
强化学习及其在机器人任务规划中的进展与分析
2023-12-30 11:34张晓明高士杰姚昌瑀
模式识别与人工智能 2023年10期
张晓明 高士杰 姚昌瑀 褚 誉 彭 硕
自动规划在机器人领域的广泛应用,为机器人任务规划带来持续发展.传统的机器人任务规划方法大多针对特定场景,通过确定性编程完成一系列任务规划[1].但是在复杂环境中,环境的动态性和部分可观性使传统的机器人任务规划难以有效开展[2].强化学习(Reinforcement Learning, RL)允许机器人通过与环境的互动不断地学习和适应,不断增强机器人在复杂环境中的智能性和适应性,更适应现实世界中的各种复杂任务.
强化学习让智能体(Agent)通过与环境的交互,学习最优的行动策略[3],从而获得最大化长期累积的奖励.传统的强化学习算法主要可分为两类:基于模型的强化学习(Model-Based RL, MBRL)和无模型强化学习(Model-Free RL, MFRL)[4].
在基于模型的强化学习中,智能体尝试建立环境的模型,如模拟环境状态转移概率和奖励函数,然后使用该模型规划和预测不同的策略效果,选取最优策略.Fong等[5]提出一种基于模型的强化学习方法,用于机器人非抓握操作的任务规划.方法采用长短时记忆模型,学习复杂的物体推动动态,再结合蒙特卡洛树搜索进行规划,用于制定接近目标位置的最佳推动动作序列,但其通常需要学习一个模型,并要求该模型允许预测动作产生的状态变化和奖励[6].虽然文献[5]方法具有较高的样本效率,但在复杂环境下往往难以精确建模.
在无模型强化学习中,智能体无需依赖环境模型,可直接通过与环境的交互学习策略.Herzog等[7]基于深度Q网络算法,结合离线数据和在线数据,构建一支由23个机器人组成的团队,有效开展垃圾分类和回收任务.Fang等[8]采用深度确定性策略梯度算法和HER(Hindsight Experience Replay)技术,引导机器人在抓取球形物体的任务中进行更有效的探索,成功提高机器人在任务规划过程中的学习效率,但其通常需要更长的训练时间和更多的交互用于学习,学习效率较低.
与传统的强化学习方法不同,分层强化学习(Hierarchical RL, HRL)作为一种特殊的强化学习方法,引入层次结构以简化复杂任务的学习,允许机器人任务规划中的抽象和分级表示,使机器人在复杂的现实世界中取得良好表现.Li等[9]提出HRL4IN(Hierarchical RL for Interactive Navigation),解决导航和机械臂操作的问题,在复杂的机器人任务中表现出较高的奖励和成功率,由此显示分层强化学习在机器人任务规划中的应用潜力.Eppe等[10]指出生物对复杂问题的解决能力依赖分层认知机制,进一步提出将生物启发的分层认知机制整合到智能体中,提高其问题解决能力,并明确指出分层强化学习在智能机器人发展,尤其是智能问题求解中具有重要地位,进一步推动强化学习在机器人任务规划领域的发展与应用.
由此可见,强化学习算法不断发展并在机器人领域被广泛应用,有效推动机器人任务规划的进步和创新,已成为机器人领域关注的重要前沿方向之一.
本文首先将机器人任务规划过程形式化为马尔科夫决策过程(Markov Decision Process, MDP),在部分可观的复杂环境下进一步形式化为部分可观测马尔科夫决策过程(Partially Observable MDP, PO-MDP).然后,基于强化学习的基本概念,详细介绍基于模型的强化学习、无模型强化学习和分层强化学习及其研究进展.其中,基于模型的强化学习包括基于黑盒模型(Model as a Blackbox)的强化学习和基于白盒模型(Model as a Whitebox)的强化学习.无模型强化学习进一步分为基于值(Valued-Based)的无模型强化学习、基于策略搜索(Policy Search)的无模型强化学习和基于演员-评论家(Actor-Critic)的无模型强化学习.分层强化学习分为基于目标(Goal)的分层强化学习和基于选项(Option)的分层强化学习.最后,介绍3类强化学习在机器人任务规划中的研究与应用,总结现存的主要挑战,并展望未来的发展方向.
1 机器人任务规划问题形式化建模
使用逻辑推理指导智能体选择一系列离散动作以完成目标的过程称为任务规划[11].在机器人任务规划中,自主探索和基于逻辑推理辅助的决策是机器人在现实世界中完成任务规划的关键要素.基于自主探索和决策过程,机器人任务规划问题可建模为MDP,或者在部分可观测的复杂环境中进一步建模为POMDP.
通常情况下,机器人MDP定义为一个五元组(S,A,M,R,γ).其中:S表示由世界环境构成的有限状态(s∈S)集合;A表示机器人的有限动作(a∈A)集合;M(s′|s,a)表示机器人在状态s时执行动作a到达状态s′的概率分布;R(s,a,s′)表示机器人在状态s时执行动作a到达状态s′获得的即时奖励;γ∈[0,1]表示折扣因子,控制智能体在决策时对未来奖励的考虑程度.规划的目的是找到一组从初始状态s0到目标状态sg的动作序列π,定义为策略,从而使长期累积奖励最大化.
在更复杂的部分可观测环境下,机器人MDP可扩展为POMDP. 机器人POMDP通常定义为一个七元组(S,A,M,R,Ω,O,γ),其中,S、A、M、R、γ的定义均与MDP中定义相同;Ω表示观测空间;O(o|s′,a)表示观测模型,代表机器人在处于状态s′且采取动作a以后,接收到环境观测(o∈O)的概率分布.
基于上述建模方式,可以将各种不同类型的任务使用一种统一的框架进行描述,从而使该领域的研究人员可应用相同或类似的算法解决多种任务规划问题,有效提高机器人的适应性与智能化水平.但是,现实世界中的任务和环境日趋复杂,机器人需要解决的任务种类和数量也日趋增多.通过将机器人的动作空间结构化,使用更高级抽象的动作概括和利用原始动作[12],可模块化分解机器人要解决的任务,从而降低问题的复杂性.这种利用模块化的分层思想解决机器人任务规划问题的方法可使每个模块专注于解决特定类型的子任务,而不必同时处理整个任务的所有细节,从而提高机器人任务规划的效率.
现可进一步定义机器人任务规划问题中的抽象动作,并将其形式化,即将机器人任务规划问题中的有限动作集合A中的一个或多个动作进行更高层次的概括,抽象化为多个抽象动作进行形式化建模,记为n=(In,βn,πn).其中:
1)In表示初始化集.S→{0,1}为一个函数,将状态空间S中的每个状态s映射到{0,1}中的值,用于描述哪些状态可以启动该抽象动作.
2)βn表示终止条件.S→[0,1]也是一个函数,将状态空间S中的每个状态映射到[0,1]中的值,用于描述在达到某个状态s时,抽象动作停止执行的概率.当βn(s)的值接近1时,表示在状态s附近该抽象动作很可能将要结束,而当βn(s)的值接近0时,表示抽象动作会持续进行.
3)πn表示抽象动作策略.这是一个策略函数,将初始化集上的状态映射到原始动作,决定在选择某一抽象动作期间,机器人采取的具体动作.
上述形式化的抽象动作建模允许机器人基于分层结构将复杂任务分解为一系列子任务或抽象动作,而每个子任务或抽象动作都有自己启动的前提条件、终止条件和原始动作策略,使机器人能更有效地应对各种复杂任务.
2 强化学习基本概念
强化学习是一种通过与环境进行交互、不断试错以解决决策问题的机器学习方法,其目的是使智能体找到一种最佳策略,以最大化长期累积的奖励值[13].通常情况下,强化学习问题也被建模为MDP或POMDP.因此,机器人任务规划研究可自然地将强化学习作为一种有效的规划方法加以应用.
强化学习的基本框架如图1所示.在强化学习中,智能体与环境交互的一系列动作不会改变环境的基本性质.同时,环境的当前状况称为状态s∈S,智能体会根据状态和奖励的反馈选择某一动作a∈A,再转移到一个新的状态s′.奖励r=R(s,a,s′)在训练智能体时具有重要作用,当智能体做出正确决策时会受到奖励,而当智能体做出不佳决策时会受到惩罚.智能体试图通过与环境互动产生的奖励信号不断改进其决策策略,这对于解决机器人任务规划这种顺序决策问题具有较好的适应性和较高的成功率.
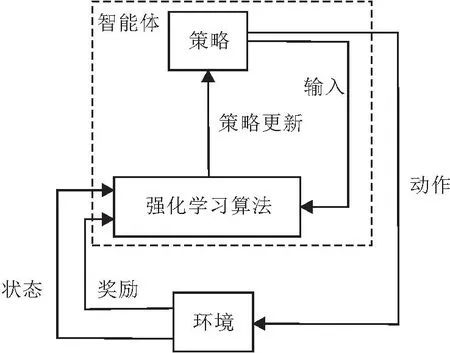
图1 强化学习基本框架Fig.1 Basic framework of reinforcement learning
在强化学习过程中,为了让智能体更好地平衡短期目标和长期目标,引入折扣因子γ∈[0,1],优化智能体获得的长期累积奖励一般记为
Ut=Rt+γRt+1+γ2Rt+2+γ3Rt+3+…
智能体通过状态和奖励回报反馈给强化学习算法.强化学习算法基于与环境的交互信息更新策略.作为决定智能体下一步动作的选择,策略通常可分为确定性策略at=π(st)和随机性策略
at~π(·|st).
智能体利用状态价值函数(State-Value Function)评估和改进策略π,即
在某一状态s下,通常采用动作价值函数(Action-Value Function)衡量采取某个动作a能获得的期望回报或累积奖励,即
通常可将状态价值函数
和动作价值函数
表示为当前状态和后继状态的值函数之间的递归关系:
p(s′,r|s,a)=P{st=s′,rt=r|st-1=s,at-1=a},
其中,p(s′,r|s,a)为一个条件概率分布,表示在给定状态s和动作a的情况下,智能体在下一个状态s′中获得奖励r的概率分布.
利用最优状态价值函数
和最优动作价值函数
可估算最优策略:
3 强化学习分类
由于强化学习算法具有较高程度的模块化特性,其标准化分类也变得较困难.目前通常的分类方式是围绕基于模型的分类方法和无模型的分类方法展开.在这种分类体系中,两种算法都有自己的应用领域和优势.无模型强化学习算法因其更通用和更适用于复杂环境的特性而被广泛应用.基于模型的强化学习算法具有更高的样本效率,算法收敛过程中所需的迭代次数更少,也具有独特的技术优势.这两种算法的对比如表1所示.

表1 两种强化学习算法的优缺点Table 1 Advantages and disadvantages of 2 reinforcement learning methods
分层强化学习作为强化学习的一种特殊类别,引入层次结构,利用高层策略指导低层策略,可应对传统强化学习在稀疏奖励和复杂任务的长期决策等方面的困难[14].强化学习算法分类如图2所示.
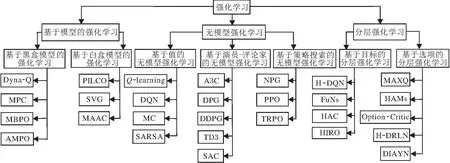
图2 强化学习算法分类Fig.2 Classification of reinforcement learning algorithms
3.1 无模型强化学习算法
无模型强化学习算法不依赖环境模型,智能体通过与真实环境的直接交互学习策略或值函数[15].通常将无模型强化学习算法进一步分为3个子类[4]:基于值的无模型强化学习算法、基于策略搜索的无模型强化学习算法和基于演员-评论家的无模型强化学习算法.
在基于值的无模型强化学习算法中,智能体在与环境交互的过程中学习构建一个价值函数,并利用价值函数衡量智能体处于特定状态或状态-动作对的累积奖励期望,从而推导最优策略.其中最典型的算法就是Q-learning[16].它通过估计Q值选取当前状态下的最优动作,并利用
不断更新Q值,其中α表示学习率.
如果状态和动作空间十分庞大[17],Q-learning需要维护的Q值表也会十分庞大.因此,作为对Q- learning的改进,DQN(DeepQ-Networks)[18]利用神经网络近似Q值函数,根据训练数据不断调整神经网络的参数,以逼近真实的Q值函数.其它典型的基于值的无模型强化学习算法也使用当前策略执行的动作学习值函数,如MC(Monte Carlo)[19]和SARSA (State-Action-Reward-State-Action)[20].不同的是,MC通过完整的轨迹学习值函数,而SARSA通过实时观察到的状态-动作序列学习值函数.
基于值的无模型强化学习算法存在两个突出的问题:
1)在面对诸如机器人机械臂连续轨迹规划的问题中,采用基于值的无模型强化学习算法的前提是离散化动作空间,往往会难以处理带来的高维动作空间;
2)基于值的无模型强化学习算法无法处理随机策略.
相比之下,基于策略搜索的无模型强化学习算法由于其直接从智能体与环境的交互中学习策略[21],可以较好地解决上述两个问题.
典型的基于策略搜索的无模型强化学习算法有NPG(Natural Policy Gradient)[22]、PPO(Proximal Po- licy Optimization)[23]和TRPO(Trust Region Policy Optimization)[24].NPG是一种基于策略梯度的强化学习算法,使用梯度下降优化策略参数.PPO旨在解决策略优化中的样本效率和稳定性问题,通过“剪切”技术控制策略参数的更新幅度,确保策略更新不会过于剧烈.TRPO通过定义策略更新的“信任区域”限制策略参数的变化,提升策略更新的有效性,避免性能下降.
基于演员-评论家的无模型强化学习算法结合值函数和策略搜索的特点,典型算法包括A3C(Asynchronous Advantage Actor-Critic)[25]、DPG(Deterministic Policy Gradient)[26]、DDPG(Deep DPG)[27]、TD3(Twin Delayed Deep Deterministic Po-licy Gradient)[28]和SAC(Soft Actor-Critic)[29].A3C结合策略梯度方法和值函数方法,使用演员-评论家架构,演员负责执行策略,评论家负责估计状态值或优势值,通过异步梯度更新的方式提高训练效率.DPG采用确定性策略梯度更新演员网络的参数.作为DPG的变体,DDPG是DPG的深度学习扩展,使用深度神经网络表示演员和评论家网络,同时还引入经验回放缓冲区稳定训练.在DDPG的基础上,TD3进一步引入两个延迟策略网络和两个延迟值网络,减少值函数的估计误差.此外,TD3还使用目标策略平滑化和双重延迟更新策略以提高训练稳定性.SAC是一种用于连续控制任务的算法,引入熵项,鼓励策略的探索性行为,增强机器人任务规划过程中的自主性和适应性.
总之,基于值的无模型强化学习算法通常适用于处理具有离散状态空间和离散动作空间的任务,而基于策略搜索的无模型强化学习算法和基于演员-评论家的无模型强化学习算法通常更适用于处理具有高维状态空间和连续动作空间的任务[30].同时,基于演员-评论家的无模型强化学习算法通常能够在性能和稳定性之间取得较好平衡,使机器人以高维感知信息作为输入进行任务规划变为可能,并可有效提高任务规划求解的成功率.
3.2 基于模型的强化学习算法
基于模型的强化学习算法是强化学习算法中的一类重要分支,用于解决传统无模型强化学习算法中数据采集效率较低的问题[31].在基于模型的强化学习算法中,模型代表智能体与环境交互的抽象表示,用于描述智能体与环境之间的互动方式.智能体首先建立模型,再利用模型模拟环境并生成模拟数据,用于策略的学习和改进.依据模型的构建方式,可将基于模型的强化学习算法进一步分为基于黑盒模型的强化学习算法和基于白盒模型的强化学习算法两类[6].
在基于黑盒模型的强化学习算法中,智能体通过与环境交互,不断从环境中采样数据,估计状态转移概率和奖励函数.模型的具体形式通常不可见,仅作为模拟数据的采样来源.Sutton等[32]提出Dyna-Q,智能体首先与环境直接交互,再将与环境直接交互时输入的状态和动作传入模型中进行Q-planning操作.在真实世界中每进行一步Q-learning操作,对应模型中就要进行多步Q-planning操作.基于该方式,智能体与真实世界的交互次数明显减少,从而提升强化学习过程中的样本效率.Dyna-Q在机器人领域的实际应用价值在于其能够基于模型进行模拟和规划,减少机器人与真实世界的直接交互次数,从而减少实验代价[33].Mayne[34]提出MPC(Mo-del Predictive Control),基于环境模型,使智能体在不学习的情况下,仅通过随机采样得到最优策略的方法.相比传统的强化学习,MPC可灵活调整以适应模型误差,所以,在无人机和机器人任务规划这类对环境扰动需要较高鲁棒性的领域中具有广泛应用[35-36].
在基于黑盒模型的强化学习算法中,不可避免地存在一个由环境模型带来的固有问题,即建立的环境模型与真实环境之间不完全一致.因此,从模型中训练的策略在价值方面可能与在真实环境中训练的策略具有一定差距,称为价值差距边界(Value Discrepancy Bound).这是在应用于真实世界中的实际机器人任务规划时,需要面对的一个较突出的问题.
Janner等[37]针对边界问题,提出MBPO(Mo- del-Based Policy Optimization),其核心是利用环境模型采样模拟轨迹数据,再将采集到的模拟轨迹数据传递到一个无模型的强化学习算法中进行训练,在提高数据采样效率的同时降低模型与真实环境之间的误差.Shen等[38]在现有的MBPO基础上进行改进,提出AMPO(Adaptation Augmented MBPO),采用加权采样策略,根据模型的不确定性以不同的概率采样模拟数据,减少在策略优化中不确定样本的比例.MBPO及其改进的系列算法有效缓解环境模型与真实世界之间固有差异导致的策略优化性能下降的问题,为基于模型的强化学习在机器人任务规划领域的实际应用提供更多的可行性.
在基于白盒模型的强化学习算法中,智能体了解环境的内部结构和数学表示,并可以直接访问模型中的状态转移概率和奖励函数等关键信息,将模型中价值函数对策略的参数进行求导,从而计算如何调整策略以最大化长期奖励,而不需要通过采样数据估计.
Deisenroth等[39]提出PILCO(Probabilistic Infe-rence for Learning Control),采用高斯过程(Gau-ssian Processes, GPs)对动态环境建模,利用闭合式策略评估,直接计算策略梯度的解析表达式,在连续状态空间中实现较高的数据效率,适用于基于物理系统的现实环境机器人任务规划.但PILCO仍存在对模型准确性要求较高的问题,机器人在面对复杂环境中的任务时,可能会因为模型的偏差影响策略性能,进而影响任务规划的成功率.Heess等[40]提出SVG(Stochastic Value Gradient),使用反向传播算法,支持连续控制问题[41]中的随机策略优化,但样本效率提升并不显著.目前SVG在机器人领域尤其是机器人任务规划领域中的实际应用较少,但由于SVG对于连续控制问题处理的良好性能,在机器人领域具有潜在的应用优势.另一方面,由于SVG的性能高度依赖于模型的准确性,仍然面临现实世界中对复杂环境准确建模的挑战.
在SVG的基础上,Clavera等[42]提出MAAC(Model-Augmented Actor-Critic),主要原理是利用学习到的环境模型等信息计算策略梯度,并采用终端值函数,防止在长时间步上的反向传播导致的不稳定性.MAAC显著降低样本复杂度,能高效学习策略,并在理论上得到验证.MAAC在机器人领域的实际应用优势在于能减少对真实机器人的样本需求,从而减少机器人与实际环境交互次数.然而,MAAC在实际应用时仍然需要面对模型误差、复杂环境建模困难等现实挑战.
总之,基于黑盒模型的强化学习算法适用于那些复杂度较高或无法精确建模的环境条件,但同时也会导致更多的交互数据和更慢的策略收敛速度.基于白盒模型的强化学习算法适用于那些复杂度较低或模型较明确的环境条件,在机器人任务规划的真实环境中,普遍面临精确建立真实世界模型的挑战.
3.3 分层强化学习
不同于仿真环境,将强化学习应用在现实机器人任务规划中时,往往会因为现实任务的粒度较大,从初始状态到目标状态的路径过长,使机器人在规划的中间过程中无法得到有效的奖励信号,导致训练过程中奖励信号微弱、稀疏,不利于机器人任务规划系统的长期决策.
分层强化学习旨在将一个长期的强化学习任务分解为子任务或子目标的层次结构,对于其中不同层次的问题,可采用强化学习或其它方法进行解决[14].
目前分层强化学习可分为2类:基于目标的分层强化学习和基于选项的分层强化学习[43].这两类算法在应用到机器人任务规划中时,均通过引入决策层将规划任务的控制决策模块化,同时上层利用下层策略执行结果反馈的内在奖励(Intrinsic Reward),缓解长期规划过程中存在的奖励稀疏问题.
Schaul等[44]提出UVFAs(Universal Value Func-tion Approximators),将强化学习中的值函数扩展到目标空间.Andrychowicz等[45]提出HER(Hindsight Experience Replay),在UVFAs的基础上,将实际训练过程中未达到目标状态的中间状态转移轨迹存放于经验缓冲池(Replay Buffer)中,并用于后续的训练,有效解决奖励稀疏的问题.
将HER改进并结合到机器人任务规划中的工作还有很多,Luo等[46]提出RHER(Relay HER),高效简洁,能有效解决机器人顺序操作物体等存在稀疏奖励困难的任务.Levy等[47]提出HAC(Hindsight Actor-Critic),以通用价值函数逼近器和事后经验回放为基础进行设计,假设在训练上层策略的过程中,下层策略已最优或次优,解决分层强化学习在策略训练过程中常出现的非平稳问题(Non-stationary).Kulkarni等[48]提出H-DQN(Hie- rarchical DeepQNetwork),上层策略和下层策略都以DQN为基础,并采用人工定义目标的方式,当下层策略完成上层控制器设定的目标时,反馈一个正的内部奖励.Vezhnevets等[49]基于RNN(Recurrent Neural Network),设计FuNs(Feudal Networks),相比H-DQN,FuN下层控制器的策略需要尽可能让隐含层特征朝目标表示的方向转移.Nachum等[50]提出HIRO(Hierarchical Reinforcement Learning with Off-Policy Correction),同样解决分层强化学习中存在的非平稳问题.
上述方法均以通用价值函数逼近器及事后经验回放技术为基础进行设计,通过将两种方法结合,能有效解决机器人任务规划过程中存在的策略训练困难的问题.
在基于选项的分层强化学习方法的早期研究中,有Parr等[51]提出的HAMs(Hierarchies of Abs-tract Machines)以及Dietterich等[52]提出的MAXQ等,这些方法普遍存在对下层控制器的奖励设计不合适的问题.Li等[53]提出HAAR(Hierarchical Rein-forcement Learning Approach with Advantage-Based Auxiliary Rewards),构建基于优势函数作为辅助奖励的框架,使低层技能的奖励不再来源于环境,而是由经过高层策略计算的优势函数取代.Bacon等[54]将Option框架与深度强化学习结合,提出Option- Critic Architecture,但由于对Option的切换过于频繁,导致运行效果和效率较低.Harb等[55]进一步提出A2OC(Asynchronous Advantage Option-Critic),在Option-Critic的中断函数策略更新中增加一个惩罚项,降低Option的切换频率.Tessler等[56]提出H-DRLN(Hierarchical Deep Reinforcement Learning Network),将分层理念与策略蒸馏、终身学习等方法结合,使系统能重用Skill,并将其从一项任务转移到另一项任务,有效地将规划策略转移到现实世界中的物理机器人,对于如何有效增强现实机器人任务规划的适应性和泛化性提供新思路.Konidaris等[57]同样采用分层思想,通过Skill Chaining主动学习Option[58]的数量.Eysenbach 等[59]提出DIAYN(Diversity Is All You Need),能够在给定的一个没有奖励的环境中,自适应地产生奖励函数,并主动探索有用的Skill,学习到状态与Skill的分布.
这类引入主动学习思想的方法能较好提升机器人利用自身决策系统主动从各种动态数据中学习的能力,从而减轻具有较大局限性的人工设计过程.
4 基于强化学习的机器人任务规划
强化学习和机器人领域之间存在紧密联系[60].强化学习为机器人任务规划的实际应用提供一种解决方案,可以使那些难以通过传统工程方法精确设计和编程的复杂行为规划得以更好实现,同时应对机器人任务规划领域面对的挑战也验证强化学习解决方案的可行性和有效性.机器人任务规划期望通过模仿高级动物的问题求解策略与智能行为[61],在不同的任务执行中协助甚至替代人类,因此,将学习能力整合到机器人系统中,是提升其智能水平的重要途径.
现今学者们越来越多地将强化学习技术应用于机器人学科,尤其是应用于机器人任务规划领域,其动机是让机器人能够自主学习如何在复杂任务中对其动作进行长期规划.本节分别介绍无模型强化学习、基于模型的强化学习和分层强化学习与机器人任务规划结合的重要进展.
4.1 基于无模型强化学习的机器人任务规划
无模型强化学习算法在难以精确建模的真实环境中应用优势明显.基于对初期大量交互数据的学习,机器人不断积累经验,性能会逐步提高,算法的渐进性优势也较明显[62],所以无模型强化学习算法在机器人中应用颇多.Ijspeert等[63]提出基于环境反馈调整的控制策略(Control Policy, CP),模仿人类动作,开发一款基于虚拟人形机器人的运动执行系统,并在二维图案绘制和网球挥杆等任务中进行实验验证.Wang等[64]尝试将Q-learning从单智能体推广到多智能体中,提出TeamQ-learning,并证明该算法可以收敛到最优策略,同时在其开发的分布式多机器人系统中,模拟完成简单环境下的多机器人推箱子任务.
Peters等[65]利用基于随机策略梯度的强化学习框架,经过200~300次训练尝试,使用Sarcos机械臂实现打棒球的简单任务规划.Konidaris等[66]利用价值函数隐式表示机器人各种技能的相应策略,从演示轨迹中构建技能树并应用于任务规划,利用uBot-5移动机械手[67],在仅学习单个轨迹演示后便可完成接近目标点并推开门等基于轨迹演示的任务.
近年来,无模型强化学习算法多应用于诸如开门、对象堆叠、装配和抓取等基于低维本体感知信息的任务规划中.Gu等[68]将基于Q函数的离线策略训练(Off-Policy)扩展到复杂的3D环境中,用于学习实现复杂开门任务,并在真实世界中利用7自由度机械臂,在不到500 000个更新步骤(对应约2.5 h训练时间)中实现任务规划100%的成功率.Haar-noja等[69]提出SoftQ-learning,用于现实世界的物体堆叠任务,并在实验中证实从头开始训练一个Sawyer机器人将乐高积木堆叠在一起,只需要不到2 h的时间,并且Sawyer机器人学习到的策略对干扰具有较强的鲁棒性.Li等[70]将基于Off-Policy的DDPG扩展到较复杂的机器人装配任务场景中,并额外引入基于关节限制的安全约束,成功使机器人在无先验知识的情况下正确学习各种装配技能,从而能安全正确地完成装配任务.Liu等[71]设计基于优先级的经验回放池和重要性采样策略,改进DDPG,改善传统深度强化学习算法在机器人机械臂抓取任务中遇到的稀疏奖励和收敛速度慢等问题.
上述方法通常基于Q-learning或DDPG的Off-Policy.Off-Policy通常需要在不同策略之间进行权衡和重要性采样,仍会导致相对较慢的学习速度.在不同的环境下,如果收集的样本数据分布发生明显变化时,算法的不稳定性会加剧,进而影响机器人任务规划的适应性.但如果基于经验回放缓冲区,Off-Policy通常需要更少的样本数量和更高的样本效率.相比之下,基于On-Policy的策略搜索算法,如NPG、PPO 和TRPO等,需要更多的样本数量,样本利用率也更低.但对于基于On-Policy的强化学习算法而言,需要更多样本数量的需求带来易用性和稳定性的提升,以及对次优超参数设置的鲁棒性的优化[72].
基于On-Policy的策略梯度算法已用于现实世界的机器人,进行诸如钉子插入(60%的平均成功率)[73]、定向投掷(基于PR2的7自由度机械臂)[74]和日常手部操作(从零开始学习阀门旋转7.4 h、翻箱子4.1 h和复杂开门操作15.6 h后,任务规划策略达到100%的平均成功率)[75]等任务.
机器人以高维图像信息作为感知输入进行任务规划,是机器人要面对的较重要也较困难的问题.无模型强化学习算法可应用于基于图像定义的任务,无需明确表示学习阶段或预先定义的环境模型.同时,随着无模型强化学习算法在效率和稳定性方面的提高,已逐步实现从原始高维图像观测中学习.Singh等[76]基于VICE(Variational Inverse Control with Events)和RAQ(Reinforcement Learning with Ac- tive Queries),提出VICE-RAQ,可仅从高维图像观测中学习,而无需手动设计奖励函数,并成功应用于实际机器人中,实现物体排列和书籍放置等任务,10次实验的平均成功率达到100%.Schoettler等[77]使用基于SAC或TD3的无模型强化学习算法,并结合先验信息,通过视觉输入(高维图像信息)感知环境信息和目标任务,在机器人中成功实现插入连接器等工业插入任务.Schwab等[78]采用SAC-X(Sche-duled Auxiliary Control),并在训练时使用扩展的观测数据集,包括原始传感器数据(如图像)、本体特征(如关节角度)和通过对象跟踪系统提供的辅助特征,在具有7自由度的Sawyer机械臂上同时学习基于特征的规划策略和基于视觉输入的策略,并成功完成“Ball-in-a-Cup”任务.
上述实验都是在非开放的实验室中设计和实现的,所以可能会存在机器人对现实视觉扰动的鲁棒性问题,并且目标局限于实验人员设计的特定任务和对象,任务规划的泛化性有待验证.
4.2 基于模型的强化学习的机器人任务规划
因为需要对环境精确建模,而这通常在实际应用中较困难,所以相比无模型强化学习算法,基于模型的强化学习算法在机器人任务规划领域应用较少.但是,基于模型的强化学习算法可以使机器人充分利用模型生成大量虚拟样本,大幅减少与实际环境交互所需的代价,有效降低机器人与实际环境交互过程中产生的机械损耗和安全风险[79],这对于实际环境中的机器人任务规划具有现实意义.所以,基于模型的强化学习的应用为机器人任务规划领域带来积极的进展.
Deisenroth等[80]利用PILCO的数据效率和对模型误差的考虑,在机器人实验中将状态空间约束纳入考虑,成功地在较短时间内让Lynxmotion的低成本机械臂完成物体堆叠任务.Lowrey等[81]提出POLO(Plan Online and Learn Offline),结合轨迹优化和价值函数学习,利用价值函数作为内在奖励指导基于MPC的探索行为,在虚拟环境下机器人重新定位立方体的任务中取得不错效果.对于腿式机器人来说,其腿部的快速稳定运动是进行一系列任务规划的基础,这就需要具备准确的动力学模型和高频率的控制动作.
Jin等[82]提出IRRL(Imitation-Relaxation Rein- forcement Learning),通过两步训练分阶段优化目标,从而消除非理想参考轨迹以适应特定的机器人动力学,同时使用熵稳定性分析,评估系统的稳定性,并在MIT-MiniCheetah类机器人中得到验证.
相比基于低维感知的状态信息,基于高维图像输入的模型通常在机器人任务规划中的应用更灵活,但对于高维数据的处理和非线性动力学模型的建立通常具有一定难度.借助深度神经网络等方法可有效面对以上挑战,加上基于模型的强化学习固有的高样本效率,使其更适合具有高维图像输入的机器人任务规划.
Finn等[83]提出预测视频中像素运动的模型,能推广到未观测到的物体.该方法关注前后两帧图像之间的变化,并结合之前帧中的背景信息,学习基于图像的环境动力学模型,进行下一帧图像的预测,同时,方法还结合规划算法,应用在真实机器人的任务规划中.Zhang等[84]提出SOLAR(Stochastic Opti- mal Control with Latent Representations),结合深度神经网络和概率图模型,构建更精确的动力学模型,并在实验中利用Baxter双臂协同机器人,在较短的时间内完成基于高维图像输入的积木堆叠和物体移动任务.Nair等[85]基于变分自编码器(Variational Autoencoder, VAE)学习一个潜在变量模型,可从高维的原始数据(如图像)中学习一个低维的潜在表示,用于更新目标状态,生成具有一定泛化性的机器人决策能力.
相比无模型强化学习算法,基于模型的强化学习算法在基于高维图像的任务中需要的试验次数明显降低[72].由于基于模型的强化学习算法在样本效率方面存在明显优势,其在处理具有高维感官输入的任务中具有较广泛的应用,包括基于PR2机器人平台进行指定位置的积木堆叠、物品插入指定的容器和拧瓶盖[86]等任务.
4.3 基于分层强化学习的机器人任务规划
相比基于模型的强化学习算法和无模型强化学习算法应用于机器人任务规划的研究,直接将现有的分层强化学习作为机器人任务规划解决方案的研究较少.现有的分层强化学习算法大多基于已有的仿真环境或游戏环境为场景,验证分层强化学习算法的性能,再结合应用到实体机器人的任务规划过程中.
现实机器人任务具有更多的不确定性和更高的复杂度,分层思想结合强化学习可将任务分解为合理的子任务,并允许机器人在不同层次上进行决策和规划,这更有助于解决复杂问题并提高任务规划的效率和性能.因此,分层强化学习求解问题的层次表征性质和能够处理多层次决策问题的能力,使其在应用于复杂机器人任务规划时更具潜力.
Yang等[87]采用基于选项的分层强化学习方法,在Option框架[43]的基础上,提出UOF(Univer-sal Option Framework),在机器人仿真平台中,利用机械臂解决物块堆叠、零件拆卸组装等典型机器人作业任务.在Option框架中,高层次的策略通过规划Option实现需要完成的任务,而低层次的Option在一段时间内执行低层次的动作以实现不同的子任务.UOF将低层次的规划和高层次的规划都拓展到以目标为导向,使高层次Option能够在低层次的Option中选择,同时赋予其目标,而高层次策略可用于规划不同的任务.Chen等[88]在重叠分层强化学习的基础上,提出交叉重叠分层强化学习方法,即通过交叉学习机器人的关节动作参数,使机器人在完成任务的过程中能获得更好的动作执行,并验证使用交叉重叠分层强化学习系统的机器人具有更快的运动速度和更平滑的行走切换等优势.
相比基于选项的分层强化算法在机器人任务规划中的应用,将HER框架应用到机器人任务规划过程中,能更有效地提升机器人策略的训练效率以及样本的利用率.Eysenbach等[89]基于HER框架,提出SoRB(Search on the Replay Buffer),结合规划算法与强化学习,利用各自的优势,完成机器人在复杂的室内环境导航等任务.Gieselmann等[90]扩展SoRB,提出PAHRL(Planning-Augmented Hierar-chical Reinforcement Learning),结合分层强化学习和任务规划,在PyBullet[91]中完成具有七自由度的机械臂关节控制以及一种具有可形变性质的流体机器人控制等任务,并且能解决具有隐式定义目标的任务规划问题.
Zhao等[92]提出HCS-R-HER,通过跨子任务重用经验数据加速学习.其中,上层元控制器负责生成目标序列,下层控制器负责执行原子操作.HCS-R- HER在设置的连续机械臂任务以及特殊的连续体机器人任务中,取得比HER等更高的成功率.Sanchez等[93]结合HER与DDPG,解决机械手在复杂的操作任务中训练困难的问题,并在仿真环境中,利用机械手进行复杂的3D旋转任务,取得较高的成功率.
Luo等[46]在HER的基础上,提出RHER,将顺序任务分解为几个复杂度逐渐增加的子任务,允许智能体按照复杂程度逐步学习以最终完成任务.同时,设计SGES(Self-Guided Exploration Stra-tegy),将已学习到的简单子任务策略指导更复杂子任务的探索,使智能体能够突破稀疏奖励的障碍,并逐阶段实现高效学习.RHER在MuJoCo[94]这类主流的强化学习仿真环境中,利用机械臂完成打开抽屉、多物块顺序堆叠等复杂任务,验证RHER能以较少的交互次数,较快地达到指定的95%成功率.
此外,针对现实世界机器人在任务规划过程中需要考虑人类在任务场景中的影响导致场景动态变化的情况, Liu等[95]结合人流感知、分层强化学习和自动化任务规划的思想,提出HA-GHDQ(Hu-man-Flow-Aware Guided Hierarchical Dyna-Q).HA- GHDQ由三个主要部分组成:分层强化学习器、环境模型和自动任务规划器.结合符号规划和分层强化学习,使用MoDs(Maps of Dynamics)中编码的人体运动模式进行机器人任务规划.在工厂环境中,使用两个模拟数据集和一个真实数据集评估HA-GHDQ,测试机器人在人类活动的场景中完成对运输和组装任务的规划性能.Yuan等[96]提出HDMP(Hierarchical Dynamic Movement Primitive),实现机器人的平滑运动任务.在HDMP中,下层结构将修改后的动态运动基元用于生成平滑的运动轨迹,同时在上层策略学习层次中通过L-PPO(Local Proximal Policy Optimization)赋予机器人自主学习能力.
这些研究工作为分层强化学习算法在机器人任务规划领域的应用提供重要参考,展现分层强化学习算法在处理现实世界中机器人任务规划的新思路.不同于基于模型的强化学习算法使智能体在模拟环境中进行学习和规划,以及无模型强化学习算法采用智能体直接与真实环境的交互以学习,分层强化学习算法的研究主要集中在对复杂任务的层次化分解,增强机器人对更复杂的任务规划问题的解决能力.
5 结束语
本文分析讨论强化学习及其在机器人任务规划中的研究进展.介绍机器人任务规划和强化学习,讨论并说明它们之间的联系.随后,重点关注强化学习在机器人任务规划领域的研究进展,并分析这些方法应用的优势和局限性.
当前的研究进展表明,强化学习适用于机器人系统,可有效解决复杂的现实世界中机器人任务规划问题.同时,强化学习在机器人任务规划领域的研究仍面临着如下挑战.
1)如何有效平衡机器人在学习过程中的探索和利用.探索与利用是矛盾的.探索通过搜集更多信息而获得较长期准确的利益估计,利用侧重于根据已掌握的信息使短期利益最大化.过多的探索行为将牺牲短期利益,进而导致整体利益受损;过多的利用行为会导致看重短期利益而忽视一些可能带来长远收益的行为.该问题是强化学习领域普遍关注的问题,其有效程度将直接影响机器人学习和决策的效率.
2)如何有效提升机器人在连续动作空间中的规划性能.用于强化学习的机器人离散化行为空间应用广泛,机器人相对更容易实现学习和问题求解.但是行为空间的离散化限制机器人的能力和表现,并且会导致不连续甚至突兀的行为动作,降低任务规划方案在真实的作业场景中的有效性.
3)如何有效应对现实世界中存在的诸多不确定性因素.现实世界是动态、复杂的,存在诸多不确定性因素,包括传感器噪声、光线变化、温湿度变化等.机器人是面向真实业务场景的,如果缺乏对这些实际动态约束条件的考虑,无法将学术研究中构建的解决方案应用于机器人实际应用中.
4)如何有效提升端到端策略有限的泛化能力.目前较多的研究关注于强化学习与卷积神经网络等机器学习方法结合,设计端到端的解决方案.该方案可实现输入机器人的视觉感知信息和其它传感器信息,输出对于机器人或智能体的控制信息,但是并不适合机器人面临的机载能源有限和算力有限的现实情况,而且其泛化能力有待提升.
5)如何缩小真实环境与模型之间的误差.环境模型是MBRL重要的组成部分,但是因为模型存在与真实环境的误差,导致学习效果和性能的下降.目前针对虚拟环境的建模已取得较好进展,但是机器人通常面对真实复杂环境,对环境建模的要求更高,因此针对真实环境建模能力的提升仍是目前面临的重要问题.
6)如何更好地将虚拟环境中训练得到的模型和策略应用到真实世界中.在机器人领域开展强化学习应用,考虑到安全、成本和采样效率等因素,可采用虚拟环境建模和真实环境应用结合的方式,提升强化学习的应用效果.这种折衷的方案带来一个新的问题,即如何保证虚拟环境中训练得到的模型和策略能有效应用到真实世界.
7)如何提升强化学习算法的渐进性能.基于模型的强化学习利用学习构建的环境模型开展规划或策略优化,具有较高的样本效率,但是相比MFRL,渐进性能明显较低.如何有效提升MBRL的渐进性能,是目前面临的重要问题之一.
8)如何应对基于模型的强化学习固有的不稳定问题.相比MFRL,环境模型具有一定的复杂性,导致MBRL通常具有更复杂的结构和更多的超参数,带来计算代价的提升,导致计算量增大、稳定性降低.在保持性能的同时,优化和简化算法设计,将有助于减少强化学习的不稳定性.
9)如何构建稳定的层级表征和精确的预测以支撑机器人层级化的心智模拟.针对小样本问题求解,通常采用迁移学习,但不会利用决策规划发挥层级化心智模拟的优势.心智模拟可提升采样效率,但在强化学习中使用层级化的心智模拟开展的研究较少,其主要原因是高层级的前向模型在开始训练时,低层级的策略已收敛,需要构建稳定的层级表征和精确的预测进行支撑.
10)如何有效提升内在动机对不确定性的应对能力.内在动机对生物智能体的智能行为非常重要,需要模型具有良好的不确定性应对能力.当前基于预测的内在动机模型对有噪声的信号和混沌不可预测的动态系统等不确定性因素的处理过于简单,导致不确定性应对能力有限,并会干扰层级化表征的学习,无法应对高层级表征的不确定性.
11)如何构建不同层级推断所需的抽象水平.在认知科学中,通常不同的抽象层级具有该层级推断需要的抽象水平.例如:高层级的推断只需要知道物体是否能够被抓取,低层级的推断需要获得物体形状等细节信息.适配推断的状态抽象需要强化学习信号,目前强化学习的奖励信号对学习过程的推动作用相对较弱.
上述针对强化学习应用在机器人领域中存在的关键问题的总结具有不同的侧重点,其中1)~4)是针对无模型强化学习算法目前面临的主要问题与挑战,5)~8)是针对基于模型的强化学习算法目前面临的主要问题与挑战,9)~11)是针对目前分层强化学习算法与智能问题求解面临的主要问题与挑战.
基于上述对于当前存在问题的分析,针对机器人任务规划研究面临的具体挑战还包括:
1)如何对多模态的机器人感知与状态信息进行更有效的分析处理,以更好地支撑任务规划.
2)在复杂的非结构化的实际环境中,如何基于强化学习进一步提升机器人任务规划的适应性与鲁棒性.
3)如何使强化学习在机器人任务规划的应用中具有可解释性.
针对上述的研究问题与挑战,对未来基于强化学习的机器人任务规划的部分研究方向进行展望.
1)复杂任务层次结构的合理表征[97].机器人学习到的表征捕获观察的基本知识,所以当表征被作为模块化信息进行分享时,可能实现机器人对不同抽象任务的成功规划和对变化环境的高适应性.有许多研究致力于将一个抽象任务逐步分解为多个元动作的组合,但机器人的元动作特征是与机器人的感知和驱动紧密联系的[98].为了使机器人具有更好的适应性,可合理构建对复杂任务分解的粒度[99],以实现任务层次结构的合理表征.
2)基于多模态信息的表征学习.对于真实环境的准确感知是机器人任务规划的基础,以往的大多数研究都是基于机器人的某一类感知信息,但事实上,人类行为的规划过程是基于多模态信息综合感知的[100],包括但不限于触觉、嗅觉、听觉和视觉等信息.所以,添加基于多模态信息的表示,同时利用深度强化学习对输入信息进行更准确的处理,会使机器人具有更全面的感知能力,这是机器人在任务规划过程中应对部分可观测环境的重要手段.
3)结合领域知识增强机器人任务规划的可解释性.与强化学习经典的模拟训练环境不同,在真实世界中,机器人任务规划结果的可靠性直接决定环境的安全性.基于深度学习的这类“黑盒”模型不能提供可靠且具有解释性的决策结果.因此,对于工作于特定领域的机器人,利用领域知识图谱等技术作为可解释性策略[101]辅助并指导强化学习的学习过程,是增强机器人任务规划可解释性的可行途径.
猜你喜欢
工程与建设(2019年2期)2019-09-02
动漫星空(兴趣百科)(2018年4期)2018-10-26
领导决策信息(2018年50期)2018-02-22
中学生数理化·八年级物理人教版(2017年3期)2017-11-09
商周刊(2017年5期)2017-08-22
中国卫生(2016年2期)2016-11-12
中国工程咨询(2016年4期)2016-02-14
少儿科学周刊·少年版(2015年4期)2015-07-07
少儿科学周刊·少年版(2015年4期)2015-07-07
少儿科学周刊·少年版(2015年4期)2015-07-07
