
基于改进MaxViT的辣椒病害识别分类方法
2024-01-01 00:00:00李西兴陈佳豪吴锐杨睿
华中农业大学学报 2024年2期





摘要 为实现复杂环境下辣椒病害的精准识别和分类,设计了一种适用于辣椒病害识别分类的方法。以辣椒在生长过程中常见的6 种病害为分类研究的对象,使用数据增强的方法扩充数据集,提出一种基于MaxViT改进的MaxViT-DF 模型,将MaxViT 模型中的普通卷积替换为可变形卷积,使模型在提取特征时能更贴近复杂环境下的识别目标;同时在MaxViT 模型施加注意力时引入特征融合模块,提高模型的全局感知能力。结果显示,改进的MaxViT-DF 模型识别分类准确率达到98.10%,对6 种辣椒病害的分类精度均高于95%。与ResNet-34、EfficientNetv2 和VGG-16 等模型相比,改进模型在收敛速度和分类精度上具有明显优势。以上结果表明,MaxViT-DF 模型能够对不同种类的辣椒常见病害进行有效的分类识别。
关键词 MaxViT-DF; 辣椒病害分类; 可变形卷积; 特征融合; 深度学习
中图分类号 TP391.41 ; S436.418.1 文献标识码 A 文章编号 1000-2421(2024)02-0123-11
21 世纪以来,全球辣椒种植面积与产量稳步增长,中国辣椒产业也进入了迅速发展阶段。据联合国粮食及农业组织的统计数据显示,2020 年中国辣椒产量约占全球产量的1/2,是全球最大的辣椒主产国[1]。在辣椒的实际种植生产过程中,各种病害阻碍了辣椒的正常生长,从而造成辣椒减产。因此,对辣椒常见病害的精准识别分类可以起到及时发现病害、指导农药使用和减少经济损失等作用。传统的辣椒病害识别主要是基于高光谱图像和基于表面纹理特征的方法,上述方法依赖人工并且不利于后续农业智能化的发展,因此亟需一种能精准识别辣椒病害的方法。
近些年来深度学习得到了快速发展,深度学习中的卷积神经网络[2](convolutional neural network,CNN)能充分利用计算机的计算能力,高效地提取图像特征,在植物病害识别分类方面取得了良好的效果[3]。Sladojevic 等[4]首次利用CNN 将植物叶片与周围环境区分开来,并且在CaffeNet 模型上微调改进,改进模型的平均识别精度达到了96.3%。张帅等[5]针对人工分析提取特征时造成的不同植物种属差异性问题,利用一个8 层卷积神经网络深度学习系统分别对简单背景和复杂背景叶片图像进行训练和识别,结果表明,使用CNN+SVM 和CNN+Softmax分类器识别方法对单一背景叶片图像识别率分别高达91.11% 和90.90%,复杂背景叶片图像的识别率也能达到34.38%。张善文等[6]针对在复杂的病害叶片图像中很难选择出对病害类型识别贡献较大的有用特征这一问题,构建了一种深度CNN 模型,直接从归一化后的彩色病害叶片图像中提取高层次的抽象特征,并在输出层进行病害识别,结果表明,与基于特征提取的传统病害识别方法相比,该方法的识别性能较高,识别分类准确率达到90.32%。虽然基于CNN 识别植物病害具有识别准确率高的优势,但是受制于网络架构因素、模型参数量大、训练时间长等特点,模型不易使用。
针对上述CNN 识别植物病害时模型训练收敛时间长和参数庞大的问题。Vishnoi 等[7]开发了一种CNN,该网络由较少数量的层组成以降低计算负担,所提出的模型仅需要较少的存储和计算资源便可以达到98% 的识别分类准确率。Liu 等[8]使用Mobile‐NetV2 模型作为骨干网络实现了对柑橘病害的识别,该方法在保持良好分类精度的同时减少了模型的预测时间和模型大小。为了使分类模型更容易部署到手机端,张鹏程等[9]对MobileNetV2 模型进行了进一步的改进,将ECA 注意力机制嵌入Mobile‐NetV2 网络的反残差结构尾部,以增强原网络的跨通道信息交互能力,提升原网络的特征提取能力,并基于该改进模型开发了一款边缘计算APP,改进模型对柑橘虫害的分类准确率达到93.63%。为了在提高检测速度的同时提高识别分类准确率,苏俊楷等[10]在YOLOv5 模型的主干网络中添加CA 注意力机制,改善目标漏检问题;在颈部使用BiFPN 替代原有的PANet;并且引入Focal-EIOU Loss 损失函数,在保持模型较低计算量的情况下,提升了模型的检测速度和算法性能,改进后的YOLOv5 模型和传统的YOLOv5s 相比,平均精度上升了4.5%。为了提高模型识别病害的泛化性和精准度,孙道宗等[11]在EfficientNetv2 网络模型引入了迁移学习机制,并且选取MultiMarginLoss 作为模型的损失函数,结果显示,改进模型在参数量和模型大小均下降的情况下,在存储空间大小、准确率和训练时间3 个指标上具有明显优势。
值得注意的是,以上的植物病害识别结果都是建立在具有良好的环境和数据集的背景下得出的,其数据集背景简单并且检测目标较易被识别,而在日常农业生产中很难有如此理想的环境。因此,为了应对背景杂乱或有干扰物等的复杂环境下对辣椒病害进行精准识别分类的问题,本研究选用Max‐ViT[12]作为骨干网络,建立了MaxViT-DF 模型,旨在保证病害特征提取能力的同时使网络兼顾注意力机制以提高分类准确率。
1 材料与方法
1.1 数据集
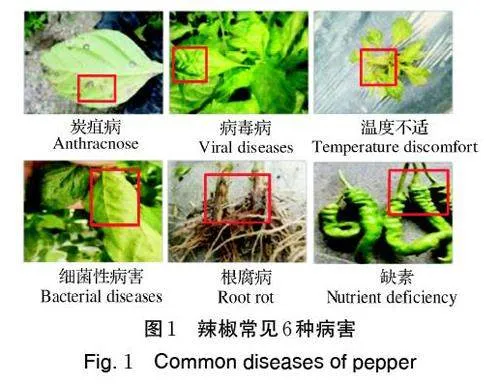
本研究以炭疽病、病毒病等对辣椒生长危害最严重的6 种病害作为研究对象,收集图像组成基础数据集,图像背景为辣椒自然生长环境,图片背景复杂并且有干扰物,如图1 所示。
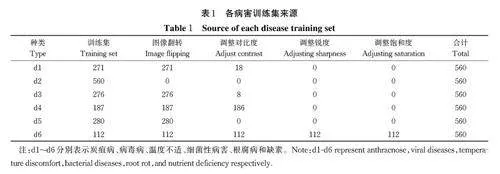
基础数据集共收集病害2 107 张图片(随机划分测试集421 张,训练集1 686 张)。为了避免模型没有足够样例区分特征,导致模型在训练过程中出现过拟合现象,通过图像翻转、调整对比度、调整饱和度和调整锐度4 类数据增强方法对训练集进行处理(图2),获得本识别分类方法的最终训练集(表1)。为了保证试验数据的均衡性,将6 种病害的训练集数量扩大至同等规模,每种病害数据集包括560 张图片,共3 360 张图片。
1.2 MaxViT模型
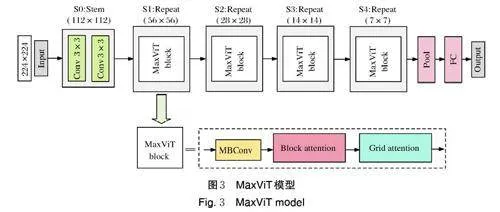
MaxViT 是2022 年谷歌提出的分层Transformer模型[13],融合了注意力机制和卷积,并且提出了1 种新颖的独立多轴注意力模块,由阻塞的局部注意力和扩张的全局注意力组成,具有线性复杂性的感知能力,MaxViT 在图像分类和目标检测方面表现良好。
MaxViT 模型如图3 所示,输入网络的是1 张224像素× 224像素的三通道RGB 图片,输出为6,对应辣椒的6 种病害。输入的图片首先通过2 个卷积层进行特征提取,然后经过4 个MaxViT block 添加注意力,在MaxViT block 中将MBConv 与注意力一起使用进一步提高了网络的泛化性和可训练性,再经过池化层和全连接层输出结果,最后将网络处理后的结果输入Softmax 分类器计算病害类别预测概率,将其中概率最大的病害作为网络识别这张图片的预测种类。
1.3 可变形卷积模块
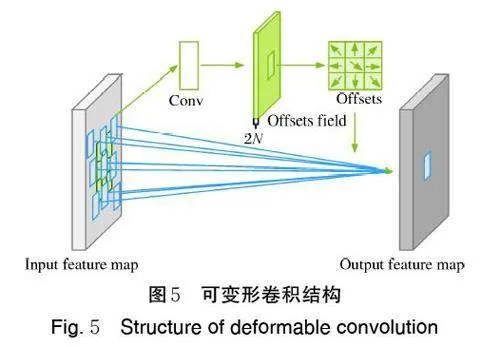
针对辣椒表面形状复杂和病害缺陷范围不规则的问题,在MaxViT 模型的基础上将提取特征的普通卷积层替换为可以偏移位置的可变形卷积[14]。可变形卷积在采样位置增加了1 个偏移量,相比于普通卷积,可变形卷积在采样时可以更贴近物体的形状和尺寸,具有更强的鲁棒性(图4)。
可变形卷积结构如图5 所示,由普通卷积和偏移模块组成。偏移模块中的偏差通过1 个卷积层获得,输入特征图,输出偏差,生成通道维度是“2N”,其中“2”分别对应平面上x 值方向和y 值方向这2 个2D 偏移,“N”是通道数,一共有2 种卷积核,包括普通卷积中的卷积核以及卷积核学习offset 对应的卷积层内的卷积核,二者可通过双线性插值反向传播同时进行参数更新。
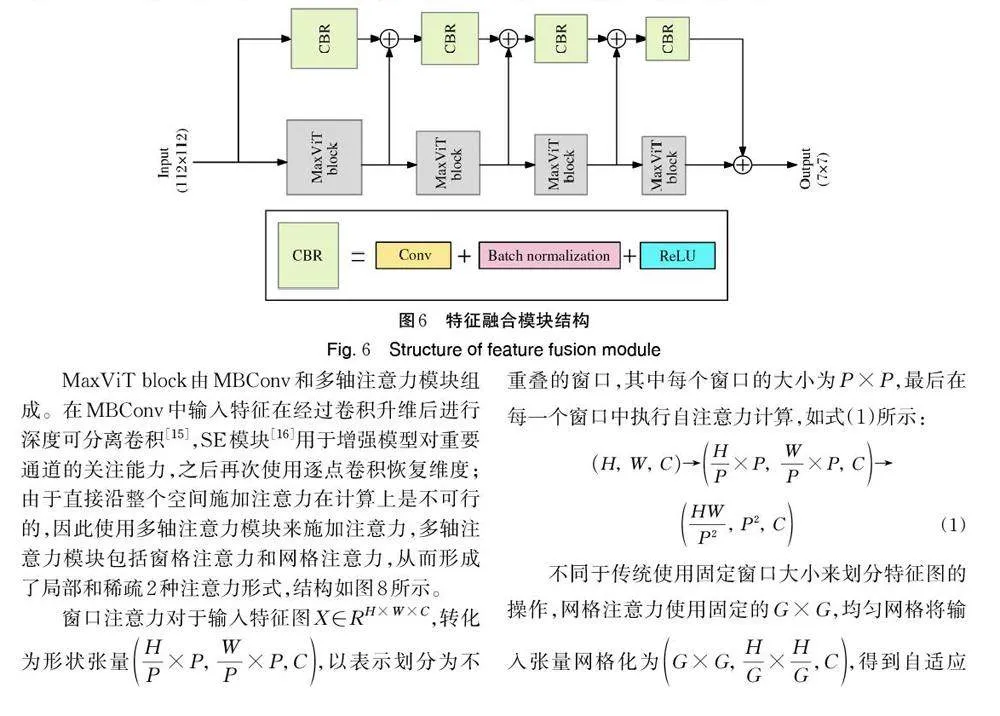
1.4 特征融合模块
MaxViT 模块在添加注意力的同时也对特征图进行尺寸的缩减,为了缓解这种因为尺寸缩减而带来的特征损失问题,本研究在MaxViT 模型的框架中引入了特征融合模块。特征融合模块结构如图6 所示,首先将输入的特征图分为2 部分,分别进入Max‐ViT 模块施加注意力和CBR 模块提取特征,CBR 模块由卷积、批量归一化和ReLU 激活函数组成;其次将MaxViT 模块的输出作为下一个MaxViT 模块的输入继续添加注意力,并且把MaxViT 模块的输出与CBR 模块的输出相加,将相加得到的结果作为下一个CBR 模块的输入继续进行下采样过程;最后将MaxViT 模块和CBR 模块的最终输出结果相加,作为整个特征融合模块的输出结果。
1.5 MaxViT-DF模型
为了提高辣椒病害的识别准确率,将可变形卷积和特征融合模块融合到原始MaxViT 模型中。MaxViT-DF 模型结构如图7 所示,用可变形卷积替代原始MaxViT 中的2 个卷积层进行特征提取,和原始MaxViT 中的2 个卷积层一样,可变形卷积将输入大小为224像素× 224像素的图片提取为112像素×112像素的特征图,并且在提取特征的过程中更加贴近识别目标的位置与形状,有利于模型在后续对提取到的特征进行准确有效的学习;将经过特征提取后的特征图放入MaxViT block 中施加注意力,同时也把特征图放入特征融合模块中融合全局信息,在每个特征融合的过程中,利用卷积层对数据进行下采样,以保证采样后的数据大小与MaxViT block 处理后的数据大小相匹配;将4 个MaxViT block 处理后的结果和特征融合模块处理结果相加,经过池化层和全连接层处理输出分类结果。
猜你喜欢
软件导刊(2017年7期)2017-09-05 06:27:00
无线互联科技(2017年12期)2017-07-18 17:40:58
科技资讯(2017年11期)2017-06-09 18:28:13
电子技术与软件工程(2017年5期)2017-04-23 23:37:37
现代电子技术(2017年7期)2017-04-14 19:20:42
江苏教育·中学教学版(2016年11期)2016-12-21 11:36:29
现代情报(2016年10期)2016-12-15 11:50:53
新教育时代·教师版(2016年23期)2016-12-06 06:02:38
法制与社会(2016年32期)2016-12-01 15:25:53
软件导刊(2016年9期)2016-11-07 22:20:49
