
工作记忆理论驱动的社交媒体用户画像自然属性预测模型
2023-12-29 05:24:34刘锦行龙思杰王聪慧
模式识别与人工智能 2023年10期
刘锦行 李 琳 龙思杰 王聪慧
社交媒体用户画像的研究可宽泛划分为两种属性:自然属性和行为属性.自然属性是指用户不会轻易随时间变化而改变的自然特质,如用户性别和出生年代等[1].行为属性是指用户随时间推移可能发生变化的行为特征,如兴趣爱好、饮食习惯等.
社交媒体平台分析用户生成内容(User Gene-rated Content, UGC),对用户进行不同维度的刻画,如推测用户性别和出生年代,了解用户群体分布特征,或挖掘用户潜在兴趣爱好,由此进行个性化推荐.
用户发表在社交媒体上的博文(推文)是某一生活时刻(Living Moment)想要发表的感想、评论及日常等内容,故可称为“moments”.社交媒体中的用户以时间线的形式发布moments,积累形成篇章级长度的多模态数据.相比常见的篇章级文本(如新闻、法律文书等)在语义上具有连贯性、结构上具有衔接性,社交媒体用户发布的moments并不具备上下文的强相关性,在结构上也是松散的.因此,如何处理这种社交媒体中众多moments组成具有一定长度规模的多模态数据,是用户画像构建需要解决的关键问题之一.
用户在不同时刻发布的内容形成一种具有篇章级长度和多个模态(文本、图像等)的篇章级多模态数据,目前的特征提取与融合方法往往依赖现有对长文本和图像的处理经验.
传统处理长文本的方法主要有三种:1)拼接用户的多个文本moments,视为一个文档[2-4];2)拼接所有文本moments后,采用滑动窗口方法切分成一组长度一致的片段[5-7],再分析每个片段并进行特征融合.3)单独分析每条文本moment后再进行特征融合[8-10].
方法1)由于合并所有的文本后再进行特征提取,使得特征提取方式是粗粒度的(Coarse-Grained).方法2)是滑动窗口的方式,前提假设是基于众多文本moments语意连贯且结构衔接.然而,这种方式必然会使一个完整的文本moment被分开,导致语义被破坏(Semantics Broken),或是在切分文本时不可避免地会将某个文本moment首部的一部分和另一个文本moment尾部拼接在一起,导致合成语篇(Synthetic Discourse)问题.方法3)在模型训练时分别处理每条文本moment,可获得细粒度的特征表示,但如何设计有效的融合机制是用户画像构建的技术难点之一.
在用户画像构建中考虑图像模态,用户的视觉moments由多幅图像组成,这些图像也构成具有一定长度规模的社交媒体图像集合.直观的处理方式是分别提取每幅图像的特征再进行特征融合,然而这种处理方式并未充分考虑用户视觉moments之间可能存在的内容关联性.
很少有用户画像构建的研究者考虑到用户模态偏好的问题,这导致不同模态的数据在属性预测任务中的贡献度存在差异.有些用户可能更倾向于同时使用图像和文本表达自己,而另一些用户可能更喜欢使用文字而非图像表达观点.这种差异导致不同用户的文本moments和视觉moments对用户画像属性标签预测的重要性不同.如何平衡这种用户模态偏好导致的不同模态数据对任务贡献度不同,也是目前研究需要关注的问题.
针对如何有效处理社交媒体用户发布的篇章级长度多模态数据,受认知心理学的启发[9],本文提出基于Moments的社交媒体用户画像自然属性预测模型(Natural Attribute Prediction Model for Social Media User Profiling Based on Moments, MomProfi-ling).首先,借鉴人类在执行认知任务时对数据的记忆和分析方法,设计有效的数据分块(Chunk)方式,改善传统方法存在的破坏语意和合成语篇的问题.然后,通过综合注意力机制,解决不同用户在发表社交内容时存在的模态使用偏好问题以及同一模态数据间对任务贡献度存在差异的问题.在两个社交媒体数据集上进行对比实验和消融实验,验证MomProfiling的有效性.
1 相关知识
1.1 数据模态选择
Yang等[11]设计PERS(Personality Profiling Meta Ensemble Framework),能有效利用来自不同社交媒体的用户博文和图像数据,从中推断用户的MBTI(Myers-Briggs Type Indicator)人格特征.Li等[4]提出AMUP(Attention-Based Multi-modal User Profiling Model),通过用户的博文文本、头像图像以及用户关系网络预测用户年龄、性别和职业.Hu等[12]研究用户决策分析,提出PROUD(Profiling User Deci-sions),利用用户的位置、时间和相关兴趣点解释用户决策.Kim等[9]利用Instagram上用户一组帖子中的文本、图像和标签,预测具有影响力的用户和他们的帖子所属的类别(如美妆、旅游和健身等),并提出Influencer Profiler.Influencer Profiler捕获文本和视觉信息之间的相关性,从Weibo平台上用户的基本信息和博文(文本和图像)中生成用户的兴趣.综上所述,社交媒体博文内容是目前研究者们最广泛采用的用户画像数据之一.
1.2 多模态特征融合方法
在PAN 2018比赛的数据集(https://pan.webis.de/clef18/pan18-web/author-profiling.html)上,包含博文文本和博文图像两种模态数据,用于预测用户的性别.
在参赛队伍中,Takahashi等[13]提出TIFNN(Text Image Fusion Neural Network),在多模态融合阶段将文本表征和图像表征进行笛卡尔积,再将经过笛卡尔积得到的矩阵进行行池化和列池化操作,最后拼接行池化和列池化的结果,获得融合表征.TIFNN取得不错的效果.
Patra等[14]使用图像字幕生成工具,将图像转化为文本表示,从推文和图像字幕中提取LSA(La- tent Semantic Analysis)、词嵌入和文体特征,最后,采用拼接方式融合文本和图像特征,利用支持向量机进行分类预测.这种拼接特征进行融合的方法属于早期融合.
另一些研究者考虑使用后期融合,将每个模态的预测概率通过一定规则组合后做出相应的决策.Schaetti[15]使用基于字符的卷积神经网络进行推文分类,使用ResNet18[16]进行图像分类,从而获得每条文本和每幅图像性别预测的概率值,最后将这些概率值相加后求平均值,得到用户的性别预测概率值.
在PAN 2018比赛之外的研究中,Suman等[10]提出PRNN(Product-Based Neural Network),如TIFNN[13]一样采用笛卡尔积的方式融合用户博文的文本特征和图像特征,用于预测用户性别.Liu等[17]提出JUHA(Joint User Profiling Model with Hierarchical Attention Network),使用用户的博文以及用户间关系研究用户性别和年龄,拼接不同模态特征并融合,这是一种较常规的方法.Chiu等[18]利用Adaboost集成学习技术将图像分类器AlexNet[19]、文本分类器Bi-LSTM(Bidirectional Long Short-Term Memory)和用户行为分类器(随机森林)三个弱分类器合并为一个强分类器,用于预测用户抑郁症倾向.然而,这种特征融合方式常见于各类算法比赛以提升成绩,未针对用户画像相关问题本身做出相应处理.Li等[20]提出COOPNet(Text-Image Cooperation Frame-work),考虑采用注意力机制对博文文本、头像图像和用户关系三种不同数据进行特征融合,推断用户性别、年龄和职业.此外,Li等[4]提出AMUP,使用情感特征增强用户博文文本特征,并结合文本、图像与它们的协作表示预测用户的性别.Long等[21]提出MomNet(Gender Prediction Framework Based on User-Posted Living Moments),利用注意力机制增强博文的文本特征和图像特征的融合,在性别预测的质量上取得提升.
按照技术分类总结上述多模态特征融合方法,具体如表1所示.
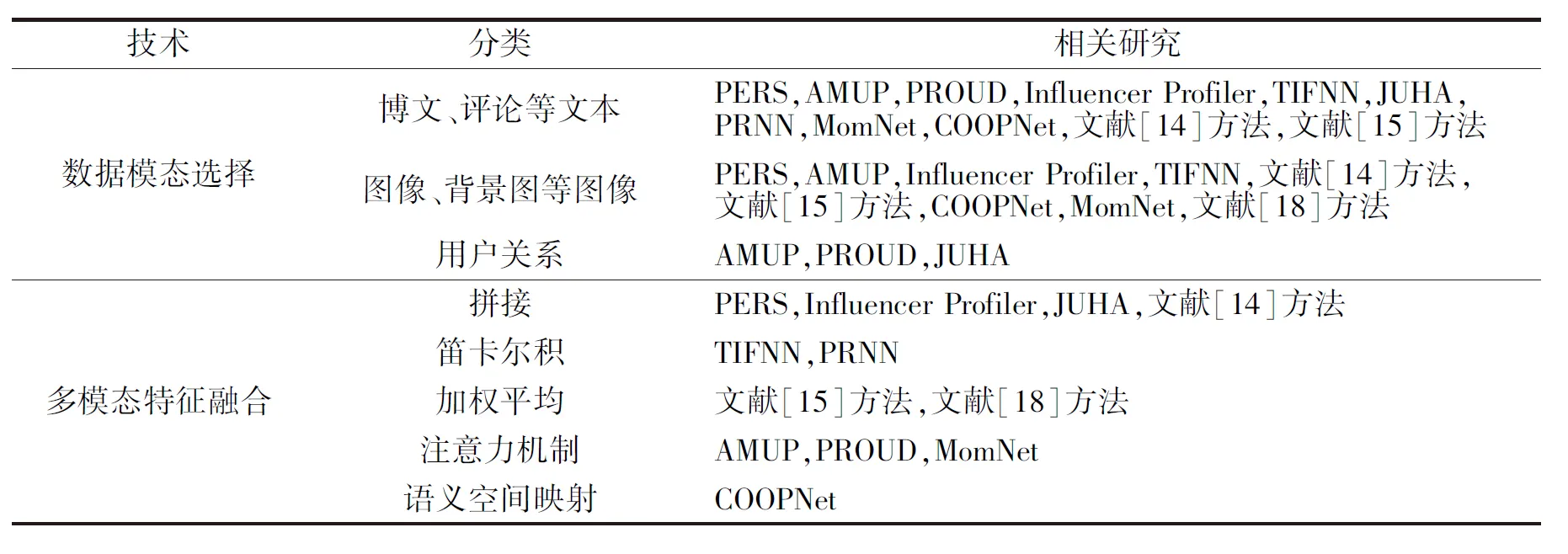
表1 多模态用户画像不同技术的相关研究Table 1 Related research on different technologies for multimodal user portraits
1.3 多模态博文数据集
在社交媒体用户画像领域中,目前公开的以用户自然属性标签为主的多模态博文数据集较少.据本文了解,仅PAN 2018比赛公布包含性别标签的多模态博文数据集.其它相关研究中使用的多模态博文用户画像数据集很少在论文中公开.这对本文基于多模态博文对用户自然属性用户画像展开研究造成一定阻碍,因此参考PAN 2018数据集,本文收集中文和英文两个数据集.
2 基于Moments的社交媒体用户画像自然属性预测模型
2.1 工作记忆理论
在认知任务中,人们需要在短时间内存储和处理各种相关信息.工作记忆(Working Memory)是指个体在执行认知任务时,暂时储存与操作信息的能力[22-23].个体之间工作记忆容量存在一点差异,与注意力调控、非言语推理等重要能力水平相关[24].
Miller[25]认为人类工作记忆的容量大约为7.通常,人类能记住5~9个随机数字.然而,这并不意味着人类的工作记忆容量仅限于记住7个左右的数字.实际上,脑内同时处理信息的容量是按“组块(Chunk)”衡量的.每个“组块”可包含多个数字、词语或其它形式的信息.而不同类型“组块”的分类方式和大小一般不同.这些“组块”间划分的主要依据是:单个“组块”的内部要有较强的联系,而“组块”之间的联系较弱[26].
受此启发,本文可将社交媒体用户发表的众多moments通过相关度联系,形成多个组块,用于特征提取与分析.
本文在模型架构设计上借鉴Baddeley等[27]提出的三成分模型.该模型由语音回路、视空间模板和中央执行系统三个子系统组成,如图1所示.
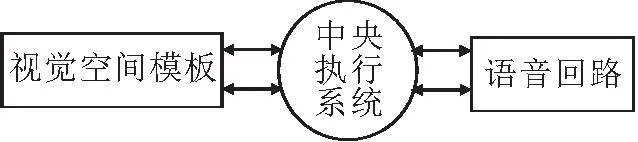
图1 Baddeley的工作记忆三成分模型框图Fig.1 Baddeley′s working memory theory with three components
语音回路和视空间模板分别负责语音和视觉信息的储存和加工,为设计针对moments的特征提取提供参考.中央执行系统主要负责协调工作记忆中各子系统的功能、控制编码和提取策略,以及操纵注意力系统等[27-29],为设计多模态特征融合模块提供借鉴.
2.2 CLIP预训练模型
Radford等[30]提出CLIP(Contrastive Language-Image Pre-training),是一种多模态预训练模型,使用4亿条图文数据对将文本作为图像的标签进行训练.与NLP领域中的BERT(Bidirectional Encoder Re-presentations from Transformers)[31]、GPT3[32]等预训练模型不同,经过多模态预训练的CLIP可同时得到良好的文本和图像的表示,在众多的多模态任务上表现优异.在社交媒体中,图像和文本是用户交流的主要媒介,这与CLIP的数据处理特点契合.
近年来出现的多模态预训练模型,包括ALBEF(Align the Image and Text Representations Before Fusing)[33]、BLIP(Bootstrapping Language-Image Pre-training)[34]、SOHO(Seeing Out of the Box)[35]等,在特征提取方面也都表现出色,这些模型为多模态任务提供强大的工具.考虑到本文研究重点是在具有多个模态(文本、图像等)的篇章级多模态数据上有效进行模态融合,因此在多模态预训练模型中选择CLIP.
本文提出的框架可采用其它多模态图文预训练模型对图文进行编码,作为用户画像框架的输入层,最终实现多模态社交媒体用户画像中的自然属性预测.
2.3 本文模型架构
受工作记忆理论的启发,本文提出基于Moments的社交媒体用户画像自然属性预测模型(MomProfling),框架如图2所示,借鉴人类大脑系统如何聚合相关的信息以及如何协调不同模态的特征以预测用户画像的标签.
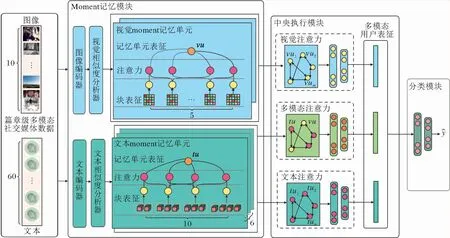
图2 MomProfling框架图Fig.2 Structure of MomProfling
MomProfling框架由3个模块组成:Moment记忆模块、中央执行模块和分类器模块.
Moment记忆模块利用相似度,关联多条文本moments和多条视觉moments,聚合到相应的块(Chunk)中.一个块作为一个特征提取的单元(Unit),一组Units最终得到相应一批moment记忆表征.这一设计保证文本moments的词汇内聚性,避免语义被破坏.同时也使以多个图像为主的视觉信息,通过相似度得以聚合,方便后续的分析.
中央执行模块通过对文本、图像及其组合的mo-ment记忆表征的综合注意力协调用户模态使用偏好和用户模态内数据的贡献度.最后,采用softmax分类器预测用户的性别或出生年代.
2.3.1Moment记忆模块
用户moments是一组文本和图像数据组成的集合.Moment记忆模块负责从moments中学习特征表示.对moments的组织划分是Moment记忆模块的第一个关键步骤.本文借鉴工作记忆机制,设计聚合策略以重组moments,防止文本moments生成人工合成的语篇或破坏现有语义,并考虑视觉图像moments的内容关联.人类在执行认知任务时,工作记忆的容量限制为5~9块(Chunk),因此,本文在一个单元中放置不超过9个moments,用于学习特征表示.
当观察用户发表的moments时,将原本在时间上有间隔但内容相关的moments关联后进行决策分析是合理的途径.因此,在文本moment记忆模块中,根据内容的相似性聚合时间上分隔的文本mo-ments.假设用户的文本moments为
[TM1,TM2,…,TMi],
经过文本编码器(Text Encoder)转换为一组词向量
tm=[tm1,tm2,…,tmi].
然后,文本相似度分析器(Textual Similarity Analy-zer)会从这组词向量中选择余弦相似度差异较大的n个向量作为主导向量,记为
将它们分配到不同的文本moment记忆单元中.tmdom的要求定义如下:
∀tp∈tmdom,tq∈tmdom,
Cosine(tp,tq)<θ,
p≠q,
(1)
其中θ表示余弦相似度的阈值.θ并非预先设定的参数,而是通过模型内部计算得出.
文本相似度分析器使用二分类搜索算法确定θ和tmdom.
1)设置主导向量数量n和足够小的搜索精度ε,初始化阈值范围[θmin,θmax],覆盖整个余弦相似度范围[0,1].
2)遍历文本向量tm,获取当前的主导向量列表tmdom,tmdom满足式(1)要求.对比当前tmdom中的向量数量与n,更新[θmin,θmax].
3)反复执行2),多次迭代,直到满足θmax与θmin之差小于ε或tmdom中向量数量不超过n时,循环结束.θmax或θmin为满足条件的最小阈值θ.
最后,文本相似度分析器从除去tmdom的tm中挑选与n个主导向量相似的元素,并放入对应的单元中.考虑工作记忆理论中关于容量限制,可设置n≤9.基于相似度聚合策略,每条文本moment在特征提取后通过相似性聚合.这样做既不会轻易产生像滑动窗口切分方式那样的合成语篇,也保证细粒度的特征提取.
但是,同一模态内的moment对任务贡献度也存在差异,具体来说,一个单元中不同的tm对用户画像分析具有不同的信息量.因此,本文将注意力机制应用Moment记忆单元,在学习moment记忆表征时能更关注对任务重要的tm.最终,n个单元得到n个文本moment记忆表征,如图2左侧绿色部分所示,表示为
tu=[tu1,tu2,…,tun].
计算机视觉通常会直接把图像缩放为某个固定尺寸,对于尺寸较大的图像来说,可能会导致较大的信息损失.同时,人类在观察图像时常常先观察局部特征再观察总体特征.考虑到在社交媒体平台中,用户发表的视觉moments尺寸(像素)大小存在差异,执行如下处理步骤.
首先,视觉moment记忆单元会将高度大于宽度的图片旋转90°,确保所有图像的宽度大于高度.再针对用户的视觉moments,按宽度进行排序,得到
[VM1,VM2,…,VMj].
然后将宽度大于特定值w的图像进行分割,其中
(2)
W1表示VM1的宽度,Wj表示VMj的宽度.得到分割后的图像宽度:
(3)
其中Woriginal表示原始图像的宽度.
根据式(2)、式(3)和
可确保被切分后的视觉moments的宽度Wsegmented不会大于2W1.这有助于限制图像尺寸的差异,并确保原本属于同幅图像的视觉moments能在一个单元中被分析.经过上述分割方式得到视觉moments,再经过CLIP的图像编码器后得到的向量:
vm=[vm1,vm2,…,vmk],k≥j.
与文本Moment记忆模块类似,特征向量数组vm通过余弦相似度将其分配到m个视觉moment记忆单元中.再利用注意力机制融合同一单元中不同的视觉moments.最终获得m个视觉moment记忆表征:
vu=[vu1,vu2,…,vum].
同样地,确保m≤9.该处理过程与文本moments类似,故不再赘述.
2.3.2中央执行模块
本文设计的中央执行模块旨在调节不同模态的特征提取,并操纵注意力系统协调不同模态的特征.如图2右侧所示,中央执行模块由3部分组成:文本注意力系统、视觉注意力系统和多模态注意力系统.它们负责协调同一模态内的moment记忆表征和不同模态间moment记忆表征的贡献度,以便从moment记忆表征中学习多模态联合用户表征.
针对文本模态,采用注意力机制赋予重要的文本moment记忆表征更高的权重.再拼接多个文本moment记忆表征,通过全连接层学习得到文本用户的向量化表征.从视觉moment记忆表征中学习得到向量化的视觉用户表征.多模态注意力系统旨在协调由于用户对不同模态的使用偏好情况而产生的不同模态信息对任务贡献度存在差异的问题.此外,同一用户的不同moments包含的出生年代和性别信息量也存在差异.为了解决这一问题,本文引入自注意力机制(Self-Attention),用于拼接来自文本、视觉和两者融合的特征,最终形成用户画像的多模态表征.
2.3.3训练方法
MomProfiling的用户画像分类器由多个全连接层和一个softmax函数组成,利用中央执行模块学到的多模态用户表征生成预测概率分布.在本文中,交叉熵(Cross Entropy, CE)用作MomProfiling的损失函数,定义如下:
其中:
p=[p0,p1,…pC-1]
表示一个概率分布,每个元素pi表示样本属于第i类的概率;
y=[y0,y1,…,yC-1]
表示样本标签的one-hot表示,当样本属于第i类时,y=1,否则,y=0;C表示样本标签.
在进行性别预测的二分类任务时,C=2;在执行出生年代预测的三分类任务时,C=3.在训练MomProfiling时,本文加载CLIP的预训练参数,将其作为获得视觉moments和文本moments特征的编码器,并冻结CLIP的参数,体现本文设计的Moment记忆模块和中央执行模块的效果.
3 实验及结果分析
3.1 实验数据集
1.3节的文献调研表明,未见公开的包含多个自然属性标签的博文数据集.尽管PAN 2018年用户画像任务中公开具有多条文本和图像博文数据且包含用户性别标签的数据集,但是为了验证多个自然属性维度上MomProfiling的实用性,需要自行收集相应的数据集.
考虑到数据质量与用户标签可信度等方面的问题,本文参考PAN 2018用户画像数据集的形式,根据已有的公开数据集上提供的用户ID,重新获取对应用户发布的博文,并构建新的数据集.
最终,本文收集一个中文的Weibo数据集和一个英文的Twitter数据集,均包含用户的多条文本和图像博文.中文Weibo数据集是从“微众杯”技术评测提供的数据集上获取的一批新浪微博的用户ID和标签,并通过爬虫技术从微博爬取对应的数据.英文Twitter数据集根据Liu等[36]提供的用户ID并通过Twitter API(Application Programming Interface)重新获取用户相应的数据.在重新收集数据之后,进行数据的筛选和整理,删除一些标签缺失或博文数量少于20条的用户.两个数据集的用户性别标签均为男或女.对出生年代标签的设置参考微众杯的数据集,分为1979年及之前、1980年至1989年、1990年及之后三个年代.
数据集统计信息如表2所示.Weibo数据集共有2 486位用户,男女比例接近3∶1,出生年代从前到后比例约为1∶3∶2.5.参照微众杯技术评测任务对训练集及测试集的划分,Weibo数据集的训练集包含2 075位用户,测试集包含411位用户.该数据集上每位用户提供的文本moments数量不超过60条,视觉moments数量不超过10条.

表2 数据集统计信息Table 2 Dataset statistics
Twitter数据集上共有6 572位用户,男女比例约为3∶1,出生年代从前到后比例约为1∶1∶1.5.参考以往研究工作的思路,将数据集随机划分并进行五折交叉验证,每次选择4 600位用户作为训练集,1 972位用户作为测试集.每位用户提供至多60条文本moments和至多10条视觉moments.
3.2 参数设置及评价指标
3.2.1参数设置
每个用户的文本moments为60条,视觉mo-ments为10条.在每个文本moment记忆单元中分析10条文本,每个视觉moment记忆单元中分析5个视觉moments(分割后).由于两个数据集的两个任务中样本数量都不均衡,为了使分类模型不过分倾向于多数类样本,采用权重随机出现样本的方法.假设数据集中有A、B两个类别的样本,其中A有x个,B有y个,那么每个属于A类别的样本的权重为:
该计算方法可类推到多分类样本的权重计算.权重越高,出现的概率也会越大.通过这样的方式可抑制模型训练结果偏向多数类别的问题.根据权重随机出现样本使用Pytorch框架中的WeightedRandom-Sampler.
在模型设置方面,在Twitter英文数据集上,使用官方实现的CLIP,并加载ViT-B/32参数.在Weibo中文数据集上,鉴于官方未提供中文预训练参数,采用Chinese-CLIP实现,并加载ViT-B-16参数.在模型训练阶段,未对CLIP参数进行微调,仅对本文设计的下游模型进行训练.此外,选择ReLU函数作为激活函数.
由于数据集和任务的不同,MomProfiling在超参数设置上也会有一定的改变.批量大小设为32,网络训练次数设为30,文本moment单元数设为6,视觉moment单元数设为2.整体上采用Adam(Adaptive Moment Estimation)作为优化器,多次实验后:学习率在Twitter数据集上性别预测任务中设为1e-5, 出生年代预测任务中设为8e-6;在Weibo数据集上性别预测任务中设为6e-6,出生年代预测任务中设为4e-5.模型在每轮训练后学习率衰减为原来的9/10.在一台拥有4块TITAN XP GPU、总计48 GB显存的服务器上进行训练.
3.2.2评价指标
在性别的二分类预测中,选择AUC(Area Under Curve)、F1 值和准确率(Accuracy, Acc)作为评价指标,而在出生年代的三分类预测中,使用微平均F1、宏平均F1和加权平均F1作为评价指标.考虑到数据集不同类别的样本数量不均匀,导致准确率和微平均F1在模型偏向多数类时可能出现较高值的情况,因此,除了准确率和微平均F1之外,其它指标的提升对于模型性能评估更重要.
3.3 对比实验
本文以多模态预训练CLIP作为文本和图像的特征提取器,结合工作记忆理论,设计MomPro-filing.为了验证MomProfiling在性别和出生年代这2个自然维度标签上的预测能力,对比如下近年来通用的6个基线模型.
1)单模态用户画像模型.
(1)Celebrity[37].用于预测用户的职业和性别的学习方法.通过Twitter和维基数据建立一个规模庞大的名人文本数据语料库——Webis Celebrity Corpus 2019.在模型上采用TextCNN作为网络模型,在Webis Celebrity Corpus 2019中进行预训练后再进行迁移学习,达到优秀的用户画像分析效果.Celebrity在PAN 2015~PAN 2018提供的数据集上取到最优成绩.
(2)CogLTX(Cognize Long Texts Like Human)[38].利用BERT处理长文本任务的学习模型.为了解决BERT对于文本输入长度存在限制且内存消耗和时间消耗较大等问题,CogLTX在工作记忆理论指导下,设计从长文本中获取关键文本段的算法,减少需要分析的文本长度.
2)多模态用户画像模型.深度学习的发展使其能有效处理和学习多种模态数据的特征,目前用户画像的研究重心也逐渐从单模态转移到利用多种模态的数据进行分析.
(1)TIFNN[13].在PAN 2018任务中取得冠军.在处理文本和图像时,使用传统的文本和图像处理方法,未针对性处理社交媒体博文数据,但其在多模态数据分析时将不同模态数据分到不同的模块中处理,再通过一个融合模块融合多种数据特征,得到最终结果.
(2)PRNN[10].与 TIFNN在整体结构上相似,但在特征提取上有一定改变.不同于TIFNN将所有推文合并进行分析的方法,PRNN将用户的n条推文分词后通过BERT分别得到相应推文的编码表示,使用相加求平均的方式融合多条推文的特征.图像处理与推文处理相类似.
(3)CLIP[30].使用4亿条图文数据对将文本作为图像的标签进行训练.CLIP联合训练一个图像编码器和一个文本编码器,预测图像和文本是否匹配.本文在预训练好的CLIP基础上,在其下游通过多层线性分类器处理CLIP 输出的文本和图像特征,完成多模态用户画像的自然属性标签预测任务.
(4)MomNet[21].使用BERT提取文本推文特征,使用VGG16提取图像特征.在特征融合阶段使用注意力机制进行特征融合.最终融合后的特征通过由全连接层和softmax函数组成的分类器,预测用户画像的属性标签.
各模型在性别预测任务上的实验结果如表3所示,表中黑体数字表示最优值,斜体数字表示次优值.由表可见,MomProfiling在性别预测上的综合性能达到最优.
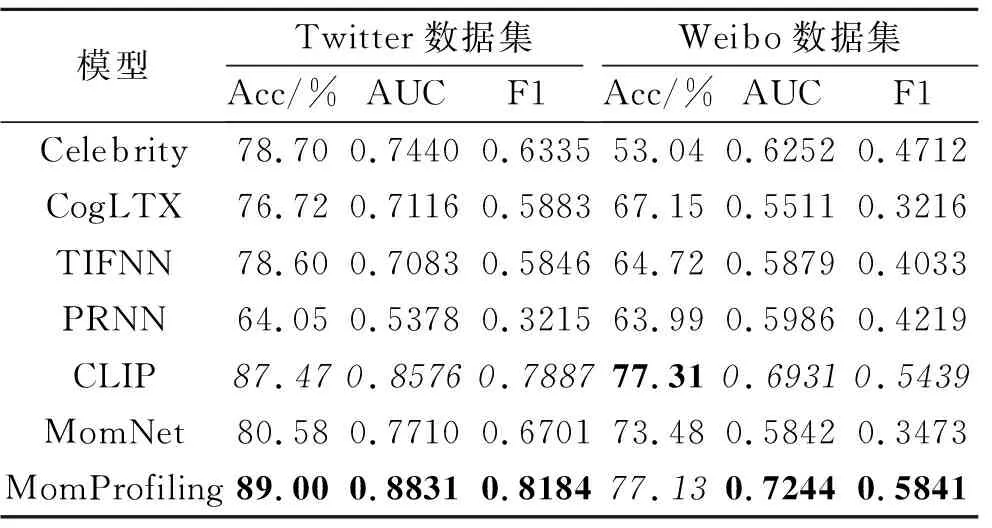
表3 各模型在性别预测任务上的性能对比Table 3 Performance comparison of gender prediction among different models
在Twitter数据集上,相比次优的CLIP,MomProfiling在3项指标上均取得明显提升.准确率提升1.7%,AUC提升2.9%,F1值提升3.7%.尽管准确率只有小幅提升,但考虑到数据集上存在数据不均衡的问题, AUC和F1指标的提升更能有效展示MomProfiling在性别预测任务上的卓越表现.
在Weibo数据集上,相比CLIP,MomProfiling的准确率略降0.2%,但在AUC和F1指标上分别提升4.5%和7.3%.这表明MomProfiling在识别少数类样本方面取得一定进步.此外,次优的CLIP引入多模态预训练模型,相比其它基线模型,在两个数据集上的效果都明显突出.相比TIFNN,CLIP在性别预测任务上的F1值在Twitter、Weibo数据集上分别达到0.788 7和0.543 9,而TIFNN分别为0.584 6和0.403 3.
各模型在出生年代预测任务上的实验结果如表4所示,表中黑体数字表示最优值,斜体数字表示次优值.由表可见,MomProfiling在Twitter数据集上的表现出色,在各项指标上均高于次优的CLIP,在宏平均F1上提高12.9%,在微平均F1上提升6.9%,在加权平均F1上提升10.2%.这说明在Twitter数据集的出生年代预测任务中,MomProfiling不仅在少数类样本上有所提升,在多数类样本的分类上也有明显进步.
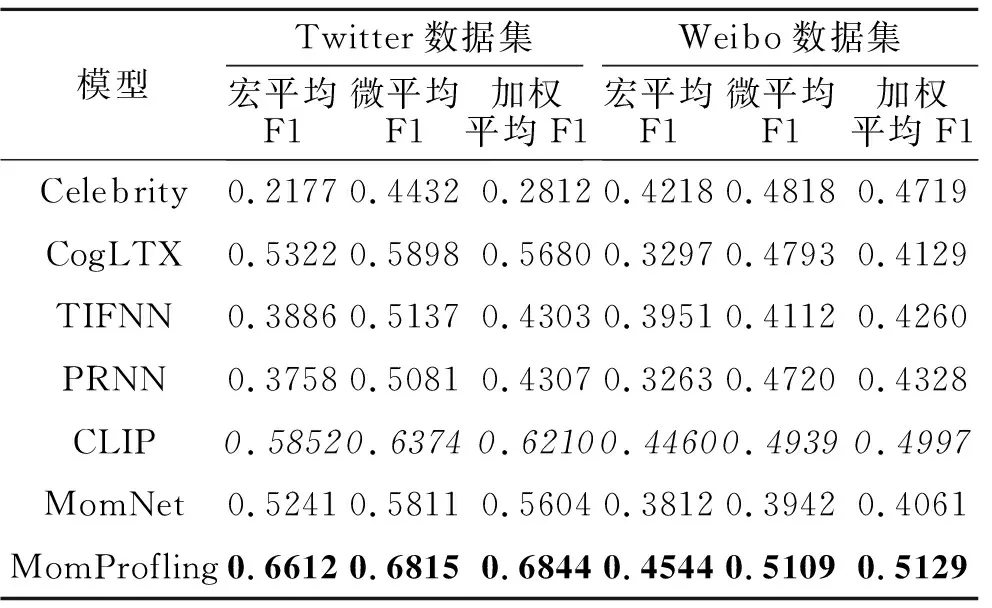
表4 各模型在出生年代预测任务上的性能对比Table 4 Performance comparison of birth year prediction among different models
在Weibo数据集上,MomProfiling针对出生年代预测效果的整体提升幅度小于在Twitter数据集上.在Weibo数据集上,相比CLIP,虽然宏平均F1提升不大,但微平均F1增长3.4%,在加权平均F1上也有2.6%的提升.两个数据集上的结果表明Mom-Profiling在Weibo数据集上出生年代预测能力的提升.
总之,相比基线模型,MomProfiling在两个任务上的用户画像构建能力都有所提升.这一结果得益于本文设计的Moment记忆模块和中央执行模块对用户发布在社交媒体中的众多moments的有效处理和分析.
3.4 消融实验
为了进一步验证这两个模块的效果,在Twi-tter、Weibo数据集上进行消融实验,分析各模块的作用.
各模块在性别预测任务上的消融实验结果如表5所示,表中黑体数字表示最优值.文本和视觉模态数据的分析都不包含MomProfiling多模态联合处理的部分.另外,在未添加Moment记忆模块和中央执行模块的情况下,给出CLIP的结果.
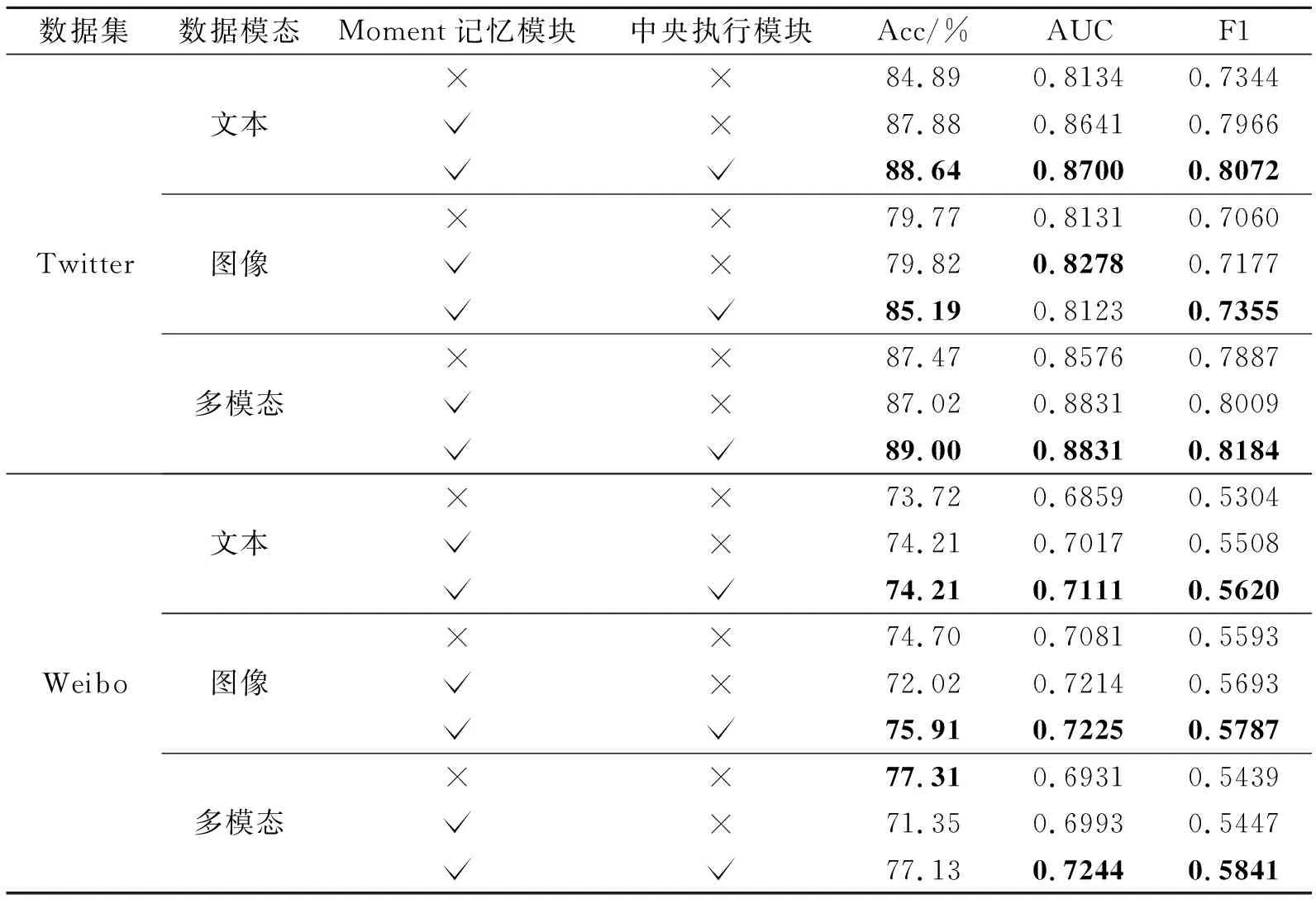
表5 MomProfiling各模块在性别预测任务上的性能对比Table 5 Performance comparison of gender prediction among different modules of MomProfiling
从同个模态内的实验数据上看,Moment记忆模块和中央执行模块的增加都为性别预测效果带来提升.在文本和图像中,Moment记忆模块带来的提升要略大于中央执行模块.本文认为这和中央执行模块设计的初衷主要是为了多模态特征的融合有关,所以在单模态数据上的效果不是很明显.
Moment记忆模块能有效组织文本和视觉moments,提升模型用户画像构建效果.增加Moment记忆模块后,在文本和图像模态上,三个指标均有所提升,尤其在文本模态上的提升更显著.在Twitter数据集的文本数据上,增加Moment记忆模块后准确率提升3.5%,AUC提升6.2%,F1值提升8.4%.在多模态数据实验中,AUC和F1值均有所提升,但准确率略微下降.这可能与在只添加Moment记忆模块时,仅采用拼接方式进行多模态融合有关.在Weibo数据集上,MomProfiling的两个子模块在准确率上提升不大,但在AUC和F1值上有明显改善.这说明MomProfiling的两个模块可有效增强对少数类样本的预测能力.
中央执行模块通过注意力机制,平衡用户对不同模态使用的偏好.增加中央执行模块后:在Twi-tter数据集的图像模态数据上,AUC指标出现轻微下降;在多模态数据上,AUC的改善程度也有限,但准确率和F1值都有较大提升.而在Weibo数据集上,引入中央执行模块后,在多模态数据上的准确率得到提升.相比CLIP,AUC和F1值都得到提升,AUC提升3.5%,F1值提升7.2%.这说明中央执行模块具有对不同类用户的区分能力,能有效应对用户模态使用偏好问题.
各模块在出生年代预测任务上的消融实验结果如表6所示,表中黑体数字表示最优值.由表可知,增加Moment记忆模块和中央执行模块后,出生年代预测的结果在稳步提升,表现基本与性别预测任务一致.但在Moment记忆模块添加后可能出现某些指标值下降的情况.例如:在Weibo数据集的多模态数据上,在添加Moment记忆模块后,虽然宏平均F1有所提升,但微平均F1和加权平均F1都有所下降.不过,这并不意味Moment模块效果不好.在样本不均衡的数据集上,反而说明改善CLIP偏向多数类的情况.
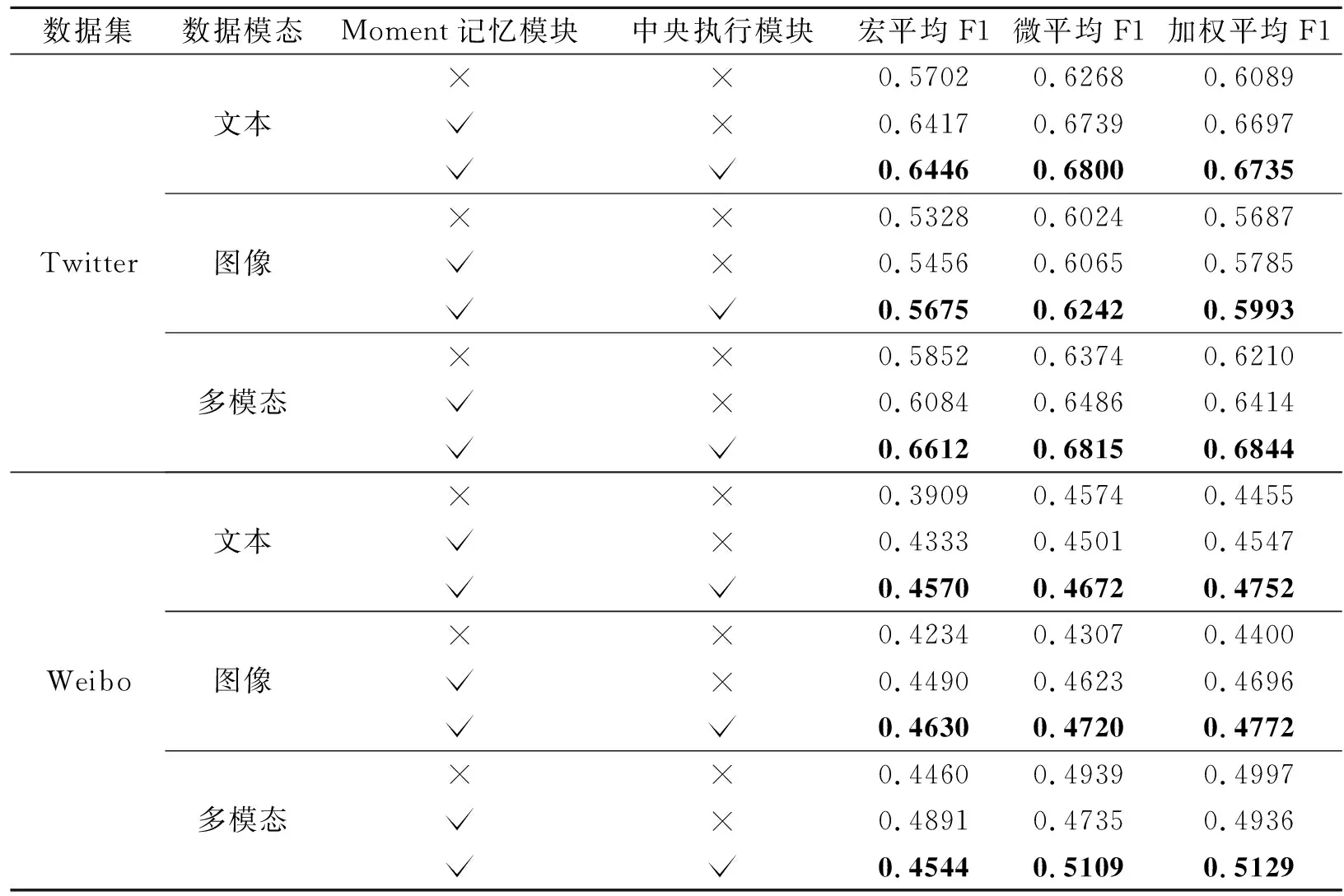
表6 MomProfiling各模块在出生年代预测任务上的性能对比Table 6 Performance comparison of birth year prediction among different modules of MomProfiling
在添加中央执行模块后,在不同模态数据的出生年代预测结果上,所有指标均最高.这说明本文设计的两个模块在相互配合之下能实现高质量的出生年代预测.
3.5 参数实验
为了研究不同数量的Moment记忆单元对模型效果的影响,本节调整MomProfiling中Moment记忆模块的单元数量.
根据2.4节的理论指导,Moment记忆模块在组织划分用户的moments数据时需要设置合适的Moment记忆单元数量,使其在符合工作记忆理论的前提下,保证数据能被有效利用.然而, Moment记忆单元数量的最佳选择并没有一个直接的方法能够计算得到,因此需要不断地调整参数,直至找出最优值.
由于MomProfiling的文本Moment记忆模块和视觉Moment记忆模块都涉及到设置Moment记忆单元数量,将文本和图像分开进行参数实验.
Moment记忆单元数量的选择受限于输入的moments数量.例如本文输入的文本moments数量为60条,那么可选择的Moment记忆单元数量就需要能将60整除,否则就需要增加或减少moment数量.
本节实验中,对于文本Moment记忆单元数量设置6、5、4三种情况,对于视觉Moment记忆单元数量设置5、2两种情况.
不同Moment记忆单元数量在性别预测任务和出生年代预测任务上的性能对比如表7和表8所示,表中黑体数字表示最优值,斜体数字表示次优值.
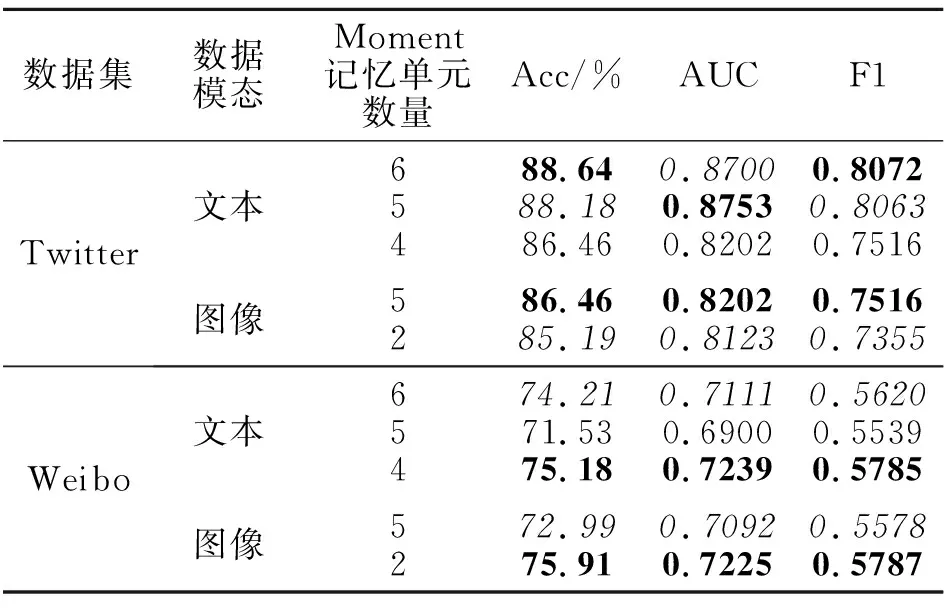
表7 Moment记忆单元数量不同时MomProfiling在性别预测任务上的性能对比Table 7 Gender prediction of MomProfiling with different numbers of moment memory units
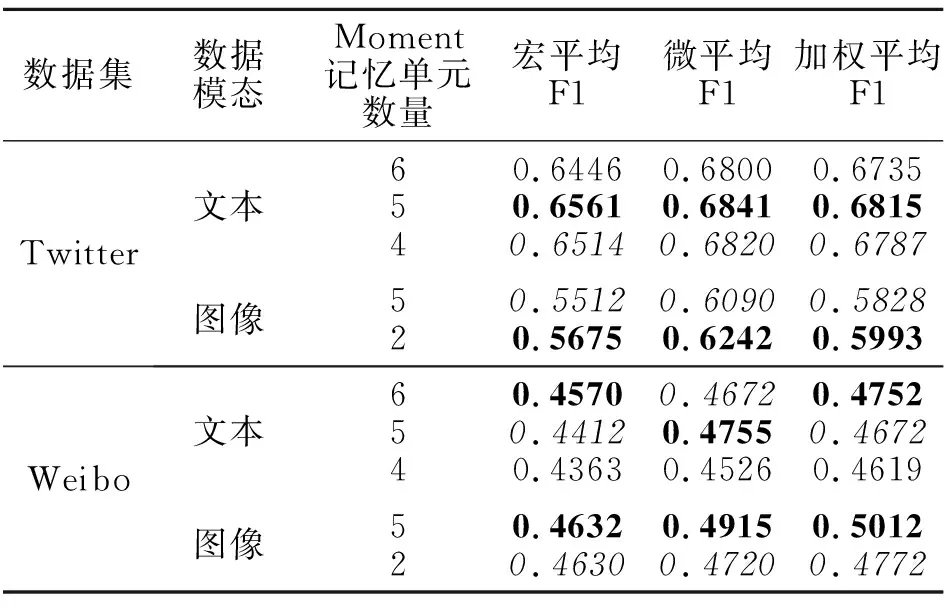
表8 Moment记忆单元数量不同时MomProfiling在出生年代预测任务上的性能对比Table 8 Birth year prediction of MomProfiling with different numbers of moment memory units
观察表7和表8可发现,Moment记忆单元数量会在一定程度上影响模型效果,但在性别预测任务和出生年代预测任务中并未发现实验结果与Moment记忆单元数量呈现正相关性或负相关性.所以在实际应用中,需要在满足工作记忆理论的情况下,尝试多种Moment记忆单元数量设置以获得较优的实验结果.
4 结 束 语
本文在认知心理学的指导下提出基于工作记忆理论的用户画像自然维度属性自动预测模型(MomProfiling),提升以出生年代和性别为主的自然属性用户画像构建质量.在对社交媒体博文数据的处理方面,提出有效的数据分块(Chunk)技术,改善以滑动窗口为主的传统方法对于语义的破坏或重组.并且利用注意力机制,解决不同用户模态使用偏好问题,一定程度上平衡同一模态内数据和不同模态间数据对任务贡献度的差异.今后可考虑扩大数据集的规模和覆盖范围,包括更多来源、更多模态和更多属性的社交媒体内容,提高数据集的代表性.从理论层面深入讨论如何在增加一个模态信息的情况下,保证基于已有模态信息构建的用户画像模型质量不致下降.
猜你喜欢
小哥白尼(神奇星球)(2022年3期)2022-06-06 07:39:34
新世纪智能(高一语文)(2020年9期)2021-01-04 00:42:42
非公有制企业党建(2020年10期)2020-10-27 06:30:14
数学年刊A辑(中文版)(2020年2期)2020-07-25 02:04:44
数学物理学报(2019年6期)2020-01-13 06:08:16
数学物理学报(2017年5期)2017-11-23 07:51:31
湖北经济学院学报·人文社科版(2015年8期)2015-12-29 05:53:07
上海电机学院学报(2015年4期)2015-02-28 14:30:00
计算物理(2014年2期)2014-03-11 17:01:39
延河(下半月)(2014年1期)2014-02-28 21:05:10
