
一种基于RippleNet模型的推荐精度提高方法
2023-12-27 12:59安文涛陈珊珊
计算技术与自动化 2023年4期
安文涛,陈珊珊
(南京邮电大学 计算机学院,江苏 南京 210023)
由于计算机技术的高速发展,计算机技术在给人们生活提供便利的同时,也给人类日常生活带来了一些麻烦,其中数据大爆炸所带来的数据过载现象尤为明显。推荐系统作为信息过滤系统,能够高效地处理数据过载事件。
基于大数据分析的信息推荐系统已广泛应用于社会各个领域,如阅读[1]、电影[2]、音乐[3]、新闻[4]推荐等。推荐功能的实现主要依靠协同过滤和聚类模型思维[5]。由于数据稀疏、冷启动困难等一系列问题在以往的推荐模型中普遍存在[6],因此后期的研究逐渐将知识图谱加入推荐系统模型。
知识图谱(Knowledge Graph,KG),是为表达实体之间语义关系的一种结构化语义数据库,“实体-关系-实体”三元组是知识图谱的基本组成单位,其中包含丰富的语义知识,可用于推荐系统,使其具有可解释性、多样化和准确的特点[7]。基于知识图谱的推荐系统主要通过引入实体之间的语义相关性,有助于发现它们的潜在联系,提高推荐项目的准确性。由于存储在知识图谱中实体间的语义关系种类具有多样性,知识图谱连接用户的历史记录和推荐的历史记录,故可以为推荐系统带来可解释性。现有的知识图谱推荐可分为两类:第一类基于路径的推荐方法[8],探索知识图谱中各个实体之间的连接关系,然后利用连接关系来计算节点相似性,从而进行推荐,但是该方法严重依赖于手动设计的元路径,实践过程中很难优化;第二类基于嵌入的方法[9],它使用知识图谱嵌入(Knowledge Graph Embedding,KGE)算法对知识图谱进行预处理,并将学习到的实体嵌入合并到推荐框架中,采用知识图谱嵌入算法一般情况更适用于图内应用,但是该类模型在推荐的过程中并没有利用到知识图谱的多跳关系,这使得结果的可解释性缺乏。
为了使知识图谱中的数据利用更全面,Wang Hong-wei等[10]2018年提出RippleNet模型,首次将基于嵌入的思想通过对图谱的语义表示与路径链接信息结合,RippleNet模型通过“偏好扩散”的思想在创建好的知识图谱中创建,RippleNet模型借助知识图谱节点间语义关系在节点之间传播得到了很好的效果。但是随着数据的增多,构建的知识图谱的冗余数据会随着增长,为了提高数据的相关性,从而提高RippleNet模型的推荐精度,本文提出新的改进方法,开展了如下工作:
1)添加子网提取算法对数据进行预处理,通过提取概念图谱的最大联通子网来去除数据冗余。
2)在RippleNet模型的基础上,利用算法处理后的数据和原数据进行对比试验,证明该方法的有效性。
1 相关工作
RippleNet背后主要的思想是偏好传播,如图1所示,RippleNet模型以一个项目和一个用户作为输入,接着将项目经过嵌入转化为低维向量,然后将该向量不断地同用户周围的n跳项目转化后的向量进行交互运算,得到该用户的向量表示,然后将用户的向量表示与项目的转化向量进行计算,得到用户的点击概率,从而完成推荐。
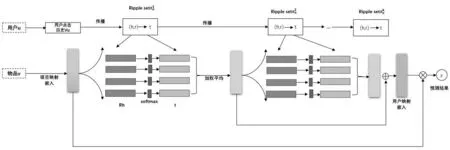
图1 RippleNet的总体框架
RippleNet模型涉及相关实体:U={u1,u2,…}表示用户集合;V={v1,v2,…}表示物品集合;Y={yuv|u∈U,v∈V}表示用户和物品的交互矩阵,被定义为隐式反馈,其中:
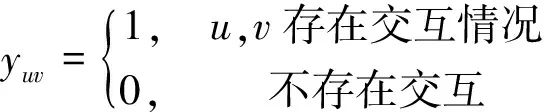
(1)
如果yuv的值为1,则表示用户u和物品v之间存在隐式的交互作用,如点击、游览、观看等行为。
RippleNet模型利用水波纹的传播思想,以用户所感兴趣的物品作为种子(seed),在知识图谱中以种子物品作为中心像水波纹一样向外扩散到其他物品上,整个过程为偏好传播。外层的物品属于用户潜在的偏好,应该被添加到计算过程中。
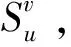
pi=softmax(vTRihi)=
(2)
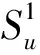
(3)

(4)
最后得到用户u和物品v交互的概率:
(5)

2 优化改进
在RippleNet模型的基础之上,利用子网提取算法处理后的数据替换未经处理的原始数据。如图2所示,首先对未经处理的概念图谱文件进行一次预处理,利用子网提取算法[11]对原概念图谱数据进行最大连通子网抽取,从而去除冗余数据,使得数据之间的相关性得到提高。利用处理后得到的最大连通子网数据文件进行知识图谱的构建,以得到知识图谱,然后利用RippleNet模型进行计算。

图2 加入数据处理后RippleNet整体框架
RippleNet模型利用水波纹的特点模拟用户的偏好传播,以一个用户和一个物品作为输入,输出用户与物品交互的预测概率,概率越高,表示用户与物品的相关性概率越高。如图2所示,在构建所需的知识图谱之前对数据文件进行一次预处理,获取最大连通子网,去除一些无关联的冗余节点。通过获取概念图谱网络的最大连通子网来提高数据的相关性。本文利用子网提取算法,以概念图谱文件作为输入,最大连通子网节点集合作为输出。
算法:子网提取算法
输入:概念图谱文件Concept_graph
输出:最大连通子网节点集合MaxSubNet
(1)从Concept_graph中抽取出度值的节点所在的三元组,将该三元组所包含的节点作为最大连通子图的中心层Sublayeri(当前i=1,表示中心层),并加入集合MaxSubNet。
(2)寻找Sublayeri集合中的相邻节点,将查找到对应的邻居节点加入集合NeighborSeti中。
(3)判断集合NeighborSeti中是否有新的不在集合MaxSubNet中的节点,若有,将NeighborSeti并入MaxSubNet中,并用集合MaxSubNet与集合NeighborSeti的差集替换Sublayeri,i=i+1,然后跳转到步骤(2);若无,则继续步骤(4)。
(4)返回MaxSubNet.
首先利用子网提取算法可以得到最大连通子网的节点集合MaxSubNet,然后根据MaxSubNet从概念图谱文件Concept_graph中提取出最大子网的边的集合,对于每一条边依旧采用Concept_graph中三元组形式并存储在文本文件Concept_graphLink中,然后根据MaxSubNet和Concept_graphLink构建图3所示的最大连通子网。其中,中心层(CentralLayer)为包含度值最大的三元组节点;第二层(Layer 2)为中心层各个节点的邻居节点集合;第三层(Layer 3)为第二层节点的邻居节点集合。以此类推,直到最外层(Outermostlayer)。
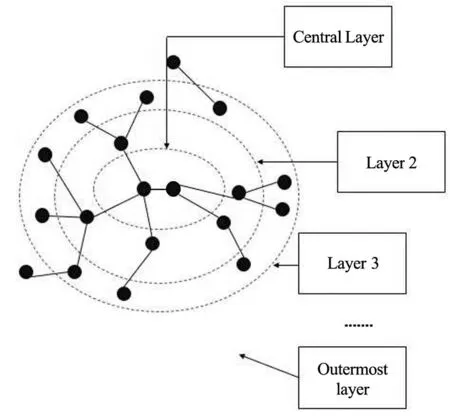
图3 最大连通子网逻辑结构
通过算法抽取出图谱网络的最大连通子网,提高了节点之间的相关性,从而能够更真实地描述其网络特性。根据子网提取算法得到最大连通子网的节点集合,再根据Concept_graph中提取边的集合GraphLink,最后生成知识图谱网络,然后利用RippleNet模型对生成的知识图谱网络进行运算。
3 实验验证
3.1 实验评价标准
分类问题中的混淆矩阵如表1所示,其中TP(True Positive)表示实际结果为1,预测也为1;FP(False Positive)表示实际结果为0,预测为1;FN(False Negative)表示实际结果为1,预测为0;TN(True Negative)表示实际结果为0,预测为0。Top-k列表推荐的具体评价标准:精准率、召回率、F1计算公式如式(6)~式(8)所示。CTR(Click Through Rate)点击率预测的评价标准,准确率和AUC的计算公式如式(9)、式(10)所示。
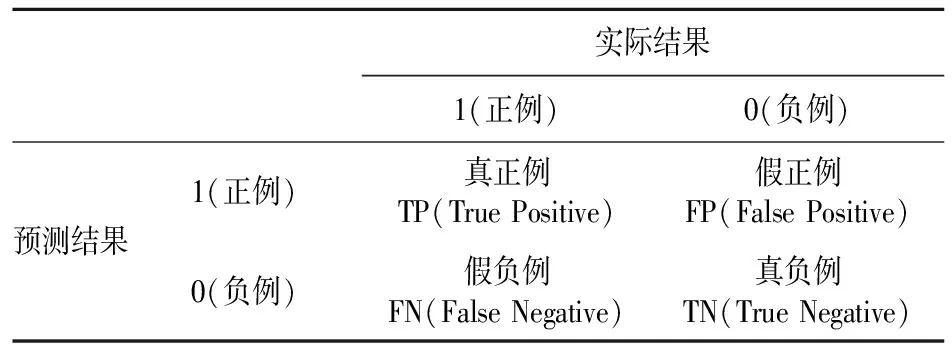
表1 混淆矩阵
(6)
(7)
(8)
(9)
(10)
式(8)中F1值是精确率和召回率的合成指标,综合了二者的结果,F1值越高,代表模型综合性能越好。式(10)中的insi表示正样本,rankinsi表示预测第i个样本的概率排名,T表示正样本的总数,F表示负样本的总数。
3.2 实验数据
实验中使用了MovieLens-1M数据集,见表2。

表2 数据集的基本统计
采用子网提取算法对所构建的概念图谱网络进行最大连通子网抽取实验,具体实验环境为64位Win11系统,8 GB内存,Python开发环境。
3.3 实验结果
由算法(SNEBF)根据概念图谱的数据文件MovieLens-1M生成的最大子网包含节点结果MovieLens-1M_MaxSubNet如表3所示。

表3 最大连通子图提取结果
根据MovieLens-1M数据文件生成的最大子网占原概念图谱网络节点和边的83.23%和92.69%,由MovieLens-1M所生成的最大子网覆盖了原概念图谱网络大部分的边和节点,能较好地反映整个网络特征。
使用原数据集MovieLens-1M 和消除冗余后的数据集MovieLens-1M_MaxSubNet在RippleNet模型上进行计算,其中CTR(Click Through Rate)点击率预测结果评价标准,AUC和精准度结果如表4所示;Top-k推荐中的精准度、召回率、F1的结果如图4所示。

表4 CTR预测的AUC和精准度结果
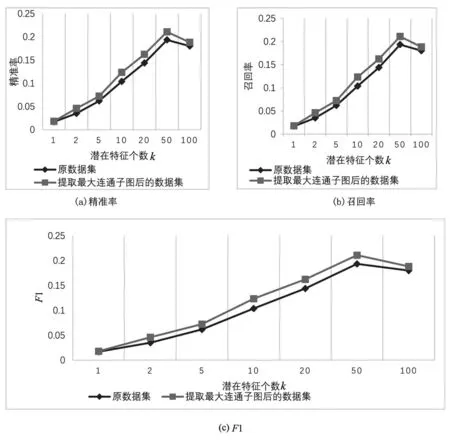
图4 Top-k推荐中的精准率、召回率、F1对比
综上,通过提取最大连通子网消除冗余数据,提高数据集的相关性,为RippleNet的偏好传播提供更相关数据,有效地降低了数据的不确定性,提升了概念图谱对数据用户特征描述的精准度。
4 结 论
在RippleNet模型的基础上,通过子网提取算法提取最大连通子网,消除冗余数据,提高数据相关性,从而提升RippleNet模型推荐性能。使用MovieLens-1M数据集进行预处理后,通过与原数据进行实验对比,使得RippleNet模型性能得到提升。后续可以将RippleNet模型与其他推荐模型相结合,在此基础上探索是否可以在准确率上继续提升。
猜你喜欢
计算机与数字工程(2023年5期)2023-08-31
计算机时代(2023年1期)2023-01-30
山西大学学报(自然科学版)(2021年1期)2021-04-21
少先队活动(2020年12期)2021-01-14
五邑大学学报(自然科学版)(2019年3期)2019-09-06
中国新通信(2019年21期)2019-03-30
中成药(2017年3期)2017-05-17
网络安全和信息化(2016年2期)2016-11-26
领导科学论坛(2016年9期)2016-06-05
现代防御技术(2014年6期)2014-02-28
