
改进Res2Net的多尺度端到端说话人识别系统
2023-12-27 14:53:02邓力洪张葛祥
计算机工程与应用 2023年24期
邓力洪,邓 飞,张葛祥,杨 强
1.成都理工大学 计算机与网络安全学院(牛津布鲁克斯学院),成都 610059
2.成都理工大学 人工智能研究中心,成都 610059
3.成都信息工程大学 控制工程学院,成都 610059
说话人识别任务旨在从音频中获取身份信息识别说话人[1]。随着语音指令的广泛使用,语音验证成为保护用户安全和隐私的必要安全措施。然而实际情况中,录音的环境可能是嘈杂的如包含音乐、笑声、聊天背景声等,并且说话人本身的因素如口音、情感、语调和说话方式也会带来影响,导致部分音频可能不包含说话人身份的鉴别信息,不能得到有效的、具有甄别性的特征。因此说话人识别应用于实际生活仍是一个非常困难的任务。如何构建一种轻量的、可以从变长的音频中提取出具有甄别性的特征的说话人识别系统,是将说话人识别应用于实际的关键[2]。
在深度学习兴起之前,传统带有概率线性判断分析(PLDA)的i-vector 系统一直处于领先地位是说话人识别的主要方法[3-4]。但随着深度学习的发展,深度神经网络(DNN)给语音识别领域带来了实质性的改进。相比于传统的i-vector 系统,DNN 架构可以通过特征提取器(深度神经网络)直接处理噪声数据集进行训练端到端的训练[5-7]。基于DNN的说话人识别系统已经取得了优于i-vector 系统的性能,并以优异的特征提取能力占据了主导地位。
在说话人识别系统中,构建一个有效的特征提取器(深度神经网络)是准确识别说话人的关键因素。基于CNN的特征提取器由于具有更强的特征提取能力被广泛地用作为说话人识别系统的骨干神经网络。基于二维卷积的ResNet 通过向CNN 中引入残差连接,可以在基本维度(深度和宽度)进行设计以控制模型容纳训练数据量的表示能力,并在各种任务中都表现出优异的性能,是当前最流行的特征提取器。然而,轻量的卷积神经网络特征提取能力非常弱,不能获取具有区别性的帧级特征,导致系统的识别准确率低无法应用于实际生活。因此,为了获得更强的特征提取能力来进一步提升系统性能,目前许多方法都采用了更深、更宽、更复杂的网络结构。如2019 年Zeinali 等人[8]构建了256 层残差网络的说话人识别系统,2020年Jung等人[9]提出了直接使用原始音频的信号作为输入的RawNet,2021年Wang等人[10]提出了将CNN与Transform相结合为说话人识别系统。在说话人识别任务中,训练和测试条件往往是不匹配的,单纯增加网络的深度和宽度容易出现过拟合,从而削弱整个网络的泛化能力。更深、更宽、更复杂的网络结构也导致模型的参数量和计算资源大幅增加。因此,构建一种轻量的、特征提取能力强的卷积神经网络是将说话人识别系统应用于实际的关键。
卷积神经网络也并非完美无缺,卷积运算是采用固定大小的卷积核来捕获音频的时间和频率信息,而卷积核的大小限制了语音特征的接受域,因此卷积神经网络的特征提取能力也受到了限制,不能捕获特征的全局信息。近年来,随着注意力机制在计算机视觉任务中表现出优秀的性能,它也逐渐被引入到说话人识别领域,并应用到说话人识别系统中。注意力机制有效地改善了卷积神经网络只能提取局部特征无法捕捉全局特征的缺点,增强了卷积神经网络的特征提取能力和泛化能力。它只会增加极少量的参数,却可以明显地提升系统性能。Zhou等人[11]在ResNet中采用了压缩激活注意力(squeeze-and-excitation attention,SE)来增强特征提取能力,这是说话人识别任务首次引入注意力。SE注意力能够捕获通道之间的依赖关系并突出更重要的通道特征[12]。受到将计算机视觉中的卷积注意力模块(convolutional block attention module,CBAM)[13]的启发Sarthak等人[14]提出了tf-CBAM注意力,对特征的时间维度和频率维度进行强调。虽然这些注意力方法都增强了神经网络的特征提取能力,但都只通过使用池化操作进行了简单的注意力学习强调了单一的特征维度忽略了其他特征维度,以及时间-频率-通道维度的相互作用。同时,池化操作也使得特征丢失了其中的说话人身份信息。
基于上述问题,本文将目标检测任务中的Res2Net引入到说话人识别任务中,验证了它在说话人识别任务中的有效性和鲁棒性[15]。不同于目前大多数方法只能利用更深更宽的网络结构来提升特征提取能力,Res2Net采用了一种并行分支网络结构来增大感受野范围,从而在不增加计算复杂度,拥有更少参数量的情况下获得了更好的识别效果。然而,Res2Net 的网络结构只能获取固定大小的感受野,不能获取更大范围的感受野,这也限制了其特征提取能力的提升。因此,本文在Res2Net的基础上改进提出FullRes2Net,相比于Res2Net它能够产生更大的感受野,从而获取更强的特征提取能力,可以应对更加复杂的声学环境和识别任务。在几乎没有增加参数量的情况下,性能提升了17%。为了解决现有注意力方法存在的问题,更有效地提升卷积神经网络的特征提取能力。本文提出了一种应用于说话人识别任务的注意力方法,混合时频通道注意力(mixed timefrequency channel attention,MTFC)。它可以对音频特征的时间、频率、通道维度进行交互,捕捉特征间的依赖,得到更多的注意信息和全局信息,从而有效增强卷积神经网络的特征提取能力。为了证明所提出方法的有效性,本文分别进行了不同的消融实验,验证了Full-Res2Net 和混合时频通道注意力的有效性。同时,本文所构建的基于混合时频通道注意力和FullRes2Net的端到端说话人识别系统,也在多种实验设置中表现出明显优于目前先进说话人识别系统的性能。
这项工作的主要贡献总结如下:
(1)本文将计算机视觉目标检测任务中的Res2Net引入到说话人识别中,验证了它在说话人识别任务中的有效性和鲁棒性。它通过采用一种并行分支网络结构来提升特征提取能力,但参数量更少。
(2)本文基于Res2Net改进提出了FullRes2Net。相比于Res2Net,它拥有更大更多的感受野组合。在参数量几乎没有增加的情况下,拥有更强的多尺度特征提取能力。
(3)本文提出了混合时频通道注意力。它可以在特征的时间、频率、通道维度进行交互,更有效地增强卷积神经网络的特征提取能力。
(4)本文将FullRes2Net 和混合时频通道注意力应用于说话人识别系统,构建了基于混合时频通道注意力和FullRes2Net 的端到端说话人识别系统,并在不同的场景下进行了实验。实验结果表明该算法的优越性,是一种参数量更少、效率更高的端到端结构,适合在现实场景中的应用。
1 基于MTFC-FullRes2Net的端到端说话人识别系统
通常说话人识别任务可以分为闭集和开集。对于闭集,所有测试说话人身份都被登记在训练集中即测试集是训练集的子集,将测试话语分类是比较容易的。因此闭集可以很好地解决说话人分类问题。而在开集中,测试集中的说话人和训练集中的说话人是相互独立的,这使得说话人识别更具有挑战性,也更接近实践。由于不可能将测试集中的语音分类为训练集中的已知的身份,需要将说话人特征映射到一个判别空间。在这种情况下,开集验证的本质是一个度量学习问题,其中的关键是学习到有区别的特征向量。
传统i-vector说话人识别系统中每个步骤都是在子任务上独立训练的,不是联合优化的。另外的一些基于DNN的说话人识别系统中需要额外的步骤来聚合帧级特征并执行验证。本文将所有子任务整合到一起,实现闭集和开集的统一端到端系统,如图1所示。其中任何类型的深度卷积网络都可以作为特征提取器,如VGG、ResNet等。而本文改进提出的FullRes2Net拥有更少的参数量更强的特征提取能力和更快的推理时间,因此使用FullRes2Net作为特征提取器的骨干网络。它可以在更细粒的层次上获得多种感受野的组合,从而获得多种不同尺度组合的特征表达,产生说话人身份信息更丰富、更全面、更具区别性的帧级特征。同时,为了强调特征信息,捕捉特征间的依赖,获取全局信息增强卷积神经网络的特征提取能力。本文构建了混合时频通道注意力(MTFC)。混合时频通道注意力能够插入任何地方,它可以增强网络的特征表达能力。但基于注意力的卷积表明,并行化卷积层和注意力模块是更有效地处理短期和长期依赖的结构。因此,本文将混合时频通道注意力嵌入到FullRes2Net之中。
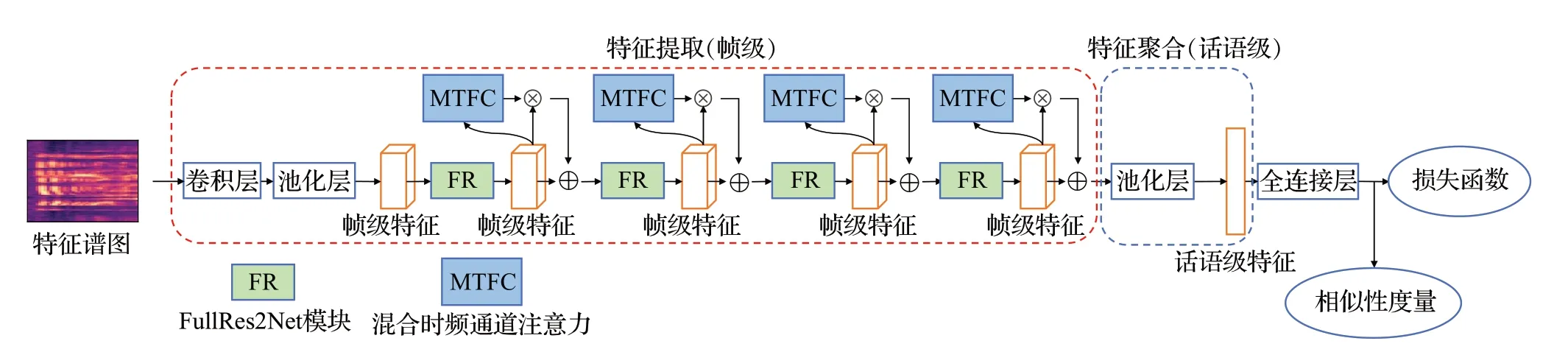
图1 端到端说话人识别系统结构Fig.1 End-to-end speaker recognition system structure
基于混合时频通道注意力和FullRes2Net的端到端说话人识别系统由四部分组成:(1)特征提取网络,使用嵌入混合时频通道注意力的FullRes2Net提取出更具区别性的帧级特征;(2)特征聚合,通过自适应平均池化将变长的帧级特征聚合为固定维度的话语级特征;(3)说话人识别损失函数,在训练时采用AM-softmax Loss以更准确地对说话人进行分类;(4)相似性度量,在训练完成后用于进行说话人识别,通过计算一对话语级特征的距离以判断这对音频是否来自同一说话人。
1.1 Res2Net
Res2Net 是一种应用于目标检测中的网络结构,旨在通过增加感受野的大小来提高卷积神经网络的特征提取能力。Res2Net 是ResNet 的一种变体,它在继承ResNet 优点的同时也有新的特性。采用了一种并行分支网络结构,并通过类似于层残差的方式连接更小的卷积算子来实现。层残差的连接方式使得Res2Net 拥有比ResNet更大的感受野和更多的感受野组合。而并行分支结构则使得Res2Net的参数量比ResNet更少。图2展示了ResNet残差块与Res2Net残差块的比较,其中⊕表示加法运算。

图2 ResNet残差块与Res2Net残差块Fig.2 ResNet residual block and Res2Net residual block
在ResNet残差块中,特征经过卷积核大小为1×1的卷积过后,接着进行一组卷积核大小为3×3的卷积。而在Res2Net模块中,特征x∈RT×F×C在经过卷积核大小为1×1 的卷积后被切分成s个特征子集xi∈RT×F×w,每个特征子集有w个通道(C=s×w)。因此,Res2Net的参数量也比ResNet 更少。在切分操作之后,每个特征子集xi(i∈{1,2,…,s})都有与之相对应的一组3×3卷积记为Ci,输出yi表示如公式(1)所示:
在图2(b)所示的Res2Net 模块中,当Ci接收到前特征子集yi-1时,前一个特征子集相当于连续经过了Ci和Ci-1的卷积运算。因此,使得当前特征子集拥有更大的感受野,获得了多种感受野大小的组合。更大的感受野可以看到更多的相关音频以及进行更好的上下文分析。而不同的感受野组合则可以对特征局部细节进行丰富。从而产生了更准确、有效的特征,如公式(2)所示。最后,将所有的yi拼接起来作为输出特征y。
1.2 FullRes2Net
然而,Res2Net 的网络结构只能获取固定大小的感受野组合,不能获取更大的感受野范围,这也限制了它特征提取能力的提升。因此,本文改进提出了FullRes2Net,结构如图3所示。
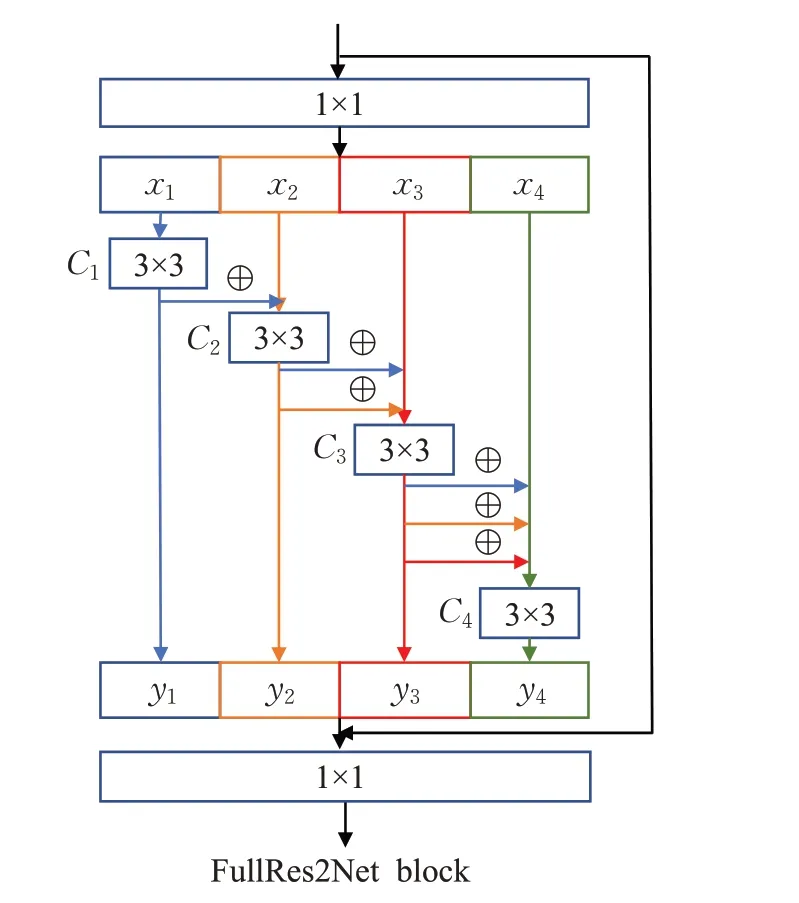
图3 FullRes2Net blcok结构Fig.3 FullRes2Net block structure
与Res2Net不同的是,FullRes2Net的并行分支中每个特征子集都会融合之前所有特征子集的输出再由自身的卷积算子进行卷积同时传给后面的特征子集。最后,再将所有的yi拼接起来作为输出特征y,如公式(3)所示。通过这种方式,每个特征子集都会收到前面所有特征子集的输出,使之前的每个特征子集的感受野不断增大,从而可以提供更多特征中的说话人身份信息,也获得了更多的、更大的感受野组合,如公式(4)所示。因此,相比于Res2Net,FullRes2Net 可以得到更多、更丰富的特征细节信息,更充分地挖掘音频特征中的说话人身份信息。FullRes2Net 也并没有引入卷积运算来增加网络的深度与宽度,因此它只增加了一些推理时间。
如公式(5)所示它代表感受野的计算方式,其中RFi表示第i层的感受野,ki是第i层的卷积核大小,sj表示第j层的卷积步长。假设经过1×1 的卷积运算后感受野为1,卷积步长为1,可以根据公式推导出Res2Net、FullRes2Net中不同并行分支上的感受野大小,如公式(6)和公式(7)所示。从公式中可以明显看出FullRes2Net拥有比Res2Net 更多、更大的感受野组合,这也使得FullRes2Net拥有比Res2Net更强的特征提取能力,可以应对更复杂的声学环境和说话人识别任务。
1.3 混合时频通道注意力
虽然FullRes2Net 拥有更强的特征表达能力,但依然不能克服卷积运算本身存在的缺陷。同时,也为了解决目前注意力方法存在的问题。本文设计了一种混合时频通道注意力(MTFC)。混合时频通道注意模块可以将时频信息和通道信息相互整合,从而分别产生相应的时频注意和通道注意。MTFC 注意力机制旨在关注时频特征和通道特征中的重要区域,并从中获取特征之间的依赖,得到取更多的注意信息,使得网络能够提取出判别性更强的帧级特征。
如图4 所示,MTFC 注意力机制包含了两种注意模块,在特征提取器输出的局部特征上捕捉特征之间的依赖性,绘制全局特征从而获得更好的特征表示。使用x作为输入特征,然后将这些特征送入时频注意模块和通道注意模块分别产生一个二维时频注意权重和一个与输入特征同大小的全局特征。分别采用不同的方式进行加权,时频注意通过乘法进行加权,它具有全局信息能突出时频信息中更重要的区域。而通道注意通过求和进行加权,它模拟了特征映射之间的长期依赖关系,有助于提高特征判别性。因此总的注意过程可以概括为:
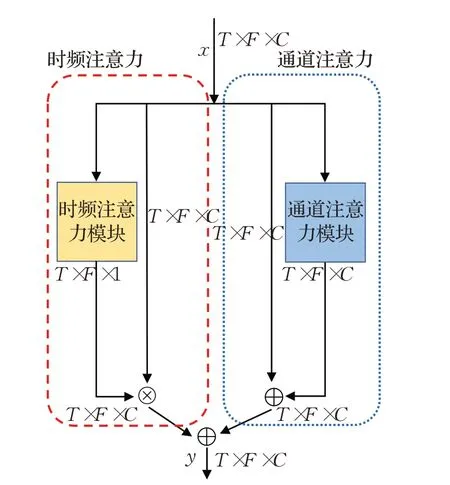
图4 混合时频通道注意力Fig.4 Mixed time-frequency channel attention
其中,MC表示通道注意模块,MTF表示时频注意模块。⊗表示乘法,⊕表示加法。在整个过程中,通道注意沿着时频维度进行传播,而时频注意沿着通道进行传播,y是最终的输出结果。下面介绍每个注意模块的详细信息。
(1)时频注意力
在计算机视觉中基于注意力的方法在建模空间关系方面尤其有前景,注意力机制使模型能够在识别过程中关注关键特征并抑制不重要的特征,捕捉特征的全局关系,从而增强卷积神经网络的特征表达能力。同样,注意力的方法也可以应用于时频域的建模。利用特征间的时频关系生成时频权重矩阵,权重矩阵的权重大小与相应位置的频率成正相关。为了使学习的卷积层更有竞争力,本文采用softmax 函数生成相应的权重矩阵而不是sigmod,因为softmax 函数鼓励不同的卷积层学习不同的特征,从而使模型更健壮[16]。根据生成的权重矩阵再重新调整原始特征图上的激活幅度。通过这种方式,同一时频位置的特征按相同的权重进行缩放,不同时频位置的特征按照不同权重进行缩放。
如图5 所示,给定一个特征输入x∈RT×F×C,特征x经过1×1的卷积操作后得到一个T×F大小的二维矩阵A。采用1×1 的卷积进可以行通道信息的交互和降维同时也增加了卷积神经网络的非线性[17]。然后对矩阵A使用softmax函数,为每个位置分配一个值表示该位置的重要性w(i,j),w∈RT×F。产生的权重矩阵再与原始输入特征x相乘重新调整激活幅度,输出特征x′∈RT×F×C。公式如下:
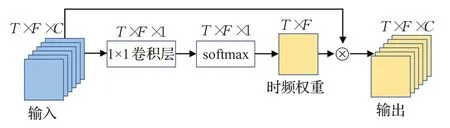
图5 时频注意力模块Fig.5 Time-frequency attention module
其中,Ws∈R1×1×C表示1×1的卷积。
(2)通道注意力
整个模块可以分为三部分:(1)背景建模,采用1×1的卷积后通过softmax 函数产生权重值,再加权映射得到全局特征。(2)特征变换,使用1×1的卷积进行特征变换,捕获通道依赖以及减少模型的参数量。(3)特征融合,采用加法的方式直接将全局特征融合到原始特征之中,如图6所示。
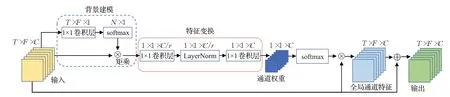
图6 通道注意力模块Fig.6 Channel attention module
使用x∈RT×F×C表示输入特征,为了能够充分利用时频信息,同样采用1×1的卷积进行通道信息的交互和降维[17],得到特征h∈RT×F×1,再使用softmax函数产生全局权重w∈RN×1(N=T×F),全局权重w与x相矩乘生成全局特征。这种方法将时频信息聚集(通过全局权重对所有的时频信息加权)到通道信息之中,使全局特征充分地利用了时频信息。全局特征经过特征变换后使用softmax 函数产生通道权重,重新调整特征的通道维度再与输入特征x相加,从而模拟了特征映射之间的长期依赖关系,有助于提高特征判别性。其中δ(·)表示特征变换部分,结构与SE 注意力类似用来减少网络的参数同时捕获通道依赖。在SE 注意力中,特征变换模块通过全连接降维实现,而参考文献[17]实验表明,全连接捕获通道依赖关系是低效且不必要的。而在参考文献[17]中,使用一维卷积捕捉通道依赖,但卷积核大小依旧限制了覆盖范围并不能对所有的通道进行运算,所捕捉的通道依赖关系依旧是局部的。本文选择使用1×1的二维卷积,它允许所有的通道特征进行复杂的可学习的交互,可以更有效地捕捉通道间的依赖关系。
其中,r表示缩放系数,Wk∈R1×1×C、W1∈R1×1×C/r、W2∈R1×1×C为1×1卷积操作,LN为层归一化(LayerNorm)用来防止梯度消失以及加速网络的收敛。将两个注意模块的输出直接相加从而实现特征融合如公式(10)所示。不采用级联操作,因为需要更多的存储空间。MTFC注意模块可以直接插入到卷积网络结构之中。且仅会增加少量的参数,但却能有效地增强特征表示。
2 实验分析
2.1 数据集
实验的语音数据集采用的是近年来常用于说话人识别任务的Voxceleb数据集[18-20]。Voxceleb是一个大型的不依赖于文本的说话人识别数据集包含Voxceleb1数据集和Voxceleb2 数据集,Voxceleb2 包含了从YouTube视频中提取的5 994个说话人的100多万段音频。平均时长为7.8 s,来自不同的声学环境,使说话人的识别更具挑战性。Voxceleb1包含了来自1 251个说话者的100 000多段音频。测试集分为Voxceleb1-O、Voxceleb1-E 和Voxceleb1-H 三种不同的测试集。Voxceleb1-O 是一个独立于Voxceleb1的测试集包括40个发言人,与Voxceleb1中的发言人不重叠。Voxceleb1-E 测试集使用了整个Voxceleb1数据集,而Voxceleb1-H测试集是一个更特殊的测试集,这个测试集包含来自同一国籍和性别的样本。Voxceleb2数据集是Voxceleb1数据集的扩展版本,但是这两个数据集是互斥的。如参考文献[21]所述,Voxceleb2 在其注释中包含一些缺陷,因此,不建议使用它来测试模型;然而,它被广泛用于训练。相比之下,Voxceleb1是在极其严格的条件下收集的;因此,经常在这个数据集上进行测试。与大多数已有参考文献相同,本文使用Voxceleb2进行训练,将Voxceleb1作为测试集。
2.2 训练参数设置
为了验证本文提出方法的有效性,实验采用与对比文献[18-20]相同的朴素训练方法。首先将所有的音频转换为单通道,16位流16 kHz采样率,然后对音频数据进行滤波(40组梅尔滤波器)、加窗(25 ms窗口重叠,步长10 ms)、特征对齐,再在频谱的每个频域方向上进行均值和方差归一化(mean and variance normalization,MVN)生成Fbank特征,作为深度卷积神经网络的输入。不进行静音检测和语音增强,后端也没有复杂的处理。使用初始学习率为0.001的Adam优化器进行网络参数优化[22]。选取ThinResNet-50作为基线系统,ThinResNet-50与标准ResNet-50 网络结构相同只是为了减少计算成本,每个残差块的通道数变为标准网络的1/4,本文引入的Res2Net 和改进的FullRes2Net 结构如表1 所示,其中T表示时间维度。
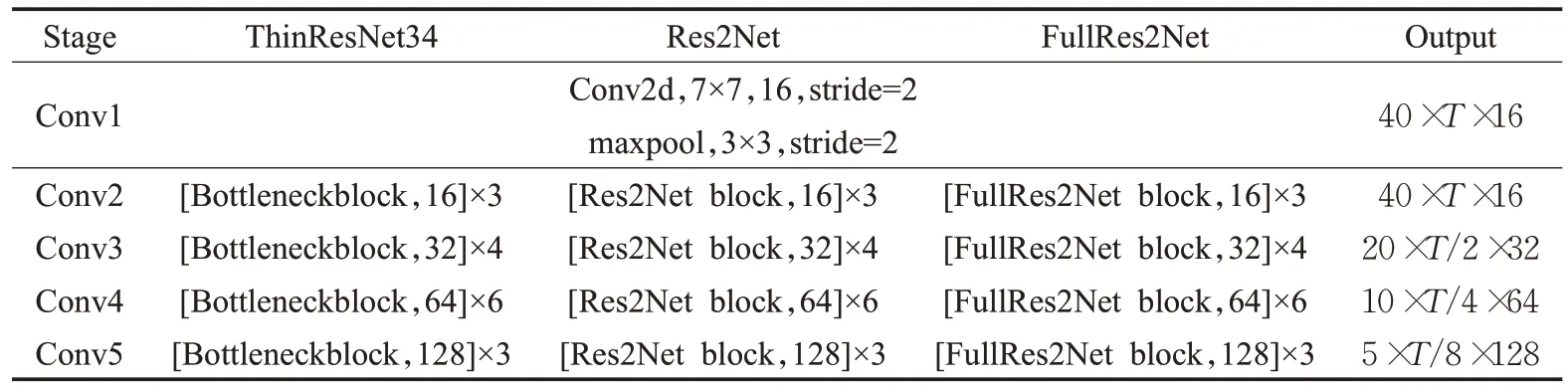
表1 网络结构Table 1 Network structure
训练时采用的方式进行分类训练。模型的损失函数采用margin=1,scale=15 的AM-softmax损失函数[23],相比于softmax 损失函数AM-softmax 通过在角空间中引入边界提高了验证精度。计算公式如下:
其中,Li是将样本正确分类的代价,θy=arccos(wTx)指样本特征和决策超平面(w)之间的角度,两个向量都经过L2标准化。因此尽可能使cosθyi-m大,其中m是角度边界,从而使角最小化。超参数s控制损失函数的“温度”,对分离良好的样本产生更高的梯度并进一步缩小类内方差。
在模型训练好后使用测试集进行开集测试,测试集与训练集是完全脱离的。测试时,从每个测试音频中抽取10个3 s的片段作为样本,然后送入系统中抽取每个片段的话语级特征并计算每对片段中所有组合(10×10=100)之间的距离,再将100个距离的平均值作为说话人身份判别依据,进行说话人身份识别。
为了客观地评估不同聚合模型的性能,本文采用常用的等错误率(equal error rate,EER)和最小检测代价标准(minimum detection cost function 2010,DCF10)[24]作为系统性能的评价指标,其值越小代表性能越好。最小检测代价函数计算公式为:
其中,CFR与CFA分别为错误拒绝率EFR和错误接收率EFA的惩罚系数;Ptarget和1-Ptarget分别为真实说话测试和冒充测试的先验概率,这里采用NIST SRE2010设定的参数CFA=1,CFR=1,Ptarget=0.01(DCF10)。DCF不仅考虑错误拒绝和错误接收不同的代价,还充分考虑到测试情况的先验概率,因此在模型性能评价上MinDCF比EER更具参考价值。
2.3 实验结果
为了验证本文所提出的FullRes2Net和混合时频通道注意力的有效性,本文首先进行两组消融实验。表2显示了在相同实验条件下(都采用朴素的训练方法)本文所改进的FullRes2Net与其他网络结构在Voxceleb1-O测试集上的结果。从表中可以看出轻量结构的ThinResNet-50表现出最差的性能EER/DCF 为5.04%/0.465 1,而在使用更深、更宽网络结构的ResNet-50 性能则有明显的提升,但相应的它的参数量和推理时间也成倍的增加,如表3 所示。将目标检测任务的Res2Net 引入说话人识别任务中并进行测试,可以看出Res2Net 取得了比ThinResNet-50 和ResNet-50 更低的EER/DCF 为3.32%/0.319 9。同时可以发现,相比于ThinResNet-50,Res2Net参数量只增加了8.9×105推理时间只增加了18 ms,但远远低于ResNet-50,证明了Res2Net 是一种参数量更少特征提取能力更强的轻量网络。而本文改进提出的FullRes2Net 相比于Res2Net 则进一步提升了系统的性能,取得了最低的EER/DCF 为2.75%/0.286 1,表明了FullRes2Net 拥有更强的特征提取能力,更有效地提取了特征中的说话人身份信息,从而得到了更具区别性的帧级特征。从表3中也看出,FullRes2Net相比于Res2Net参数量子只增加6×104推理时间也只增加了8 ms,但性能却提升了17%是更优秀的轻量特征提取器。在训练过程中,记录这些网络结构的损失曲线和准确率曲线,如图7所示是训练集的损失值变化曲线。可以看出,本文所改进的FullRes2Net 结构损失值低于其他方法,收敛效果最优。表明本文所提FullRes2Net可以更好的收敛。而注意力曲线则相较于对比的所有网络结构始终保持最高,并明显地领先于Res2Net。损失值和准确率的实验结果表明,本文提出的FullRes2Net 拥有更强的特征提取能力,得到帧级特征也更有效、更具区别性。

表3 不同网络的参数量以及推理时间Table 3 Number of parameters and inference time for different networks

图7 不同网络的训练损失曲线与准确率曲线Fig.7 Loss curves and accuracy curves of different networks in the training
表4 展示了本文所提出的混合时频通道注意力中时频注意力和通道注意力在Voxceleb1-O 的测试结果。从表中可以看出,时频注意力的表现相比于通道注意力的表现要差一些。时频注意力由于注意力机制并不具有卷积那样的局部特征提取能力,因此会忽略掉一些特征细节。但它可以有效地注意到特征时频域中更明显的重要区域以及不重要的区域,对这些重要进行强调,对不要的区域进行抑制。在通道注意力中,通过全局权重对所有的时频信息加权,将时频信息聚集到通道信息之中。从而可以充分地利用时频信息,进而产生更准确的全局通道权重。不同于二维的时频注意,一维的通道注意会更简单也更准确地对重要的通道特征进行强调。但将两者同时作用相加则会产生更明显的信息增益,通道注意会突出重要的通道特征,而时频注意会突出重要的时频区域。同时,通道注意也会弥补时频注意缺失的部分特征细节。表5 展示了本文所提出的混合时频通道注意力与不同注意力方法在Voxceleb1-O测试集上的结果,同样在相同实验条件下进行测试,但系统的骨干架构直接选取FullRes2Net。从表中可以看出,注意力的使用明显地提升了基线系统的系统,增强了卷积神经网络的特征提取能力。SE注意力通过强调特征的通道维度使系统的EER/DCF 降至2.63%/0.254 3,tf-CBAM 注意力通过强调特征的时间维度和频率维度进一步提升了系统的性能,取得了比SE 注意力更低的EER/DCF 为2.46%/0.252 3。而本文所提的MTFC 则取得了最低EER/DCF 为2.23%/0.224 3 并明显地领先于tf-CBAM注意力,证明了MTFC注意力是更优秀的注意力方法,通过对时间-频率-通道维度交互得到了更多的说话人身份信息,同时使用二维1×1卷积的方式也更有效地捕捉了特征间的依赖关系,从而相比于其他注意力方法更有效地提升了卷积神经网络的特征提取能力。也证明了SE注意力和tf-CBAM注意力中使用池化的方式丢失了说话人身份信息,也不能进行有效的注意力学习。由表6可以看出,相比于结构最简单参数量更少的SE 注意力(包括了FullRes2Net 在内),本文所提出的MTFC 注意力参数量增加了3×104,推理时间增加了8 ms,但性能却提升了15%。同样,本文记录了这些注意力在训练过程中的损失曲线和准确率曲线,如图8所示是不同注意力方法的训练集的损失曲线和准确率曲线。从图中可以看出,本文所提出的混合时频通道注意力损失值相对于其他注意力方法更低,收敛速度更快,并且损失值始终低于其他方法,收敛效果最优。表明本文所提方法可以使神经网络更好的收敛。而在准确率曲线中,MTFC 注意力则表现出最优的性能,相较于对比的所有注意力始终保持最高,并明显地领先于tf-CBAM注意力。损失值和准确率的实验结果表明,本文所提出的MTFC 注意力,更有效地获取了特征之间的依赖,得到了更多的注意信息,从而也更有效地增强了卷积神经网络的特征提取能力,提高了模型的性能。
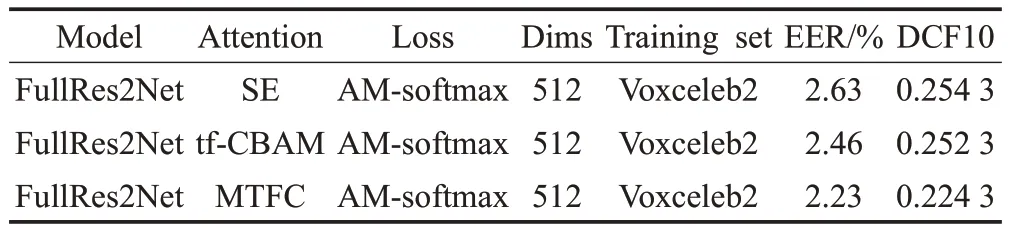
表5 不同注意力方法在Voxceleb1-O的测试结果Table 5 Test results of different attention in Voxceleb1-O
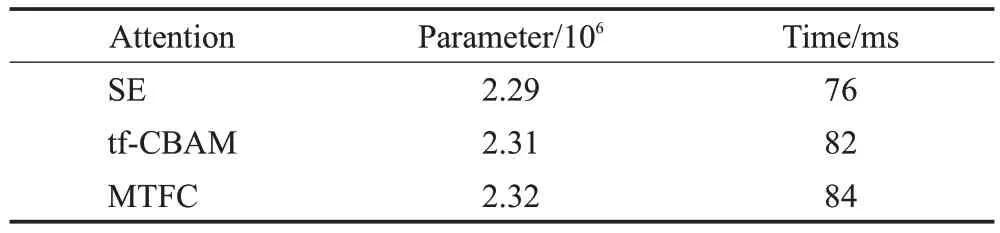
表6 不同注意力方法的参数量以及推理时间Table 6 Number of parameters and inference time for different attention
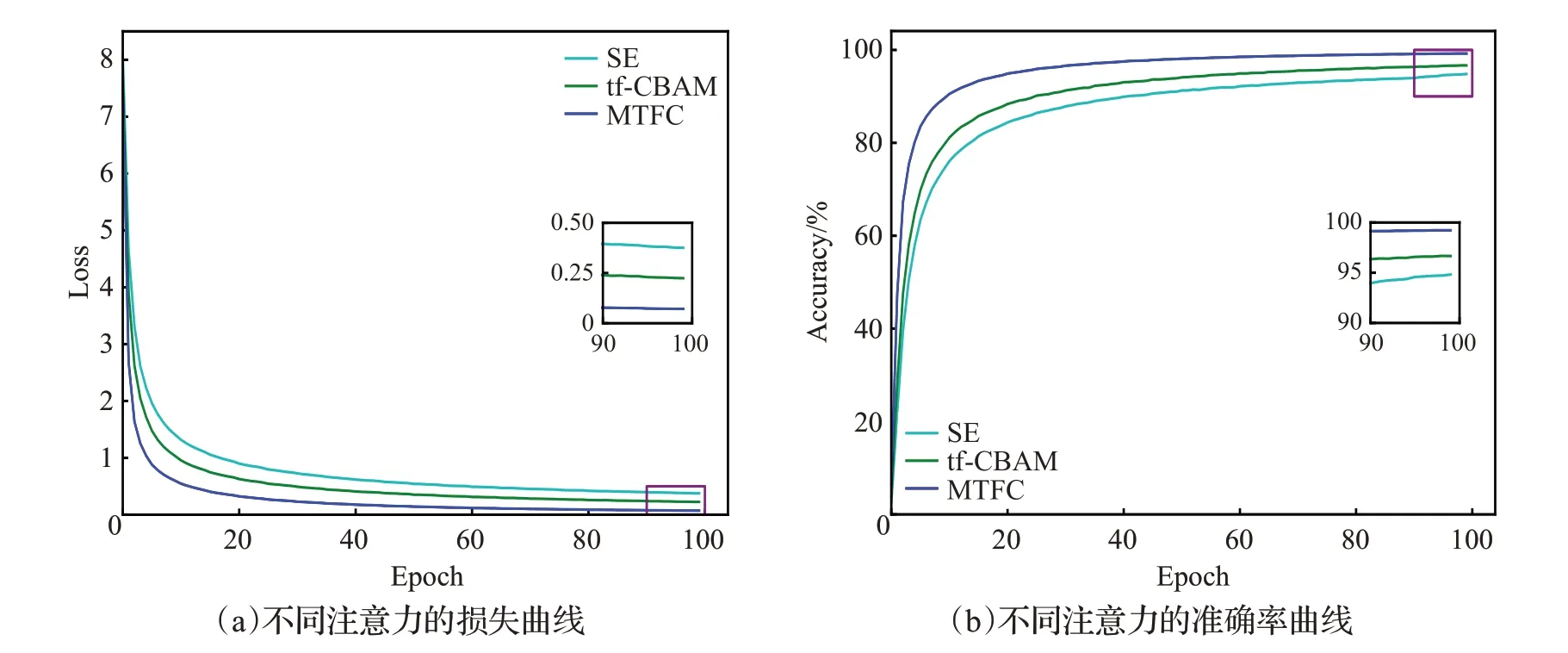
图8 不同注意力的训练损失曲线与准确率曲线Fig.8 Loss curves and accuracy curves of different attention in training
接下来,本文将所提出的MTFC-FullRes2Net 端到端说话人识别系统在Voxceleb1-O上与当前那些使用更深、更宽、更复杂网络结构的先进说话人识别系统进行了比较与评估。结果如表7所示。在此之前的实验中,使用复杂网络结构的RawNet和CNN+Transform说话人识别系统表现出最后的性能EER分别为2.48%与2.56%。而本文构建的MTFC-FullRes2Net结构超过了之前的最佳结果取得了更低的EER/DCF 值为2.23%/0.224 3,并且优于目前大部分的说话人识别系。证明了本文所提出的MTFC-FullRes2Net端到端说话人识别系统具有更强的特征提取能力,同时也参数量也远远小于所对比的使用复杂结构网络模型的说话人识别系统。
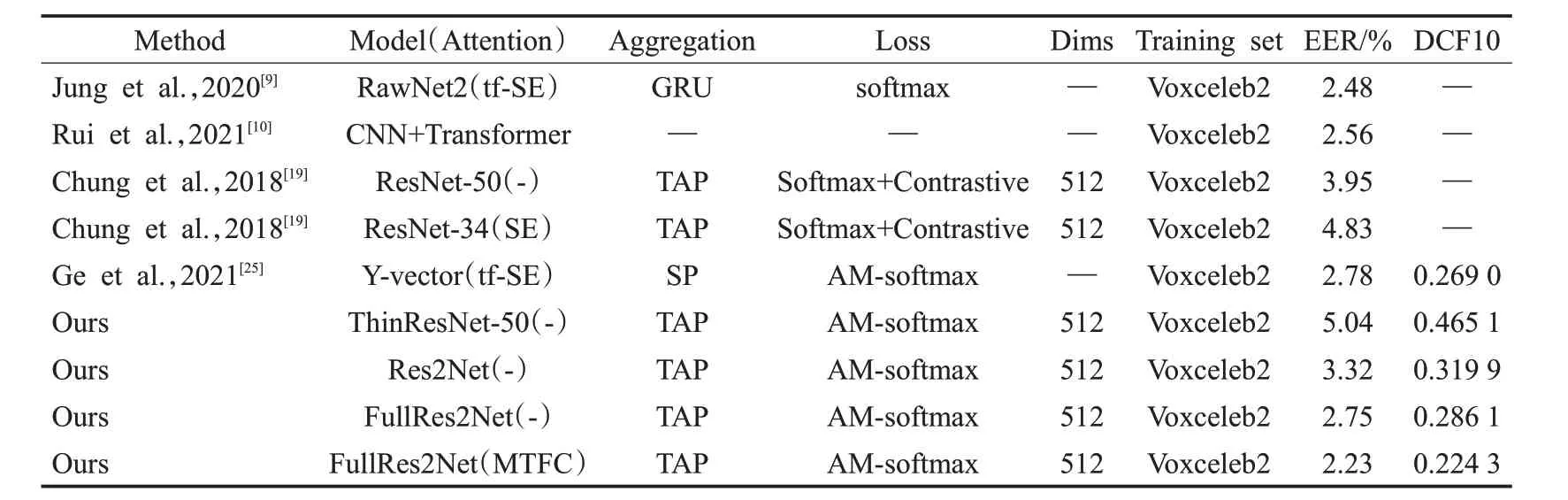
表7 不同系统在Voxceleb1-O的测试结果Table 7 Test results of different systems in Voxceleb1-O
为了更全面地评估系统性能,本文在规模更大也更困难的测试表单Voxceleb1-E 和Voxceleb1-H 再次进行了测试。如表8所示,在使用整个Voxceleb1作为测试集的Voxceleb1-E 中,本文所提出的MTFC-FullRes2Net 端到端说话人识别系统依然取得了更好的结果。

表8 不同系统在Voxceleb1-E的测试结果Table 8 Test results of different systems in Voxceleb1-E
而在使用同一国家和性别的Voxceleb1-H 测试集上,由于口音和语调的差别减小相似性更高更难以区别,模型的EER/DCF值都有所上升。但从表9可以看出本文提出的MTFC-FullRes2Net说话人识别系统依然保持领先,EER/DCF为3.75%/0.376 2远远低于其他方法。证明MTFC-FullRes2Net端到端说话人识别系统获得的帧级特征区别性更强,从而在聚合模型聚合帧级模型的过程中得到甄别性更强的话语级特征,可以更好地区分相似度更高的说话人。

表9 不同系统在Voxceleb1-H的测试结果Table 9 Test results of different systems in Voxceleb1-H
为了进一步可视化MTFC-FullRes2Net端到端说话人识别系统,本文使用了Maaten等人[26]提出的可视化方法将MTFC-FullRes2Net得到话语级特征通过t-SNE方法降维后形成可视化效果图。在Voxceleb1-H中随机选取50名说话人以不同的颜色表示,每人随机选取10段音频并从每段音频中随机提取出10个3 s的测试片段,共5 000个3 s的测试片段。如图9所示,(a)为ThinResNet-50所提出的话语级特征可视化效果图,可以看出得到的话语级特征类间、类内距离都较大且分类错误和碰撞的情况也比较多,表明基线系统得到的话语级特征不具有甄别性。同时,来自同一说话人的话语级特征之间相似性弱使得类内距离较大。(b)为采用Res2Net 得到的可视化效果图,相比于(a)它的分类错误更少,但话语级特征类内的距离依然较大,表明Res2Net拥有更强的特征提取能力,得到的话语级特征甄别性也更强。(c)为FullRes2Net的可视化效果图,可以明显看出相比(b)它的类间距离更大,类内距离更小聚合的也更加紧密,表明本文所改进的FullRes2Net是有效的,它拥有比Res2Net更强的特征提取能力。(d)表示使用MTFC-FullRes2Net得到的话语级特征的可视化效果图,可以明显看出它不仅分类错误更少,同时类间距离也更大,类内结合得更紧密。表明混合时频通道注意力机制的引入可以使卷积神经网络得到更具区别性的帧级特征,从而提升话语特征的甄别性,并使来自同一说话人的话语级特征具有更高的相似性。

图9 不同网络的t-SNE降维可视图Fig.9 t-SNE reduced dimensional view of different networks
3 结束语
本文提出基于混合时频通道注意力和FullRes2Net的端到端说话人识别系统,将目标检测任务中的Res2Net引入到说话人识别任务中,验证了其有效性并改进提出FullRes2Net,利用FullRes2Net 在更细粒的层次上获得多种感受野的组合,从而获得多种不同尺度组合的特征表达,产生说话人身份信息更丰富、更全面、更具区别性的帧级特征。同时,为了解决现有注意力方法存在的问题以及改善卷积网络本身存在的缺陷,本文提出了混合时频通道注意力(MTFC),以提高卷积网络的特征提取能力,更有效地获取音频中的说话人身份信息。所提出的MTFC-FullRes2Net 说话人识别系统在Voxceleb 测试集上的EER/DCF 为2.23%/0.224 3,相较于Res2Net 性能提升了34%参数量增加了9×104,而相较于轻量的ThinResNet-50 性能提升了56%但参数量只增加了在9.8×105。同时,它也优于现有的多种使用复杂结构的说话人识别系统,是一种参数量更少、推理时间更快、效率更高的端到端结构。
猜你喜欢
电子制作(2018年19期)2018-11-14 02:37:08
自动化学报(2017年11期)2017-04-04 02:52:58
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27 06:31:53
管理现代化(2016年3期)2016-02-06 02:04:41
管理现代化(2016年3期)2016-02-06 02:04:13
智能系统学报(2015年4期)2015-12-27 09:37:52
舰船科学技术(2015年8期)2015-02-27 15:38:48
噪声与振动控制(2015年4期)2015-01-01 07:08:21
电测与仪表(2014年17期)2014-04-04 11:56:48
振动、测试与诊断(2014年6期)2014-03-01 01:14:47
