
计算心理测量视域下的学生数字素养测评
2023-12-25 03:06:46朱莎郭庆吴砥
现代远程教育研究 2023年6期
朱莎 郭庆 吴砥



摘要:定期开展数字素养发展监测与评估是提升全民数字素养的基础和前提。当前,学生数字素养评价主要沿用“依据规则给潜在特质赋值”的经典测量观,以标准化测试及自陈式量表为主要测评工具,存在评价内容有限、评价方法片面等问题。计算心理测量理论为破解学生数字素养评价难题提供了新的理论和方法支持。它主张综合运用心理测量学、计算机科学等多学科的研究方法,将评价嵌入真实情境任务中,激发并追踪主体与情境之间的交互,通过多源异构数据采集与分析,实现过程性评价。计算心理测量视域下的学生数字素养测评框架基于自上而下理论驱动和自下而上技术驱动相结合的推理链,在以证据为中心的设计思想指导下,构建复杂的任务情境获取细粒度数据,并利用数据挖掘技术从海量细粒度数据中提取证据,进而实现精准评价。以此框架开展的面向小学高年级学段的数字素养测评实践表明,该测评范式有助于形成从数字素养“能力模型”到“测量模型”的闭环推理链,在经过多轮次迭代优化后,可形成高质量的学生数字素养测评任务、可靠的学生数字素养证据和稳定的学生数字素养测量模型。
关键词:计算心理测量;以证据为中心的设计;数字素养评价;游戏化测评任务
中图分类号:G434 文献标识码:A 文章编号:1009-5195(2023)06-0019-11 doi10.3969/j.issn.1009-5195.2023.06.003
基金项目:国家自然科学基金青年科学基金项目“融合证据推理和认知网络分析的学生信息素养高阶思维能力精准评价研究”(62107019);国家社会科学基金“十三五”规划2020年度教育学重点课题“学生信息素养的内涵、标准与评价体系研究”(ACA200008)。
作者简介:朱莎,博士,副教授,硕士生导师,华中师范大学国家数字化学习工程技术研究中心(湖北武汉 430079);郭庆,博士研究生,华中师范大学人工智能教育学部(湖北武汉 430079);吴砥(通讯作者),博士,教授,博士生导师,华中师范大学教育部教育信息化战略研究基地(华中)(湖北武汉 430079)。
一、引言
数字素养与技能是数字社会公民学习工作生活应具备的数字获取、制作、使用、评价、交互、分享、创新、安全保障、伦理道德等一系列素质与能力的集合(中央网络安全和信息化委员会办公室,2021),是实现数字化转型的关键支撑(吴砥等,2022a)。2021年11月,中央网信办发布《提升全民数字素养与技能行动纲要》,指出“提升全民数字素养与技能,是顺应数字时代要求、提升国民素质、促进人的全面发展的战略任务”,要“建立符合我国国情的全民数字素养与技能发展评价指标体系”,“定期开展全民数字素养与技能发展监测调查和评估评价”(中央网络安全和信息化委员会办公室,2021)。
然而,当前学生数字素养评价主要沿用“依据规则给潜在特质赋值”的经典测量观,在评价内容、评价方法等方面存在诸多局限性。一方面,传统的“试题—答案”测验设计范式侧重考查学生数字知识、数字应用技能等低阶认知能力,难以评价学生利用数字技术分析解决问题、进行创新创造等高阶思维能力。另一方面,当前学生数字素养评价以标准化测验和自陈式量表为主要工具,评价结果效度低、解释力度不强。尽管近年来部分学者采用情境任务测评、档案袋评价等方法来衡量学生数字素养水平,但这些数据难以为学生数字素养表现提供全面的证据(吴砥等,2022b)。
计算心理测量理论主张综合运用心理测量学、计算机科学等多学科的研究方法,将评价嵌入真实情境任务中,激发并追踪主体与情境之间的交互,通过多源异构数据采集与分析,实现过程性评价(Mislevy,2021)。计算心理测量理论为破解学生数字素养评价困难提供了创新的方法支持。本研究将自上而下的基于证据推理的理论模型和自下而上的基于技术驱动的测量模型相结合,构建计算心理测量理论视域下的学生数字素养测评框架,并在此基础上开展实测分析,验证所提出评价框架的实践效度。
二、计算心理测量的理论根基与应用现状
2015年,冯·戴维(Von Davier)首次提出了计算心理测量理论,随后将其定義为一种综合运用随机过程理论、心理测量理论以及数据挖掘、机器学习等计算机科学领域的思想和方法,基于表现性测试收集复杂细粒度数据,对被试潜在特质进行精准测量的方法论(Von Davier,2017)。效度验证理论以及社会认知理论是计算心理测量理论的两大理论根基。
1.效度验证理论
传统心理测量范式强调“测验是否衡量了测量目标”的效度观,强调工具的内容效度、效标效度等,其衡量方式依赖于专家内容审查和计算测验得分与效标成绩之间的相关系数(戴一飞,2016)。这种效度观操作简单便捷,却存在着专家内容审查的主观性以及效标选择的科学性等问题,难以反映一些高阶能力测评工具的效度。美国教育研究者协会(American Educational Research Association,AERA)等出版的《教育与心理测验标准》(Standards for Educational and Psychological Testing)中将效度重新定义为“依据分数所作出的推理是否适恰、是否富有意义、是否具备实用性,测验的效度验证就是搜集证据来支持上述推理的过程”(AERA et al.,1999)。彼时,效度理论已经开始从相关系数计算向基于证据的验证转变。迈克尔·T.凯恩(Michael T. Kane)进一步提出效度理论应落脚到效度验证,强调从考生作答过程的数据中挖掘证据,以支持和证实测验结论的可靠性(Kane,2001)。由此,效度验证理论的核心思想从传统的计算某项测验的效度指标转变为衡量测验分数的可解释力度,在操作上强调利用经验或理论证据来评判测验分数及其推断的充分和适当性,即使用证据去支持对测验结果的解释。
效度验证理论奠定了计算心理测量理论的思想基础,即强调测评要构建相对复杂的任务,诱发被试的知识、技能和能力(Knowledge,Skill and Abilities,KSAs)表现,基于表现挖掘并提取证据,建立证据与KSAs之间的统计关系,强化测评结果的可解释力度。
2.社会认知理论
传统心理测量范式起源于以伯尔赫斯·弗雷德里克·斯金纳(Burrhus Frederic Skinner)为代表的特质和行为心理学,强调心理测量即是试题与被试之间的“刺激—反应”,并根据反应结果为被试的潜在特质赋值(Mislevy,2021)。此种测评范式操作简便,有利于开展大范围的测评,但仅将测评看作是“刺激—反应”会忽略学生复杂的认知心理过程,导致测评过程及结果解释的简单化。
社会认知理论反对将环境看作简单的行为刺激源,强调认知是主体内部心理过程与外部环境相互作用的结果。社会认知中的“社会”反映了人与环境之间交互的规律性(Mislevy,2021),个人需要从环境中抽象出关键认知事件以开展后续的认知活动,不同人会提取出不同的认知事件。人与环境之间交互的规律性即是指这些因人而异的认知事件具有共同的本质,可以聚集成一些性质、规律相似的事件集群(Hansen et al.,1997)。罗伯特·J.麦斯雷弗(Robert J. Mislery)将这些事件集群的本质和规律称为语言(Linguistic)、文化(Cultural)和实质性(Substantive)模式(简称LCS模式)(Mislevy,2021)。个人的认知活动就是在与环境交互的过程中提取关键认知事件并识别事件隐藏的LCS模式,在此基础上展开后续的认知行为。社会认知中的“认知”强调个人利用自身的认知资源与环境进行复杂交互(Holland,2006),具有以下特点:首先,个人将自己过去的经验以及知觉、思想和信念等组织成有意义的思维模式(即认知资源),用于各种认知事件的解决;其次,个人在与情境交互的过程中,其对某一事件的认知行为会随着时间推移而不断变化;最后,个人会根据情境中认知事件的解决过程,总结经验,不断调整和完善自己的认知资源。
社会认知理论完善了计算心理测量理论的实践框架,强调测评为学生提供的任务应当具有丰富且真实的情境,激发学生利用自身的认知资源与环境进行交互;测评证据的提取就是识别学生不同粒度的认知资源的过程。社会认知理论还指出了证据的两种来源,一是来自个人既有的认知资源,这类证据主要由领域专家根据经验预先确定;二是来自随时间而变化的认知行为,这类证据通常是从学生的行为序列中采用数据挖掘技术而得到。
3.计算心理测量的主要思想与应用现状
计算心理测量理论在评价理念方面坚持效度验证思想,在以证据为中心的设计(Evidence-Centered Design,ECD)理念指导下,强调构建任务诱发KSAs表现,依据表现提取证据,依据证据进行推理,提高评价效度(Mislevy et al.,2003)。在评价内容方面,计算心理测量理论适用于高度抽象、结构复杂的综合能力和素养的评价。在评价技术方面,受社会认知理论的启发,计算心理测量理论强调利用多元化数据挖掘技术提取行为序列中的隐性证据,利用机器学习等技术建立证据与KSAs之间的测量模型。总体来说,计算心理测量理论形成了自上而下理论驱动和自下而上技术驱动相结合的测评逻辑(Mislevy,2021)。自上而下的理论驱动以ECD框架为基本指导,包含了能力模型、任务模型、证据模型的设计(Mislevy et al.,2003)。能力模型是指待测量的KSAs及其概念框架,回答了“测量什么”的问题。任务模型是指为了诱发学生的KSAs而开发的情境任务,回答了“用什么测量”的问题。证据模型是指由专家预先确定的衡量学生KSAs的变量及其计分方式,回答了“如何测量”的问题。麦斯雷弗指出了三种证据:与任务绩效相关的结果,在情境中产生的行为,个人的背景信息(Mislevy,2021)。测量模型表征了从证据到KSAs的推理过程,即利用数学与统计模型建立证据与能力模型之间的关联(朱莎等,2020)。自下而上的技术驱动包含过程数据采集、证据挖掘与筛选、测量模型構建等环节。首先,需要全面记录被试完成任务过程中的细粒度的行为序列数据;其次,通过数据挖掘技术从这些低层级、细粒度的行为序列数据中逐步提取新的变量,并筛选出能有效评价能力模型的关键证据;最后,整合证据并通过数学和统计模型构建KSAs的测量模型,实现精准有效的评价(Cipresso et al.,2019)。
目前,国外计算心理测量理论的相关研究主要关注理论发展、算法设计等内容,也开展了一些基于计算心理测量理论的测评实践。例如,斯蒂芬·T.波利亚克(Stephen T. Polyak)等人设计了第一人称的迷宫游戏,同时结合数据挖掘、机器学习等技术,衡量了中学生的协作问题解决能力(Polyak et al.,2017)。亚历山大·瓦图京(Alexander Vatutin)等人则专注于数学问题解决能力,基于学生与数字教科书的交互进行证据推理(Vatutin et al.,2021)。埃里克·斯诺(Eric Snow)等人基于证据推理和数据挖掘为中国香港小学生和美国中学生开发了一个计算思维评估工具,实现了学生计算思维能力的有效评估(Snow et al.,2019)。戴维·德加多-戈麦斯(David Delgado-Gómez)等人开发了一款无限奔跑类型的数字游戏,并根据学生在游戏中的行为实现了注意力的精准测评(Delgado-Gómez et al.,2020)。国内学者也开始关注计算心理测量理论。例如,李美娟等人系统介绍了计算心理测量理论的发展与内涵,并尝试构建了针对协作问题解决能力的测评框架(李美娟等,2022);郑勤华等人构建了理论与技术双向驱动的学生综合素养测评新范式(郑勤华等,2022)。
综上所述,国外已经开展了计算心理测量理论的实证应用研究,其科学性和有效性在一定程度上得到了证实。而国内对计算心理测量理论的研究还处于引介阶段,缺乏相关的应用研究以及实证分析。从评价内容来看,相关研究主要聚焦于对问题解决能力的评价,对于数字素养这种复杂能力体系的关注还较为匮乏。
三、计算心理测量视域下学生数字素养测评 框架
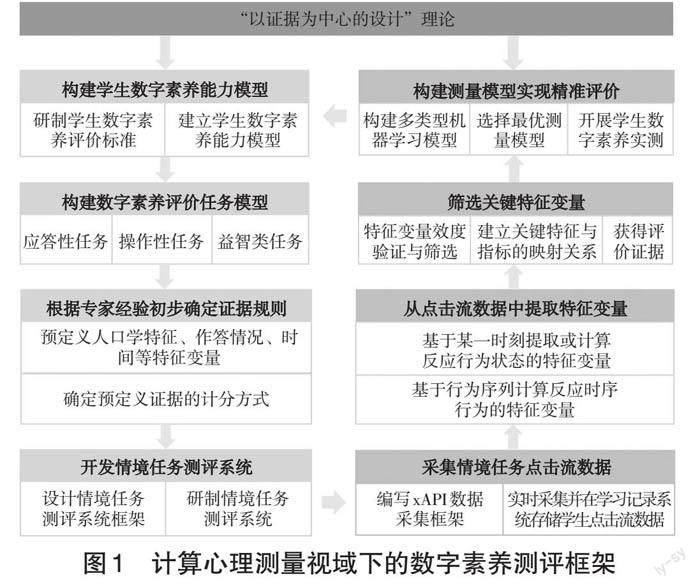
基于计算心理测量理论的思想,本研究构建了计算心理测量视域下自上而下理论驱动和自下而上技术驱动相结合的数字素养测评框架,如图1所示。
1.理论驱动的以证据为中心的设计
“以证据为中心的设计”理论是计算心理测量视域下数字素养测评的出发点,突出了自上而下理论驱动的推理链,主要包括构建学生数字素养能力模型、构建数字素养评价任务模型、根据专家经验初步确定证据规则,以及开发情境任务测评系统四个环节。
第一,构建学生数字素养能力模型。学生数字素养评价标准是构建评价能力模型的基础。首先,检索国内外学生数字素养评价标准/框架,在考虑我国学生数字素养培育现状与发展需求的基础上,进行关键词提取、整理与合并,形成学生数字素养评价标准初稿。其次,选取一定数量的领域专家,开展多轮次专家咨询,逐步修订、完善评价标准。最后,深入分析并厘清学生数字素养评价指标的外部行为表现,由此确定每个评价指标对应的可观测变量,界定这些可观测变量的操作性定义,建立数字素养能力模型。
第二,构建数字素养评价任务模型。对于知识和情感态度层面的测量,适合开发应答性任务以快速、准确地进行评分和比较,如判断题、多项选择题等;对于信息检索、获取等基本技能的测量,适合开发操作性任务以引发学生的真实操作,如连线题、拖拽题等;对于计算思维等高阶能力的测量,适合开发益智类任务以捕捉学生的思维,如迷宫题等。在情境设计方面,可以设计分裂式情境,即不同任务的情境相互独立;也可以设计连续性情境,将所有任务嵌入其中,营造沉浸式的测评体验。
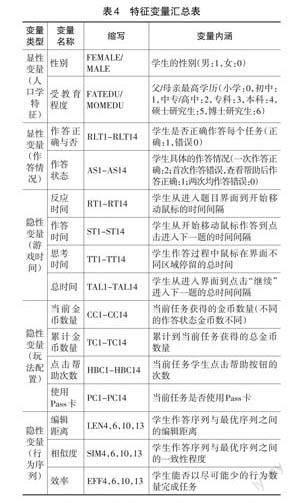
第三,根据专家经验初步确定证据规则。专家需要确定每个评价指标对应的特征变量及其计分方式。从先前的研究中发现,这些特征变量包括但不限于:学生的人口学特征,如性别、年龄、父母受教育程度等能够预测学生数字素养水平的因素(Hatlevik et al.,2018);学生的作答情况,即学生是否完成任务或任务结果是否正确,这是心理测量学已证实的有效证据;测评日志文件中的时间变量,如学生作答任务花费的时间等能预测能力表现的变量(Michaelides et al.,2020)。
第四,开发情境任务测评系统。首先,需厘清测评系统在内容呈现、数据采集、人机交互等方面的需求,然后进行系统的框架设计,包括处理流程、组织结构、模块划分、功能分配、接口设计、数据结构设计等。一方面要有效呈现任务模型,另一方面要具备过程性数据分布式采集与存储功能,以便提取证据。其次,在框架设计的基础上进行编码开发,并对开发完成的系统进行测试,逐渐完善系统的界面、配置、性能、数据库等,确保系统的安全性、稳定性以及满足需求的并发数量。
2.技术驱动的数据挖掘推理
计算心理测量视域下的数字素养测评在以证据为中心设计的理论驱动基础上,采取自下而上的技术驱动的方式进行数据挖掘,从低层级、细粒度的行为序列数据中逐步提取新的证据,来验证测评的效度。具体过程包括采集情境任务点击流数据、从点击流数据中提取特征变量、筛选关键特征变量、构建测量模型实现精准评价四个环节。
第一,采集情境任务点击流数据。点击流数据是指学生在与系统交互的过程中,经由鼠标点击形成的细粒度行为数据,能够反映学生的操作经历,蕴含丰富的评价信息(李爽等,2021)。xAPI技术规范是采集点击流数据的常用手段,它以(任务)为核心,记录学生在某一情境中的行为动作、行为操作的对象、使用的工具以及行为发生的时间戳(顾小清等,2014)。计算心理测量视域下的学生数字素养评价可以采用xAPI技术规范,通过编写xAPI数据采集框架,以一定的格式语句描述学生完成任务的点击行为,实现学生点击流行为数据的实时追踪、采集和存储。
第二,从点击流数据中提取特征变量。基于xAPI技术规范的点击流数据具有时序特征,从这些去情境化的细粒度行为数据中提取的特征变量有两种常见类型:一是关注某一时刻的行为状态,直接提取或通过简单的数学运算提取其状态特征,如某项任务的作答得分情况、某项任务的花费时间等;二是基于时序性的行为序列数据,如拖拽、连线等行为序列,计算学生行为序列与最优行为序列之间的差距,可以反映学生思维的复杂性、完成任务的效率等。
第三,筛选关键特征变量。提取出的特征变量可能存在与评价指标间相关性较低、解释性较差等问题,因此需要筛选关键特征变量。首先,整合特征变量,进行缺失值处理、无效数据剔除、数据降噪、数据标准化等工作。其次,进行效度验证,剔除与评价指标相关性较低或可解释性较差的特征变量。可以利用机器学习方法(如递归特征消除、方差过滤、卡方过滤、F检验、互信息等)自动筛选出与数字素养相关性较高且不存在高度共线性的关键特征。最后,将筛选出的关键特征与学生数字素養能力模型的各个指标建立映射关系。
第四,构建测量模型实现精准评价。首先,选择多种机器学习模型作为候选测量模型,经训练和验证后得到最优模型。其次,计算心理测量视域下的数字素养测评范式遵循“理论模型—数据采集—变量挖掘—指标映射—测量模型”的闭环推理逻辑,根据每一轮测量模型的预测结果可以精准定位到难度过高、过低等设计不良的情境任务,促进测评任务的修订;可以优化数据采集框架,丰富数据采集点;还可以发现新的变量挖掘方法。最后,经过循环迭代,将形成精准的、稳定且成熟的学生数字素养测量模型,进而应用到不同场景的学生数字素养测评实践中。
四、计算心理测量视域下的学生数字素养测 评设计
1.学生数字素养测评能力模型设计
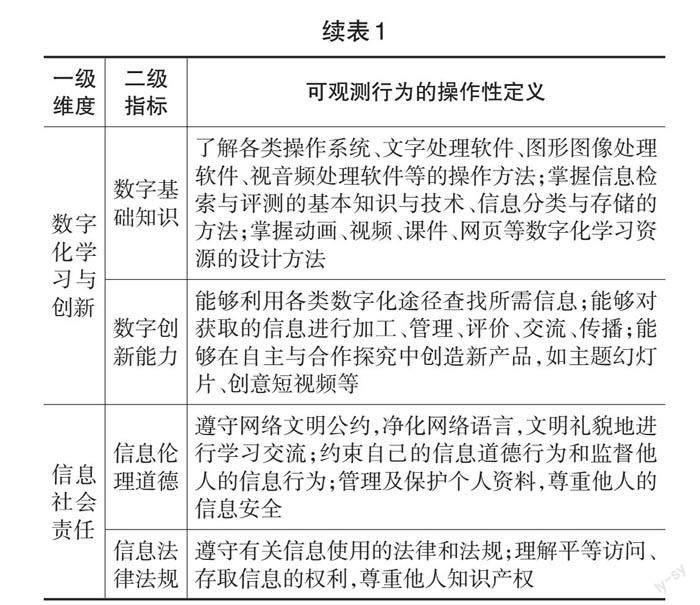
《义务教育信息科技课程标准(2022年版)》指出了数字素养的4个一级维度:信息意识、计算思维、数字化学习与创新、信息社会责任,同时对每个一级维度进行了内涵阐释(中华人民共和国教育部,2022)。基于这4个维度,研究团队首先整合了国际权威数字素养标准/框架,如欧洲共同体DigEuLit数字素养框架(Martin et al.,2006)、欧盟数字素养框架1.0/2.0(Ovcharuk,2020)、联合国全球数字素养框架(Law et al.,2018)、数字智能联盟数字智商(DQ)全球标准(Park,2019)等,对这些标准/框架的指标进行关键词提取、整理与合并,并结合我国义务教育阶段学生的发展现状和需求,细化了数字素养各维度的二级指标。在此基础上,为了构建可观察、可操作的数字素养能力模型,需要进一步细化指标对应的可观测行为表现。其次,研究分析了学生数字素养评价指标的内涵及其相互关系,厘清了各评价指标与其能力表现的实质性联系,确定了每个评价指标对应的行为表现特征,界定了每个评价指标的可观察行为及其操作性定义,形成了学生数字素养评价能力模型初稿。再次,研究采取德尔菲法向10余名领域内的专家进行了意见咨询,根据专家每一轮意见修订能力模型并再次征询意见,直到所有专家对于维度、指标、可观测行为的操作性定义达成一致。最终,形成的学生数字素养能力模型如表1所示。
2.学生数字素养游戏化测评任务设计
研究基于数字素养能力模型设计了面向小学高年级学段的叙事性数字素养测评游戏“果敢的奇幻星球之旅”(Zhu et al.,2022)。学生将扮演小学生果敢,在“蔚蓝星”的探险之旅中完成一系列数字素养相关任务,以解救被黑客抓起来的人鱼公主并帮助她寻找丢失的夜明珠。游戏设置了14项任务,包含5种题型,表2呈现了所有任务的题型、简介和对应的数字素养二级评价指标。游戏以解题闯关为主,每项任务均设置了帮助机制、金币奖励和Pass卡机制。根据每项任务的完成情况(一次作答正确;首次作答错误,查看帮助后作答正确;两次均作答错误),系统将为学生累计不同数量的金币奖励;学生第一次作答错误,系统将自动给出任务帮助,此后学生可以主动点击帮助按钮(点击帮助会消耗金币);当学生连续作答错误两次,系统将赠送学生一张Pass卡,并强制结束该关卡。
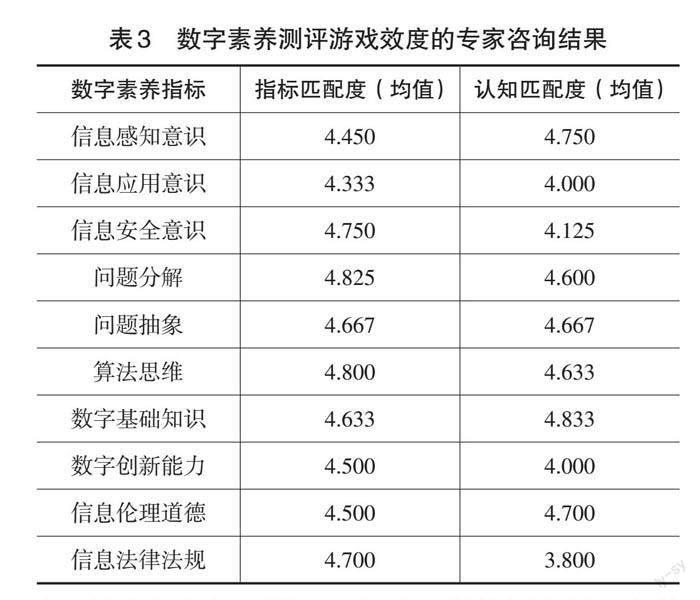
为了验证游戏的内容效度,研究通过专家咨询法,选取了10余名领域内的专家,采取五点计分方式收集其对测评任务所考查的指标的认可程度(即指标匹配度)。同时由于研究选择四年级学生参与测评,因此还向专家咨询了游戏任务是否符合四年级学生的认知水平(即认知匹配度)。咨询结果见表3。整体来看,本研究设计的游戏化任务与数字素养各评价指标之间的匹配程度较高,也符合四年级学生的认知水平。
3.学生数字素养游戏化测评特征变量设计
(1)基于专家经验的预定义证据规则
已有研究将特征变量划分为显性和隐性两类(孙建文等,2022)。本研究采用了此种划分方式,其中显性变量包括两类:一是人口学特征变量。先前研究表明,性别、年龄、父母受教育程度是影响学生数字素养表现的关键人口因素(Hatlevik et al.,2018),由于本研究以四年級学生为样本,学生年龄差距较小,因此不考虑该因素。纳入本研究的人口学特征变量为性别、父母受教育程度。二是学生在每一项游戏化任务上的作答情况,例如作答正确与否、作答状态。
隐性变量也包括两类:一是被研究者广泛关注的时间变量,例如学生完成任务花费的总时间、实际作答时间、反应时间、思考时间等。二是与游戏配置相关的数据,例如当前任务获得金币数量、累积到当前任务获得的总金币数量、点击帮助的次数、当前任务是否获得Pass卡等。
(2)基于行为序列的特征变量挖掘
除了上述由专家确定的特征变量,对于迷宫题、连线题和拖拽题等操作较为复杂的游戏任务,研究还采集了学生作答的操作行为序列。针对这些行为序列可以自下而上地挖掘出一些新的隐性变量,包括学生行为序列与最优行为序列之间的编辑距离、相似度、效率等。编辑距离是指将学生作答的行为序列转换为最优行为序列所需的最小插入、删除和替换的操作总数;相似度表示学生的行为序列偏离最优行为序列的程度;效率衡量了学生能否以尽可能少的行为数量完成任务。这些基于行为序列提取的特征变量可以更准确地区分作答结果相同的学生,体现其在数字素养水平上的差异。综合自上而下由专家确定的证据以及自下而上从过程性数据中挖掘的证据,表4呈现了数字素养测评所有的特征变量。
五、计算心理测量视域下学生数字素养测评 实践
1.测评实证研究设计
参与本次测评的学生来自武汉市某小学四年级随机选取的三个班级,共计125名,其中男生46人,女生79人。测评工具包括两部分:一是研究团队开发的“果敢的奇幻星球之旅”数字素养测评游戏,二是研究团队面向小学中高学段开发的数字素养标准化测试题。该套测试题多次用于全国大规模学生数字素养测评项目,已经被证明具有良好的信效度、难度、区分度等指标,具有较高的效标价值(余丽芹等,2021)。本次测评结果也将作为本研究测量模型的标签。
测评在该小学的计算机实验室进行,由各班信息技术教师组织。在测评开始前,信息技术教师向学生告知测评目的并强调操作规则、浏览器设置以及其他注意事项,并通过教师端计算机向学生统一发送测评链接。接着,学生打开测评链接,填写个人信息并完成数字素养标准化测试题。最后,学生提交标准化测验答卷,按照情境顺序完成游戏化任务。测试需在40分钟内完成。
2.指标映射关系建立
对于采集的所有特征变量,使用Python3.8的Pandas包和Scikit-Learn包进行预处理,包括将具有连续性意义的特征变量标准化,以加快后续模型训练速度,提高准确率,并对特征变量进行缺失值填补。对于标准化测验的结果,研究参考国内外关于学生KSAs预测的做法将学生的测验成绩进行二值化等宽分箱,作为标签变量(Hautala et al.,2020)。根据研究团队多次开展的大规模学生数字素养测评经验,小学生数字素养得分主要集中在中等和较高水平,处于较低水平的学生比例极少,采用二值化等宽分箱处理符合小学生数字素养特征。
完成数据预处理之后,借助Scikit-Learn包进行特征变量的效度验证和关键特征的自动筛选。研究采用递归特征消除和互信息两种方法进行特征变量筛选。对于决策树、随机森林、逻辑回归、XGBoost等能够返回特征重要性的模型,使用5折交叉验证的递归特征消除法识别最优特征变量组合;对于支持向量机、朴素贝叶斯等不返回特征重要性的模型,采用互信息法衡量每个特征变量与标签之间的相关性,筛选互信息值较高的特征变量。经过特征筛选得到每个二级维度与特征变量之间的映射关系如表5所示。
3.测量模型构建
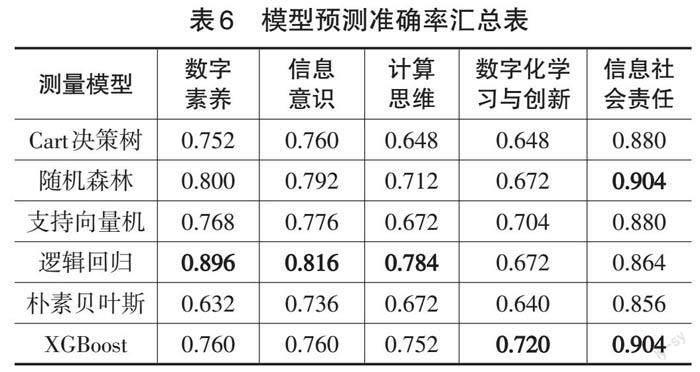
研究选取6种机器学习模型建立数字素养及各一级维度的测量模型。首先,采取5折交叉验证的网格搜索(GridSearchCV,cv=5)进行模式参数调节,以自动识别最优参数组合。由各模型的预测准确率(如表6所示)可知:对于数字素养,预测效果最好的模型是逻辑回归,准确率达到了89.6%;其对信息意识的预测準确率达到81.6%,对计算思维的预测准确率达到78.4%。XGBoost预测数字化学习与创新的准确率最高,达到72.0%。随机森林和XGBoost预测信息社会责任的准确率最高,均达到90.4%。整体来看,本研究的游戏化测评任务得到了相对精准的测评结果。
4.测评应用结果分析
(1)游戏化测评整体结果分析
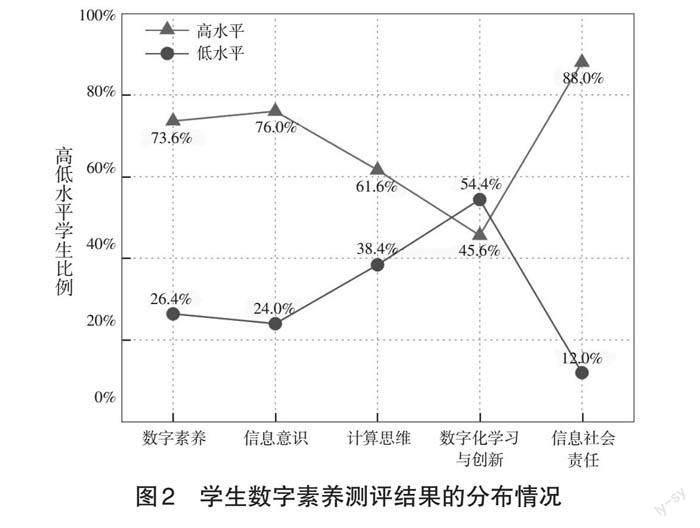
使用上述最佳测量模型的预测结果,本研究绘制了学生数字素养总体水平以及各一级指标表现水平的分布情况,如图2所示。可见,参与游戏化测评的学生数字素养整体表现良好,73.6%的学生达到了较高的数字素养水平。然而,学生在数字素养各维度的表现并不均衡,学生在信息社会责任方面表现最好(高水平学生占比达88.0%),在信息意识方面表现较好(高水平学生占比达76.0%),在计算思维方面表现一般(高水平学生占比达61.6%),而在数字化学习与创新方面表现较差(高水平学生占比低于50%)。
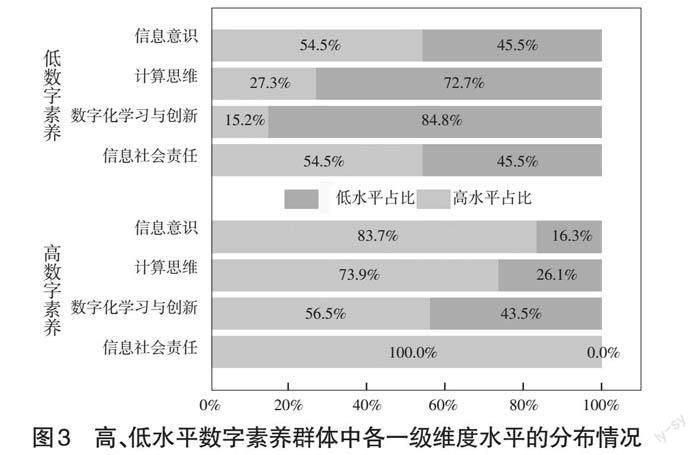
研究基于预测结果进一步计算了高、低水平数字素养群体中,各一级维度水平的分布情况,如图3所示。分析发现,在高水平数字素养的群体中,学生通常具备较高的信息意识(高水平占比达83.7%)、计算思维(高水平占比达73.9%)以及信息社会责任(高水平占比达100%);然而高水平数字素养的学生不一定具备较高水平的数字化学习与创新(高水平占比仅56.5%)。在低水平数字素养群体中,学生通常具备较低水平的数字化学习与创新(低水平占比达84.8%)和计算思维(低水平占比达72.7%);而低水平数字素养的学生也可能具备较高水平的信息意识(高水平占比达54.5%)和信息社会责任(高水平占比达54.5%)。
(2)游戏中过程性行为特征分析
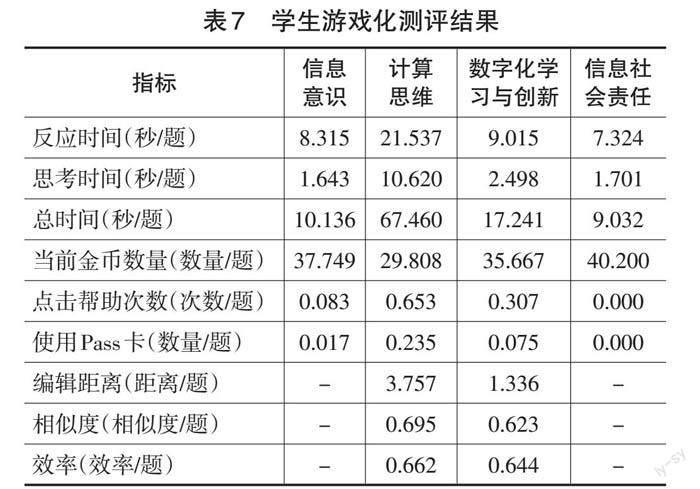
研究还分析了学生在游戏中的过程性行为,具体结果如表7所示。分析发现,关于游戏时间,不论是反应时间、思考时间还是总时间,学生都是在计算思维题目上耗时最多。在玩法配置方面,学生在计算思维题目上平均获得金币数量最少,点击帮助次数和使用Pass卡数量最多。在行为序列方面,仅计算思维、数字化学习与创新两个维度设计了可以采集行为序列的拖拽题、迷宫题和连线题。其中作答计算思维题目的行为序列编辑距离比数字化学习与创新题目更大,行为序列的相似度和效率差异则较小。这意味着学生在回答计算思维题目时,其行为序列与最优行为序列之间的偏离程度更大。然而,测评的整体结果显示,学生在计算思维上总体表现优于数字化学习与创新,这是因为解决计算思维问题对学生而言更具挑战性,他们倾向于花费更多时间、做出更多尝试以解决问题,因此造成行为序列编辑距离较大,得分表现却较好的结果。
表7 学生游戏化测评结果
[指标 信息
意识 计算
思维 数字化学习与创新 信息社会责任 反应时间(秒/题) 8.315 21.537 9.015 7.324 思考时间(秒/题) 1.643 10.620 2.498 1.701 总时间(秒/题) 10.136 67.460 17.241 9.032 当前金币数量(数量/题) 37.749 29.808 35.667 40.200 点击帮助次数(次数/题) 0.083 0.653 0.307 0.000 使用Pass卡(数量/题) 0.017 0.235 0.075 0.000 编辑距离(距离/题) - 3.757 1.336 - 相似度(相似度/题) - 0.695 0.623 - 效率(效率/题) - 0.662 0.644 - ]
综合整体测评结果和游戏中的行为表现,本研究发现大部分小学高段学生已经初步具备了信息意识,对信息具有比较敏锐的判断力,能遵守网络道德行为规范与法律法规。然而在基本信息科学的相关概念、原理及创新能力方面还略显不足,且在面对具有复杂操作的情境任务时,学生的思维过程更加复杂,花费更长时间,更倾向于获取帮助,且作答准确率更低,说明学生还较为缺乏解决问题的高阶思维能力。整体而言,上述研究结果与研究团队前期开展的大规模标准化测评结果相似(余丽芹等,2021)。
六、结语
本研究基于计算心理测量理论,构建了双向驱动的学生数字素养测评框架,并基于此框架开展了实践探索,是计算心理测量理论从理论走向实践的尝试,为后续开展过程性评价提供了借鉴和参考。本研究的主要贡献有以下三方面:一是突破传统心理测量范式下学生数字素养评价内容单一、评价结果信效度低的桎梏,构建了计算心理测量视域下学生数字素养测评框架,并首次尝试将点击流数据引入学生数字素养评价。二是设计并开发了学生数字素养游戏化测评任务及系统,能有效捕捉学生的思维过程,为评价学生数字素养水平提供了更加丰富可靠的证据。三是开展了计算心理测量视域下的学生数字素养测评实践,总体上取得了良好的评价效果。与传统评价仅关注作答结果相比,本研究将基于技术驱动的方法从点击流数据中挖掘出的诸多特征变量作为关键预测特征,如金币数量、点击帮助次数、行为序列相似度等,结合理论驱动所定义的人口学特征、作答情况、作答时间等特征变量,有效提高了测量模型的准确率,证实了计算心理测量视域下数字素养测评的实践效度。
本研究依然存在一些局限。一是样本量较小、数据模态有限,未来的研究可在本研究基础上开展更大范围的实践,同时考虑采集眼动、脑电、音视频、语言文本等多模态数据,使学生数字素养评价的证据更加丰富。二是本研究的任务分布略不均衡,部分指标的游戏任务较少,导致这些指标的映射特征较少。未来可进一步设计更加丰富的游戏任务,确保各指标具有相对均衡的任务数量,并开展更多轮次的测评,验证并不断优化游戏任务,提高测评结果的可靠性。三是本研究将标准化测验结果作为机器学习建模的标签,可能在测试时存在一些随机误差。尽管大规模的测评已证实本研究所采用的标准化测验可作为可靠的效标,但为了减小误差,未来的研究还可以考虑整合多模态数据,探索学生数字素养水平的智能化评价技术。
参考文献:
[1]戴一飞(2016).效度论证范式下的ECD测试设计框架——我国教育考试国家题库的升级路径之一[J].中国考試,(11):28-37.
[2]顾小清,郑隆威,简菁(2014).获取教育大数据:基于xAPI规范对学习经历数据的获取与共享[J].现代远程教育研究,(5):13-23.
[3]李美娟,刘红云,张咏梅(2022).计算心理测量理论在核心素养测评中的应用——以合作问题解决测评为例[J].教育研究,43(3):127-137.
[4]李爽,郑勤华,杜君磊等(2021).在线学习注意力投入特征与学习完成度的关系——基于点击流数据的分析[J].中国电化教育,(2):105-112.
[5]孙建文,胡梦薇,刘三女牙等(2022).多维异步在线讨论行为特征分析与学习绩效预测[J].中国远程教育,(5):56-63.
[6]吴砥,朱莎,王美倩(2022a).学生数字素养培育体系的一体化建构:挑战、原则与路径[J].中国电化教育,(7):43-49,63.
[7]吴砥,余丽芹,朱莎(2022b).智能时代中小学生信息素养评价的主要挑战与实施路径[J].人民教育,(5):44-48.
[8]余丽芹,索峰,朱莎等(2021).小学中高段学生信息素养测评模型构建与应用研究——以四、五年级学生为例[J].中国电化教育,(5):63-69,101.
[9]郑勤华,陈丽,郭利明等(2022).理论与技术双向驱动的学生综合素养评价新范式[J].中国电化教育,(4):56-63.
[10]中华人民共和国教育部(2022).教育部关于印发义务教育课程方案和课程标准(2022年版)的通知[EB/OL].[2022-10-07].http://www.moe.gov.cn/srcsite/A26/s8001/202204/
W020220420582361024968.pdf.
[11]中央网络安全和信息化委员会办公室(2021).提升全民数字素养与技能行动纲要[EB/OL].[2022-10-07].http://www.cac.gov.cn/2021-11/05/c_1637708867754305.htm.
[12]朱莎,吴砥,杨浩等(2020).基于ECD的学生信息素养评价研究框架[J].中国电化教育,(10):88-96.
[13]AERA, APA & NCME (1999). Standards for Educational and Psychological Testing[M]. New York: American Educational Research Association:9-25.
[14]Cipresso, P., Colombo, D., & Riva, G. (2019). Computational Psychometrics Using Psychophysiological Measures for the Assessment of Acute Mental Stress[J]. Sensors, 19(4):781.
[15]Delgado-Gómez, D., Sújar, A., & Ardoy-Cuadros, J. et al. (2020). Objective Assessment of Attention-Deficit Hyperactivity Disorder (ADHD) Using an Infinite Runner-Based Computer Game: A Pilot Study[J]. Brain Sciences, 10(10):716.
[16]Hansen, J. G., & Liu, J. (1997). Social Identity and Language: Theoretical and Methodological Issues[J]. Tesol Quarterly, 31(3):567-576.
[17]Hatlevik, O. E., Throndsen, I., & Loi, M. et al. (2018). Students’ICT Self-Efficacy and Computer and Information Literacy: Determinants and Relationships[J]. Computers & Education, 118:107-119.
[18]Hautala, J., Heikkilä, R., & Nieminen, L. et al. (2020) Identification of Reading Difficulties by a Digital Game-Based Assessment Technology[J]. Journal of Educational Computing Research, 58(5):1003-1028.
[19]Holland, J. H. (2006). Studying Complex Adaptive Systems[J]. Journal of Systems Science and Complexity, 19(1):1-8.
[20]Kane, M. T. (2001). Current Concerns in Validity Theory[J]. Journal of Educational Measurement, 38(4):319-342.
[21]Law, N., Woo, D., & Wong, G. (2018). A Global Framework of Reference on Digital Literacy Skills for Indicator 4.4.2[EB/OL]. [2022-10-07]. https://unesdoc.unesco.org/ark:/48223/pf0000265403.
[22]Martin, A., & Grudziecki, J. (2006). DigEuLit: Concepts and Tools for Digital Literacy Development[J]. Innovation in Teaching and Learning in Information and Computer Sciences, 5(4):249-267.
[23]Michaelides, M. P., Ivanova, M., & Nicolaou, C. (2020). The Relationship Between Response-Time Effort and Accuracy in Pisa Science Multiple Choice Items[J]. International Journal of Testing, 20(3):187-205.
[24]Mislevy, R. J. (2021). Next Generation Learning and Assessment: What, Why and How[M]// Von Davier, A. A., Mislevy, R. J., & Hao, J. (Eds). Computational Psychometrics: New Methodologies for a New Generation of Digital Learning and Assessment. Switzerland: Springer, Cham:9-24.
[25]Mislevy, R. J., Almond, R. G., & Lukas, J. F. (2003). A Brief Introduction to Evidence-Centered Design[R]. Princeton, NJ: ETS Research & Development Division.
[26]Ovcharuk, O. (2020). European Strategy for Determining the Level of Competence in the Field of Digital Technologies: A Framework for Digital Competence for Citizens[J]. Educational Dimension, 3:25-36.
[27]Park, Y. (2019). Common Framework for Digital Literacy, Skills and Readiness[R]. DQ Global Standards Report.
[28]Polyak, S. T., Von Davier, A. A., & Peterschmidt, K. (2017). Computational Psychometrics for the Measurement of Collaborative Problem Solving Skills[J]. Frontiers in Psychology, 8:2029.
[29]Snow, E., Rutstein, D., & Basu, S. et al. (2019). Leveraging Evidence-Centered Design to Develop Assessments of Computational Thinking Practices[J]. International Journal of Testing, 19(2):103-127.
[30]Vatutin, A., Moskalenko, M., & Skryabin, M. et al. (2021). Computational Psychometric Approach for Assessing Mathematical Problem-Solving Skills[J]. Procedia Computer Science, 193:250-255.
[31]Von Davier, A. A. (2017). Computational Psychometrics in Support of Collaborative Educational Assessments[J]. Journal of Educational Measurement, 54(1):3-11.
[32]Zhu, S., Bai, J., & Zhang, M. et al. (2022). Developing a Digital Game for Assessing Primary and Secondary Students’Information Literacy Based on Evidence-Centered Game Design[C]// Lee, L K., Hui, Y K., & Mark, K P. et al. (2022). 2022 International Symposium on Educational Technology (ISET). Hong Kong: IEEE:173-177.
收稿日期 2023-03-13 責任编辑 汪燕
Evaluation of Students’Digital Literacy from a Computational Psychometric Perspective
ZHU Sha, GUO Qing, WU Di
Abstract: Regular monitoring and assessment of digital literacy development is the foundation and premise for enhancing the digital literacy of the entire population. Currently, the evaluation of students’ digital literacy primarily adheres to the classical measurement view of “assigning values to potential traits based on rules”, mainly utilizing standardized tests and self-reported scales as assessment tools. This approach faces limitations such as restricted evaluation content and one-sided evaluation methods. Computational psychometrics offers new theoretical and methodological support to solve the challenges in evaluating students’ digital literacy. It advocates for the combined use of research methods from multiple disciplines, including psychometrics and computer science, embedding assessment in real-world tasks to stimulate and track interaction between subjects and contexts. Through the collection and analysis of multi-source heterogeneous data, a process-oriented evaluation is realized. The evaluation framework for students’ digital literacy from the computational psychometrics perspective, guided by an evidence-centered design philosophy, constructs a reasoning chain combining top-down theoretical drive and bottom-up technology drive. It builds complex task scenarios to gather fine-grained data and uses data mining techniques to extract evidence from vast amounts of detailed data, thereby achieving precise evaluation. The practice of digital literacy assessment for upper elementary grades, conducted with this framework, demonstrates that this assessment paradigm helps form a closed-loop reasoning chain from the “capability model” of digital literacy to the “measurement model”. After multiple iterations of optimization, it can produce high-quality digital literacy assessment tasks, reliable evidence of students’ digital literacy and a stable measurement model.
Keywords: Computational Psychometrics; Evidence-Centered Design; Digital Literacy Evaluation; Gamified Assessment
