
混合分布式光伏及需求负荷预测研究
2023-12-29 06:25万童
电气技术与经济 2023年10期
万 童
(国网江苏省电力有限公司扬州市江都区供电分公司)
0 引言
电力负荷预测对电力公司平衡电网功率至关重要,这种平衡发生在几个时间尺度上: (1) 短期 (约一小时至一周) 的日常运作, (2) 中期 (约一周至一年) 的维护和更长的计划, (3) 更长期 (计划超过一年) 。电力负荷取决于天气, 客户的每日和每周使用模式, 以及不同的天气条件对这些模式的影响。这些使用模式中的一些是商业或工业用途, 而另一些是由住宅用途驱动的。这些因素之间的平衡随所预测地区的气候和土地使用情况而变化很大。预测电力负荷通常包括检查历史负荷数据以及有关过去、 现在和预测未来天气状况的信息,包括温度、 太阳日照、 湿度、 降水量和风速[1-2]。
DPⅤ (分布式光伏) 预测面临的问题是缺乏关于每个 DPⅤ 装置的详细信息, 或者关于其历史光伏发电量的任何详细数据。因此, 本文使用“自上而下”的方法来预测光伏发电量, 还提供电力负荷预测和评估的影响,光伏生产的表观负荷。
本文的其余部分描述了论文的数据、 方法、 预测系统的构建和结果分析。第1节简述了预测的使用方式。第2节描述了 DPⅤ 预测模型, 第3节描述了负荷预测模型。第4部分总结了本文的工作, 并提出了进一步研究和应用的结论和建议。
1 预测方法分析
混合分布式光伏及需求负荷预测分析是通过对光伏发电量和家庭需求负荷进行实时预测和分析, 以优化能源网格的管理和使用。在混合分布式光伏系统中, 多个光伏发电系统和家庭需求负载系统通过能源网格相互连接, 形成一个相互交织的复杂网络。为了最大程度地利用可再生能源并确保系统的可靠性和稳定性, 需要对光伏发电量和需求负荷进行实时监测和预测。在混合分布式光伏及需求负荷预测分析中, 主要通过以下技术进行实现: 时间序列分析: 通过分析光伏发电功率和需求负荷的时间序列, 确定它们的趋势、 周期性和季节性, 进而预测未来的变化趋势; 机器学习算法: 采用机器学习算法对历史数据进行训练、 分析和预测, 例如支持向量机、 神经网络等, 这些算法能够自动处理数据并提供高质量的预测结果; 智能控制策略: 在实际运行中, 通过智能控制策略, 进行光伏发电量和需求负荷的调节和优化, 以确保系统的可靠性和稳定性; 数据挖掘技术: 通过数据挖掘技术, 对大规模的历史数据进行分析和处理, 发现其中的规律和趋势, 并为决策提供参考。
2 DPV预测模型
2.1 预测步骤分析
随着DPⅤ容量的增长, 它在所有时间尺度上对净负荷的影响越来越大。本文希望评估当前的动力涡轮发电水平是否作为一个明显的负荷削减。DPⅤ缺口预测算法与前人开发的算法相似[3-4]: 它首先预测点位的太阳辐照度, 然后使用基于历史数据训练的算法将辐照度预测转换为功率, 最后使用扩展比例创建区域功率预测。在这种情况下, 因为我们的数据是在0.1° × 0.1°的网格框中提供的, 所以我们预测了一个特定小时内将生产的区域的容量百分比。算法的一般流程如图1 所示。该程序可分为三个一般步骤:
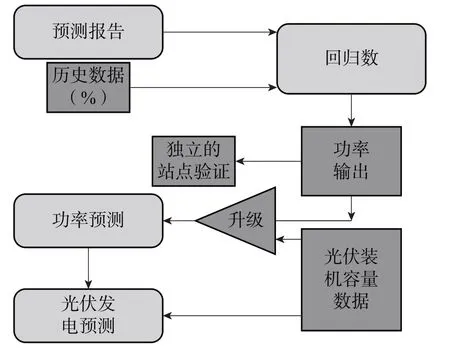
图1 分布式光伏预报系统流程图
1. 在预测地区气象预报所有地点汇编每小时有关气象变量的预报。
2. 应用机器学习技术预测地区的光伏生产能力百分比。利用最近邻校正法, 通过配对气象预报和光伏百分比容量观测数据建立了立体式回归树模型, 并应用于预报。其结果是对每个气象预报位置附近光伏DPⅤ输出的百分比能力的预测。
3. 通过将气象预报站点的装机容量百分比预测乘以该站点附近的DPⅤ总装机容量, 将预测值提高到代表该地区所有光伏装机容量的水平。由此产生的电力预测可以在服务区域的所有气象预报站点求和, 从而产生总负荷削减的预测。气象预报还可以用来预测附近特定馈线的功率。
容量预测的百分比用于预测地表向下的短波辐射 (也称为水平辐射) 、 温度、 云量百分比、 低、 中、高云量、 1 小时降雨机率和降水量。除了判定预报,预报的有效时间和预报的有效天数也包括太阳角的替代物, 以便识别该地区的太阳气候学。预测准备时间也包括在内, 以说明基于模型准备时间的预测准确度的潜在差异。
2.2 DPV预测的结果
使用图1 所示的方法, 将一年的光伏容量数据百分比与气象预报观测值进行匹配, 以产生一个模型来预测服务区40个气象站点中的每一个的DPⅤ[5]。图2显示了所选的地区气象预报地点两天的电力容量百分比预测样本。这些预测既表明了预期的日周期, 也表明了两天内该地区 站点的相当大的变化, 图2 还显示了个别地点全天可能发生的快速变化, 0-48h 光伏发电能力百分比预测为所有气象预报地点的单一预测发电时间。每条线表示单个站点的电力容量百分比。
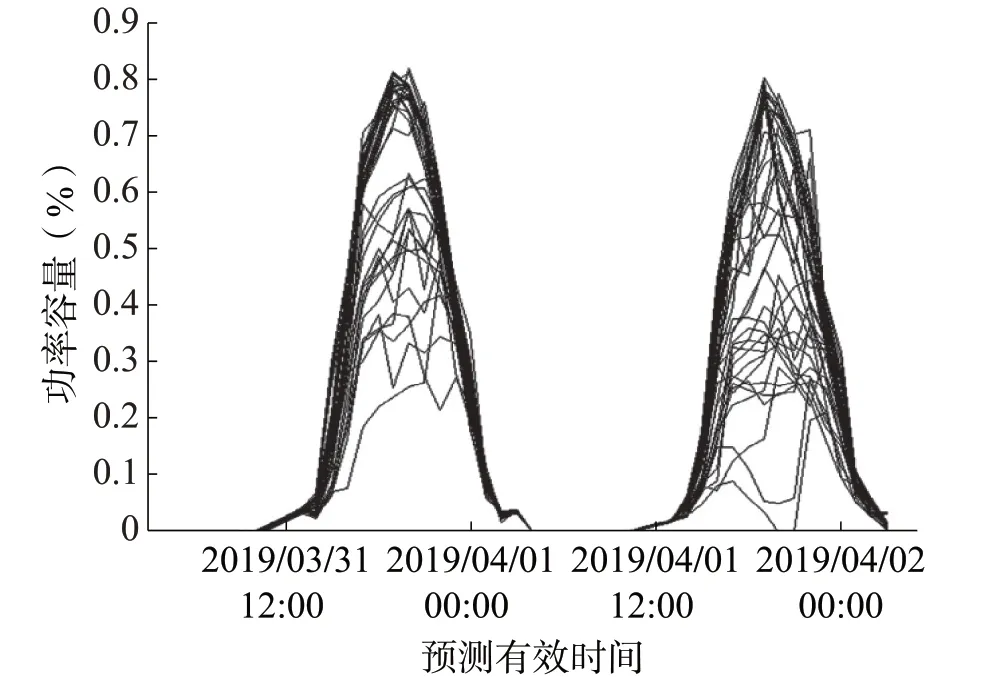
图2 光伏发电能力百分比预测
利用训练数据集对容量百分比预测模型进行评估具有很好的应用前景。数据被随机分为2/3 的训练和1/3的测试集, 然后组合到训练和测试过程中 (提前时间是一个输入变量) 。在24h 前置时间测试装置的百分比容量预测的绝对误差, 平均约2%的总DPⅤ容量在一个地区。对于所有提前到48h 的测试, 最大的测试集平均误差约为4%。因此, 已经证明了一个成功的计算分布式光伏发电量的方法。
为了完成对DPⅤ电力预测的更直接的评估, 从的六个地点获得实际的电力输出。图3 显示了这些地点的实际数据归一化的根均方差 (nRMSE) 和偏差(nBias) 。此外, nRMSE和nBias计算了6个月期间在这些位置 (黑色断线) 的所有匹配对, 并通过实际数据归一化。
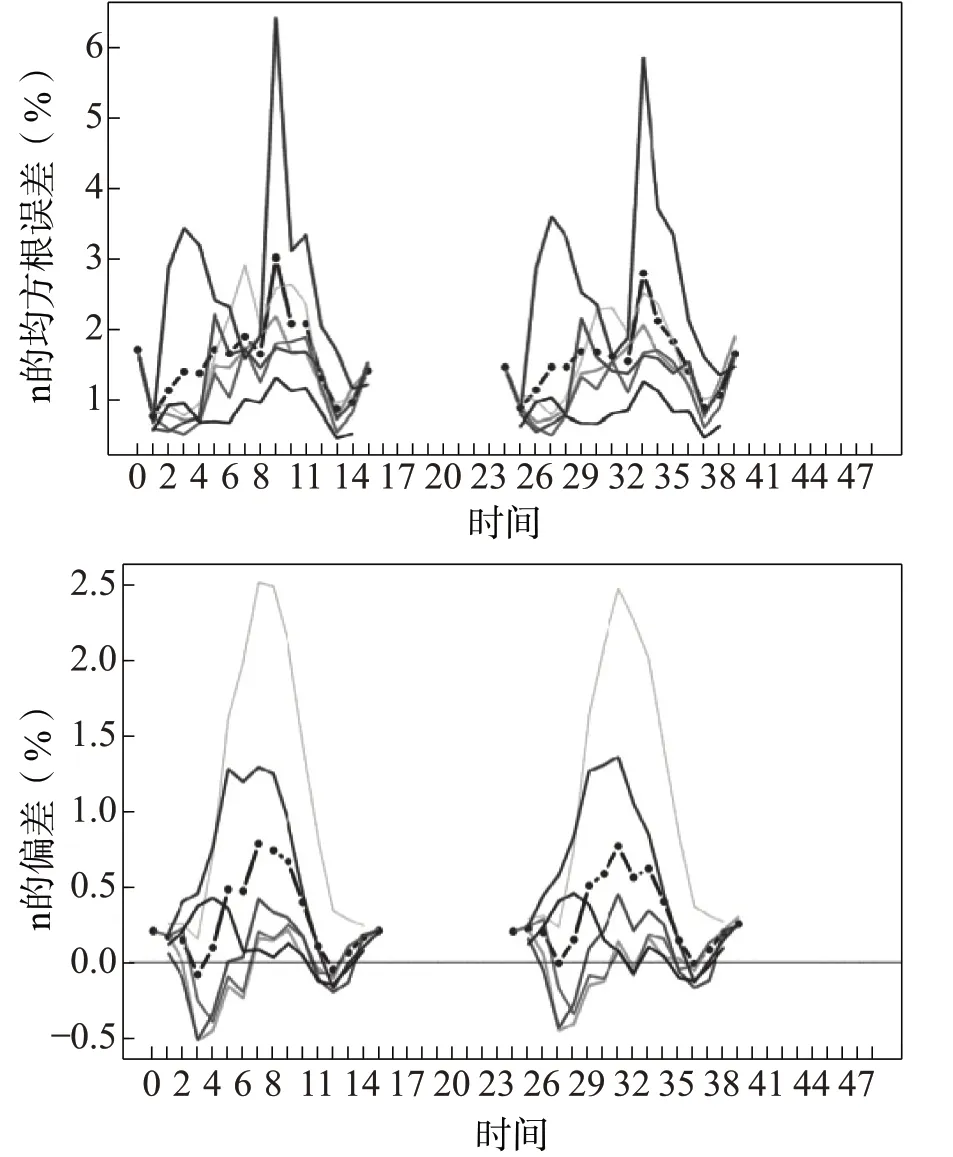
图3 在六个馈线位置 (实线)
这些大量的数据代表了使用六个月每小时数据的统计聚合来计算分数。聚合方法在最终统计计算之前的每个有效时间使用误差或平方误差总和 (称为部分总和), 并提供更好的预测方式, 而不是计算平均误差。对1100 时初始化的日内 (0-15h) 和日前 (24-39h) 预报进行了评估。其中, nRMSE 值小于3%。还要注意的是, 未来一天的预测并没有表现出降低的准确性。这一结果表明, 本文已经找到了一种方法来独立验证负荷预测和评估, 表明预测误差是在一个可接受的限度。
3 负荷预测模型
负荷预测模块的输入包括来自气象预报观测的气象变量和位置的预测, 时间变量 (每天的小时, 每周的日子, 每年的时间), 太阳角度, 以及之前的负荷观测。气象变量包括温度、 露点、 风速、 云量百分比、 每小时降水量、 降雨机率和降雨、 冰雪的条件概率。如上所述, 许多相同的变量被单独用于DPⅤ预测。
3.1 电力负荷数据分析
通过数据查找, 得到了每小时该地区电气的历史数据集。加载数据, 通过从实时数据升级来增强。图4 强调了温度的重要性, 绘制了一年来来自十个气象预报站点的标度负荷与加权平均数温度的对比图。对于低于12℃的温度, 随着温度的降低, 负荷值以近似线性的方式增加。当温度超过12℃时, 负荷值以二次或指数方式增加。正如预期的那样, 与晚秋、 冬季和早春相关的日期主要出现在图的左侧, 而晚春、 夏季和早秋的值出现在图的右侧。可以发现的新模式: 在同样的温度下,春季到初夏倾向于比一年中其他时候经历的负荷更小。这可能在一定程度上反映了人们在季节转变期间能够忍受更大的温度变化, 或者也可能反映了其他天气变量 (例如, 更长期的温度趋势、 多云或降水) 的影响。在任何情况下, 这三个图表说明了每日, 每周和季节使用模式和温度的重要性, 同时也表明了准确预测电力负荷的复杂性。其他几个天气变量可以显著影响电力负荷, 并被用于网络负荷预测模型。
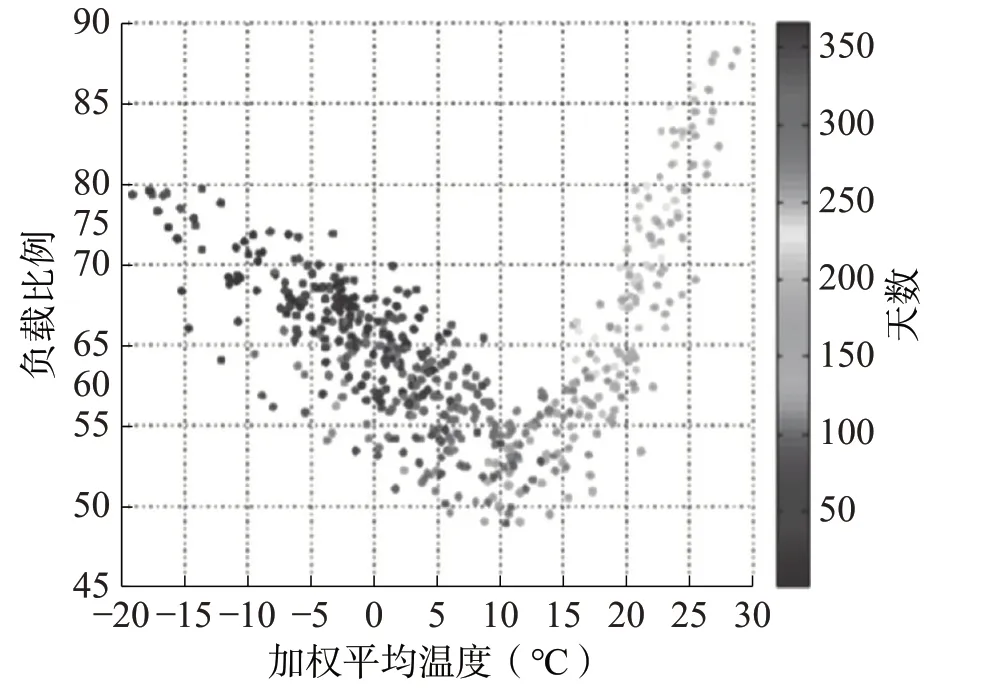
图4 比例PSCo净负荷在2协调世界时对10个METAR站点的加权平均温度, 颜色比例代表天数
3.2 与电力负荷有关的气象分析
开发负荷预测模型的第一步是确定选定地区哪些 气象预报位置与预测净负荷最相关。这是通过使用不同位点的观测温度作为负荷预测因子, 通过3 倍交叉验证 (对2/3的数据进行训练并对剩余的1/3进行测试) 来训练和测试预测模型, 并对结果进行排序。接下来, 将十个最重要的地点的观测结果以加权平均值的形式组合起来, 选择权重, 使用3 倍的交叉验证来最大化平均温度的预测性能。第三, 计算了温度、太阳角和先前负荷的时间指数移动平均(EMA) 。EMA 将最大的平均权重分配给最近的值, 并通过每个时间步长的恒定衰减因子来减少先前值的权重。因此, 对于指数衰减因子α∈( )0,1, 与时间序列Xt相关的EMA序列Yt可以递归计算为
α的小值实际上只包括EMA 中的最近值。然后,使用迭代正向选择和反向消除方法评估所有原始和派生变量, 以找到最小的, 熟练的预测因子集, 最小化平均绝对百分比误差 (MAPE) 。这些变量被用来训练使用整个训练数据集的负荷预测的最终模型。
4 结束语
我们已经描述和评估了部署在某地区的电力负荷和自上向下DPⅤ预测系统。这些系统的设计允许两者的结合, 以便明确地将光伏发电量预测作为DPⅤ部署过程中非平稳期负荷预测的一部分。这种设计的优点是, 随着用户光伏安装数据库的更新, 光伏和净负荷算法将立即调整他们的预测, 而不需要再训练。此外, 随着新的数值天气预报模型的投入使用, 它们可以很容易地被纳入气象变量的预报, 从而提高DPⅤ预报和净负荷预报的准确性。净负荷预测和分布式光伏光伏预测模块在服务区都取得了良好的效果。
还评估了在固定部署期间和部署翻倍的年份, 在电力负荷预测中明确包括分布式光伏预测的重要性,首先部署的容量比目前看到的要大。值得注意的是,DPⅤ预测系统和电力负荷预测系统都包括各种天气和光伏变量, 包括 (但不限于) 每年的一周、 每周的某一天、 每天的时间、 季节指示、 降雨机率、 温度、 太阳高度和太阳角。因此, 我们希望用这些信息来评估DPⅤ预测必要性。事实上, 我们发现在固定部署期间, 明确包括自上而下的DPⅤ预测并没有改善净负荷预测, 也没有包括在回归树的重要变量列表中。这是一个重要的结论, 因为它表明, 如果净负荷预测引擎构造包括所有适当的光伏相关变量, 那么没有必要明确预测DPⅤ的生产。
未来研究中如果有足够的数据进行计算, “自下向上”方法是否会提供更多的价值, 或者可以评估是否有更多的特定地点的数据将提供重要的研究价值,使特定的DPⅤ预测是必要的。这些问题将在未来的研究中得到解决。
猜你喜欢
黑龙江气象(2022年1期)2022-05-18
能源(2017年10期)2017-12-20
能源(2017年5期)2017-07-06
电子制作(2017年20期)2017-04-26
新闻传播(2016年1期)2016-07-12
山东医药(2015年15期)2016-01-12
雷达与对抗(2015年3期)2015-12-09
产业与科技论坛(2015年14期)2015-03-19
灾害学(2014年1期)2014-03-01
自动化博览(2014年12期)2014-02-28
