
基于类别域自适应的滚动轴承故障诊断
2023-12-23 10:30张英杰张彩华陆碧良李蒲德
振动与冲击 2023年24期
张英杰, 张彩华, 陆碧良, 丁 晨, 李蒲德
(湖南大学 信息科学与工程学院,长沙 410082)
滚动轴承已成为旋转机械和设备中使用最频繁和最核心的部件之一,广泛应用于风电、航空航天、交通运输等工业领域。由于工作环境是复杂的高负荷、非线性、强耦合、不稳定系统,在经历长期运转后,滚动轴承极易发生故障,危及系统安全运行,造成经济财产损失,为了旋转机械的可靠性,应当及时诊断出滚动轴承故障以降低事故风险。
随着机器学习的兴起,国内外学者提出了多种智能故障诊断算法。传统的智能故障诊断算法主要分为基于信号分析结合传统机器学习的模型以及基于深度学习的模型。基于传统机器学习方法的诊断模型分为两步:首先筛选出原始信号的代表特征,比如快速傅里叶变换(fast fourier transform,FFT)[1]、小波变换[2]等信号处理技术[3],进而利用传统的机器学习进行分类,如支持向量机(support vector machine,SVM)、贝叶斯分类器以及BP(back propagation)神经网络等,此类方法对原始信号的特征筛选不能充分利用原始数据的隐藏信息,而且传统的机器学习都是一些较为浅层的分类器,其学习能力有限,存在较多局限性。近年来,深度学习在模式识别、故障诊断等领域得到了广泛而又成功的应用。Yuan等[4]提出了一种基于快速傅里叶变FFT结合卷积神经网络(convolutional neural networks, CNN)的滚动轴承故障诊断方法。Lu等[5]提出了一种多通道输入连续卷积神经网络结合支持向量机的早期故障诊断模型。Chen等[6]提出了一种基于多个小波变换的一维卷积递归神经网络。王琦等[7]在一维卷积神经网络的基础上进行改进提出了FRICNN-ID(fault recognition based on improved one-dimensional convolutional neural network)方法,可以准确识别滚动轴承不同故障的状态。雷春丽等[8]采用马尔科夫转移场处理数据再用CNN进行自动特征提取和故障诊断。试验结果表明在滚动轴承变工况和数据集小时具有良好的泛化性。Zhang等[9]利用一维卷积神经网络提取特征,并输入到经过粒子群优化的支持向量机分类器中,提高了诊断的精度和准确性。Yang等[10]利用二维卷积神经网络与随机森林结合,在噪声环境下仍能取得不错的性能。这些方法在滚动轴承数据集上取得了良好的诊断效果,但都需要足够的带标签样本进行训练,并且训练数据和测试数据要遵循相同的分布[11]。然而,在实际工业生产中,对采集的大量数据进行人为标注代价高昂,鉴于风电场的地理环境不同、风机型号多样、实时运行期间工况也多变复杂,采集的数据很难与训练数据服从同一分布[12]。因此在跨域故障诊断情况下,前述方法诊断性能将急剧下降。
为了解决上述实际问题:本文引入迁移学习中的领域自适应方法,领域自适应在计算机视觉领域,自然语言处理等领域[13-17]取得了极大的成果。在故障诊断领域中领域自适应方法主要分为三类:一是基于差异方法利用深度网络提取高维故障特征,再通过自适应层减小域分布距离。如Lu等[18]通过DNN网络最小化两个域之间的最大均值差异以减少域间分布距离,完成了滚动轴承在不同工况下的健康状态识别。Li等[19]利用深度卷积神经网络作为特征提取器,并最小化自适应层两个域之间的多核最大均值差异,在不同负载条件下验证了该方法的有效性。康守强等[20]将源域共享模型参数迁移到目标域在线训练模型中构建分类模型,在变负载工况下具有较高的分类准确率和稳定性。Wang等[21]将子域适应与域适应相结合构建子域适应迁移模型以减少联合分布偏差。二是基于对抗的领域自适应方法,Guo等[22-23]通过梯度反转层优化特征提取器,使鉴别器损失最大化,使其无法区分源域和目标域,达到域自适应的效果。Chai等[24]进一步提出基于细粒度对抗网络的领域自适应方法,既能对两个域进行全局比对,又能对两个域的每个故障类进行细粒度比对。第三类是结合差异和对抗的方法,Shao等[25]将原始数据通过短时傅里叶变换转为时频域图像作为输入,并采用50层深残差网络预训练ImageNet作为特征提取器。使用域混淆和多核最大平均差异最小化源域与目标域之间的差异,并在两个轴承数据集上证明了该方法的有效性,但该方法需要将时间序列信号通过短时傅里叶变换转换成更明显的高维特征进行训练,而不能直接挖掘具有代表性的特征。前述域自适应的方法仅考虑了源域和目标域类别一致时的闭集跨域故障诊断问题,忽略了更为普遍的目标域类别是源域类别子集的部分跨域故障诊断问题,因此本文提出了一种基于类别域自适应的模型。主要贡献如下:
(1) 采用一维卷积神经网络1DCNN直接提取原始振动信号的特征,通过分类器实现智能故障诊断,实现了端到端智能故障诊断过程,同时也避免了特征转换的损失。
(2) 提出了一种新的基于类别域自适应方法,将源域和目标域从域对齐精细到类别间的对齐。在轴承数据集上的试验验证了在闭集跨域故障诊断和部分跨域故障诊断情况下,本文方法跟经典的域自适应方法相比,仍具有竞争力和有效性。
1 理论基础
1.1 域自适应
为了更好理解域自适应的问题,引入更为常见的迁移学习。在迁移学习有两个基本的术语:域D(Domain)和任务T(Task)。域D包括特征空间χ和特征分布P(X)两个部分,其中D={χ,P(X)},X={x1,…,xn}∈χ,xi∈X为域中第i个训练样本。在任务T包括标签空间Y和预测函数f(·),T={Y,f(·)},其中:f(x)=P(yi|xi)为条件概率分布函数;yi∈Y为域中第i个样本的标签。迁移学习中将域分为源域Ds和目标域Dt,相应地,任务分为源域任务Ts和目标域任务Tt。本文主要关注无监督同构迁移学习即源域数据有标签{xsi,ysi};xsi∈Xs,ysi∈Ys,目标域数据无标签{xti};xti∈Xt,且源域和目标域有相同的特征空间和任务,仅域分布不同。下面给出域自适应的定义。
定义1给定一个源域Ds和源域的学习任务Ts,目标域Dt和目标域的学习任务Tt,利用在Ds和Ts上学习的知识提高目标域上预测函数f(·)的能力,其中Ds≠Dt:Ps(X)≠Pt(X),Ts=Tt。
在本文中,源域和目标域数据来自不同负载工况下以及不同损伤程度的轴承振动数据,对于每种迁移任务故障类别相同,即标签空间相同,如何利用源域数据提升目标域的分类准确率是本文方法主要解决的问题。
1.2 卷积神经网络
卷积层卷积运算部分是CNN中最重要的运算模块之一。卷积层通常使用多个卷积核对输入数据进行卷积运算,从而提取出不同的局部特征,这个结果被称为特征映射。每个卷积核的参数通过反向传播算法最佳化得到,相比于完全连接层,卷积层具有参数共享,局部连接的结构特性,它可以利用更少的参数提取更丰富的特征,使得最终的训练模型具有较强的泛化能力。卷积运算公式如下
gk=ωk*xi+bk;k=1,2,…,q;i=1,2,…,n
(1)
式中:ωk为卷积层的第k个卷积核系数;bk为卷积核的偏置参数;xi为输入的第i个数据;gk为第k个卷积核提取第i个样本的特征。
最大池化层池化层有时也称为采样层。池化层的主要功能是在尽可能保留原始显著特征的同时减小特征的输出维数,这样不仅减少了参数的数量,提高了模型的训练速度,而且很好地保留了主要特征。最大池化CNN中最常用的池化方法之一,它输出指定范围内的最大值。最大池化的数学表达式为
(2)
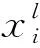
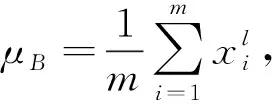
(3)
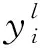
全连接层低维特征经过卷积层、池化层和批量归一化后,输入到全连接层。在全连接层中,将深度特征信息与分类进行整合,构建提取的特征与样本标签之间的映射关系。全连接层的最后一层称为输出层,或分类层。最常用的分类器是Softmax分类器。数学公式可以表示为
yl=f(ωlxl-1+bl)
(4)
式中:l为网络的层数;yl为全连接层的输出;xl-1为全连接层的输入;ωl为权重参数;bl为偏置系数。
2 本文模型
为了解决无标签跨域故障诊断问题,本文提出了一种新的基于类别的域自适应模型。该模型主要分为3个部分:特征提取器、分类器以及锚定器,如图1所示。模型总损失函数由分类损失和锚定损失构成,如下
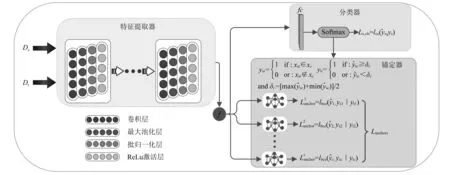
图1 本文模型架构Fig.1 Proposed model architecture
Ltotal=argminLcls+λLanchor
(5)
式中:Lcls为分类器的损失,见式(7);Lanchor为锚定器损失,见式(8);λ为一个跟迭代次数有关的权衡超参数,见式(6)。
(6)
2.1 特征提取器
本文中的特征提取器Fθ以一维卷积神经网络1DCNN作为基本结构,将源域数据和目标域数据作为模型特征提取器的输入,它直接提取分割后的原始信号特征,避免了人为特征的选择,最大潜力地挖掘原始数据的相关状态特征。如图1中特征提取器模块所示,它主要由4个卷积块组成,每个卷积块结构相同均在卷积层后引入了最大池化层和批量归一化层,批量归一化层保证特征提取过程中数据的分布不产生大的变化,减少协变量的偏移。最后引入全局平均池化GAP代替全连接层减少模型的训练参数,加快训练模型的速度。它的参数设置如表1所示。
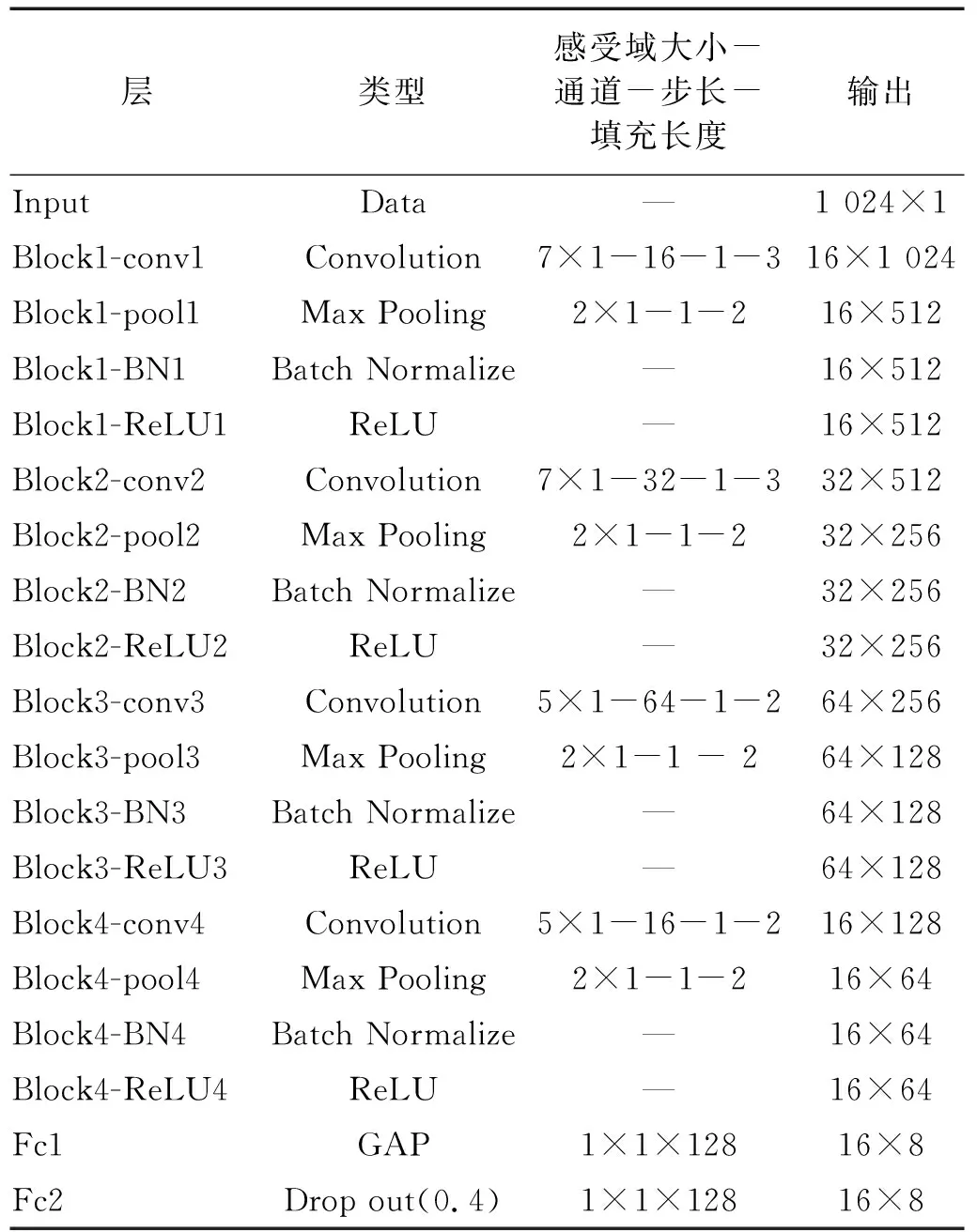
表1 特征提取器架构的详细配置Tab.1 Detailed configuration of the feature-extractor architecture
2.2 分类器
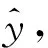
Lcls=E(xsi,ysi)~(Ds,Ys)lce{Fcls[Fθ(x)],y}
(7)
式中:E(xsi,ysi)~(Ds,Ys)为样本来自源域数据;lce为交叉熵损失函数。
在反向传播时更新分类器和特征提取器参数,随着迭代的增加,分类器的损失越来越小,源域样本分类准确率越来越高,同时保证了特征提取器获取的高维特征代表性越来越强。
2.3 锚定器
锚定器作为本文方法的核心部分,灵感来于心理学上的锚定效应,它是指在不确定情况下,目标值向初始值即“锚”的方向接近而产生估计偏差的现象[26]。基于此效应本文在细粒度上为源域的每个故障种类分配一个独立但结构相同的锚定器Fa。锚定器是一组由多层感知机构成的二分类器,见图1中锚定器区域。以某故障类c为例,本文将源域数据中类c归为正类,其他故障类归为负类;而对于无标签的目标域样本,将属于伪类c的概率超过动态锚值δc的样本归为正类,而低于动态锚值以及其他故障类的样本归为负类。其中动态锚值δc等于源域数据在分类器Softmax后类c上的最大和最小概率的均值,这确保了目标域伪标签的可靠性。因此锚定器有别于Shao等研究中减少源域类c和目标域伪类c分布差异的思想,也不同于文献[27]中将源域类c和目标域伪类c分别划分为正负类进行对抗训练的方法。锚定器的损失定义如下
(8)
随着迭代的增加,通过源域样本训练的分类器损失越来越小,获取的动态锚值的也逐渐精准可靠,因此目标域伪标签误差也随之逐渐降低,对于c类的锚定器,目标域样本中的正类会逐渐靠近c类的源域样本,而负类的样本作为会逐渐远离c类的源域样本。基于以上原因,本文模型一方面可以保证目标域和源域中的同故障类互相靠近,同时使异类之间逐渐远离,最终实现基于类别高精度的跨域故障诊断目标。
2.4 算法流程
本文的算法处理流程,如表2所示。同时采用L2正则化和Dropout技术减少模型的过拟合,从而提高模型的准确性。该模型在整个故障诊断过程中不需要人工提取特征,可以将滚动轴承的原始数据直接输入到一维卷积网络提取特征,然后通过锚定器减少域分布距离。从以上可以看出,这是一种“端到端”的算法结构,具有优秀的通用性。

表2 基于类别域自适应算法的处理流程Tab.2 Process flow of domain adaptive algorithm based on class
3 试验研究
3.1 试验一:凯斯西储大学轴承故障数据集
该数据集由美国凯斯西储大学(Case Western Reserve University,CWRU)进行试验和发布。采集试验台的图片,如图2所示。包括一个1.5 kW的电动机,一个扭矩传感器/译码器,一个功率测试计。由于驱动端采集到的轴承振动信号受到的干扰小于风扇端采集到的振动信号,因此试验中采用驱动端加速度传感器采集到的振动数据。

图2 CWRU数据集试验装置Fig.2 Test rig of the CWRU dataset
数据集包括4种负载条件,0(1 797 r/min),0.75 kW(1 772 r/min),1.50 kW(1 750 r/min)和2.25 kW(1 730 r/min)滚动轴承振动信号。在每个负载条件下,其数据集包括9种故障类型和1种正常状态数据。轴承用电火花加工单点损伤,轴承内圈、外圈和滚动体的故障直径分别为7 mils(约0.18 mm)、14 mils(约0.36 mm)和21 mils(约0.53 mm),对于外圈本文选取6点钟方向的采集的振动信号作为试验数据。试验中采集的数据根据采样频率分为12 kHz和48 kHz。本文采用采样频率为12 kHz的振动信号数据作为后面试验的数据集。试验选取4种负载工况(0,0.75 kW,1.50 kW,2.25 kW),每种负载工况选取10种滚动轴承状态数据,按照相同个数、相同长度选取每种状态数据作为试验样本。在开始训练前,选取10个相同负荷条件下的不同状态数据,每个状态数据500条,并对每个状态数据进行预处理,如调整格式、归一化等。按照7∶3的比例分成训练集和测试集。0负载和12 kHz采样频率下的9种滚动轴承故障状态,如表3所示。
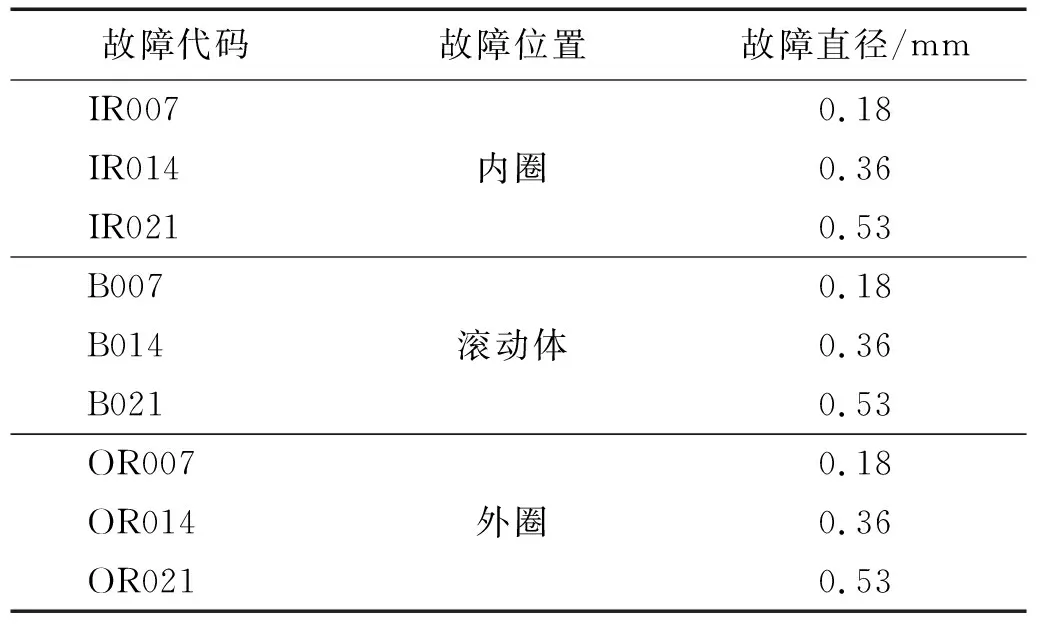
表3 0负载下滚动轴承失效状态的9种类型Tab.3 Detailed nine types of rolling bearing failure status under 0 load
3.1.1 特征提取器
首先为了验证本文设计的1DCNN特征提取器的能力,对同负载下的故障数据进行分类。不同比较方法下的故障诊断性能,如表4所示。从表4中可以看出,本文方法训练的诊断模型的特征提取能力明显优于比较方法,且平均准确率达到了100%。通过对比分析不难发现,机器学习技术受限于人工特征选择和浅层特征表征学习能力。逻辑回归(logistic regression,LR)和SVM的平均精度低于基于深度网络的BPNN(back propagation neural network)和1DCNN(one-dimensional convolutional neural network);但在总体测试正确率方面,BPNN网络的测试集正确率仅为92.44%,远低于1DCNN。
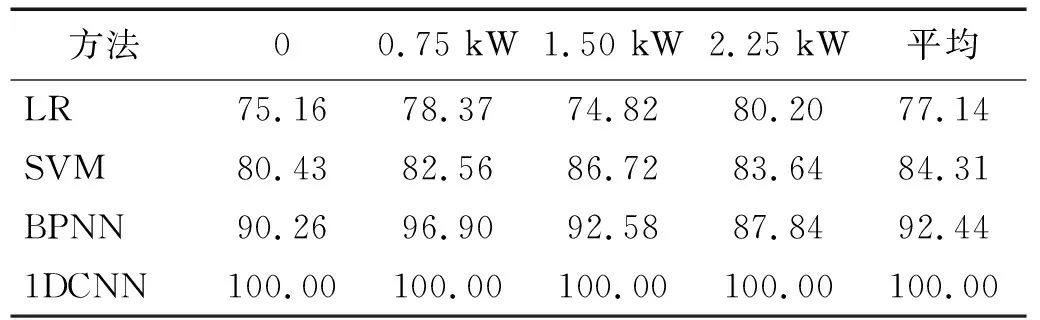
表4 不同比较方法下的故障诊断性能Tab.4 The fault diagnosis performance under the different comparison methods 单位:%
3.1.2 试验对比结果
对于跨域故障诊断,本文首先探讨了目前大部分方法关注的源域故障种类和目标域故障种类一致时的情况。针对于4种负载情况,本试验一共分12个跨域故障诊断的场景,以场景T01为例,源域是0负载下的振动数据,目标域则是0.75 kW下的振动数据。具体试验数据如表5所示,本文对5次试验的求均值,每次试验的迭代次数均为100次。其中1DCNN只包含特征处理器和分类器,并未做域自适应处理,它将在源域训练好的模型直接对目标域数据进行预测分类,为了保证试验的可靠性和说服力,将其结果作为本文对比试验的基准数据。本文对3种经典的深度域自适应模型作为对比方法,其中Coral和DDC是基于距离的深度域自适应模型,DANN是基于对抗的域自适应模型。本文对这些模型进行了改进,它们和提出的模型都使用1DCNN提取特征和预测分类。从试验结果中,可以看出本文方法在跨域诊断中表现优异,取得了不错的试验结果,其平均准确率达到了98.84%。
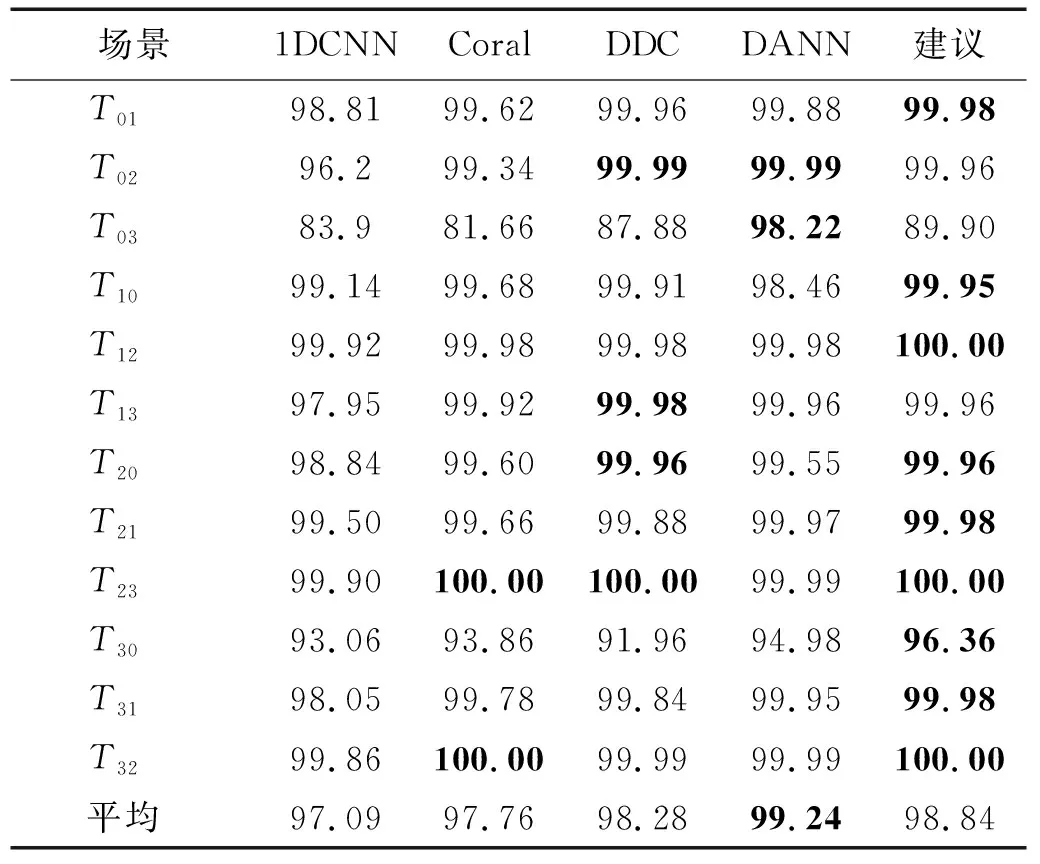
表5 当cs=ct时不同场景下不同方法的准确率Tab.5 The accuracy of different methods in different scenarios where cs=ct 单位:%
在12种场景中,本文所提模型均优于基准数据,并且在几乎所有的场景中优于或达到对比方法的同一水准。本文提出的模型平均准确率优于基于差异的模型,略低于DANN模型。cs=ct时不同场景下所提方法与经典方法的比较,如图3所示。由图3可知,场景T03中,DANN模型的表现远高于其他模型为了验证本文方法在类域自适应上的能力,又在部分域自适应领域进行了试验对比,首先将目标域中内圈、外圈和滚动体的故障类都减少一类,此时目标域中只有7类故障,而源域中有10类故障。其试验数据如表6所示,减少目标域类别后,在所有场景中,所有模型准确率均有明显下降。cs=ct时不同场景下,所提方法与经典方法的比较,如图4所示。由图4可知,在域分布差异最大的T30,T03两个场景中本文方法均表现最优。在平均准确率上,基准模型1DCNN下降了2.44%,DANN方法下降最多,达到3.99%,本文方法仅下降了1.08%。虽然本文方法在个别场景下略低于DDC模型,但平均准确率在所有对比模型中取得了最优的结果。
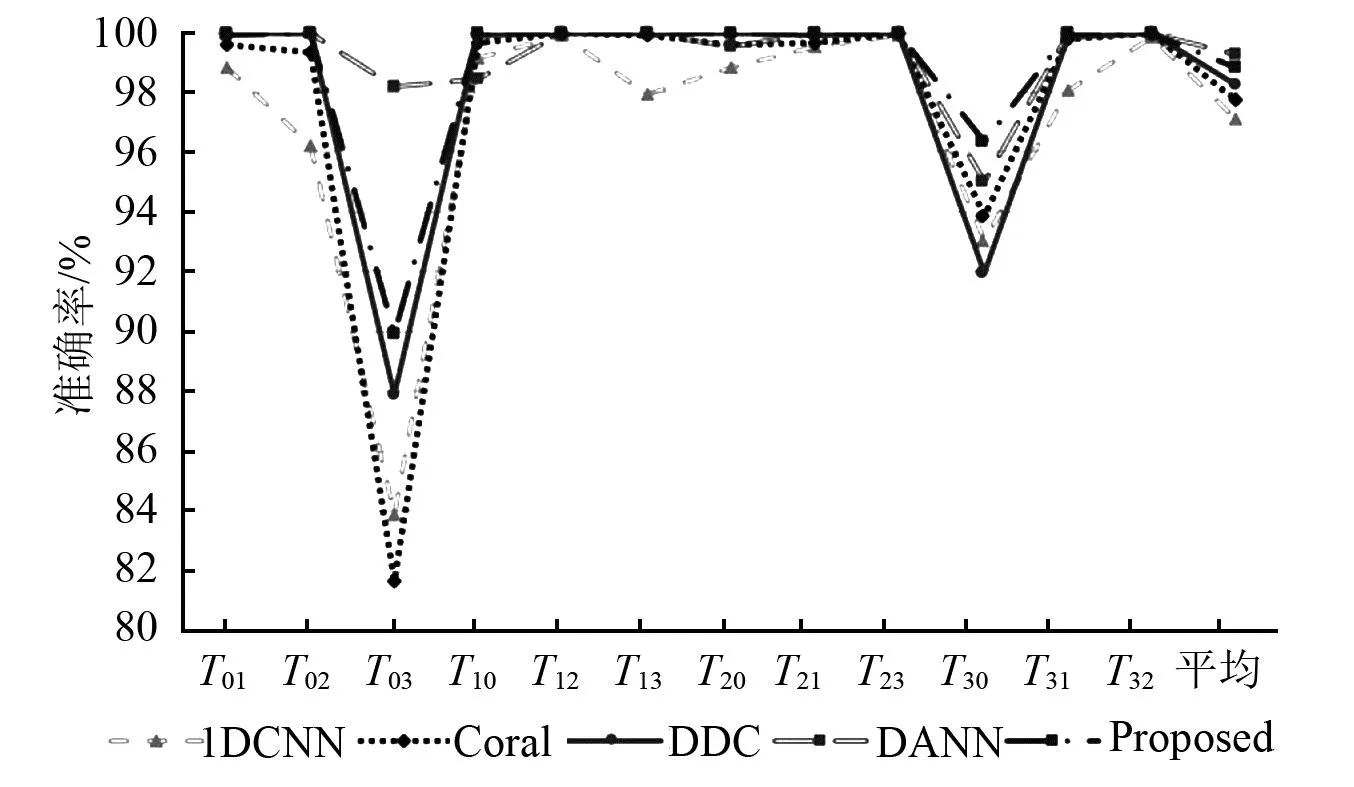
图3 cs=ct时不同场景下所提方法与经典方法的比较Fig.3 Comparison between the proposed method and classical methods under different scenarios where cs=ct
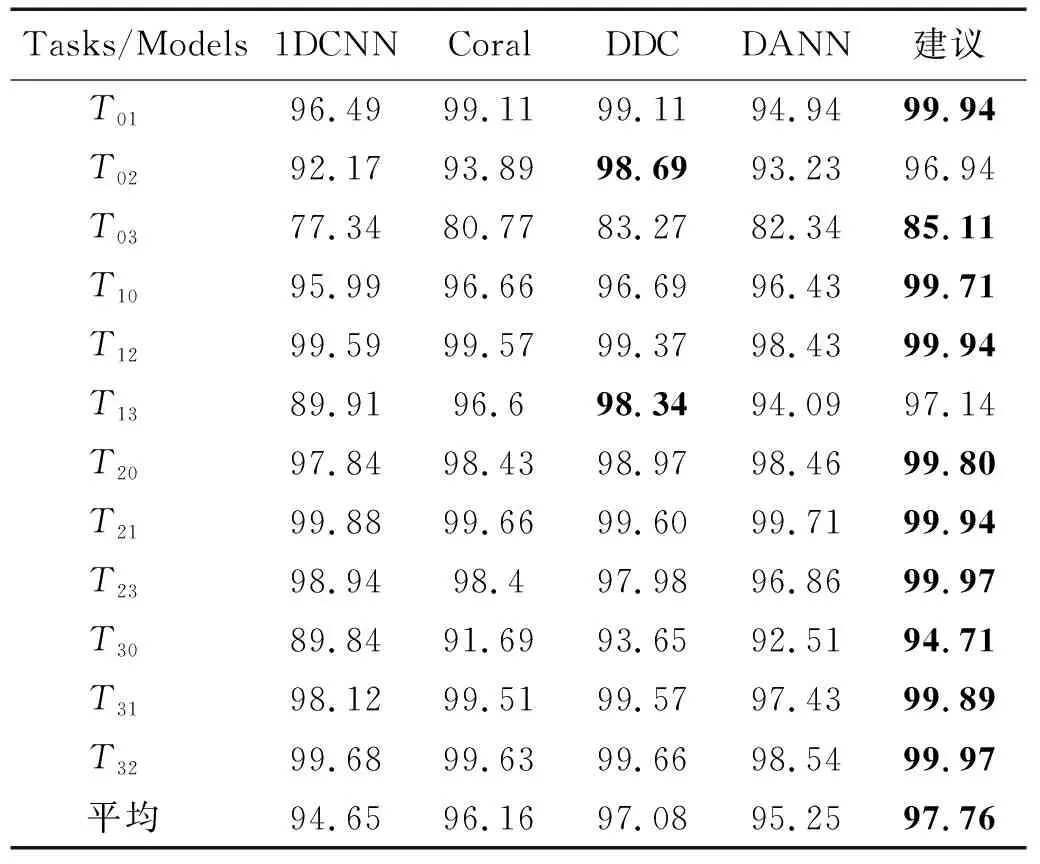
表6 当ct∈cs时不同场景下不同方法的准确率Tab.6 The accuracy of different methods in different scenarios where ct∈cs 单位:%
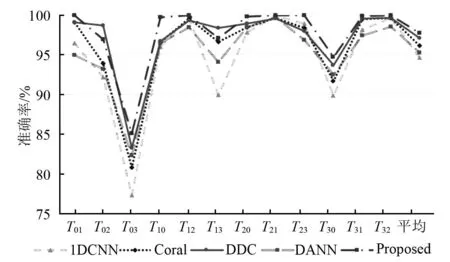
图4 ct∈cs时不同场景下,所提方法与经典方法的比较Fig.4 Comparison between the proposed method and classical methods under different scenarios where ct∈cs
此外以T30场景为例,对比本文所提出的模型与其余模型的迭代过程,如图5所示,图5(a)为源域和目标域类别一致的情形,本文方法比基于对抗的DANN模型收敛更快,并且优于基于距离的模型。图5(b)为减少目标域类别的情形,DANN震荡十分显著且不收敛,基于距离的模型也出现了小幅度的震荡,而本文方法在保证高准确率的同时收敛也最快。最终结果验证了本文方法的在跨域故障诊断中的有效性和优越性。
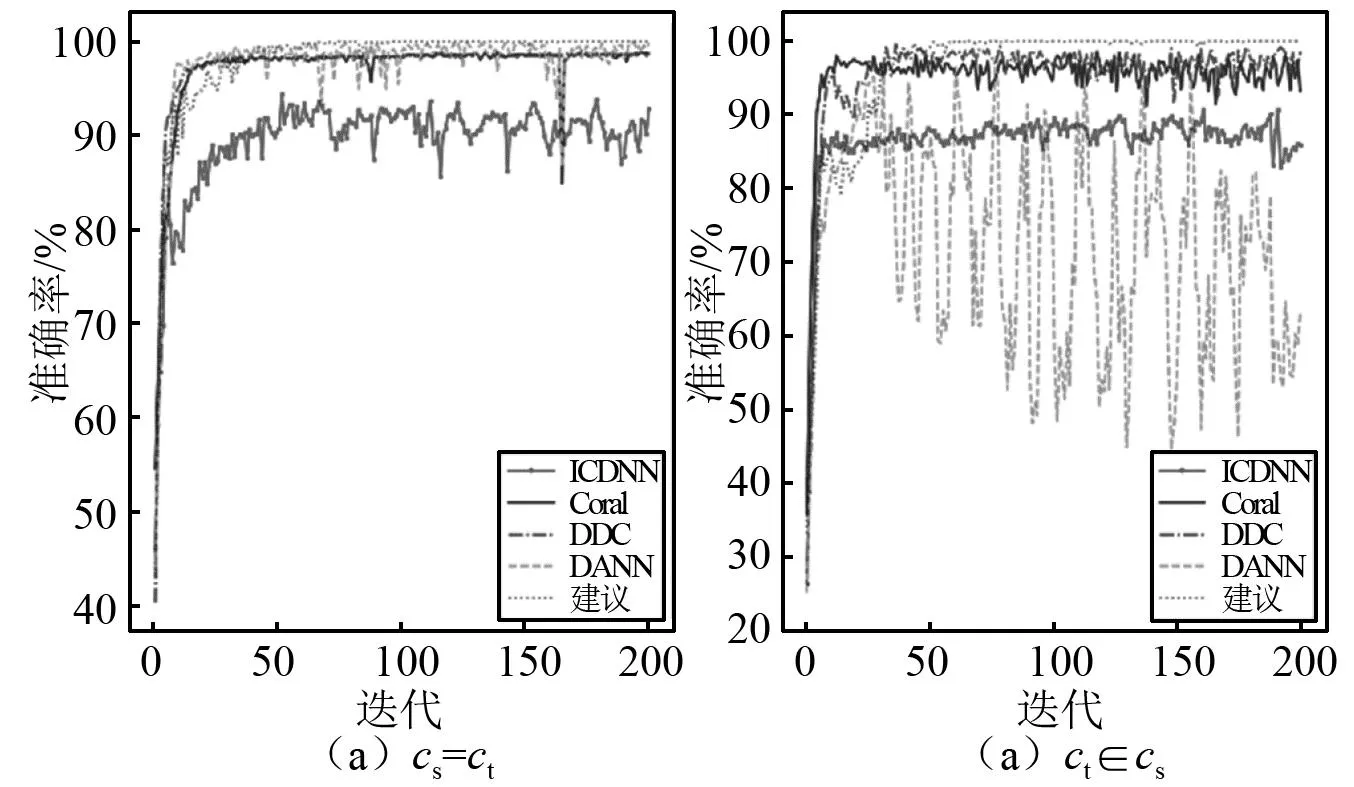
图5 不同模型的准确率对比Fig.5 Comparison of accuracys of different methods
3.1.3 特征可视化
为了直观地观察分类效果,本文使用t-SNE[28]技术将特征提取器提取的高维特征映射到二维空间中。以部分域自适应中的场景T30为例,如图6所示,每个模型中均有两个子图,图6(a)~图6(d)左子图不同形状代表不同的类别,图6(b)~图6(d)右子图圆状代表源域样本,叉状代表目标域样本。目标域中内圈、外圈和滚动体的故障类分别减少一类,每个模型都选取训练好的特征提取器提取高维特征。
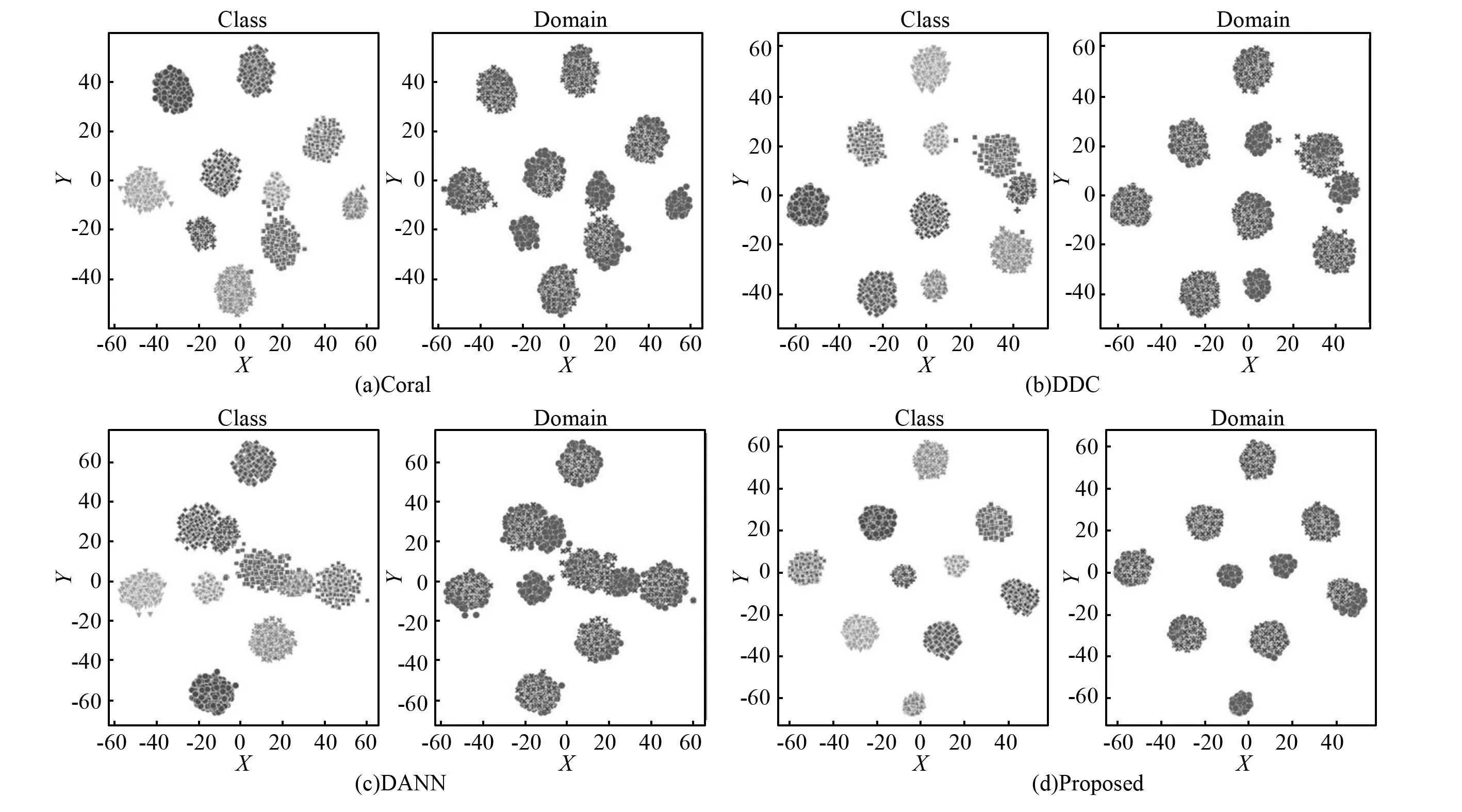
图6 利用t-SNE可视化T30场景特征Fig.6 Visualization of T30 scenarios features with t-SNE
由图6可知,相比其他模型本文提出的方法使源域和目标域的分布明显更接近,而且在不同故障类之间,本文方法即保证了类内距离更近,也使类间的距离更远,类间分布更为均匀,获得了更好的分类结果。
进一步利用t-SNE可视化1DCNN模型,如图7所示。由图7可知,观察到目标域中的加号故障类(故障类5)被误分到方块故障类(故障类2)中,即在高维空间中目标域中的故障类5相比真实类别距离故障类2更近。根据锚定效应,目标域故障类5将以源域故障类2为锚值,这种偏差随着迭代次数增加而加强,最终导致分类错误。这解释了为何在该场景下本文模型以及基于距离的模型表现不佳的原因。
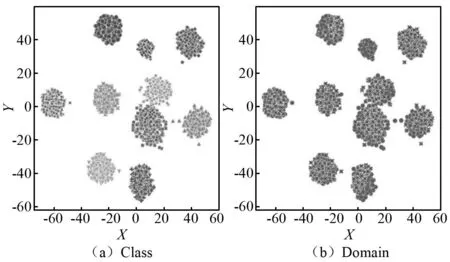
图7 利用t-SNE可视化T03场景下1DCNN模型特征Fig.7 T-SNE visualization of 1DCNN model features in T03 scenario
闭集域自适应中T03场景下的混淆矩阵图,如图8所示。基于距离的模型和本文方法都将故障类5划分到故障类2中,而基于对抗的DANN模型可以避免这一现象。

图8 T03场景下各模型混淆矩阵对比图Fig.8 Comparison diagram of confusion matrix in T03 scenario
3.2 试验二:帕德博恩大学轴承数据集
帕德博恩(Paderborn)大学轴承数据集采集自如图9所示的模块化试验台,它从左至右依次由电动机、转矩测量轴、滚动轴承测试模块、飞轮、负载电机组成。该数据集包含从健康轴承、人为损坏轴承和实际损坏轴承中获得的信号数据。轴承的健康状态分为正常(NO)、内圈(IF)和外圈(OF)故障所有这些轴承都包含3种不同的负载工况,如表7所示。人为损伤形式包括电火花加工、钻削和手工电雕刻。此外,实际损伤以点蚀或塑性变形的形式出现。更详细的试验细节描述可见参考Lessmeier等的研究。
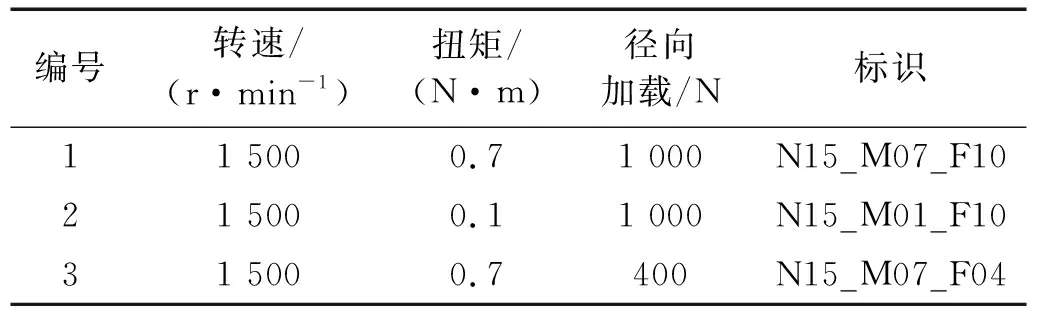
表7 操作参数Tab.7 Operating parameters

图9 帕德伯恩数据集试验装置Fig.9 Test rig of the Paderborn dataset
为了进一步验证模型的泛化性,在Paderborn数据集上设置两组域自适应试验:一是以人为损伤数据集为源域,不同工况下实际损坏轴承数据集为目标域,其中S1→T代表N15_M07_F10工况下采集的故障信号为源域,目标域为表7中3种工况下的振动数据;二是根据轴承的一级和二级损伤程度划分源域和目标域。具体的域自适应试验场景设置见表8所示。

表8 域自适应试验设置说明Tab.8 Domain adaptive task description
对比试验结果如表9、图10所示。本文模型在5种域自适应任务中并未全部取得最优结果,但是在不同的任务中,本文模型准确率一直保持稳定,尤其是任务C中,并且最终的平均准确率比基准方法提高了5.31%,也因此取得最优的表现。此外图11、图12分别展示了任务A下的迭代过程精度曲线与t-SNE可视化特征,与图6类似每个t-SNE子图分别包括两部分,左部分为不同类别,右部分分别对应源域(圆状)与目标域(叉状)。
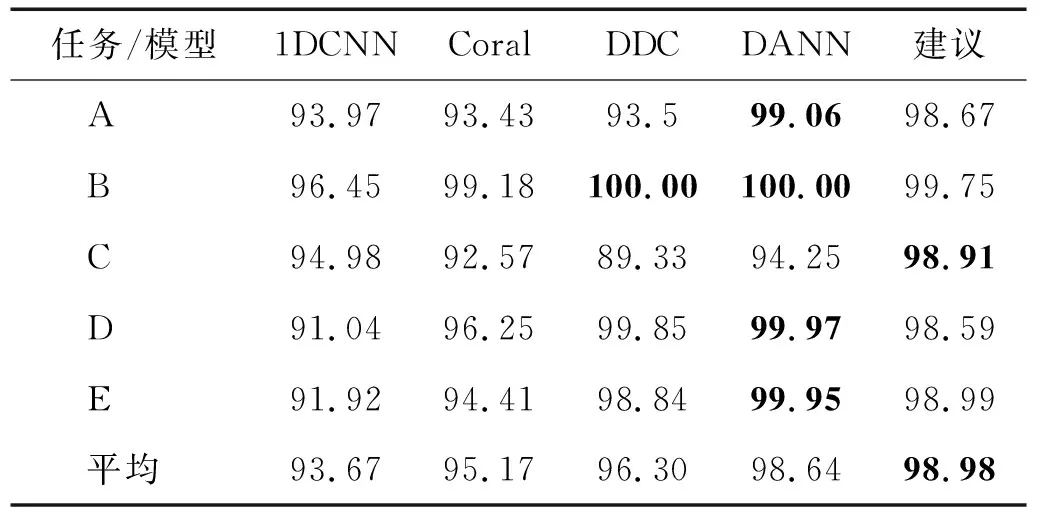
表9 不同任务下对比方法的准确率Tab.9 The accuracy of comparsion methods in different tasks 单位:%
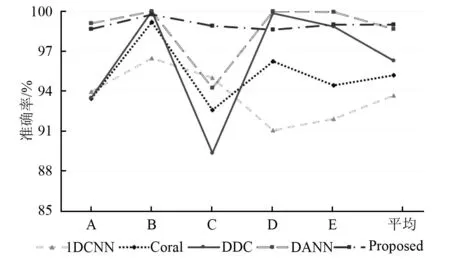
图10 所提方法与经典方法的比较Fig.10 Comparison between the proposed method and classical methods under different tasks
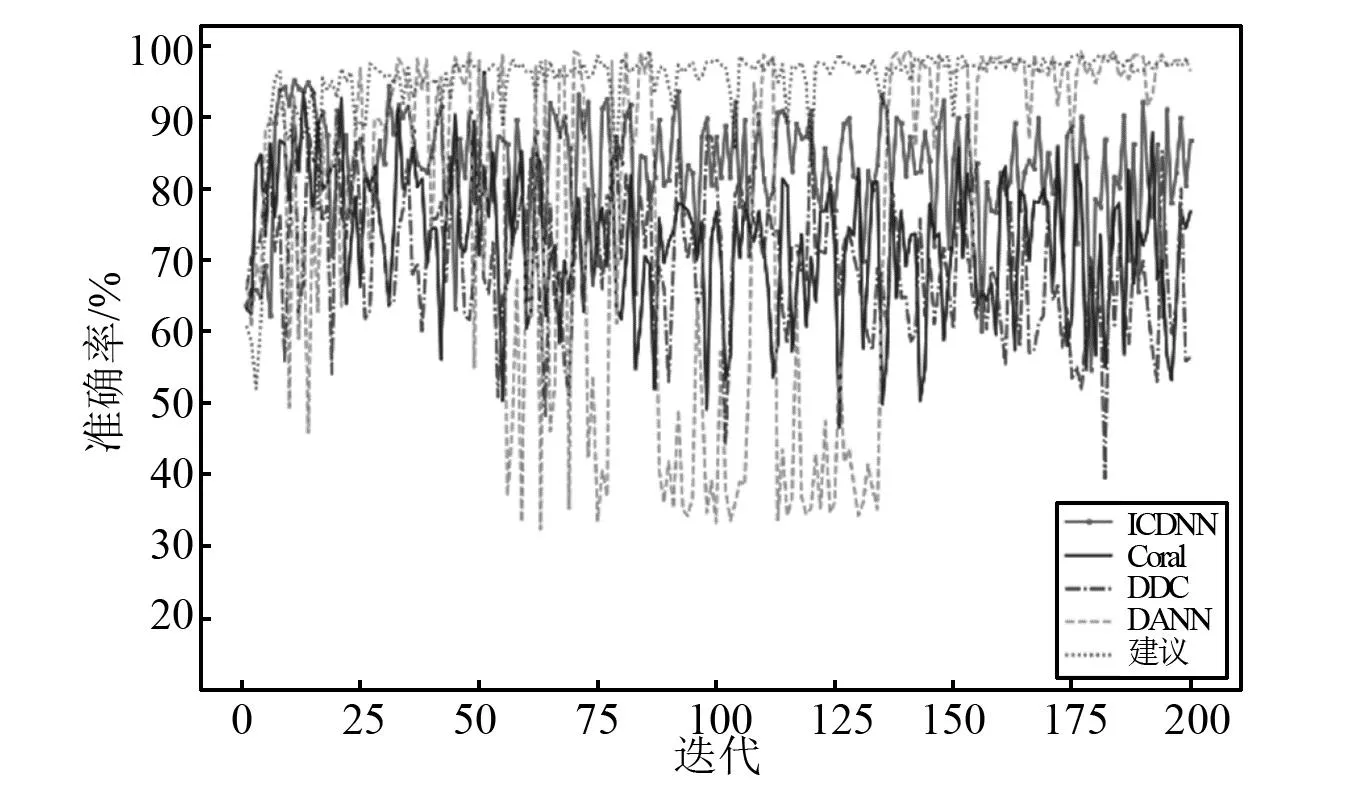
图11 A任务下不同方法的测试精度曲线Fig.11 Test accuracy curves of different methods for Atask
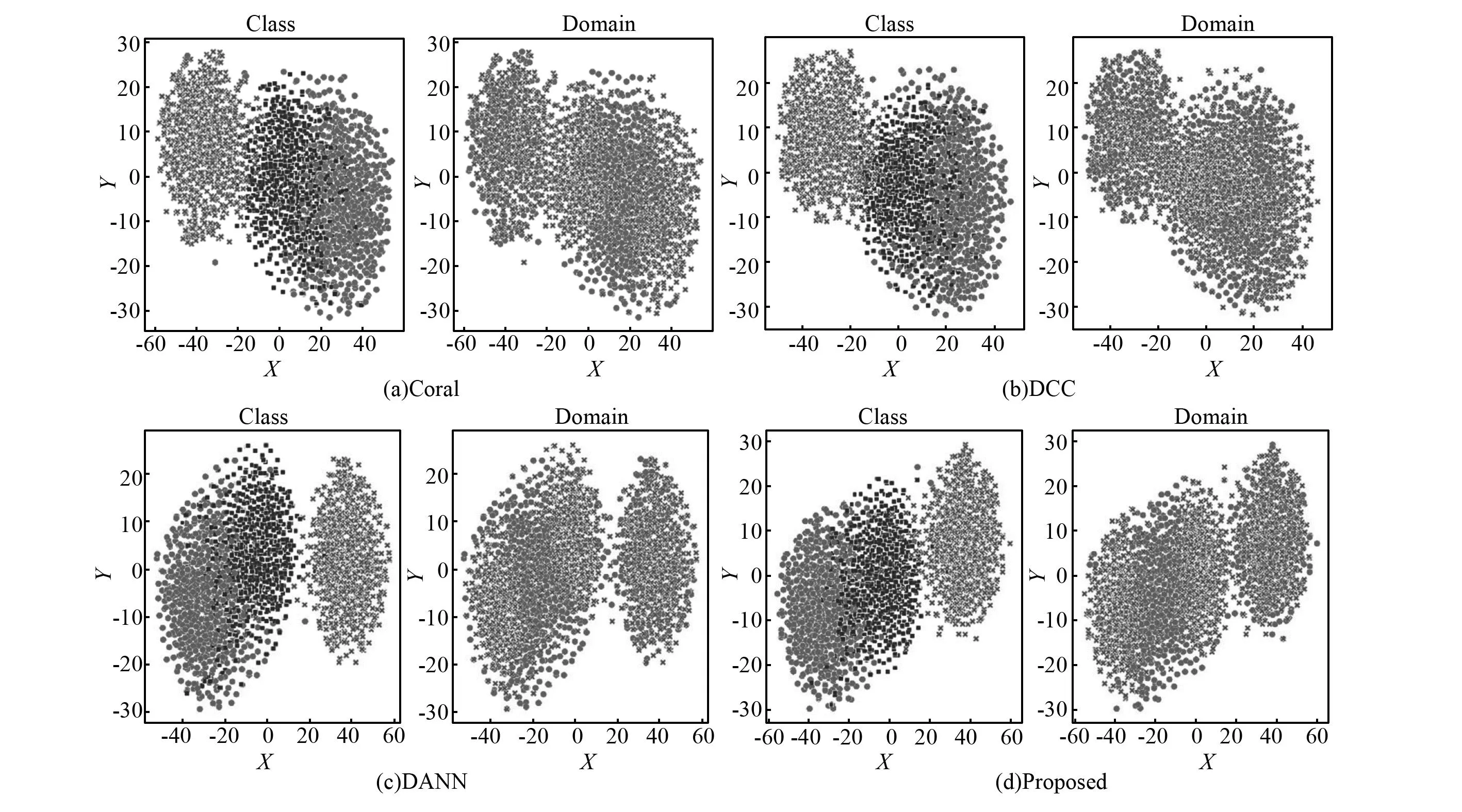
图12 利用t-SNE可视化A场景特征Fig.12 Visualization of A scenarios features with t-SNE
图11可知,对比算法迭代过程中稳定性较差,本文模型在收敛速度和稳定性上更强。利用t-SNE可视化A场景特征,如图12所示。由图12可知,本文模型较于其他算法目标域样本不同类别间距分割明显,区分度更好。
4 结 论
针对滚动轴承的跨域故障诊断问题,本文提出一种基于类别的域自适应模型,它通过1DCNN将原始数据作为输入,提取相邻时间点之间的信息特征,无需对原始数据进行信号处理和人工特征筛选,摆脱了对人工特征提取的依赖,突破了传统方法依赖专家经验的局限性。并通过锚定器将域对齐精细到类别对齐,减小源域和目标域同类别间的距离,扩大不同类间的距离。最后在CWRU和Paderborn轴承数据集上验证了模型的有效性和先进性。基于锚定思想可以将该模型作为一种通用架构应用到其他故障诊断研究中,促进跨域故障诊断领域的进步。
然而在轴承故障诊断领域,很难获取真实有效的数据集,目前研究者们只能利用仿真数据验证模型的有效性,这也是本文面临的一个难点所在。此外在实际工业故障诊断中面临更多的是开放集域自适应问题,不同来源的数据集中可能存在私有标签,共享部分标签。如何利用共享标签提高开放集域自适应的准确率将是下一步的研究方向和工作重点。
猜你喜欢
计算机技术与发展(2020年11期)2020-12-04
电子制作(2018年19期)2018-11-14
自动化学报(2017年11期)2017-04-04
重庆工商大学学报(自然科学版)(2015年10期)2015-12-28
电子与信息学报(2015年12期)2015-08-17
噪声与振动控制(2015年4期)2015-01-01
振动、测试与诊断(2014年5期)2014-03-01
机械与电子(2014年1期)2014-02-28
河南科技(2014年3期)2014-02-27
轴承(2010年2期)2010-07-28
