
基于算法推荐的个性化广告传播研究
2023-12-30 02:01徐慧琴郝风平方志伟聂莉娟
无线互联科技 2023年20期
徐慧琴,郝风平,方志伟,聂莉娟
(金肯职业技术学院,江苏 南京 210000)
0 引言
在当今数字化时代,广告传播已经从传统的媒体平台转向了互联网和新媒体渠道。这种转变推动了个性化广告传播的兴起,为广告主和消费者之间的互动提供了新的机遇和挑战[1]。个性化广告传播技术通过采集用户行为、兴趣和特征等数据,能够精确地向目标受众传递广告信息,满足他们多样化的需求和兴趣。相比传统的广告传播方式,基于算法推荐的个性化广告传播具有更高的精准度和效果,同时也可以减少资源浪费。本文旨在深入研究基于算法推荐的个性化广告传播,探讨其原理、实现流程和效果评估等,并解决其中存在的问题与挑战。通过对该领域的深入剖析和实证研究,希望为广告行业提供有效的个性化广告传播解决方案,推动该技术的进一步创新和发展。
1 个性化广告推荐算法的原理及分类
个性化广告推荐技术的核心思想是基于用户的行为、兴趣和社交等信息,对广告进行个性化推荐,提高广告的效果和用户满意度。根据推荐算法的不同,个性化广告推荐技术可以分为基于协同过滤的算法、基于内容的算法、基于混合算法的算法等[2]。
1.1 基于协同过滤的算法
基于协同过滤的算法是一种利用用户之间的相似性和共同行为模式进行推荐的方法,通过分析用户的历史行为找到与其相似的用户或物品,从而推荐给用户与其兴趣相关的广告。具体来说,基于协同过滤的算法分为基于用户的协同过滤和基于物品的协同过滤。
基于用户的协同过滤是通过分析用户之间的相似度来找到兴趣相似的用户,从而推荐广告。在具体实施时首先是计算用户之间的相似度,通常采用余弦相似度、Jaccard相似度等指标进行计算;接着根据用户相似度对广告进行推荐,通常采用最近邻算法、基于矩阵分解的算法等进行计算。
基于物品的协同过滤则是通过分析广告之间的相似度,找到与目标广告相似的广告,从而推荐给用户。基于物品的协同过滤算法在计算相似度推荐时通常采用基于物品的最近邻算法等方法。
1.2 基于内容的算法
基于内容的算法是一种基于广告内容的推荐算法,它通过分析广告的特征和内容,找到与用户兴趣相似的广告,从而进行推荐。基于内容的算法分为以下几个阶段:
第一阶段,对广告的内容进行分析和特征提取。通常采用自然语言处理技术和机器学习技术对广告进行文本处理、特征提取和降维处理,从而得到广告的特征向量。
第二阶段,对用户进行兴趣建模。通常采用协同过滤算法、聚类算法等技术对用户的历史行为和兴趣进行建模,从而得到用户的兴趣向量。
第三阶段,计算广告和用户之间的相似度。通常采用余弦相似度、欧式距离、曼哈顿距离等指标计算广告和用户之间的相似度。
第四阶段,根据相似度对广告进行推荐。通常采用基于内容的最近邻算法、基于贝叶斯分类器的算法等对广告进行推荐。
1.3 基于混合算法的算法
基于混合算法的算法是一种将多种推荐算法进行混合的推荐算法,旨在提高推荐准确率和覆盖率。基于混合算法的算法可以分为多种类型,如基于加权融合的算法、基于规则融合的算法、基于深度学习的算法等。将多种推荐算法进行整合,从而提高推荐准确率和覆盖率。基于混合算法的算法首先是采用不同的推荐算法对广告进行推荐,例如:基于协同过滤的算法、基于内容的算法等;接着对推荐算法的结果进行不同技术的融合,如加权融合、规则融合等,从而得到最终的推荐结果。
2 算法应用的实现流程
基于算法推荐的个性化广告传播技术是一种利用用户数据和算法模型进行广告精准推荐的方法。该技术的实现流程主要包括以下几个方面。
2.1 数据采集和预处理
个性化广告推荐系统的实现需要收集和处理用户和广告数据,包括用户的行为数据、兴趣数据和社交关系数据,以及广告的内容、结构、语言风格等数据。(1)从目标数据源(如数据库、网站等)获取原始数据,为了确保数据的准确性和完整性,对原始数据进行清洗操作。(2)进行数据的转换与整合,将不同格式和来源的数据进行统一表示,完成数据的转换与整合之后,通过特征选择与构建,从数据中提取出与研究目标相关的有代表性的特征。(3)进行特征缩放和特征归一化,消除不同特征间的尺度差异。(4)对预处理后的数据集进行划分,将其分为训练集和测试集,并进行必要的数据集平衡处理,以确保两个数据集的样本分布较为均衡。通过这些步骤,本研究得到了高质量、适用于后续分析和建模的数据集,为研究提供了可靠的基础。具体的数据采集及预处理运行流程如图1所示。
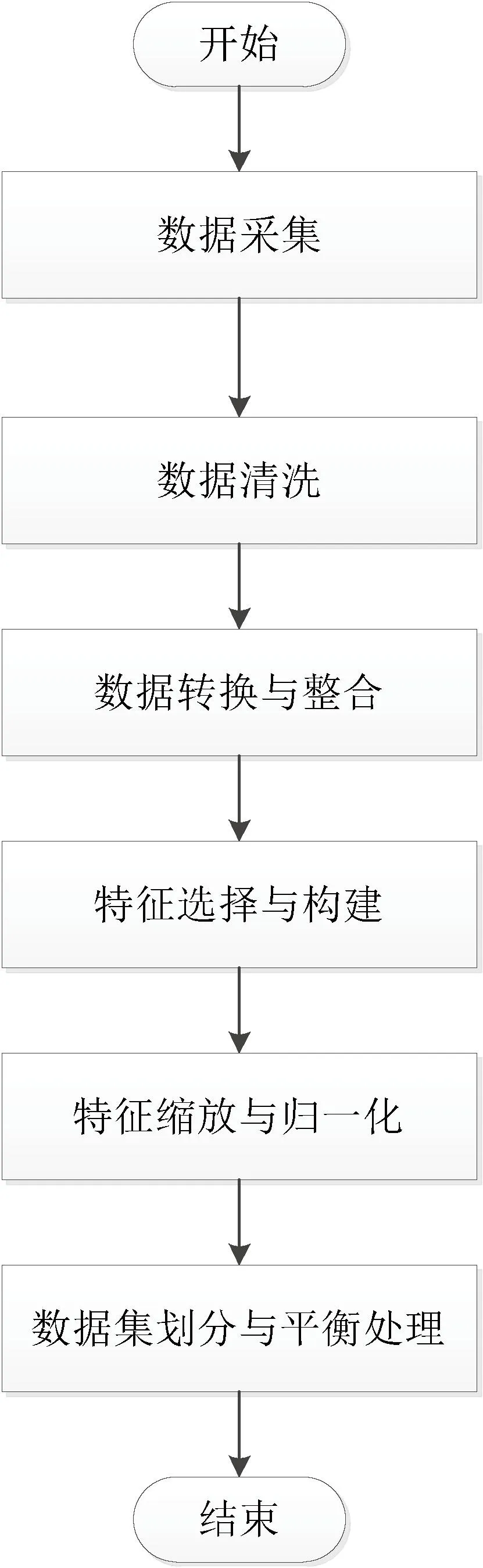
图1 数据采集及预处理运行流程
2.2 用户标签建模
在用户数据分析的基础上,可以将用户标记为不同的兴趣类别或特征标签。用户标签建模的核心步骤涉及特征提取。特征提取通过分析用户的历史行为数据和其他相关信息,本研究采用逻辑回归算法提取具有代表性和区分性的特征。
P(y=1|x)=1/(1+exp(-(wT×x+b)))
(1)
式(1)表达了目标变量取值为1的概率,x是输入特征向量,w和b是模型参数。wT表示w的转置,exp表示自然指数函数。逻辑回归算法的核心思想是通过对输入特征进行线性加权组合,并将结果通过一个特定的sigmoid函数映射到0和1之间的概率范围内,在这里采用梯度下降算法迭代更新参数w和b的值,使其能够最小化损失函数。
2.3 相似度计算和推荐算法的选择
个性化广告推荐的实现需要选择合适的相似度计算方法和推荐算法,从而计算广告和用户之间的相似度,并将广告进行排序和推荐。目前,常用的相似度计算方法包括余弦相似度、欧式距离、曼哈顿距离等指标,常见的推荐算法包括协同过滤、内容推荐和混合推荐等。协同过滤算法基于用户行为的相似性进行推荐,内容推荐算法根据广告内容与用户兴趣的匹配程度进行推荐,而混合推荐算法结合了多个算法的优势。选择合适的算法可以提高广告推荐的准确性和效果。本研究选择基于余弦相似度的协同过滤推荐算法进行实现。基于余弦相似度的协同过滤推荐算法是利用用户的历史行为数据,通过计算评分向量之间的余弦相似度来度量用户之间的相似程度,进而实现个性化推荐。
首先构建用户-物品评分矩阵:创建一个评分矩阵ratings,其中每一行代表一个用户对物品的评分。这个评分矩阵可以根据实际情况进行定义和填充。
下一步通过计算用户之间评分向量的余弦相似度,找到与目标用户最相似的若干个用户,余弦相似度是一种衡量向量之间相似性的方法。
(2)
式(2)中A和B表示两个n维向量,A是 [A1,A2, …,An] ,B是 [B1,B2, …,Bn],‖A‖和‖B‖分别表示向量A和向量B的长度,A与B的夹角θ的余弦相似度的计算过程涉及将向量映射到高维空间并计算它们之间的夹角。结果范围在-1到1之间,当两个向量的夹角接近于0°时,也就是它们的方向几乎相同,此时余弦相似度接近于1,表示两个向量非常相似。当夹角接近于90°时,也就是它们的方向几乎垂直,此时余弦相似度接近于0,表示两个向量之间没有明显的相似性。当夹角接近于180°时,也就是它们的方向完全相反,此时余弦相似度接近于-1,表示两个向量完全不相似。
一旦找到最相似的用户,算法就可以利用这些用户的喜好和行为模式来预测目标用户对尚未评价的物品的喜好程度。通常情况下,该算法会根据最相似用户对尚未评价物品的平均评分或加权平均评分,将这些物品推荐给目标用户。
(3)
式(3)为用户的相似度,其中wnn′是用户n与用户n′的相似度,rn表示用户n的评分向量。
(4)
式(4)为相似用户的加权平均值,rnm是用户n对商品m的评分,inm(0,1)表示用户n对商品m有无评分,1表示有评分,0表示无评分。Un为用户n的相似用户集合。
2.4 模型训练
基于余弦相似度的协同过滤推荐算法,可以利用历史数据来计算用户之间的相似度,并结合用户的评分数据进行训练,预测用户可能感兴趣的广告内容。模型训练采用矩阵分解算法,核心是将用户-物品评分矩阵分解为两个低维度的矩阵,通过学习得到的隐含特征向量表示用户和物品的关系。这种隐含特征向量可以捕捉到用户和物品之间的潜在关联,从而能够准确地评分预测和推荐,矩阵分解算法在协同过滤推荐中被广泛应用于提高推荐准确性和个性化度。
(5)
式(5)中P矩阵是N个用户对K个主题的关系,Q矩阵是K个主题跟M个物品的关系,至于K个主题具体是什么,在算法里面K是一个参数,需要调节,通常为10~100。如何来衡量分解后的矩阵与原始评分矩阵之间的误差或差异程,本研究采用损失函数来求解,也就是式(6)中所有的非“-”项(即原有矩阵里未评分项)的损失之和的最小值。
(6)
2.5 算法推荐评估
一旦模型训练完成,可以根据用户-物品评分表和相似度矩阵表使用协同过滤算法生成推荐结果表。推荐结果表中列出了针对每个用户的未评分物品的推荐评分,这些评分代表了用户可能对该物品的喜好程度[3]。推荐结果的评分是通过将其他相似用户对相似物品的评分进行加权计算得出的,具有较高相似度得分的用户对推荐结果产生更大的影响。通常,推荐结果的评分范围与用户-物品评分表中的评分范围相似,较高的评分表示用户可能更感兴趣。
通过提供个性化的推荐体验,推荐结果可以帮助用户发现他们可能未注意到的物品,并根据用户的反馈和行为数据进行效果追踪[4]。
用户-物品评分如表1所示,以用户为行,以物品为列,每个单元格中的数值表示用户对物品的评分。该表格用于存储用户对物品的评价信息,是协同过滤算法的基础数据。表中有4个用户(User1、User2、User3、User4)和6个物品(Item1、Item2、Item3、Item4、Item5、Item6)。其中,缺失的评分用“-”表示,例如:User1对Item2的评分为3,而User4对Item3的评分为-。
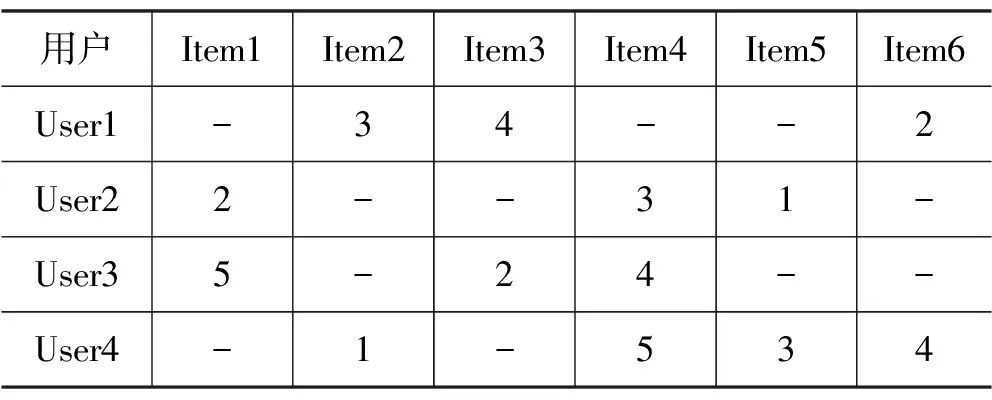
表1 用户-物品评分
相似矩阵如表2所示,显示不同用户或物品之间的相似度得分。表格的行和列代表用户或物品,每个单元格中的数值表示相似度分数,范围从0到1。例如:User1和User2的相似度得分为0.3,User3和User4之间的相似度得分为0.5。
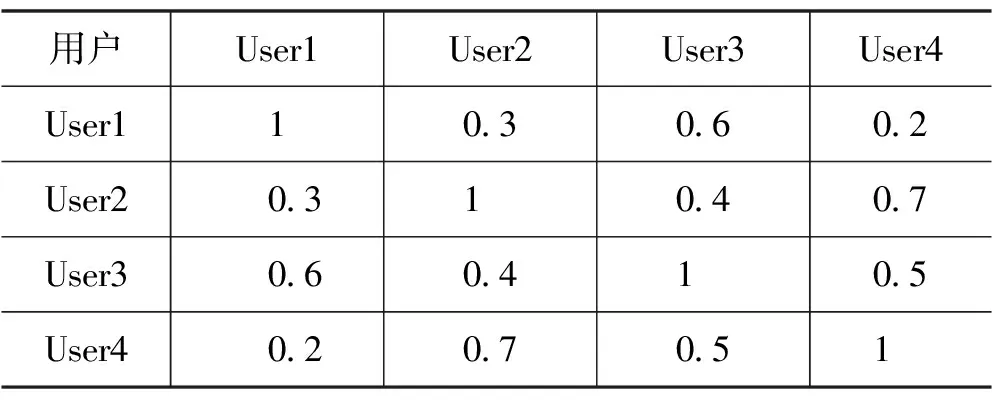
表2 相似矩阵
推荐结果如表3所示,显示协同过滤算法生成的推荐结果。每个单元格表示相应用户对该物品的推荐评分。推荐评分是根据其他用户对相似物品的评分加权计算得出的。例如:对于User1,Item1的推荐评分为2.7,Item2的推荐评分为2.2。
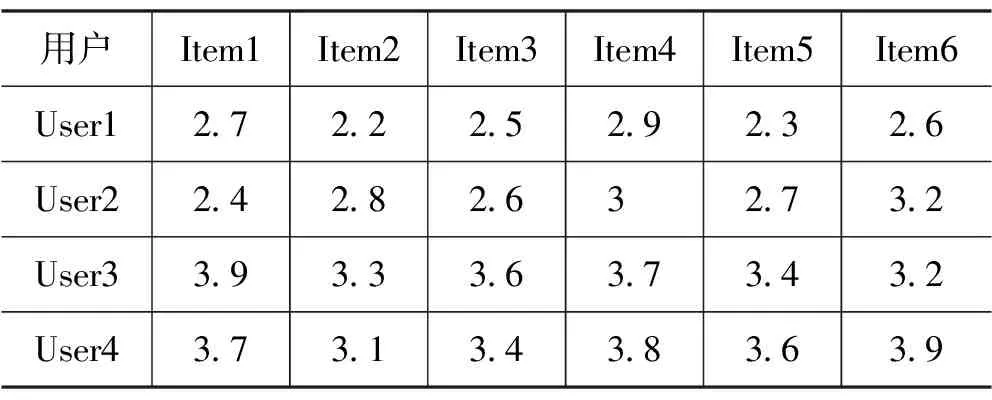
表3 推荐结果
3 结语
本研究通过研究基于算法推荐的个性化广告传播技术,探索了如何利用用户数据和算法模型实现广告精准推荐。通过对用户数据的分析和建模,本研究能够更好地理解用户的兴趣和需求,并为其提供个性化的广告推荐。选择适合的推荐算法并对模型进行训练和优化,使得广告推荐更加准确和有效。通过实施该技术,广告主可以将广告消息精准地传递给目标用户,提高广告传播的精准度和点击率[5]。同时,消费者也能够获取到更符合其个人兴趣和需求的广告内容,提供更有价值的广告体验。然而,个性化广告传播技术仍然面临一些挑战和限制,隐私保护是一个重要的问题,需要平衡用户数据的使用和个人隐私权益。另外,用户行为和兴趣的变化也是一个动态的过程,需要不断更新和优化推荐算法和模型,以确保广告投放的效果。
综上所述,基于算法推荐的个性化广告传播技术在提供精准广告推荐和满足消费者需求方面具有广阔的应用前景。未来的研究可以进一步探索用户数据的利用方式、改进算法模型的效果,并深入研究广告效果评估和隐私保护等问题,以进一步完善该技术并推动其在实际应用中的广泛使用。
猜你喜欢
小学生学习指导(低年级)(2022年5期)2022-05-31
疯狂英语·初中天地(2021年11期)2021-02-16
文苑(2020年4期)2020-05-30
少年漫画(艺术创想)(2019年2期)2019-06-06
新闻传播(2018年12期)2018-09-19
中学数学杂志(高中版)(2016年6期)2017-03-01
汽车与新动力(2016年6期)2017-01-04
北京信息科技大学学报(自然科学版)(2016年5期)2016-02-27
职业技术(2015年8期)2016-01-05
小天使·一年级语数英综合(2015年8期)2015-07-06
