
基于质谱的N-糖蛋白分析进展
2023-12-30 13:42田志新
中国药科大学学报 2023年6期
田志新
(同济大学化学科学与工程学院,上海 200092)
N-连接糖基化(简称N-糖基化)是蛋白质上常见的翻译后修饰。在修饰位点方面,N-糖基化修饰在N-X-S/T/C(X ≠ P)序列子上,人体蛋白质组中具有至少一个序列子,也就是说潜在的N-糖蛋白占78.8%;一个蛋白质的氨基酸序列上,一般具有多个序列子,这些序列子可以修饰一个或多个N-糖基化的组合;这是N-糖基化修饰位点的宏观不均一性,跟其他小分子(如甲基化、乙酰化、磷酸化)相同。在修饰结构方面,与小分子修饰仅仅具有单一结构不同,糖基化修饰具有数以万计的结构,包含单糖组成,序列结构、链接结构、异头异构,立体构象等多个结构维度;N-糖基化修饰也因此具有独特的微观不均一性,同一个N-糖基化位点通常按一定的化学计量比修饰不同的糖链。N-糖基化修饰以位点和结构特异的方式调控N-糖蛋白的结构和功能。突变PD-1 第71 号N-糖基化位点(N71)可以减少其对CAR-T细胞的抑制,从而提高CAR-T 的细胞毒性和免疫治疗的疗效[1]。PD-1上第58 号N-糖基化位点(N58)上的N-糖基化是PD-1 和PD-L1 结合所必需的[2]。带特定糖链结构和核心岩藻糖(YY(F)M(MYLS)MYLS,Y 为N-乙酰葡萄糖胺,M 为甘露糖,L 为半乳糖,F 为岩藻糖,S为唾液酸)的甲胎蛋白(AFP)糖基化变体(AFPL3)较全部AFP 蛋白在肝癌早期诊断中具有更高的灵敏度[3]。N-连接糖外侧的岩藻糖与病毒感染[4]、肠道微生物[5]、肠道共生菌[6]等密切相关;N-连接糖外侧的唾液酸则与抗炎[7]、过敏[8]及肠道微生物[9]密切相关。Fc 段带α2,6 唾液酸的IgG 在关节炎治疗中具有抗炎活性,而对应的α2,3 变体则没有。疾病条件下的N-糖基化需通过位点和结构特异的定量分析来表征。
随着材料制备、高效液相色谱分离、高效串级质谱分析、智能化生物信息学等技术的快速发展和广泛应用,基于质谱的组学技术已被深入用于正常生理和异常病理条件下蛋白质N-糖基化的位点和结构特异定性定量分析。在分子水平上,借助仅使用外切糖苷酶(如PNGase F),仅使用蛋白质水解酶(如胰蛋白酶),同时使用上述两种酶和不使用任何酶,N-糖基化可以在N-连接糖[10-15]、完整N-糖肽[16-33]、含N-糖基化位点多肽[12]、完整N-糖蛋白[34]等4个层次上进行分析(图1-A)。
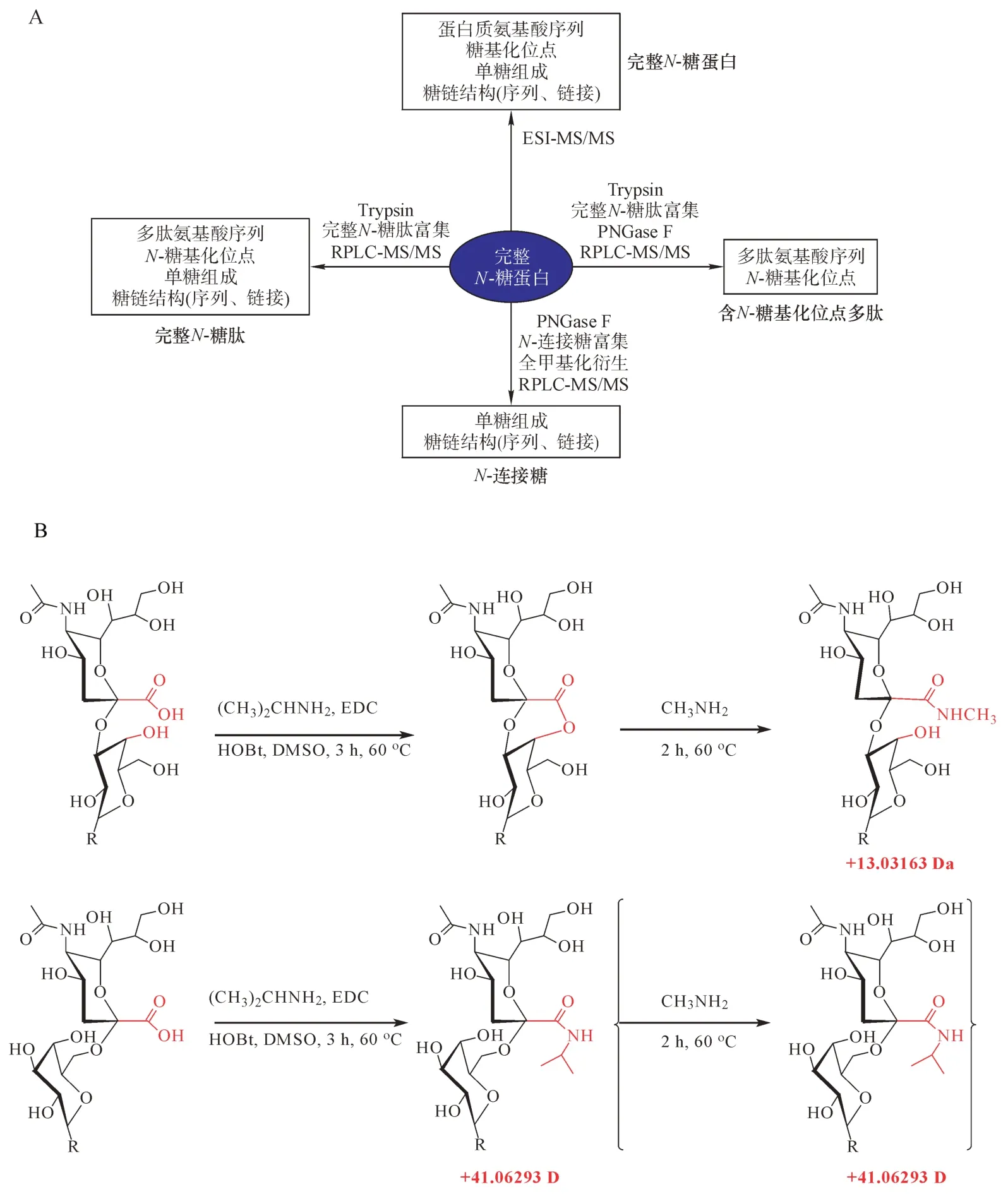
图1 蛋白质N-糖基化质谱分析的分子水平及唾液酸链接特异化学衍生反应策略
在N-连接糖分子水平上的N-糖基化分析,Xiao 等[14], Human Glycome Project[35], 以及Mechref等[36]先后进行了一般性全面综述报道。在完整N-糖肽分子水平上的N-糖基化分析,Luo 等[37]在富集,Reiding 等[38]在串级质谱解离,DelaField 等[39]在定量,Polasky 等[40]在生物信息学等方面进行了具体的综述;Kolarich 等[41]、Scott等[42]、Thaysen-Andersen等[43]则进行了一般性的全面综述。
本文主要介绍本课题组基于选择性化学衍生的唾液酸链接结构鉴定[26]、基于亲水分离的唾液酸链接异构和岩藻糖位置异构的鉴定、基于同位素质荷比及轮廓指纹比对原位质谱解析算法[44-46]、基于位点决定性碎片离子的N-糖基化位点定位[47]、基于结构诊断离子的N-连接糖序列结构的鉴定、基于特征碎片离子的特定序列和链接结构(如核心岩藻糖、平分型结构、唾液酸链接异构)的验证、基于两重同位素[25]和多重等重[26]标记的定量等技术所发展的位点和结构特异定量N-糖蛋白质组学;同时介绍在癌症细胞模型(癌细胞[20,29]、癌症干细胞[27]、耐药癌细胞[18,21,23-24,31])、癌症临床成对癌和癌旁组织、癌症血清[48]、人体体液(尿液[28])、大分子药物(新冠重组疫苗[33]、单克隆抗体[32])等体系中(差异表达)N-糖基化的分析。
1 基于质谱的N-糖蛋白分析新技术新方法进展
1.1 基于选择性化学衍生的唾液酸链接结构鉴定
烷基酰胺化是唾液酸α2,3 和α2,6 链接特异衍生的常见化学反应(图1-B)。α2,3 链接选择性与甲胺反应,质量上增加13 D;而α2,6链接选择性与异丙胺反应,质量上增加41 D。在结合多重TMT 标记的临床肺癌组织(相对于癌旁组织)差异表达唾液酸化的比较N-糖蛋白质组学研究中,田等[26]鉴定出307 个具有链接特异性的唾液酸化完整N-糖肽,对应于84个N-连接糖、232个N-糖基化位点、229 个多肽骨架和221 个完整N-糖蛋白;以倍数变化≥ 1.5 和P< 0.05 为标准,共定量到84 个链接特异唾液酸化完整N-糖肽,其中29个含有α2,6链接,55个含有α2,3链接。例如,来自葡萄糖-6-磷酸异构酶(P06744,G6PI_HUMAN)N-糖基化位点N105 的双α2,6-链接唾液酸化,变化倍数为1.92;来自酪氨酸蛋白激酶(Q9H792,PEAK1_HUMAN)N-糖基化位点N677 的双α2,3-链接唾液酸化,其倍数变化为0.83(图2)。

图2 通过唾液酸链接特异衍生鉴定的完整N-糖肽[26]
1.2 基于亲水分离的唾液酸链接异构和岩藻糖位置异构的鉴定
亲水作用色谱对唾液酸链接异构和岩藻糖位置(序列)异构体具有非常高的分离分辨,在完整N-糖肽分子水平上可以达到基线分离。在基于penta-HILIC-MS/MS 在线分离分析的HepG2 中差异表达N-糖基化的研究中,来自三肽基肽酶Ⅰ(O14773,TPP1_HUMAN)的完整N-糖肽FLSSPHLPSSYFNASGR_N3H4F0S1 的α2,3 链接异构体 01Y41Y41 M(31M)61M61Y41L32S 在HepG2 细胞(相对于LO2细胞)中上调(6.2 ± 1.2);而具有相同单糖组成和序列结构的α2,6 链接异构体01Y41Y41M(31 M)61M61Y41L62S 下调(0.3 ± 0.1)(图3)[20]。来自整合素a3(P26006,ITA3_HUMAN)的完整N-糖肽MNITVK_N4H5F1S2 的岩藻糖支链异构体01Y41Y41M(31M21Y(31F)41L32S)61M61Y41L32S在HepG2 中下调(0.4 ± 0.1),而对应的核心异构体 01Y(61F)41Y41M(31M41Y41L2S)61M41Y41L32 S上调(1.5 ± 0.1)(图4)。
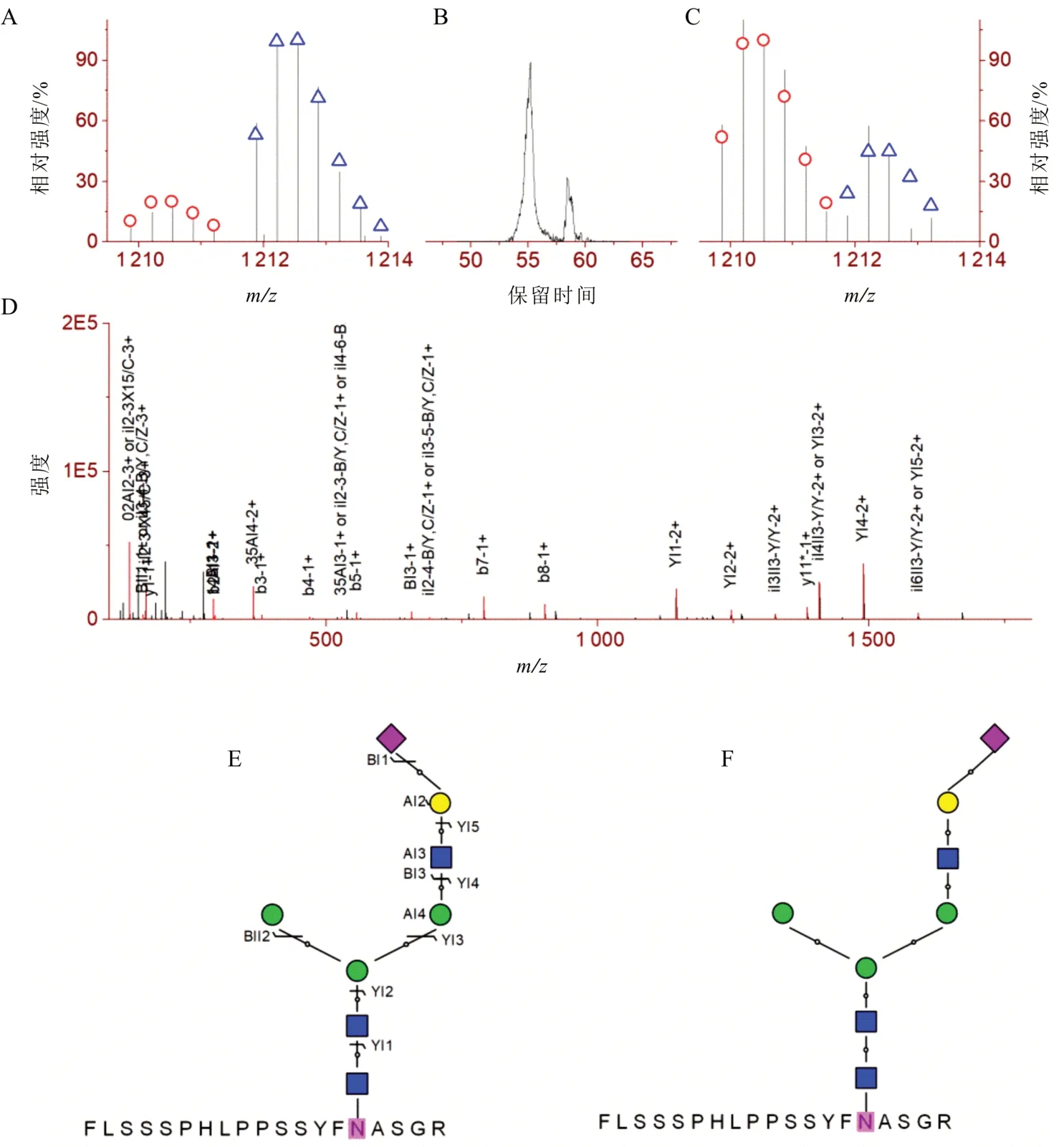
图3 具有相同单糖组成N3H4F0S1和序列结构的完整N-糖肽FLSSPHLPSSYFNASGR(O14773,TPP1_HUMAN)的唾液酸链接特异的差异表达;在HepG2 与LO2 中,01Y41Y41M(31M) 61M61Y41L32S(A,B 中的左LC 峰)的上调(6.2 ± 1.2)与01Y41Y41M(31 M) 61M61Y41L62S(C,B中)的下调(0.3 ± 0.1)[20]
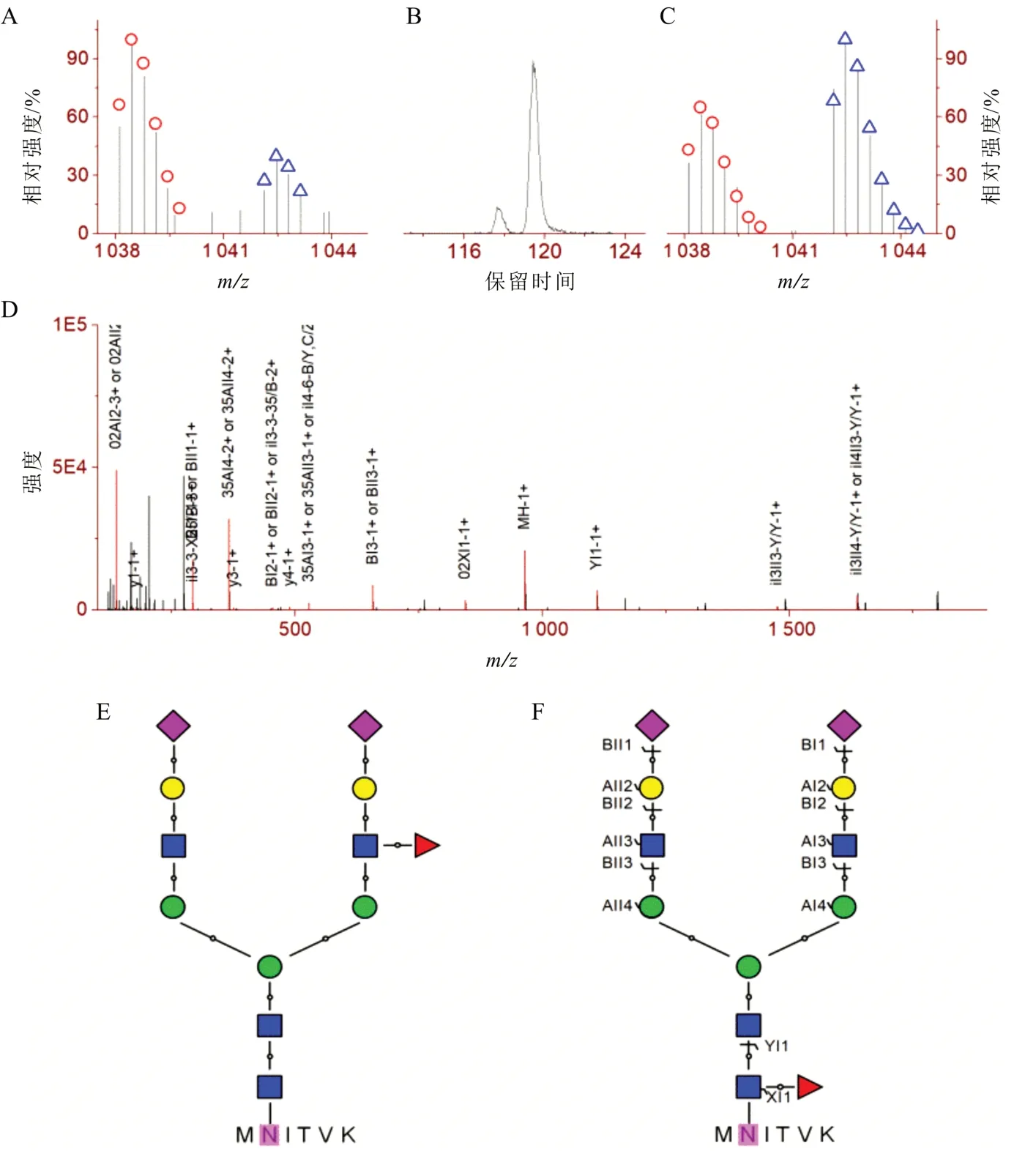
图4 来自整合素α3(P26006,ITA3_HUMAN)的完整N-糖肽MNITVK_N4H5F1S2 的岩藻糖序列/位置异构体特异差异表达。在HepG2 与LO2 中,支链异构体01Y41Y41M(31M21Y(31F)41L32S) 61M61Y41L32S(a,左侧LC 峰值在B 中)的下调(0.4 ± 0.1)与核心异构体01Y(61F)41Y41M(31M41Y41L2S) 61M61g41L32S的上调(1.5 ± 0.1)(C,右侧LC峰值在B中)[20]
1.3 基于同位素质荷比及轮廓指纹比对原位质谱解析算法
基于电子轰击和化学电离的无机及有机质谱中,分子离子峰一般是1价(由电离方式决定,无论正、负离子)且其同位素轮廓最左侧单同位素峰理论强度往往是最高的(由分子大小决定,随着分子增大,强度逐渐降低;直至8 000 D 左右完全消失,此时整个轮廓呈高斯对称状)。此时单同位素峰的质荷比实验值可以准确用于分子的定性鉴定。基于电喷雾电离的生物质谱中,分子离子峰一般是多价且其同位素轮廓最左侧的同位素峰因强度较低,在实验上往往观察不到,也就是不能被直接测量到。传统解析算法通常使用模型分子(如平均氨基酸)对实验轮廓进行拟合来获得实验上没有被观察到的单同位素峰及其质荷比,但很难处理重叠数据、非理想数据以及相对分子质量超过10 kD的分子。Li等[44]发明了同位素质荷比及轮廓指纹比对(isotopic mass-to-charge ratio and envelope fingerprinting, iMEF)原位解析算法,通过整个实验和理论轮廓的比对来解析质谱图中离子(图5-A),包括一级质谱中的前体离子和多级质谱中的碎片离子。通过要求同位素峰强度阈值(IPACO,isotopic peak abundance cutoff)以上的每个理论同位素峰在实验同位素轮廓中被观察到,且同位素峰质荷比偏差(IPMD,isotopic peakm/zdeviation)和同位素峰强度偏差(IPAD,isotopic peak abundance deviation)须满足设定的阈值,全面严格控制实验同位素轮廓的质量,从而从源头上控制相应分子鉴定的准确度。同位素轮廓指纹比对算法的另外一个优势是重叠同位素轮廓数据的有效解析(图5-B),从而将质谱图信号利用得最大化,解析出最多的离子,在二级质谱中将鉴定、修饰位点定位和修饰结构的鉴定最大化。
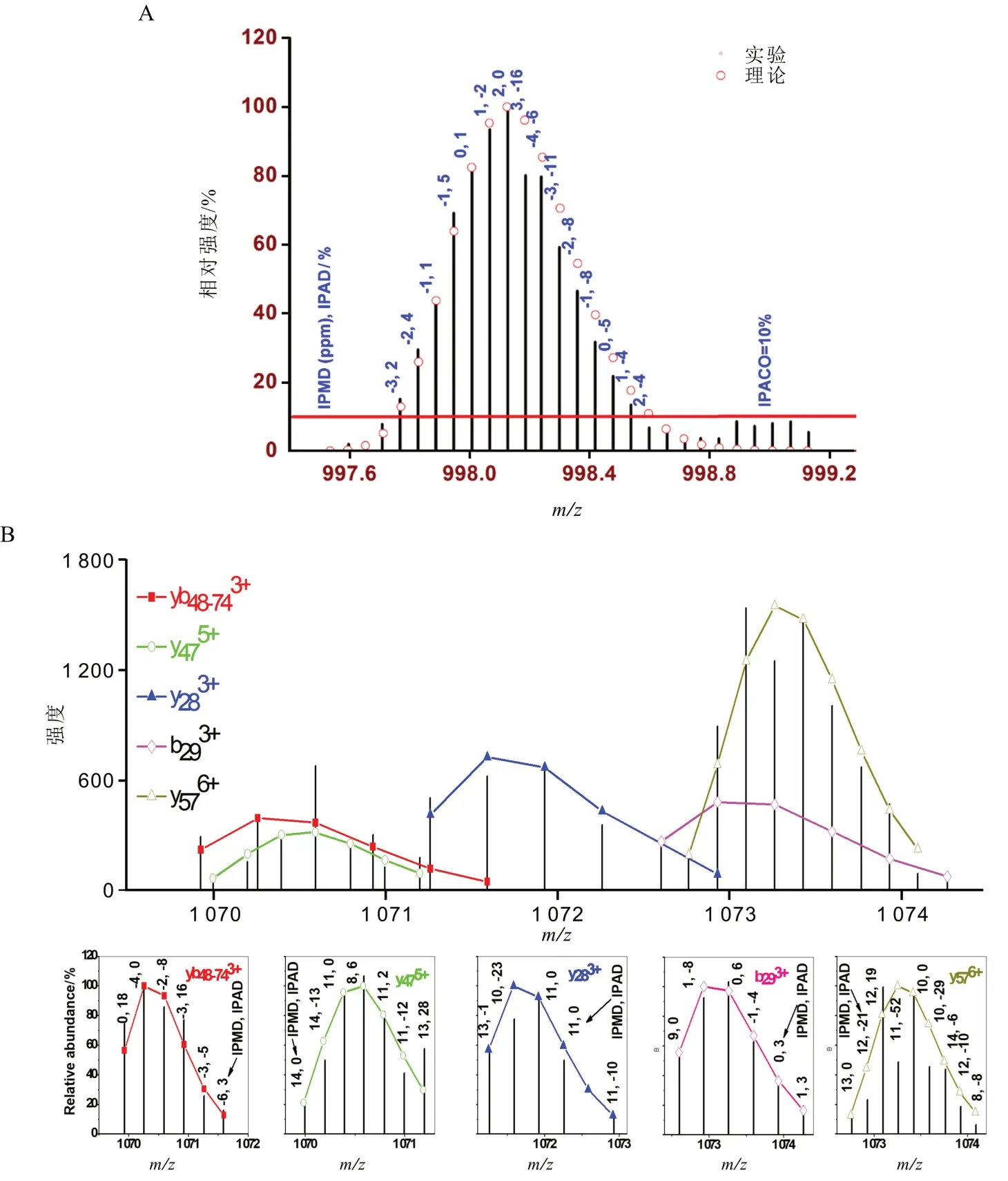
图5 基于同位素轮廓指纹比对的原始质谱图及重叠数据的解析A:同位素轮廓指纹比对(圆圈:理论轮廓;竖线:实验轮廓);B:基于同位素轮廓指纹比对的重叠数据的解析
1.4 基于位点决定性碎片离子的N-糖基化位点定位
同一个多肽或蛋白质氨基酸序列上往往具有多个潜在的N-糖基化位点。考虑到脆弱修饰(如磷酸化、糖基化等)在串级质谱中存在较大比率中性丢失的情况,Shen 等[28]发展了基于包含修饰(残基或完整分子)的位点决定性碎片离子对的定位方法,利用直接的实验证据对修饰进行准确定位(图6-A)。利用该定位策略的磷酸化定位工具Pbracket 在对包含101 520 个合成磷酸肽(位点已知)的96 个LC-MS/MS 数据组中,错误定位率为0.9%[45]。在N-糖基化的定位中,基于包含N-乙酰葡萄糖胺残基的位点决定性b/y 离子对(由高能碰撞诱导解离产生)和或包含完整N-连接糖分子的位点决定性c/z 离子对(由基于电子的解离方式产生,图6-B)对N-糖基化修饰位点进行准确定位。

图6 基于位点决定性碎片离子的翻译后修饰的定位
1.5 基于结构诊断离子的N-连接糖序列结构的鉴定
同一个单糖组成一般对应数10 个序列结构,除了谱图水平上常规基于靶向-诱饵数据库搜索的假阳性控制,不同序列结构可以由特征序列结构诊断碎片离子进行区分和确认。Xiao 等[20]定义了Glycoform score(简称为G Score),其定义为能独立区分相同分子组成(分子式,包括相同单糖组成)的不同序列结构的结构诊断碎片离子的数量[11,20]。单糖组成为N4H5F1S2 的N-连接糖的岩藻糖支链位置异构体和核心位置异构体在高能碰撞诱导解离中分别得到了4 个(3,5AI4-1+、YI3-2+、YI2-2+、YI1-2+)和3 个(YI1-1+、ZI4-2+、YI3-2+)结构诊断碎片离子的相互区分和鉴定(图7-A ~ 7-D)。
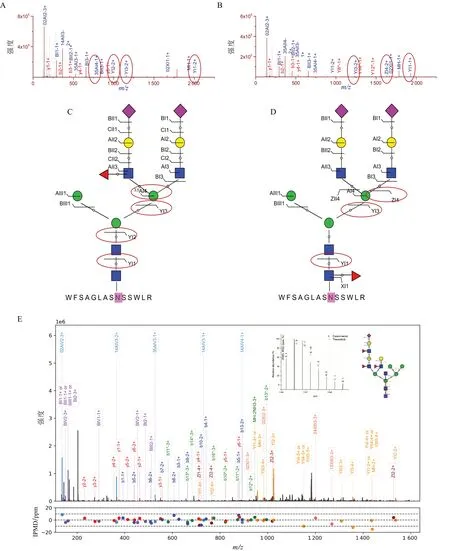
图7 基于结构诊断碎片离子的岩藻糖支链和核心序列异构体的区分
1.6 基于特征碎片离子的特定序列和链接结构的验证
平分型结构、核心岩藻糖等特征序列结构可以通过对应的特征单糖序列进行靶向验证。平分型结构特征单糖序列为N-N-H-N 或N(F)-N-H-N(如果含有核心岩藻糖)。如在单糖组成为N5H9F3S1 的完整N-糖肽(图7-E)的N-连接糖部分结构的鉴定中,观察到了N-N-H-N 对应的+2 价碎片离子;从而实现了该平分型结构的验证。
1.7 基于同位素两重标记的相对定量
完整N-糖肽分子水平上的N-糖基化的定量可以采用鸟枪法蛋白质组学常用的N 端及赖氨酸残基上胺基的还原烷基化来实现,包括适用于成对样本的同位素标记(如二甲基化、二乙基化)和大队列样本的等重标记(如iTRAQ、TMT)。Wang等[25]发展的稳定同位素二乙基标记获得了高达50倍的动态范围(图8-A),随后在癌症、癌症干细胞、耐药癌细胞等体系中差异表达N-糖基化分析中得到了广泛应用。
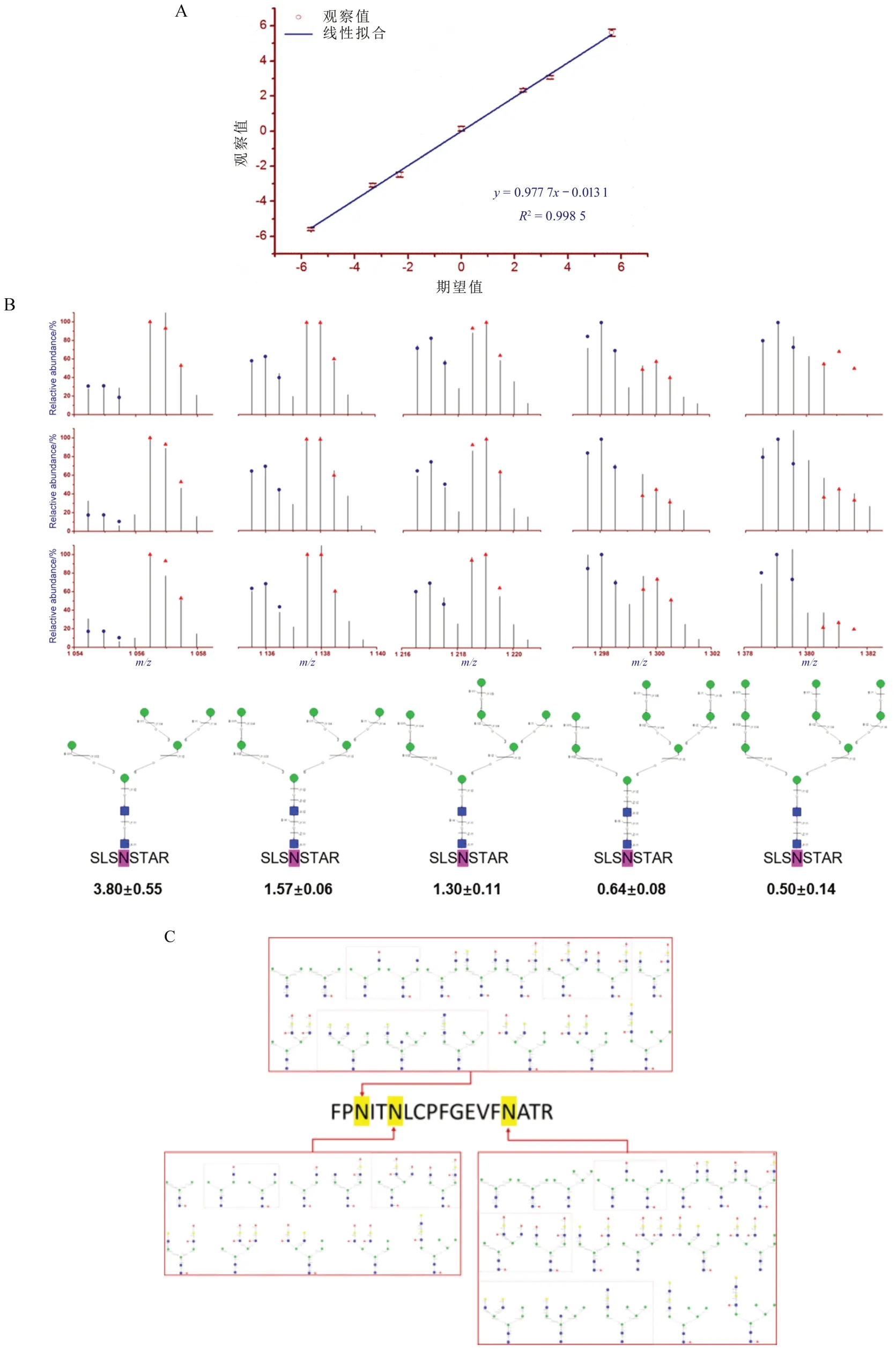
图8 N-糖基化的位点和结构特异定性定量分析
2 基于质谱的N-糖蛋白分析应用进展
2.1 在潜在N-糖蛋白质标志物位点和结构特异发现中的应用
上述位点和结构特异定量N-糖蛋白质组学方法已被应用于基于细胞模型和临床样本(血清、成对癌和癌旁组织、尿液)的癌症、癌症干细胞、癌症耐药等体系中差异表达N-糖基化的分析,观察到了疾病条件下位点和结构特异的异常N-糖基化变化。另外,还观察到了N-连接糖尺寸依赖的差异表达,如在MCF7/ADR CSCs(相对于MCF7/ADR)中观察到了甘露糖尺寸依赖的由上调,到趋于平缓,到下调的联系变化(图8-B)[24]。
2.2 在N-糖蛋白生物药位点和结构特异表征中的应用
除了临床复杂样本,上述位点和结构特异N-糖蛋白质组学方法也被广泛应用于单个N-糖蛋白N-糖基化宏观和微观不均一性的鉴定;同一个糖链可以修饰在不同的糖基化位点,且同一个单糖组成往往对应多个序列结构。如新冠病毒重组S蛋白受体结合区域共有3 个N-糖基化位点,N331,N334 和N343[33];分别鉴定到了12 个、17 个和19 个糖链结构(图8-C);其中包含3组序列异构体(图中虚线框中的结构)。
3 结论与展望
基于质谱的最新发展水平的位点和结构特异定量N-糖蛋白质组学目前已经成为蛋白质N-糖基化修饰定性定量分析的首选方法。相对于N-连接糖和完整N-糖蛋白分子,在完整N-糖肽分子水平上,当前高效液相色谱对完整N-糖肽复杂混合物具有较高的分离分辨和峰容量,保证了整体定性定量分析的深度。借助多肽骨架的同位素标记和等重多重标记,可以实现少量样本(如成对样本)和大队列样本的相对定量,实现疾病条件下差异表达的N-糖基化在完整N-糖肽水平上的位点和结构特异的准确定量。在生物信息学数据解析方面,相对于基于质量比对的传统方法,同位素轮廓指纹比对搜索算法能够准确识一级质谱的前体离子和二级质谱中的碎片离子;同时能对重叠数据进行高效解析,匹配实验碎片离子解析的最大化直接提高氨基酸和单糖序列结构和N-糖基化位点鉴定的准确度。基于包含部分(如完整N-糖肽上N-糖基化部分在高能碰撞诱导解离下留在多肽骨架上的单个N-乙酰葡萄糖胺单糖)和或完整(如基于电子的解离中N-连接糖部分保持完整)糖基化修饰的位点决定性碎片离子,也就是利用直接实验中观察到的直接证据,实现N-糖基化位点的准确定位;对于单糖序列结构,一个分子组成(包括同单糖组成)对应的多个潜在序列结构可以由序列结构诊断和特征碎片离子进行明确区分和确认;对于唾液酸链接结构,链接特异化学衍生反应(如烷基酰胺化)、亲水色谱分离以及串级质谱特征都能进行有效区分和确认。位点和结构特异定量N-糖蛋白质组学方法的推广正助力更高效N-糖蛋白相关早诊标志物、药物靶点及药物的研发及精准医学的发展。
猜你喜欢
河南化工(2022年5期)2023-01-03
食品安全导刊(2021年21期)2021-08-30
现代畜牧科技(2021年6期)2021-07-16
食品工业科技(2019年5期)2019-04-01
中国药理学与毒理学杂志(2015年3期)2015-12-16
医学研究杂志(2015年12期)2015-06-10
大连医科大学学报(2015年6期)2015-03-22
中国当代医药(2015年33期)2015-03-01
中国粮油学报(2014年7期)2014-02-06
现代检验医学杂志(2014年1期)2014-02-06
