
基于LSTM的水文站流量短期预测建模差异性研究
2024-01-01 00:00:00乔长建刘震邰建豪
人民黄河 2024年6期
关键词:黄河流域








关键词:LSTM;离散小波;水文预测;时频分析;黄河流域
中图分类号: TV11;TP181 文献标志码:A doi:10.3969/j.issn.1000-1379.2024.06.020
引用格式:乔长建,刘震,邰建豪.基于LSTM 的水文站流量短期预测建模差异性研究[J].人民黄河,2024,46(6):119-125.
水文预测对水资源规划管理具有重要作用,尤其是流量短期预测对防灾减灾具有重大意义[1-3] 。然而,影响流量的参数在时间尺度和空间尺度上存在复杂的非线性特性,使流量短期预测存在较大困难[4] 。
当前对水文模拟预测的方法主要包括过程驱动法和数据驱动法[5] 。过程驱动法是以概化经验模型或具有物理机制的水文模型为主,模型率定对各种水文数据的依赖性较强[6-8] ,需要考虑不同时空尺度的水文参数不确定性。数据驱动法主要以历史水文数据为基础,拟合出一个预测模型,无须考虑水文过程的物理机制。随着机器学习技术的发展,数据驱动模型更加广泛地运用于径流研究中,如一些学者假设自变量与因变量间为线性关系,利用传统时序建模方法(ARI⁃MA)[9] 、自回归模型(AR)[10] 以及自回归滑动平均模型(ARMA)[11] 进行建模;还有一些学者利用径流序列的非线性特征进行建模, 如人工神经网络模型(ANN)、支持向量机(SVM)等[12] 。
当前,深度学习是机器学习中的热点[1] 。深度神经网络最显著的特征是多元神经网络架构中的层,它提供了比非深度神经网络更复杂的函数。针对序列数据的学习训练,研究人员开始关注循环神经网络(RNN)及其变体,并发现其具有较好的径流时间序列预测性能。例如:Wang等[13] 使用RNN 进行气象统计降尺度和气象评估,证明其相对于传统的ANN 模型有更高的拟合精度;蔡文静等[14] 构建了基于经验模态分解( EMD)、变分模态分解(VMD)、离散小波变换(DWT)的LSTM 子序列组合预测模型,其预测精度比单一序列预测模型的高。然而,围绕机器学习的水文站流量预测研究主要集中在模型构建和参数选择上,不同流域的气候、海拔、地下水、降雨等因素各异,水文站流量的影响因子也不同,缺乏参数选择对不同流域的神经网络训练模型预测结果影响的研究,导致基于机器学习的水文预测模型的适应性和推广运用程度较低。因此,本文选用LSTM 模型,针对不同特征流域的水文站,研究预测模型在不同参数输入时的预测精度,进而分析不同流域的建模差异性,以期提高水文预测模型的适应性。
1研究区概况
黄河发源于青藏高原巴颜喀拉山北麓约古宗列盆地,干流全长5464km,流域总面积79.5 万km2(含内流区面积4.2 万km2)。为验证预测模型的可用性和精度,选取黄河流域3 个子流域(唐乃亥上游流域、汾河流域、花园口下游流域)作为研究对象(见图1)。
唐乃亥上游流域属于黄河源区,位于青藏高原东北部,其水资源与生态环境关乎整个黄河流域的水安全和区域发展。流域内大型水利设施较少,水文站测得的流量数据主要与气候(雪山融化和降雨)有关,因此对该流域建模时可以忽略非气候因素影响,围绕水文站流量、气温和降水因子建立预测模型。汾河流域发源于山西省宁武县管涔山,纵贯山西省中部,流经太原和临汾两大盆地,于万荣县汇入黄河,流域面积3.9471 万km2,河长693.8 km,年降水量变化大,沿岸地区每年从汾河取水24.3 亿m3,取水量占全省水资源利用总量的46%,下游河津水文站监测汾河流域入黄河的流量。花园口下游流域(花园口至利津)河段长期淤积,形成举世闻名的地上“悬河”,黄河约束在大堤内,成为海河流域与淮河流域的分水岭。除大汶河由东平湖汇入外,该河段无较大支流汇入。流域狭长,面积仅2.3 万km2,占黄河全流域面积的3%,因此可以忽略流域降雨产流因素,考虑上游流量建立流量预测模型。
2数据来源与研究方法
2.1数据来源
流量数据(各水文站2006年5月1日至2020 年11月25日流量)源自黄河水利委员会黄河水情网站。唐乃亥上游流域使用唐乃亥水文站监测数据,汾河流域使用河津水文站监测数据,花园口下游流域使用花园口、夹河滩、高村、孙口、艾山、泺口、利津7 个水文站监测数据。
降水量、气温数据源自NOAA Climate PredictionCenter发布的2006—2020年全球降水量、气温数据集,基于经纬度提取流域内各气象站的数据,最终得到唐乃亥上游流域14个气象站的降水量、气温数据,汾河流域35 个气象站的降水量、气温数据,花园口下游流域14 个气象站的降水量、气温数据。
2.2研究方法
3结果与分析
3.1各水文站流量时频分析
2006年5 月1 日—2020年11 月25日唐乃亥、河津、利津水文站流量、气温、降水量数据统计结果见表1。唐乃亥、利津水文站为黄河干流水文站,日均流量较大;河津水文站为汾河支流水文站,日均流量较小。
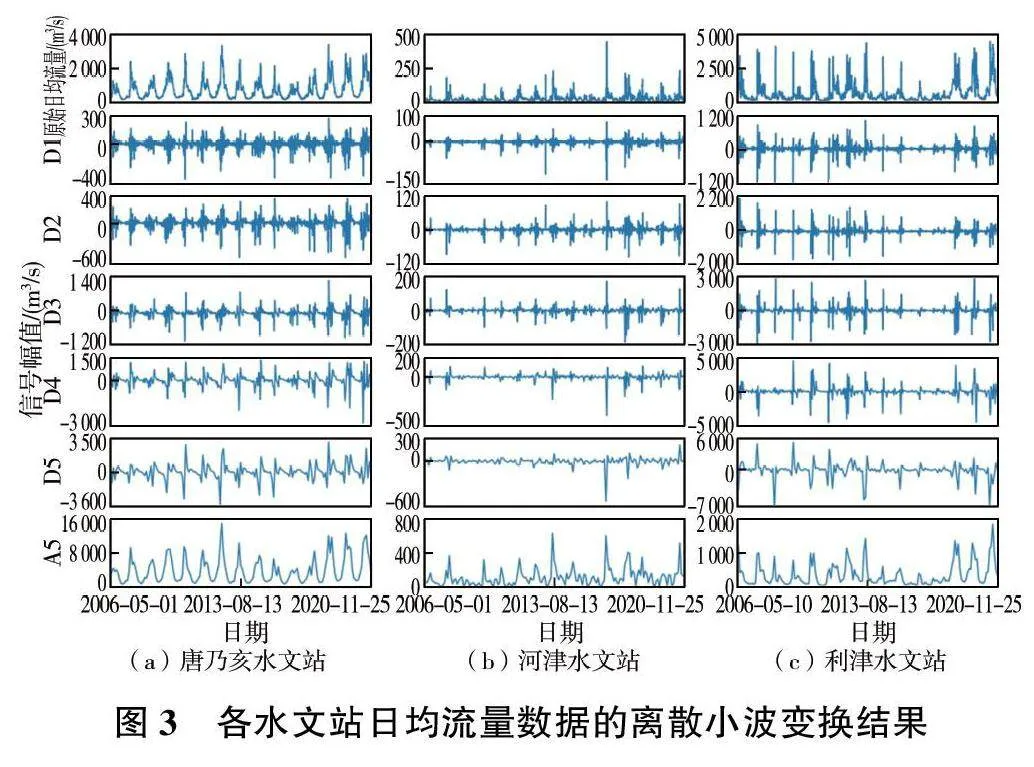
对唐乃亥、河津、利津水文站日均流量的时序数据进行离散小波变换,分解为1 个逼近信号(A5)和5 个细节信号(D1、D2、D3、D4、D5),见图3(上方第一行图为原始日均流量—时间关系图,第二行至第七行图均为信号幅值—时间关系图)。逼近信号保留原始流量的周期性特征,细节信号显示出细节变化和噪声等信息。如果一个信号分解出来的逼近信号周期性特征明显,细节信号幅度越小,则信号的预测性越高。
分析图3 可知,A5信号周期性特征的显著性由高到低为唐乃亥>利津>河津,D1~D5 信号幅度由小到大为河津<唐乃亥<利津。D1~D5信号波动主要出现在原始流量序列波峰,波峰(汛期)预测受气温、降雨等因素影响较大。结合水文站地理环境、流域特点、日均流量时频分析,初步推测:1)唐乃亥水文站在黄河上游,人类活动较少,主要受冰山融雪影响,因此流量变化更能表现出季节性(周期性)特征,预测模型仅依据历史流量序列即可有较高的预测精度,若结合气温、降水量,则预测精度会更高。2)利津水文站在黄河下游,花园口至利津段流域狭长,受降水影响有限,受上游流量的影响较大,预测模型仅依据历史流量序列的预测性较低,若结合上游流量,则预测精度会更高。3)汾河流域产流主要受地下水、降水的影响,河道流量小且受人类活动(灌溉、引水等)影响较大,因此其表现出弱周期性、较强随机性,预测模型仅依据历史流量序列时的预测性较低,结合降水、人类活动因素时应有较高预测精度。
3.2影响因子相关性分析
唐乃亥水文站处于黄河上游,流量的影响因子单一,因此选择流域日均降水量、日均气温作为预测模型备选因子;河津水文站作为汾河流域出口,流量受流域产流影响较大,同样选择流域日均降水量、日均气温作为预测模型备选因子;利津水文站受上游流量影响较大,因此选择上游水文站流量以及流域日均降水量、日均气温作为预测模型备选因子。利用Spearman 模型计算各水文站预测模型备选因子与流量的相关系数,唐乃亥水文站降水量、气温与流量的相关系数分别为0.52、0.69,河津水文站降水量、气温与流量的相关系数分别为0.60、0.03,利津降水量、利津气温、花园口流量、夹河滩流量、高村流量、孙口流量、艾山流量、泺口流量与利津流量的相关系数分别为0.17、0.41、0.68、0.70、0.74、0.79、0.84、0.92。最终,选用相关系数大于0.40 的备选因子作为预测模型的输入因子进行训练和预测。
3.3基于LSTM 的流量预测分析
3.3.1LSTM 模型建模
模型使用两层LSTM 和一层全连接神经网络,第一层LSTM 有100 个神经元,第二层LSTM 有50 个神经元。为避免过拟合,dropout 设置为0.2,训练epochs为100,批大小为16,最终输出水文站未来5 d 的日均流量。预测模型神经网络结构见表2,表中参数个数为神经网络层中权重矩阵和偏置向量的总和,输出维度为神经网络层提取特征的结构。
模型基于15 d 历史数据预测未来5 d 的流量。根据3.2 节影响因子相关性分析,对于唐乃亥上游流域,设置两种LSTM 输入方案,方案一是输入唐乃亥水文站15 d 历史流量,方案二是输入唐乃亥水文站15 d 历史流量、流域日均气温、流域日均降水量;对于汾河流域,设置两种LSTM 输入方案,方案一是输入河津水文站15 d 历史流量,方案二是输入河津水文站15 d 历史流量、流域日均降水量;对于花园口下游流域,设置四种LSTM 输入方案,方案一是输入利津水文站15 d 历史流量,方案二是输入花园口、泺口、艾山、孙口、高村和利津共6 个水文站15 d 历史流量、日均气温,方案三是输入利津、泺口水文站15 d 历史流量,方案四是输入利津、花园口水文站15 d 历史流量。LSTM 输出为唐乃亥、河津、利津水文站未来5 d 的流量。
3.3.2预测结果分析
唐乃亥、河津、利津水文站未来5 d 流量预测结果分别见图4、图5 和图6,预测精度见表3。对比不同方案的预测结果,方案一(均是单因子输入)的预测值曲线在实测值曲线偏右,而其他多因子输入方案的预测结果没有出现波峰后移现象,说明输入多因子可以提高模型综合预测能力。方案一预测第5 d 的流量值总体明显低于实测值,尤其是波峰位置,说明预测时间越长,预测精度越低;而其他多因子输入方案预测第5 d的流量值比方案一的值高,精度明显提升,说明引入外在影响因子能完善预测模型。
对比不同水文站的模型预测结果,唐乃亥水文站方案一第5 d 预测结果的NSE 达0.90,说明该水文站上游地区水文过程时序性较稳定,模型仅依据历史流量序列就具有较高的预测性能,方案二进一步提高了预测精度。河津水文站方案一前2 d 预测结果的精度较高,第5 d 虽能预测出流量走势,但对流量波动性拟合不足,这与汾河流量小、易受随机因素影响相关,波峰位置预测值普遍低于实测值;方案二对波峰位置的流量预测精度明显提升,但对波动小的流量拟合仍然不足,且第3 ~ 5d 训练期预测结果的NSE 分别为0.82、0.79、0.73,对照验证期预测结果的NSE 分别为0.63、0.52、0.39,说明模型出现过拟合现象,对模型输入因子的考虑还不够全面。利津水文站方案一第1 d的预测精度较高,第5 d 偏离较大;方案二考虑上游水文站的流量后,预测精度明显提升,第5 d 预测结果的NSE 达到0.85;方案四第5 d 预测精度比方案三的高,说明上游水文站与利津站的距离影响预测精度,如花园口水文站距离利津水文站约570 km,若流速以2 m/ s计算,花园口的水将在3 d 左右流到利津,根据花园口水文站流量可预测利津水文站未来3 d 的流量,即距利津水文站越远,未来能预测更长时间的流量。
4结论
本文基于黄河不同子流域特点选择3 个水文站进行流量预测对比,用离散小波变换对波形差异进行时频分析,基于LSTM 进行短期流量预测建模。通过对比分析,得出以下结论:
1)仅利用自身流量因子训练得出的水文站预测模型易出现平移预测,即预测值曲线在实测值曲线偏右,且流量稳定时期预测精度高、波峰时期预测精度低。
2)唐乃亥水文站的上游流域受人类活动影响小,其流量的时序数据周期性好,波形稳定,预测模型可以基于自身历史流量序列进行建模,具有较高的预测精度。
3)受上游影响较大的干流水文站,模型仅依据水文站历史流量的预测性较低,输入上游多因子进行建模后,模型精度有所提高。采用距预测水文站较远的上游水文站流量数据进行建模时,可预测更长时间的流量。
猜你喜欢
山西财税(2023年8期)2023-12-28 08:05:28
现代经济信息(2023年18期)2023-06-25 05:46:22
文学与文化(2022年3期)2022-11-19 02:32:20
人民黄河(2022年9期)2022-09-08 13:04:38
人民黄河(2022年7期)2022-07-07 06:52:24
人民黄河(2022年4期)2022-04-07 09:04:04
河北环境工程学院学报(2021年1期)2021-03-19 08:42:26
当代陕西(2019年23期)2020-01-06 12:17:40
收藏界(2019年2期)2019-10-12 08:26:10
人大建设(2019年12期)2019-05-21 02:55:42
