
基于自然语言处理的典籍海外接受研究
2023-12-29 07:36:42张曙康
中国传媒科技 2023年12期
张曙康
(四川大学 外国语学院,四川 成都 610200)
随着中国文化“走出去”战略的实施及全球文化交流的加深,典籍外译作为中外文化交流互鉴的有效方式,尤其是在弘扬传统文化,提升国家文化软实力方面扮演着至关重要的角色。其中《论语》作为儒家经典,体现了中华民族的核心价值观,具有重要的跨文化传播意义。然而,在典籍“走出去”的过程中,我们不得不面对一系列挑战,如中华典籍的“出口转内销”现象,即不少中华典籍在译介为外语后,其读者实际上并非外国人,承载传播中华文化重任的这些作品很多仅成为中国学生学习翻译与古文的参考资料。[1]当前中华典籍出海,面临着“走进去”与“走下去”的挑战。[2]
在传统的中华文学海外传播研究中,学界的研究思路难以获知海外读者对文学作品的真实接受水平,其原因在于,传统的译介研究往往以各国图书馆藏以及专业学者的评论作为标准,忽视了普通大众的读者反应。在英国学者纽曼(Francis W. Newman)看来,大众的评价标准由于更加符合人类整体与历史的发展要求,理应被放在更为重要的位置。[3]此外,图书翻译出版5R 理论[4]与拉斯韦尔(Harold Lasswell)的5W 模式[5]都同样指出,译本在一定规模的读者群体中的接受是传播循环的一个重要组成部分,否则“一本本堆放在各地高校图书馆里的翻译成外文的中国文学、文化典籍”只能落得个“无人借阅、无人问津”的下场。[6]
近年来,译介研究陆续注意到译本传播效果中普通读者评论的缺席,并积极采取实证研究的路径考察译本在海外普通读者中的传播与接受情况。如张璐首创使用Python 情感分析技术大规模考察亚马逊读者评论,量性结合地客观反映海外普通读者对中国译介文学的情感态度,使得数据密集型的文学出海研究成为可能。[7]后续的研究者对于《西游记》《红楼梦》《孙子兵法》《易经》《人生》《生死疲劳》等英译本进行了类似的研究,并为中华文化出海也提供了相应策略。[8-13]
然而上述研究者在进行评论极性分析时,往往只借助词频统计手段来发掘正、负面情感评论的关键词或者主题,如张璐“通过细读正向情感中分值排名前10%且评论字数超过30 的264 条评论[4]”来人工发掘主题,沈国荣、张婕妤“利用 AntConc 语料库检索软件对Goodreads 网站所有正向积极评论的词频进行统计[6]”,而未能使用更加深入的文本挖掘手段来自动发掘主题。只有少数学者如赵爽、周桂君使用BERT模型[11]与余承法、郑剑委使用NVivo 软件实现关键词、主题的深入提取。[8]而关于《论语》海外读者评论的情感分析研究,根据本文调查目前国内尚无文献,国外仅有一篇,但也只是基于词频或获赞数的角度来挖掘文本关键词与主题。[9]鉴于此,本研究借助Python中的nltk,scikit-learn,gensim 等工具包,重点应用了vader 情感分析模型以及LDA 主题生成模型,分析了Goodreads 网站上《论语》刘殿爵译本的在线评论极性情况,其中通过LDA 主题模型分析读者情感正负的潜在原因。通过这一研究方法,本文希望为今后中华文化对外传播研究提供新的思路,推动中华文化在全球传播中实现更为广泛和深入的影响。
1.文本挖掘技术
1.1 情感分析
情感分析指对带主观色彩的文本进行分析、处理、归纳和推理的过程,最早由麻省理工学院的Picard 教授在其著作Affective Computing[10]中首次提出,在文本挖掘、舆情研判、产品口碑等领域具有重要的意义。该技术可有效适配于译介研究,利用海量在线评论数据评判译本的海外接受情况。目前情感分析方法主要包括三类:(1)情感词典;(2)基于传统机器学习的方法;(3)基于深度学习的方法。
情感词典方法是一种基于词典的无监督学习的情感分析方法。其基本原理是,首先构建一个情感词典,包含正面词、负面词、程度副词等,并给每个词预先定义一个情感极性权重。然后对文本进行预处理,包括分词、词性标注等。接着检索文本中出现的词是否在情感词典中,如果出现则查找其权重。最后,计算文本中所有情感词的权重之和,由此判断文本整体的情感极性和强度。其主要过程如下图1 所示[11]:
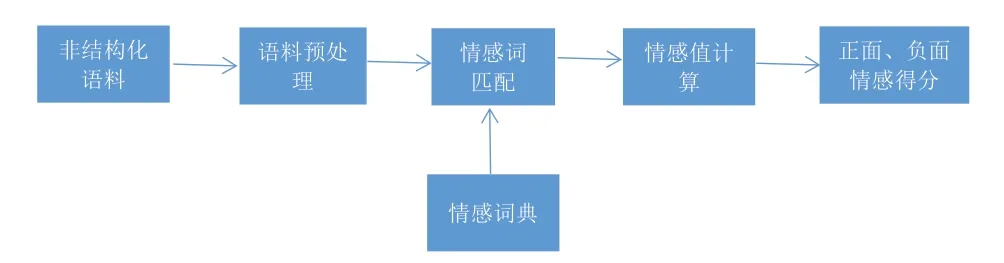
图1 基于情感词典的计算方法
传统机器学习方法主要包括监督学习、无监督学习和半监督学习三大类。这些方法在处理情感分类任务时,通常依赖于经典的机器学习算法,如Pang 等首次使用支持向量机(SVM)与朴素贝叶斯(Naive Bayes)等技术,实现了一个标准的有监督机器学习方法,将情感识别的准确率达到80%左右。[12]
深度学习方法是最近几年在情感分析领域发展迅速且效果突出的新兴技术。其在自然语言处理领域的应用可以追溯到Bengio 等人的论文[13],他们首先提出使用神经网络来构建文本的语言模型。后续研究者尝试了各种不同的神经网络模型,目的是将文本映射到向量空间得到词语的分布式数值表示,再将这些向量表示作为分类器的输入,完成文本的情感分类。目前主要的深度学习模型包括:卷积神经网络(CNN)[14]、循环神经网络(RNN)[15]、长短期记忆网络(LSTM)[16]或结合注意机制[17]的4 种方法。此外近年来涌现出的BERT[18]、GPT[19]等预训练大模型,在情感分析任务中也取得了可喜的成果。
尽管基于深度学习的路径为目前最有效的情感分析手段,但该方法需要大量计算资源进行训练,这对硬件设备提出较大要求。因此本文选取了实现难度较低的情感词典分析模型,调用nltk 工具包借用基于规则的vader 情感字典进行文本极性打分。
1.2 TF-IDF 文本向量表示
作为一种非结构化的数据,文本不能被计算机直接处理,因此需要对文本建立向量模型来进行表示。本研究采用TF-IDF(Term Frequency-Inverse Document Frequency)作为文本向量化方法。其主要思想是根据词语在文档中的频率以及在整个语料库中的重要性来表示文本,计算公式如下所示[20]:

图2 TF-IDF 算法公式
其中TFi为词项i 在文档d 中的出现频率;IDFi表示包含词项i 的文档|{j :ti ∈ dj}| 占所有文档|D|的比例的负对数,可表示该词项在语料库中的稀有程度,|{j :ti ∈ dj}| + 1 为数据平滑处理的一种手段以免数据过于稀疏。TF-IDF 指数综合二者,可表示特定词项在特定文档中的重要性。
1.3 LDA 模型
LDA(Latent Dirichlet Allocation)是由 Blei 等人在2003 年提出的三层贝叶斯概率模型[21],其基本思想在于,每篇文档都可以由多个主题构成,每个主题都由多个词汇构成。在不考虑词汇出现顺序的情况下,LDA 通过学习可以构建出“文档-主题分布”以及“主题-词分布”。目前LDA 已经广泛应用于图书馆学[22]、新闻传播[23]、经济学[24]、政治学[25]等多个领域,为科研动态分析、舆情演化路径、推荐方法和用户行为等研究提供了理论依据和方法支持。
训练LDA 模型需预先设置三个超参数α、β 和主题数k。α 是文档-主题分布的先验超参数,β 是主题-词分布的先验超参数,通常设置为默认值即可。主题数k 是模型的一个关键超参数。设置过小会导致主题过于泛化,设置过大会导致模型过拟化。而k 的选择可以通过计算困惑度来确定,困惑度能反映模型对新样本的预测能力。困惑度越低,表示模型对新样本的概率分布预测越准确。困惑度的计算公式如下所示。[26]

图3 LDA 模型困惑度公式
其中,D 表示文档集合,M 是文档个数,Wd 表示第d 个文档中的词集合,P(Wd)表示在文档d 中词W 的概率。通常随着LDA 模型主题数量k 的增加,困惑度呈递减趋势,因此可以训练多个不同主题数的LDA 模型,比较其在给定训练集上的困惑度,然后选择困惑度较低且主题数相对较少的LDA 模型作为最优模型。
2.研究步骤
借助Python 的Scrapy 库与Selenium 库模拟用户操作实现页面动态爬取,总共在Goodreads 网站上获得刘殿爵译本评论数据一共952 条(截至2023 年5 月),每条数据主要得到了以下评论信息:用户名、用户评论、评论时间、评论星级、评论获赞数。在此步骤后,对数据进行初步宏观评估,即统计评论数量每年的增速以及累计的译本评论数量,并实现图表可视化处理。借助python 的matplotlib 与pandas 库可实现该项操作
前往“百度开放翻译平台”注册账号,并且获取APP ID 以及密钥。接着使用python 编程语言借助requests 库与hashlib 库,凭借注册好的ID 与密钥调用百度翻译的开放接口,从而将多语种用户评论统一翻译为英文。并且通过python 的re 库和pandas 等库,仅保留英文单词数为30 个以上的评论(596 条)以确保数据质量。
根据nltk 内置的基于规则的vader 情感分析器对读者评论极性打分,打分结果为正值、负值、零。本文将读者评论情感分值大于0 的划分为正面评论语料库(522 条)、小于0 的则为负面评论语料库(63条)。在此步骤后,同样对数据进行初步宏观评估,即统计所有评论年均的情感分值得分,并实现可视化处理。同样借助python 的matplotlib 与pandas 库实现该项操作。
对读者主观的星级评定与情感分析得分进行皮尔森相关性测试,发现相关度系数约为0.30、 p 值<0.01 说明二者显著相关,这也意味着统一为英文之后评论的情感分析得分和用户评分的趋向是一致的,从侧面交叉证明了vader 情感分析器的有效性。
对正面、负面评论语料库都实行文本预处理,总共包括去除标点符号与其他特殊符号,去除常用英语停用词,对语料进行词形还原三个步骤。值得注意的是,直接进行词形还原效果一般,因此需要对词项进行词性标注(POS)后再进行词形还原。去除特殊符号的正则表达式为pattern = r’[^a-zA-Zs]’表示将除了英文字母与空白符之外的符号全部去除,停用词表为nltk 自带常见英文停用词,词性标注使用nltk 的方法pos_tag,词形还原器同样来自nltk 的WordNetLemmatizer 模块。此外划分好语料库且文本预处理之后,借助wordcloud 等库绘制正、负面语料库的词云图,从而获得语料的宏观信息概览。
预处理之后的语料,便可进行TF-IDF 向量化,从而适应LDA 模型对结构化数据的需求。TF-IDF 向量化步骤借助了sklearn 的TfidfVectorizer 模块,LDA模型同样来自sklearn 的LatentDirichletAllocation 模块。由于LDA 模型需要根据数据集计算困惑度(perplexity)从而得出最佳的主题数k,因此在该步骤本文借助gensim 的LdaModel 模块实现困惑度的获取,并借助matplotlib 实现困惑度——主题数的可视化。
对于正向评论语料库,使用LDA 模型发掘文档集合中潜在的主题;由于负面评论语料库较小,直接以人工提取负面评论中的主题信息。而LDA 模型的参数分别为:n_components= 5(根据困惑度结果,最佳的主题个数为k=5),max_iter=100,learning_method='batch'。
3.研究结果
本文研究结果分为两个部分:第一为研究的宏观结果即评论信息的总体情况,如评论数量、年均情感分值及评论总体词云图等;第二为微观信息的挖掘,在该步骤具体应用LDA 模型实现正面评论信息的深度提取,并对负面评论语料信息进行文本细读。
3.1 评论信息宏观结果
3.1.1 评论、情感极性趋势
如下图4所示。自2007年Goodreads网站创立以来,《论语》刘殿爵译本的累计评论数量不断攀升,其增速也一直稳步前进,仅在2016-2018 年有小幅回落,但是在2020-2023 年间达到顶峰并保持着每年90 评论左右的增长速度。可见,随着中国的和平崛起,其文化影响力也稳步提升,或印证着亨廷顿的观点:一个国家的文化影响力在很大程度上取决于其在国际舞台上的地位和实力。[27]此外图5 年均情感分值趋势图显示,海外读者对于《论语》刘殿爵译本的总体情感分值一直维持在一个较高的水平,处在0.5 ~1.0 正面评价区间之内,可见外国读者普遍对《论语》持正面态度。
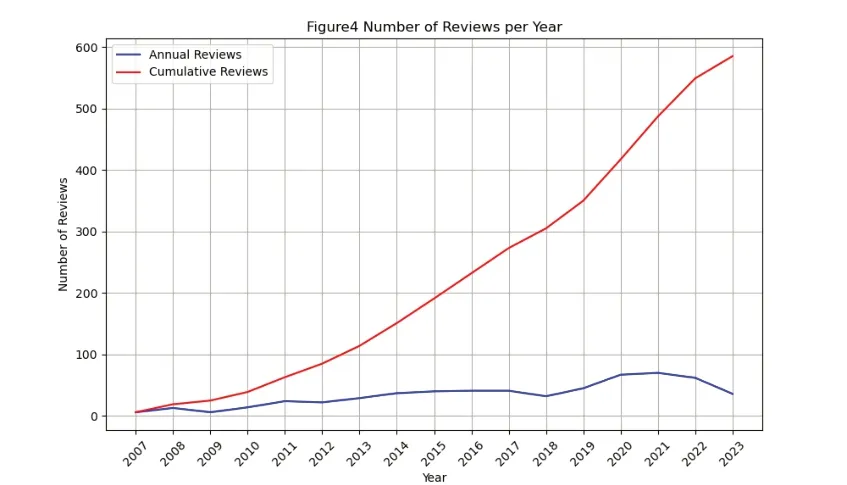
图4 评论数量信息

图5 年均情感分值趋势图
3.1.2 基于词云图的评论信息挖掘
基于情感分值,评论语料被划分为正面与负面两种,其中正面占大多数有562条评论,而负面则为63条。如下图6 所示,Confucius、Book 是两个词云图中最凸显的内容。在正面词云图中,good、time、read 等词显著可见,可见读者对儒家文化的热衷,认为儒家学说是历经了时间考验的经典,值得常常阅读;而鉴于负面语料库评论较少,故暂不做分析,待下文将其进行文本细读,集中发掘负面语料之主题。

图6 正、负面语料库词云图(左正右负)
3.2 读者评论信息微观挖掘
3.2.1 LDA 困惑度
如上文所述LDA 模型的困惑度(perplexity)是一种衡量模型效果的指标,一般困惑度越低,代表模型的性能越好。本文在文档数据TF-IDF 向量化之后,选用gensim 的LDA 模型进行训练,候选主题数在[2,50]的区间之内。借助LDA 模型的log_perplexity方法与一个for循环,用matplotlib库绘制了如下主题数、log 困惑度如折线图7。

图7 主题数、困惑度折线图
一般而言,困惑度随着主题数的增加会一直下降,但是过多的主题数会导致模型过拟合,因此选择主题数k 要在低困惑度与过拟合之间达到平衡。折肘法认为在困惑度出现显著拐点时的k 值为最佳主题数。然而观察下图并未出现显著拐点,故取常用的默认k 值=5 为最优主题数,以免k 值过大导致模型过拟合。[28]
3.2.2 基于LDA 主题模型的主题词生成
鉴于负面评论语料库只有63 条评论,因此本文调用机器学习库sklearn,仅对预处理、TF-IDF 向量化之后的正面评论语料库(522 条)用LDA 模型进行训练,并取主题数k=5 为最优主题数。最终生成文档——主题分布、主题——词分布如表1、2 所示。
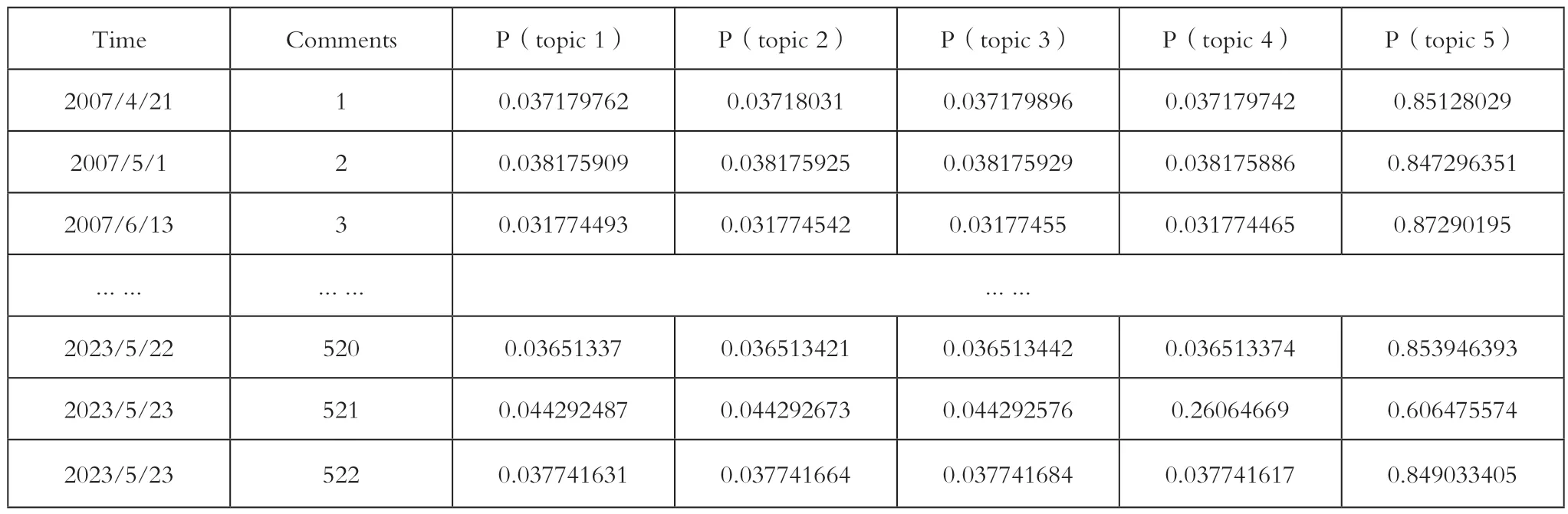
表1 正面评论文档——主题概率分布分布
如表1 所示,522 个评论文档由不同概率的主题所构成,并且第5 个主题的主题强度远远大于其余主题。因此本文的第5 个主题单独使用一个y 轴表示,并整理年均评论文档主题强度为图8 所示。再结合表2 的5 个主题,可知正面评论语料库中占主导地位的主题,从2007 年至今一直为第5 个主题“论语的哲学智慧”,围绕着关键词Confuciusanalectsphilosophy的是一系列的正面词汇如goodlike hink ime 等。可见独特的东方典籍对于海外读者确实具有莫大的吸引力,在对《论语》的阅读与思考中(read & think),这些读者孜孜不倦地求索着古老的中国哲学智慧(philosophy),并且这种独特的思想体系,经时间(time)的洗礼在当代仍焕发着活力。此外其余四个主题,主要涉及论语内容艰深如“君子之德风,小人之德草,草上之风必偃(grass,wind,blow,bend)”需要集中注意力(concentrated,coffee)才能理解,不同译本如由UNESP 圣保罗州立大学出版的Giorgio Sinedino 译本、意大利译者Lippiello 教授的译本,涉及对于孔子本人的敬仰(wiseguy,transcendental,wellhoned)。

表2 正面评论语料主题——高概率主题词分布
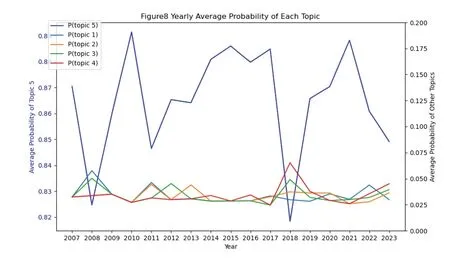
图8 不同主题强度趋势图
此外主题中似乎也出现了一些代表负面情绪的词汇如criticize、ugly、underperform 等,但是需要注意的是本文所分析的语料为实时提取的在线评论,因此在语料的整体趋势已经明确的情况下,即作为语料的主导主题“《论语》哲学智慧经久不衰”显示大部分读者对孔子、《论语》以及独特的东方哲学表达赞美之情的情况下,个别负面词汇可以忽略不计。此外,尽管上述主题取自正面评论语料库,但是vader 情感分析模型的识别正确率不能100%的保证,因此会有少许负面情感评论被错误识别。最后,本文将上述负面词汇作为关键词在原始正面语料中进行检索(由于上文已经实现了词形还原,所以在检索时需注意定位这些词汇的不同形式),结果显示这些词汇实际上常常表示为赞美,只是读者评论的语境较为复杂,如:
例1:There is nothing transcendental in Confucius. I give him an extra star for never underperforming his wellhoned wise-guy act,because he would have been an entertaining guy to sit at the feet of; but only in China is that enough to base a religion on!—— Ravanagh Allan
例2:Before me,I often criticized Confucianism for being oppressive,frustrated,and restrained. In fact,I shouldn’t have avoided reading the Four Books and Five Classics because of this. Moreover,when I was a child,there were many things that I couldn’t understand. Now I have enough wisdom and clarity to relearn Confucianism,A philosophy without value cannot last for 2500 years. —— H.
3.2.3 负面语料库文本细读
对63 条评论进行细读,发现其中有1 条为重复评论故剔除。在剩余的62 条评论中仅20 条评论情感分类错误,即情感为正面或中立的评论被评定为负面,情感分析的正确率高达67.7%。此外,再次细读20 条情感分类错误的评论,其分类错误原因分为两点:一是评论中引用《论语》译文过多,针对在线评论设计的vader 情感分析器不能很好适应;二是对于那些褒贬参半的中立评论,vader 不能察觉其微妙的立场而将其划分为负面评论,例如:
例3:直接引用:
“The things which weigh heavily upon my mind are these—failure to improve in the virtues,failure in discussion of what is learnt,inability to walk according to knowledge received as to what is right and just,inability also to reform what has been amiss.”——d
德之不修,学之不讲,闻义不能徙,不善不能改,是吾忧也——(《论语·述而》)
例4:褒贬参半
Rating it as 4 stars not because I agree with everything in it,but because it is generally thought provoking and provides a lot of insight into Asian thought. As a student of Asia broadly,and a resident of South Korea for the last 4 years,it’s amazing how much these teachings still underpin Asian societies today. That said,obviously I don’t agree with everything,and quite a few of the proverbs/parables cannot be understood without proper context. I think next up I’ll have to read a commentary or something to get some of the missing context. Either way,it’s a must-read to understand Eastern thought.——Ian Wagner
而至于剩下的42 条负面评论,经过细读可以分为五类:
其一为对《论语》对话片段式的文体不满,认为《论语》的行文上下并不连贯,缺乏严谨的逻辑论证,且格言式的警句经不起推敲以至于读起来十分费解与无聊,其中读者的关键词主要为:conflicting ideas,repetitive,choppy,disjointed,bored,couldn't understand,lost,confounding,preached and not reasoned,fragmentary,confusing and nonsensical,disorganized。此类一共有29 条,占所有负面评论约69.0%的比例。
其二为对翻译质量的不满,此类一共6 条,占所有负面评论比例约14.3%,例如:
例5:Some very interesting thoughts and sayings,though a lot of it is political and there are a lot of Chinese names which can be confusing and a little boring. I also wasn’t thrilled with the translation. I prefer the translation found in the textbook I use with my 10th graders (Arthur Waley).——Lisa
其三为对《论语》内容的失望所导致的不满,认为《论语》宣扬的理念只不过是日常生活中的伦理常识,在今天的社会中无甚新意、过于简单。此类评论一共有6 条,占所有负面评论比例约为14.3%,例如:
例6:…This book just scratching the surface. There is no answer,or fundamental thoughts but teachings,which are way out of focus of today…——Silence
例7:…Not as good as I was hoping. A lot of the passages were anecdotes that didn’t seem totally relevant. Some of them were very good - I did bookmark a lot of pages - however nothing was life changing or something that I hadn’t already read and/or thought of myself…——Anna
其四为对《论语》中所宣扬信条的不满,认为“君君臣臣父父子子”的纲常理论严重限制了东亚社会的发展。此类评论一共5 条,占所有负面评论约11.9%的比例,例如:
例8:…Unfortunately,there is mischief about childish piety in front of their parents,dated whining about sacrifices and rituals,references to lost traditions,misogynistic passages and even material that you may wonder if they were not added by mistake…——Gijs Grob
最后为其他类,一共2 条,占比约4.8%,主要包括对刘殿爵译本的编排不满,与选文及注释的不满,例如:
例9:A slim,disappointing primer on Confucius’famous Analects. The selections are skimpy and their annotations,in spite of the authoritative source,just as limited. A dead-end to the sage,not the proverbial Path.——Dan Lalande
结语
本研究使用Python 中的Scrapy 和Selenium 两个库爬取了Goodreads 网站刘殿爵《论语》译本的评论信息。并且由于原始评论包括多国语言,先使用百度翻译api将所有评论翻译成英文。然后保留长度超过30 个英文单词的有效评论596 条。接下来使用nltk 中的vader情感分析器对评论进行情感极性打分,根据正负分值将评论划分为正面评论(522 条)和负面评论(63 条),并且通过皮尔森相关性检验发现情感评分与读者主观打分的相关系数为0.30(p 值<0.01),说明情感分析结果有效。最终情感分析准确率达到67.7%。并且使用词频统计和词云可视化手段对评论数据进行了宏观的初步探索。
宏观数据显示,从2007 年Goodreads 网站开始创立至今,《论语》刘殿爵译本已累积增加到952 条(数据截至2023 年5 月)。近3 年(2020—2023 年)平均增速保持在每年约90 条的较高水平。此外从2007年至今,各年度评论的平均情感分值均在0.5-1 之间,符合正面评价的范围。即使是评论数量增幅较小的2016—2018 年,平均分值也控制在0.6 以上。由此可见,随着中国国力提升和对外开放程度加深,《论语》这本中华典籍获得了持续增长的国际关注度,其英译本的评价保持乐观。
在信息微观挖掘方面,本文将预处理之后的正面评论语料库文本,进行TF-IDF 向量化的步骤,即将文本转化为向量空间上的数值表示。然后将向量化结果输入LDA 主题模型进行训练,设定最优主题数为k=5。LDA模型结果显示,在5 个主题中,关于论语哲学智慧的讨论是评论的主导主题,占比远超过其他主题。从2007年开始,这一主题的评论量一直保持增长,反映出论语核心价值观的吸引力。在负面评论细读方面,本文发现vader 情感分类的准确度为67.7%。分类错误的原因主要来自评论中包含大段的引文导致判错以及中立评论无法判断等。这进一步说明,该情感分析技术可有效应用于在线评论文本的处理。此外,负面评论集中为对《论语》文体(69.0%)、翻译质量(14.3%)、内容深度(14.3%)、《论语》信条(11.9%)等方面的批评。这为译本的优化提供了具体的改进方向。
综上所述,本研究证明了利用Python 和相关的文本挖掘工具评估中华典籍国际传播效果的可行性。后续研究可以通过扩大样本规模、采用预训练语言模型等方式提高主题挖掘的准确度,并进行跨语言/跨译本的对比研究,以获得更丰富的研究结论,为进一步推进中华文化“走出去”提供决策支持。
猜你喜欢
中国新闻周刊(2021年26期)2021-07-27 04:02:12
天津外国语大学学报(2020年1期)2020-03-25 13:29:26
能源(2018年8期)2018-09-21 07:57:22
知识经济·中国直销(2018年6期)2018-06-29 07:55:52
作文评点报·低幼版(2017年13期)2017-04-18 18:15:11
信息安全研究(2016年4期)2016-12-01 06:06:54
Asian Pacific Journal of Reproduction(2015年1期)2015-12-22 12:09:35
语言与翻译(2015年4期)2015-07-18 11:07:45
电脑迷(2012年4期)2012-04-29 06:12:13
当代外语研究(2010年3期)2010-03-20 14:36:38
