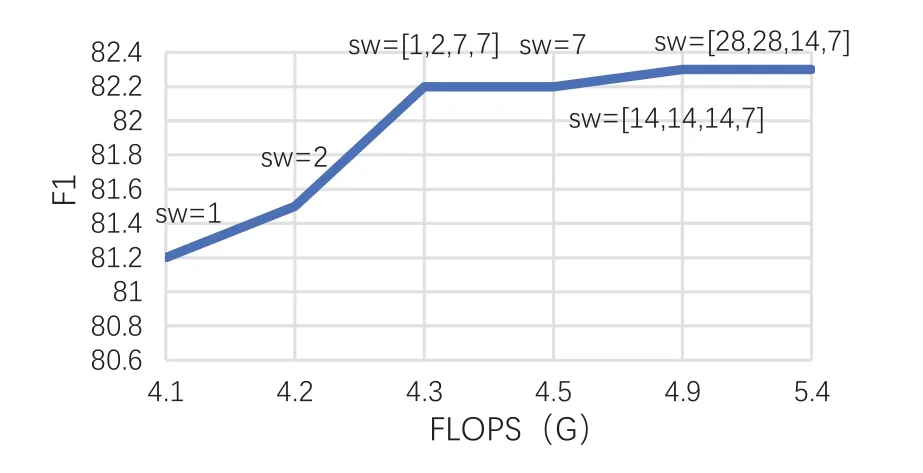
Fig.6 Experimental results of different Sw parameters图6 不同Sw参数实验结果
为证明各模块的有效性,本文进行了CCMHSA、CCMHCA 与 MHSA、MHCA 混合搭配的消融实验,实验结果如表1 所示。由实验结果可以看出,本文两个模块相较于基准网络模块在本文数据集识别上均有所提升,其原因在于本文在原模块的基础上使用十字注意力方式获得了更大的感受野,并添加位置信息模块,从而增强了模块对目标肺炎区域检测的准确度。

Table 1 Inter-module ablation experiments表1 模块间消融实验
将CCUNET、GP-CCUNET 与基线网络U-Transformer以及目前角膜分割效果最好的网络MBT-NET 进行实验对比,实验结果如表2 所示。由CCUNET 与U-Transformer 的F1结果可以发现,将多头自注意力模块替换为十字自注意力模块有助于提高对本文数据集的分割精度,且准确率和召回率分别提升了2.8% 与3%。对比GP-CCUNET 与CCUNET 可以发现,采用全局—局部策略进行双线分割,之后进行特征融合的方法,在使用CCUNET 作为基础网络结构后仍可以发挥很好的互补效用,提升分割精度,并且在本文数据集上比在其他领域分割效果很好的MBT-NET的F1 值高出1.1%,证明本文方法可以有效提高分割精度。
各个网络的分割结果比较如图7 所示。在此处选取了比较经典的分割图进行了比较,由第1 行的橘色框可以看出,GP-CCUNET 的分割蒙板与MBT-NET 和GT 图最为接近,且由第1 行的蓝色框可以看出,CCUNET 的边界识别精度明显变高;由第2 行的黄色框则更能清晰地看出,GPCCUNET 和MBT-NET 能更好地识别与背景相似的复杂病灶边界,并将其精准标明;第3 行是病灶块多且边界异常不明显的COVID-19 患者CT 图,可以看出GT-CCUNET 精准地将蓝框中的细节病灶标注了出来,显现了本文改进方法的有效性;第4 行为网络的负面效果图,由于采用全局—局部融合的策略,本文方法对于不太明显但分布十分密集的小病灶的识别能力并不强,而MBT-NET 对其的分割效果不错。该分割结果证明了十字注意力模块、位置信息的加入以及采用全局—局部的分割策略,均有助于实现对COVID-19 病灶的精准分割。在特征提取过程中,全局策略与局部策略具有互补性。

Fig.7 Comparison of segmentation results using different methods图7 不同方法分割结果比较
本文提出的网络继承U-Net 的优势,相较于SE-Net 等单纯的注意力网络仅需使用少量数据集便可完成训练,这对于标注困难的医疗影像方面的病灶分割与识别很重要。相较于DA-Net,本文网络采用的十字注意力模式可以调整窗口设置以获取更多的上下文信息。DA-Net 的位置模块被内嵌于注意力模块,而本文网络的位置模块与注意力模块分离,可以根据不同环境设置不同权重以提高分割精度。
综上所述,针对新冠肺炎的病灶提取,本文方法相较于传统分割方法具有更好的分割性能和更强的抗干扰能力,对于复杂背景下的分割依然可以达到较好的分割效果,识别出病灶点并进行分割标注,使得本文方法在新冠肺炎的CT 检测中具有一定的应用价值。
4 结语
针对肺部CT 片病灶检测中出现的小病灶检测困难、背景与病灶部分像素差距小的问题,本文对U-Transformer网络的卷积结构进行改进,使用注意力核替换卷积核进行学习,解决了传统卷积方法对图片全局信息学习不足的问题,并采用全局—局部的分割策略先分开分割再整合信息,使得网络可更好地识别病灶部位的边界以及小的病灶区域。实验结果表明,相较于传统分割方法,本文方法对于新冠肺炎病灶的分割在边界定位的准确度以及对小病灶区域的识别检测上具有显著优势。但该方法对于较不明显的病灶区域检测还存在着一定误差,下一步将进一步研究新冠肺炎CT 片的特征,以期获得更好的检测效果。
猜你喜欢
数学物理学报(2022年4期)2022-08-22 04:07:12
数学物理学报(2022年2期)2022-04-26 14:08:04
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
电子制作(2019年11期)2019-07-04 00:34:38
金桥(2018年4期)2018-09-26 02:24:54
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
传媒评论(2017年3期)2017-06-13 09:18:10
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
中国卫生(2014年5期)2014-11-10 02:11:26
