
改进YOLO的X射线管道焊缝检测算法
2024-01-01 00:00:00王合佳林宁林振超黄凯牛顿郑力新
华侨大学学报(自然科学版) 2024年6期




摘要: 提出一种基于YOLOv8n算法改进的YOLOv8n-MG算法,用于解决目标小、遮挡重叠、算法参数量大等问题。首先,引入GSConv和VoV-GSCSP模块降低算法复杂度,提高算法对缺陷粗糙边缘的检测能力;其次,使用轻量级的上采样算子Carafe替换原有的传统上采样,保留更多的细节特征;最后,引入混合局部通道注意力(MLCA)机制,以较低的计算成本和参数量保留更多的空间特征信息,并利用Adam优化器提高算法对复杂参数空间的学习能力。结果表明:优化后的算法与YOLOv8n算法相比,参数量减少了11.3%,检测帧率提高了7.7%,平均精度提高了2.8%。
关键词: 焊接缺陷; 缺陷检测; MLCA模块; YOLOv8算法; 检测帧率
中图分类号: TP 391.41; TU 229文献标志码: A" "文章编号: 1000-5013(2024)06-0766-10
X-Ray Pipe Weld Detection Algorithm of Improved YOLO
WANG Hejia1, LIN Ning2, LIN Zhenchao2, HUANG Kai2, NIU Dun2, ZHENG Lixin1
(1. College of Engineering, Huaqiao University, Quanzhou 362021, China;
2. Quanzhou Branch of Special Equipment Inspection Research Institue, Huaqiao University, Quanzhou 362021, China)
Abstract: An improved YOLOv8n-MG algorithm based on the YOLOv8n algorithm is proposed to solve issues such as the small targets, overlapping occlusion, and large number of algorithm parameters, etc. Firstly, the GSConv and VoV-GSCSP modules are introduced to reduce the complexity of the the algorithm and enhance its ability to detect rough edges of defects. Secondly, a lightweight up-sampling operator, Carafe, is used to replace the traditional up-sampling, preserving more detailed features. Finally, a mixed local channel attention (MLCA) mechanism is introduced to retain more spatial feature information with lower computational cost and parameters, and the Adam optimizer is used to improve the algorithm′s learning ability in complex parameter spaces. The results show that compared with the YOLOv8n algorithm, the optimized algorithm reduces the number of parameters by 11.3%, improves the detection frame rate by 7.7%, and improves the average accuracy by 2.8%.
Keywords: weld defect; defect detection; mixed local channel attention module; YOLOv8 algorithm; detection frame rate
随着我国工业化水平的不断提高,焊接技术已广泛应用于承压容器、冶金工业、石油化工等多个领域。工业设备的焊接质量直接影响焊接结构的使用性能和寿命[1]。由于生产工艺和焊接环境等因素的影响,工业设备的焊缝位置在制造和使用过程中容易产生各类焊接缺陷[2]。这些缺陷根据不同焊缝位置可分为内部缺陷(裂纹、未熔合、未焊透、条形和圆形缺陷等)和表面缺陷。内部缺陷利用X射线技术将其映射到图像中,并通过专家或计算机视觉进行检测。
随着深度学习技术的进步,深度学习在焊缝缺陷检测方面显示出巨大的潜力。目前的目标检测算法大致可分为两种:两阶段检测算法和一阶段检测算法。两阶段检测算法包括R-CNN算法[3],Faster R-CNN算法[4]和HyperNet算法[5]等。一阶段检测算法包括YOLO算法[6-8],SSD算法[9]等。许多研究人员采用这两种算法对实际场景进行研究,并取得了一定进展。Liu等[10]提出AF-RCNN算法,将ResNet 和FPN作为网络的骨干,同时利用了轻量级模型信道注意和空间注意机制。Chen等[11]在Faster R-CNN算法的基础上进行改进,利用深度残差网络Res2Net增强了焊接缺陷特征提取能力。然而,上述模型通过增加模型的参数量和复杂程度以提高检测精度,导致参数量过大、推理速度较慢。
为了解决检测速度的问题,Liu等[12]提出了一种基于改进LF-YOLO算法的高效的特征提取(EFE)模块,速度为61.5 F·s-1 ,平均精度为92.9%。Zhang等[13]在YOLOv8-nano算法引入了对小目标敏感的全维动态卷积和基于归一化(NAM)注意力机制,提高了模型检测性能。程松等[14]在YOLOv5算法中引入GhostBottleneck模块和注意力机制,极大减少了算法参数量,使其适用于嵌入式设备。Yang等[15]在YOLOv3-tiny算法的主干上增加了空间金字塔池化结构(SPP)模块,减少了检测头的数量,极大减少了算法参数量,但该算法的小目标检测性能不足。上述算法因过分强调速度提升而导致整体性能下降。
在实际工业环境中,焊接过程中的焊丝飞溅会造成焊渣等杂质的产生,不同缺陷相互重叠会对缺陷的定位和识别分类造成干扰,因此,上述研究的准确性和检测速度有一定局限性。基于此,本文提出一种基于 YOLOv8n算法改进的深度学习检测算法。
1 YOLOv8n-MG算法
1.1 YOLOv8算法
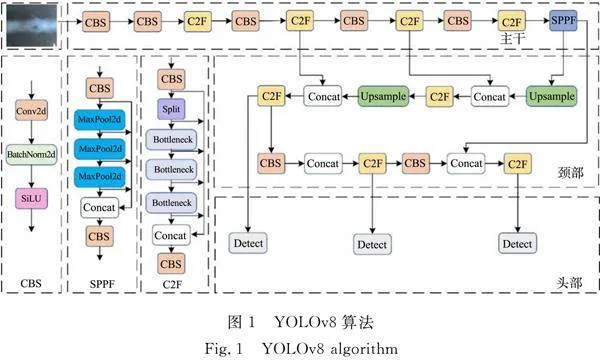
YOLO算法是目前较为先进的单阶段目标检测框架,旨在通过仅分析一次图像提供检测结果。从YOLOv1算法开始,经过多次改进和更新,一直到YOLOv8算法。YOLOv8算法整合了YOLOv5算法部分结构,将第1个卷积层的内核从6×6过渡到3×3,并用 C2F模块取代了 C3 模块,更新了部分瓶颈的结构变化及顶层激活函数的变化。YOLOv8算法主要包括主干、颈部和头部。YOLOv8算法,如图1所示。
主干提取图像特征。YOLOv8算法使用一个新的骨干网络,它由多个C2F模块加上空间金字塔池化(SPPF)模块组成,SPPF模块使用更多的跳过连接来丰富模型的特征表达能力,能够处理不同尺度的物体,使网络能够在多个尺度上提取特征,增强了模型的尺度适应能力。
颈部负责融合特征。颈部采用了双流特征金字塔网络(FPN),以实现对多尺度特征图的语义和空间信息进行有效融合。
头部预测对象类别和位置。头部输出有两个分支:一个是分类分支,输出每个像素点属于每个类别的概率;另一个是回归分支,输出每个像素点对应的目标框参数。
在数据增强方面,由于YOLOv8 算法采用了 Mosaic 方法,通过随机裁剪和拼接图像增强数据集,增强模型的识别能力。因此,在模型训练的最后10个时期关闭了 Mosaic,以便让模型在未经过裁剪的图像数据集上完成最终收敛,以减轻 Mosaic 数据增强方法的潜在缺点。
为了方便用户在不同场景下测试速度与平均精度的平衡,YOLOv8算法提供了5种不同尺寸的算法供用户选择,包括YOLOv8n算法,YOLOv8s算法,YOLOv8m算法,YOLOv8l算法,YOLOv8x算法。与其他4种算法相比,YOLOv8n算法更轻量级,更易于现场部署。因此,选择YOLOv8n算法作为基准算法。
1.2 YOLOv8n-MG算法
与大面积的母材背景相比,缺陷小目标只占几个像素,而且其边缘特征较为粗糙,导致难以准确识别;部分缺陷类型(如未焊透)出现局部不连续现象,导致无法准确定位;YOLOv8算法的多次下采样操作丢失部分语义信息,无法有效提取小目标的细节特征,这会给多个缺陷重叠检测带来难度,而且不同类别的缺陷大小差别很大。针对这些问题,选择最轻量的YOLOv8n算法作为基准算法进行改进。
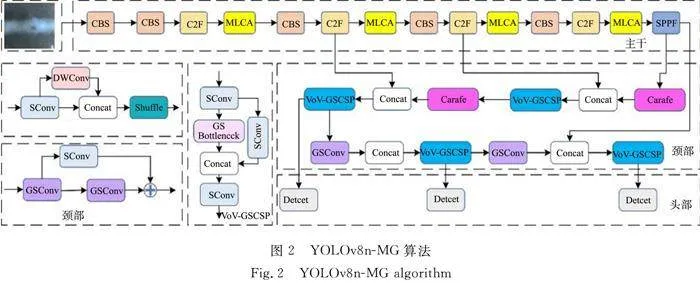
YOLOv8n-MG算法使用GSConv[16]模块替代颈部的Conv模块,使用VoV-GSCSP[17]模块替代颈部的C2F模块,GSConv模块和VoV-GSCSP模块的灵活组合可以有效提高模型对粗糙边缘的检测能力和对不同尺度缺陷的检测能力。YOLOv8n-MG算法使用轻量级的上采样算子Carafe[18]替换原有的Upsample传统上采样,保留更多的细节特征。引入混合局部通道注意力(MLCA)[19]机制对骨干网络的C2F模块进行改进,以更少的参数量保留更多的语义信息,通过强调缺陷部位的信息而抑制大面积母材背景信息,结合更多的空间和通道信息,增强对小目标缺陷特征提取能力。最后,利用Adam优化器提高模型复杂参数空间的学习能力,提高算法对于小目标的检测能力。
YOLOv8n-MG算法,如图2所示。
优化后的算法的平均精度为95.1%,比基准模型提高2.8%;检测帧率为85.6%,比基准模型提高了7.7%;参数量为5.5×106个,比基准模型少0.7×106个,减少了11.3%。这表明优化后的算法在使用更少参数的基础上,不仅能够保证高精度,还能保持检测速度。优化后的算法具有更好的特征感知能力、更好的缺陷边缘的检测能力、更多的通道和空间特征信息,从而提高了准确性。
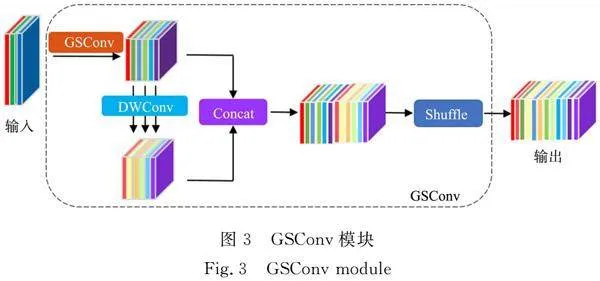
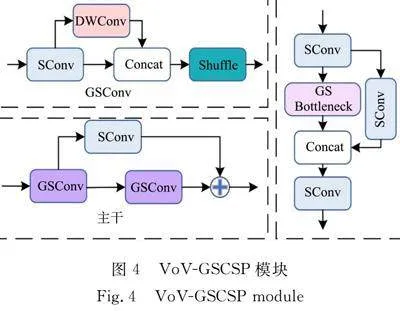
1.2.1 GSConv模块 YOLOv8n 的 颈部引入了GSConv模块和VoV-GSCSP(VoV-Ghost shuffle cross stage partial)模块进行更改。使用GSConv模块和跨级部分网络模块CSP(cross stage partial)模块设计出VoV-GSCSP模块,降低计算和网络复杂性,同时保持足够的精度。在传统的前馈神经网络(CNN)中,空间信息逐渐转换成通道信息,而这一过程在每一次特征图空间压缩和通道的扩张时都会导致语义信息的部分丢失,这使得焊缝缺陷边缘的特征提取不完整,不利于区分大面积的母材背景和小面积的焊缝缺陷。因此,引入VoV-GSCSP模块,尽可能多地保留每个通道的隐藏连接。
GSConv模块,如图3所示。
GSConv模块融合了GhostNet和ShuffleNetv2的轻量级思想。GhostNet主要解决了标准卷积的输出通常有很多相似的特征图,会给计算带来冗余的问题。GhostNet的Ghost卷积不是标准卷积,而是先使用标准卷积来获得第一部分;其次通过深度卷积对这部分进行卷积,以获得几个相似的特征图作为第二部分的结果。最后,将这两个部分连接在一起,作为输出特征图。ShuffleNetv2 主要解决了深度可分离卷积中的信道信息分离问题,即输入特征图中的信道信息在计算过程中相互独立,导致信息交互不足,而通过shuffle操作提高特征间的信息流动,将标准卷积和深度可分离卷积产生的特征信息融合在一起,增加小目标缺陷特征提取的多样性和丰富度,降低计算复杂度,提高模型的泛化能力。
GSConv通过将输入通道划分为多个组,并对每个组进行独立的卷积运算,有利于模型对于缺陷边缘信息的提取和最大化保留,有助于区别母材背景和缺陷信息,同时减少了计算量。GSConv旨在保持较低时间复杂度的同时,尽可能地保留通道之间的隐藏连接,并提高预测速度。
VoV-GSCSP模块,如图4所示。VoV-GSCSP模块利用不同的结构设计方案,通过跨阶段网络连接选择全局上下文信息,进一步提高模型对缺陷重叠边缘信息特征的提取能力,解决缺陷重叠混淆的问题,提高特征利用效率和网络性能,降低计算和网络结构的复杂性。通过结合GSConv模块和VoV-GSCSP模块,实现了YOLOv8n算法颈部结构的重构,更有利于小目标焊缝缺陷特征的提取和分类,在减少模型计算量的同时,也提高了焊缝缺陷识别的准确性。
1.2.2 轻量级上采样算子Carafe 特征上采样是许多网络架构中的关键操作,上采样生成的特征图的质量对模型的准确性至关重要。YOLOv8-nano算法使用Upsample操作,仅利用输入特征图中的空间信息,而忽略了语义信息,这会导致信息丢失或模糊,影响检测精度。因此,引入轻量级上采样算子Carafe。算子Carafe可以保留更多的缺陷图像细节,同时减少采样过程导致的焊接缺陷的信息丢失,并且不会额外增加学习参数,这有利于模型的压缩和轻量化。Carafe分为两个主要模块,即上采样核预测模块和特征重组模块。假设上采样的倍率为α,输入特征图的高、宽、长分别为H,W,C。采样算子Carafe的采样操作有如下2个步骤。
1) 通过上采样核预测上采样核。对于输入特征图,使用1×1的卷积,将通道数进行压缩。假设上采样核的尺寸为kup×kup,利用kenc×kenc的卷积层来预测上采样核,得到形状为αH×αW×k2up的上采样核,并对上采样核利用softmax激活函数进行归一化。
2) 通过特征重组模块,完成上采样。将输出特征图中的每个位置映射回输入特征图,得到kup×kup为中心的预测值,并用该点的上采样核作点积得到输出值。内容感知重组模块可使局部区域中相关的特征信息得到更多的关注,重组后的特征图,比原有的特征图具有更多的语义信息。
引入轻量级上采样算子Carafe,适应不同内容和尺度的特征,有助于实现对不同尺度缺陷目标的特征提取,不同于Upsample需要引入额外的参数量,算子Carafe只引入少量的参数,保持轻量化的特性。
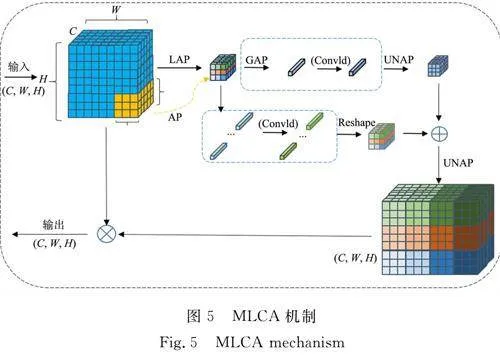
1.2.3 MLCA机制 注意力机制在计算机视觉中被广泛应用,能够帮助神经网络强调重要元素并抑制不相关的元素。然而,大多数信道注意力机制只关注信道特征信息,而忽略了空间特征信息, 不利于提高在大面积母材背景下提取小面积缺陷的能力,从而导致目标检测性能模型较差。此外,现有的空间注意力模块往往复杂且成本高昂。
MLCA机制结合了局部和全局特征、通道和空间特征信息,从而提高网络的表达效果,同时,相较于其他的注意力机制,MLCA机制的参数量更少,成本较低。MLCA机制工作原理有如下6点。
1) 输入特征图,并进行局部平均池化和全局平均池化处理。局部池化关注局部区域的特征,而全局池化捕捉整个特征图的统计信息。
2) 通过一维卷积(Conv1d),对局部池化和全局池化后的特征进行特征转换,以压缩特征通道并保持空间维度不变。
3) 重新排列一维卷积后的特征,便于后续操作。
4) 通过“乘法”操作,将一维卷积后的特征与原始输入特征相结合,实现特征选择,强化对有用特征的关注。
5) 通过“加法”操作,将全局池化后的特征与局部池化特征相结合,融合全局上、下文信息。
6) 通过反池化(UNAP)操作,将特征图恢复到原始的空间维度。
MLCA机制,如图5所示。MLCA机制的优点在于以较低的计算成本保留更多的空间特征信息,从而使得卷积层能够接收到更多有用的通道信息,提高小目标缺陷特征图的表达能力和模型的检测性能,有助于区分在大面积母材背景下小面积缺陷的能力,同时参数量更少,能够在不影响精度的情况下,同时提高推理速度,实现模型的轻量化,便于模型部署。
2 实验结果与分析
2.1 实验环境
为训练模型,使用Adam作为优化器,将训练批量大小设置为32,初始学习率为 0.001,为了优化模型在训练过程中的性能,采用学习率衰减方法。学习率衰减方法使用初始学习率调整模型的参数,从而更新速度。此外,还利用学习率系数控制训练过程中学习率的衰减。迭代次数设置为1 000。实验在NVIDIA GeForce GTX TITAN Xp GPU上进行,使用python3.8和Pytorch深度学习框架。
2.2 实验数据集
由于焊接工业领域的数据集很难收集,而且人工标注成本很高,目前公开的数据集也很稀少,如Mery[20]在 2015年提出了GDXray数据集,但仅包含10个焊缝缺陷数据样本,而且没有对缺陷进行标注。实验数据集来自福建省特种设备检验研究院(泉州分院)。对X射线管道焊缝缺陷胶片原件进行图像采集,使用专业的VIDAR工业胶片扫描仪对胶片进行扫描。在胶片扫描过程中,因为胶片本身拍摄仪器和管道的原因,扫描出的图像不明显。对扫描的图像进行灰度调节,使得焊缝图像明显可见,对采集到的图像进行筛选,删除缺陷颜色暗淡和不易于母材区分的图像,仅留下缺陷特征较为明显的图像(共431张),从而能够方便专业人士进行标签标注。
增强图像数据方法有随机调整图像亮度、增加高斯噪点、水平翻转。图像数据增强后,数据集扩展为1 884张图片,命名为HWDXray数据集。在专业人士的指导下,对图片标注焊缝缺陷(裂纹、未熔合、未焊透、条形和圆形缺陷)。数据集按7∶2∶1的比例划分成1 318张图片的训练集、377张图片的测试集和189张图片的验证集,图像像素大小为1 280 px×680 px,训练时将图片尺寸统一缩放,像素尺寸为640 px×640 px。HWDXray数据集缺陷样例,如图6所示。
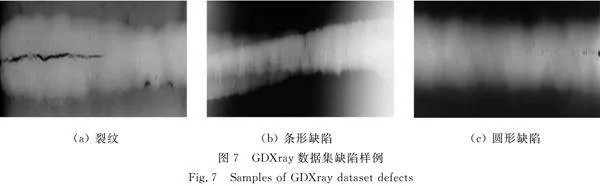
将GDXray数据集的10张焊缝缺陷数据作为验证模型的泛化性能,由于原数据集并没有提供缺陷标注,所以在专业人士的指导下同HWDXray数据集进行相同的标注。GDXray数据集缺陷样例,如图7所示。
2.3 模型评估指标
精度(P)公式为
P=TPTP+FP。(1)
式(1)中:TP为正确识别为正样本的数量;FP为错误识别为正样本但实际上是负样本的数量。
召回率(ξ)为
ξ=TPTP+FN。(2)
式(2)中: FN为预测为负样本但实际上是正样本的数量。
不同召回率对应的精度平均值(Pa,R)为
Pa,R=∑nk=1p(k)ΔR(k)。(3)
式(3)中:n为召回率的总数;p(k)为第k个召回率相对应的精度值;ΔR(k)为第k次召回率和第(k-1)次召回率的差值。
平均精度(Pa)为
Pa=1M∑Mi=1Pi。(4)
式(4)中:M为类别个数。
检测帧率(η)为
η=1ttot=1tpre+tdet+tpos。(5)
式(5)中:ttot为总处理时间;tpre为预处理时间;tdet为检测时间;tpos为后处理时间。
2.4 颈部优化对模型性能的影响
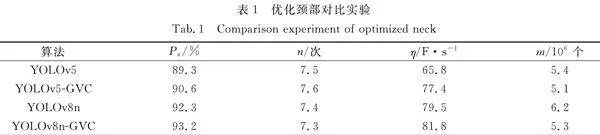
分别在YOLOv8n算法和YOLOv5算法的颈部引入GSConv模块、VoV-GSCSP 模块及轻量级算子Carafe,将其命名为YOLOv8n-GVC算法和YOLOv5-GVC算法。在保持其他参数不变的情况下,使用相同的数据集、实验环境和评估指标进行检测和测试,优化颈部对比实验,如表1所示。 表1中:n为处理器处理次数;m为参数量。
由表1可知:YOLOv8n-GVC算法和YOLOv5-GVC算法的性能表现令人满意,其Pa比原算法分别提高了0.9%和1.3%,YOLOv8-GVC算法最高,为92.3%;YOLOv8n-GVC算法和YOLOv5-GVC算法参数量比原算法也有一定程度的下降,分别下降了0.9×106和0.3×106个,YOLOv5-GVC模型的参数量最少,为5.1×106个;YOLOv5-GVC算法比YOLOv8n-GVC算法参数量更少,算法更轻量化,但YOLOv8n-GVC算法在具备较高识别精度的同时,参数量也得到保证(参数量仅多了0.2×106个,但Pa却提高了2.6%)。
GSConv模块和VoV-GSCSP模块跨级部分网络的设计不但减少了模型计算量,而且提高了对缺陷边缘特征信息的提取,有助于解决大面积母材背景下小面积焊缝缺陷的问题。而轻量级算子Carafe对上采样核进行预测和重组,提高上采样效果,并进一步实现模型的轻量化。表明通过引入GSConv模块、VoV-GSCSP 模块及轻量级算子Carafe,不仅减少算法的计算量,还提高了焊缝缺陷识别的准确率,从而实现了模型精度和速度之间的平衡。
2.5 不同注意力机制对模型性能的影响
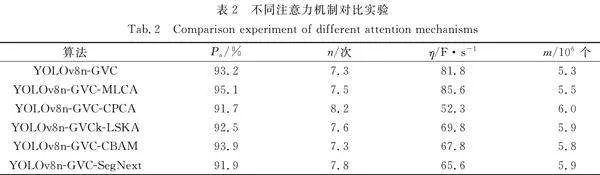
将YOLOv8n-GVC算法作为基准算法,在基准算法的基础上添加了MLCA[19],CPCA(Channel prior convolutional attention[21],LSKA(Large separable kernel attention)[22],CBAM(Convolutional block attention module)[23],SegNext[24]等机制,在保持其他参数不变的情况下,使用相同的损失函数、数据集、实验环境和评估指标。不同注意力机制对比实验,如表2所示。
由表2可知:YOLOv8n-GVC-MLCA算法的Pa最高,为95.1%,比基准算法提高1.9%,表明MLCA机制能够更好地结合更多的通道和空间特征信息,保留了更多的语义信息,提高了对缺陷小目标的检测精度,参数量只增加了0.2×106个,减少对计算资源的需求;增加了注意力机制之后,算法的参数量都比基准算法高,并且大多数η比原基准算法要低,这表明注意力机制的引入影响了模型的效率和速度,增加了算法的参数量,不利于算法的实际应用性。
MLCA机制通过局部池化和全局池化的操作,结合更多的通道和空间特征的信息,在不占用更多内存的情况下,最大限度地保留语义信息,提高模型检测精度。而通过在C2F模块的基础上添加MLCA机制,能够更好地利用空间和通道维度的信息,提高特征的语义性和多样性。
2.6 改进算法性能
在自制的X射线管道焊缝图像数据集上进行改进算法性能的实验测试,将模型训练设置为1 000个epoch,当平均精度没有明显提高时,程序会自动停止训练。改进算法的检测结果,如图8所示。由图8可知:改进算法能够在大面积的焊接母材的背景下检测缺陷,对于整个图形而言,缺陷所占的面积很小,而且在大面积的母材背景下很难被发现,还有多个缺陷重叠的情况,但改进算法对于缺陷的检测结果较好;在针对实际工业环境焊接过程中产生的焊渣影响、不同尺度的缺陷、缺陷重叠等问题上都取得较为不错的结果,有助于分类缺陷、解决缺陷识别困难等问题。
2.7 目标检测算法性能对比
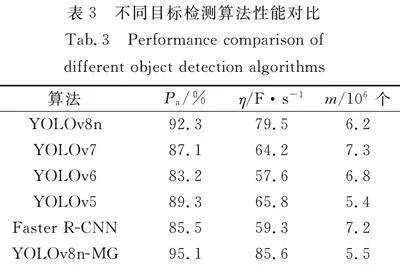
为了验证改进算法的优越性,将YOLOv8n-MG算法与目前主流的目标检测算法进行比较,在保持其他参数不变的情况下,使用相同的评估指标进行比较,比较它们在X射线管道焊缝数据集上的性能表现。不同目标检测算法性能对比,如表3所示。
由表3可知:YOLOv8n-MG算法Pa均优于其他算法,为95.1%,比基准算法提高2.8%,η比基准算法略高6.1 F·s-1,提高了7.7%,参数量比大部分算法更少,比基准算法少0.7×106个,减少了11.3%。这表明YOLOv8n-MG算法在使用更少参数量的基础上,不仅能够保证精度高,还能保持较好的检测速度,实现模型精度和速度之间的平衡。
为了进一步验证改进算法的泛化能力和有效性,将YOLOv8n-MG算法在GDXray数据集上进行验证,比较YOLOv8n-MG在不同数据集的性能表现。YOLOv8n-MG算法在GDXray数据集上的平均精度为63.4%,这表明模型的泛化性能较好。考虑到不同胶片影像采集标准及缺陷定义的差异,各数据集间存在着较大的缺陷类型差距,而YOLOv8n-MG算法能在相似的焊缝缺陷数据集上识别出正确缺陷,展现出不错的泛化性能。
结果表明,提出改进的YOLO算法取得了令人满意的结果,对缺陷小目标检测、缺陷重叠、模型参数量较大等问题具有优异性,以较少的参数量实现了更高的精准度和推理速度,也证明模型具有一定的泛化性能,这有利于实验场景中的适用性和有效性。改进的YOLO算法不仅保留了YOLO系列的速度优势,而且提高了对焊缝缺陷小目标的检测精度。
3 结论
为了解决X射线管道焊接检测中存在的数据集缺乏、缺陷小目标、遮挡重叠、推理速度慢等问题,自制了X射线管道焊接缺陷数据集,并提出YOLOv8n-MG算法。YOLOv8n-MG算法在YOLOv8n算法的基础上,对算法多个方面进行了优化和改进,包括对优化颈部为GSConv,并引入VoV-GSCSP模块和Carafe轻量级上采样算子,对骨干的C2F模块添加MLCA机制。利用自制的X射线管道焊缝缺陷HWDXray数据集,使用平均精度和检测帧率等指标评估了算法性能,并与其他目标检测算法和GDXray数据集进行比较。结果表明,YOLOv8n-MG算法在保持较高检测速度的同时,显著提高了检测精度,取得了良好的效果。
未来将进一步发展检测模型,并扩大数据集,收集更多情况下的X射线管道焊缝样本,使每种缺陷的样本更加丰富和均衡,从而能够更详细地分析和标注缺陷特征;继续专注于提高算法检测准确性,降低网络参数,并将算法和系统部署到普通的计算机设备中。从而能够帮助相关的检验人员辅助X射线管道焊缝缺陷的检测工作。
参考文献:
[1] 高杨.长输管道自动焊接设备及技术发展探究[J].石化技术,2022,29(12):219-221.
[2] BARSOUM Z,JONSSON B.Influence of weld quality on the fatigue strength in seam welds[J].Engineering Failure Analysis,2011,18(3):971-979.DOI:10.1016/j.engfailanal.2010.12.001.
[3] GIRSHICK R,DONAHUE J,DARRELL T,et al.Region-based convolutional networks for accurate object detection and segmentation[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2015,38(1):142-158.DOI:10.1109/TPAMI.2015.2437384.
[4] GAVRILESCU R,ZET C,FOAL U C,et al.Faster R-CNN: An approach to real-time object detection[C]∥2018 International Conference and Exposition on Electrical and Power Engineering.Lasi:IEEE Press,2018:0165-0168.DOI:10.1109/ICEPE.2018.8559776.
[5] KONG Tao,YAO Anbang,CHEN Yurong,et al.Hypernet: Towards accurate region proposal generation and joint object detection[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Las Vegas:IEEE Press,2016:845-853.DOI:10.1109/CVPR.2016.98.
[6] REDMON J,DIVVALA S,GIRSHICK R,et al.You only look once: Unified, real-time object detection[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Las Vegas:IEEE Press,2016:779-788.DOI:10.1109/CVPR.2016.91.
[7] REDMON J,FARHADI A.YOLO9000: Better, faster, stronger[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Honolulu:IEEE Press,2017:7263-7271.DOI:10.1109/CVPR.2017.690.
[8] REDMON J,FARHADI A.YOLOV3: An incremental improvement[EB/OL].(2018-04-08)[2024-01-03].https:∥arxiv.org/abs/1804.02767.
[9] LIU Wei,ANGUELOV D,ERHAN D,et al.SSD: Single shot multibox detector[C]∥Computer Vision-ECCV 2016: 14th European Conference.Cham:Springer International Publishing,2016:21-37.DOI:10.1007/978-3-319-46448-0_2.
[10] LIU Weipeng,SHAN Shengqi,CHEN Haiyong,et al.X-ray weld defect detection based on AF-RCNN[J].Welding in the World,2022,66(6):1165-1177.DOI:10.1007/s40194-022-01281-w.
[11] CHEN Yongbin,WANG Jingran,WANG Guitang.Intelligent welding defect detection model on improved R-CNN[J].IETE Journal of Research,2023,69(12):9235-9244.DOI:10.1080/03772063.2022.2040387.
[12] LIU Moyun,CHEN Youping,XIE Jingming,et al.LF-YOLO: A lighter and faster YOLO for weld defect detection of X-ray image[J].IEEE Sensors Journal,2023,23(7):7430-7439.DOI:10.1109/JSEN.2023.3247006.
[13] ZHANG Yi,NI Qingjian.A novel weld-seam defect detection algorithm based on the S-YOLO model[J].Axioms,2023,12(7):697.DOI:10.3390/axioms12070697.
[14] 程松,杨洪刚,徐学谦,等.基于YOLOv5的改进轻量型X射线铝合金焊缝缺陷检测算法[J].中国激光,2022,49(21):2104005.DOI:10.3788/CJL202249.2104005.
[15] YANG Jun,FU Bo,ZENG Jinquan,et al.YOLO-Xweld: Efficiently detecting pipeline welding defects in X-ray images for constrained environments[C]∥International Joint Conference on Neural Networks.Padua:IEEE Press,2022:1-7.DOI:10.1109/IJCNN55064.2022.9892765.
[16] HU Jie,WANG Zhangbin,CHANG Minjie,et al.Psg-YOLOV5: A paradigm for traffic sign detection and recognition algorithm based on deep learning[J].Symmetry,2022,14(11):2262.DOI:10.3390/sym14112262.
[17] LI Hulin,LI Jun,WEI Hanbing,et al.Slim-neck by GSConv: A lightweight-design for real-time detector architectures [J].Journal of Real-Time Image Processing,2024,21(3):62.DOI:10.1007/s11554-024-01436-6.
[18] WANG Jiaqi,CHEN Kai,XU Rui,et al.Carafe: Content-aware reassembly of features[C]∥Proceedings of the IEEE/CVF International Conference on Computer Vision.Seoul:IEEE Press,2019:3007-3016.DOI:10.1109/ICCV.2019.00310.
[19] WAN Dahang,LU Rongsheng,SHEN Siyuan,et al.Mixed local channel attention for object detection[J].Engineering Applications of Artificial Intelligence,2023,123:106442.DOI:10.1016/j.engappai.2023.106442.
[20] MERY D,RIFFO V,ZSCHERPEL U,et al.GDXray: The database of X-ray images for nondestructive testing[J].Journal of Nondestructive Evaluation,2015,34(4):42.DOI:10.1007/s10921-015-0315-7.
[21] HUANG Hejun,CHEN Zuguo,ZOU Ying,et al.Channel prior convolutional attention for medical image segmentation[EB/OL].(2023-06-08)[2024-01-03].https:∥arxiv.org/abs/2306.05196.
[22] LAU K W,PO L M,REHMAN Y A U.Large separable kernel attention: Rethinking the large kernel attention design in cnn[J].Expert Systems with Applications,2024,236:121352.DOI:10.1016/j.eswa.2023.121352.
[23] WOO S H,PARK J,LEE J Y,et al.Cbam: Convolutional block attention module[C]∥Proceedings of the European Conference on Computer Vision.Cham:Springer International Publishing,2018:3-19.DOI:10.1007/978-3-030-01234-2_1.
[24] GUO Menghao,LU Chengze,HOU Qibin,et al.Segnext: Rethinking convolutional attention design for semantic segmentation[J].Advances in Neural Information Processing Systems,2022,35:1140-1156.DOI:10.48550/arXiv.2209.08575.
(责任编辑: "陈志贤" 英文审校: 陈婧)
通信作者: 郑力新(1967-),男,教授,博士,主要从事图像分析、机器视觉、深度学习方法的研究。E-mail:zlx@hqu.edu.cn。
基金项目: 福建省科技计划项目(2020Y0039); 福建省泉州市科技计划项目(2020C042R)https://hdxb.hqu.edu.cn/
猜你喜欢
科技创新与应用(2017年7期)2017-03-27 17:21:04
中国高新技术企业(2016年34期)2017-02-10 16:40:20
计算技术与自动化(2016年4期)2017-01-11 14:19:49
北极光(2016年2期)2016-04-29 22:29:52
中国科技博览(2016年10期)2016-04-29 05:22:41
科技视界(2016年3期)2016-02-26 11:42:37
科学家(2015年12期)2016-01-20 06:37:36
科技资讯(2015年23期)2016-01-12 18:51:48
智富时代(2015年4期)2015-06-02 06:33:20
软件导刊(2015年1期)2015-03-02 12:27:17
