
一种基于投票的ICT类课程学生在线学习成绩预测模型
2024-01-02 08:35殷锡亮张琳琳杨兴全周德云
软件导刊 2023年12期
殷锡亮,张琳琳,罗 洋,杨兴全,周德云
(1.哈尔滨职业技术学院 电子与信息工程学院,黑龙江 哈尔滨 150081;2.黑龙江交通职业技术学院 信息工程系,黑龙江 哈尔滨 150025;3.黑龙江职业学院 信息工程学院,黑龙江 哈尔滨 150070)
0 引言
2020 年初,各行各业因疫情受到不小影响。依据教育部“停课不停学”的指导意见,全国各高校普遍采用线上教学替代或补充线下教学的方式以开展教学活动,这一举措为教学的顺利开展提供了良好支撑。与线下教学相比,线上教学可获得较好的教学效果[1-2]。然而,在线学习过程中,难免有学生因自律性差而导致学习效果不佳。针对这种情况,一种较好的途径是利用在线教学平台提供的学生学习过程数据,结合教学过程中进行的问答、测试等,设计学生学习预测模型。利用此模型,可以对预期学习效果不佳的学生进行提前预警,此外,还可对不同学生进行有的放矢地重点帮扶。
然而,近年来针对高等职业院校学生的在线学习预测模型研究少之又少。因此,本文通过对高职院校信息通讯技术(Information and Communication Technology,ICT)类课程的在线教学过程数据分析,提出了一种基于投票的学生在线学习成绩预测模型,在学习过程的早期对学习效果不显著的学生进行预警,从而帮助教师提高在线教学整体质量和效果。
1 相关工作
在线教学效果评估方法是近年来在线教学研究领域的重要方向之一。研究方向大致分为两类:一类是对理论模型的研究,另一类是采用机器学习模型针对在线教学或学生学习效果给出具体指标。
廖卓凡等[3]提出一种双循环互促的计算机专业课在线教学方法和评估设计框架。针对评估手段,采用高频度低频率作业与实验配合自动化在线测试系统,随之形成一个内循环,从而及时反馈教学效果。Hu 等[4]针对编程类课程提出一种多元学习评价模型,学习行为由数据流评估。数据流分为4 类,包括学习指导、理解创新、互动分享和学习支持。使用各项指标进行相关性分析,得到学习活动中生成的结构和非结构化的数据流,并将其作为参数体现在多元学习评估模型中,进而将结果可视化给学习者。从评价主体、评价内容和评价形式3 个维度对整个教学过程以及学生学习效果进行评价。根据在线教学平台提供的数据,将学生分为3 种:①喜欢提问的学生;②喜欢回答问题的学生;③既不喜欢提问也不喜欢回答的学生。结合学生在线学习预测模型,建议教师或者教学管理者及时关注这类学生并进行必要干预。
郝翠萍[5]以“大学英语”为研究基础,提出一种基于多元线性回归的考试成绩预测模型,分别以高考成绩、平均成绩、分级成绩和期末卷面成绩为特征自变量,以大学英语四级考试成绩为目标变量,利用显著性校验剔除对目标变量影响较小的特征变量,最后利用3 个学期的期末考试成绩对大学英语四级考试成绩进行预测,获得了较好效果。王涛涛等[6]使用“大学生就业指导”课程的在线学习数据,选择讨论区总帖子数量、总在线学习时间、同学评价、查看课程资源的次数、讨论区回复帖子数量5 个特征作为自变量,使用二元逻辑回归对学生该门课程的成绩进行预测,准确率达77.3%。王改花等[7]以“现代教育技术”在线开放课程为研究对象,以学习时间跨度、平均在线学习停留时长、重复学习率、讨论交流、学习笔记、期末考试成绩为特征变量,并将该门课程总成绩离散化为4 类,对学生该门课程的总成绩进行分类预测。对比多种决策树模型预测结果,对影响学生最终成绩的因素进行分析。林青等[8]提出一种基于随机森林的在线教学评估方法,使用其所在院校开设的《程序设计基础》《大学计算机基础》《线性代数》3 门课程的学生在线学习数据,选择观看网络广播视频和PPT 时间、课堂问答、课后思考题、作业以及在线测试分数为特征变量,对学生最终学习成绩进行分类预测。
此外,有研究人员针对学生的在线学习行为利用深度学习、计算机视觉等技术进行了更为细致的分析。文献[9]提出一种基于眼动信号、音频信号和视频图像的多模态情感识别方法,其核心是两种新型的特征,一种称为眼动坐标差特征,代表学习者的集中度,另一种称为像素变化率序列,代表图像切换速度。依据上述特征使用卷积神经网络模型将在线学习者的在线学习情绪分为感兴趣、高兴、困惑和无聊4 类。李磊[10]基于人脸检测和识别、头部姿态估计、表情识别等计算机视觉技术,搭建面向在线教学效果评估的头部姿态及表情识别系统,分析在线学习者的行为和情绪,根据检测结果给出本次课程学员状态的综合评估结果。从理论角度出发,上述科学研究结果可用于发掘预测模型中的新特征。
然而,以上针对在线学习成绩预测模型的实现方法都以普通本科教学为研究对象,且选择课程面较窄,本文使用多种机器学习模型,以高职教学为研究对象,选取多门课程数据进行比对,提出一种新的基于投票的学生在线学习成绩预测模型。
2 高等职业院校ICT类课程
课程是承载教学的基本单元,课程改革是目前高等职业教育改革的核心。高等职业院校专业课程教学与教学效果评估过程与普通本科院校存在明显差异,例如强调能力培养、普遍采用过程性考核方法等。结合中国特色高水平职业院校建设要求,课程一般包含PPT、微课、教学视频、试题库、虚拟实训平台等多种教学资源。在教学过程中,教师会充分利用这些教学资源,提升教学效果。ICT 类课程开设于计算机、通信等专业,专业教师具备较高的信息技术素养,在利用多媒体等技术教学方面具有先天优势。因此,在线上教学中,ICT 类课程教师可以充分地将在线教学平台融入到教学过程[11]。
为深入贯彻“深化产教融合、校企合作”的根本任务,对接区域战略性新兴产业人才需求,依据行业岗位知识、能力、素质需求,对计算机、通信专业课程进行三维一体化的课程体系重构。其中,三维指对ICT 类课程进行三个维度的分割,第一个维度从知识层面分为基础课、核心课和综合课;第二个维度从技能层面分为信息技术(Information Technology,IT)工程师课程和通信技术(Communication Technology,CT)工程师课程;第三个维度从素质层面分为1+X 认证、企业初级认证和企业中级认证。一体化指以计算机网络技术和移动通信技术专业为支撑,辐射相关专业并用类似模式形成一体化的ICT 集群。课程性质分为理论实践结合和实践课两种。所有课程均配套相关的实训软件或平台。由于ICT 类课程具备一定的共性,因此基于该类课程研究在线教学中学生的学习成绩预测模型。ICT类课程体系如图1所示。
3 基于投票的预测模型
3.1 投票模型
机器学习模型通常在训练集上预测或者分类效果较好,而在测试集上效果较差,又或者在某一个数据集上效果较好,而更换另外一个数据集后性能变差。为了克服这种问题,集成学习应运而生,其原理是将多个弱学习器集成为一个强学习器,投票是集成学习中的一种,在金融[12]、商业[13]、医学[14]、生态环境[15]、计算机科学[16]等领域均有较好的预测效果。投票模型框架如图2所示。
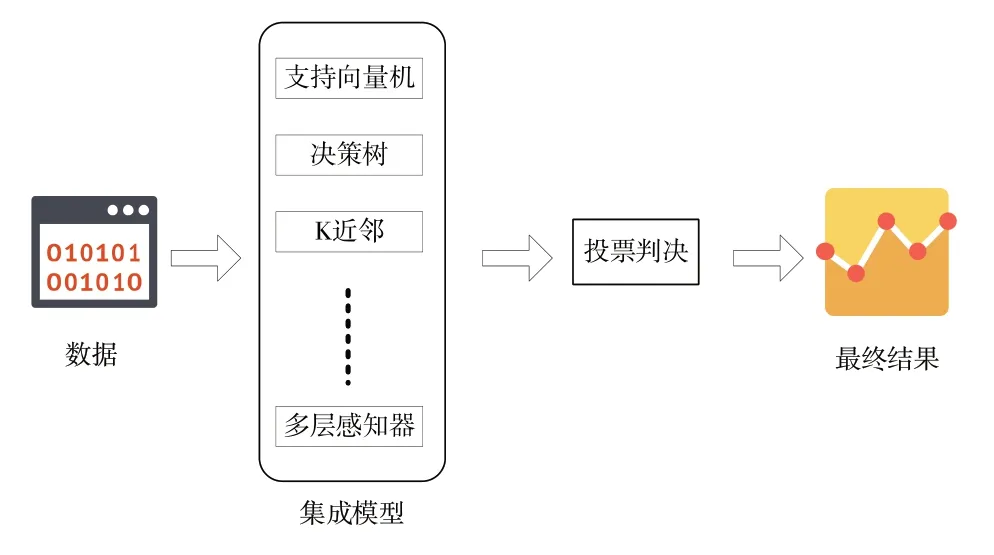
Fig.2 Frame of voting model图2 投票模型框架
投票模型一般分为硬投票和软投票两类。对于硬投票,其原理是首先统计集成模型中弱学习器的结果,然后选取票数最多的结果为最终结果;而软投票是将若干分类器的平均结果作为最终的结果输出,其中平均可以是算数平均值也可以是加权平均值[17-18]。该过程类似学生的学习过程,比如一个学生的论文提交给审稿人审阅,学术委员会根据不同审稿人的意见对学生论文的成绩给予最终评定。因此,从理论角度出发,基于投票的集成学习在评估学生在线学习效果时具有可解释性。
3.2 ICT类课程在线学习预测模型
对于ICT 类课程中的考试课程,教师往往需要对学生考试成绩给出具体分数值,学习过程中,一般以学习进度(包括学生线上签到、在线学习时长)、学习习惯(重复观看视频次数)、课堂互动(课堂问答)、平时成绩(作业或任务完成情况)、项目测验(阶段性考核)等5 个方面衡量学生在线学习效果,记为特征向量x=[x1,x2,x3,x4,x5]。将最终考试成绩记为y,因此可以建模为一个回归问题。对于ICT类课程中的考查课程,只需要针对学生成绩给出分级。在学习过程中,教师一般以出勤表现(学生线上签到、在线学习时长)和课堂表现(课堂中任务完成情况、课后作业完成情况)衡量学生在线学习效果,记为特征向量xˉ=[x1,x2,x3,x4]。将最终考核成绩记为yˉ∈[1,2,3,4,5],与考试课程仅建模为回归问题不同,考查课既可建立为回归问题也可建立为分类问题。预测模型与回归问题和分类问题无关,预测模型表达式为:
其中,n代表弱学习器的个数,wi代表第i个弱学习器的权重,fi代表第i个弱学习器的建模函数。当课程为考试课并且y<60 时或者当课程为考查课并且y=1 时,对学生进行学习预警。
4 应用实验
4.1 实验环境
本文实验环境如表1所示。

Table 1 Experiment environment表1 实验环境
4.2 实验数据集
本文选取网络技术应用、HCIA 进阶2 门考试课,宽带接入技术、Web 前端脚本技术、Python 程序设计3 门考查课程的在线教学过程数据为实验数据集。其中,网络技术应用是精品在线课,其余课程为一般课程。这些课程分别由3 个院校的5 名教师讲授。有效参与在线学习的学生人数共计541 人。网络技术应用与HCIA 进阶课程较难,学生成绩相对较差,不及格比例均超过20%。而另外3 门课程为考查课,学生成绩相对较高,不及格学生占比低于0.5%。虽然考查课成绩相对较高,预测模型对成绩较差学生效果不显著,但也可以作为教学过程中的辅助工具,引导学生取得更好的学习效果。5门课程的成绩分布如图3所示。

Fig.3 Distribution of the final academic achievements of different students in five courses图3 5门课程的不同学生最终学习成绩分布
4.3 实验参数
对于回归问题,分别使用线性回归、决策树、随机森林、多层感知器、支持向量机回归、K 近邻、梯度提升、直方图梯度提升等模型与投票模型进行比较。对于分类问题,分别使用逻辑回归、决策树、随机森林、多层感知器、支持向量机、K 近邻、梯度提升等模型与投票模型进行比较。投票由决策树、随机森林、梯度提升、支持向量机模型构成,选择软投票方法,权重选择均匀分布。
首先使用最大最小化方法对特征向量进行预处理,然后使用交叉验证法和格子搜索法分别寻找每个模型的超参数最优值,最后使用随机抽样法进行100 次实验,取平均值作为每个模型的最终预测结果。实验参数如表2所示。

Table 2 Experiment parameters表2 实验参数
4.4 基于回归模型的实验结果
网络技术课程有效在线学习学生人数为151 人,任课教师使用平时成绩、学习进度、学习习惯、互动、章测试5个维度指标评测学生的在线学习过程情况,最后使用期末考试的方法测验学生学习效果。在网络技术课程数据集上,基于投票的预测模型的均方根误差、绝对误差和中值误差分别为13.31、9.13 和6.7 分,其中只有中值误差略高于随机森林、决策树和支持向量机模型,均方根误差和绝对误差均比其他模型低。使用线性回归、决策树、随机森林、多层感知器、支持向量机、梯度提升、K 近邻、直方图梯度提升和投票模型构建的预测模型在网络技术课程数据集上的误差比较如图4所示。
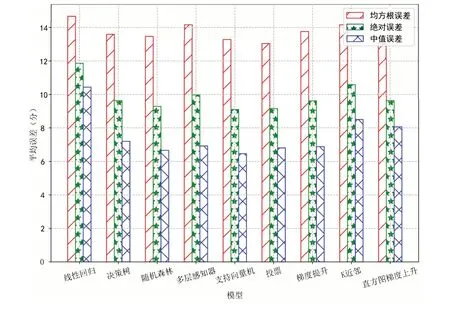
Fig.4 Comparison of prediction errors based on different machine learning model图4 基于不同机器学习模型的预测误差比较
此外,分别使用学习过程中的25%、50%、75%和100%进度数据对学生期末考试成绩进行预测,得到基于投票的预测模型的误差如表3所示。
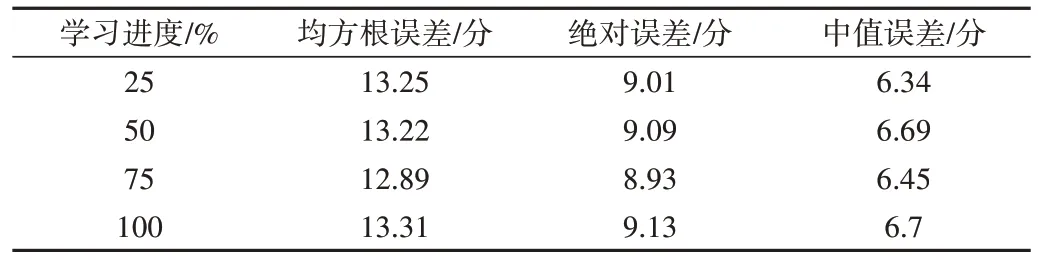
Table 3 Prediction errors of prediction model based on voting under different learning rates表3 基于投票的预测模型在不同学习进度下的预测误差
由表3 可知,基于投票的预测模型在不同学习进度条件下的误差变化不大。使用网络技术课程中的平时成绩、学习进度、互动3 个特征维度进行最优模型参数搜索,再将模型用于HCIA 进阶与光纤技术2 门课程数据集上。这两门课程都采用课件学习、课堂活动和作业以评估学生平时在线学习效果,而在期末采用考试方式考核学生综合学习效果。两门课程共计有64 名学生有效参与在线学习,鉴于学生人数较少且教师采用相同的指标考核,将这两门课合并进行预测。基于投票的预测模型的均方根误差在10 分、12 分、14 分、16 分、18 分、20 分以内的概率分别为12%、29%、72%、86%、99%、100%。投票模型基于线性回归、随机森林、梯度提升3 种学习器集成,权重选择均匀分布。各种预测模型的均方根误差累积概率比较如图5所示。
4.5 基于分类模型的实验结果
对于Web 前端脚本技术,教师分别使用考勤、平时作业、答题、笔记和作品5 个维度衡量学生在线学习效果,对于Python 程序设计,教师分别使用出勤、作业、笔记、课堂表现4 个维度衡量学生在线学习效果。鉴于考勤中学生数据区分度较低,在本文实验中将该维度特征剔除,使用剩余维度特征对学生期末成绩给予分类预测。此外,由于学情因素,教师普遍采用鼓励性的评估手段,在使用分类模型评估时会因为样本不均衡导致性能下降。为了克服该因素,对此类课程均使用三分级制衡量学生最终成绩。在进行模型训练时,仍然采用逻辑回归、决策树、随机森林、多层感知器、支持向量机、K 近邻、梯度提升和投票共计8 种经典的分类模型进行比较。与上述回归模型实验方法类似,首先使用最大最小化方法对特征向量作预处理,然后使用交叉验证法和格子搜索法分别寻找每个模型的超参数最优值,最后使用随机抽样法进行100 次实验,取平均值作为每个模型的最终评估结果。图6 展示了随机测试中使用基于投票的预测模型在Python 程序设计课程数据集上的分类混淆矩阵。
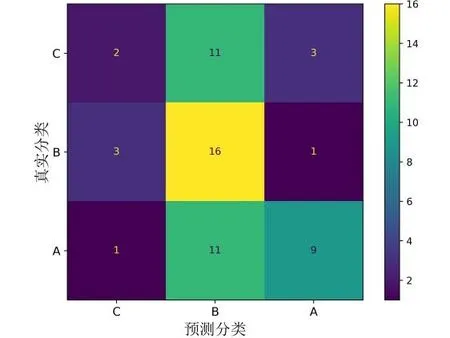
Fig.6 Confusion matrix of prediction based on voting图6 基于投票的预测混淆矩阵
在评估分类模型性能时,本文选择准确率、加权平均召回率、加权平均精确率、加权平均F1 分数以及马修斯系数共计5 项评估指标进行比较。在Web 前端脚本技术课程数据集的测试中,其测试集的各种分类评估指标对比如表4所示。
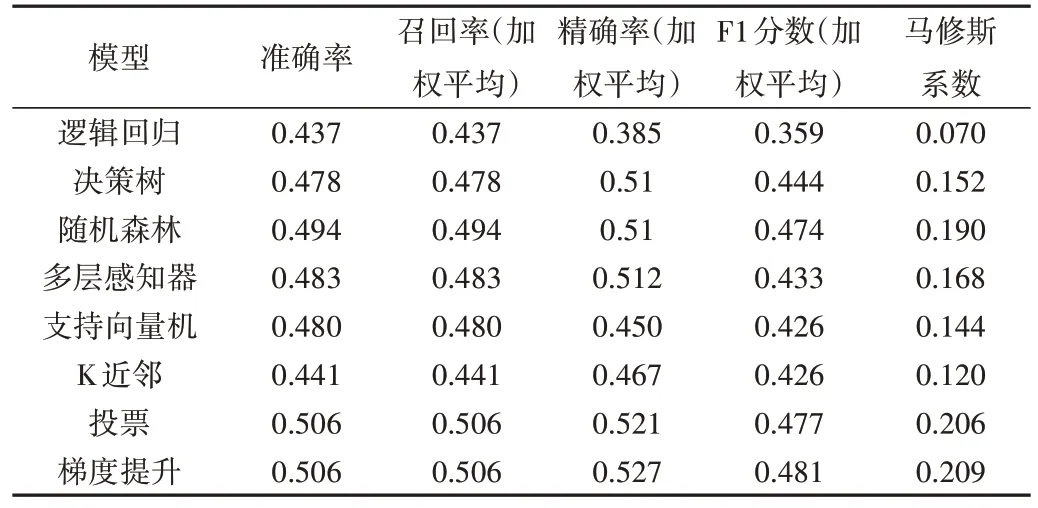
Table 4 Comparison of prediction metrics for classification model表4 分类模型预测指标对比表
通过分析表4 可知,Web 前端脚本技术和Python 程序设计两门课程的成绩分布相差较大,使用分类不均衡样本构建的分类模型在评估测试集时性能较差,这意味着在构建考查课程的预测模型时需要预先进行数据清理,将类中的相近数据进行合并以使得数据分类更加均衡。此外,为了获取更好的分类效果,教师应深度挖掘评估指标的内在关联,或加入新的评估指标,如利用深度学习分析学生的学习态度或学习习惯。
综上,基于投票的回归预测模型在考试课及考查课上的预测结果优于使用分类预测模型在考查课上取得的预测结果。鉴于此,可以针对不同的课程选择不同的弱学习器进行集成,且灵活性相对较高。
5 结语
线上教学将成为教学过程中不可或缺的一个有机组成部分。在高职ICT 类课程学生在线学习评估过程中,大多数教师采用了“过程性考核+期末考核”的方法。线上教学过程中,学生的学习自主性和自律性较差,根据学生在线学习数据提前预警,将起到非常重要的作用。因此,本文在过程性考核评价体系的基础上,结合投票集成学习提出了一种效果更优的预测模型。通过对比仿真实验可知,本文方法能够获得更低的预测误差和相对较高的分类预测准确度。
下一步研究方向是结合深度学习模型对学生线上听课过程的视频进行分析,利用异常检验技术发现网络学习欺诈行为、利用时间序列分析发现学习者的效率随时间变化而变化的规律等,使得该预测模型能够获得更准确的预测结果。
猜你喜欢
黄河之声(2022年10期)2022-09-27
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
民族文汇(2022年14期)2022-05-10
数学小灵通(1-2年级)(2021年4期)2021-06-09
作文大王·笑话大王(2019年8期)2019-09-09
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
