
专利视域下融合协同过滤与链路预测的企业潜在合作关系预测研究*
2023-12-23 03:46:30周志刚窦路遥
情报杂志 2023年12期
周志刚 窦路遥 李 毅
(山西财经大学信息学院 太原 030006)
0 引 言
创新驱动背景下,企业间技术合作将成为突破“技术枷锁”束缚的关键内驱力和解决“卡脖子”难题的重要落脚点,精准识别企业间潜在的技术合作关系能够加快聚合创新要素、逐步组建技术团体以及建立健全协作体系,对于优化国家创新合作环境和激发创新主体研发活力发挥着至关重要的作用。然而,在企业潜在合作关系预测的过程中,仍面临关系判别误差较大和关系识别依据单一的阻碍,导致预测结果在面向合作实践领域时表现出较强的不确定性。基于上述背景,如何融合多维合作关系影响指标,并借助逻辑走向为主的技术方法,继而实现企业潜在合作关系的有效预测已成为当前亟待解决的重要问题。
在文本挖掘层面,专利文献中包含的技术文本内容与IPC分类号可以作为企业合作关系的客观判断标准;在合作网络层面,企业间潜在的链接可能性关系能够为潜在合作关系预测提供概率分布。因此,从文本挖掘和合作网络的混合视角出发,有助于在全局层面把握企业潜在合作关系的外部实践判别依据和内部随机游走逻辑,实现预测结果准确化、系统化以及规则化的表达。精准而有效的企业潜在合作关系预测模式能够为企业技术合作提供方法支持和决策支撑,对于落实创新发展战略、塑造技术产业结构、扩大关键技术优势具有重要的现实意义。
1 文献综述
情报领域所指的潜在合作关系,一般指研究主体有可能产生合作但未产生实际合作的隐藏关系。细化到企业专利概念范畴,企业潜在合作关系预测的相关研究则集中于专利合作模式分析、专利内容相似判别、创新网络演化推演等方面。专利合作模式分析方面,周莉等[1]等基于企业间的专利合作历史和次数统计预测企业未来可能的合作伙伴;吕源等[2]通过收集企业、高校、科研机构的专利信息实现产学研关系的识别,并对企业未来的合作领域进行了预测;袁晓东等[3]借助合作专利中既存的引用关系对企业间的技术合作和市场话语权关系进行了推演。专利内容相似判别多从词频分布、语义信息、上下文关联等视角进行探讨。周志刚等[4]从技术生命周期理论入手,结合专利文本词频的概率表达情况判断企业竞合关系;胡凯等[5]借助LDA模型识别专利文本中的技术主题,以此发现企业关键应用技术的落脚点;赵展一等[6]融合专利类别与语义信息识别企业间的匹配关系;夏冰等[7]联合词位置和语义信息识别企业间合作关系的判断逻辑。张金柱等[8]构建基于表示学习的无监督跨语言专利推荐方法,提升了企业间合作关系预测精度;吴红等[9]测度专利标引词在企业文本的映射程度,明晰了专利与企业关联规则的量化规律。创新网络演化推演多关注于网络结构和领域合作,岑杰[10]以373家战略性新兴企业为研究样本,通过专利合作网络相对中心度分析企业合作特征。衣春波等[11]以集成电路领域专利数据构建企业、产学研、关系特征演化网络,从整体、网络特征等层面分析该领域网络演化规律。傅俊英等[12]通过计算得来的专利权人间的技术相似性,构建石墨烯专利异构网络对合作伙伴进行评估与检验。
企业潜在合作关系的预测方法聚焦于专利网络分析、专利文本挖掘与关联规则分析、链路预测等。Wang等[13]结合专利文献计量和社会网络分析,洞察半导体公司合作网络结构和知识溢出渠道。Scherngell等[14]统计专利权人合作频次与概率分布,以专利网络预测不同专利权人间再次合作的可能性大小。同时,也有学者融合专利网络演化[15]、专利地域[16],诉讼关系[17]等,预测企业间潜在存在的网络关系。在专利文本挖掘上,李欣等[18]融合分词思想与向量化表达来刻画企业间潜在合作关系;吕源等[2]利用k-means聚类和特定语义分析识别技术主题,并根据主题相似度评估企业的潜在合作关系;赵展一等[6]利用向量化后的专利相似度度量中小企业的潜在合作伙伴;唐焕玲等[19]发现专利提取精度层面的技术进步促进了企业潜在合作关系的发展;曹晨等[20]基于LDA模型并结合文档词袋特征表达,探讨创新型企业的合作发展预期。李冰等[21]以二部图理论,构建异质网络,利用随机游走链路预测算法对企业潜在关系进行预测判断和实证分析。
综上所述,现有研究虽然在企业潜在合作关系预测领域提供了丰富的理论基础,但是仍存在有待完善之处。其一,当前研究多围绕专利文本内容相似性进行讨论,鲜有研究从“专利文本+专利类别+网络路径”的多元视角上探讨企业潜在合作的实践匹配关系;其二,现有研究多聚焦以既存合作关系为基础的预判和以科学计量理念为依据的推演,忽视了合作网络中链接权重与专利文献中内容类别的间接相关性;其三,分析内容多落脚在方法精度与设计思路上的逻辑闭环,缺乏实践领域上客观具体的案例分析和实证检验。
基于此,本文做出如下创新:①研究思路上,将基于专利合作网络的链路预测思想与基于“企业-专利”关系的协同过滤思想进行融合,结合IPC号自带的序列相似特点,形成“连接强度+匹配程度+相似度”的多维复合体系。②研究方法上,借助SVD奇异值分解实现协同过滤与链路预测方法的聚合,通过矩阵分解的方式完成多维度性质的组合,全面覆盖企业潜在合作关系预测的关键性权重节点。同时,构建矩阵格值密度作为测试算法精准度的检验方法。③研究内容上,选取非晶合金领域作为实证分析案例,与现阶段我国创新驱动的战略需求相匹配,有助于相关创新主体的协同合作和领域技术进步。
2 研究设计
2.1 研究方法
2.1.1 协同过滤推荐算法
基于“用户-物品”的协同过滤推荐算法映射到“企业-专利”上时,其算法原理解释为:①基于企业的协同过滤:企业间对类似专利会产生关注偏好[22];②基于专利的协同过滤:相近企业关注部分专利发展,则目标企业同样关注这部分专利发展或者关注类似专利发展[23]。其中协同过滤算法的理解如图1所示:
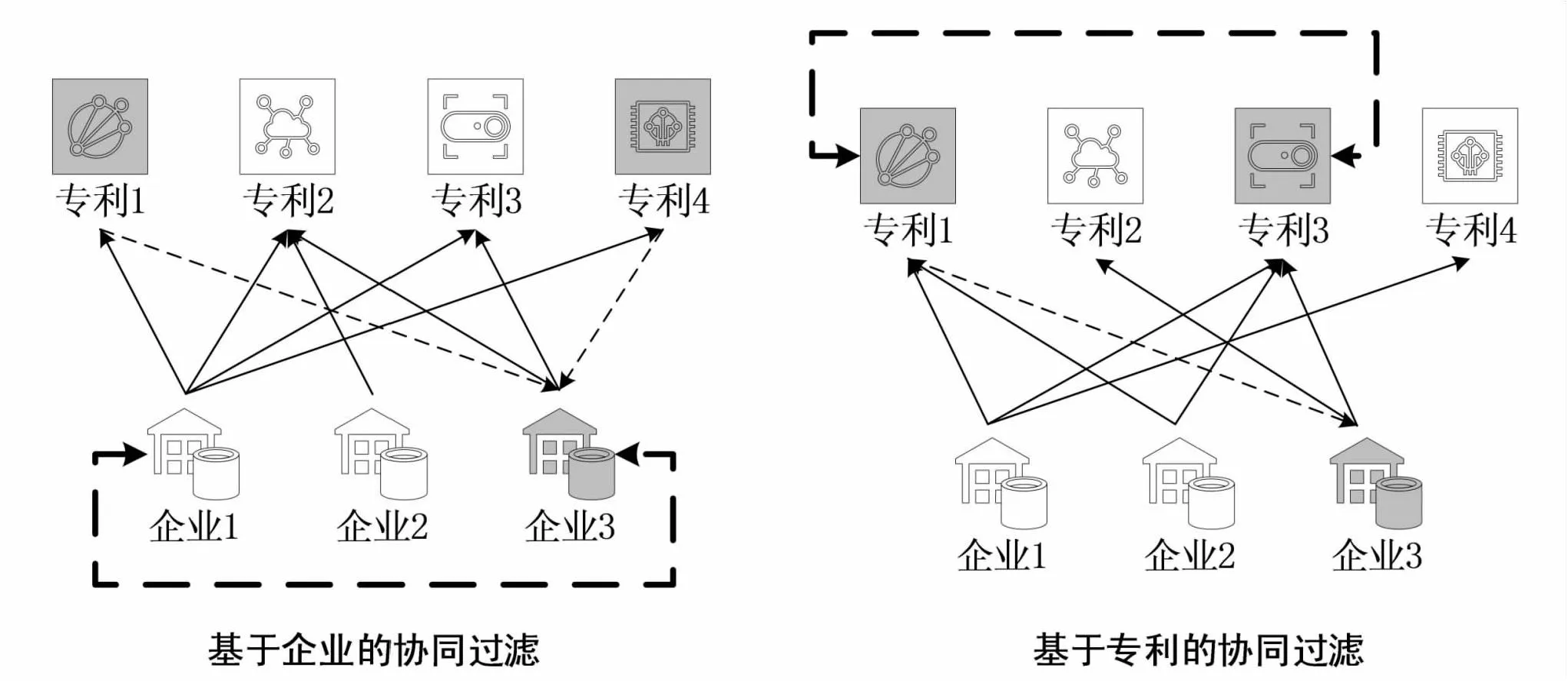
注:粗虚线为协同过滤基础条件,细虚线为算法逻辑推演。图1 协同过滤算法图解
然而,随着企业与专利文本的数量日趋上涨,企业关注的专利数量在整体专利数量的占比逐渐下降,导致企业与专利间关系矩阵的数据极端稀疏,使得推荐算法的推荐质量降低。在实际操作中,通常采用SVD奇异值分解来解决稀疏矩阵的问题[22]。对初始特征矩阵进行奇异值分解:
Mm×n=Um×m*(Zm×n)*(Vn×n)T
(1)
U是m×m的酉矩阵,∑是m×n的对角矩阵,V是n×n的酉矩阵。Z对角线上是M的奇异值,将奇异值从大到小进行排列,前r个奇异值满足式(1)时,Z就可以只保留前r列、前r行,即m×n维变成r×r维,而U选取前r列,选取前r行,因此M就可以分解为:
Mm×n≈Um×r*(Zr×r)*(VT)r×n
(2)
而“企业-专利”矩阵分解流程为:①构建企业与专利关联关系矩阵,按照专利关注度进行权重分配继而完成矩阵格值填充,结合权重指标对矩阵格值进行归一化处理并形成观测举证。②依据矩阵分解流程将观测矩阵进行因子分解,利用低维矩阵相乘无限逼近观测矩阵,继而形成预测矩阵。矩阵分解示例详见图2。

图2 协同过滤矩阵分解图例
2.1.2 链路预测
链路预测是一种用于预测网络中节点之间链路存在或不存在的方法[24]。在基于专利的企业合作关系研究中,通过神经网络实现企业节点特征的聚合与更新,再使用链接预测层来计算企业节点间的合作概率,最后使用Sigmoid函数来输出企业间潜在合作的概率值。公式表达如下:
(3)
(4)
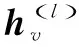
2.2 基于专利文本的内容相似性指标
利用Bidirectional Encoder Representation from Transformers(BERT)[25]进行文本向量化处理与表达,得到专利标题与专利摘要的文本向量,预训练模型采用Google发布的中文BERT-Base,模型的超参数设置如表1所示。

表1 超参数设置
结合Pearson相关系数计算专利文本向量相似度,用来表示专利文本内容的相似程度。其公式表示如下:
(5)
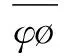
2.3 基于IPC号的类别相似性指标
专利间因共有IPC号而存在技术类别相似性。整体的IPC分类号有5级,分别为部(Section)、大类(Class)、小类(Subclass)、大组(Maingroup)、小组(Subgroup)。其中部用8种字母表示(A/B/C/D/E/F/G/H),大类用2个数字表示,小类用1个字母表示(除去A/Z/I/O/U/X),主组为1~3个数字,分组为除“00”外的2~4个数字。将IPC分类号的5级表示形式替换为“字母-数字”的序列形式(A→1,B→2…Z→26),例如将IPC分类号为B22D17/14(一种非晶合金的压铸成型方法)替换为2 22 04 017 0014,IPC分类号为C22C1/03(一种非晶合金构件及其制备方法)替换为3 22 03 001 0003。
随后利用Smith-Waterman(SW)双序列比对算法[26]进行相似度计算,其算法目的在于寻找序列间的高相似部分,实现局部序列匹配,继而通过专利局部匹配序列与专利全局序列长度的比值进行相似度判断。
2.4 基于链路预测的路径相似性指标
2.4.1 SimRank指标
SimRank指标是指在全局合作网络随机游走的条件下,如果两个企业节点的邻居节点集在特征属性上相似,那么认为这两个企业节点也相似[27]。具体的自洽定义式表达为:
(6)

2.4.2 RA指标
Resource Allocation(RA)指标是指合作网络中的企业节点拥有一定的自有资源,而没有直接关联的企业节点可以通过中介节点(即共同邻居)实现资源传递与流通。同时,该指标还假设所有企业节点会均分自身的节点资源给邻居节点,这与企业通过共享专利进行合作的模式相当接近(即共享专利使用权实现信息资源流通)[27-28],而此时邻居节点所分配到的资源份额则被定义为这两个企业节点的相似度[28]。其公式表达如下:
(7)
(8)
其中Sxy表示节点x和节点y之间的相似度大小,即目标节点y接收到的来自节点x的资源数,Sz表示节点Z接收到的来自其所有邻居节点的资源总数。Γ(x)∩Γ(y)表示节点x和节点y的共同邻居节点集合,WZZ'表示节点Z和其邻居节点Z'之间的权重或资源数。
2.5 融合指标权重
融合内容相似性、类别相似性、路径相似性,构建潜在合作关系的综合指标矩阵,即:
P=(1-α-β)·M+α·N+β·Q
(9)
其中P为融合指标构成的相似度矩阵,M,N,Q分别为内容相似性矩阵、类别相似性矩阵,路径相似性矩阵;1-α-β,α,β分别为矩阵M,N,Q的权重值,α,β∈[0,1]。当α=0,β=0时,融合矩阵实质为内容相似性矩阵;当α=1,β=0时,融合矩阵实质为类别相似性矩阵;当α=0,β=1时,融合矩阵实质为路径相似性矩阵。需要说明的是,为保证后续推荐算法的量纲一致性,对矩阵P格值进行标准化处理,处理方式如下:
(10)
其中P(Δ)为矩阵P的格值大小,P*为标准化后的矩阵P格值。
2.6 研究框架与算法设计
本文综合专利文本、合作网络、IPC号的多方维度,将协同过滤推荐算法与链路预测进行融合,构建“链路推荐”算法框架并进行实证检验与效果评价,流程图如图3所示。
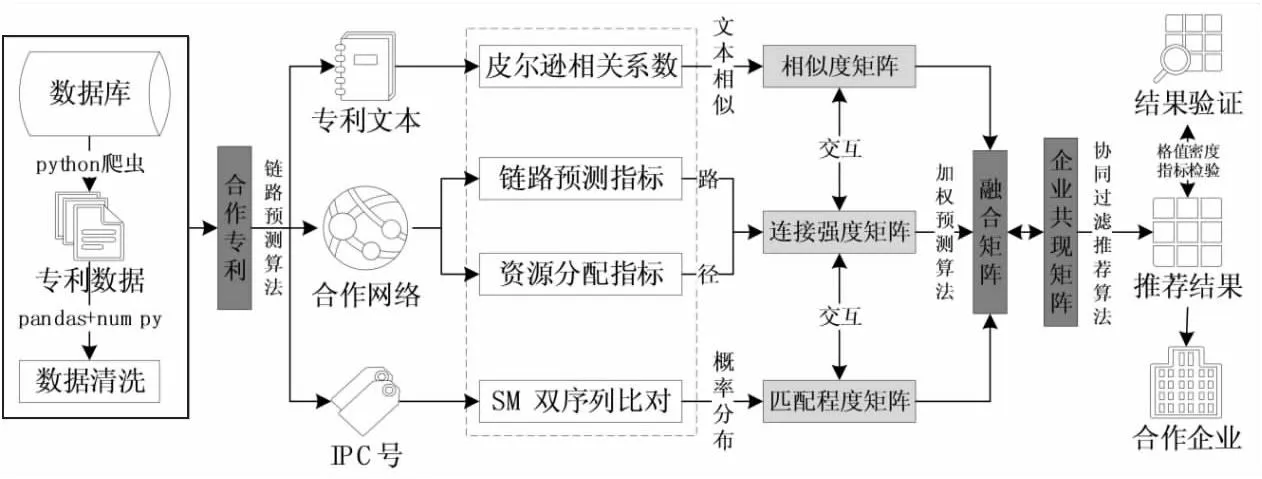
图3 基于“链路推荐”企业潜在合作关系研究框架
其核心算法的伪代码如下:
算法1:“链路推荐”算法
输入:专利数据S;企业合作网络矩阵W;IPC分类号分数矩阵N
输出:合作企业推荐表List(E-TOP2)
1:遍历S中企业专利数据字典,计算文本内容相似度矩阵M;
2:通过W构建企业合作网络关系,计算链路强度SimRank矩阵;
3:计算RA指标大小,输入矩阵G进行序列回溯,匹配序列相关度,制成矩阵Q;
4:输入矩阵N,M,Q,使用决策树+支持向量机获取训练模型1-α-β,α,β;
5:构建融合矩阵P=(1-α-β)·M+α·N+β·Q;
6:输入W和P,构建企业与融合指标映射关系,形成新的相似度矩阵WP;
7:对于相似度矩阵WP中每个元素小于阈值π的位置,将其设置为0;
8:选择相似度值排名前2位的企业进行推荐结果展示,汇总成推荐表List(E-TOP2) 。
3 实证分析
3.1 数据获取与预处理
非晶合金,也称非晶态金属,是一类具有非晶态(无定形结构)特征的金属材料。与晶体金属相比,非晶合金在结构上缺乏长程有序性,其原子排列呈现出无规则、非周期性的特点。非晶合金的应用领域相当广泛,包括电子、航空航天、汽车、能源等领域。被用于制造高性能传感器、电池、导线、磁性材料、结构件等[29-30]。专利数据来源于Incopat专利数据库,截至2022年12月该专利数据库储存专利文献170 763 808件,涉及158个国家地区。从incopat专利数据库中限定时间为2014-2022年,领域为非晶合金,进行数据检索,获得专利共9 854项,除去重复专利和个人专利,部分材料辅助专利,筛选企业间合作专利,获得有效专利共6 564项。鉴于推荐算法是对未来潜在合作关系进行预测,因此对获得的数据集进行划分,将2014-2020年作为推荐算法的输入数据集(训练集),将2021-2022年作为推荐结果的对比数据集(测试集)。
3.2 网络关系构建
基于筛选出合作专利构建企业共现矩阵,随后利用Gephi0.9绘制合作网络图,该网络为无向图,节点代表专利合作企业(见图4),涉及企业844个,关系连线条数为1 056。选取Fruchterman Reingold布局描述非晶合金领域专利合作网络整体架构,依据度值大小对企业节点大小进行排序,其中度值越大则节点越大。企业间合作次数通过连线密集程度表示,其中密集度越大则合作越紧密。计算整体网络密度值为0.002,趋近为0,说明网络上的企业节点关系并不密切,绝大部分企业处于自发独立状态,网络中的专利共享资源未得到充分利用,这也从侧面说明进行潜在合作关系挖掘是有必要的。
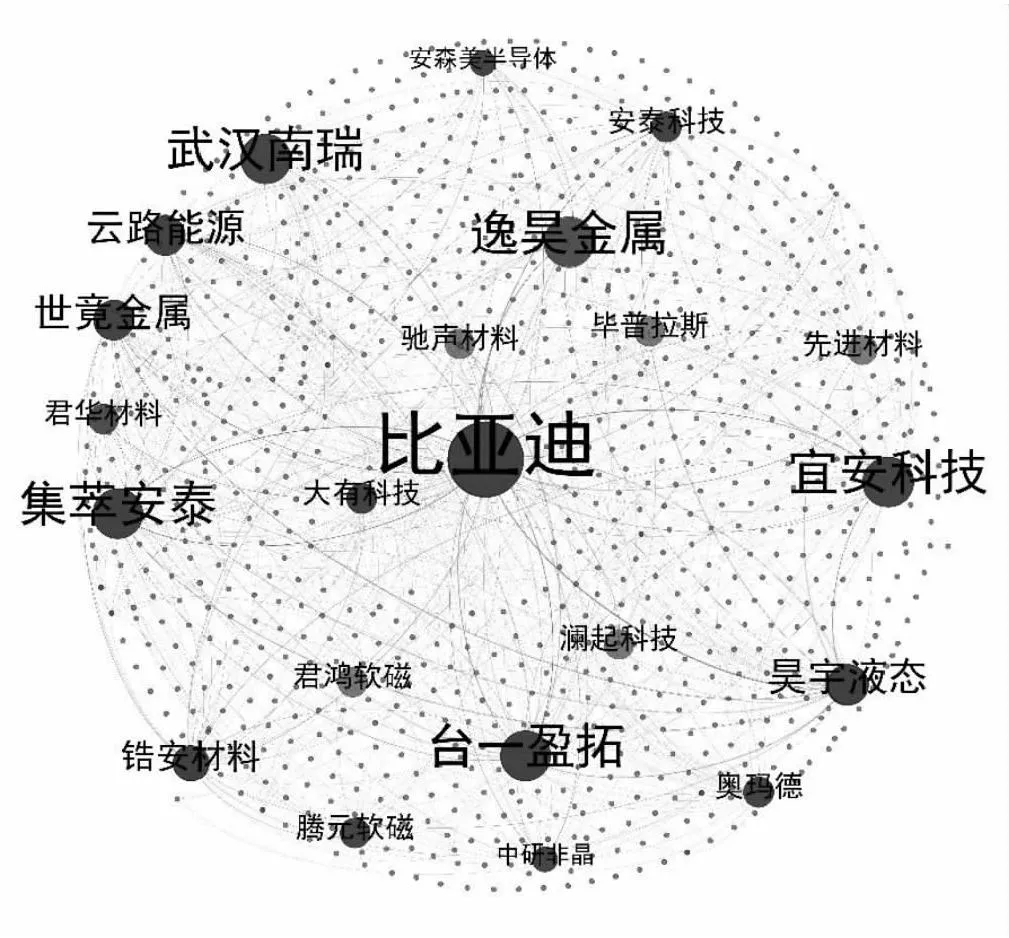
图4 基于专利的企业合作网络
3.3 指标计算结果
3.3.1 文本相似度
基于合作专利文本信息,利用Pearson系数计算专利文本内容间的相似度,结果越大说明专利间的相似度越大,即专利研究方向具备越强的关联性,存在的合作机会就会越大。将企业自身的专利文本相似程度设置为1,构建相似度矩阵,具体情况如表2所示。
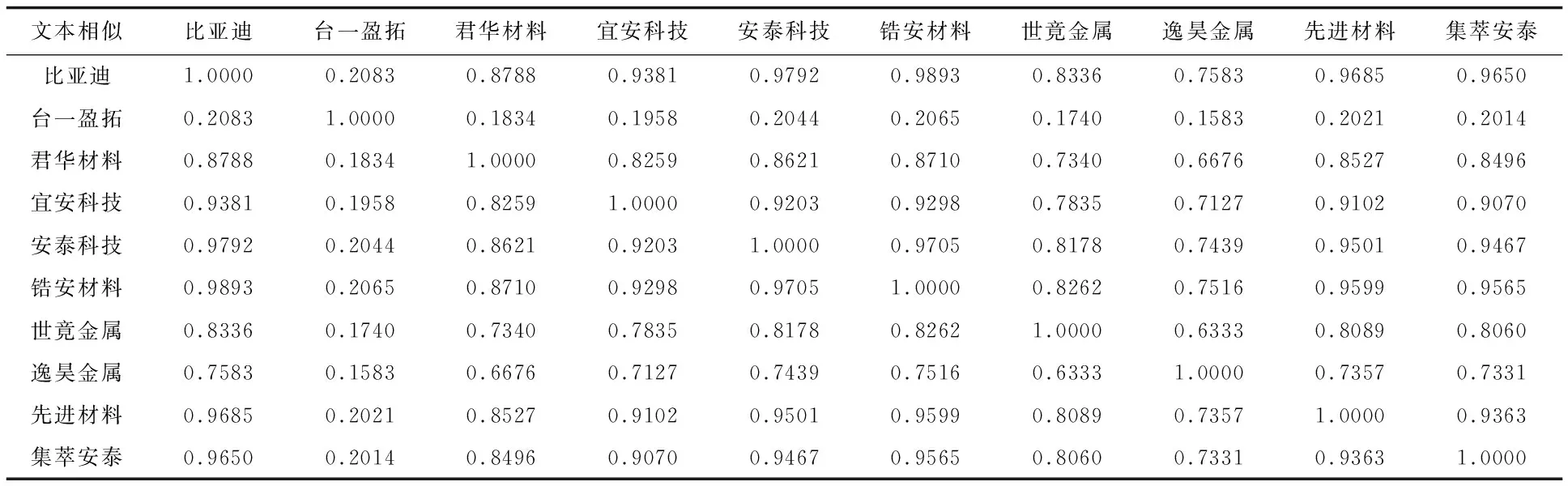
表2 文本相似度结果(示例)
3.3.2 匹配程度
对IPC号进行分类别序列分析,结合SM算法计算IPC号类别间的相似度大小,来判断专利间匹配程度的大小。依据回溯规则(https://github.com/yohstone)以及概率分布,对专利类别情况进行量化表示,限制值域范围在[0,1]之间,数值大小越接近于1,则说明专利类别相似度越高。匹配程度情况见表3。
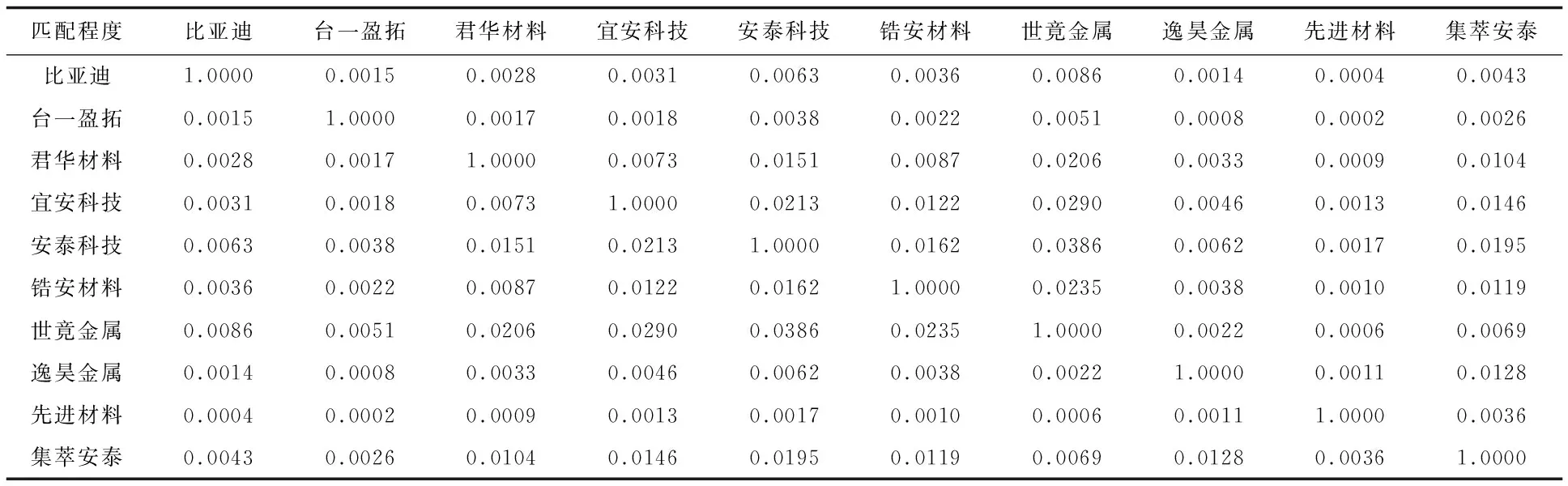
表3 匹配程度结果(示例)
3.3.3 连接强度
基于合作网络,融合SimRank指标与RA指标(SimRank+RA)对企业间合作的路径关系进行评价[28],计算结果越大说明企业所处的网络节点相似度越高,所分配到的资源数量越多,即合作的可能性越大。连接强度情况见表4。
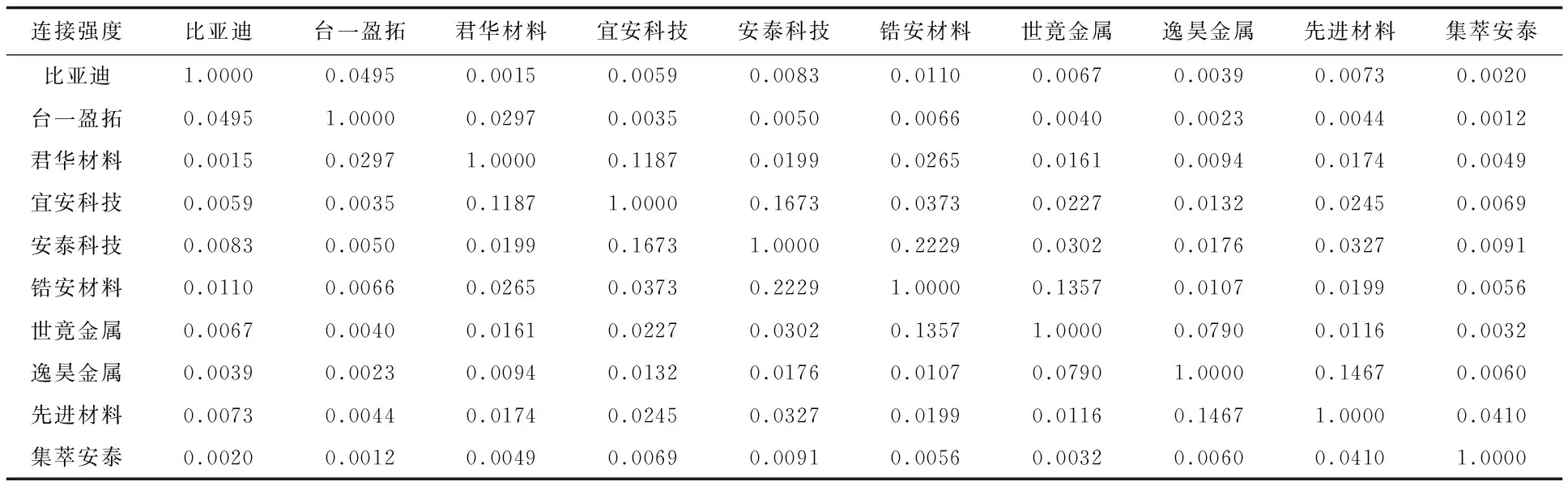
表4 连接强度结果(示例)
3.4 推荐结果分析
对文本相似度、匹配程度、连接强度结果的线性相关性进行分析,来选择合适的参数寻优方式确定各指标的最佳权重值。由分析结果可知,三个计算结果间的线性表现并不一致,显著性关系较为模糊。文本相似度与匹配程度结果间存在显著的线性关系,连接强度与文本相似度、匹配程度间并不存在直接的线性关联。相关性分析情况见表5。
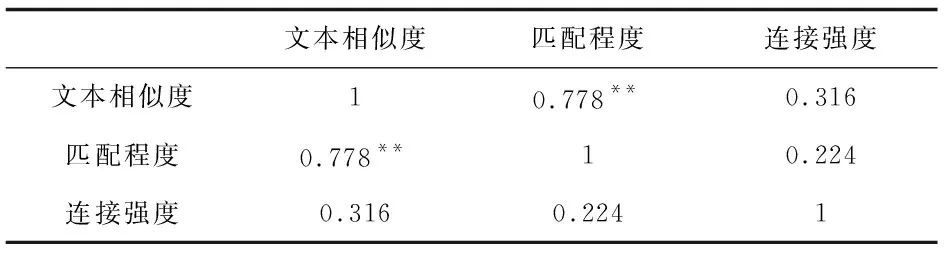
表5 指标相关性分析
融合专利文本、链路预测、IPC号相似性指标结果,结合式(9)利用权重预测算法确定α,β的值大小,其中指标权重值利用贝叶斯参数寻优[31]进行确定,来解决指标结果间非线性关联的问题,并借助AUC指标[32]表示预测准确率,算法的伪码如下:
算法2:权重预测算法
输入:关系元组(指标M,指标N,指标Q,组参数O)
输出:最佳参数组合(α,β,1-α-β),最佳AUC值
1:计算综合指标:score=(1-α-β)·M+α·N+β·Q,计算AUC指标;
2:定义约束条件,将综合指标阈值设置为0.2,否则返回null表示违反约束条件;
3:定义搜索空间范围:α,β,1-α-β∈[0,1],M,N,Q的指标值范围为[0,1];
4:设置优化迭代次数,epochs=10;
5:根据高斯过程模型和期望改进策略使用贝叶斯优化进行参数搜索;
6:检查是否找到更好的解决方案;
7:输出最佳参数组合(α,β,1-α-β)和最佳AUC值。
计算出α=0,0.1,0.2,…,1.0时的AUC值,结合贝叶斯优化方法计算相应的β值和1-α-β值,最终得到66种权重组合(权重值间隔为0.1的全部组合数目),其中组参数O为(0.1,0.1,0.8)时AUC值最大为0.950,指标的预测效果最佳。为此,依据上述数据结果将权重设置为(0.1,0.1,0.8),构建以文本相似度为主,连接强度和匹配程度为辅的综合评价指标,并通过计算得到新的相似度矩阵作为协同过滤推荐算法的预测基础。权重预测结果见图5。
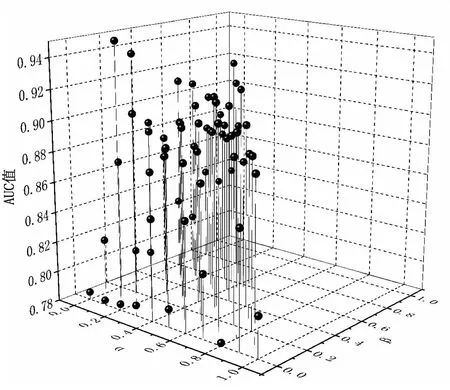
图5 综合指标AUC值变化图
选择预测效果最优的权重组合模式进行合作企业推荐,并从中选取最具合作可能的前两名企业作为推荐结果进行表示。以东莞台一盈拓科技股份有限公司(台一盈拓)为例,截至2022年12月,台一盈拓拥有员工400余人,生产基地面积超100亩,总资产超14亿元,拥有非晶合金领域的专利56件,仅次于比亚迪;同时拥有100余项自主知识产权(截至2022年12月),并以年均6项以上持续增长,在非晶合金领域属于龙头企业。由推荐结果可知,首推的合作企业是比亚迪公司,对二者的技术专利进行分析,发现在非晶合金的热压成型设备制造,非晶合金用的压铸工艺上的研究都较为深入,可以通过加强技术合作进一步扩大行业话语权与市场范围。次推的企业是芜湖君华材料有限公司(君华材料),该公司共有非晶合金领域专利40件,其研究方向聚焦于非晶合金装置制造,与台一盈拓所关注的热压成型设备制造相关程度较大,可以互相学习技术优势,实现技术进步。其余企业也可通过推荐结果进行技术领域细分,提前制定未来技术发展方向。推荐结果见表6。
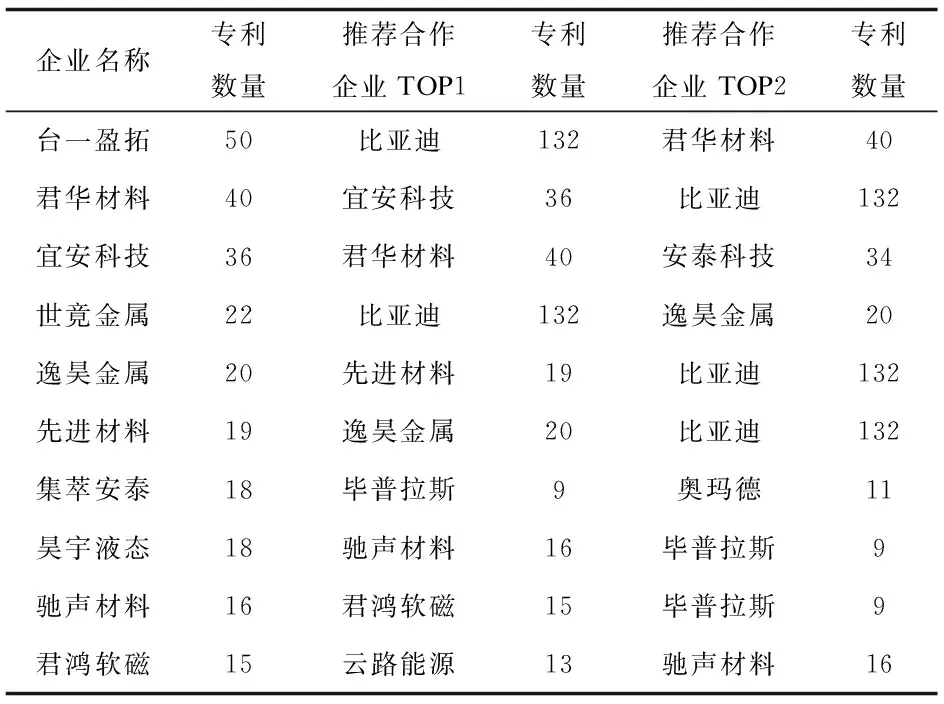
表6 推荐结果表示(部分)
随机挑选20家企业融合矩阵用热力图进行可视化表达,从而更直观的把握企业潜在合作关系的预测基准。融合矩阵热力图见图6。
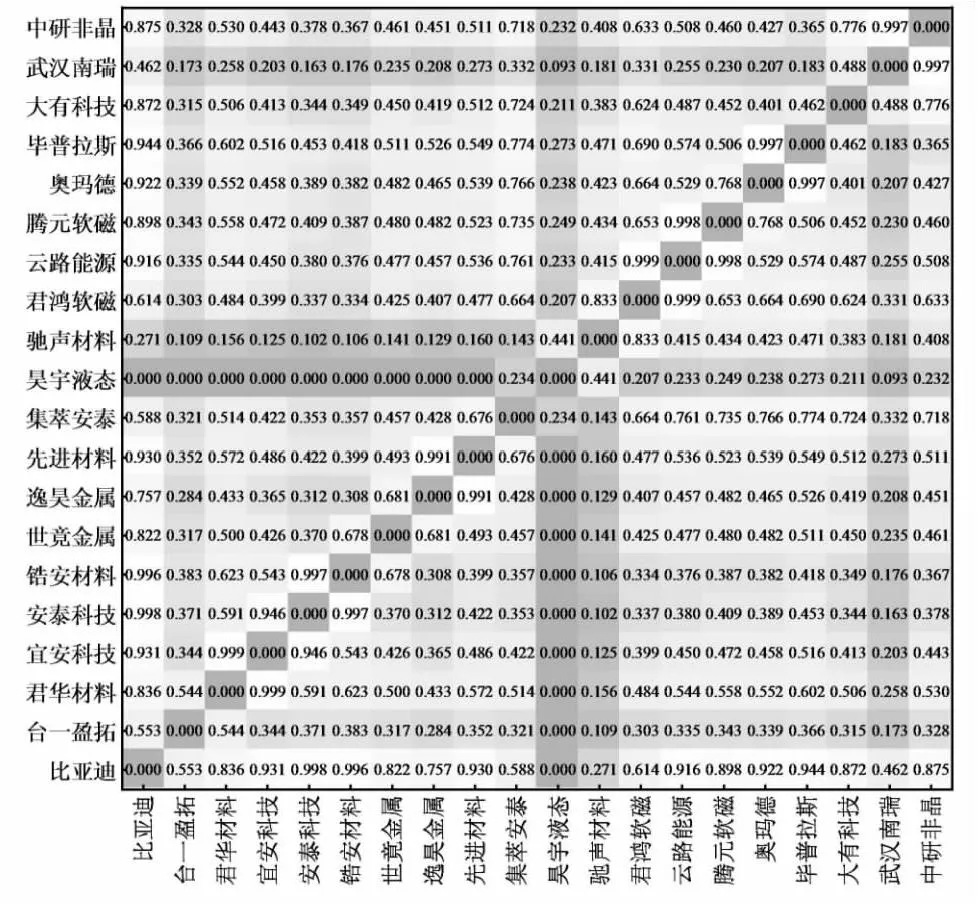
图6 融合矩阵热力图
3.5 融合算法效用评价
本文将数据集按照时间维度划分为训练集和测试集,利用推荐算法进行预测未来企业潜在的合作关系,通过“连接强度+匹配程度+相似度”的多维体系实现传统协同过滤算法的逻辑更新(“链路算法”)。为此,本文比较传统算法与融合算法的精确度来评价算法的实际效用水平。
3.5.1 修改矩阵格值密度
改变观测矩阵已知格值密度,在原有矩阵基础上利用Random模块选取20个企业进行算法检验,对比观测矩阵既有格值与预测矩阵检验格值,利用Jaccard系数计算两矩阵差异率,检验方法如图7所示,检验结果如表7所示。
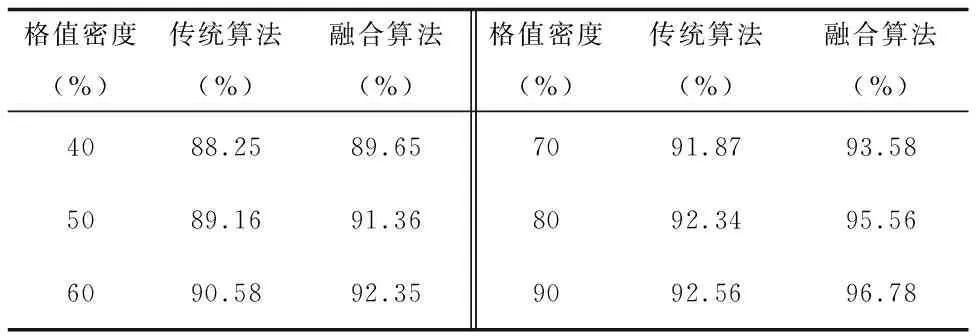
表7 链路推荐算法准确率对比
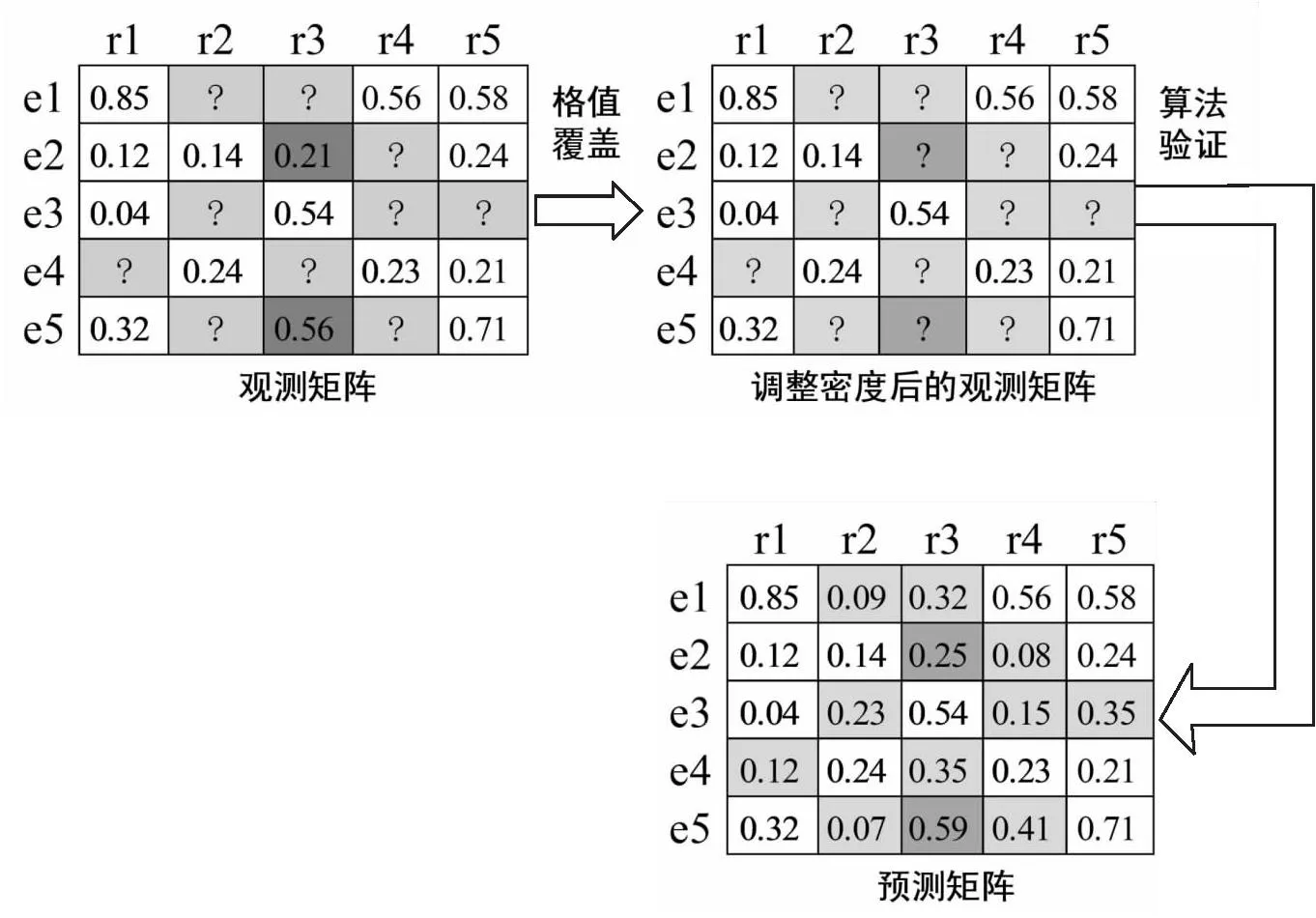
注:e1-e5代指企业,r1-r5代指融合指标图7 改变格值密度检验方法
随机选取部分矩阵格值作为检验项,同时更改矩阵格值密度并计算观测矩阵与预测矩阵相似情况。由检验结果可知,检验误差率在6.55%左右,平均准确率高于传统推荐算法2.42%。说明“链路推荐”算法得出的结果能够准确的表达企业间潜在合作关系,较之传统的协同过滤推荐算法更具准确度。
3.5.2 精准率、召回率、F1值分析
分别计算基于最优权重下融合指标产生的推荐结果的精准率、召回率、F1值,发现“链路推荐”算法的精准率在95.54%左右,召回率在73.67%左右,F1值在76.78%左右,较之传统的推荐算法分别提升了7.28%,6.58%,8.98%左右(见图8),说明“链路预测”算法在实践应用中更具备匹配度。
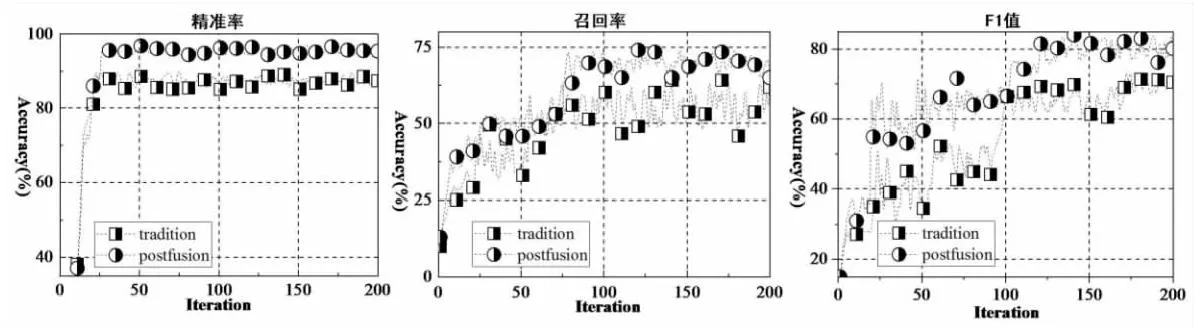
图8 链路推荐算法精准率、召回率、F1值对比
4 结 论
本研究通过融合协同过滤和链路预测,分别通过Pearson相关系数、SimRank指标和RA指标、SM算法,计算专利文本的内容相似性、链路预测的路径相似度、IPC号的类别相似度,随后借助权重预测算法构建以三者为基础的融合加权指标,探究“链路推荐”算法在预测企业潜在合作关系的有效性。主要研究结论如下:
a.专利合作网络能够表征企业间创新合作的实际关系,链路预测思想与协同过滤思想通过奇异值分解能够实现系统化结合,从而有助于构建全面的企业潜在合作关系预测的行为逻辑。IPC号所形成的序列化表达与SM算法底层逻辑接近,通过罚分规则与回溯规则能够为IPC号的类别相似程度提供新的表达方式,所形成的矩阵结果表达也能够与链路预测、协同过滤结果形成逐一对应,继而促进运算效率。
b.基于实证检验与推荐结果误差率测试,专利合作网络中的链路预测相关指标、协同过滤算法中的相似度、IPC号的序列匹配程度,能够融合成一个多维矩阵,作为输入可以提升推荐算法的精准度,“链路推荐”算法较之传统的推荐算法在准确率上能够取得3%左右的提升。
综上所述,专利合作网络中的链路预测、协同过滤思想与IPC号序列所形成的“连接强度+匹配程度+相似度”的多维复合体系能够有效预测企业潜在合作关系。后续的研究可以从以下三个方面进行改进:①利用新兴文本挖掘技术,精确化专利文本内容相似度计算[33]。②采用混合协同过滤的方法,优化协同过滤中的稀疏矩阵问题[34]。③引入科研机构形成合作关系扩充,健全产学研一体化建设。
猜你喜欢
纺织科学研究(2023年9期)2023-10-23 11:18:10
水运工程(2022年7期)2022-07-29 08:37:38
移动通信(2021年5期)2021-10-25 11:41:48
传感器世界(2019年4期)2019-06-26 09:58:44
中央民族大学学报(自然科学版)(2016年3期)2016-06-27 07:55:32
南都周刊(2015年4期)2015-09-10 07:22:44
南都周刊(2015年3期)2015-09-10 07:22:44
南都周刊(2015年1期)2015-09-10 07:22:44
中国交通信息化(2014年3期)2014-06-05 03:07:09
自动化与仪表(2014年10期)2014-02-26 08:21:17
