
学习支架支持的初中人工智能实验教学
——以可视化机器学习软件Orange为例
2023-12-21 11:21陈智敏广东省中山市中山纪念中学
中国信息技术教育 2023年24期
陈智敏 广东省中山市中山纪念中学
《义务教育信息科技课程标准(2022年版)》强调通过相关的实验探究活动帮助学生在感知、理解和应用人工智能技术的过程中增强人工智能意识,感受机器计算与人工计算的异同等,从而培养学生的核心素养。笔者认为,借助恰当的学习支架开展人工智能教学,可以引导学生通过实验探究的方式学习人工智能知识与技能,并了解科学探究的方法与步骤,有助于培养其分析、理解、创造性解决问题的能力以及适应智能化社会的公民素养。然而,目前由于人工智能教育在实验教学层面缺乏学习支架的支持,无法有效开展科学探究。[1]因此,初中人工智能教学有必要科学设计并开展实验探究,借助学习支架的支持,将知识建构、技能培养与思维发展融入实验过程,促进学生核心素养的发展。
●初中信息科技课程实施人工智能实验教学的困境
网络上有丰富的人工智能开源平台和框架,也有科研机构等提供的免费体验平台及实验项目。实验过程多为采集数据,通过调用接口将数据上传到人工智能平台,再返回预测结果,或者调用已有数学模型进行结果预测。因此,大量的人工智能实验项目可以借助平台的支持得到实现,然而对初中学生来说,资源的起点高、难度大,同时由于受到注册、登录账号等问题的影响,在教学中的应用也存在较大的困难,无法进行大规模教学,这也是很多无需安装且具有实用价值的免费平台存在的问题。[2]
现有的图形化编程软件及平台因趣味性强、易上手、可扩展等而成为常用的工具,尤其是在加入多样化的人工智能模块后,极大地降低了学生操作人工智能的门槛。目前,一些软件平台还能与微控制器、单板机等开源硬件连接,加强人工智能与开源硬件的联动。[3]但由于其定位为初步体验智能技术,并不具备调整相关模型参数的功能等,因此,模型解决实际问题的能力有所欠缺,不利于探究实验的开展。
当然,也可以基于Python编程工具等选择适当的第三方扩展库,采集数据进行模型的训练和可视化操作等,从而开展人工智能实验教学,在一定程度上能够有效促进学生的计算思维发展。然而,初中学生的认知规律和数理基础不足以支撑其开展探究,对学生的编程水平要求也较高,难度较大。
●学习支架Orange支持初中人工智能实验教学
学习支架又称“脚手架”,维果斯基将学生的实际发展水平和潜在发展水平相交叠的区域称为最近发展区,而学习支架则是在学生穿越最近发展区时所给予的帮助。在初中人工智能实验教学的开展过程中,需要借助经济实用、方便快捷、安全且逻辑清晰的可视化机器学习软平台或者软件帮助开展模块参数的快速调整等。Orange是由斯洛文尼亚的卢布尔雅那大学计算机与信息科学学院的生物信息实验室开发的一款基于组件的开源可视化数据挖掘及机器学习软件[4],开源的低成本为普及中小学人工智能实验教学提供了合适的学习支架。
Orange安装版和便携版的功能一致,拥有非常直观的交互式用户界面,近2 0 个大类、220个左右的组件提供了数据采集、数据分析、建立模型功能,可直接下载、使用设计好的实验项目,或将预先定义好的多种组件拖拽到画布中以组成工作流,结合交互式的数据探索和清晰的可视化操作,帮助学生更容易地了解机器学习(无需深入学习程序设计知识)。因此,利用Orange开展初中人工智能实验教学是一种有意义的尝试,有助于降低学习难度,提升学生的学习参与度。通过简易的学习活动驱动学生开展实践体验并收集记录实验数据,有助于学生在应用过程中进一步理解机器学习的过程及实现的原理。
●利用Orange软件开展初中人工智能实验教学的实践
1.直观对比选择不同特征所构建模型的预测效果,理解有效特征设计的重要性
决策树是经典的机器学习算法,基于训练集中的各个特征,通过一系列问题来推测样本的所属类别,是记录决策过程的一种树状结构。笔者以“基于决策树算法处理鸢尾花分类”实验为例,引导学生在导入数据集后,根据相关特征,对已知品种的鸢尾花测量数据进行学习进而构建出基于决策树的机器学习模型,并测试评估分类效果,着重探究有效特征设计的重要性。实验设计如图1所示。
鸢尾花分类实验数据集分为3类,每类50个数据,每个数据包含花萼长度、花萼宽度、花瓣长度、花瓣宽度4个特征和1个类别信息。学生根据指引对比在File组件中同时选择4个特征,或者只选择花瓣长度和花瓣宽度等特征组合来训练机器模型Test and Score组件中显示的模型测试结果,从而理解特征的质量很大程度上决定了最终分类结果的好坏,并借助组件Tree Viewer进一步理解决策树算法的实现原理。当然,实验还可以借助Orange软件的智能可视化功能,通过Scatter plot、Distributions等组件观察哪些特征组合能够提供最多的信息并达到最佳的区分效果,或者使用Rank组件根据变量之间的相关性对数据集的特征属性进行评分,从而发现有效的特征属性。
2.直观对比选择不同模型参数所产生的预测效果,理解模型参数调整的必要性
k 近邻算法是指对每个给定的待预测数据,找出k个与其距离最接近的点,根据这些点的类别频数对未知数据的类别进行预测。k近邻算法的思路很简单,但却比较依赖一个合理的k值。那么,k的选取有没有要求?值过大或过小会产生什么样的影响?笔者以“基于k近邻算法处理鸢尾花分类”实验为例,引导学生在导入数据集后,根据相关特征,对已知品种的鸢尾花测量数据进行学习,进而构建一个基于k近邻算法的机器学习模型,并测试评估分类效果,着重探究模型参数调整的必要性。实验设计如图2所示。

图2
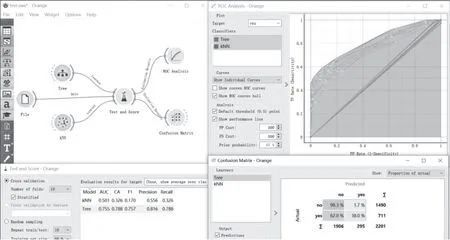
图3
在实验过程中,学生通过对比在KNN组件中选择不同的k值,以及在Test and Score组件中改变数据集划分训练集和测试集的具体参数时所训练的机器模型的测试结果,从而理解k值需要根据数据情况动态调整,如果选取的k值太小,预测结果对邻近的实例点就会非常敏感,如果选取的k值较大,则相当于用较大邻域的训练数据进行预测,整体模型又会变得简单而不具备预测能力。
3.直观对比选择不同的机器学习模型的预测效果,理解机器学习模型的适用性
机器学习的过程就是通过训练已有数据得到某个模型,并且期望该模型能够很好地契合新数据。笔者以“不同分类模型预测效果对比”实验为例,引导学生分别根据鸢尾花数据集等构建基于决策树和k近邻算法的机器学习模型,引导学生通过对比不同模型预测效果,理解机器学习的原理及不同模型的特点。实验设计如图3所示。
在实验过程中,学生通过对比选择不同数据集时在组件Test and Score、ROC Analysis、Confusion Matrix中显示的两种模型的测试结果发现,在鸢尾花数据集上两种模型并没有明显的差异,但是在泰坦尼克号的数据集上两者的分类效果具有明显差异:基于k近邻算法的分类模型的ROC曲线被基于决策树算法的分类模型曲线完全包住,后者的性能优于前者。学生通过测试结果明确,机器学习过程中特定数据集需要通过评估不同模型的训练效果最终选择性能较好的模型。
●结语
本文利用可视化机器学习软件Orange有效开展了初中人工智能实验教学,为学生提供适切的学习支架,降低了学习难度,引导学生直观对比选择不同特征构建模型的预测效果,理解有效特征设计的重要性;直观对比选择不同模型参数所产生的预测效果,理解模型参数调整的必要性;直观对比选择不同的机器学习模型的预测效果,理解机器学习模型的适用性等,帮助学生在应用过程中进一步理解机器学习的过程及实现的原理。后续,笔者还将挖掘更多类型且有效的学习支架,为初中人工智能的回归、分类等教学实验助力,并进一步探寻培养和提升学生核心素养和能力的方法和途径。
猜你喜欢
天天爱科学(2023年3期)2023-02-23
环球时报(2022-07-13)2022-07-13
能源工程(2022年2期)2022-05-23
环球时报(2022-03-14)2022-03-14
重型机械(2020年2期)2020-07-24
小学生必读(低年级版)(2020年4期)2020-06-28
装备制造技术(2019年12期)2019-12-25
童话世界(2018年35期)2018-12-03
电影(2018年8期)2018-09-21
散文诗(2017年18期)2018-01-31
